这些内容都是自己一边学习一边总结的,其中每一个知识点都是经过翻阅大量资料整理,包含一些常见的报错和报警都会详细的举例和说明,大家一起学习。
往期学习文章
2024年最新Flink教程,从基础到就业,大家一起学习--基础篇-CSDN博客
2024年最新Flink教程,从基础到就业,大家一起学习--入门篇-CSDN博客
2024年最新Flink教程,从基础到就业,大家一起学习--Flink集群部署-CSDN博客
下面内容中会出现很多Hadoop及其组件的端口号,如果觉得太多看的有点花,可以看下这篇文章
Hadoop端口号全解析:掌握这些端口,轻松驾驭大数据集群,一文读懂常用端口号及其作用!-CSDN博客
一、部署模式
在一些应用场景中,对于集群资源分配和占用的方式,可能会有特定的需求。Flink为各种场景提供了不同的部署模式,主要有以下三种:会话模式(Session Mode)、单作业模式(Per-Job Mode)、应用模式(Application Mode)。
它们的区别主要在于:集群的生命周期以及资源的分配方式;以及应用的main方法到底在哪里执行——客户端(Client)还是JobManager。
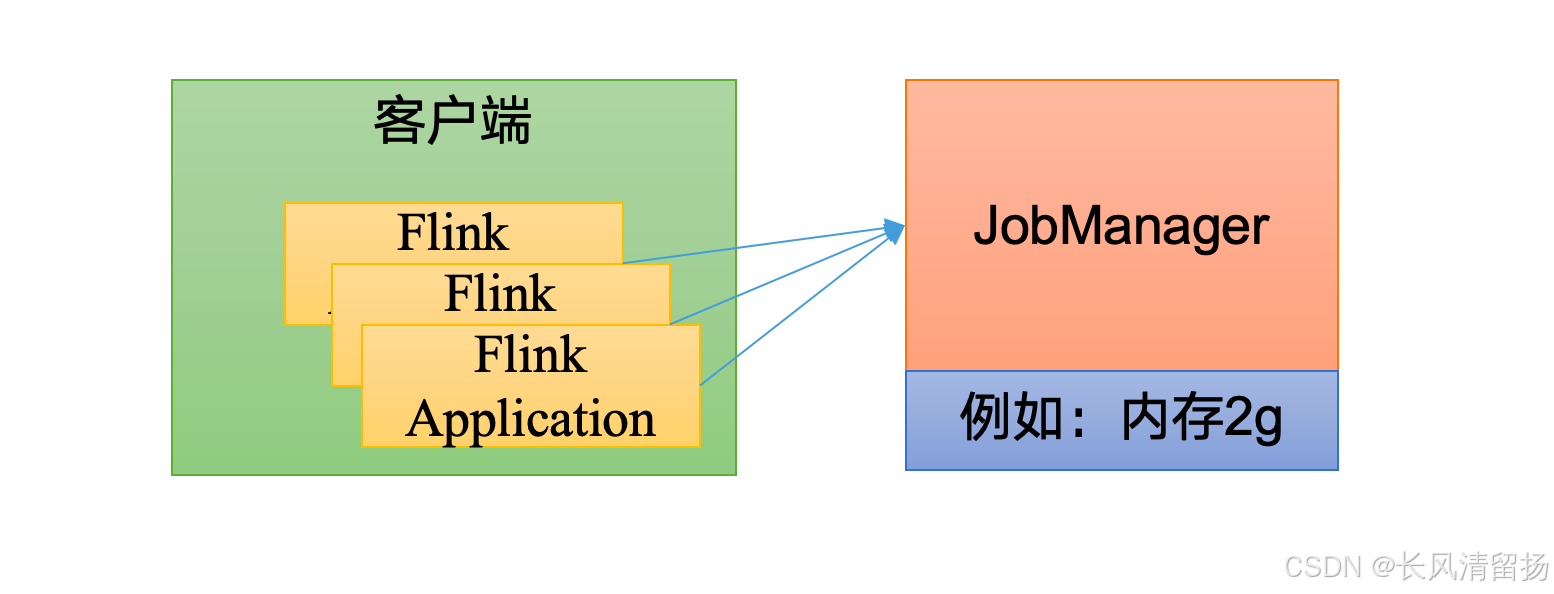
1. 会话模式(Session Mode)
会话模式其实最符合常规思维。我们需要先启动一个集群,保持一个会话,在这个会话中通过客户端提交作业。集群启动时所有资源就都已经确定,所以所有提交的作业会竞争集群中的资源。
特点:
- 在会话模式下,用户首先启动一个长期运行的Flink集群(Session),然后在这个会话中提交多个作业。
- 集群资源在启动时就已经确定,提交的作业会竞争集群中的资源,直到作业运行完毕释放资源。
- 集群的生命周期独立于集群上运行的任何作业的生命周期。
优点:
- 资源利用率高,因为可以重复使用已运行集群的资源。
- 简化了集群管理,减少了操作复杂性,因为不需要为每个作业频繁地启动和关闭集群。
缺点:
- 资源竞争:所有作业共享同一个集群的资源,可能会争夺CPU、内存和网络带宽,导致性能下降。
- 故障传播:如果一个作业行为异常或导致TaskManager失败,可能会影响在同一TaskManager上运行的其他作业。
- 隔离性有限:会话模式提供的作业之间的隔离性有限,一个作业的问题可能会潜在地影响在相同集群中运行的其他作业。
适用场景:
- 需要频繁提交大量小作业的场景。
- 对启动延迟要求较高且运行时间较短的作业,如交互式查询。
- 会话模式比较适合于单个规模小、执行时间短的大量作业。
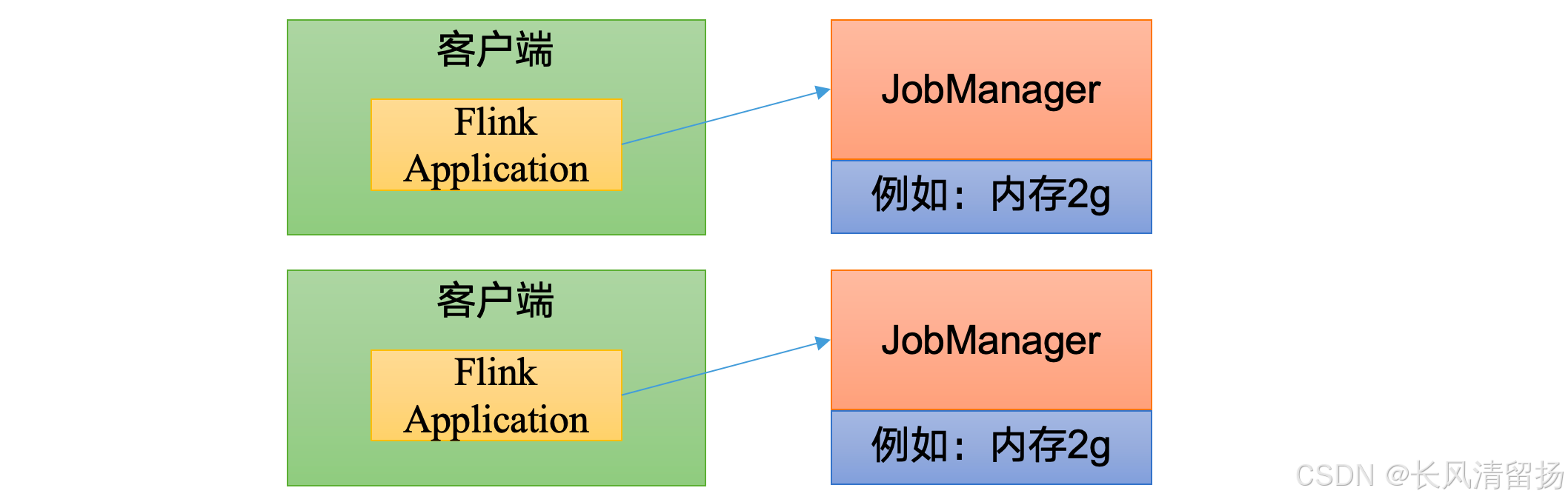
2. 单作业模式(Per-Job Mode)
会话模式因为资源共享会导致很多问题,所以为了更好地隔离资源,我们可以考虑为每个提交的作业启动一个集群,这就是所谓的单作业(Per-Job)模式。
