数据集包含多个生理变量,并设置了一个目标列“参与水平”(Engagement Level),反映学生的情绪和认知状态。目标是提供学生反应的全景视图,帮助教师实时调整教学策略。
特征包括:
-
心率(Heart Rate)
-
皮肤电导率(Skin Conductance)
-
脑电波(EEG,Electroencephalography)
-
体温(Temperature)
-
瞳孔直径(Pupil Diameter)
-
微笑和皱眉强度(Smile and Frown Intensity)
-
皮质醇水平(Cortisol Level)
-
活动水平(Activity Level)
-
环境噪声水平(Ambient Noise Level)
-
光照水平(Lighting Level)
目标列:
- 参与水平
(Engagement Level):分为高度参与(Highly Engaged)、中度参与(Moderately Engaged)和不参与(Disengaged)。
该数据集适用于基于生物传感器的监测系统开发,以及研究学生在教育环境中的情绪与认知参与。通过实时跟踪参与度,帮助研究人员和开发人员构建自适应系统,以改善学生的学习体验和学习效果。

数据加载与预处理
import numpy as npimport pandas as pd# 文件路径,注意这里是目标数据集的存放位置filepath = r"G:\...\2024-12-10-公众号Python机器学习ML.csv"# 读取CSV文件为DataFrame格式df = pd.read_csv(filepath)# 打印前5行数据,快速查看数据结构和字段内容print(df.head()) # 输出数据的前5行,方便初步了解数据# 打印数据类型和非空信息print(df.info()) # 查看每列的字段类型、非空值计数等# 查看数据的描述性统计信息(仅针对数值型列)print(df.describe()) # 输出均值、标准差、最小值、四分位数等信息# 检查缺失值情况print(df.isnull().sum()) # 输出每列的缺失值数量,用于缺失值处理
分析
- 数据初步检查
:快速查看数据的形状和字段信息。
- 数据质量检测
:包括检查缺失值和字段类型。
- 描述性统计
:对数值型特征的分布进行基本分析,为后续EDA提供依据。
数据探索性分析(EDA)
import matplotlib.pyplot as pltimport seaborn as sns# 遍历每一列,对类别型变量绘制计数图for col in df:if df[col].dtype == 'O': # 检查是否是类别型变量sns.countplot(x=col, data=df) # 统计每个类别的样本数量plt.show() # 显示图像print('-------------------------------------------')# 