SVM支持向量机
1 概述
Support Vector Machine是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器
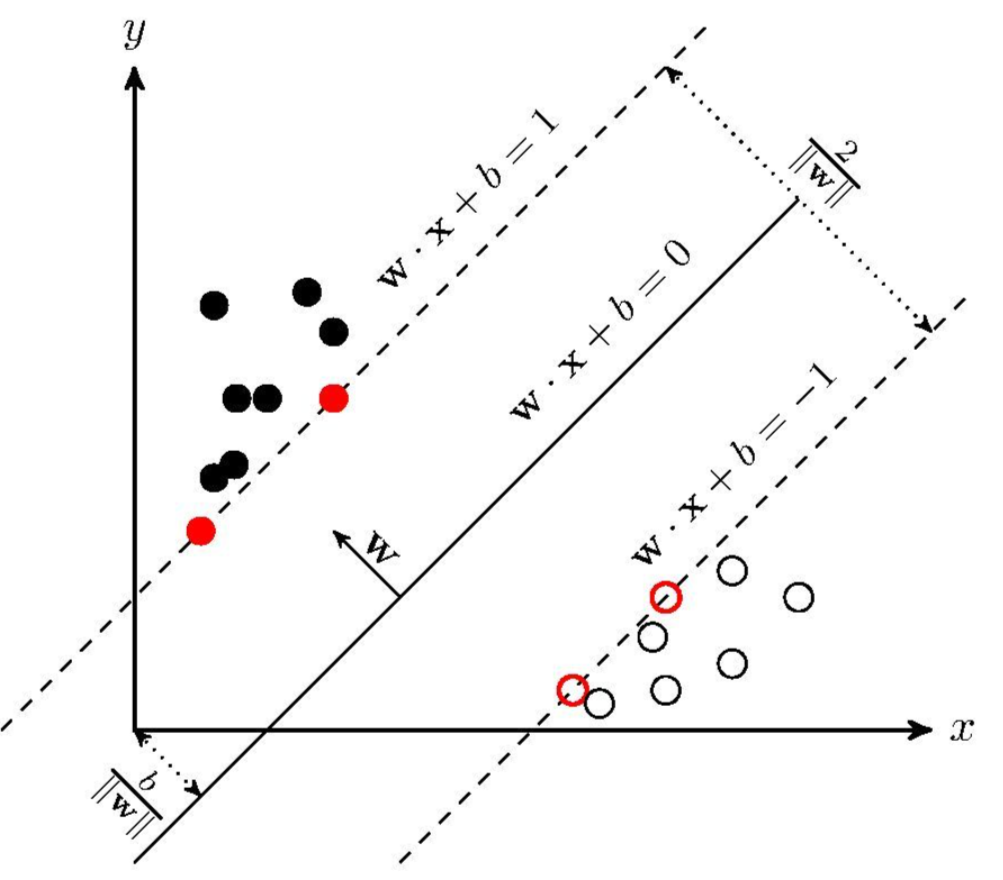
SVM学习的基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。如下图所示, w x + b = 0 wx+b=0 wx+b=0 即为分离超平面,对于线性可分的数据集来说,这样的超平面有无穷多个(即感知机),但是几何间隔最大的分离超平面却是唯一的。
2 推导
2.1 距离
正常三维条件下点
(
x
0
,
y
0
,
z
0
)
(x_0, y_0, z_0)
(x0,y0,z0)到平面
A
x
+
B
y
+
C
z
+
D
=
0
Ax + By + Cz + D = 0
Ax+By+Cz+D=0的距离公式(高中知识):
∣
A
x
0
+
B
y
0
+
C
z
0
+
D
∣
A
2
+
B
2
+
C
2
\frac{\vert Ax_0 + By_0 + Cz_0 + D \vert}{\sqrt{A^2 + B^2 + C^2}}
A2+B2+C2∣Ax0+By0+Cz0+D∣
推导分析过程:
平面方程: a x + b y + c z = d ax + by + cz = d ax+by+cz=d ,平面外一点 P ( x 0 , y 0 , z 0 ) P(x_0, y_0, z_0) P(x0,y0,z0)
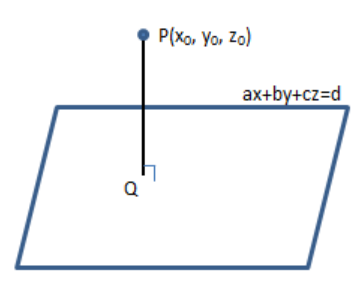
PQ垂直平面,即为求PQ的长度,但不知Q点的具体数据。
故构造一个平面上的点 P ′ ( x 1 , y 1 , z 1 ) P^{'}(x_1, y_1, z_1) P′(x1,y1,z1),问题即转化为求 P ′ P → \overrightarrow {P^{'}P} P′P 在法向量N上面的分量,即 P ′ P → \overrightarrow {P^{'}P} P′P 与N相同方向的单位向量的点积。
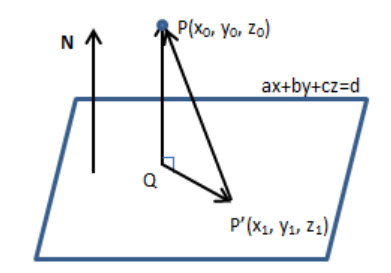
设距离为D。
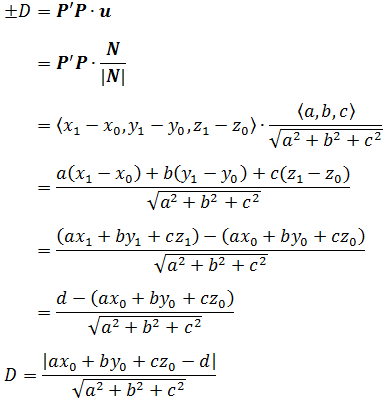
现在考虑一般情况:
求平面外一点 x x x 到平面 w T x + b = 0 w^T x + b = 0 wTx+b=0 的距离:
结论:平面 A x + B y + C z + D = 0 Ax + By + Cz + D = 0 Ax+By+Cz+D=0的法向量为 ( A , B , C ) (A, B, C) (A,B,C)