特点:
- 在单作业模式下,每个作业都会启动一个独立的Flink集群,作业完成后集群也会关闭。
- 这种模式为每个作业提供了资源隔离,避免了资源争用的问题。
- 通常与第三方资源调度器(如YARN、Kubernetes等)结合使用,以便更有效地管理集群资源。
-
这些特性使得单作业模式在生产环境运行更加稳定,所以是实际应用的首选模式。
优点:
- 资源隔离好,一个作业的问题不会影响其他作业。
- 负载分散,每个作业都有自己的JobManager,减少了单个JobManager的负载。
缺点:
- 每个作业都需要启动和关闭集群,因此在处理大量作业时可能会产生额外的开销。
适用场景:
- 需要严格资源隔离和稳定性保障的场景。
- 长时间运行的作业,愿意承受增加启动延迟以提升作业的恢复能力。
注意:
- 需要注意的是,Flink本身无法直接这样运行,所以单作业模式一般需要借助一些资源管理框架来启动集群,比如YARN、Kubernetes(K8S)。
3. 应用模式(Application Mode)
前面提到的两种模式下,应用代码都是在客户端上执行,然后由客户端提交给JobManager的。但是这种方式客户端需要占用大量网络带宽,去下载依赖和把二进制数据发送给JobManager;加上很多情况下我们提交作业用的是同一个客户端,就会加重客户端所在节点的资源消耗。
所以解决办法就是,我们不要客户端了,直接把应用提交到JobManger上运行。而这也就代表着,我们需要为每一个提交的应用单独启动一个JobManager,也就是创建一个集群。这个JobManager只为执行这一个应用而存在,执行结束之后JobManager也就关闭了,这就是所谓的应用模式。

特点:
- 应用模式与单作业模式类似,也是为每个作业启动一个独立的Flink集群。
-
应用模式与单作业模式,都是提交作业之后才创建集群;单作业模式是通过客户端来提交的,客户端解析出的每一个作业对应一个集群;而应用模式下,是直接由JobManager执行应用程序的。
- 与单作业模式不同的是,在应用模式下,作业的
main方法直接在JobManager上执行,而不是在客户端执行。 - 这种模式简化了作业的提交过程,并减少了客户端与JobManager之间的通信开销。
优点:
- 节省了客户端的CPU周期和网络带宽,因为不需要在客户端执行
main方法和发送JobGraph。 - 提供了与单作业模式相同的资源隔离和负载均衡保证。
缺点:
- 如果多个正在运行的作业中的任何一个被取消,所有作业都将停止,并且JobManager将关闭(除非使用非阻塞式提交)。
适用场景:
- 需要高效利用资源且对作业提交过程有优化需求的场景。
- 提交由多个作业组成的应用程序,并希望它们共享一个集群但保持资源隔离。
这里我们所提到的部署模式,相对是比较抽象的概念。实际应用时,一般需要和资源管理平台结合起来,选择特定的模式来分配资源、部署应用。接下来,我们就针对不同的资源提供者的场景,具体介绍Flink的部署方式。
