一、数据准备
agent.log:时间戳,省份,城市,用户,广告,中间字段使用空格分隔。
二、需求分析

方法一:
(1)用空格分割每一行的数据,需要的数据是省份id和广告id
(2)将省份id和广告id和次数1组成键值对,通过算子map组合成((省份id,广告id),1)
(3)计算相同key的总和,使用算子reduceByKey将相同key的值聚合到一起,在shuffle前有combine操作
(4)用map将((省份id,广告id),sum)改为(省份id,(广告id,sum))
(5)将同一个省份的所有广告进行分组聚合(省份id,List((广告id1,sum1),(广告id2,sum2)…))
(6)对同一个省份所有广告的集合进行排序并取前3条
方法二:
(1)用空格分割每一行的数据,需要的数据是省份id和广告id
(2)将同一个省份的所有广告进行分组聚合(省份id,List(广告id1,广告id2,…))
(3)将广告id和次数1组成键值对,通过算子map组合成(广告id,1),并根据广告id进行分组聚合,再通过算子map转换成List之后取出广告id和List大小
(4)根据List大小进行降序排序,并取出前3条
三、代码实现
方法一:
package com.require
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Demo1 {
def main(args: Array[String]): Unit = {
//1、实例化conf对象以及创建sc对象
val conf = new SparkConf().setMaster("local").setAppName(Demo1.getClass.getSimpleName)
val sc = new SparkContext(conf)
//2、读取文件
val fileRDD: RDD[String] = sc.textFile("F:\\数据\\agent.log")
//3、切分、拼1
val toOneRDD: RDD[((String, String), Int)] = fileRDD.map { x =>
val strings: Array[String] = x.split(" ")
((strings(1), strings(4)), 1)
}
//4、聚合((province,add),sum)
val sumRDD: RDD[((String, String), Int)] = toOneRDD.reduceByKey(_ + _)
//5、将省份作为key,广告加点击数为value:(province,(add,sum))
val mapRDD: RDD[(String, (String, Int))] = sumRDD.map(x => (x._1._1, (x._1._2, x._2)))
//6、将同一个省份的所有广告进行分组聚合(province,List((add1,sum1),(add2,sum2)...))
val groupRDD: RDD[(String, Iterable[(String, Int)])] = mapRDD.groupByKey()
//7、对同一个省份所有广告的集合进行排序并取前3条
val sortRDD: RDD[(String, List[(String, Int)])] = groupRDD.mapValues { x =>
x.toList.sortWith((x, y) => x._2 > y._2).take(3)
}
//8、将数据拉取到Driver端并打印
sortRDD.collect().foreach(println)
sc.stop()
}
}
方法二:
package com.require
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object Demo2 {
def main(args: Array[String]): Unit = {
//1、实例化conf对象以及创建sc对象
val conf = new SparkConf().setMaster("local").setAppName(Demo2.getClass.getSimpleName)
val sc = new SparkContext(conf)
//2、读取文件
val fileRDD: RDD[String] = sc.textFile("F:\\数据\\agent.log")
//3、切分
val mapRDD: RDD[(String, String)] = fileRDD.map(x => {
val strings: Array[String] = x.split(" ")
(strings(1), strings(4))
})
//4、根据省份进行分组(province,List(add1,add2,...))
val groupRDD: RDD[(String, Iterable[String])] = mapRDD.groupByKey()
//5、处理List
val result: RDD[(String, List[(String, Int)])] = groupRDD.map(x => {
//将广告拼1,并分组取出大小
val stringToInt: Map[String, Int] = x._2.map((_, 1)).groupBy(_._1).map(y => {
val size: Int = y._2.toList.size
(y._1, size)
})
//根据广告数量降序排序并取出前三
val tuples: List[(String, Int)] = stringToInt.toList.sortBy(-_._2).take(3)
(x._1, tuples)
})
//6、打印
result.foreach(println)
sc.stop()
}
}
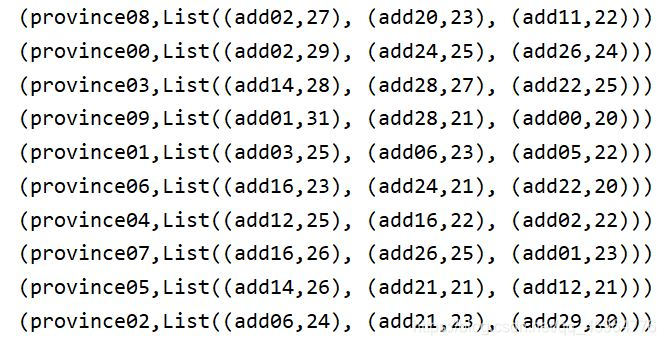
四、运行结果