文章目录
Pandas 的名字来源于“Panel Data”和“Python Data Analysis Library”的缩写。它最初由 Wes McKinney 开发,旨在提供高效、灵活的数据操作和分析工具。Pandas 在数据科学、统计分析、金融、经济学等领域得到了广泛应用。
Pandas 是一个用于数据操作和分析的开源 Python 库。它提供了高性能、易于使用的数据结构和数据分析工具。Pandas 的核心数据结构是 Series 和 DataFrame,分别用于处理一维和二维数据。
pandas菜鸟教程:https://www.runoob.com/pandas/pandas-tutorial.html
pandas官方文档:https://pandas.pydata.org/docs
pandas源代码:https://github.com/pandas-dev/pandas
安装导入
1、安装pandas
pip install pandas
2、导入 Pandas
import pandas as pd
主要数据结构
-
Series: 一维数组,类似于 Python 列表或 Numpy 数组,但具有标签(索引)。
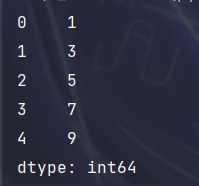
import pandas as pd # 创建一个 Series s = pd.Series([1, 3, 5, 7, 9]) print(s)输出如下:
-
DataFrame: 二维表格数据结构,类似于 Excel 表格或 SQL 表。
import pandas as pd # 创建一个 DataFrame data = { 'Name': ['小仔', '大仔', '梦无矶'], 'Age': [15, 18, 99], 'City': ['上海', '长沙', '杭州'] } df = pd.DataFrame(data) print(df)输出如下:

常用方法和操作
创建数据结构
import pandas as pd
df = pd.DataFrame()
print(df) # 这样创建的就是一个空数据结构
读取和写入数据
# 读取 CSV 文件
df = pd.read_csv('data.csv')
# 写入 CSV 文件
df.to_csv('output.csv', index=False)
数据选择和过滤
import pandas as pd
df = pd.read_csv('excel_path/data.csv')
# 选择列
print(df['Name'])
print("------------------------------")
print(df[['Name', 'Age']])
print("------------------------------")
# 根据索引选择行
print(df.iloc[0]) # 第一行
print("------------------------------")
print(df.iloc[1:3]) # 第二行到第三行
print("------------------------------")
# 根据标签选择行
print(df.loc[0]) # 第一行
print("------------------------------")
print(df.loc[0:1]) # 第一行到第二行
print("------------------------------")
# 条件过滤 # 选择年龄大于30的行
print(df[df['Age'] > 30])
输出:
0 小仔
1 大仔
2 梦无矶
Name: Name, dtype: object
------------------------------
Name Age
0 小仔 15
1 大仔 18
2 梦无矶 99
Name 小仔
Age 15
City 上海
Name: 0, dtype: object
------------------------------
Name Age City
1 大仔 18 长沙
2 梦无矶 99 杭州
------------------------------
Name 小仔
Age 15
City 上海
Name: 0, dtype: object
------------------------------
Name Age City
0 小仔 15 上海
1 大仔 18 长沙
------------------------------
Name Age City
2 梦无矶 99 杭州
数据操作
import pandas as pd
df = pd.read_csv('excel_path/data.csv')
# 添加新列
df['Salary'] = [50000, 60000, 70000]
print(df, end="\n\n")
# 删除列
df = df.drop(columns=['Salary'])
print(df, end="\n\n")
# 修改列 年龄这一列的所有年龄+1
df['Age'] = df['Age'] + 1
print(df, end="\n\n")
# 缺失值处理 填充缺失值 使用每列的均值填充缺失值
df['Age'].fillna(df['Age'].mean(), inplace=True)
print(df, end="\n\n")
输出:
Name Age City Salary
0 小仔 15.0 上海 50000
1 大仔 18.0 长沙 60000
2 梦无矶 NaN 杭州 70000
Name Age City
0 小仔 15.0 上海
1 大仔 18.0 长沙
2 梦无矶 NaN 杭州
Name Age City
0 小仔 16.0 上海
1 大仔 19.0 长沙
2 梦无矶 NaN 杭州
Name Age City
0 小仔 16.0 上海
1 大仔 19.0 长沙
2 梦无矶 17.5 杭州
缺失值填充扩展:
import pandas as pd
import numpy as np
