java集合
一、集合的概述
1.1 什么是集合?
数字就是一个集合。集合实际上就是一个容器。可以来容纳其他类型的数据
1.2 为什么集合所有的较多?
集合是容器,是载体,可以一次容纳多个对象.
1.3 集合不能够直接存储基本数据类型,另外集合也不能够直接直接存储java对象(或者集合中存储的引用)
存在自动装箱.
1.4 在java中不同的集合底层对应不同的数据结构,往不同的集合中存储元素,等于将数据放到了不同的数据结构中.
new ArrayList() 创建一个集合,底层是数组
new LinkedList() 创建一个集合对象,底层是链表
new TreeSet() 树结构
1.5集合在java jdk的java.util包下
二、集合的继承结构图
java中集合分为两大类:
一类是以单个方式存储元素: 这一类的超级父接口是java.util.Collection;
一类是以键值对的方式存储元素: 这一类集合的父接口java.util.Map;
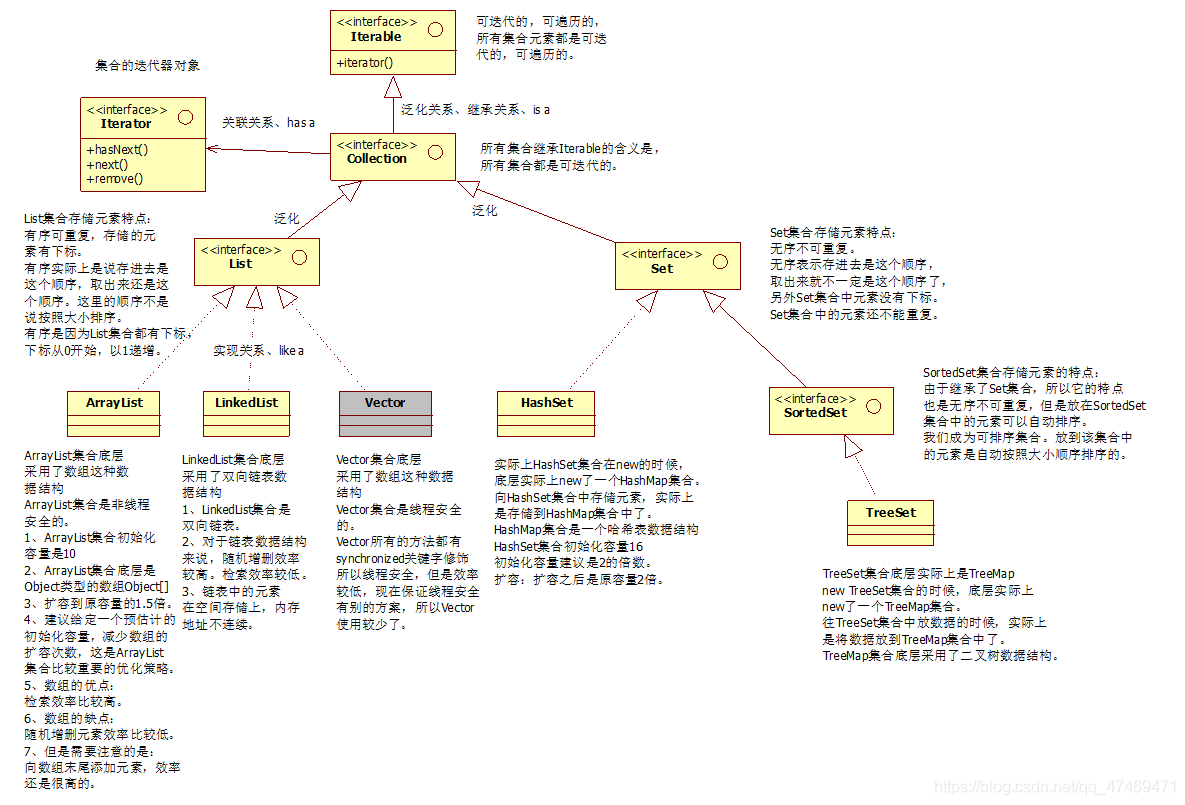
三、Collection接口的常用方法
没有使用泛型之前,Collection中可以存储Object类型,使用泛型过后,Collection中只能够存储具体的类型。
boolean add(Object e) 向集合中添加元素
//Collection c = new Collection();
// 是接口无法实例化
Collection c = new ArrayList();
c.add(1200); // 自动装箱,实际上是放入了一个对象的内存地址
// Integer i = new Integer(1200);
c.add(true);
size()获取集合中元素的个数
System.out.println(c.size()); // 2
void clear()清除集合中所有的元素
c.clear();
System.out.println(c.size()); // 0
boolean contains(Object o)判断集合是否包含指定元素
Collection c = new ArrayList();
c.add(1200);
c.add(true);
System.out.println(c.contains(1200)); // true
System.out.println(c.contains(3)); // false
boolean remove(Object o)删除集合中某个元素
Collection c = new ArrayList();
c.add(1200);