二、Standalone运行模式
独立模式是独立运行的,不依赖任何外部的资源管理平台;当然独立也是有代价的:如果资源不足,或者出现故障,没有自动扩展或重分配资源的保证,必须手动处理。所以独立模式一般只用在开发测试或作业非常少的场景下。
Flink的Standalone运行模式是其最基本的部署方式,它不需要依赖任何外部的资源管理平台,如YARN、Kubernetes等,而是直接在操作系统上启动Flink的相关服务,如Client、JobManager、TaskManager等。以下是对Flink Standalone运行模式的详细解析:
基本概述
- 定义:Standalone模式是指Flink直接在操作系统上启动Flink相关服务,不依赖其他资源管理框架进行资源管理的部署方式。
- 架构:Flink采用Master-Slave架构,其中Master角色对应JobManager,负责作业的调度和资源管理;Slave角色对应TaskManager,负责执行作业的具体任务。
组件说明
- JobManager:
- 职责:负责作业的提交、调度、监控和容错等。
- 配置项:如
jobmanager.memory.process.size,用于配置JobManager进程可使用的全部内存。
- TaskManager:
- 职责:负责执行作业的具体任务,每个TaskManager都是一个JVM进程,可能在独立的线程上执行一个或多个subtask。
- Task Slot:TaskManager通过task slot来控制能接收多少个task,每个task slot表示TaskManager拥有资源的一个固定大小的子集。
- 配置项:如
taskmanager.memory.process.size和taskmanager.numberOfTaskSlots,分别用于配置TaskManager进程可使用的全部内存和每个TaskManager能分配的Slot数量。
运行流程
- 启动集群:
- 通过执行
start-cluster.sh脚本启动Flink集群,该脚本会启动JobManager和TaskManager进程。 - 启动成功后,可以通过Web UI(通常是
http://<JobManager-Host>:8081)对Flink集群和任务进行监控管理。
- 通过执行
- 提交作业:
- 可以通过Web UI的Submit New Job页面提交作业,指定作业的jar包、入口类、启动参数等。
- 也可以通过命令行使用
flink run命令提交作业,指定作业的jar包路径、入口类、并行度等参数。
- 作业执行:
- JobManager接收到作业提交请求后,会进行作业的解析、调度和执行。
- TaskManager根据JobManager的调度指令执行具体的任务。