# 创建一个包含缺失值的 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [np.nan, 2, 3, 4],
'C': [1, 2, 3, np.nan]
}
df = pd.DataFrame(data)
# 检查每个单元格是否缺失
print(df.isna())
# 检查每列的缺失值总数
print(df.isna().sum())
# 删除包含缺失值的行
df_dropped_rows = df.dropna()
print(df_dropped_rows)
# 删除包含缺失值的列
df_dropped_cols = df.dropna(axis=1)
print(df_dropped_cols)
# 使用常数填充缺失值
df_filled_constant = df.fillna(0)
print(df_filled_constant)
# 使用前一个值(向前填充)填充缺失值
df_filled_ffill = df.fillna(method='ffill')
print(df_filled_ffill)
# 使用后一个值(向后填充)填充缺失值
df_filled_bfill = df.fillna(method='bfill')
print(df_filled_bfill)
# 使用每列的均值填充缺失值
df_filled_mean = df.fillna(df.mean())
print(df_filled_mean)
# 使用每列的中位数填充缺失值
df_filled_median = df.fillna(df.median())
print(df_filled_median)
# 仅填充特定列的缺失值
df['A'] = df['A'].fillna(df['A'].mean())
print(df)
# 使用线性插值法填充缺失值
df_interpolated = df.interpolate()
print(df_interpolated)
# 先向前填充,再向后填充
df_combined_fill = df.fillna(method='ffill').fillna(method='bfill')
print(df_combined_fill)
基本统计分析
# -*- coding: utf-8 -*-
"""
@Time : 2024/6/4 13:43
@Email : [email protected]
@公众号 : 梦无矶的测试开发之路
@File : 07_基本统计分析.py
"""
__author__ = "梦无矶小仔"
import pandas as pd
df = pd.read_csv('excel_path/data.csv')
# 数据描述性统计
print(df.describe())
print("----------------")
# 计算平均值
print(df['Age'].mean())
# 计算中位数
print(df['Age'].median())
# 计算标准差
print(df['Age'].std())
# 计算最大值
print(df['Age'].max())
# 计算最小值
print(df['Age'].min())
输出:
Age
count 3.00000
mean 44.00000
std 47.65501
min 15.00000
25% 16.50000
50% 18.00000
75% 58.50000
max 99.00000
----------------
44.0
18.0
47.65501022977542
99
15
分组和聚合
# 按城市分组并计算平均年龄
grouped = df.groupby('City')['Age'].mean()
合并和连接
__author__ = "梦无矶小仔"
import pandas as pd
df = pd.read_csv('excel_path/data.csv')
# 创建另一个 DataFrame 注意这个Name相当于是键
data2 = {
'Name': ['小美', '梦无矶', '小仔'],
'Salary': [50000, 60000, 80000]
}
df2 = pd.DataFrame(data2)
# 合并两个 DataFrame
merged_df = pd.merge(df, df2, on='Name', how='inner')
print(merged_df)
输出:
Name Age City Salary
0 小仔 15 上海 80000
1 梦无矶 99 杭州 60000
2 小美 17 杭州 50000
重塑数据
数据重塑(Data Reshaping)是指改变数据表的结构或格式,以便更好地进行数据分析和处理。重塑数据通常包括将数据从宽格式转换为长格式,或从长格式转换为宽格式。
1. pivot 和 pivot_table
pivot 方法用于将长格式数据转换为宽格式数据,类似于 Excel 中的数据透视表。
__author__ = "梦无矶小仔"
import pandas as pd
# 示例数据
data = {
'Date': ['2024-06-01', '2024-06-02', '2024-06-01', '2024-06-02'],
'City': ['杭州', '赣州', '赣州', '杭州'],
'Temperature': [20, 30, 45, 40]
}
df = pd.DataFrame(data)
# 使用 pivot 将长格式数据转换为宽格式
pivot_df = df.pivot(index='Date', columns='City', values='Temperature')
print(pivot_df)
输出:
City 杭州 赣州
Date
2024-06-01 20 45
2024-06-02 40 30
pivot_table方法更灵活,可以进行聚合操作。
# 使用 pivot_table 进行聚合
pivot_table_df = df.pivot_table(index='Date', columns='City', values='Temperature', aggfunc='mean')
