文章目录
前言
你好,我是无名小歌。
今天给大家分享一个分布式存储系统ceph。
简介(理论篇)
什么是ceph?
Ceph在一个统一的系统中独特地提供对象、块和文件存储。Ceph 高度可靠、易于管理且免费。Ceph 的强大功能可以改变您公司的 IT 基础架构和管理大量数据的能力。Ceph 提供了非凡的可扩展性——数以千计的客户端访问 PB 到 EB 的数据。ceph存储集群相互通信以动态复制和重新分配数据。
为什么使用ceph?
目前众多云厂商都在使用ceph,应用广泛。如:华为、阿里、腾讯等等。目前火热的云技术openstack、kubernetes都支持后端整合ceph,从而提高数据的可用性、扩展性、容错等能力。
一个 Ceph 存储集群至少需要一个 Ceph Monitor(监视器)、Ceph Manager(管理) 和 Ceph OSD(对象存储守护进程)。
Monitors
Ceph Monitor ( ceph-mon) 维护集群状态的映射,包括监视器映射、管理器映射、OSD 映射、MDS 映射和 CRUSH 映射。这些映射是 Ceph 守护进程相互协调所需的关键集群状态。监视器还负责管理守护进程和客户端之间的身份验证。冗余和高可用性通常需要至少三个监视器。
Managers
Ceph Manager守护进程 ( ceph-mgr) 负责跟踪运行时指标和 Ceph 集群的当前状态,包括存储利用率、当前性能指标和系统负载。高可用性通常需要至少两个管理器。
Ceph OSD
一个Ceph OSD(ceph-osd)存储数据、处理数据复制、恢复、重新平衡,并通过检查其他 Ceph OSD 守护进程的心跳来向 Ceph 监视器和管理器提供一些监视信息。冗余和高可用性通常需要至少三个 Ceph OSD。
MDS
Ceph 元数据服务器(MDS ceph-mds) 代表Ceph 文件系统存储元数据(即 Ceph 块设备和 Ceph 对象存储不使用 MDS)。Ceph 元数据服务器允许 POSIX 文件系统用户执行基本命令(如 ls、find等),而不会给 Ceph 存储集群带来巨大负担。

Ceph 将数据作为对象存储在逻辑存储池中。使用 CRUSH算法,Ceph 计算出哪个归置组应该包含该对象,并进一步计算出哪个 Ceph OSD Daemon 应该存储该归置组。CRUSH 算法使 Ceph 存储集群能够动态扩展、重新平衡和恢复。
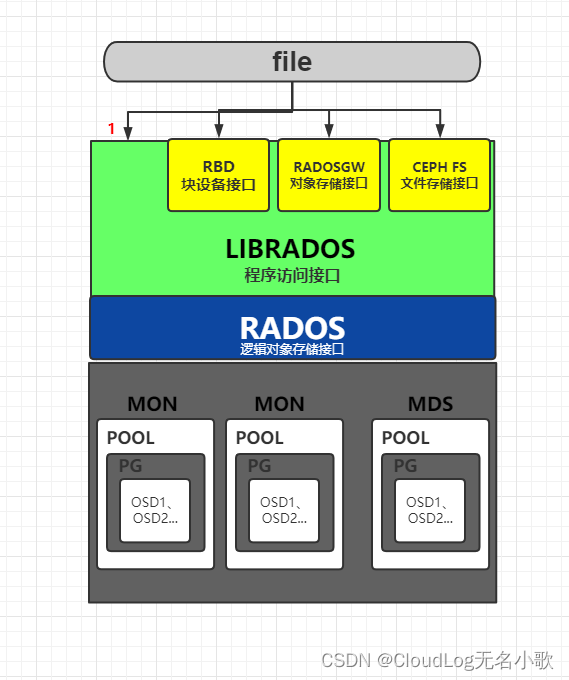
逻辑结构
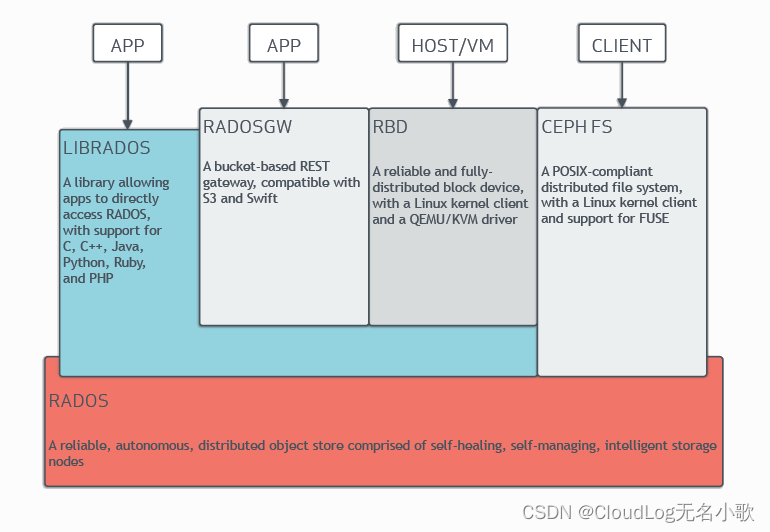
LIBRADOS: 一个允许应用程序直接访问 RADO 的库,支持 C、C++、Java、Python、Ruby 和 PHP
RADOSGW: 基于存储桶的 REST网关,兼容s3和Swift
RBD: 一个负责任的,完全-分布式块设备,使用Linux内核cliont和QEMU/KVM驱动程序
CEPHFS: 符合POSIX标准的分发文件系统,具有Linux内核客户端和对FUSE的支持
RADOS: 由自我修复、自我管理、智能存储节点组成的可靠、自主、分布式对象存储
数据存储原理
Ceph 存储集群从Ceph 客户端接收数据——无论是通过Ceph 块设备、Ceph 对象存储、 Ceph 文件系统还是您使用创建的自定义实现 librados——都存储为 RADOS 对象。每个对象都存储在一个 对象存储设备上。Ceph OSD 守护进程处理存储驱动器上的读、写和复制操作。对于较旧的 Filestore 后端,每个 RADOS 对象都作为单独的文件存储在传统文件系统(通常是 XFS)上。使用新的默认 BlueStore 后端,对象以类似数据库的整体方式存储。
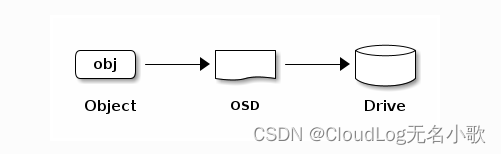
Ceph OSD 守护进程将数据作为对象存储在平面命名空间中(例如,没有目录层次结构)。对象具有标识符、二进制数据和由一组名称/值对组成的元数据。语义完全取决于Ceph 客户端。例如,CephFS 使用元数据来存储文件属性,例如文件所有者、创建日期、最后修改日期等。
ceph客户端: 可以访问 Ceph 存储集群的 Ceph 组件的集合。其中包括 Ceph 对象网关、Ceph 块设备、Ceph 文件系统及其相应的库、内核模块和 FUSE。

对象 ID 在整个集群中是唯一的,而不仅仅是本地文件系统。
三大存储
RADOSGW(对象网关)
Ceph 对象网关是一个构建在librados之上的对象存储接口,Ceph 对象存储支持两个接口:
- 兼容 S3 :通过与 Amazon S3 RESTful API 的大部分子集兼容的接口提供对象存储功能。
