GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond(当非局部网络遇到挤压激励网络)
论文:GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond
源码:https://gitcode.net/mirrors/xvjiarui/GCNet/-/blob/master/mmdet/ops/gcb/context_block.py
目录
3.2 Global Context Modeling Framework(GC框架)
3.3 Global Context Block(GC模块)
一、背景、出发点和主要工作
背景: GCNet是NLNet的衍生网络。
出发点:通过严格的实证分析,作者发现对于图像中不同的查询位置,non-local network所捕获的全局上下文几乎是相同的。
主要工作:在本文中,作者受上述发现启发,创建了一个基于query-independent(查询无关)公式的简化网络,它保持了NLNet的精度,但显著减少了计算量。进一步观察发现,这种简化的设计与SENet具有相似的结构,因此作者将SE模块与NL模块一同整合入了一个捕获全局上下文的三步式通用框架中。在通用框架中,作者设计了一个轻量级的模块,称为全局上下文(GC)块,可以有效地捕获全局上下文,并且轻量级的属性允许将其应用于骨干网络中的多个层(通用性)。
- 1. 作者基于query-independent公式精简了NLNet,减少了计算量。
- 2. 作者将SE模块与NL模块共同整合入多头注意力机制中,命名为GC模块。
- 3. GC模块是一个轻量级的模块,因此它允许被应用于骨干网络中的多个层中。(通用性,即插即用,估计是因为残差连接的作用)
二、Non-local Networks分析
2.1 重温Non-local Networks
(1)Non-local Networks的定义:
其中,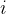
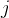
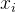
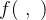
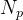
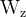
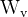
(2)计算像素邻域间的相似度的四种方法:
分别是高斯函数、嵌入式高斯函数、点积和Concatenation(维度拼接操作)。
2.2 分析
作者分别从可视化和数学统计两个方面上对NLNet进行了分析。
1. 可视化
目的: 观察不同像素点的注意力图特征。
过程:从COCO数据集中随机选择六张图像,对每张图像分别可视化三个不同的query位置(红点)通过NL模块生成地注意力图(热图)。作者惊奇地发现,对于不同的query位置,它们的注意力图几乎是相同的。如下图所示:

生成不同的query位置注意力图的公式推测可为:
由这个公式得到的矩阵是query位置处的像素与图像上其他像素之前相似度矩阵。

2. 统计分析
目的:比较不同的query位置生成的注意力图的差异大小。
方法:采用余弦距离和Jensen-Shannon散度(JSD)两种方法进行比较。
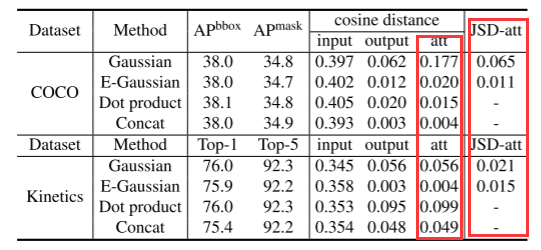
由上表可知,NL模块产生的attention map的余弦差与JSD差都非常小,这再次验证了可视化的观察结果。换句话来说,虽然NL模块打算计算特定于每个query位置的全局上下文,但训练后的全局上下文实际上与query位置无关。
三、Methods(方法)
NL模块最初的定义,采用嵌入式高斯函数计算相似度:
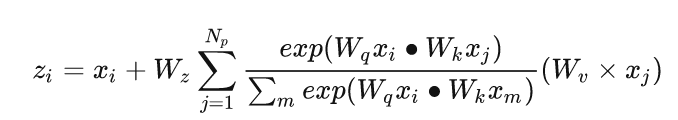
3.1 简化Non-local模块(SNL模块)
1. 去除 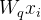
基于上述观察,作者认为全局上下文的捕获实际上与query位置无关,作者设计直接生成一个全局attention map,所有的位置共享这一个attention map,去除生成查询的卷积操作( 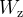
Q:百思不得其解,公式中嵌入式高斯函数
为什么只有一个输入?
A:实际上,据推测这里不是嵌入式高斯函数,而是softmax函数,结合GCNet代码观察,生成全局attention map的是经过一个1x1卷积 + view操作 + softmax函数实现的。softmax函数定义如下:
2. 变换 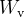
为了进一步降低计算成本,作者应用分配定律将
1x1的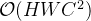
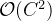
3.2 Global Context Modeling Framework(GC框架)
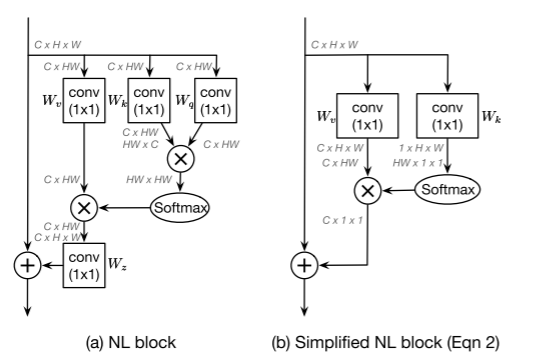
如下图所示,简化的non-local block可以抽象为三个过程:
(a) 全局注意力池化:采用 1x1 卷积 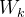