c.add(true);
c.remove(1200);
System.out.println(c.size());
boolean isEmpty()判断集合是否为空
Collection c = new ArrayList();
c.add(1200);
c.add(true);
System.out.println(c.isEmpty()); // false 表示不为空
Object[] toArray()将集合转换为数组
Collection c = new ArrayList();
c.add(1200);
c.add(4323);
Object[] arr = c.toArray();
System.out.println(arr[0]+"--"+arr[1]);
四、迭代
Iterator iterator()返回在此collection的元素上进行迭代的迭代器
获取迭代器的目的是为了遍历集合,
在Map集合中不能够使用,在所有的Collection的子类中使用
迭代器的方法
boolean hashNext()
next()
void remove() // 删除的一定是迭代器指向的当前元素
Collection的迭代
Collection c = new ArrayList();
c.add(1200);
c.add(4323);
Iterator iterator = c.iterator();//获取集合的迭代器对象
while (iterator.hasNext()){ // boolean hasNext()如果仍有元素可以迭代返回true
System.out.println(iterator.next());// 迭代下一个元素
}
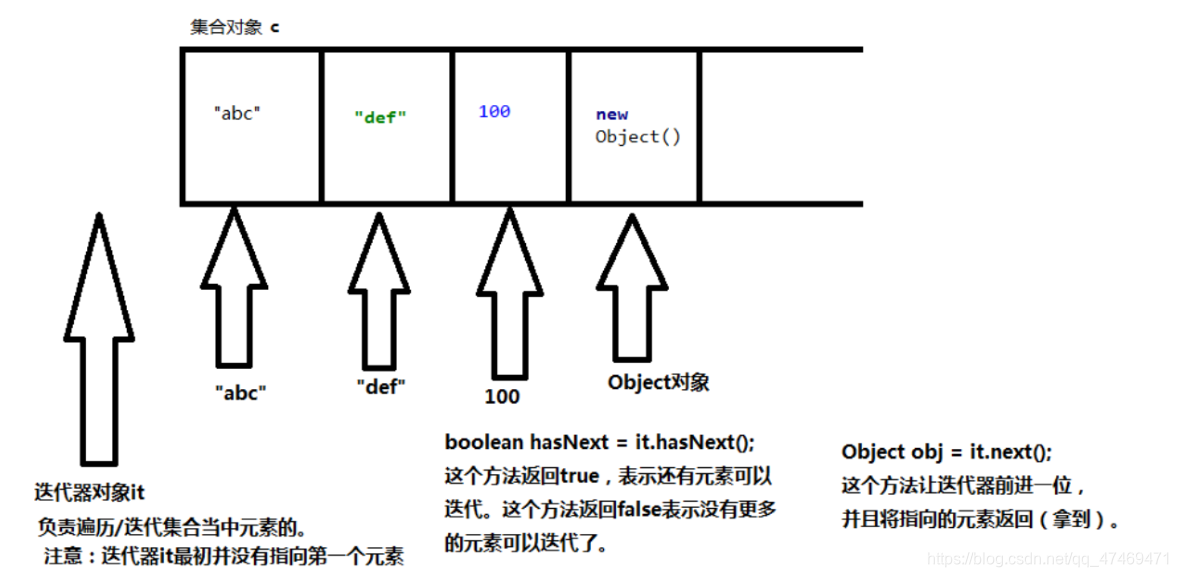
保存进去的是什么类型输出的就是什么类型
迭代器的注意事项
ArrayList arrayList = new ArrayList();
Iterator iterator = arrayList.iterator();
//此时的迭代器指向的是没有元素状态下的迭代器
arrayList.add("张某");
arrayList.add("qiang");
while (iterator.hasNext()){
System.out.println(iterator.next());
}
// 报错 java.util.ConcurrentModificationException
// 集合结构发生改变,迭代器没有重新获取的时候调用next()方法的时候报错
总结:集合结构只要发生改变,迭代器必须重新获取.