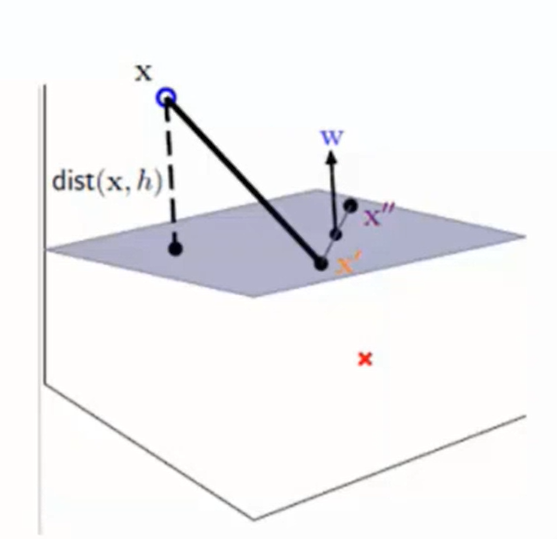
同上述原理:
距离就为
d
i
s
t
a
n
c
e
(
x
,
b
,
w
)
=
∣
w
T
∣
∣
w
∣
∣
(
x
−
x
′
)
∣
=
1
∣
∣
w
∣
∣
∣
w
T
x
+
b
∣
distance(x, b, w) = \vert \frac{w^T}{\vert \vert w \vert \vert}(x - x^{'}) \vert = \frac{1}{\vert \vert w \vert \vert} \vert w^Tx + b \vert
distance(x,b,w)=∣∣∣w∣∣wT(x−x′)∣=∣∣w∣∣1∣wTx+b∣
上述公式进行了代入,将 x ′ x^{'} x′代入平面方程得 w T x ′ = − b w^Tx^{'} = -b wTx′=−b
2.2 数据
数据集: ( x 1 , y 1 ) ( x 2 , y 2 ) . . . ( x n , y n ) (x_1, y_1)(x_2, y_2)...(x_n, y_n) (x1,y1)(x2,y2)...(xn,yn)
Y Y Y 为样本的类别:当 X X X 为正例时, Y = + 1 Y = +1 Y=+1,当 X X X为负例时, Y = − 1 Y = -1 Y=−1
决策方程:
y
(
x
)
=
w
T
Φ
(
x
)
+
b
y(x) = w^T \Phi(x) + b
y(x)=wTΦ(x)+b (其中
Φ
(
x
)
\Phi(x)
Φ(x)是对数据做了核变换,可以暂时理解为
x
x
x)
{
y
(
x
i
)
>
0
⇔
y
i
=
+
1
y
(
x
i
)
<
0
⇔
y
i
=
−
1
⟹
y
i
y
(
x
i
)
>
0
\begin{cases} y(x_i) > 0 \Leftrightarrow y_i = +1 \\ y(x_i) < 0 \Leftrightarrow y_i = -1 \end{cases} \Longrightarrow y_i y(x_i) > 0
{y(xi)>0⇔yi=+1y(xi)<0⇔yi=−1⟹yiy(xi)>0
2.3 目标函数求解
我们要求的就是找到一个线性划分(比如说直线),使得离该线最近的点最远。
将点到直线距离进行转化(化简):
y
i
⋅
(
w
T
⋅
Φ
(
x
)
+
b
)
∣
∣
w
∣
∣
\frac{y_i \cdot (w^T \cdot \Phi(x) + b)}{\vert \vert w \vert \vert}