- 监控与管理:
- 可以通过Web UI查看作业的运行状态、性能指标、日志信息等。
- 也可以通过命令行工具对作业进行停止、重启等操作。
优缺点
- 优点:
- 简单易用:不需要依赖外部资源管理平台,部署和配置相对简单。
- 灵活性高:可以根据实际需求自定义配置和调优。
- 缺点:
- 资源利用率低:在资源不足或作业负载不均的情况下,可能导致资源浪费或作业执行缓慢。
- 扩展性差:当作业量增加时,需要手动扩展集群规模,无法自动适应负载变化。
应用场景
Standalone模式一般适用于开发测试环境或作业量较少的生产环境。在这些场景下,由于作业量相对较少且对资源利用率的要求不高,因此可以通过手动配置和管理来满足需求。同时,Standalone模式也支持将集群部署在容器中运行(如Docker或Kubernetes),以提高部署的灵活性和可移植性。
综上所述,Flink的Standalone运行模式是一种简单易用但资源利用率和扩展性相对有限的部署方式。在实际应用中,需要根据具体场景和需求选择合适的部署模式。
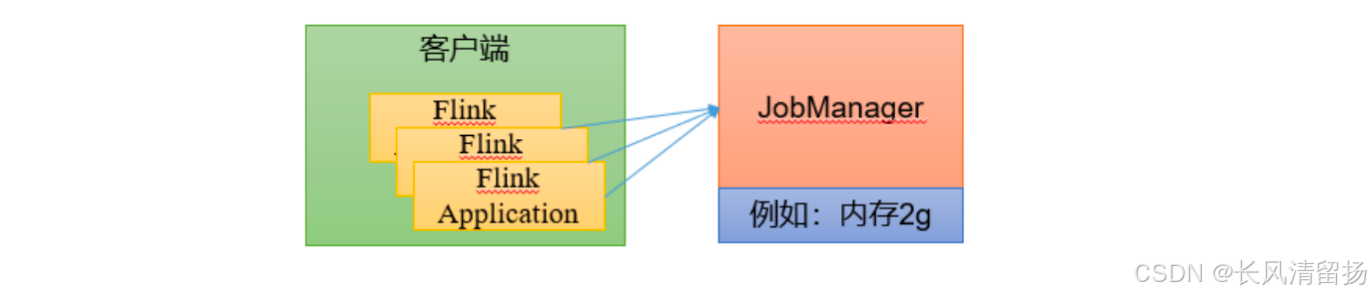
会话模式部署
这篇文章就是会话模式部署,感兴趣的小伙伴可以去看看
2024年最新Flink教程,从基础到就业,大家一起学习--Flink集群部署-CSDN博客
提前启动集群,并通过Web页面客户端提交任务(可以多个任务,但是集群资源固定)。
单作业模式部署
Flink的Standalone集群并不支持单作业模式部署。因为单作业模式需要借助一些资源管理平台。
应用模式部署
应用模式下不会提前创建集群,所以不能调用start-cluster.sh脚本。我们可以使用同样在bin目录下的standalone-job.sh来创建一个JobManager。

部署步骤
(0)关闭Standalone运行的会话模式
之前在上一章节通过start-cluster.sh启动了集群,现在需要先关闭掉
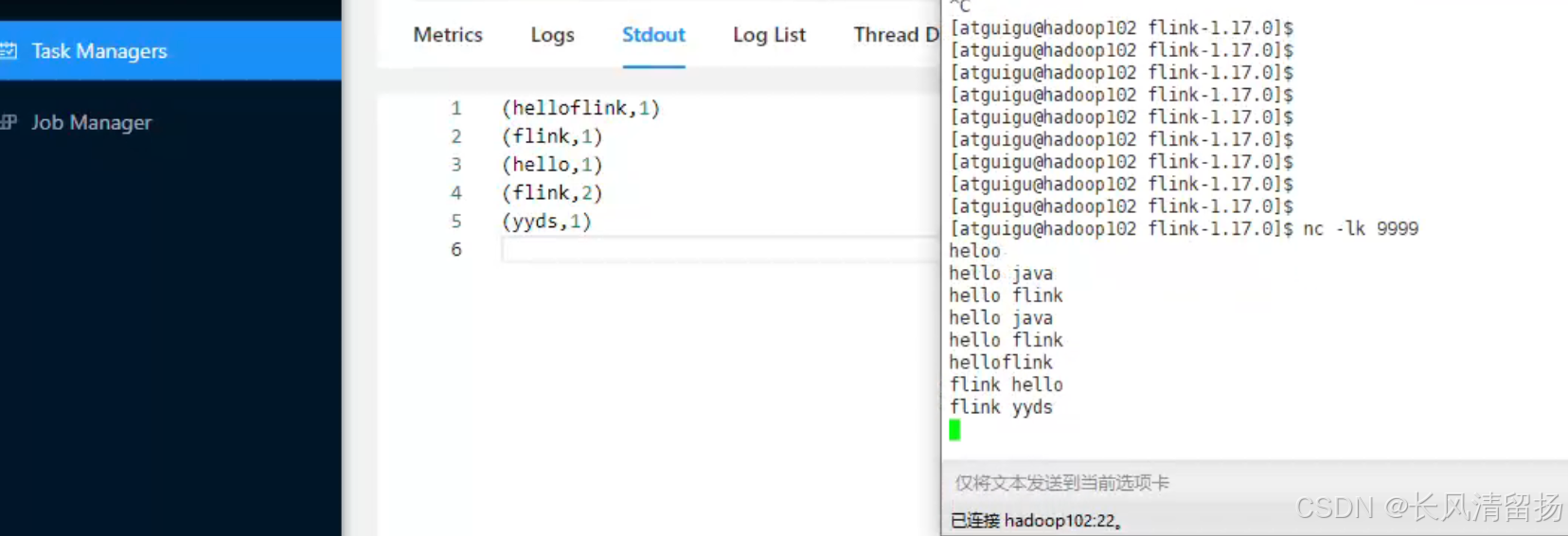
bin/stop-cluster.sh(1)环境准备。在hadoop102中执行以下命令启动netcat。
nc -lk 9999(2)进入到Flink的安装路径下,将应用程序的jar包放到lib/目录下。
应用程序源码请看2024年最新Flink教程,从基础到就业,大家一起学习--Flink集群部署-CSDN博客这篇文章
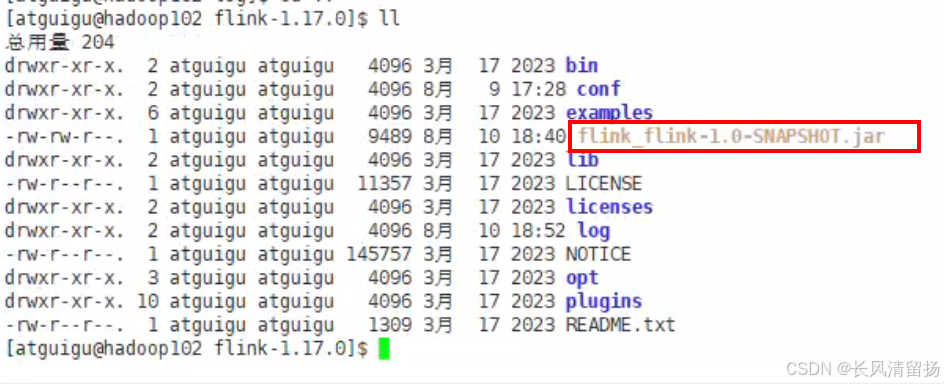
这个包就是上一篇文章写的wordcount的flink程序jar包,将该jar包移动到lib目录下,必须是lib目录下
mv flink_flink-1.0-SNAPSHOT.jar ./lib/flink_flink-1.0-SNAPSHOT.jar(3)执行以下命令,启动JobManager。
