文章目录
前言
Redis从入门到精通,本文详细讲解了redis基础内容,以及Spring Cache,Spring Data Redis技术的使用
提示:以下是本篇文章正文内容,下面案例可供参考
一、Redis基础
1. Redis简介
Redis是一个基于内存的key-value结构数据库。非关系型数据库。
Redis 是互联网技术领域使用最为广泛的存储中间件。
官网:https://redis.io中文网:https://www.redis.net.cn/
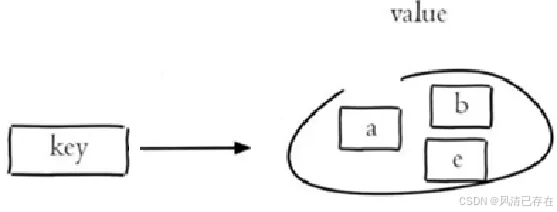
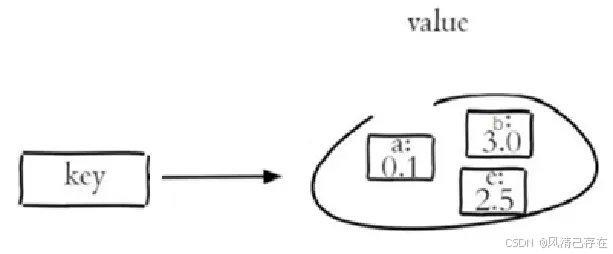
key-value结构存储:
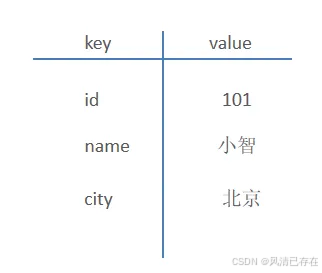
- 主要特点:
- 基于内存存储,读写性能高
- 适合存储热点数据(热点商品、资讯、新闻)
- 企业应用广泛
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供的数据是可以达到100000+的QPS(每秒内查询次数)。它存储的value类型比较丰富,也被称为结构化的NoSql数据库。
NoSql(Not Only SQL),不仅仅是SQL,泛指非关系型数据库。NoSql数据库并不是要取代关系型数据库,而是关系型数据库的补充。
关系型数据库(RDBMS):
- Mysql
- Oracle
- DB2
- SQLServer
非关系型数据库(NoSql):
- Redis
- Mongo db
- MemCached
2. Redis下载与安装
- Redis下载
Redis安装包分为windows版和Linux版:- Windows版下载地址:https://github.com/microsoftarchive/redis/releases
- Linux版下载地址: https://download.redis.io/releases/
- Redis安装
-
在Windows中安装Redis(项目中使用)
Redis的Windows版属于绿色软件,直接解压即可使用,解压后目录结构如下: -
在Linux中安装Redis(简单了解)
- 将Redis安装包上传到Linux
- 解压安装包,命令:tar -zxvf redis-4.0.0.tar.gz -C /usr/local
- 安装Redis的依赖环境gcc,命令:yum install gcc-c++
- 进入/usr/local/redis-4.0.0,进行编译,命令:make
- 进入redis的src目录进行安装,命令:make install
-
安装后重点文件说明:
- /usr/local/redis-4.0.0/src/redis-server:Redis服务启动脚本
- /usr/local/redis-4.0.0/src/redis-cli:Redis客户端脚本
- /usr/local/redis-4.0.0/redis.conf:Redis配置文件
-
- windows中安装成服务
在系统服务中自动启动了
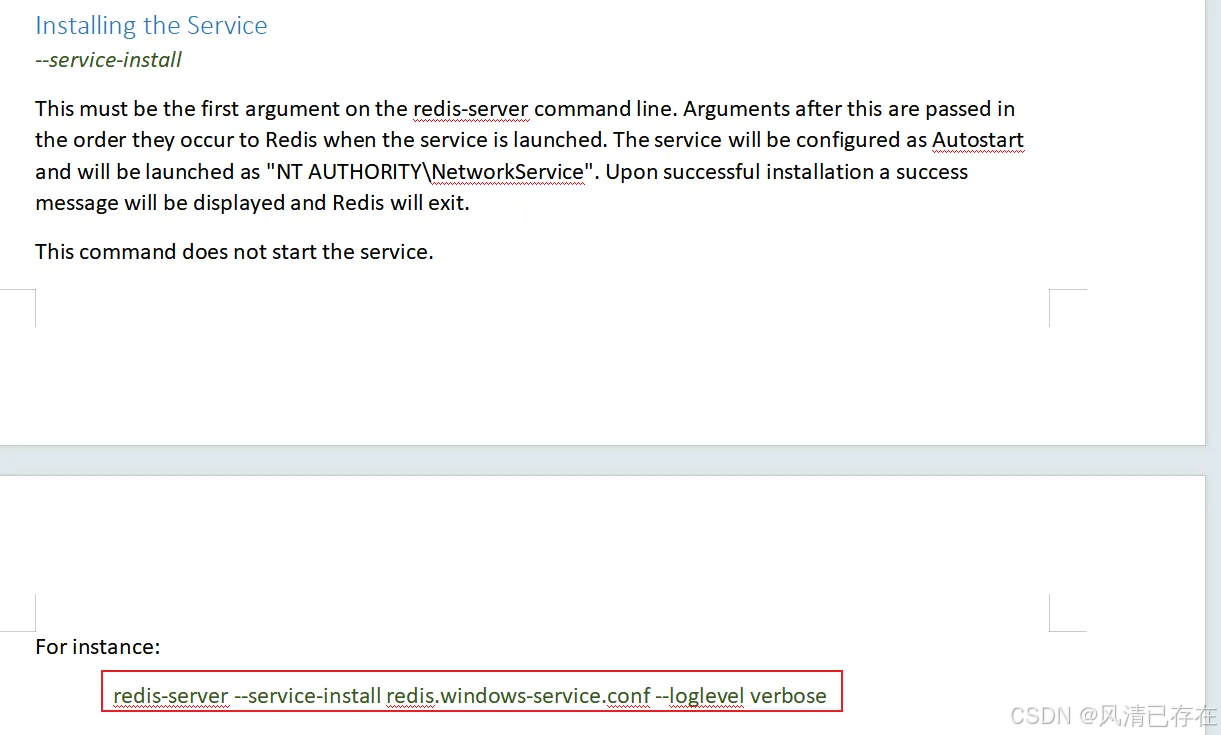
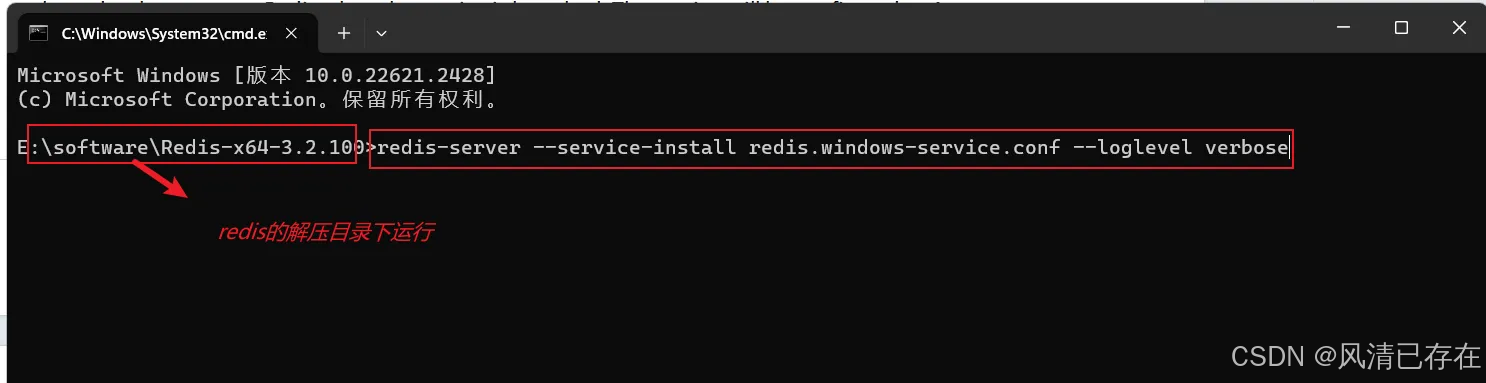

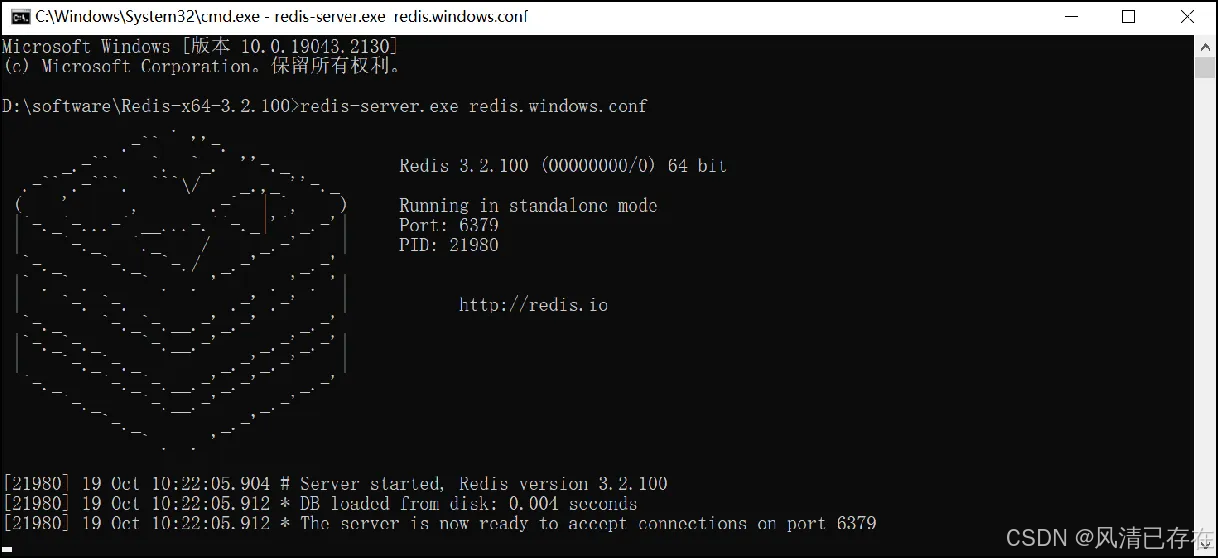
3. Redis服务启动与停止
以window版Redis进行演示:
- 服务启动命令
redis-server.exe redis.windows.conf