∣∣w∣∣yi⋅(wT⋅Φ(x)+b)
y i y ( x i ) > 0 y_i y(x_i) > 0 yiy(xi)>0 直接乘上 y i y_i yi 将绝对值去掉, ∣ y i ∣ = 1 |y_i| = 1 ∣yi∣=1,并不影响值大小
放缩变换:对于决策方程(w, b)可以通过放缩变换使其结果值
∣
Y
∣
≥
1
|Y| \geq 1
∣Y∣≥1 ,则
y
i
⋅
(
w
T
⋅
Φ
(
x
i
)
+
b
)
≥
1
y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1
yi⋅(wT⋅Φ(xi)+b)≥1
缩放之前w和b有无数组解,缩放之后w和b只有一组解。
优化目标:
a
r
g
m
a
x
w
,
b
{
1
∣
∣
w
∣
∣
m
i
n
i
{
y
i
⋅
(
w
T
⋅
Φ
(
x
i
)
+
b
)
}
}
\mathop{arg\ max} \limits_{w, b} \bigg\{ \frac{1}{||w||} \mathop{min} \limits_i \Big \{ y_i \cdot (w^T \cdot \Phi(x_i) + b)\Big \} \bigg\}
w,barg max{∣∣w∣∣1imin{yi⋅(wT⋅Φ(xi)+b)}}
m i n i { y i ⋅ ( w T ⋅ Φ ( x i ) + b ) } \mathop{min} \limits_i \Big \{ y_i \cdot (w^T \cdot \Phi(x_i) + b) \Big \} imin{yi⋅(wT⋅Φ(xi)+b)} 是求所有样本点到平面的最小距离的那个点
a r g m a x w , b \mathop{argmax} \limits_{w,b} w,bargmax 是最大化到平面最小距离的点的距离,此时的w,b的值
由于 y i ⋅ ( w T ⋅ Φ ( x i ) + b ) ≥ 1 y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1 yi⋅(wT⋅Φ(xi)+b)≥1, 故最小值为1,只需要考虑 a r g m a x w , b 1 ∣ ∣ w ∣ ∣ \mathop{arg\ max} \limits_{w, b} \frac{1}{||w||} w,barg max∣∣w∣∣1