print(pivot_table_df)
2. melt
melt 方法用于将宽格式数据转换为长格式数据。
melted_df = pivot_df.reset_index().melt(id_vars='Date', value_vars=['赣州', '杭州'], var_name='City', value_name='Temperature')
print(melted_df)
输出:
Date City Temperature
0 2024-06-01 赣州 45
1 2024-06-02 赣州 30
2 2024-06-01 杭州 20
3 2024-06-02 杭州 40
3. stack和 unstack
stack 方法将数据的列索引转换为行索引,而 unstack则相反。
# 使用 stack 将列索引转换为行索引
stacked_df = pivot_df.stack()
print(stacked_df)
输出:
Date City
2024-06-01 杭州 20
赣州 45
2024-06-02 杭州 40
赣州 30
dtype: int64
# 使用 unstack 将行索引转换为列索引
unstacked_df = stacked_df.unstack()
print(unstacked_df)
输出与 pivot_df相同:
City 杭州 赣州
Date
2024-06-01 20 45
2024-06-02 40 30
常用方法总结
- 读取和写入数据:
pd.read_csv(),pd.read_excel(),pd.read_sql()DataFrame.to_csv(),DataFrame.to_excel(),DataFrame.to_sql()
- 数据选择和过滤:
DataFrame.loc[],DataFrame.iloc[],DataFrame.at[],DataFrame.iat[]- 条件过滤:
DataFrame[condition]
- 数据操作:
- 添加/删除列:
DataFrame['new_column'],DataFrame.drop() - 修改列:直接赋值
- 缺失值处理:
DataFrame.isnull(),DataFrame.fillna(),DataFrame.dropna()
- 添加/删除列:
- 统计分析:
- 描述性统计:
DataFrame.describe() - 计算:
mean(),median(),std(),sum(),min(),max()
- 描述性统计:
- 分组和聚合:
DataFrame.groupby(),DataFrame.agg(),DataFrame.apply()
- 合并和连接:
pd.merge(),DataFrame.join(),pd.concat()
- 重塑数据:
- 转置:
DataFrame.T - 重置索引:
DataFrame.reset_index() - Pivot表:
DataFrame.pivot(),DataFrame.pivot_table()
- 转置:
其他的不会再查!
pandas操作excel
pandas不能直接操作excel,因此我们需要依赖其他的第三方库进行操作,比如openpyxl。
安装相关库
pip install openpyxl
读取单个工作表
# 读取 Excel 文件中的第一个工作表
df = pd.read_excel('excel_path/data.xlsx')
print(df)
输出:
# 读取 Excel 文件中的第一个工作表
df = pd.read_excel('data.xlsx')
print(df)
读取指定工作表
# 读取 Excel 文件中的指定工作表,读取Sheet2表,如果该表不存在会报错
df = pd.read_excel('data.xlsx', sheet_name='Sheet2')
print(df)
输出:
Name City Age
0 小仔 杭州 98
读取多个工作表
# 读取 Excel 文件中的多个工作表
dfs = pd.read_excel('data.xlsx', sheet_name=['Sheet1', 'Sheet2'])
print(dfs['Sheet1'])
print(dfs['Sheet2'])
# 读取所有工作表
dfs = pd.read_excel('data.xlsx', sheet_name=None)
for sheet_name, df in dfs.items():
print(f"Sheet name: {sheet_name}")
print(df)
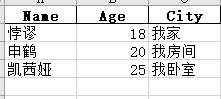
写入单个 DataFrame 到 Excel
__author__ = "梦无矶小仔"
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['悖谬', '申鹤', '凯茜娅'],
'Age': [18, 20, 25],
'City': ['我家', '我房间', '我卧室']
}
df = pd.DataFrame(data)
# 写入到 Excel 文件
df.to_excel('excel_path/output.xlsx', index=False)
写入多个 DataFrame 到不同工作表
# -*- coding: utf-8 -*-
"""
@Time : 2024/6/4 15:20
@Email : [email protected]
@公众号 : 梦无矶的测试开发之路
@File : 13_写入多个DataFrame到Excel.py.py
"""
__author__ = "梦无矶小仔"
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['悖谬', '申鹤', '凯茜娅'],
'Age': [18, 20, 25],
'City': ['我家', '我房间', '我卧室']