- 兼容 Swift:提供对象存储功能,其接口与 OpenStack Swift API 的大部分子集兼容。
Ceph 对象存储使用 Ceph 对象网关守护进程 ( radosgw),它是用于与 Ceph 存储集群交互的 HTTP 服务器。由于它提供了与 OpenStack Swift 和 Amazon S3 兼容的接口,因此 Ceph 对象网关有自己的用户管理。
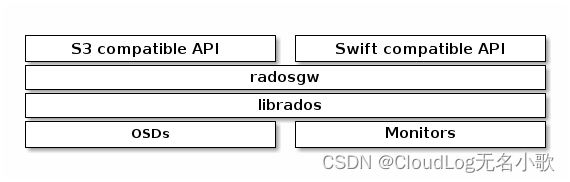
Ceph 对象存储不使用Ceph 元数据服务器。
BRD(块存储)
块是字节序列(通常为 512)。基于块的存储接口是在 HDD、SSD、CD、软盘甚至磁带等介质上存储数据的成熟且常见的方式。
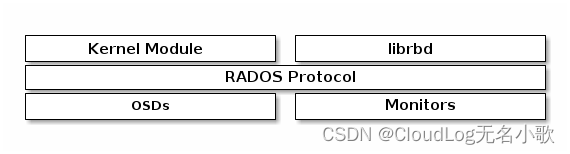
Ceph 块设备是精简配置的、可调整大小的,并将数据分条存储在多个 OSD 上。Ceph 块设备利用 RADOS功能,包括快照、复制和强一致性。Ceph 块存储客户端通过内核模块或librbd库与 Ceph 集群通信。
CEPHFS(文件存储)
Ceph 文件系统或CephFS是一个符合 POSIX 的文件系统,构建在 Ceph 的分布式对象存储RADOS之上。
文件元数据与文件数据存储在单独的 RADOS 池中,并通过可调整大小的元数据服务器集群或MDS提供服务,该集群可以扩展以支持更高吞吐量的元数据工作负载。文件系统的客户端可以直接访问 RADOS 以读取和写入文件数据块。
对数据的访问是通过 MDS 集群来协调的,MDS 集群作为由客户端和 MDS 共同维护的分布式元数据缓存状态的权限。元数据的突变由每个 MDS 聚合成一系列有效的写入 RADOS 上的日志;MDS 没有在本地存储元数据状态。该模型允许在 POSIX 文件系统的上下文中客户端之间进行一致和快速的协作。
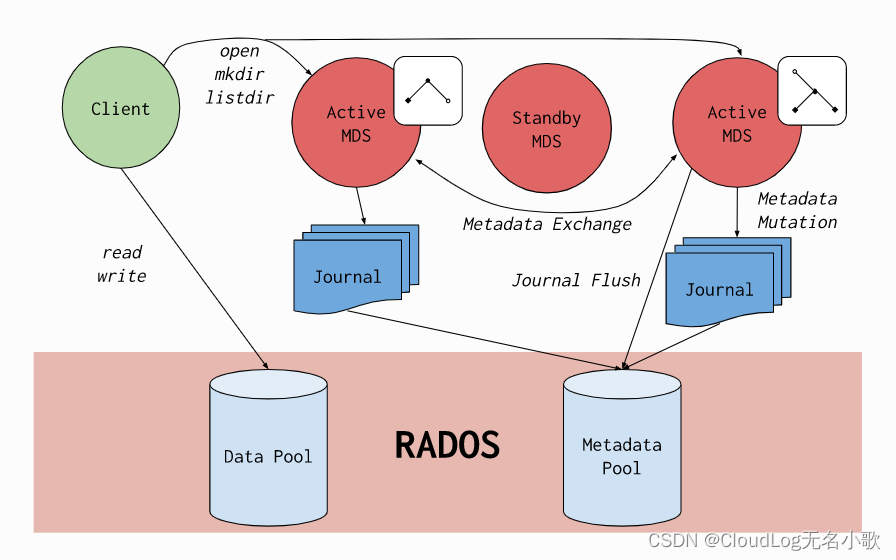
所有组件结合起来
在这之前还需要明白两个概率:POOLS、PG
POOL、PG简介
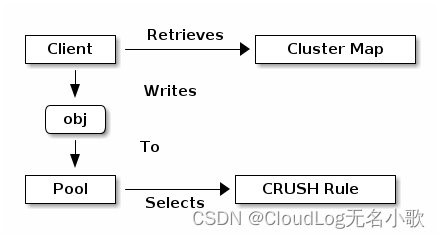
1、POOLS: 存储池,它们是用于存储对象的逻辑分区。
Ceph 客户端从 Ceph 监视器检索集群映射,并将对象写入池中。池size或副本的数量、CRUSH 规则和归置组的数量决定了 Ceph 将如何放置数据。
池至少设置以下参数:
-
对象的所有权/访问权
-
归置组的数量
-
要使用的 CRUSH 规则
CRUSH 是一种算法,详情自行百度吧。
2、PG: 每个池都有许多归置组。CRUSH 将 PG 动态映射到 OSD。当 Ceph 客户端存储对象时,CRUSH 会将每个对象映射到一个归置组。
使用集群映射的副本和 CRUSH 算法,客户端可以准确计算在读取或写入特定对象时使用哪个 OSD。
组件结合
这个架构图主要是把散乱的组件和概念结合起来,所有这里就不过多介绍了,相信大家看到这里都能明白。
搭建ceph(操作篇)
个人环境
| 主机名 | IP | 网卡模式 | 内存 | 系统盘 | 数据盘 |
|---|---|---|---|---|---|
| ceph-1 | 192.168.200.43 | NAT | 2G | 100G | 20G |
| ceph-2 | 192.168.200.44 | NAT | 2G | 100G | 20G |
| ceph-3 | 192.168.200.45 | NAT | 2G | 100G | 20G |
| ceph-client | 192.168.200.45 | NAT | 2G | 100G | 20G |
1、基础配置
后面的操作步骤,请注意观察命令是在那台主机上执行的(非常重要)
1、修改主机名称(三节点操作)
[root@localhost ~]# hostnamectl set-hostname ceph-1
[root@ceph-1 ~]# bash
[root@localhost ~]# hostnamectl set-hostname ceph-2
[root@ceph-2 ~]# bash
[root@localhost ~]# hostnamectl set-hostname ceph-3
[root@ceph-3 ~]# bash
[root@localhost ~]# hostnamectl set-hostname ceph-client
[root@ceph-clinet ~]# bash
2、配置hosts文件映射(三节点操作)
$ cat >> /etc/hosts << EOF
192.168.200.43 ceph-1
192.168.200.44 ceph-2
