Mybatis-puls 多表联查使用
问题引出 :一个朋友提出的问题 .
多表联查使用 mp+stream 是否合适? 自从我学了Mybatis plus以来加上看了一些大佬的项目,很多都是直接使用mp+stream流实现多表联查的功能,不过基本上都是二到三张表。我自己也是觉得这种方式的效率比较高,但是这样我就因为一个功能查询多次数据库。究竟是遵从规范好(使用associate),还是这种方式呢。
结论: 各有优缺点根据场景和业务去选择,需要考虑查询数据量,索引 ,手写sql 笛卡尔积 和多表联查时候索引失效的情况,根据具体问题和情况尝试后选择更合适的查询方式 .
chat gpt 样式答案
多表联查使用mp+stream 是否合适? 自从我学了Mybatis plus以来加上看了一些大佬的项目,很多都是直接使用mp+stream流实现多表联查的功能,不过基本上都是二到三张表。我自己也是觉得这种方式的效率比较高,但是这样我就因为一个功能查询多次数据库。究竟是遵从规范好(使用associate),还是这种方式呢。 分析这句话,从不同的角度来讲一下优缺点,使用场景和一些我没有考虑到的地方,并给我一个示例
使用到的题词技巧,直接询问,并指出回复方向性,并且由于ai 回复指定回复方向后会忽略一些没注意到的地方,所以使用需要给个提示防止限定范围回复.
使用 MyBatis Plus(简称 MP)结合 Stream 流进行多表联查是一种常见的方式,可以有效地简化代码,并提高查询的性能和效率。这种方式在处理二到三张表的联查时特别适用。
下面是对使用 MP + Stream 进行多表联查的优缺点、适用场景以及一些需要考虑的方面的分析:
优点:
- 简化代码:使用 MP 提供的 API 可以更简洁地编写多表联查的查询语句,避免手动编写复杂的 SQL 语句。
- 提高性能:Stream 流可以对结果集进行并行处理,充分利用多核处理能力,提高查询效率。
- 可读性强:使用 Stream 流的链式操作可以使查询语句更加清晰、易读,方便理解和维护。
缺点:
- 额外的数据库查询:由于使用了 Stream 流,可能需要进行多次数据库查询,这会增加数据库的访问次数和网络开销。
- 内存消耗:在进行多表联查时,如果查询结果集很大,可能会占用较多的内存。
适用场景:
- 二到三张表的联查:MP + Stream 适用于涉及二到三张表的联查,可以很好地处理表之间的关联关系。
- 数据量较小:如果查询结果集较大,可能会占用较多内存,因此在处理数据量较大的情况下,需要注意内存消耗。
示例代码: 假设有两个实体类
User和Order,它们之间存在关联关系,一个用户可以有多个订单。我们可以使用 MP + Stream 进行联查,查询出所有用户的订单信息:select * from x in(sele)
select x from t left u join where t
javaCopy code List<User> userList = userMapper.selectList(null); List<Order> orderList = userList.stream() .flatMap(user -> orderMapper.selectList(new QueryWrapper<Order>().eq("user_id", user.getId())).stream()) .collect(Collectors.toList());在上述示例中,首先使用 MP 的