当前目标变为: m a x w , b 1 ∣ ∣ w ∣ ∣ \mathop{max} \limits_{w, b} \frac{1}{||w||} w,bmax∣∣w∣∣1,即求 ∣ ∣ w ∣ ∣ ||w|| ∣∣w∣∣的最小值,但有约束条件 y i ⋅ ( w T ⋅ Φ ( x i ) + b ) ≥ 1 y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1 yi⋅(wT⋅Φ(xi)+b)≥1
将求极大值转化为求极小值的问题,求 1 2 ∣ ∣ w ∣ ∣ 2 \frac{1}{2}||w||^2 21∣∣w∣∣2 的最小值。
需要使用拉格朗日乘子法:(此处不做证明,直接给出结论)
L
(
w
,
b
,
α
)
=
1
2
∣
∣
w
∣
∣
2
−
∑
i
=
1
n
α
i
(
y
i
⋅
(
w
T
⋅
Φ
(
x
i
)
+
b
)
−
1
)
L(w, b, \alpha) = \frac{1}{2}||w||^2 - \sum \limits_{i = 1}^n \alpha_i (y_i \cdot (w^T \cdot \Phi(x_i) + b) - 1)
L(w,b,α)=21∣∣w∣∣2−i=1∑nαi(yi⋅(wT⋅Φ(xi)+b)−1)
上式需要满足约束条件: y i ⋅ ( w T ⋅ Φ ( x i ) + b ) ≥ 1 y_i \cdot (w^T \cdot \Phi(x_i) + b) \geq 1 yi⋅(wT⋅Φ(xi)+b)≥1
满足KKT条件的点未必是局部(全局)最优点(还可能是局部极大和鞍点),但局部(全局)最优点必然满足KKT条件。对于凸优化问题,满足KKT条件的解直接就是全局最优解
最优解的必要条件: { ∇ L ( x , λ ) = ∇ f ( x ) + λ ∇ g ( x ) = 0 λ ≥ 0 λ g ( x ) = 0 ( 互补松弛 ) g ( x ) ≤ 0 ( 原约束 ) \text{最优解的必要条件: } \begin{cases} \nabla L(\mathbf{x}, \lambda) = \nabla f(\mathbf{x}) + \lambda \nabla g(\mathbf{x}) = 0 \\ \lambda \ge 0 \\ \lambda g(\mathbf{x}) = 0 (\text{互补松弛})\\ g(\mathbf{x}) \le 0 (\text{原约束}) \end{cases} 最优解的必要条件: ⎩ ⎨ ⎧∇L(x,λ)=∇f(x)+λ∇g(x)=0λ≥0λg(x)=0(互补松弛)g(x)≤0(原约束)推导可参考:https://blog.csdn.net/v_july_v/article/details/7624837