bin/standalone-job.sh start --job-classname wordcount.flink_wc_socket这里我们直接指定作业入口类,脚本会到lib目录扫描所有的jar包。
-
bin/standalone-job.sh:这是Flink安装目录下的一个脚本文件,用于在standalone模式下启动Flink作业。standalone模式是Flink作业运行的一种方式,意味着作业直接在Flink集群上运行,而不是通过客户端/服务器架构(如YARN或Kubernetes)来管理。 -
start:这个参数告诉standalone-job.sh脚本你想要启动一个作业。 -
--job-classname wordcount.flink_wc_socket:这个参数指定了要启动的作业的完全限定类名(fully qualified class name)。在这个例子中,它指的是wordcount.flink_wc_socket这个类,这个类实现了Flink作业逻辑的Java类。这个类包含了Flink程序的入口点,即定义了数据流(DataStream)操作来处理数据并计算结果。
(4)同样是使用bin目录下的脚本,启动TaskManager。
bin/taskmanager.sh start(5)在hadoop102上模拟发送单词数据。

(6)在hadoop102:8081地址中观察输出数据

(7)如果希望停掉集群,同样可以使用脚本,命令如下。
bin/taskmanager.sh stop
bin/standalone-job.sh stop三、YARN运行模式(重点)
YARN上部署的过程是:客户端把Flink应用提交给Yarn的ResourceManager,Yarn的ResourceManager会向Yarn的NodeManager申请容器。在这些容器上,Flink会部署JobManager和TaskManager的实例,从而启动集群。Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
相关准备和配置
在将Flink任务部署至YARN集群之前,需要确认集群是否安装有Hadoop,保证Hadoop版本至少在2.2以上,并且集群中安装有HDFS服务。
(1)配置环境变量,增加环境变量配置如下:
sudo vim /etc/profile.d/my_env.sh然后首先确保已经配置了Hadoop的配置,Hadoop的bin和sbin一定要确保加载到了环境变量中
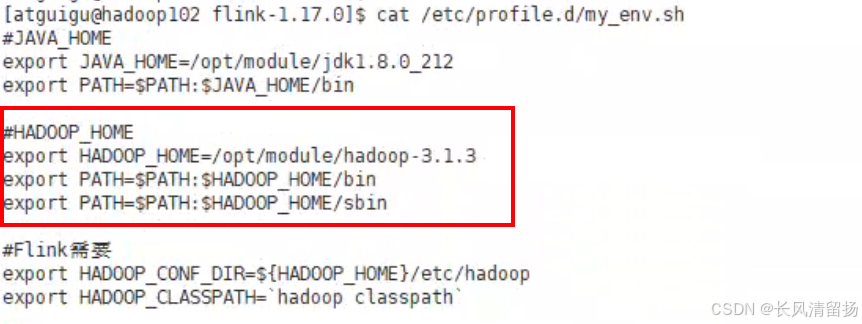
然后再配置flink的配置
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`注意
`hadoop classpath`:这个``反引号在shell中表示执行命令的意思,就是表示执行了hadoop classpath的命令,