selectList方法查询所有用户信息,然后通过 Stream 的flatMap操作在每个用户上执行订单查询,并使用collect方法将结果收集为列表。需要注意的是,在实际应用中,根据具体的业务需求和数据量大小,您可以权衡使用 MP + Stream 进行多表联查的优缺点,并选择最合适的方法。
那以 mp + Stream 方式实现多表查询的话大概多大数据量会对服务器内存性能造成影响,需要精确一下数据量的条数
使用 MP + Stream 方式进行多表查询时,对服务器内存性能的影响取决于多个因素,包括数据量、查询的复杂性、内存管理等。无法给出一个具体的数据量界限来确定对服务器内存性能的影响,因为这取决于具体的场景和服务器配置。
但是可以提供一些一般性的指导原则:
- 小规模数据:对于小规模数据,即数据量相对较小的情况,通常对服务器内存性能的影响较小。在 MP + Stream 方式下,处理几万条数据不会对服务器的内存性能产生显著影响。
- 中等规模数据:中等规模数据可能包含几万到几百万的记录。在使用 MP + Stream 进行多表查询时,如果结果集的数据量较大,可能会占用较多的内存。这可能导致服务器的内存压力增加,从而影响性能。在这种情况下,需要考虑分批加载数据或使用分页查询等策略,以减少内存占用。
- 大规模数据:对于大规模数据,包含数百万到数十亿条记录。在这种情况下,使用 MP + Stream 方式进行多表查询可能会对服务器的内存性能产生显著影响。大规模数据集可能无法完全加载到内存中,因此需要采取适当的优化措施,如分布式处理、分片查询等。
需要根据具体的数据量、服务器硬件配置、查询复杂性和业务需求来评估对服务器内存性能的影响。建议进行性能测试和优化,以确定服务器在给定的数据量下的内存性能,并根据需要采取相应的措施来提高性能和可扩展性。
mp + Stream 方式实现多表联查有那些限制
使用 MP + Stream 方式进行多表联查可能会有以下限制:
- 数据量限制:当涉及大规模数据集时,将整个结果集加载到内存中可能会导致内存溢出。这可能需要采取分页查询或分批加载数据的策略来处理大量数据。
- 复杂性限制:MP + Stream 适用于相对简单的联查场景,涉及二到三张表的联查较为常见。当涉及更复杂的联查场景,特别是涉及多张表或嵌套子查询时,使用 MP + Stream 可能变得复杂或不太适用。
- 性能限制:尽管 MP + Stream 可以提高查询性能,但它并不适用于所有情况。在某些情况下,使用传统的关联查询或者其他优化手段可能更加高效。性能取决于多个因素,包括数据库索引、查询语句的复杂性、数据量等。
- 数据一致性限制:在使用 MP + Stream 进行多表联查时,可能存在数据一致性的问题。如果查询的数据需要保持一致性,特别是在并发环境下,需要额外的措施来确保数据一致性,如加锁或使用事务。
- 版本限制:MP + Stream 方式可能需要特定的版本支持,具体取决于使用的 MyBatis Plus 和相关依赖库的版本。确保使用兼容的版本以获得最佳的功能和性能。
需要根据具体的业务需求和查询场景评估使用 MP + Stream 方式的适用性和限制。在设计和实施查询逻辑时,可以考虑其他的查询优化技巧和数据库特性,以达到更好的性能和可维护性。
多给几个不同角度的示例来体现 mp + Stream
以下是几个示例,展示了使用 MP + Stream 方式实现多表联查的不同角度:
- 一对多关联查询: 假设有两个实体表,User 和 Order,一个用户可以有多个订单。使用 MP + Stream 方式可以通过以下代码实现一对多关联查询:
javaCopy code// 查询所有用户及其订单列表 List<User> userList = userMapper.selectList(null); userList.stream().forEach(user -> { List<Order> orders = orderMapper.selectList(new QueryWrapper<Order>().eq("user_id", user.getId())); user.setOrders(orders); });
- 多对多关联查询: 假设有三个实体表,Student、Course 和 StudentCourse,一个学生可以选择多门课程,使用 MP + Stream 方式可以通过以下代码实现多对多关联查询:
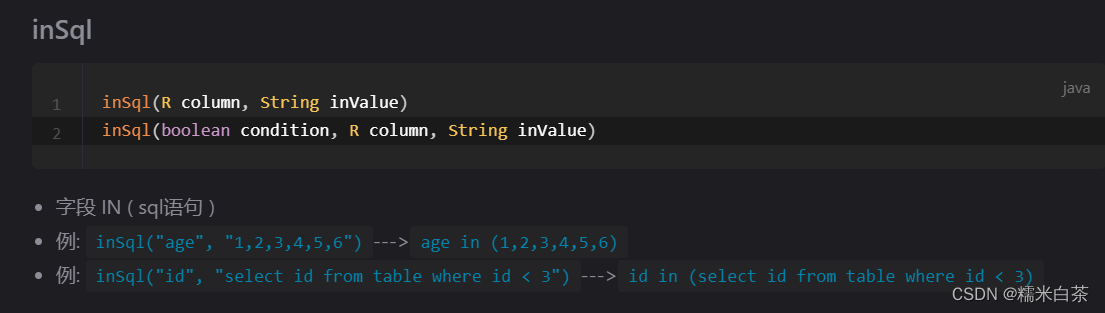
javaCopy code// 查询所有学生及其选修的课程列表 List<Student> studentList = studentMapper.selectList(null); studentList.stream().forEach(student -> { List<Course> courses = courseMapper.selectList(new QueryWrapper<Course>() .inSql("id", "SELECT course_id FROM student_course WHERE student_id = " + student.getId())); student.setCourses(courses); });
- 嵌套子查询: 假设有两个实体表,Department 和 Employee,一个部门有多个员工。使用 MP + Stream 方式可以通过以下代码实现嵌套子查询:
javaCopy code// 查询所有部门及其员工列表 List<Department> departmentList = departmentMapper.selectList(null); departmentList.stream().forEach(department -> { List<Employee> employees = employeeMapper.selectList(new QueryWrapper<Employee>() .eq("department_id", department.getId())); department.setEmployees(employees); });这些示例展示了使用 MP + Stream 方式实现不同类型的多表联查。可以根据具体的业务场景和数据模型,灵活运用 MP + Stream 方式来实现高效的多表查询。
总体考虑,数据量大小,服务器性能,实际用户数量下两种查询对比,高并发情况下数据一致性保证,实现难度,表的数量,在标准用户数量数据量下测试更加具有效果,数据sql 优化的一种题解,可以同时写两种逻辑,根据数据量判断和并发数量具体判断,需要有足够经验和时间去尝试,对于数据一致性不高数据查询起来优势明显,比如热榜之类的.
一次简单的测试
ok gpt 给的答案很明显,但是我觉得有问题但那时说不出来问题在哪,但是简单测试之后实际查询效果在千为数量级的查询中发现实际效果慢了八倍.当时不知道如何才算是 mp 查询多表,直到离职交接工作最后一天,问了老大一个问题,关于数据量影响性能,他问了我个问题 你觉的 mysql 是什么?
什么是 MySQL ?
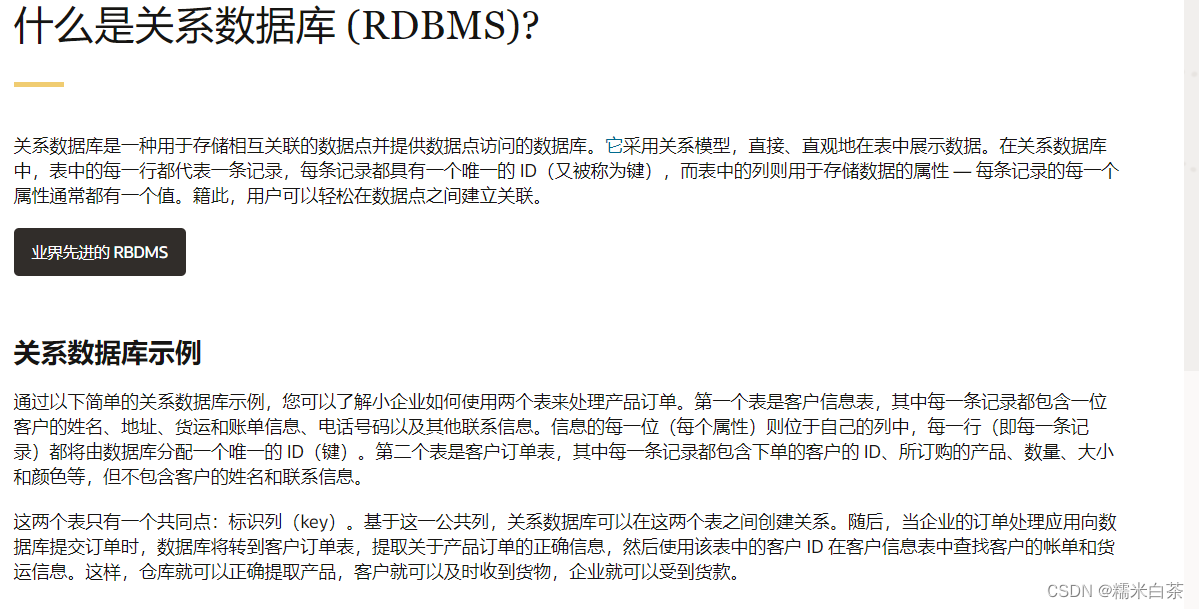
什么是关系数据库 ?