使用在迭代集合元素的过程中,不能够调用集合对象remove方法,删除元素.
会改变集合的结构.
但是使用集合的remove方法可以删除数据.
ArrayList arrayList = new ArrayList();
arrayList.add("张某");
arrayList.add("qiang");
Iterator iterator = arrayList.iterator();
while (iterator.hasNext()){
Object o = iterator.next();
System.out.println(o);
iterator.remove(); // 删除的是当前的迭代器指向的元素.
}
五、contains()方法解析
contains方法是用来判断集合中是否包含某个元素的方法,底层判断的方法是euqals()方法.
注意放入集合的对象需要重写equals方法,这样比较的就是内容,否则就是内存地址.
public class one {
public static void main(String[] args) {
List arr = new ArrayList();
arr.add(new afg("asd"));
afg s = new afg("asd");
System.out.println(arr.contains(s)); // true
}
}
class afg{
String s;
public afg(String s) {
this.s = s;
}
public afg() {
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
afg afg = (afg) o;
return Objects.equals(s, afg.s);
}
}
六、remove方法解析
依旧是调用了equals()方法.
ArrayList arrayList = new ArrayList();
String s = "aasd";
arrayList.add(s);
String ss = "aasd";
arrayList.remove(ss);
System.out.println(arrayList.size()); // 0
七、List接口的常用方法
List集合的特点:有序可重复
有序:因为List集合的元素有下标
List接口除了继承了Collection的方法还存在自己特殊的方法
void add(int index, E element)
E get(int index)
int indeof(Object o)//获取指定对象第一次出现的索引
int lastIndexof(Object o)//最后出现的索引
E remove(int index)//删除指定下标位置的元素
E set(int index, E element)//修改指定下标的数据
List list = new ArrayList();
list.add("a");
list.add("b");
list.add("c");
list.add(0,"d");
// 添加到指定下标的位置,其余的数据往后面移动,方法应用不多,效率较低
// Iterator integer = list.iterator();
// while (integer.hasNext()){
// System.out.println(integer.next());
// }
//因为有下标的缘故所以可以不使用迭代遍历
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
//获取指定对象第一次出现的索引
System.out.println(list.indexOf("d"));
//最后出现的索引
System.out.println(list.lastIndexOf("c"));
//删除指定下标位置的元素
list.remove(0);
list.set(0,"aa");
八、ArrayList
1.ArrayList 初始化容量是10,还可以手动指定初始化容量
底层先创建了一个长度为0的数组,当添加第一个元素的时候,初始化容量为10,扩容是原容量的1.5倍.
List list = new ArrayList(20);//定义初始化长度
System.out.println(list.size()); // 0 size获取的是集合中元素的个数
2.底层是Object类型的数组
3.ArrayList集合的扩容是原容量的1.5倍,底层是数组,优化的方法就是尽可能少的扩容,或者开始就尽量设置初始化的容量.
4.ArrayList集合的构造方法
Collection c = new HashSet();
c.add(100);
c.add(200);
c.add(300);
// 通过这个构造方法就可以将hashset集合转化为ArrayList结合
List list = new ArrayList(c);
九、LinkedList
链表的优点:
由于链表上二点元素空间存储上内存地址不连续
所以随机增删元素的时候不会有大量元素的位移,因此随机增删效率较高
所以在以后的开发中,如果遇见随机增删集合中的元素业务比较多,建议使用LinkedList
链表的缺点:
不能通过数学表达式计算查找元素的内存地址,每一次都是从头节点开始遍历,直到找到为止,所以Linkedlist集合的查找的效率较低.