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop 这个是Hadoop的配置文件目录
配置完成之后更新一下环境变量
source /etc/profile.d/my_env.sh(2)启动Hadoop集群,包括HDFS和YARN。
在hadoop102上启动hdfs
start-dfs.sh
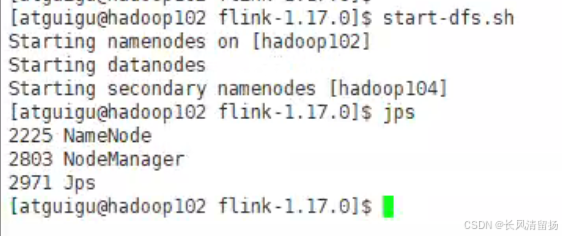
在hadoop103上启动yarn
start-yarn.sh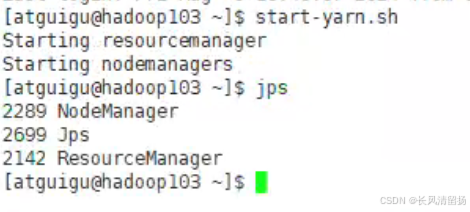
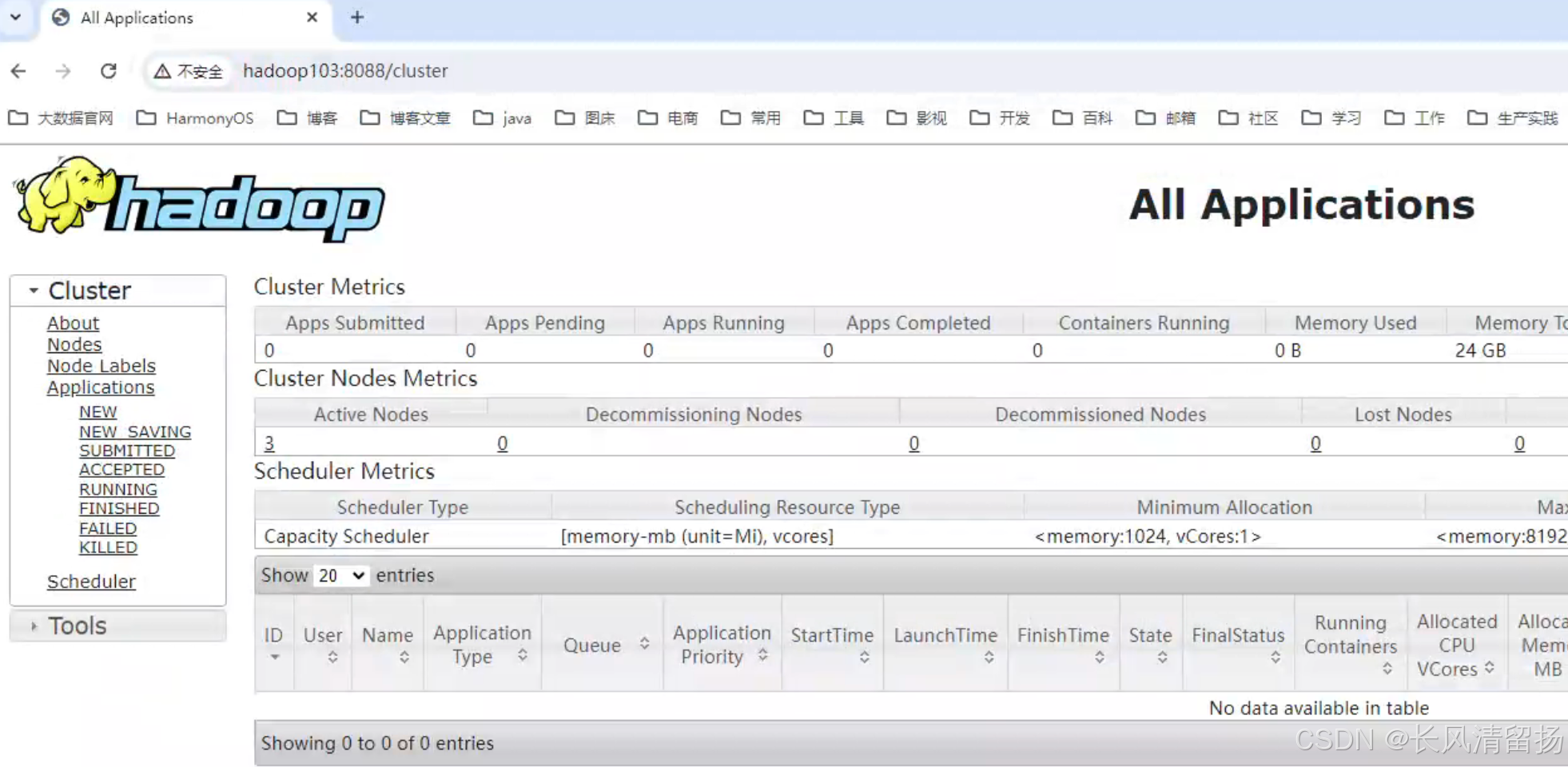
确认一下yarn是否已经启动
在浏览器上输入,hadoop103:8088,下面可以看到yarn已经正常启动了
(3)在hadoop102中执行以下命令启动netcat。
nc -lk 9999
会话模式部署
YARN的会话模式与独立集群略有不同,需要首先申请一个YARN会话(YARN Session)来启动Flink集群。
1)启动集群
(1)启动Hadoop集群(HDFS、YARN)。
在环境准备中已经启动了,在hadoop102上启动了hdfs,在hadoop103上启动了yarn
(2)执行脚本命令向YARN集群申请资源,开启一个YARN会话,启动Flink集群。
在flink的bin目录下可以看到有一个yarn-session.sh脚本,改脚本就表示yarn会话模式
bin/yarn-session.sh -d -nm test参数详解:
- -d:分离模式,如果你不想让Flink YARN客户端一直前台运行,可以使用这个参数,即使关掉当前对话窗口,YARN session也可以后台运行。
- -jm(--jobManagerMemory):配置JobManager所需内存,默认单位MB。
- -nm(--name):配置在YARN UI界面上显示的任务名。
- -qu(--queue):指定YARN队列名。
- -tm(--taskManager):配置每个TaskManager所使用内存。
注意:Flink1.11.0版本不再使用-n参数和-s参数分别指定TaskManager数量和slot数量,YARN会按照需求动态分配TaskManager和slot。所以从这个意义上讲,YARN的会话模式也不会把集群资源固定,同样是动态分配的。
关于参数的解释和都有哪些参数,如果从网上看的话不一定准确,因为不同的Flink版本的参数都是不一样的,最准确的就是直接使用yarn-session.sh脚本查看它的帮助文档,虽然都是英文,但是复制下来去翻译软件上翻译一下就行
./yarn-session.sh -help
(3)注意点和问题点以及报错
在这篇文章中对flink进行了一些配置