原理可参考:https://zhuanlan.zhihu.com/p/31886934
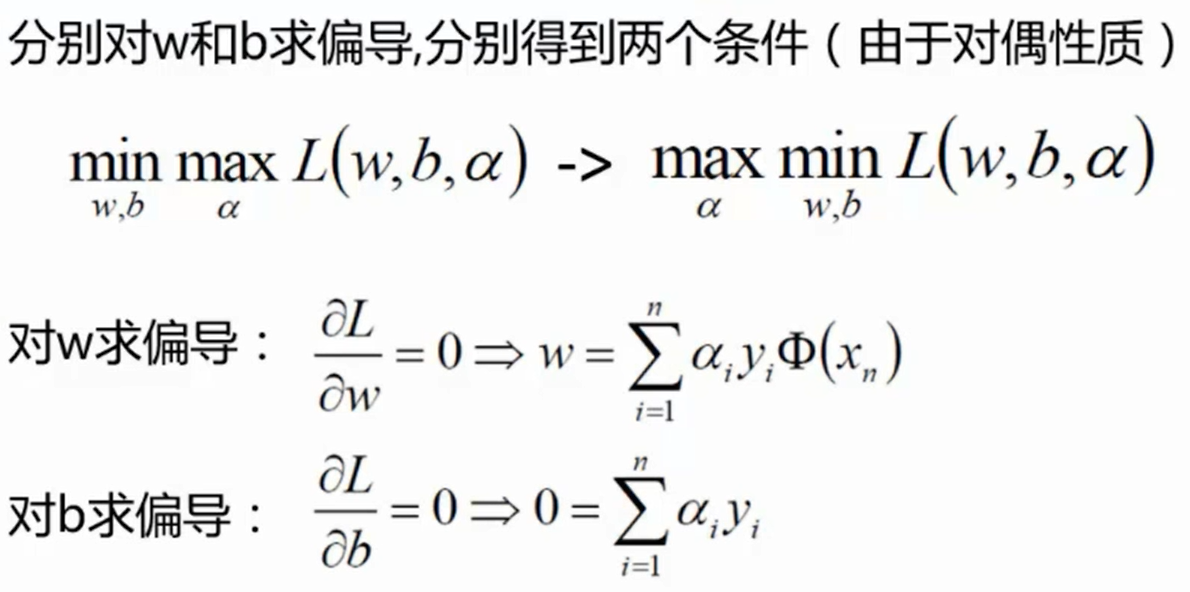

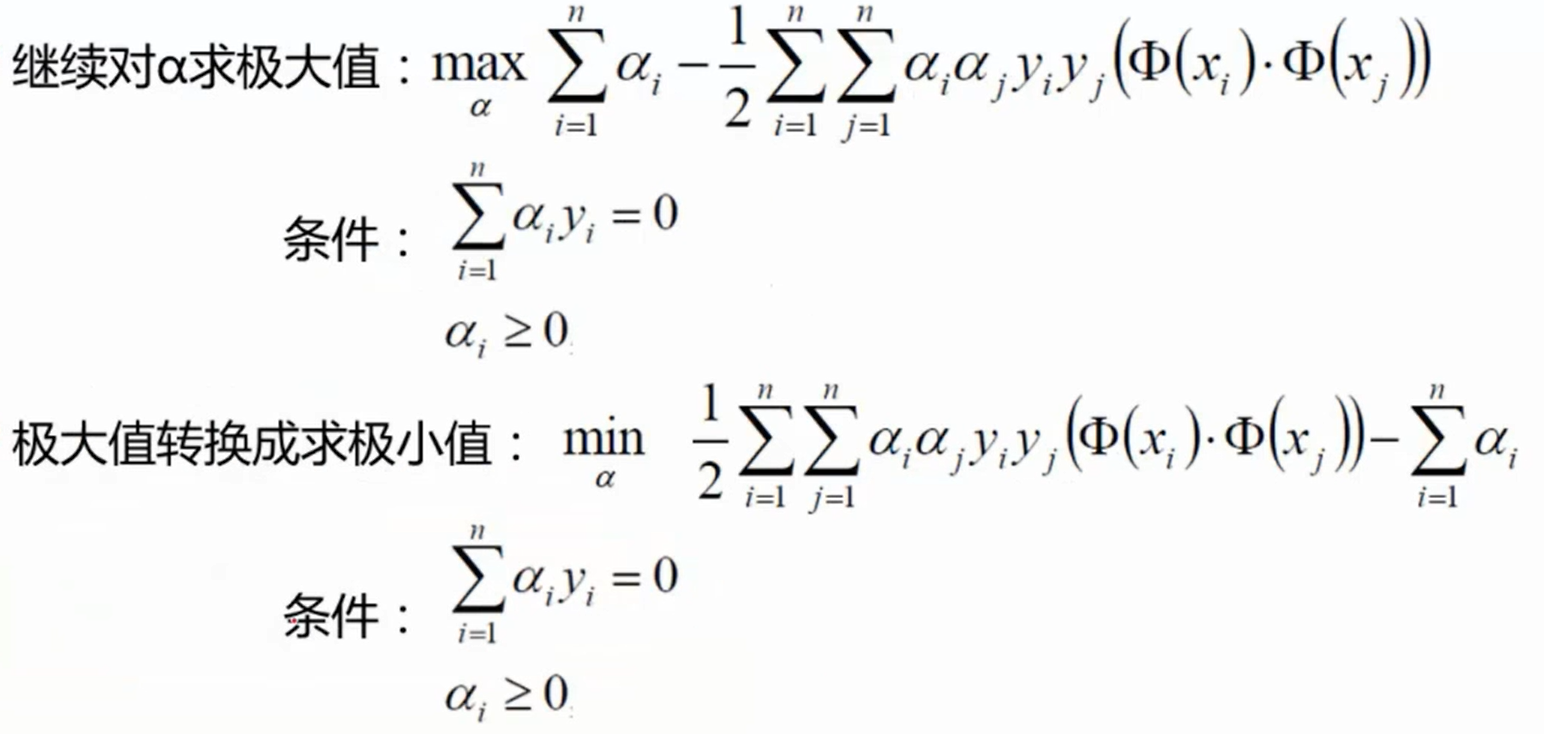
3 SVM实例
有三个数据:3个点,正例 x 1 ( 3 , 3 ) , x 2 ( 4 , 3 ) x_1(3, 3), x_2(4, 3) x1(3,3),x2(4,3), 负例 x 3 ( 1 , 1 ) x_3(1, 1) x3(1,1),(数据是二维数据)对其进行二分类。
首先需要求解下式的最小值:
1
2
∑
i
=
1
n
∑
j
=
1
n
α
i
α
j
y
i
y
j
(
x
i
⋅
x
j
)
−
∑
i
=
1
n
α
i
(
1
)
\frac{1}{2}\sum \limits_{i = 1}^n \sum \limits _{j = 1}^n \alpha_i \alpha_j y_i y_j (x_i \cdot x_j) - \sum \limits_{i = 1}^n\alpha_i \hspace{3em} (1)
21i=1∑nj=1∑nαiαjyiyj(xi⋅xj)−i=1∑nαi(1)
注意: x i ⋅ x j x_i \cdot x_j xi⋅xj 的运算是点积运算。
约束条件:
α 1 + α 2 − α 3 = 0 α i ≥ 0 , i = 1 , 2 , 3 \alpha_1 + \alpha_2 - \alpha_3 = 0 \\ \alpha_i \geq 0, \hspace{2em} i = 1, 2, 3 α1+α2−α3=0αi≥0,i=1,2,3
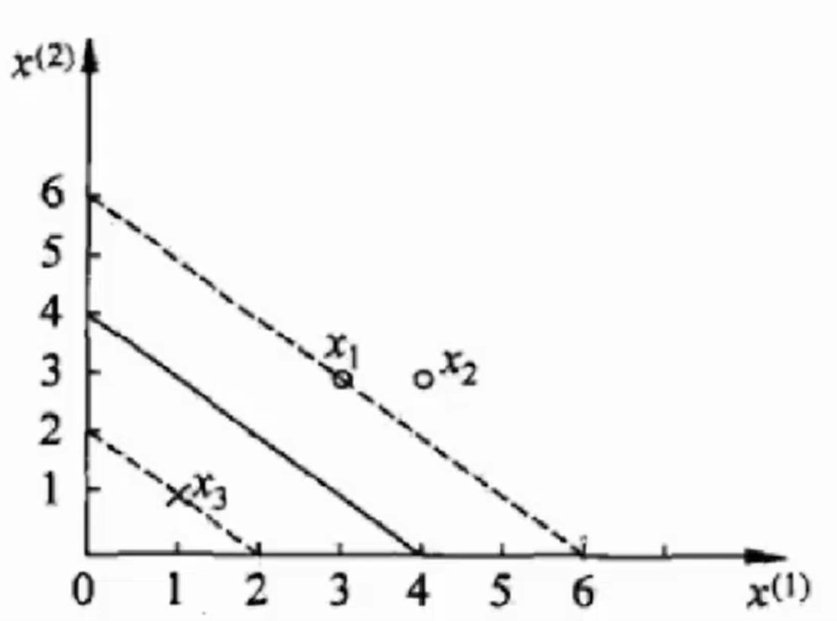
将对应的数据带入(1)式,得:
1
2
(
18
α
1
2
+
25
α
2
2
+
2
α
3
2
+
42
α
1
α
2
−
12
α
1
α
3
−
14
α
2
α
3
)
−
α
1
−
α
2
−
α
3
\frac{1}{2} \Big( 18 \alpha_1^2 + 25\alpha_2^2 + 2 \alpha_3^2 + 42\alpha_1\alpha_2 - 12\alpha_1\alpha_3 - 14\alpha_2\alpha_3 \Big) - \alpha_1 - \alpha_2 - \alpha_3
21(18α12+25α22+2α32+42α1α2−12α1α3−14α2α3)−α1−α2−α3
由于
α
1
+
α
2
=
α
3
\alpha_1 + \alpha_2 = \alpha_3
