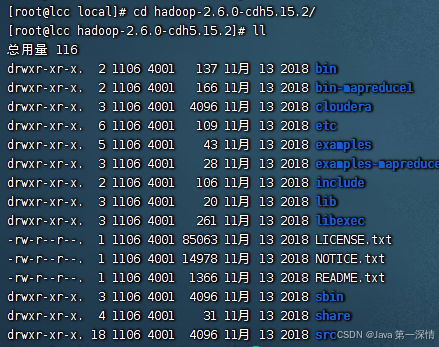
1、上传Hadoop安装包至linux并解压
tar -zxvf hadoop-2.6.0-cdh5.15.2.tar.gz安装包:
链接:https://pan.baidu.com/s/1u59OLTJctKmm9YVWr_F-Cg
提取码:0pfj
2、配置免密码登录
生成秘钥:
ssh-keygen -t rsa -P ''
将秘钥写入认证文件:
cd ~/.ssh
cat id_rsa.pub >> ~/.ssh/authorized_keys
修改认证文件权限:
chmod 600 ~/.ssh/authorized_keys3、配置环境变量
将
Hadoop
加入环境变量
/etc/profile
:
vi /etc/profile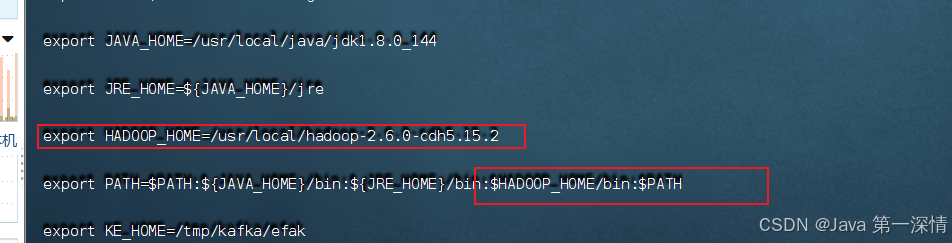
4、修改Hadoop配置文件
1
) 修改hadoop-env.sh
文件
vi /usr/local/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hadoop-env.sh