ArrayList : 把检索发挥到极致.(末尾添加元素效率还是高),非线程安全
LinkedList:把随机增删发挥到极致.
LinkedList的底层也是有下标的,但是检索查找某个元素的效率比较低,因为只能够从头节点开始
List list = new LinkedList();
list.add("a");
list.add("b");
for (int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
// LinkedList结合没有初始化容量
十、Vector
10.1vevtor的特点
1.底层是一个数组
2.初始化容量:10
3.扩容之后是之前容量的两倍
4.Vector中所有的方法都是线程安全的,都有synchronized关键字.
是线程安全的,效率较低,使用较少
Collections
java.util.Collection 是集合接口
java.util.Collections是集合的工具类
- Collections.synchronizedList(集合对象)变成线程安全的
List list = new ArrayList();
Collections.synchronizedList(list);
十一、泛型
jdk5.0后推荐出来的新特征
1)不使用泛型的缺点?
会导致使用迭代器取出数据的时候是Object类型的,无法直接调用方法,需要向下转型.
2)使用泛型机制的优点
集合List中只允许保存指定的数据类型。
迭代出来的数据都是指定的数据类型不需要强制转换。
List<String> ar = new ArrayList<String>();
ar.add("12");
ar.add("13");
for (String s : ar){
System.out.println(s);
}
泛型只在程序编译的阶段起作用,只是给编译器参考的。(运行阶段意义不大)
3)泛型的缺点
导致集合中存储的元素缺乏多样性.
自动类型推断机制(又称为:钻石表达式)
List ar = new ArrayList<>(???); 变化就是???的位置可以不写数据类型,jdk8之后的可以
List<String> ar = new ArrayList<>();
ar.add("12");
ar.add("13");
for (String s : ar){
System.out.println(s);
}
自定义泛型
在定义类的时候自定义泛型会导致,在创建对象的是时候指定的什么数据类型,
类里面的对应的泛型区域就是指定的类型.
定义传入的数据类型
public class one {
public static void main(String[] args) {
gen<String> s = new gen<>();
s.doSome("哈哈哈");
}
}
class gen<asdf>{
public void doSome(asdf o){
System.out.println(o);
}
}
//asdf 只是单纯的标识符,没有特殊意义,具体的数据类型还是在创建对象时候指定
// 如果保存进集合的数据类型不是指定的数据类型会类型不匹配.
定义返回的数据类型
public class one {
public static void main(String[] args) {
gen<String> s = new gen<>();
System.out.println(s.doSome("12083"));
}
}
class gen<asdf>{
public asdf doSome(asdf o){
return o;
}
}
注意:自定义泛型的时候<> 里面定义的是标识符,java源代码经常出现的是E和T.
e是element单词首字母
T是type单词首字母
十二、 foreach
for(元素类型 变量名 : 数组或集合){
System.out.println(变量名);
}
缺点,没有下标无法修改数据
十三、Set
HashSet
Set s1 = new HashSet();
s1.add("a");
s1.add("b");
s1.add("c");
for (Object o : s1){
System.out.println(o);
}
1)无序(指的是没有下标),不可重复
2)放到HashSet里面的元素实际上是放到了HashMap集合的key部分.