Redis服务默认端口号为 6379 ,通过快捷键Ctrl + C 即可停止Redis服务
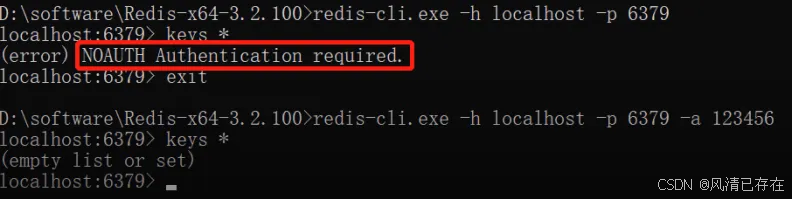
当Redis服务启动成功后,可通过客户端进行连接。 - 客户端连接命令
redis-cli.exe
通过redis-cli.exe命令默认连接的是本地的redis服务,并且使用默认6379端口。也可以通过指定如下参数连接:- -h ip地址
- -p 端口号
- -a 密码(如果需要)
注意: - 修改密码后需要重启Redis服务才能生效
- Redis配置文件中 # 表示注释
重启Redis后,再次连接Redis时,需加上密码,否则连接失败。
此时,-h 和 -p 参数可省略不写。
- Redis客户端图形工具
默认提供的客户端连接工具界面不太友好,同时操作也较为麻烦,接下来,引入一个Redis客户端图形工具。直接安装即可。安装完毕后,直接双击启动

- 新建连接
- 连接成功
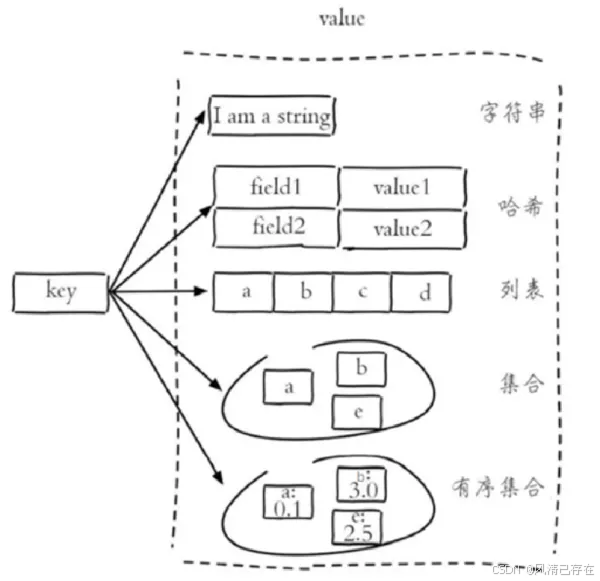
3 Redis数据类型
- 五种常用数据类型介绍
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型,key和value支持的最大是512M:- 字符串 string - 最常用 key:string
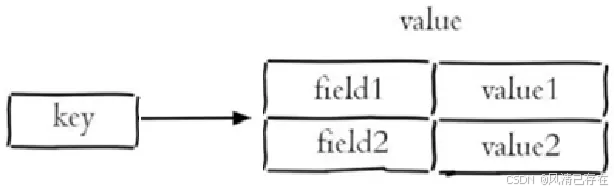
- 哈希 hash key:map
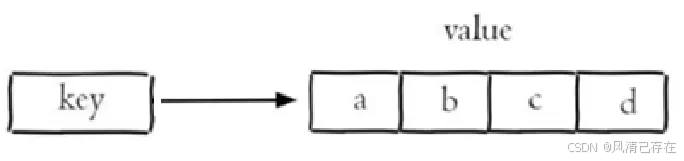
- 列表 list key: 列表 [1,2,3]
- 集合 set key:set 无序
- 有序集合 sorted set / zset key :zset
- 各种数据类型特
- 解释说明:
- 字符串(string):普通字符串,Redis中最简单的数据类型
- 哈希(hash):也叫散列,类似于Java中的HashMap结构
- 列表(list):按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList
- 集合(set):无序集合,没有重复元素,类似于Java中的HashSet
- 有序集合(sorted set/zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
4. Redis常用命令
-
字符串操作命令
Redis 中字符串类型常用命令:- SET key value 设置指定key的值
- GET key 获取指定key的值
- SETEX key seconds value 设置指定key的值,并将 key 的过期时间设为 seconds 秒
- SETNX key value 只有在 key 不存在时设置 key 的值
- 更多命令可以参考Redis中文网:https://www.redis.net.cn
-
哈希操作命令
Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,存储一些具有对应关系的数据,比如用户信息。
常用命令:- HSET key field value 将哈希表 key 中的字段 field 的值设为 value
- HGET key field 获取存储在哈希表中指定字段的值
- HDEL key field 删除存储在哈希表中的指定字段
- HKEYS key 获取哈希表中所有字段
- HVALS key 获取哈希表中所有值