192.168.200.45 ceph-3
192.168.200.46 ceph-client
EOF
3、关闭防火墙(三节点操作)
$ systemctl stop firewalld && systemctl disable firewalld
$ setenforce 0
$ sed -i 's/SELINUX=.*/SELINUX=permissive/g' /etc/selinux/config
4、配置ssh免密登录
使用 ssh-keygen 命令生成公钥、私钥(一直按回车),再使用 ssh-copy-id 命令将公钥copy复制到目标主机,最后使用一个for循环测试是否可免密登录。
[root@ceph-1 ~]# ssh-keygen
[root@ceph-1 ~]# ssh-copy-id ceph-1
[root@ceph-1 ~]# ssh-copy-id ceph-2
[root@ceph-1 ~]# ssh-copy-id ceph-3
[root@ceph-1 ~]# ssh-copy-id ceph-client
[root@ceph-1 ~]# for i in 1 2 3 client; do ssh ceph-$i hostname ; done
ceph-1
ceph-2
ceph-3
ceph-clinet
5、配置yum源(ceph-1节点执行)
$ yum install -y wget
$ mv /etc/yum.repos.d/* /media/ # 所有节点执行
$ wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
$ wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
$ vi /etc/yum.repos.d/ceph.rpeo
[ceph]
[ceph]
name=Ceph packages for
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/$basearch
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://mirrors.aliyun.com/ceph/keys/release.asc
priority=1
# 查看repo包个数,这里包个数为:28,719
$ yum clean all;yum repolist
...
ceph 524/524
ceph-noarch 16/16
ceph-source 30/30
repo id repo name status
base/7/x86_64 CentOS-7 - Base - mirrors.aliyun.com 10,072
ceph/x86_64 Ceph packages for 524
ceph-noarch Ceph noarch packages 16
ceph-source Ceph source packages 0
epel/x86_64 Extra Packages for Enterprise Linux 7 - x86_64 13,753
extras/7/x86_64 CentOS-7 - Extras - mirrors.aliyun.com 512
updates/7/x86_64 CentOS-7 - Updates - mirrors.aliyun.com 3,842
repolist: 28,719
#将ceph-1节点yum,复制到ceph-2、ceph-3、ceph-client节点(需要提前移除默认repo文件)
$ for i in 2 3 client; do scp /etc/yum.repos.d/* ceph-$i:/etc/yum.repos.d/ ;done
6、chrony配置时间同步
- ceph-1节点执行
注意:chronyc sources命令查看时间同步是否成功,左下角 ^* 表示成功, ^? 表示不成功。
这一步很重要确保完成,否则安装ceph集群时会报一些奇奇怪怪的错误。
$ yum install chrony -y
$ sed -i '3,6s/^/#/g' /etc/chrony.conf
$ sed -i '7s/^/server ceph-1 iburst/g' /etc/chrony.conf
$ echo "allow 192.168.200.0/24" >> /etc/chrony.conf
$ echo "local stratum 10" >> /etc/chrony.conf