α1+α2=α3,化简得:
4
α
1
2
+
13
2
α
2
2
+
10
α
1
α
2
−
2
α
1
−
2
α
2
4 \alpha_1 ^ 2 + \frac{13}{2} \alpha_2^2 + 10\alpha_1\alpha_2 - 2\alpha_1 - 2\alpha_2
4α12+213α22+10α1α2−2α1−2α2
分别对
α
1
,
α
2
\alpha_1,\alpha_2
α1,α2求偏导,偏导等于0得
{
α
1
=
1.5
α
2
=
−
1
\begin{cases} \alpha_1 = 1.5 \\ \alpha_2 = -1 \end{cases}
{α1=1.5α2=−1
发现不满足约束条件
α
i
≥
0
\alpha_i \geq 0
αi≥0,故解应在边界上。分别让两个值等于0求解
{
α
1
=
0
α
2
=
−
2
13
(
×
)
{
α
1
=
0.25
α
2
=
0
(
✓
)
\begin{cases} \alpha_1 = 0 \\ \alpha_2 = -\frac{2}{13} \end{cases} (\times) \\ \begin{cases} \alpha_1 = 0.25 \\ \alpha_2 = 0 \end{cases} (\checkmark)
{α1=0α2=−132(×){α1=0.25α2=0(✓)
第一组解不满足,故最小值在
(
0.25
,
0
,
0.25
)
(0.25, 0, 0.25)
(0.25,0,0.25)处取得。
将
α
\alpha
α结果带求解
w
=
∑
i
=
1
n
α
i
y
i
Φ
(
x
i
)
w = \sum \limits_{i = 1}^n \alpha_i y_i \Phi(x_i)
w=i=1∑nαiyiΦ(xi),
Φ
(
x
i
)
\Phi(x_i)
Φ(xi)以
x
i
x_i
xi来代替
w
=
1
4
×
1
×
(
3
,
3
)
+
1
4
×
(
−
1
)
×
(
1
,
1
)
=
(
1
2
,
1
2
)
b
=
y
i
−
∑
i
=
1
n
a
i
y
i
(
x
i
x
j
)
=
1
−
(
1
4
×
1
×
18
+
1
4
×
(
−
1
)
×
6
)
=
−
2
w = \frac{1}{4} \times 1 \times (3,3) + \frac{1}{4} \times (-1) \times(1,1) = (\frac{1}{2}, \frac{1}{2}) \\ b = y_i - \sum \limits_{i = 1}^n a_i y_i (x_i x_j) = 1 - (\frac{1}{4} \times 1 \times 18 + \frac{1}{4} \times (-1) \times 6) = -2