遍历每一列,对数值型变量绘制分布图for col in df:if df[col].dtype != 'O': # 检查是否是数值型变量sns.histplot(df[col], kde=True) # 画出直方图,并叠加核密度曲线plt.show() # 显示图像print('-------------------------------------------')
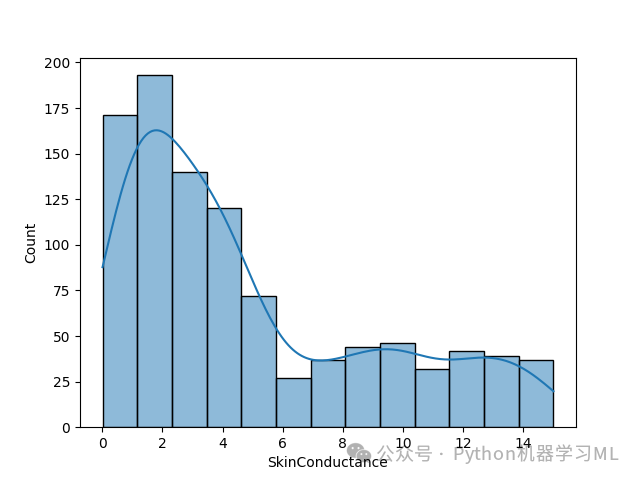
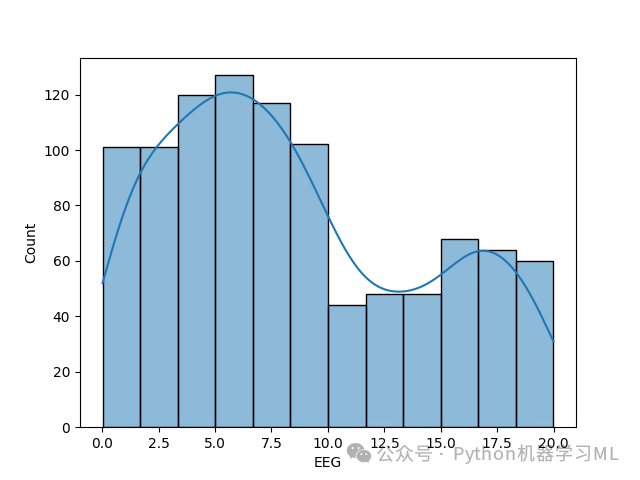
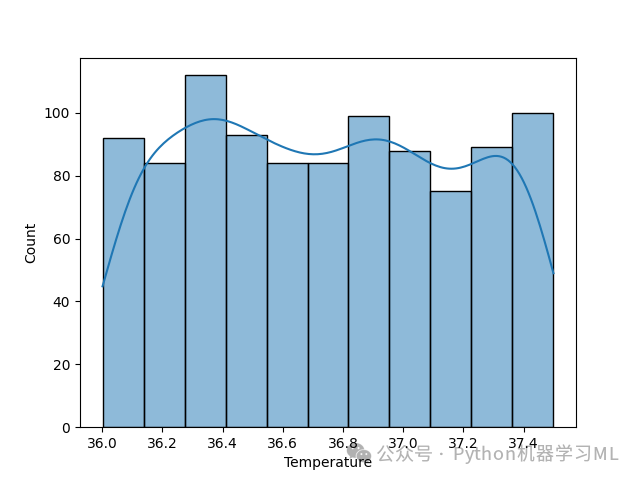
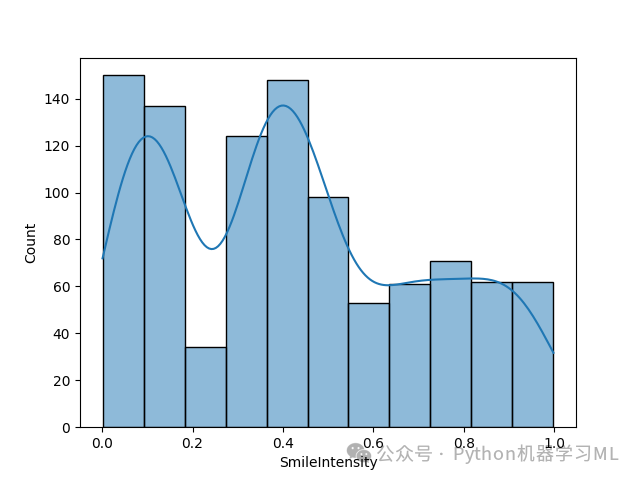
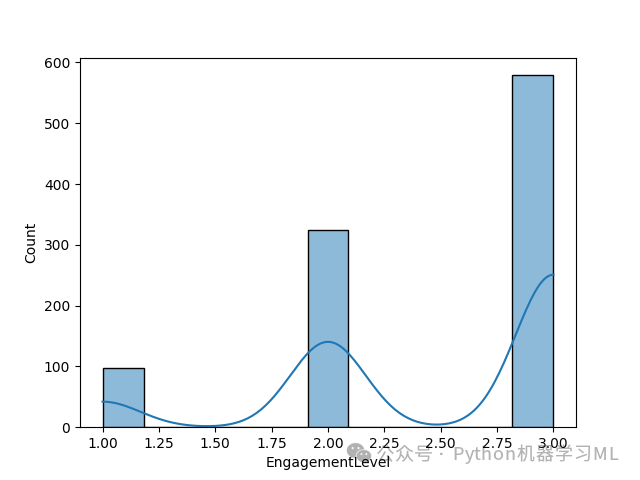
结果分析
-
类别型特征分布:
-
可视化各类别样本的分布,检查是否存在类别不均衡问题。
-
如果某些类别样本过少,可能需要进行采样或合并处理。
-
-
数值型特征分布:
-
直方图可以直观展示数值型特征的分布形状(正态分布、偏态分布等)。
-
核密度曲线(KDE)叠加可以更平滑地观察分布趋势。
-
数据预处理与划分
from sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import LabelEncoder# 初始化标签编码器le = LabelEncoder()# 对类别型变量进行编码for col in df:if df[col].dtype == 'O': # 仅处理类别型变量df[col] = le.fit_transform(df[col]) # 用整数替换类别值# 分离特征变量和目标变量X = df.drop('EngagementLevel', axis=1) # 特征矩阵Y = df['EngagementLevel'] # 目标变量# 划分数据集为训练集和测试集X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=10) # 测试集占比30%
分析
- 编码处理
:将类别型变量转换为整数,方便模型接受。
- 划分数据集
:确保模型能够在独立的测试集上评估性能。
模型训练与预测
代码实现
from sklearn.ensemble import RandomForestClassifier# 初始化随机森林模型model = RandomForestClassifier()# 在训练集上训练模型model.fit(X_train, Y_train)# 在测试集上进行预测ypred = model.predict(X_test)# 打印预测结果print(ypred) # 输出测试集上的预测值
分析
-