}
df = pd.DataFrame(data)
# 创建另一个 DataFrame
data2 = {
'Name': ['刻晴', '丽莎', '巴尔泽布'],
'Age': [19, 21, 24],
'City': ['璃月', '蒙德', '稻妻']
}
df2 = pd.DataFrame(data2)
# 写入到不同工作表
with pd.ExcelWriter('excel_path/write1.xlsx') as writer:
df.to_excel(writer, sheet_name='Sheet1', index=False)
df2.to_excel(writer, sheet_name='Sheet2', index=False)
追加数据到现有 Excel 文件
__author__ = "梦无矶小仔"
import pandas as pd
# 读取现有的 Excel 文件
existing_df = pd.read_excel('excel_path/output.xlsx', sheet_name='Sheet1')
# 新数据
new_data = {
'Name': ['无妨', '紫霄'],
'Age': [55, 60],
'City': ['木星', '海王星']
}
new_df = pd.DataFrame(new_data)
# 追加新数据到现有 DataFrame
updated_df = pd.concat([existing_df, new_df], ignore_index=True)
# 写入回 Excel 文件
with pd.ExcelWriter('excel_path/output.xlsx', mode='a', if_sheet_exists='replace') as writer:
updated_df.to_excel(writer, sheet_name='Sheet1', index=False)
写入带有超链接的内容
pandas里面写入使用=HYPERLINK字段处理。
# 字典数据
df = pandas.DataFrame(字典数据, index=[0])
# 加超链接
df._set_value(0, '字段名', '=HYPERLINK("{}", "点击跳转详情")'.format(字段名))
示列:
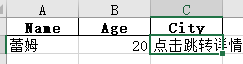
__author__ = "梦无矶小仔"
import pandas as pd
# 创建一个 DataFrame
data = {
'Name': ['蕾姆'],
'Age': [20],
'City': ['独栋别墅']
}
df = pd.DataFrame(data, index=[0]) # 多行写入不需要加index=[0]
goto = 'https://www.baidu.com/s?wd=%E7%8B%AC%E6%A0%8B%E5%88%AB%E5%A2%85'
# 加超链接 0表示写入的位置
df._set_value(0, "City", '=HYPERLINK("{}", "点击跳转详情")'.format(goto))
# 写入到 Excel 文件
df.to_excel('excel_path/write2.xlsx', index=False)
点击就可以直接跳转了。
借助openpyxl写入
__author__ = "梦无矶小仔"
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils.dataframe import dataframe_to_rows
from openpyxl.styles import Font
# 现有的 Excel 文件
excel_file = 'excel_path/write3.xlsx'
# 创建新的 DataFrame 以追加
new_data = {'Name': ['百度', 'CSDN主页'], 'URL': ['https://www.baidu.com', 'https://blog.csdn.net/qq_46158060']}
new_df = pd.DataFrame(new_data)
# 使用 openpyxl 加载现有的工作簿
wb = load_workbook(excel_file)
# ws = wb.active
ws = wb["Sheet1"]
# 找到最后一行
if ws.max_row == 1 and ws.cell(row=1, column=1).value is None:
last_row = 0
else:
last_row = ws.max_row
# 将新的 DataFrame 追加到现有的 Excel 文件
for r in dataframe_to_rows(new_df, index=False, header=last_row == 0):
ws.append(r)
# 添加超链接和样式
start_row = last_row + 1 if last_row != 0 else 1
for row in range(start_row, start_row + len(new_df)):
cell = ws.cell(row=row, column=1)
url = ws.cell(row=row, column=2).value
cell.hyperlink = url
cell.font = Font(color="0000FF", underline="single")
# 保存工作簿
wb.save(excel_file)
上面这些全部可以自己封装成通用的方法,以后要使用直接调用就可以了。
本文所有代码地址:
github:https://github.com/Lvan826199/mwj_utils
gitee:https://gitee.com/xiaozai-van-liu/mwj_utils
关于使用openpyxl进行excel操作,比如样式写入,单元格样式调整,链接跳转,放到下次讲。