TreeSet
Set s1 = new TreeSet();
s1.add(12);
s1.add(32);
for (Object o : s1){
System.out.println(o);
}
1)无序(指的是没有下标),不可重复
2)可以按照大小排序,称为可排序集合
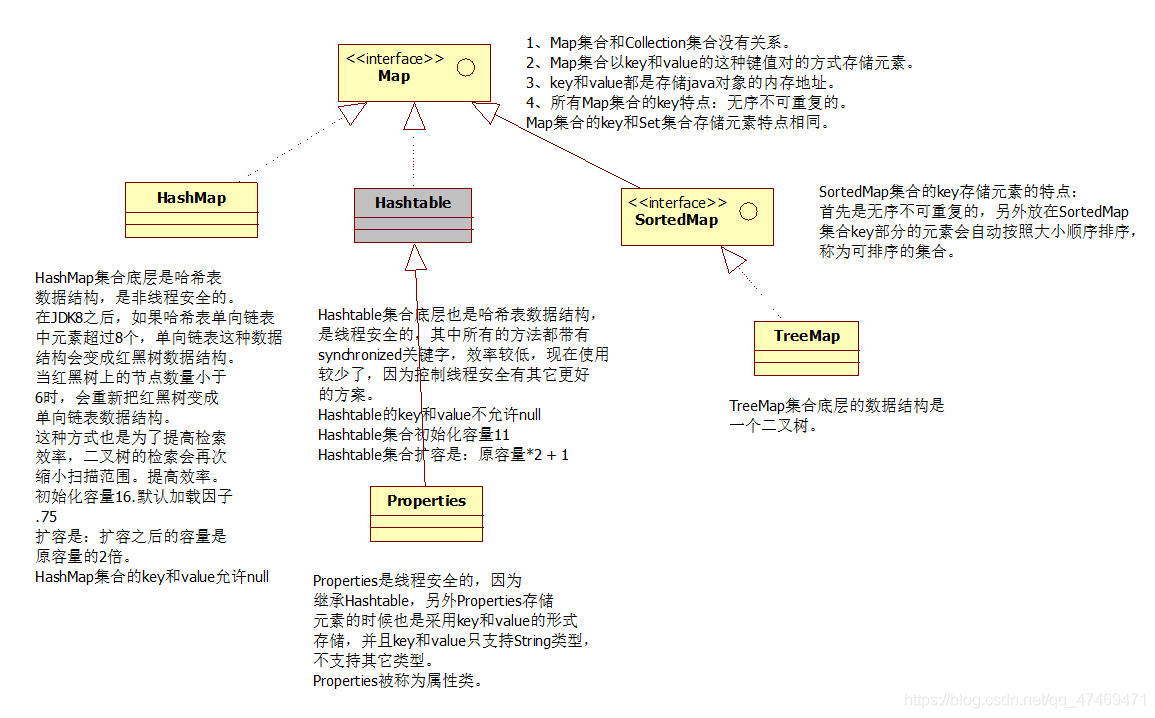
十四、Map
1)Map和Collection没有继承关系
2)Mpa集合Key和Value的方式存储数据:键值对
key和value都是引用数据类型
key和value存储的是对象的内存地址
key起主导地位,value是key的一个附属品
一、map常用方法
V put (K key, V value) 向集合添加键值对
void clear() 清空集合
boolean containsKey(Objec key) 判断集合中是否包含某个key
boolean containsValue(Object value) 判断集合中是否包含某个value
V get(Object key) 通过key获取value
boolean isEmpty() 判断集合是否为空
Set<k> keySet() 获取集合所有的key
V remove(Object key) 通过key删除键值对
int size() 键值对的个数
Collection <v> values() 获取所有的value,返回一个Collection集合
Set<Map, Entry<K,V>> entrySet() 将map集合转换为set集合
会将key和value使用=链接起来保存到set集合里面,里面的元素类型是
Map.Entry<K,V>
注意:上面的单词里面存在contains都是调用equals来进行比对的.
key重复的时候value会覆盖
Map<Integer, String> map1 = new TreeMap<>();
map1.put(1,"恐怖如斯");//添加键值对
map1.put(2,"张某");
System.out.println(map1.get(1));//输出key对应的value
System.out.println(map1.size());//获取键值对的数量
System.out.println(map1.containsKey(1));
二、map集合的遍历
2.1第一种方式,获取所有的key,通过遍历key获取value
Map<Integer, String> map1 = new TreeMap<>();
map1.put(1,"恐怖如斯");//添加键值对
map1.put(2,"张某");
Set<Integer> s = map1.keySet();
//也可以使用迭代器
for (Object o : s){
System.out.println(o + " = " + map1.get(o));
}
// 1 = 恐怖如斯
// 2 = 张某
2.2 第二种方式Set<Map, Entry<K,V>> entrySet()
Map<Integer, String> map1 = new TreeMap<>();
map1.put(1,"恐怖如斯");//添加键值对
map1.put(2,"张某");
Set<Map.Entry<Integer, String>> s = map1.entrySet();
Iterator iterator = s.iterator();
while (iterator.hasNext()){
Map.Entry<Integer, String> node = (Map.Entry<Integer, String>) iterator.next();
Integer key = node.getKey();
String value = node.getValue();
System.out.println(key+"--"+value);
}
//效率比较高,获取node的key和value的数据都是直接从node对象中获取.