-
列表操作命令
Redis 列表是简单的字符串列表,按照插入顺序排序,可以用于实现消息队列、任务列表等场景。
常用命令:- LPUSH key value1 [value2] 将一个或多个值插入到列表头部 left push
- LRANGE key start stop 获取列表指定范围内的元素
- RPOP key 移除并获取列表最后一个元素 remove pop
- LLEN key 获取列表长度
- BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超 时或发现可弹出元素
-
集合操作命令
Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据
常用命令:- SADD key member1 [member2] 向集合添加一个或多个成员
- SMEMBERS key 返回集合中的所有成员
- SCARD key 获取集合的成员数
- SINTER key1 [key2] 返回给定所有集合的交集
- SUNION key1 [key2] 返回所有给定集合的并集
- SREM key member1 [member2] 移除集合中一个或多个成员
-
有序集合操作命令
Redis有序集合是string类型元素的集合,且不允许有重复成员。每个元素都会关联一个double类型的分数。
常用命令:- ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员zset add
- ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
- ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment
- ZREM key member [member …] 移除有序集合中的一个或多个成员
-
通用命令
Redis的通用命令是不分数据类型的,都可以使用的命令:- KEYS pattern 查找所有符合给定模式( pattern)的 key EXISTS key 检查给定 key 是否存。
- 在 TYPE key 返回 key 所储存的值的类型 DEL key 该命令用于在 key 存在是删除 key
5. 扩展数据类型
- geospatial 地理位置
- Redis 在 3.2 推出 Geo 类型,该功能可以推算出地理位置信息,两地之间的距离 。
有效的经度从 -180 度到 180 度。有效的纬度从 -85.05112878 度到 85.05112878 度。当坐标位置超出指定范围时,该命令将会返回一个错误。(error) ERR invalid longitude latitude pair xxx yyy
常用的有如下命令- GEOADD key longitude latitude member [longitude latitude member …] 添加成员以及设置经纬度信息
- GEODIST key member1 member2 [M | KM ] 返回2者之间的距离,M 和KM是距离单
- GEOPOS key [member [member …]] 返回指定成员的地理位置信息
- GEORADIUS key longitude latitude radius [M | KM ] 返回以指定位置为中心,指定距离为半径之内的数据
- GEOADD location 116.310442 40.056564 itcast001