(b) 特征转换(transform):通过 1x1 卷积
(c) 特征聚合:它采用加法将全局上下文特征聚合到每个位置的特征。
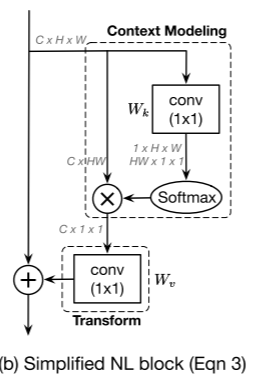
作者将上述过程抽象视为一个全局上下文建模框架,定义为:
其中, (a) 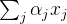
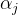
(b) 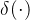
(c) F (·,·) 表示将全局上下文特征聚合到每个位置的特征的融合函数(SNL模块中的广播元素加法)。
3.3 Global Context Block(GC模块)
为了进一步优化训练参数,将特征转换部分中简单的1x1卷积操作替换为bottleneck transform模块,bottleneck transform模块由一个1x1卷积、一个ReLU层、一个1x1卷积和一个 sigmoid函数组成(与SENet中excitation操作基本一致)。这样做可以将参数数量从C⋅C减少到2⋅C⋅C/r。

Q:SNL为什么用1x1卷积代替(SENet)线性层?
A:作用是一样的,都是为了减少运算过程中参数数量。
替换完bottleneck transform模块之后,GC模块的定义如下:
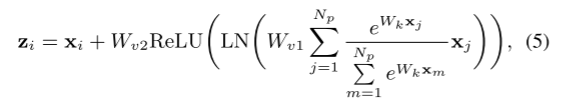
其中,

- (a) 用于上下文建模的全局注意力池。
- (b) bottleneck transform以捕获通道相关性。
- (c) 用于特征融合的广播元素加法。
四、实验
4.1 COCO上的对象检测/分割
评价指标:average-precision分数(AP)。
backbones:Mask R-CNN,FPN或ResNet/ResNeXt。
实验细节:所有模型使用Synchronized SGD进行12个epoch的训练,学习速率初始化为0.02。
(1)消融实验
分别在ResNet/ResNeXt的c4位置的最后一个剩余块之前插入添加一个SE模块、SNL模块、GC模块。
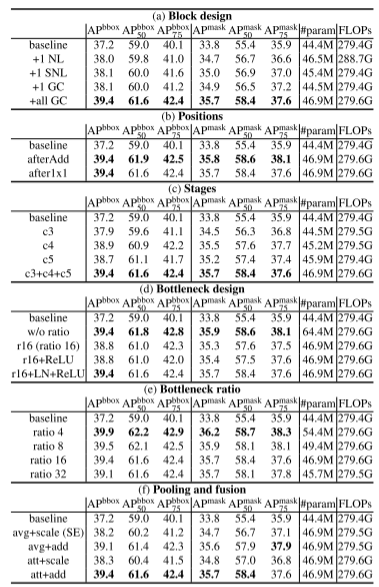
由上表(a)显示,SNL和GC在参数更少、计算更少的情况下都可以达到与NL相当的性能,这表明原来的non-local设计在计算和参数方面存在冗余。
上表(f)列出了池化和融合的不同选择,表明在融合阶段加法比缩放更有效,集中注意力只比普通集中效果好一点点。
(2)backbones增强实验
在效果更佳的backbones上评估我们的GCNet,方法是用ResNet-101和ResNeXt-101替换ResNet-50,向多个层(c3+c4+c5)添加GC模块,并采用级联策略 。