随便一搜有了很多答案,但是大家都太官方了,输入固定输出,底层符合计算机体系结构,都是程序嘛.
不过是编译语言不一样,执行业务不一样,不同的程序各司其职,数据库不过是操纵硬盘的程序罢了,SQL 语言那,类比于接口固定参数,不同的语句是不同的接口,可变部分是传入参数,接口组合实现功能,有专门的公司对这个程序更新,而大多数程序员只要使用各种各样的数据库实现操作计算机底层硬件写入想要的数据就可以了.
所以说,好多问题都可以理解了,为什么在循环中写程序那么慢,因为相当于每一次都得建立链接啊,每一次传输都得占用一个共同的资源,还有慢 sql, SQL优化,数据库引擎 , 索引, 好多东西都突然能理解了. 没有绝对完美的系统 , 好的厨师能用同样的食材做出更好吃的饭 . 如果想更好的使用数据库 , 肯定需要对它足够了解 .
而 mp 查询多表其实就是考虑到程序的性能数据量 ,可扩展性,等因素做出的一个尝试 .先上示例
mp 多表查询
分为两种情况
- 一条 SQL 一次查询
- 多条 SQL 查询多次
一条 sql 的
Page<Post> listFavourPostByPage(IPage<Post> page, @Param(Constants.WRAPPER) Wrapper<Post> queryWrapper,
long favourUserId);
<select id="listFavourPostByPage"
resultType="com.yupi.springbootinit.model.entity.Post">
select p.*
from post p
join (select postId from post_favour where userId = #{favourUserId}) pf
on p.id = pf.postId ${ew.customSqlSegment}
</select>
两种方式,第一种方式是在条件构造器中加入一个查询列的 语句作为一个 in 操作的原始数据来源
第二种方式通过 传入一个条件构造器, 两张表连表查询的结果集按照传入的条件构造器做筛选 .
以上两种本质上都是一种 mp 实现多表的方式 , 讲求 一次查询,一次结果集返回 .
多条 SQL 查询多次
/**
* 分页获取题目提交列表(除了管理员外,普通用户只能看到非答案、提交代码等公开信息)
*
* @param questionSubmitQueryRequest
* @param request
*/
@PostMapping("/list/page")
public BaseResponse<Page<QuestionSubmitVO>> listFavourQuestionSubmitByPage(@RequestBody QuestionSubmitQueryRequest questionSubmitQueryRequest,
HttpServletRequest request) {
if (questionSubmitQueryRequest == null) {
throw new BusinessException(ErrorCode.PARAMS_ERROR);
}
long current = questionSubmitQueryRequest.getCurrent();
long size = questionSubmitQueryRequest.getPageSize();
// 限制爬虫
ThrowUtils.throwIf(size > 20, ErrorCode.PARAMS_ERROR);
Page<QuestionSubmit> questionSubmitPage = questionSubmitService.page(new Page<>(current, size),
questionSubmitService.getQueryWrapper(questionSubmitQueryRequest));
User loginUser = userService.getLoginUser(request);
return ResultUtils.success(questionSubmitService.getQuestionSubmitVOPage(questionSubmitPage, loginUser));
}
@Override
public QuestionSubmitVO getQuestionSubmitVO(QuestionSubmit questionSubmit, User loginUser) {
QuestionSubmitVO questionSubmitVO = QuestionSubmitVO.objToVo(questionSubmit);
if (!questionSubmit.getUserId().equals(loginUser.getId()) && !userService.isAdmin(loginUser)) {
questionSubmitVO.setCode(null);
}
return questionSubmitVO;
}
@Override
public Page<QuestionSubmitVO> getQuestionSubmitVOPage(Page<QuestionSubmit> questionSubmitPage, User loginUser) {