- GEOADD location 116.307080 40.055798 courier_1 116.316688 40.057338 courier_2
- GEOADD location 116.313772 40.053699 courier_3 116.311184 40.051204 courier_4
- GEOADD location 116.309331 40.052172 courier_5 116.310937 40.050827 courier_6
- GEOADD location 116.314077 40.056256 courier_7 116.316486 40.056098 courier_8
- hyperloglog 基数统计
- 基数:数学上集合的元素个数,是不能重复的。
UV(Unique visitor):是指通过互联网访问、浏览这个网页的自然人。访问的一个电脑客户端为一个访客,一天内同一个访客仅被计算一次。 - Redis 2.8.9 版本更新了 hyperloglog 数据结构,是基于基数统计的算法。
- hyperloglog 的优点是占用内存小,并且是固定的。存储 2^64 个不同元素的基数,只需要 12 KB 的空间。但是也可能有 0.81% 的错误率。
int 4 b * 100000000 /1000 = 4*100000kb /1000 = 400M
这个数据结构常用于统计网站的 UV。传统的方式是使用 set 保存用户的ID,然后统计 set 中元素的数量作为判断标准。
但是这种方式保存了大量的用户 ID,ID 一般比较长,占空间,还很麻烦。我们的目的是计数,不是保存数据,所以这样做有弊端。但是如果使用 hyperloglog 就比较合适了。
常用命令如下:- PFADD key [element [element …]] 将需要统计的成员保存到key中
- PFCOUNT key 统计key的 成员数
- HyperLogLog的使用场景主要包括以下几个方面:
- 用户去重:使用HyperLogLog可以对海量的用户数据进行去重,快速地统计出不重复的用户数量。
- 网站UV统计:使用HyperLogLog可以对网站的访问日志进行分析,统计出每天、每周、每月的独立访客数量。
- 广告点击统计:使用HyperLogLog可以对广告的点击数据进行分析,统计出独立点击用户的数量,以及对多个广告进行并、交运算等。
- 数据库查询优化:使用HyperLogLog可以对数据库中的数据进行去重,减少查询的数据量,提高查询效率。
- 分布式计算:使用HyperLogLog可以在分布式系统中对数据进行去重、并、交等操作,以支持分布式计算。
- bitmap 位图
- 1G = 1024 M 1M=1024kb 1kb = 1024b 1b=8bit。bitmap就是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个bit的值,或者是0,或者是1;也就是说一个bit能存储的最多信息是2。bitmap 常用于统计用户信息比如活跃粉丝和不活跃粉丝、登录和未登录、是否打卡等。
常用命令如下:- SETBIT key offset value 设置或清除存储在键处的字符串值中偏移处的位。
- GETBIT key offset 获取存储与key指定偏移处的位
- BITCOUNT key [start end [BYTE | BIT]] 统计key中所有设置了位的数量
- bitmap原理
- 我们为什么要选择bitmap? 因为只需要512M能表述2^32 的数据的是否存在!