2024年最新Flink教程,从基础到就业,大家一起学习--Flink集群部署-CSDN博客
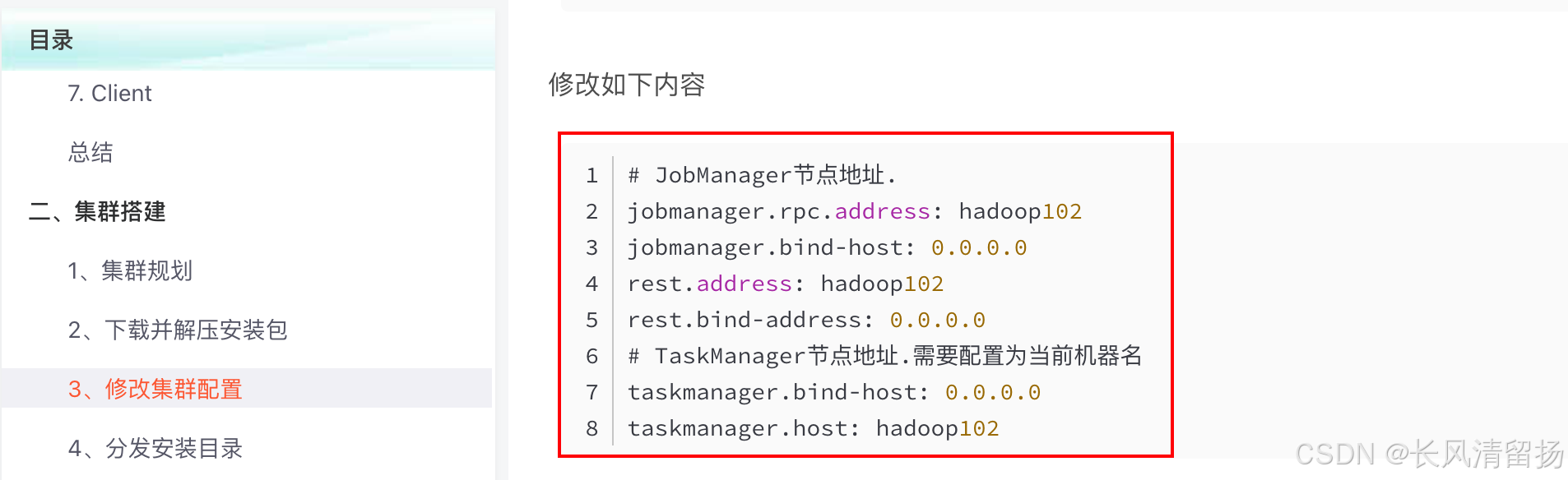
现在我们使用的是flink 1.17版本,如果是yarn模式的话,yarn模式启动这些配置会自动覆盖的,但是在旧版本的Flink中是不能直接指定jobmanager和taskmanager的地址的,不然会出现报错,在Flink 1.17中会自动覆盖这些配置,由yarn来进行管理
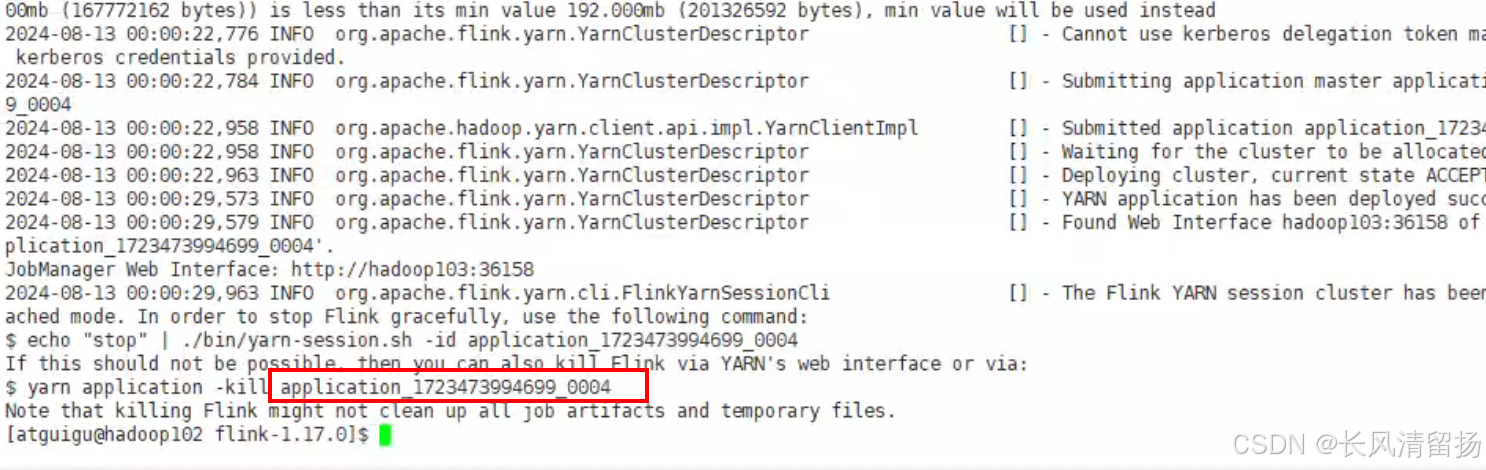
然后在申请会话资源的时候,bin/yarn-session.sh -d -nm test ,我这边出现了报错,报错信息是
File /user/.flink/application_1723473994699_0002b/flink-table-api-java-uber-1.17.0.jar could only be written to 0 of the 1 minReplication nodes. There are 0 datanode(s) running and 0 node(s) are excluded in this operation
意思是找不到DataNode,具体问题已经解决,可以参考我下面的这篇文章
执行start-dfs.sh后,datenode没有启动的最全解决办法(全网最全)-CSDN博客
(4)申请yarn会话资源之后
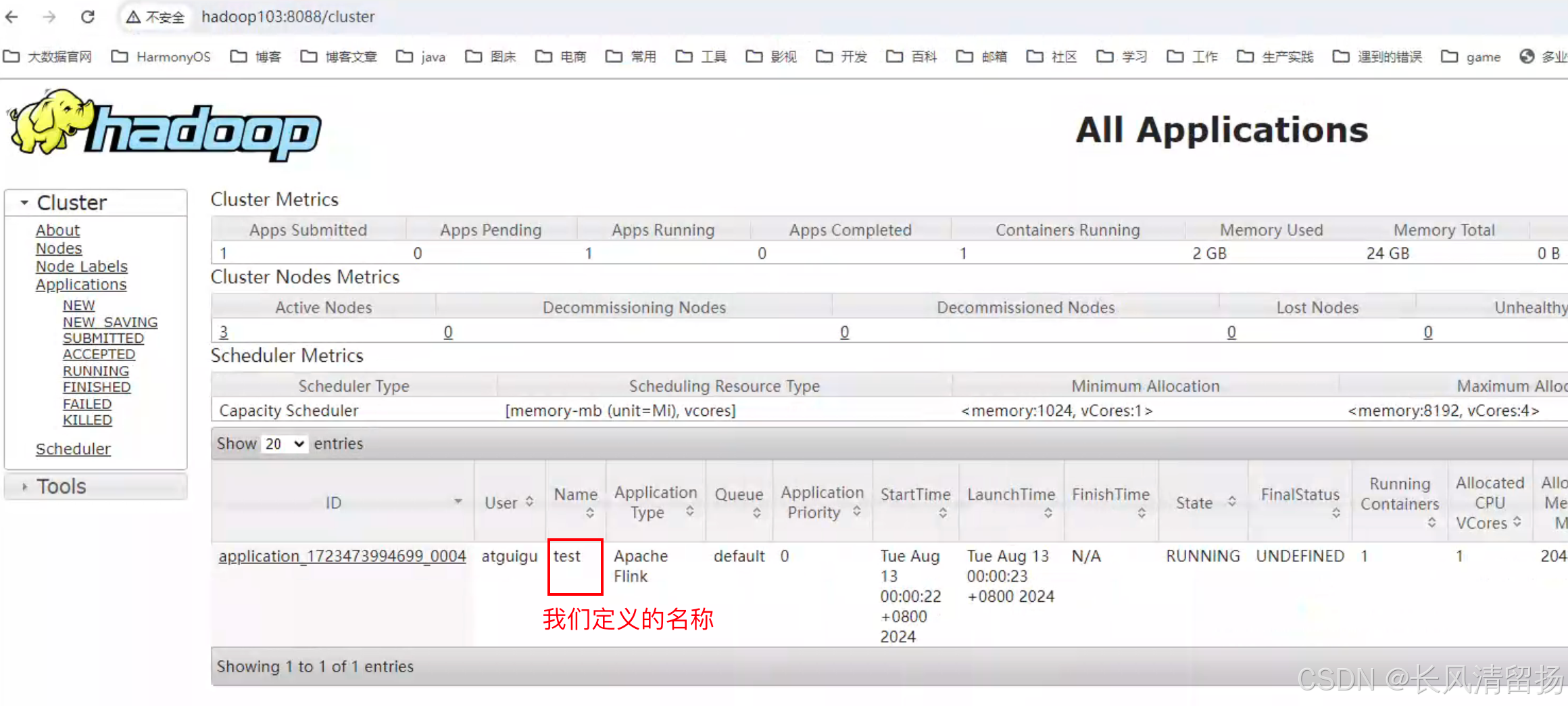
YARN Session启动之后会给出一个Web UI地址以及一个YARN application ID,如下所示,用户可以通过Web UI或者命令行两种方式提交作业。
在yarnUI页面上可以看到刚才启动的会话,test就是我们定义的名称,如果不定义的话,默认就是Flink session cluster
(5)访问Flink Web UI 的两种方式
因为要通过yarn来访问申请的这个yarn会话的FlinkUI
然后可以原来的flink端口已经访问不了了http://hadoop102:8081/ 这个端口已经不能访问了
第一种方式
就是在申请完yarn会话之后,在日志中会给我们提示一个地址,可以直接把这个地址粘贴到浏览器上,但是提供的这个端口是会变了,每次申请的都不一样
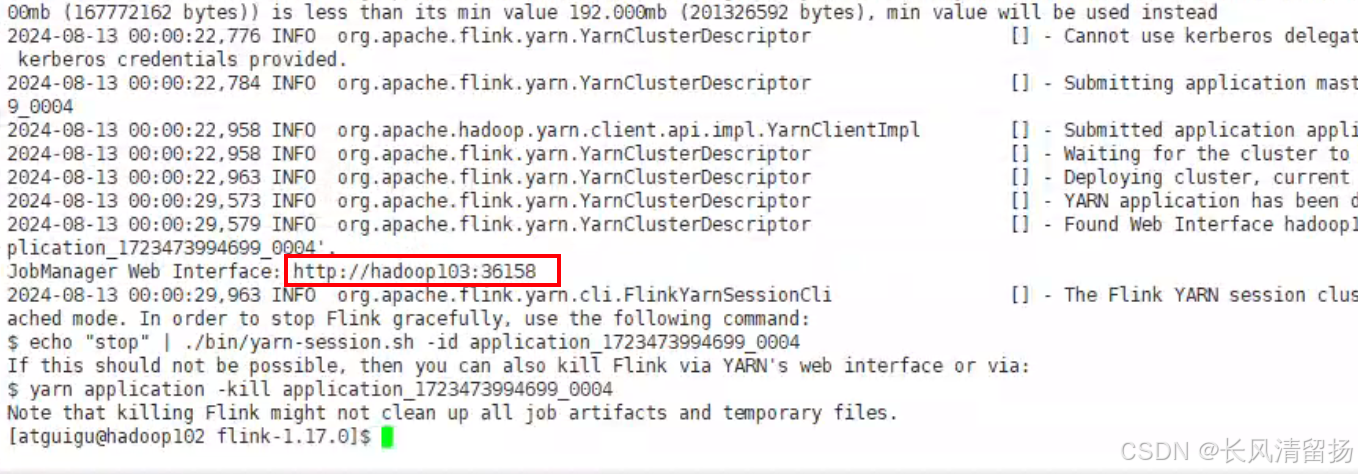
第二种方式
在yarn UI页面上,找到我们申请的会话,然后最右边点击这个按钮就可以了,这种是通过端口8088代理的方式访问的

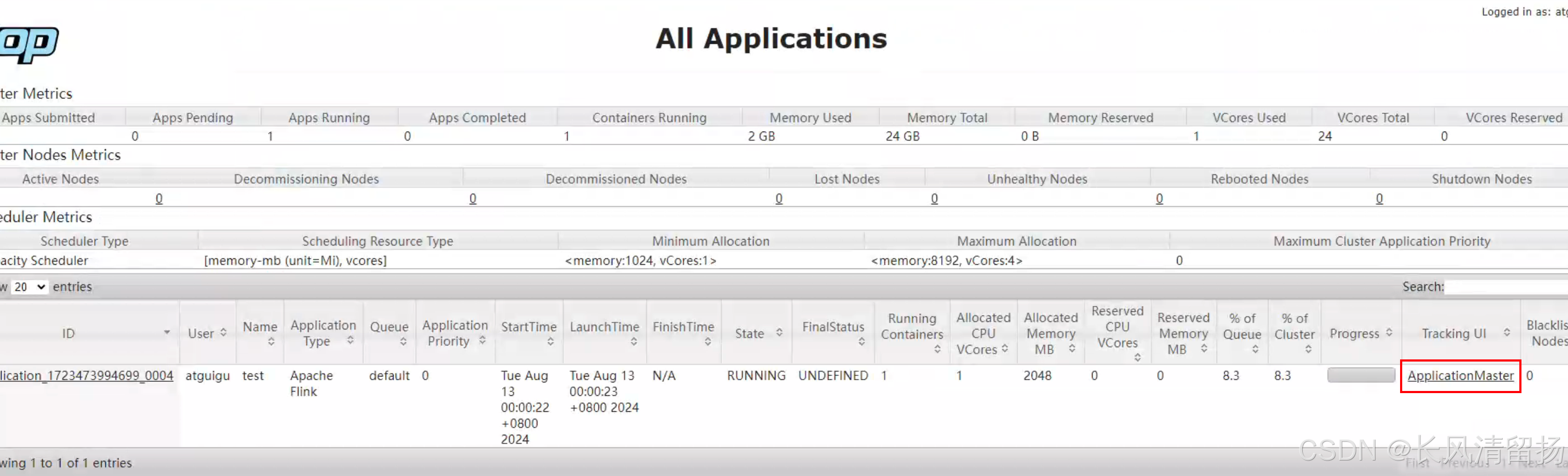
(6)Flink会动态分配资源
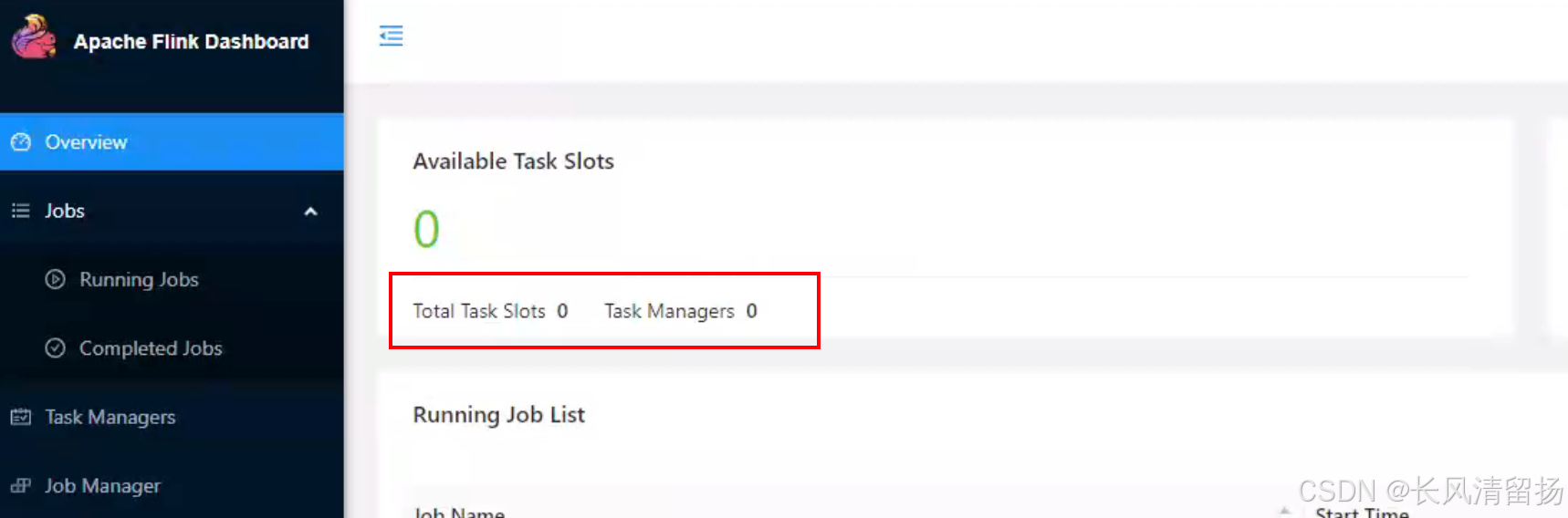