$ systemctl restart chronyd && systemctl enable chronyd
$ chronyc sources
210 Number of sources = 1
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* ceph-1 10 6 7 2 -25ns[-6354ns] +/- 10us
[root@ceph-1 ~]# date
Fri Jun 3 17:45:29 CST 2022
- ceph-2、ceph-3、ceph-client节点执行
$ yum install chrony -y
$ sed -i '3,6s/^/#/g' /etc/chrony.conf
$ sed -i '7s/^/server ceph-1 iburst/g' /etc/chrony.conf
$ systemctl restart chronyd && systemctl enable chronyd
$ chronyc sources
210 Number of sources = 1
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* ceph-1 11 6 7 1 -2624ns[ -411ms] +/- 1195us
[root@ceph-2 ~]# date
Fri Jun 3 17:45:29 CST 2022
2、创建ceph集群
后面的操作步骤,请注意观察命令是在那台主机上执行的(非常重要),几乎所有操作在ceph-1节点。
1、 安装ceph-deploy(三节点操作)
注意:检查ceph版本是否为 ceph-deploy-2.0.1 版本。如果使用ceph-deploy-1.5.x版本使用此文档会有小问题。
推荐使用ceph-deploy-2.0.1 版本
[root@ceph-1 ~]# yum install ceph-deploy ceph python-setuptools -y
[root@ceph-1 ~]# ceph-deploy --version
2.0.1
[root@ceph-2 ~]# yum install ceph python-setuptools -y
[root@ceph-3 ~]# yum install ceph python-setuptools -y
2、部署集群
ceph.conf:ceph配置文件
ceph-deploy-ceph.log:日志文件
ceph.mon.keyring:mon密钥文件(mon之间通信会用到)
[root@ceph-1 ceph]# cd /etc/ceph
[root@ceph-1 ceph]# ceph-deploy new ceph-1
[root@ceph-1 ceph]# ll
total 16
-rw-r--r--. 1 root root 198 Jun 2 16:06 ceph.conf
-rw-r--r--. 1 root root 2933 Jun 2 16:06 ceph-deploy-ceph.log
-rw-------. 1 root root 73 Jun 2 16:06 ceph.mon.keyring
-rw-r--r--. 1 root root 92 Apr 24 2020 rbdmap
修改副本数
[root@ceph-1 ceph]# cat ceph.conf
[global]
fsid = 1bd553c0-75e5-4f1e-aa51-88cb9aae7ba5
mon_initial_members = ceph-1
mon_host = 192.168.200.43
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
osd_pool_default_size = 2 #添加
安装ceph相关程序包、依赖包
[root@ceph-1 ceph]# ceph-deploy install ceph-1 ceph-2 ceph-3
安装ceph monitor监视器
安装monitor后使用ceph -s查看集群状态报错(需要身份验证文件)
[root@ceph-1 ceph]# ceph-deploy mon create ceph-1
[root@ceph-1 ceph]# ceph -s
2022-06-02 16:07:16.087 7fb927470700 -1 auth: unable to find a keyring on /etc/ceph/ceph.client.admin.keyring,/etc/ceph/ceph.keyring,/etc/ceph/keyring,/etc/ceph/keyring.bin,: (2) No such file or directory