假设我们存储id , id是long类型 8字节 2^32*8 b /2^10 / 2^57 kb /2^10 = 2^47 m /2^10 = 2^5 G = 32G - bitmap是如何做到的呢?
- bitmap的value其实是一个字符串。redis中value的最大是512M =2^9M *210=219 kb *2^10 = 2^29b * 8 = 232所以,总共有232个位来表示数据的是否存在。 也就是说可以表述42亿多的数据是否存在。
- bitmap如何用一个位表示 id =asdfalskdfasdnflksajdfl 用户是否存在呢?
- 我们应该设置2^32中的某一个位的值为1来表示 id=asdfalskdfasdnflksajdfl 是存在的。所以此时我们发现我们需要将一个字符串 id=asdfalskdfasdnflksajdfl 得换算成 一个数值 作为2^32次方中的索引。
- 如何将一个字符串换算成一个数值呢?hash算法!!! hash算法 32位 = 4b = int = 2^32,
ps:hash算法存在hash冲突,只会误判,不会漏判。
- 我们为什么要选择bitmap? 因为只需要512M能表述2^32 的数据的是否存在!
二、在Java中操作Redis
Redis的Java客户端
Redis 的 Java 客户端很多,常用的几种:
- Jedis
- Lettuce
- Spring Data Redis
Spring 对 Redis 客户端进行了整合,提供了 Spring Data Redis,在Spring Boot项目中还提供了对应的Starter,即 spring-boot-starter-data-redis。
重点讲解Spring Data Redis。
1. Spring Data Redis的使用
1.1. 介绍
Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,对 Redis 底层开发包进行了高度封装。在 Spring 项目中,可以使用Spring Data Redis来简化 Redis 操作。
网址:https://spring.io/projects/spring-data-redis
Spring Boot提供了对应的Starter,maven坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,对相关api进行了归类封装,将同一类型操作封装为operation接口,具体分类如下:
- ValueOperations:string数据操作 redisTemplate.opsForValue()
- SetOperations:set类型数据操作 redisTemplate.opsForSet()
- ZSetOperations:zset类型数据操作 redisTemplate.opsForZSet()
- HashOperations:hash类型的数据操作 redisTemplate.opsForHash()
- ListOperations:list类型的数据操作 redisTemplate.opsForList()
1.2. 环境搭建
导入Spring Data Redis的maven坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置Redis数据源
sky:
redis:
host: localhost
port: 6379
database: 2
解释说明:
- database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。可以通过修改Redis配置文件来指定数据库的数量。
1.3. 编写配置类,创建RedisTemplate对象
package com.sky.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory){
log.info("开始创建redis模板对象...");
RedisTemplate redisTemplate = new RedisTemplate();
//设置redis key、value的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
//value值支持中文正常显示
redisTemplate.setValueSerializer(new FastJsonRedisSerializer<Object>(Object.class));
//设置redis的连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
return redisTemplate;
}
}
解释说明:
- 当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为JdkSerializationRedisSerializer,导致我们存到Redis中后的数据和原始数据有差别,故设置为StringRedisSerializer序列化器。
- 不配置,默认注入
@Autowired
private RedisTemplate<String,String> redisTemplate; //这里可以指定泛型
@Autowired
//这个注入进行了序列化不会乱码
private StringRedisTemplate redisTemplate; //这个也是redis注入的另一个实现类
RedisTemplate默认使用JDK的序列化机制,因此从程序中输入的字符串经过序列化看起来像是乱码;而StringRedisTemplate使用了String的序列化机制,因此有一种所见即所得的效果。


1.4. 通过RedisTemplate对象操作Redis
package com.sky.test;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.*;
@SpringBootTest
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate(){
System.out.println(redisTemplate);
//string数据操作
etOperations = redisTemplate.opsForZSet();
}
}
测试
说明RedisTemplate对象注入成功,并且通过该RedisTemplate对象获取操作5种数据类型相关对象。
上述环境搭建完毕后,接下来,我们就来具体对常见5种数据类型进行操作。
1.5. 操作示例
/**
* 操作字符串类型的数据
*/
@Test
public void testString(){
// set get setex setnx
redisTemplate.opsForValue().set("name","小明");
String city = (String) redisTemplate.opsForValue().get("name");
System.out.println(city);
redisTemplate.opsForValue().set("code","1234",3, TimeUnit.MINUTES);
redisTemplate.opsForValue().setIfAbsent("lock","1");
redisTemplate.opsForValue().setIfAbsent("lock","2");
}
/**
* 操作哈希类型的数据
*/
@Test
public void testHash(){
//hset hget hdel hkeys hvals
HashOperations hashOperations = redisTemplate.opsForHash();