// 适合大量数据
for (Map.Entry<Integer, String> o : s){
System.out.println(o.getKey() + "=" + o.getValue());
}
//1=恐怖如斯
//2=张某
将map集合转换为set集合
会将key和value使用=链接起来保存到set集合里面,里面的元素类型是
Map.Entry<K,V>
十五、HashMap集合
1)hashmap集合底层是哈希表/散列表的数据结构
2)哈希表是一个怎样的数据结构
是数组和单向链表的结合体
数组:在查询方面的效率高,随增删的效率低
单向链表:在随机增删方面的效率高,查询效率低
哈希表将两种数据结构融合在一起,充分发挥她们各自的优点
3)HashMap集合底层的源代码
public class HashMap{
// HashMap底层实际上就是一个数组。(一维数组)
Node<K, V>[]table;
//静态内部类: HashMpa.Node
static class Node<k,v>{
final int hash;
//哈希值是方法执行的结果,可以通过哈希算法转化为数组下标
final k key;
V value
Node<K,V> nect; // 指向下一个节点
}
}
4)HashMap集合的默认初始化容量是16,默认加载因子是0.75
默认加载因子意思是当HashMap集合底层容量达到75%时,数组开始扩容.
HashMap集合的初始化容量必须是2的倍数,也是官方推荐的,这是为了达到散列均匀,为了提高HashMap集合的存取效率,所必须的.
一、重写HashCode注意事项
问题一:
不重写 hashCode继承的父类的HashCode()返回的是的地址,
**重写 ** hashcode返回的是结果算法转换过后的对应的数据的下标.
问题二:
向map集合中存,取数据的时候,都是先调用key的hashcode方法,然后再调用equals方法!
equals方法有可能调用,也有可能不调用
//举例
put(k,v)举例,什么时候equals方法不会调用?
k.hashCode()方法返回哈希值,哈希值结果哈希算法转换为数组下标,
数组下标如果是null,equals不需要执行.
//简单来说意思就是:当数据添加到哈希表里面的时候会通过调用hashcode方法得到哈希值通过哈希算法得到数组的下标,如果自定义的类重写了hashcode方法后创建的对象添加到集合里面的时候自动调用hashcode方法返回的哈希值是一样的,以至于经过哈希算法得到的数组下标也是一样的,如果下标的位置的单项链表为空将不需要调用equals方法直接往里面添加数据,如果对应下标的结点存在就调用equals方法进行比较判断是否重复.
注意:如果一个类的equals方法重写了,那么hashCode()方法一定要重写
equals方法返回true,hashcode方法返回的必须一样,equals方法返回true表示两个对象相同,在同一个单向链表上面比较。那么对于同一个单向链表上的节点来说,他们的哈希值一定是相同的.
问题三:
在实际的使用中直接使用idea生产hashcode和equals方法即可,
在使用alt + inster方法来生成的时候需要注意,如果需要判断当名字相同就表示相同那么就勾选上名字,年龄就不要勾选.
五、
二、hashmap集合的key部分允许为空吗?
允许
Map map = new HashMap();
map.put(null, null);//hashmap允许集合key为null
System.out.println(map.size());
map.put(null,1);
System.out.println(map.get(null)); //也可以通过null将value的值提取出来.
但是由于的hashmap的key部分的数据无法重复,所以key为null可以存在但是只能够存在一个,不然就会被替换.