2022-06-02 16:07:16.087 7fb927470700 -1 monclient: ERROR: missing keyring, cannot use cephx for authentication
[errno 2] error connecting to the cluster
使用gatherkeys子命令,收集配置新节点的身份验证密钥。
这时你会发现/etc/ceph目录下多了5个密钥文件,再一次使用ceph -s发现可以使用并且集群状态是HEALTH_OK。
[root@ceph-1 ceph]# ceph-deploy gatherkeys ceph-1
[root@ceph-1 ceph]# ll
total 44
-rw-------. 1 root root 113 May 31 09:51 ceph.bootstrap-mds.keyring #mds密钥
-rw-------. 1 root root 113 May 31 09:51 ceph.bootstrap-mgr.keyring #mgr密钥
-rw-------. 1 root root 113 May 31 09:51 ceph.bootstrap-osd.keyring #osd密钥
-rw-------. 1 root root 113 May 31 09:51 ceph.bootstrap-rgw.keyring #rgw密钥
-rw-------. 1 root root 151 May 31 09:51 ceph.client.admin.keyring #admin管理用户密钥
-rw-r--r--. 1 root root 223 May 31 09:50 ceph.conf
-rw-r--r--. 1 root root 14695 May 31 09:51 ceph-deploy-ceph.log
-rw-------. 1 root root 73 May 31 09:47 ceph.mon.keyring
# 连接ceph集群admin用户密码
[root@ceph-1 ceph]# cat ceph.client.admin.keyring
[client.admin]
key = AQAWHZZiaX5eFBAAwkKizCr+cjbeQpqmjMZ5sQ==
caps mds = "allow *"
caps mgr = "allow *"
caps mon = "allow *"
caps osd = "allow *"
[root@ceph-1 ceph]# ceph -s
cluster:
id: 48a5d20d-b4b7-49cd-b50e-3876509024e2
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
3、部署mgr管理服务
[root@ceph-1 ceph]# ceph-deploy mgr create ceph-1
[root@ceph-1 ceph]# ceph -s
cluster:
id: 48a5d20d-b4b7-49cd-b50e-3876509024e2
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: ceph-1(active)
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 27 GiB / 30 GiB avail
pgs:
统一集群配置
将admin密钥文件拷贝到指定节点,这样每次执行ceph命令时就无需指定monitor地址和ceph.client.admin.keyring了。
$ ceph-deploy admin ceph-1 ceph-2 ceph-3
#各节点添加r读权限
$ chmod +r /etc/ceph/ceph.client.admin.keyring
4、部署osd
三节点磁盘都格式化为xfs格式
[root@ceph-1 ceph]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
sdb 8:16 0 20G 0 disk
sr0 11:0 1 1024M 0 rom
[root@ceph-1 ceph]# mkfs.xfs /dev/sdb #所有集群节点执行
[root@ceph-1 ceph]# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
...