hashOperations.put("100","name","tom");
hashOperations.put("100","age","20");
String name = (String) hashOperations.get("100", "name");
System.out.println(name);
Set keys = hashOperations.keys("100");
System.out.println(keys);
List values = hashOperations.values("100");
System.out.println(values);
hashOperations.delete("100","age");
}
/**
* 操作列表类型的数据
*/
@Test
public void testList(){
//lpush lrange rpop llen
ListOperations listOperations = redisTemplate.opsForList();
listOperations.leftPushAll("mylist","a","b","c");
listOperations.leftPush("mylist","d");
List mylist = listOperations.range("mylist", 0, -1);
System.out.println(mylist);
listOperations.rightPop("mylist");
Long size = listOperations.size("mylist");
System.out.println(size);
}
/**
* 操作集合类型的数据
*/
@Test
public void testSet(){
//sadd smembers scard sinter sunion srem
SetOperations setOperations = redisTemplate.opsForSet();
setOperations.add("set1","a","b","c","d");
setOperations.add("set2","a","b","x","y");
Set members = setOperations.members("set1");
System.out.println(members);
Long size = setOperations.size("set1");
System.out.println(size);
Set intersect = setOperations.intersect("set1", "set2");
System.out.println(intersect);
Set union = setOperations.union("set1", "set2");
System.out.println(union);
setOperations.remove("set1","a","b");
}
/**
* 操作有序集合类型的数据
*/
@Test
public void testZset(){
//zadd zrange zincrby zrem
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
zSetOperations.add("zset1","a",10);
zSetOperations.add("zset1","b",12);
zSetOperations.add("zset1","c",9);
Set zset1 = zSetOperations.range("zset1", 0, -1);
System.out.println(zset1);
zSetOperations.incrementScore("zset1","c",10);
zSetOperations.remove("zset1","a","b");
}
/**
* 通用命令操作
*/
@Test
public void testCommon(){
//keys exists type del
Set keys = redisTemplate.keys("*");
System.out.println(keys);
Boolean name = redisTemplate.hasKey("name");
Boolean set1 = redisTemplate.hasKey("set1");
for (Object key : keys) {
DataType type = redisTemplate.type(key);
System.out.println(type.name());
}
redisTemplate.delete("mylist");
}
//分页查询 项目示例
public PageResponse<RoleVo> findRolePage(RoleDto roleDto, int pageNum, int pageSize) {
//设置key
String key = CacheConstant.RESOURCE_PREFIX+ roleDto.hashCode()+pageNum+pageSize;
//查询
String listStr = redisTemplate.opsForValue().get(key);
if (StringUtils.isNotBlank(listStr)){
return BeanUtil.toBean(listStr,PageResponse.class);
}
PageHelper.startPage(pageNum, pageSize);
Page<Role> page = roleMapper.selectPage(roleDto);
PageResponse<RoleVo> pageResponse = PageResponse.of(page, RoleVo.class);
//存入redis
redisTemplate.opsForValue().set(key, JSON.toJSONString(pageResponse),30, TimeUnit.MINUTES);
return pageResponse;
}
2. Spring Cache的使用
2.1. 介绍
前言:
-
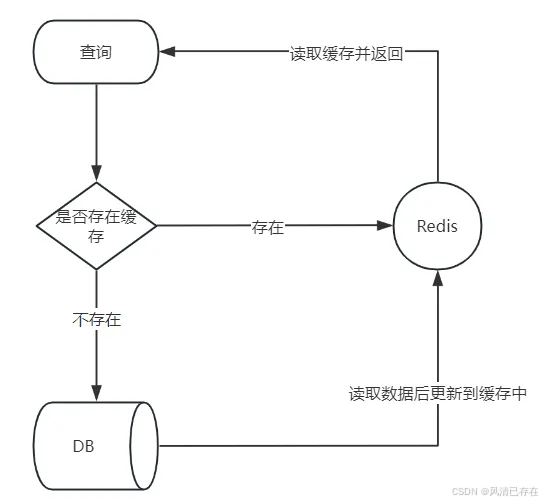
在我们查询部门数据的时候,特别是树形结构,要把所有的属性结构数据都展示出来,这个是会对数据库的访问造成一定的压力,并且从数据库查询效率也不是很高,所以我们通常都会添加缓存来提升效率
-
添加缓存的基本逻辑:
-
Spring Cache 是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。
-
Spring Cache 提供了一层抽象,底层可以切换不同的缓存实现,例如:
- EHCache
- Caffeine
- Redis(常用)
-
常用注解

2.2. 使用
- 集成环境
- 在引导类上添加EnableCaching注解
- 配置application.yml文件配置缓存对象

# 缓存相关配置
# 这里如果启用redis作为缓存那么就写redis,如果用ehcache就写ehcache
spring:
cache:
type: redis
2.3. 注解详解
- @CachePut 说明:
- 作用: 将方法返回值,放入缓存
- value: 缓存的名称, 每个缓存名称下面可以有很多ke
- key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
- 在目标方法上加注解@CachePut,用法如下:
/**
* CachePut:将方法返回值放入缓存
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@PostMapping