三、hashmap和hashtable的区别
区别一:
hashtable的key和value都不可以为null,但是hashmap的都可以为null
区别二:
hashtable线程安全,现在使用较少因为控制线程安全有更加好的方案.
十六、properties
掌握属性类对象的相关方法即可,
properties是一个map集合,继承hashtable,properties的key和value都是String类型
properties被称为属性类对象.
需要学习的方法
Obkect setProperty(String key, String value)
// 调用Hashtable的方法的put 存数据
String getProperty(String key)
// 根据key获取value 取数据
Properties p1 = new Properties();
p1.setProperty("url","jack");
p1.setProperty("http","123");
System.out.println(p1.getProperty("url")); // jack
System.out.println(p1.getProperty("http")); // 123
十七、TreeSet与TreeMap
1.TreeSet底层实际上是TreeMap
2.TreeMap底层是二叉树结构
3.放入TreeSet的元素就是放入TreeMap元素的key部分
4.TreeSet集合中的元素无序不可重复,但是可以按照元素的大小自动排序
称为可排序集合
TreeSet<String> s = new TreeSet<>();
s.add("bcc");
s.add("add");
s.add("caa");
for (String ss : s){
System.out.println(ss);
}
// add
// bcc
// caa
按照字典顺序自动排序
4.对于自定义类型来说,自定义类型无法排序
因为没有指定person之间的比较规则,会出现异常
java.lang.ClassCastException:javase.person cannot be cast to java.lang.Comparable 需要继承接口
public class one {
public static void main(String[] args) {
TreeSet<person> s = new TreeSet<>();
person p1 = new person(20);
person p2 = new person(30);
person p3 = new person(40);
person p4 = new person(50);
for (person pp : s){
System.out.println(pp);
}
}
}
class person{
private int i;
public person(int i) {
this.i = i;
}
@Override
public String toString() {
return "person{" +
"i=" + i +
'}';
}
}
十八、自定义类实现Comparable接口,排序
放在TreeSet集合中的元素需要实现java.lang.Comparable接口
并且实现Comparable方法, equals可以不写
CompareTo方法非常重要,
返回0, 表示相同
返回 > 0 ,会继续在左指树上面找
返回 < 0, 会继续在右指树上面找
public class one {
public static void main(String[] args) {
TreeSet<cus> arr = new TreeSet<>();
arr.add(new cus(12));
arr.add(new cus(32));
arr.add(new cus(122));
arr.add( new cus(62));
arr.add(new cus(92));
for (cus cc:arr){
System.out.println(cc.age);
}
}
}
// 放在TreeSet集合中的元素需要实现java.lang.Comparable接口
// 并且实现Comparable方法, equals可以不写
class cus implements Comparable<cus>{
int age;
public cus(int age) {
this.age = age;
}
public cus() {
}
//在这个方法里面写比较的逻辑
// 比较规则由程序员来规定
@Override
public int compareTo(cus o) {
return this.age - o.age; // 反过来写就表示降序
}
}
当有一个需求,要求年龄相同的时候比较名字
名字String类型,可以直接调用String类里面重写的Compareto方法
class cus implements Comparable<cus>{
int age;
String name;
public cus(int age, String name) {
this.age = age;
this.name = name;
}
public cus() {
}
//在这个方法里面写比较的逻辑
// 比较规则由程序员来规定
@Override
public int compareTo(cus o) {
if (o.age == this.age){
//年龄相同比较名字
// 名字String类型,可以直接调用String类里面重写的Compareto方法
return this.name.compareTo(o.name);
}else {
return this.age - o.age;
}
}
@Override
public String toString() {
return "cus{" +
"age=" + age +
", name='" + name + '\'' +
'}';
}
}
十九、实现比较器Comparator进行排序
比较器实现Comparatro接口(Comparable是java.lang包下,Comparatro是java.util包下的)
以类的形式实现比较器