sdb xfs 5dfa0891-e40f-48ee-9591-da7e353cf842
[root@ceph-1 ceph]# ceph-deploy osd create ceph-1 --data /dev/sdb
[root@ceph-1 ceph]# ceph-deploy osd create ceph-2 --data /dev/sdb
[root@ceph-1 ceph]# ceph-deploy osd create ceph-3 --data /dev/sdb
#查看osd状态
[root@ceph-1 ceph]# ceph-deploy osd list ceph-1 ceph-2 ceph-3
[root@ceph-1 ceph]# ceph -s
cluster:
id: e9ae008c-8567-4af5-a6be-22c75d430f2e
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: ceph-1(active)
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
使用ceph
一、cephfs文件系统
1、部署mds
[root@ceph-1 ceph]# ceph-deploy mds create ceph-1 ceph-2 ceph-3
[root@ceph-1 ceph]# ceph mds stat
, 3 up:standby
[root@ceph-1 ceph]# ceph -s
cluster:
id: e9ae008c-8567-4af5-a6be-22c75d430f2e
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: ceph-1(active)
osd: 3 osds: 3 up, 3 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs:
2、创建存储池
[root@ceph-1 ceph]# ceph osd pool create cephfs_data 128
pool 'cephfs_data' created
[root@ceph-1 ceph]# ceph osd pool create cephfs_metadata 60
pool 'cephfs_metadata' created
3、创建文件系统
语法:ceph fs new <fs_name> <metadata> <data>
[root@ceph-1 ceph]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
[root@ceph-1 ceph]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
4、创建文件系统后,MDS 进入活动状态。
创建了文件系统并且 MDS 处于活动状态(active),就可以挂载文件系统了。
[root@ceph-1 ceph]# ceph mds stat #1个处于活跃、2个处于热备份
cephfs-1/1/1 up {0=ceph-1=up:active}, 2 up:standby
[root@ceph-1 ceph]# ceph -s
cluster:
id: e9ae008c-8567-4af5-a6be-22c75d430f2e
health: HEALTH_OK
services:
mon: 1 daemons, quorum ceph-1
mgr: ceph-1(active)
mds: cephfs-1/1/1 up {0=ceph-1=up:active}, 2 up:standby
osd: 3 osds: 3 up, 3 in
data:
pools: 2 pools, 188 pgs
objects: 22 objects, 2.2 KiB
usage: 3.0 GiB used, 57 GiB / 60 GiB avail
pgs: 188 active+clean
5、 挂载使用cephfs
再客户端使用命令挂载
[root@ceph-1 ceph]# cat ceph.client.admin.keyring
[client.admin]
key = AQCcb5hi9KIrGRAA+4Pq24BCk/JgnkX7WDMiqQ==
...
[root@ceph-clinet ~]# mount -t ceph 192.168.200.43:6789:/ /mnt -o name=admin,secret=AQCcb5hi9KIrGRAA+4Pq24BCk/JgnkX7WDMiqQ==
[root@ceph-clinet ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
...