随机森林模型是一种基于决策树的集成学习方法,具有较强的鲁棒性。
-
预测结果可与真实值对比,以评估模型性能。
模型评价
代码实现
from sklearn.metrics import confusion_matrix, classification_report# 计算混淆矩阵mat = confusion_matrix(Y_test, ypred)# 绘制混淆矩阵热图cmap = sns.diverging_palette(220, 20, as_cmap=True)sns.heatmap(mat, annot=True, fmt='d', cmap=cmap)plt.savefig('confusion_matrix.png') # 保存图像plt.show() # 显示图像# 打印分类报告print(classification_report(Y_test, ypred))
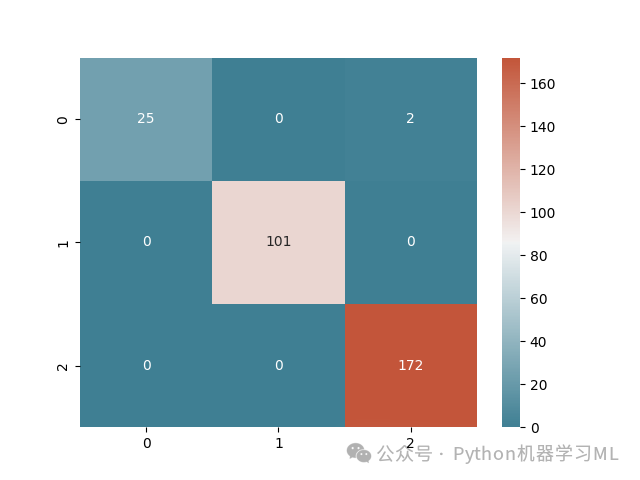
结果分析
-
混淆矩阵:
-
直观展示分类模型在每个类别上的预测结果(真阳性、假阳性、真阴性、假阴性)。
-
对角线上的值越大,模型准确率越高。
-
-
分类报告:
-
提供每个类别的准确率、召回率和 F1 分数。
-
综合评估模型的分类性能。
-
代码实现
from lazypredict.Supervised import LazyClassifier# 初始化 LazyClassifierreg = LazyClassifier(verbose=0, ignore_warnings=False, custom_metric=None)# 训练并评估所有模型models, predictions = reg.fit(X_train, X_test, Y_train, Y_test)# 打印所有模型的评估结果print(models)# 选择最佳模型best_model = models.loc[models['Accuracy'] == models['Accuracy'].max()]print(best_model)
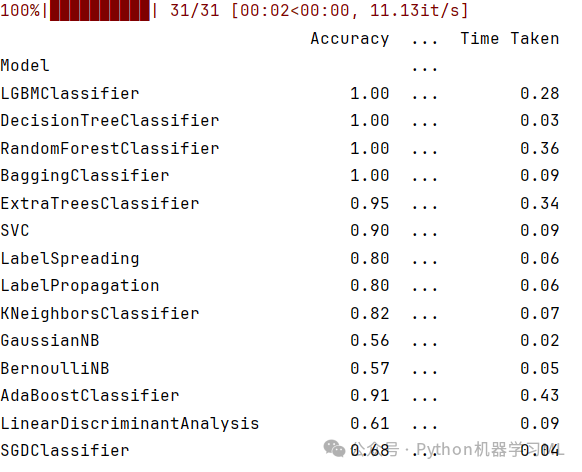
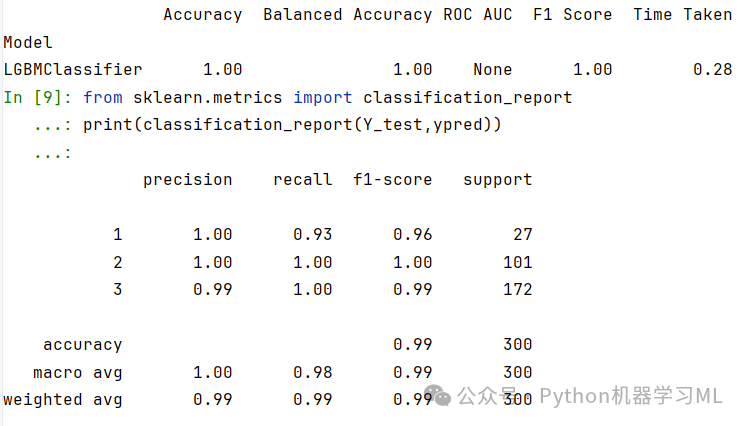
结果分析
- LazyClassifier
自动对多种模型进行训练与评估。
-
最佳模型的选择依据准确率最大化,便于后续进一步优化。
总结
本文通过对学生情绪监控数据的探索与建模,展示了从数据加载、EDA、模型训练到评价的完整流程。实验表明,随机森林和自动模型选择工具(如 LazyPredict)均能为分类问题提供高效解决方案。
关键思路:
-
数据探索是理解问题的基础,类别分布与特征分析尤为重要。
-
模型的评价不仅依赖准确率,还需综合考虑召回率与 F1 分数。
-
自动化工具(如 LazyPredict)能够极大提高建模效率。