List<QuestionSubmit> questionSubmitList = questionSubmitPage.getRecords();
Page<QuestionSubmitVO> questionSubmitVOPage =
new Page<>(questionSubmitPage.getCurrent(), questionSubmitPage.getSize(), questionSubmitPage.getTotal());
if (CollectionUtils.isEmpty(questionSubmitList)) {
return questionSubmitVOPage;
}
HashSet<Long> questionSubmitIds = new HashSet<>();
HashSet<Long> userIds = new HashSet<>();
questionSubmitList.forEach(res -> {
questionSubmitIds.add(res.getQuestionId());
userIds.add(res.getUserId());
});
Map<Long, List<Question>> questionListMap = questionService.listByIds(questionSubmitIds)
.stream()
.collect(Collectors.groupingBy(Question::getId));
Map<Long, List<User>> userListMap = userService.listByIds(userIds).stream()
.collect(Collectors.groupingBy(User::getId));
List<QuestionSubmitVO> questionSubmitVOList = questionSubmitList.stream()
.map(questionSubmit -> {
QuestionSubmitVO questionSubmitVO = getQuestionSubmitVO(questionSubmit, loginUser);
Long questionId = questionSubmitVO.getQuestionId();
Question question = null;
if (questionListMap.containsKey(questionId)) {
question = questionListMap.get(questionId).get(0);
}
questionSubmitVO.setQuestionVO(QuestionVO.objToVo(question));
Long usersId = questionSubmitVO.getUserId();
User user = null;
if (userListMap.containsKey(usersId)) {
user = userListMap.get(usersId).get(0);
}
questionSubmitVO.setUserVO(userService.getUserVO(user));
return questionSubmitVO;
}).collect(Collectors.toList());
questionSubmitVOPage.setRecords(questionSubmitVOList);
return questionSubmitVOPage;
}
这一长串代码涉及到了三张表内的数据,最后返回到同一个实体用于接口返回数据.
如果要是传统写法,一条 sql 搞定 ,各种嵌套查询就完了,好吧,这种 sql 我光整理逻辑去测试就得一会 .
至此,我所知道的两种 mp 查连表的两种方式已经写完了
考虑使用情况
问题:多表联查写的代码只针对一种场景,且需要在一个库里才好操作,如果a,b两表不同库会麻烦一些(todo去尝试)
产生的问题, 不在同一个库中,不在同一个操作系统(服务器内),不同场景下的反复 写不同的复杂 sql
数据库内部实现: 对于多表查询的具体实现机制,
索引失效情况
数据返回值数量级
总结 : 可能会产生慢 sql 也可能会有 , 对程序的扩展和编码并不友好,不利于程序后期的拆分和扩展,维护起来也偏于苦难 ,有时光看懂一个复杂的 sql 逐层分析可能时间就需要好久 . 数据库多表联查的细节实现可以具体研究 .
多次查询在内存内计算,好处为可以更好的设置索引,确保每次作为链接条件查询的可以多次命中加速单次查询数据的速度,内存中计算关联关系,可以更加理解明白程序间的关联关系,将数据库所在服务器的压力转移到程序所在服务器内存中(压力互换,类似于使用缓存化解数据库压力), 但是这种情况下更适合分布式微服务,更好拆分数据库,程序服务器,方便负载均衡和增强性能 .
复杂 sql 多表联查适合 访问压力不大的单体架构或者说用户量相对固定的场景,服务器压力不大,不需要考虑使用微服务就能撑得住的场景,但是如果不确定未来以那种形式存在,最方便的就是单次查询服务器内部确定关联关系,无非就是后期讲单次调用换成远程调用.扩展性无敌,但是要实际考虑数据量,费用等多种因素之后才能确定到底具体哪种好,没有绝对正确的方案 .
下一步 :
了解数据库在多表联查时候执行过程
整理索引失效的情况,实际数据实际案例测试
整理数据库运行的机制
测试性能差距
进一布掌握数据高级知识,和 Mybatis 和 Mybatis 框架