修改
JAVA_HOME
:(这里要改成你自己linux中的jdk路径)
export JAVA_HOME=/usr/local/jdk1.8.0_181
2
)修改
core-site.xml
文件
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://lcc:9090</value>
</property>
</configuration>
3) 修改
hdfs-site.xml
文件
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.6.0-cdh5.15.2/tmp</value>
</property>
</configuration>
4) 修改mapred-site.xml文件
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5
)修改
slaves
文件
vi slaves
改成上面的
lcc(这里就是你的一个主机名,注意要在hosts文件中配置好 ip地址 主机名)
这里配置的是单节点, 指向本机主机名称。
6)修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5、启动Hadoop服务
进入到sbin目录
cd /usr/local/hadoop-2.6.0-cdh5.15.2/sbin/执行启动脚本
./start-all.sh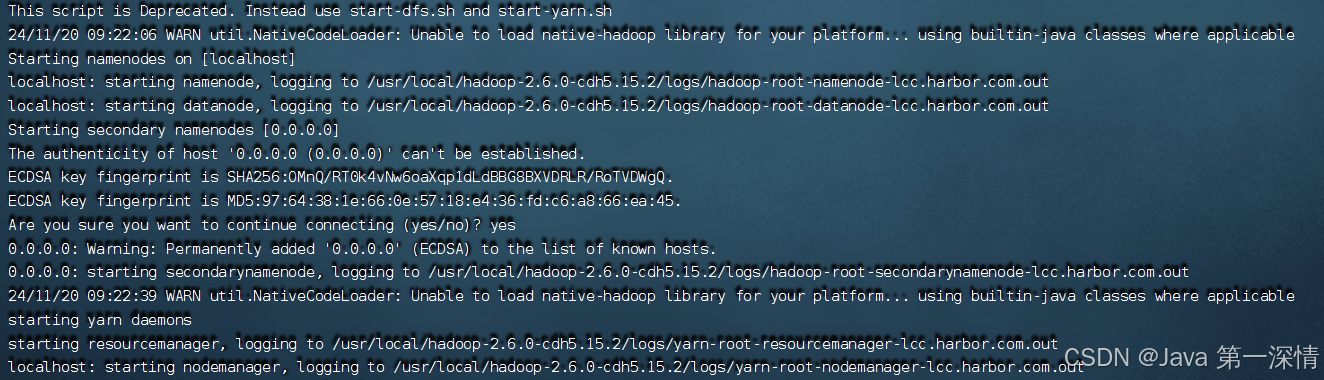
上传一个文件, 用于测试:
hdfs dfs -put /usr/local/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hadoop-env.sh /如果遇到如下报错:

请执行以下命令解决

再次重新执行hdfs上传即可
6、访问验证
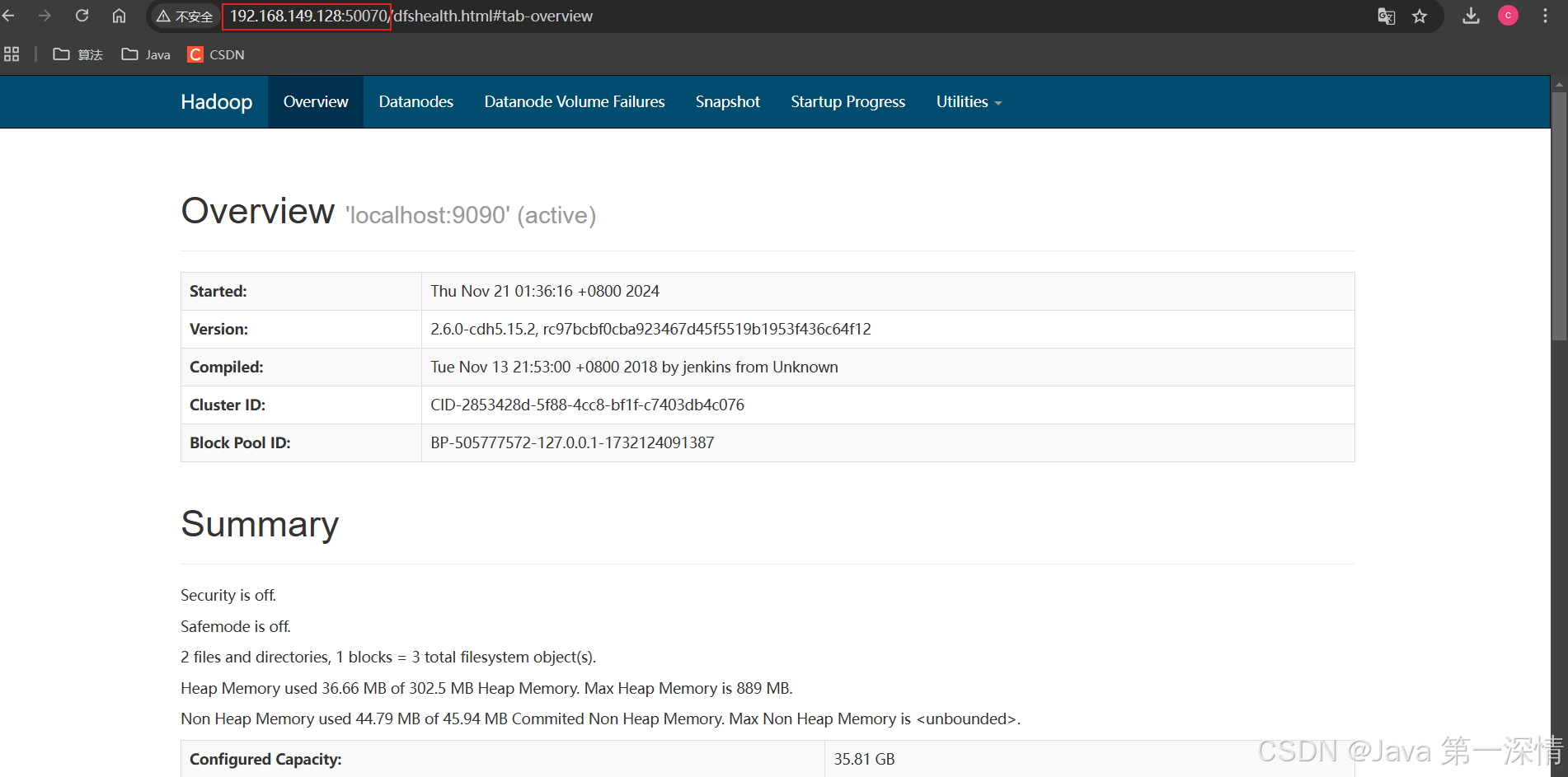
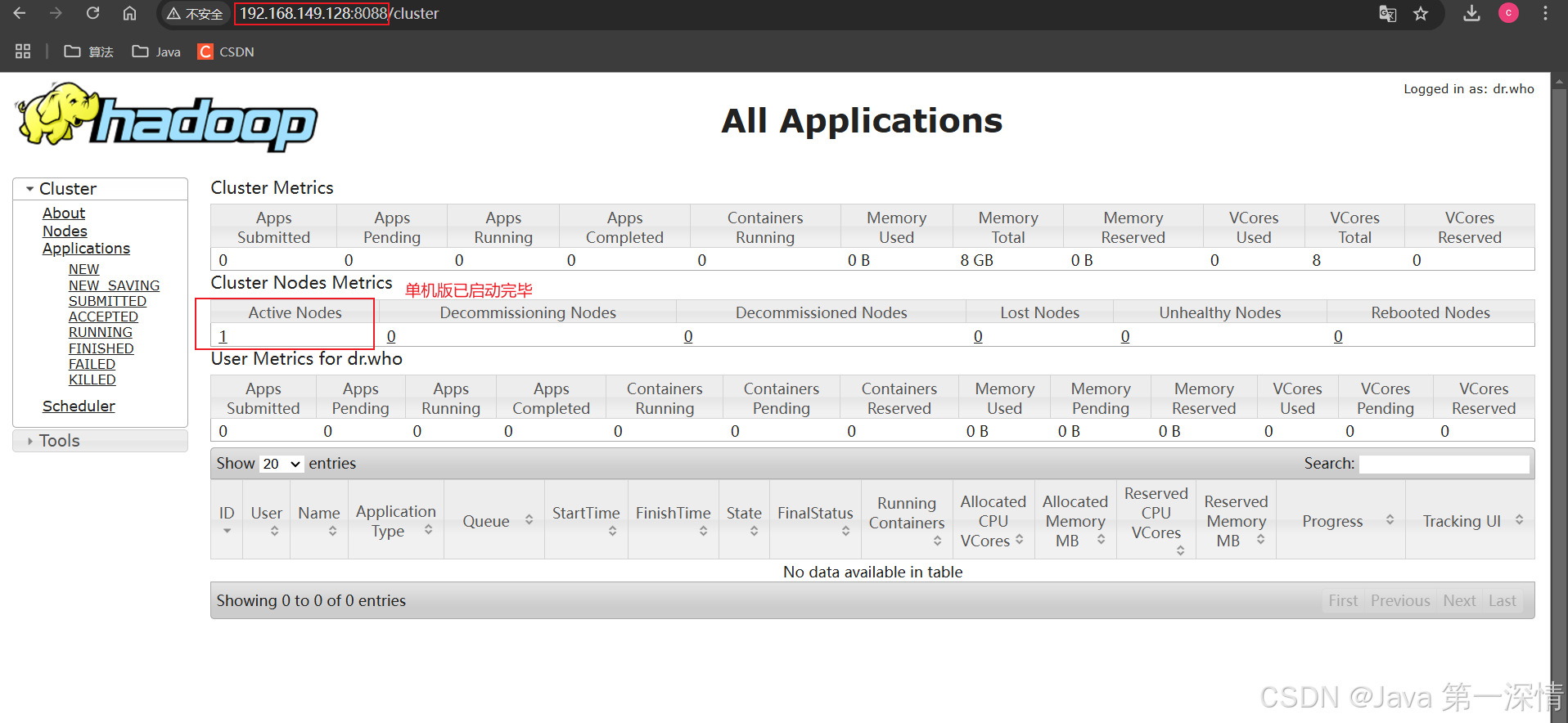
至此Hadoop单机版安装完毕