@CachePut(value = "userCache", key = "#user.id")//key的生成:userCache::1
public User save(@RequestBody User user){
userMapper.insert(user);
return user;
}
说明:key的写法如下
- user.id : #user指的是方法形参的名称, id指的是user的id属性 ,也就是使用user的id属性作为key ;
- result.id : #result代表方法返回值,该表达式代表以返回对象的id属性作为key ;
- p0.id:#p0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key
- a0.id:#a0指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key
- root.args[0].id:#root.args[0]指的是方法中的第一个参数,id指的是第一个参数的id属性,也就是使用第一个参数的id属性作为key
- @Cacheable注解
- 作用: 在方法执行前,spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据,调用方法并将方法返回值放到缓存中
- value: 缓存的名称,每个缓存名称下面可以有多个key
- key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
- 使用示例
/**
* Cacheable:在方法执行前spring先查看缓存中是否有数据,如果有数据,则直接返回缓存数据;若没有数据, *调用方法并将方法返回值放到缓存中
* value:缓存的名称,每个缓存名称下面可以有多个key
* key:缓存的key
*/
@GetMapping
@Cacheable(cacheNames = "userCache",key="#id")
public User getById(Long id){
User user = userMapper.getById(id);
return user;
}
- 多条件使用:
@Cacheable(value = "userCache",key="#userDto.hashCode()",unless = "#result.size() == 0")
//当条件比较冗余时,我们可以将条件封装,使用其封装对象的hash值当做key参数实体内容一致,则哈希值一致
public List<User> getList(UserDto userDto){
List<User> list = userMapper.getList("%" + userDto.getName() + "%", userDto.getAge());
return list;
}
如果返回结果为空,则不缓存unless = "#result = = null"或unless = “#result.size() = = 0” unless条件为true则不存入缓存
- @CacheEvict注解
- 作用: 清理指定缓存
- value: 缓存的名称,每个缓存名称下面可以有多个key
- key: 缓存的key ----------> 支持Spring的表达式语言SPEL语法
- 使用示例
@DeleteMapping
@CacheEvict(cacheNames = "userCache",key = "#id")//删除某个key对应的缓存数据
public void deleteById(Long id){
userMapper.deleteById(id);
}
@DeleteMapping("/delAll")
@CacheEvict(cacheNames = "userCache",allEntries = true)//删除userCache下所有的缓存数据
public void deleteAll(){
userMapper.deleteAll();
}
- @Caching注解
- 作用: 组装其他缓存注解
- cacheable 组装一个或多个@Cacheable注解
- put 组装一个或多个@CachePut注解
- evict 组装一个或多个@CacheEvict注解
- 使用示例
@Caching(
cacheable = {
@Cacheable(value = "userCache",key = "#id")
},
put = {
@CachePut(value = "userCache",key = "#result.name"),
@CachePut(value = "userCache",key = "#result.age")
}
)
public User getById(Long id){
User user = userMapper.getById(id);
if(user == null){
throw new RuntimeException("用户不存在");
}
return user;
}
当调用getById方法之后,首先到缓存中根据id查询数据,如果查询不成功还是会到数据库中找数据,同时会再往redis中set两个缓存,key分别是name和age
- 项目使用示例
- 过期时间等设置需要在配置文件中设置,不如Spring Data Redis灵活
@Service
@Transactional
public class ResourceServiceImpl implements ResourceService {
/**
* 多条件列表查询
* @param resourceDto
* @return
*/
@Cacheable(value = CacheConstant.RESOURCE_LIST ,key ="#resourceDto.hashCode()")
@Override
public List<ResourceVo> getList(ResourceDto resourceDto) {
}
/**
* 封装资源的树形结构
*
* @param resourceDto
* @return
*/
@Cacheable(value = CacheConstant.RESOURCE_TREE )
@Override
public TreeVo resourceTreeVo(ResourceDto resourceDto) {
}
/**
* 添加资源
* @param resourceDto
*/
@Caching(evict = {@CacheEvict(value = CacheConstant.RESOURCE_LIST ,allEntries = true),
@CacheEvict(value = CacheConstant.RESOURCE_TREE ,allEntries = true)})
@Override
public void createResource(ResourceDto resourceDto) {
}
/**
* 修改资源
* @param resourceDto
*/
@Caching(evict = {@CacheEvict(value = CacheConstant.RESOURCE_LIST ,allEntries = true),
@CacheEvict(value = CacheConstant.RESOURCE_TREE ,allEntries = true)})
@Override
public void updateResource(ResourceDto resourceDto) {
}
/**
* 启用禁用
* @param resourceVo
* @return
*/
@Caching(evict = {@CacheEvict(value = CacheConstant.RESOURCE_LIST ,allEntries = true),