public class one {
public static void main(String[] args) {
TreeSet<cat> ar = new TreeSet<>(new bipowder());
ar.add(new cat(23));
ar.add(new cat(63));
ar.add(new cat(223));
ar.add(new cat(2));
for (cat c: ar){
System.out.println(c);
}
}
}
// 普通类
class cat{
int age;
public cat(int age) {
this.age = age;
}
public cat() {
}
@Override
public String toString() {
return "cat{" +
"age=" + age +
'}';
}
}
//写比较器的类
class bipowder implements Comparator<cat>{
@Override
public int compare(cat o1, cat o2) {
return o1.age - o2.age;
}
}
以匿名内部类的方式实现比较器
直接new接口
public class one {
public static void main(String[] args) {
TreeSet<cat> ar = new TreeSet<>(new Comparator<cat>(){
@Override
public int compare(cat o1, cat o2) {
return o1.age - o2.age;
}
});
ar.add(new cat(23));
ar.add(new cat(63));
ar.add(new cat(223));
ar.add(new cat(2));
for (cat c: ar){
System.out.println(c);
}
}
}
class cat{
int age;
public cat(int age) {
this.age = age;
}
public cat() {
}
@Override
public String toString() {
return "cat{" +
"age=" + age +
'}';
}
}
二十、对于TreeSet的最终结论
1.放到TrssSet或者TrssMap集合的key部分的元素需要做到排序,包括两种方式
1) 放在集合中的元素实现java.lang.Comparable
- 在构造TrssSet或者TrssMap集合的时候给他传一个比较器对象
2.Comparable与Comparator(比较器)该如何选择
当比较不会发生改变的时候,或者说当比较规则只有一个的时候,建议Comparable接口
如果比较规则有多个,并且需要多个比较规则之间切换,建议使用Comparator接口,Comparator接口符合OCP原则.
二十一、Collections工具类
工具集合类方便集合的操作
// Arraylist不是线程安全的
List<String> list = new ArrayList();
//1. 变成线程安全的
Collections.synchronizedList(list);
//2.排序
list.add("b");
list.add("a");
Collections.sort(list);
for (String s : list){
System.out.println(s);
}
// 注意:对于自定义的类,如果要进行排序需要实现Comparable接口
// 排序的对象规定只能够是List集合,如果是Set集合可以使用List集合的
// 构造方法将其转换为List集合
//也可以写成
//Collections.sort(list集合, 比较器对象);
二十二、集合的选用
不同的数据结构在某些方面发挥的效果不一样:
ArrayList: 检索效率较高,增删效率较低。
LinkedList:增删效率较高,检索效率较低。
Vector:线程安全的.速度慢
TreeSet:可对字符串进行排序
lass cat{
int age;
public cat(int age) {
this.age = age;
}
public cat() {
}
@Override
public String toString() {
return "cat{" +
"age=" + age +
'}';
}
}
二十、对于TreeSet的最终结论
1.放到TrssSet或者TrssMap集合的key部分的元素需要做到排序,包括两种方式
1) 放在集合中的元素实现java.lang.Comparable
- 在构造TrssSet或者TrssMap集合的时候给他传一个比较器对象
2.Comparable与Comparator(比较器)该如何选择
当比较不会发生改变的时候,或者说当比较规则只有一个的时候,建议Comparable接口
如果比较规则有多个,并且需要多个比较规则之间切换,建议使用Comparator接口,Comparator接口符合OCP原则.
二十一、Collections工具类
工具集合类方便集合的操作
// Arraylist不是线程安全的
List<String> list = new ArrayList();
//1. 变成线程安全的
Collections.synchronizedList(list);
//2.排序
list.add("b");
list.add("a");
Collections.sort(list);
for (String s : list){
System.out.println(s);
}
// 注意:对于自定义的类,如果要进行排序需要实现Comparable接口
// 排序的对象规定只能够是List集合,如果是Set集合可以使用List集合的
// 构造方法将其转换为List集合
//也可以写成
//Collections.sort(list集合, 比较器对象);
二十二、集合的选用
不同的数据结构在某些方面发挥的效果不一样:
ArrayList: 检索效率较高,增删效率较低。
LinkedList:增删效率较高,检索效率较低。
Vector:线程安全的.速度慢
TreeSet:可对字符串进行排序