192.168.200.43:6789:/ ceph 13G 0 13G 0% /mnt
[root@ceph-clinet ceph]# umount /mnt #取消挂载
6、密钥文件挂载客户端需要安装ceph-common,否则报错
[root@ceph-clinet ceph]# cat admin.secret
AQCcb5hi9KIrGRAA+4Pq24BCk/JgnkX7WDMiqQ==
[root@ceph-clinet ceph]# mount -t ceph 192.168.200.43:6789:/ /opt/cephfs/ -o name=admin,secret=/etc/ceph/admin.secret
mount: wrong fs type, bad option, bad superblock on 192.168.200.43:6789:/,
missing codepage or helper program, or other error
In some cases useful info is found in syslog - try
dmesg | tail or so.
7、使用 FUSE 挂载 CEPHFS
ceph -fuse是挂载 CephFS 的另一种方式,尽管它挂载在用户空间。因此,FUSE 的性能可能相对较低,但 FUSE 客户端更易于管理,尤其是在升级 CephFS 时。
[root@ceph-clinet ceph]# yum install -y ceph-fuse
[root@ceph-1 ceph]# scp /etc/ceph/ceph.client.admin.keyring ceph-client:/etc/ceph
[root@ceph-clinet ceph]# mkdir /etc/cephfs && ceph-fuse -m 192.168.200.43:6789 /opt/cephfs/
[root@ceph-clinet ceph]# df -h
Filesystem Size Used Avail Use% Mounted on
...
ceph-fuse 13G 0 13G 0% /opt/cephfs
[root@ceph-clinet ceph]# umount /opt/cephfs/
cephfs文件系统配置使用完,给虚拟机做个快照。后面会使用。
二、块存储
1、创建存储池pool
[root@ceph-1 ceph]# ceph osd pool create block_data 60
[root@ceph-1 ceph]# ceph osd lspools
1 cephfs_data
2 cephfs_metadata
3 block_data
2、创建RBD镜像,feature为layering
[root@ceph-1 ceph]# rbd create myimage -s 10G --image-feature layering -p block_data
[root@ceph-1 ceph]# rbd ls -p block_data
myimage
[root@ceph-1 ceph]# rbd info myimage -p block_data
rbd image 'myimage':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
id: 108b6b8b4567
block_name_prefix: rbd_data.108b6b8b4567
format: 2
features: layering
op_features:
flags:
create_timestamp: Thu Jun 2 21:33:40 2022
3、将myimage映射为块设备
[root@ceph-1 ceph]# rbd map myimage -p block_data
/dev/rbd0
[root@ceph-1 ceph]# rbd showmapped
id pool image snap device
0 block_data myimage - /dev/rbd0
[root@ceph-1 ceph]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
...
rbd0 252:0 0 10G 0 disk
4、格式化挂载使用
[root@ceph-1 ceph]# mkfs.xfs /dev/rbd0
[root@ceph-1 ceph]# mount /dev/rbd0 /mnt
[root@ceph-1 ceph]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/centos-root 50G 1.6G 49G 4% /
devtmpfs 899M 0 899M 0% /dev
tmpfs 911M 0 911M 0% /dev/shm
tmpfs 911M 9.6M 902M 2% /run
tmpfs 911M 0 911M 0% /sys/fs/cgroup
/dev/sda1 1014M 142M 873M 14% /boot
/dev/mapper/centos-home 47G 33M 47G 1% /home
tmpfs 183M 0 183M 0% /run/user/0
tmpfs 911M 52K 911M 1% /var/lib/ceph/osd/ceph-0
/dev/rbd0 10G 33M 10G 1% /mnt
三、对象存储
在使用对象存储之前,使用我们cephfs快照。(如果安装了块存储,这里的对象存储网关启动不了,原因不明。)
1、在 ceph-1 上通过 ceph-deploy 将 ceph-radosgw 软件包安装到 ceph-1 中
[root@ceph-1 ceph]# ceph-deploy install --rgw ceph-1
2、创建RGW服务
[root@ceph-1 ceph]# ceph-deploy rgw create ceph-1
[root@ceph-1 ceph]# ps -ef | grep radosgw
ceph 2347 1 2 15:50 ? 00:00:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-1 --setuser ceph --setgroup ceph
root 2962 1771 0 15:51 pts/0 00:00:00 grep --color=auto radosgw
[root@ceph-1 ceph]# systemctl status ceph-radosgw\*
● [email protected] - Ceph rados gateway
Loaded: loaded (/usr/lib/systemd/system/[email protected]; enabled; vendor preset: disabled)
Active: active (running) since Fri 2022-06-03 15:50:45 CST; 31s ago
Main PID: 2347 (radosgw)
CGroup: /system.slice/system-ceph\x2dradosgw.slice/[email protected]
└─2347 /usr/bin/radosgw -f --cluster ceph --name client.rgw.ceph-1 --setuser ceph --setgroup ceph
Jun 03 15:50:45 ceph-1 systemd[1]: Started Ceph rados gateway.