@CacheEvict(value = CacheConstant.RESOURCE_TREE ,allEntries = true)})
@Override
public void isEnable(ResourceVo resourceVo) {
}
/**
* 删除菜单
* @param resourceNo
*/
@Caching(evict = {@CacheEvict(value = CacheConstant.RESOURCE_LIST ,allEntries = true),
@CacheEvict(value = CacheConstant.RESOURCE_TREE ,allEntries = true)})
@Override
public void deleteByResourceNo(String resourceNo) {
}
}
3. Spring Data Redis常用API
- RedisTemlate相关方法体系
- RedisTemlate类主要提供opsForValue(), opsForHash(), opsForList(), opsForSet(), opsForZSet() 等方法来获取特定数据类型的操作接口。这些方法返回相应的操作对象。
- ValueOperations<K, V>,HashOperations<K, HK, HV>,ListOperations<K, V>,SetOperations<K, V>接口的实现这些对象提供了对该数据类型进行操作的方法,其主要为在Redis中存储和获取内容。
- 而上述各个对象都实现了RedisOperations 接口,这个接口中提供了更多的Redis的具体操作,接口详情见下面
- 其他常用方法
- keys(String Pattern)获取当前所有的key(Pattren为正则表达式,模糊匹配需要使用通配符即* )
- delete(String Pattern/Collection keyLsit)删除当前redis中符合条件的key-value
- remove()删除当前redis中所有的key-value
- RedisOperations接口

Long remainTimeToLive = redisTemplate.opsForValue().getOperations().getExpire(jwtTokenKey, TimeUnit.SECONDS);
Long remainTimeToLive = redisTemplate.opsForValue().getOperations().getExpire(jwtTokenKey, TimeUnit.SECONDS);
这段代码是用来获取 Redis 中某个键的剩余生存时间(TTL,Time To Live)。具体来说,redisTemplate.opsForValue().getOperations().getExpire(jwtTokenKey) 会返回键 jwtTokenKey 的剩余过期时间(以秒为单位),如果键不存在或者没有设置过期时间,则会返回一个特定的值。
让我们分解一下这段代码:
- redisTemplate.opsForValue():这一步获取了 ValueOperations 的实例,它是用来操作字符串类型的键值对的。
- getOperations():由于 ValueOperations 实现了 Operations 接口,因此可以通过调用 getOperations() 来获取一个 RedisOperations 的实例,这个实例提供了更多的 Redis 操作方法,包括获取键的过期时间。
- getExpire(jwtTokenKey):这个方法实际上获取指定键的过期时间。返回值是一个 Long 类型,表示键还有多少秒过期。如果键不存在或者没有设置过期时间,则返回 -2L;如果键存在但是没有设置过期时间,则返回 -1L。
RedisOperations详解
RedisOperations 接口是 Spring Data Redis 提供的一个基础接口,它提供了一系列基本的 Redis 操作方法。虽然通常我们不会直接使用 RedisOperations,而是使用它的子接口如 BoundValueOperations, BoundHashOperations, BoundListOperations, BoundSetOperations, BoundZSetOperations 或者 ValueOperations, HashOperations, ListOperations, SetOperations, ZSetOperations 等来执行更具体的 Redis 操作。然而,RedisOperations 本身也提供了一些通用的操作方法。下面是一些常用的方法及其说明:
- 基本操作
- void delete(K key)
删除给定的键。 - void delete(Collection keys)
删除给定集合中的所有键。 - boolean exists(K key)
检查给定的键是否存在。 - K randomKey()
随机返回一个键。 - void rename(K oldKey, K newKey)
重命名给定的键。 - void renameIfAbsent(K oldKey, K newKey)
如果新的键不存在则重命名给定的键。 - Long expire(K key, long timeout, TimeUnit unit)
设置键的过期时间。 - Long persist(K key)
移除键的过期时间。 - Long getExpire(K key, TimeUnit unit)
获取键的剩余过期时间。
- void delete(K key)
- 批量操作
- Map<K, Boolean> executePipelined(RedisCallback callback)
批量执行命令并返回结果。 - Map<K, Boolean> executePipelined(RedisCallback callback, K… keys)
批量执行针对特定键的命令并返回结果。 - Map<K, Boolean> executePipelined(RedisCallback callback, Collection keys)
批量执行针对特定键集合的命令并返回结果。
- Map<K, Boolean> executePipelined(RedisCallback callback)
- 事务支持
- void multi()
开始一个事务。 - List exec()
执行事务中的所有命令。 - void discard()
取消事务中的所有命令。
- void multi()
- 其他
- String debug()
返回调试信息。 - void shutdown()
关闭 Redis 服务器。 - String info()
返回关于 Redis 服务器运行状态的信息。
- String debug()
示例:
// 删除键
redisTemplate.delete("myKey");
// 检查键是否存在
boolean exists = redisTemplate.hasKey("myKey");
// 获取键的过期时间
Long ttl = redisTemplate.getExpire("myKey", TimeUnit.SECONDS);
// 设置键的过期时间
redisTemplate.expire("myKey", 60, TimeUnit.SECONDS);
// 开始一个事务
redisTemplate.multi();
// 执行事务中的所有命令
List<Object> results = redisTemplate.exec();
// 取消事务中的所有命令
redisTemplate.discard();