w=41×1×(3,3)+41×(−1)×(1,1)=(21,21)b=yi−i=1∑naiyi(xixj)=1−(41×1×18+41×(−1)×6)=−2
故平面方程为:
0.5
x
1
+
0.5
x
2
−
2
=
0
0.5 x_1 + 0.5 x_2 - 2 = 0
0.5x1+0.5x2−2=0
因为 w = ∑ i = 1 n α i y i Φ ( x i ) w = \sum \limits_{i = 1}^n \alpha_i y_i \Phi(x_i) w=i=1∑nαiyiΦ(xi)
支持向量的 α \alpha α值不等于0, α = 0 \alpha = 0 α=0的向量不是支持向量,对最终结果没有影响。
支持向量就是那些对最终结果起作用的向量,也可以当做是边界上的向量。
4 软间隔
数据中有时候会有一些噪音点,如果考虑它们结果可能不会很好。
之前讨论的是要求所有样本点全部满足约束(这是硬间隔),而实际情况中这显然是不太可能的,软间隔则是允许某些样本点不满足约束。
为解决该问题,引入松弛因子: y i ( w ⋅ x i + b ) ≥ 1 − ξ i y_i(w \cdot x_i + b) \geq 1 - \xi_i yi(w⋅xi+b)≥1−ξi
新的目标函数:
m
i
n
w
,
b
,
ξ
i
1
2
∣
∣
w
∣
∣
2
+
C
∑
i
=
1
n
ξ
i
\mathop{min}\limits_{w, b, \xi_i} \frac{1}{2} ||w||^2 + C \sum \limits _{i = 1}^n \xi_i
w,b,ξimin21∣∣w∣∣2+Ci=1∑nξi
C是我们需要指定的一个参数
当C趋近于很大时:意味着分类严格不能有错误
当C趋近于很小时:意味着可以由更大的错误容忍
解法基本一样:

5 SVM核变换
将低维不可分映射到高维,找到一种变换方法,即为 ϕ ( x ) \phi(x) ϕ(x)
高斯核函数:
K
(
X
,
Y
)
=
exp
{
−
∣
∣
X
−
Y
∣
∣
2
2
σ
2
}
K(X, Y) = \exp \bigg\{ -\frac{||X-Y||^2}{2\sigma^2} \bigg\}
K(X,Y)=exp{−2σ2∣∣X−Y∣∣2}
6 基于sklearn求解SVM
参考 https://blog.csdn.net/weixin_42600072/article/details/88644229