Jun 03 15:50:45 ceph-1 systemd[1]: Starting Ceph rados gateway...
3、访问RGW
RGW默认端口 7480
[root@ceph-1 ceph]# yum install -y net-tools
[root@ceph-1 ceph]# netstat -tnplu
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
...
tcp 0 0 0.0.0.0:7480 0.0.0.0:* LISTEN 2347/radosgw
浏览器访问http://192.168.200.43:7480/

使用 S3 访问 RGW
1、创建 s3 的兼容用户
[root@ceph-1 ceph]# radosgw-admin user create --uid ceph-s3-user --display-name "Ceph S3 User Demo"
...
"keys": [
{
"user": "ceph-s3-user",
"access_key": "V3J9L4M1WKV5O5ECAKPU",
"secret_key":"f5LqLVYOVNu38cuQwi0jXC2ZTboCSJDmdvB8oeYw"
...
}
access_key 与 secret_key 这里可以记录一下,也可以使用命令再次查看。
[root@ceph-1 ceph]# radosgw-admin user info --uid ceph-s3-user
使用命令行方式操作 rgw
1、配置命令行工具
[root@ceph-1 ceph]# yum -y install s3cmd
[root@ceph-1 ceph]# s3cmd --configure
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
Access Key: 82EWM49KPWGFVR0CWSD4 #输入用户Access
Secret Key: 129CSMM9Dk3CC1lZwM7kn75lXMhrWBAMPEuyJL5k ##输入用户Secret
Default Region [US]: #默认回车
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
S3 Endpoint [s3.amazonaws.com]: 192.168.200.43:7480 #输入Rgw服务地址
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: 192.168.200.43:7480/%(bucket)s #输入
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
Encryption password: ##默认回车
Path to GPG program [/usr/bin/gpg]: ##默认回车
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
Use HTTPS protocol [Yes]: no #输入no
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
HTTP Proxy server name:
New settings:
Access Key: 82EWM49KPWGFVR0CWSD4
Secret Key: 129CSMM9Dk3CC1lZwM7kn75lXMhrWBAMPEuyJL5k
Default Region: US
S3 Endpoint: 192.168.200.43:7480 ##输入Rgw服务地址
DNS-style bucket+hostname:port template for accessing a bucket: 192.168.200.43:7480/%(bucket)s
Encryption password:
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: False
HTTP Proxy server name:
HTTP Proxy server port: 0
Test access with supplied credentials? [Y/n] y #输入y
Please wait, attempting to list all buckets...
Success. Your access key and secret key worked fine :-)
Now verifying that encryption works...
Not configured. Never mind.
Save settings? [y/N] y #输入y
Configuration saved to '/root/.s3cfg'
2、这是需要修改版本,启用v2版本即可
[root@ceph-1 ~]# s3cmd mb s3://s3cmd-demo
ERROR: S3 error: 403 (SignatureDoesNotMatch)
[root@ceph-1 ceph]# sed -i '/signature_v2/s/False/True/g' /root/.s3cfg
3、创建
[root@ceph-1 ceph]# s3cmd mb s3://s3cmd-demo
Bucket 's3://s3cmd-demo/' created
4、上传
[root@ceph-1 ceph]# s3cmd put /etc/fstab s3://s3cmd-demo/fatab-demo
upload: '/etc/fstab' -> 's3://s3cmd-demo/fatab-demo' [1 of 1]
541 of 541 100% in 1s 327.08 B/s done
5、下载
[root@ceph-1 ceph]# s3cmd get s3://s3cmd-demo/fatab-demo
download: 's3://s3cmd-demo/fatab-demo' -> './fatab-demo' [1 of 1]
541 of 541 100% in 0s 39.79 KB/s done
6、删除
[root@ceph-1 ceph]# s3cmd del s3://s3cmd-demo/fatab-demo
delete: 's3://s3cmd-demo/fatab-demo'
参考资料
https://docs.ceph.com/en/latest/