值得注意的是,即使采用了更强的backbones,与基线相比,GCNet的收益仍然很大,这表明GC模块与GC框架是对当前模型能力的补充。
4.2 ImageNet图像分类
与在CoCo数据集上的实验设计,分别在ResNet/ResNeXt的c4位置添加一个SE模块、SNL模块、GC模块,此外在c3+c4+c5位置插入GC模块。
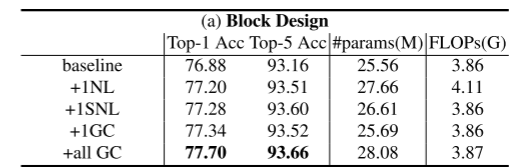
表a报告了不同块的结果。GC块的性能略优于NL块和SNL块,参数少,计算量少,表明了模块设计的通用性和泛化能力。
五、结论
non-local networks作为研究远程依赖的先驱工作,打算建模特定于查询的全局上下文,但只建模与查询无关的上下文。在此基础上,作者对non-local networks进行了简化,并将简化后的模型抽象为全局上下文建模框架。然后作者提出了一个新的实例化框架,GC模块,它是轻量级的,可以有效地捕获远程依赖。CNet是通过将GC块应用到多个层来构建的,它通常在各种识别任务的主要基准上优于简化的NLNet和SENet。
六、代码实现
GCNet/mmdet/ops/gcb/context_block.py
# Copyright (c) OpenMMLab. All rights reserved.
from typing import Union
import torch
from torch import nn
from ..utils import constant_init, kaiming_init
from .registry import PLUGIN_LAYERS
def last_zero_init(m: Union[nn.Module, nn.Sequential]) -> None:
if isinstance(m, nn.Sequential):
constant_init(m[-1], val=0)
else:
constant_init(m, val=0)
@PLUGIN_LAYERS.register_module()
class ContextBlock(nn.Module):
"""ContextBlock module in GCNet.
See 'GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond'
(https://arxiv.org/abs/1904.11492) for details.
Args:
in_channels (int): Channels of the input feature map.
ratio (float): Ratio of channels of transform bottleneck
pooling_type (str): Pooling method for context modeling.
Options are 'att' and 'avg', stand for attention pooling and
average pooling respectively. Default: 'att'.
fusion_types (Sequence[str]): Fusion method for feature fusion,
Options are 'channels_add', 'channel_mul', stand for channelwise
addition and multiplication respectively. Default: ('channel_add',)
"""
_abbr_ = 'context_block'
def __init__(self,
in_channels: int,
ratio: float,
pooling_type: str = 'att',
fusion_types: tuple = ('channel_add', )):
super().__init__()
assert pooling_type in ['avg', 'att']
assert isinstance(fusion_types, (list, tuple))
valid_fusion_types = ['channel_add', 'channel_mul']
assert all([f in valid_fusion_types for f in fusion_types])
assert len(fusion_types) > 0, 'at least one fusion should be used'
self.in_channels = in_channels
self.ratio = ratio
self.planes = int(in_channels * ratio)
self.pooling_type = pooling_type
self.fusion_types = fusion_types
if pooling_type == 'att':
self.conv_mask = nn.Conv2d(in_channels, 1, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
else:
self.avg_pool = nn.AdaptiveAvgPool2d(1)
if 'channel_add' in fusion_types:
self.channel_add_conv = nn.Sequential(
nn.Conv2d(self.in_channels, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.in_channels, kernel_size=1))
else:
self.channel_add_conv = None
if 'channel_mul' in fusion_types:
self.channel_mul_conv = nn.Sequential(
nn.Conv2d(self.in_channels, self.planes, kernel_size=1),
nn.LayerNorm([self.planes, 1, 1]),
nn.ReLU(inplace=True), # yapf: disable
nn.Conv2d(self.planes, self.in_channels, kernel_size=1))
else:
self.channel_mul_conv = None
self.reset_parameters()
def reset_parameters(self):
if self.pooling_type == 'att':
kaiming_init(self.conv_mask, mode='fan_in')
self.conv_mask.inited = True
if self.channel_add_conv is not None:
last_zero_init(self.channel_add_conv)
if self.channel_mul_conv is not None:
last_zero_init(self.channel_mul_conv)
def spatial_pool(self, x: torch.Tensor) -> torch.Tensor:
batch, channel, height, width = x.size()
if self.pooling_type == 'att':
input_x = x
# [N, C, H * W]
input_x = input_x.view(batch, channel, height * width)
# [N, 1, C, H * W]
input_x = input_x.unsqueeze(1)
# [N, 1, H, W]
context_mask = self.conv_mask(x)
# [N, 1, H * W]
context_mask = context_mask.view(batch, 1, height * width)
# [N, 1, H * W]
context_mask = self.softmax(context_mask)
# [N, 1, H * W, 1]
context_mask = context_mask.unsqueeze(-1)
# [N, 1, C, 1]
context = torch.matmul(input_x, context_mask)
# [N, C, 1, 1]
context = context.view(batch, channel, 1, 1)
else:
# [N, C, 1, 1]
context = self.avg_pool(x)
return context
def forward(self, x: torch.Tensor) -> torch.Tensor:
# [N, C, 1, 1]
context = self.spatial_pool(x)
out = x
if self.channel_mul_conv is not None:
# [N, C, 1, 1]
channel_mul_term = torch.sigmoid(self.channel_mul_conv(context))
out = out * channel_mul_term
if self.channel_add_conv is not None:
# [N, C, 1, 1]
channel_add_term = self.channel_add_conv(context)
out = out + channel_add_term
return out