Flink会根据运行在JobManger上的作业所需要的Slot数量动态分配TaskManager资源。
可以看到,现在没有提交作业,没有作业在运行,那么Total Task Slots 和 Task Managers都是0
等到后面提交作业的时候就会根据作业需要的数量自动分配资源
2)提交作业
(1)通过Web UI提交作业
这种方式比较简单,与上文所述Standalone部署模式基本相同。
在点击submit上传的时候,提示说现在是使用代理,不支持上传,但是不要紧的,点击中间蓝色的 here就可以了,点击here就会从代理访问变成具体的IP地址和端口访问
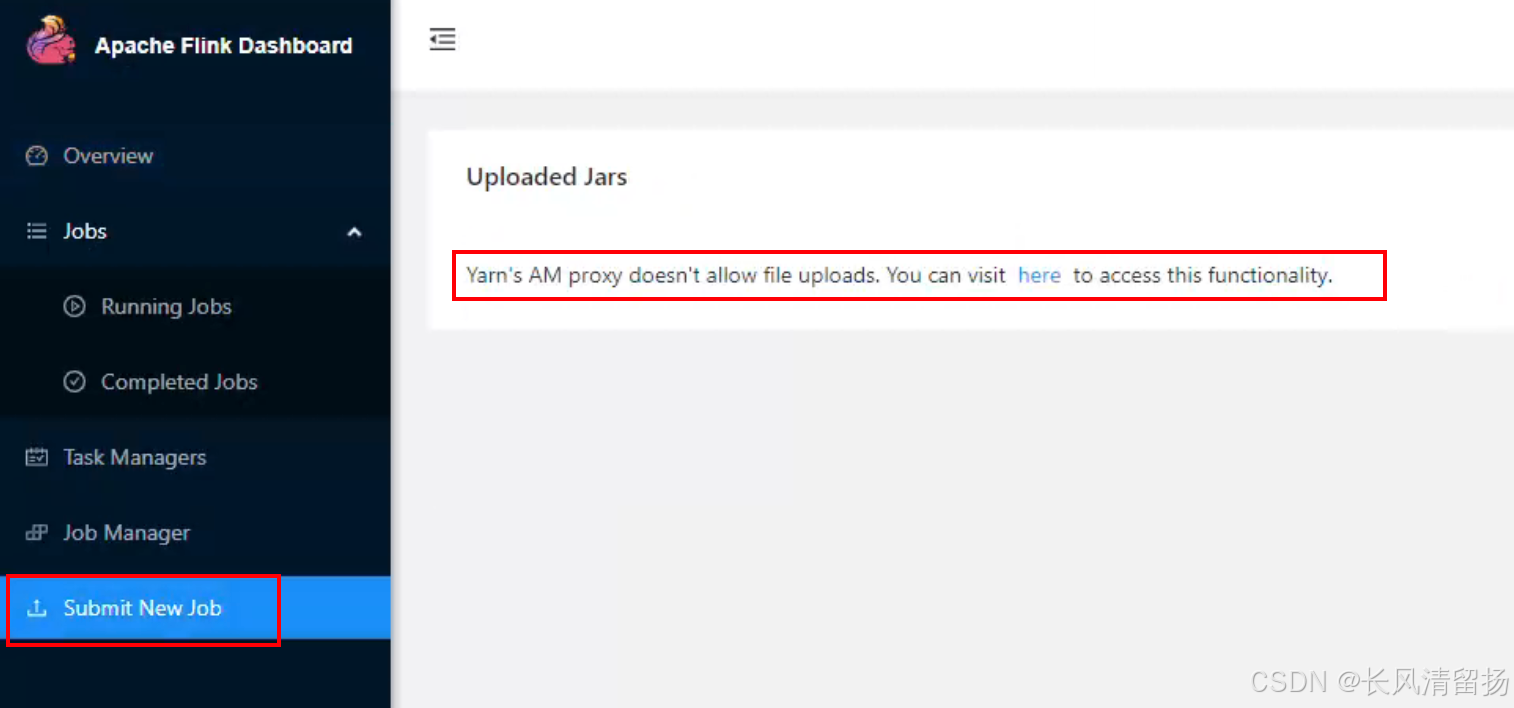
上传jar包
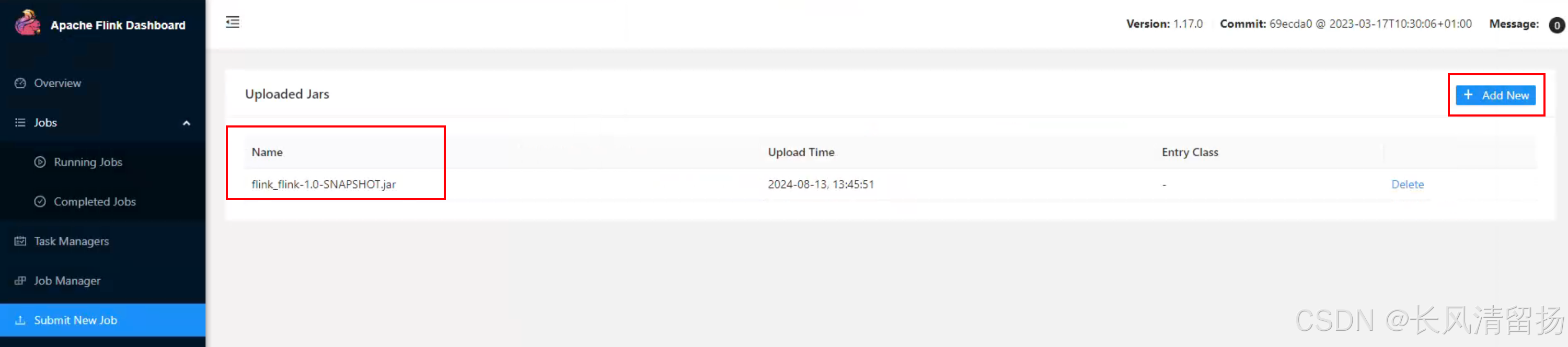
输入全类名和并行度,然后点击提交

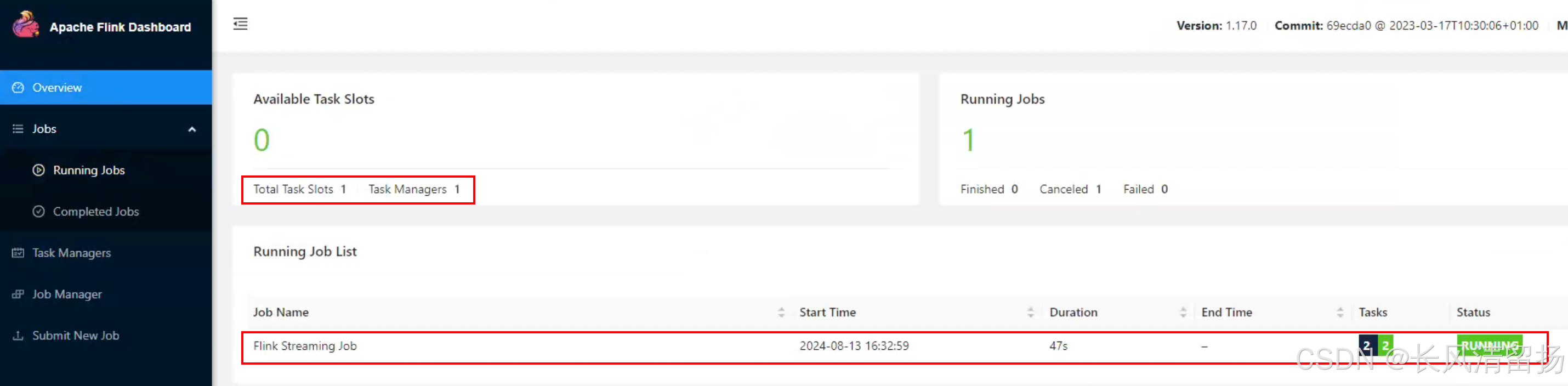
现在可以看到,因为提交了一个任务,yarn自动分配了 Slots 和 Task Managers
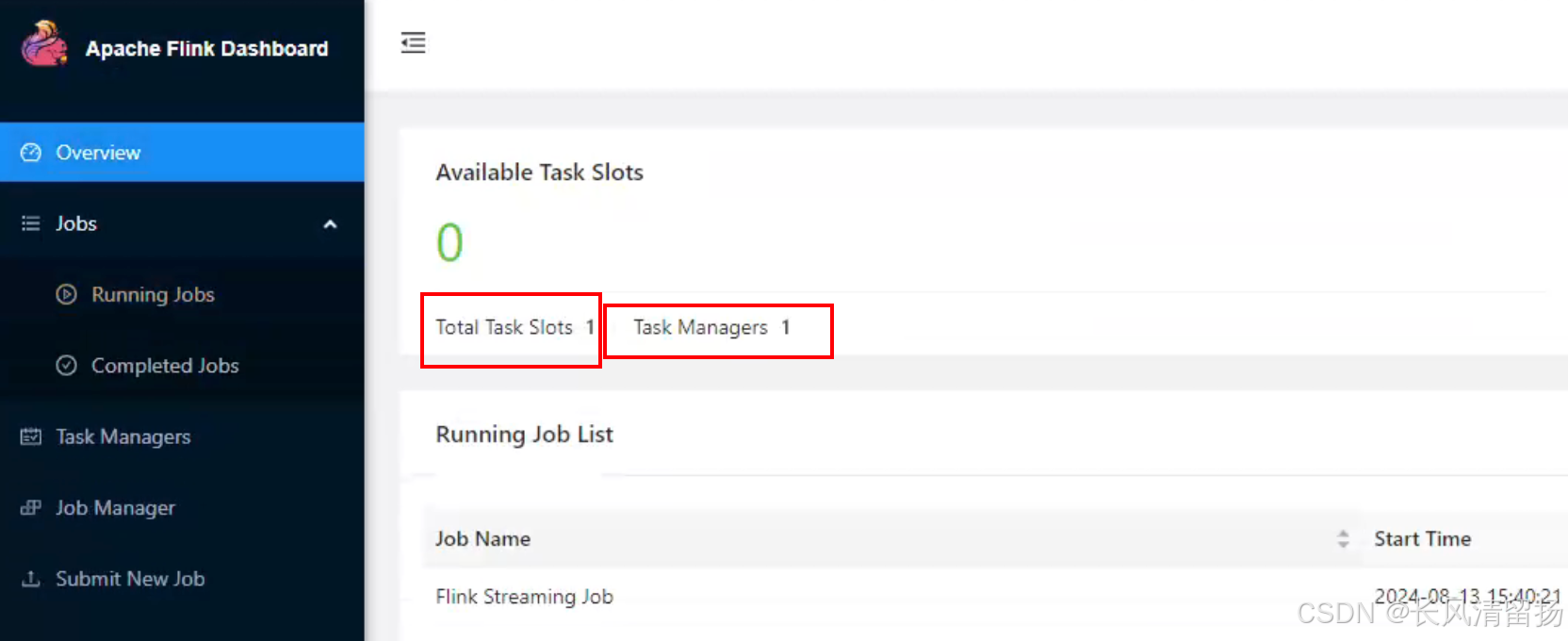
点击查看输入信息
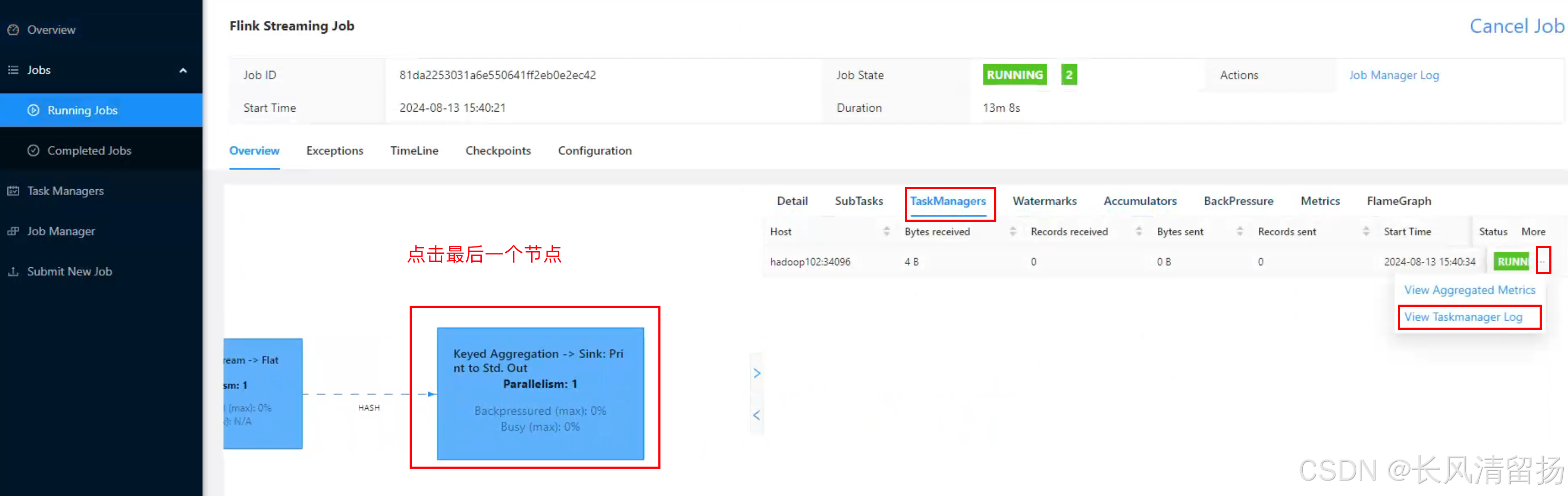
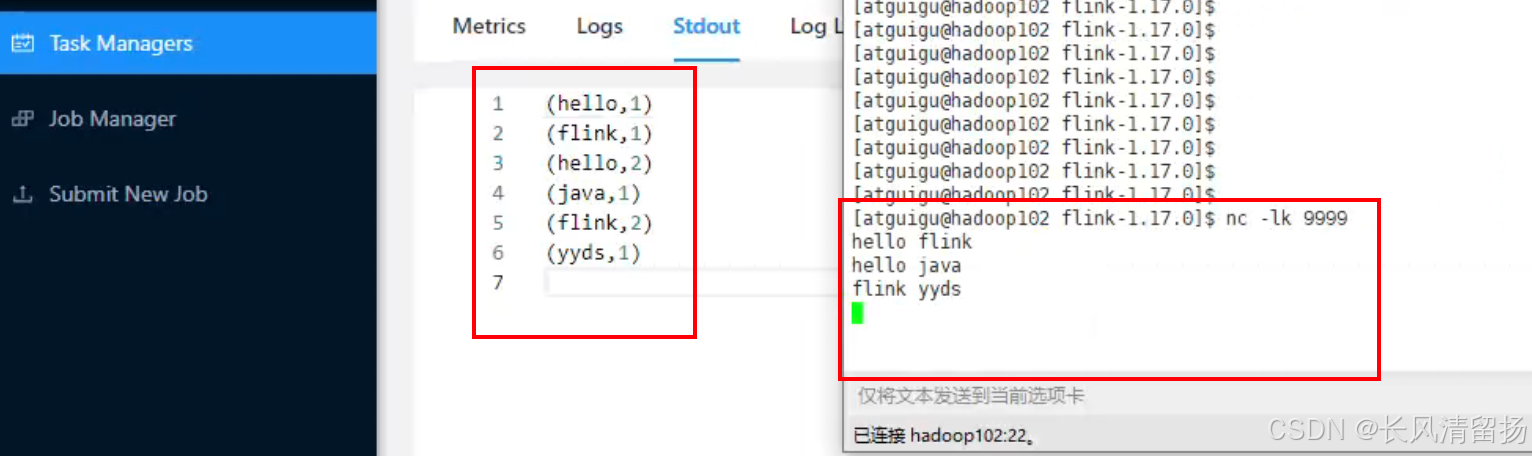
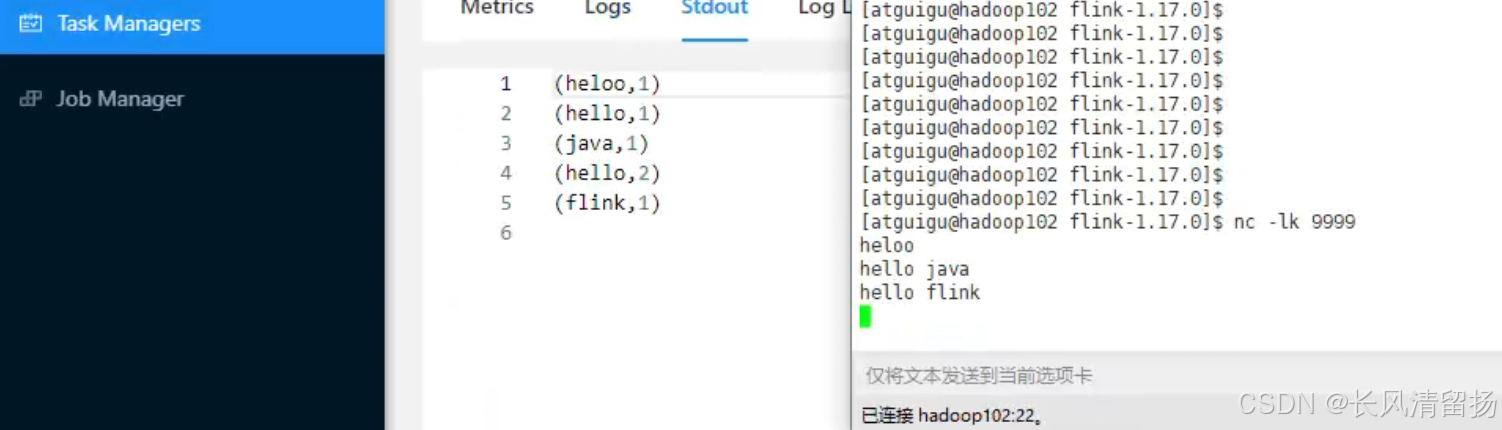
在netcact上输入内容,查看程序输出的信息
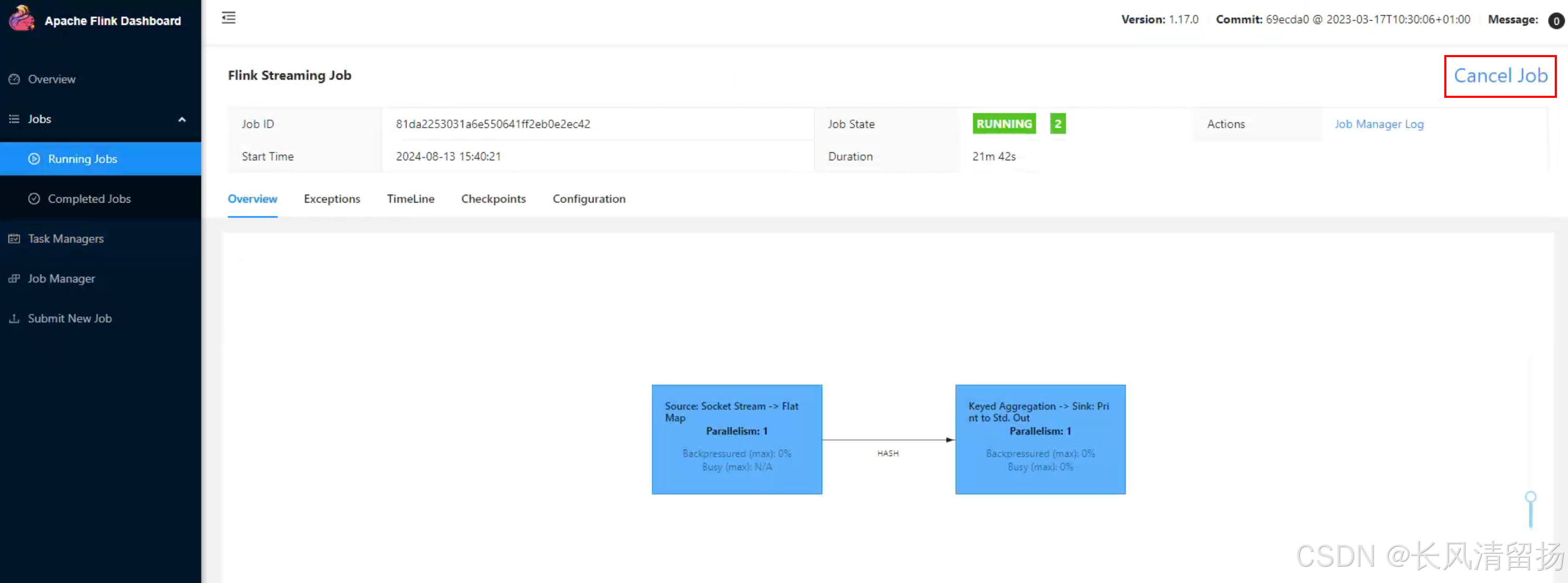
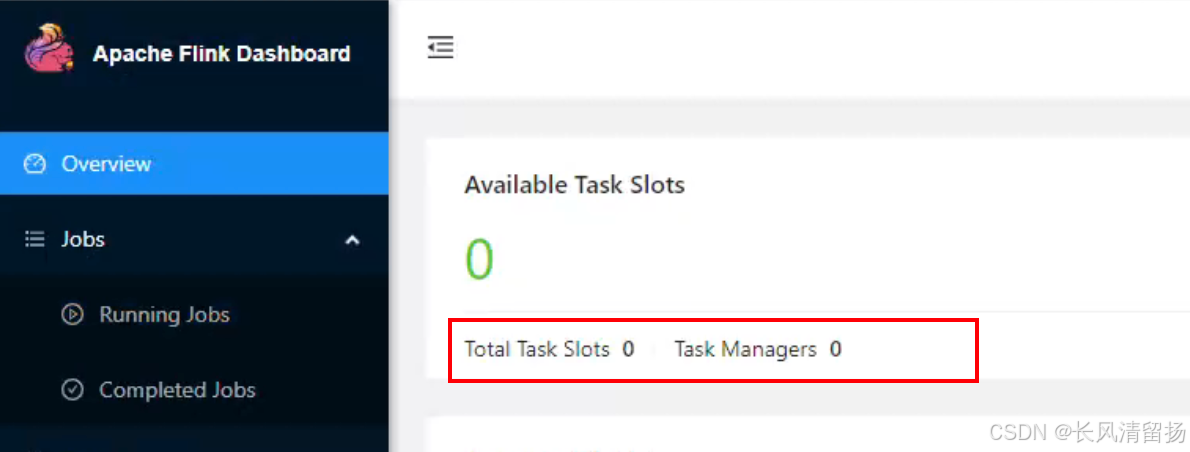
然后结束该任务,并且查看占用的资源是否被回收了,之前启动该flink任务之后,占用了一个Slots 和 一个Task Managers,现在结束任务之后 大约 1-2 分钟之后yarn就会回收资源,将Slots 和 Task Managers进行回收,这个就是yarn的机制,动态分配资源
(2)通过命令行提交作业
① 将FlinkTutorial-1.0-SNAPSHOT.jar任务上传至集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
bin/flink run
-c wordcount.flink_wc_socket flink_flink-1.0-SNAPSHOT.jar之前命令行提交flink程序的时候,需要-m指定要提交到的JobManager,例如hadoop102:8081,但是yarn模式下是不需要手动指定的,yarn会自动指定,如果想手动指定的话,在申请yarn session会话的时候,下面这个就是jobManager的地址,每次申请yarn session的时候,地址都是不一样的
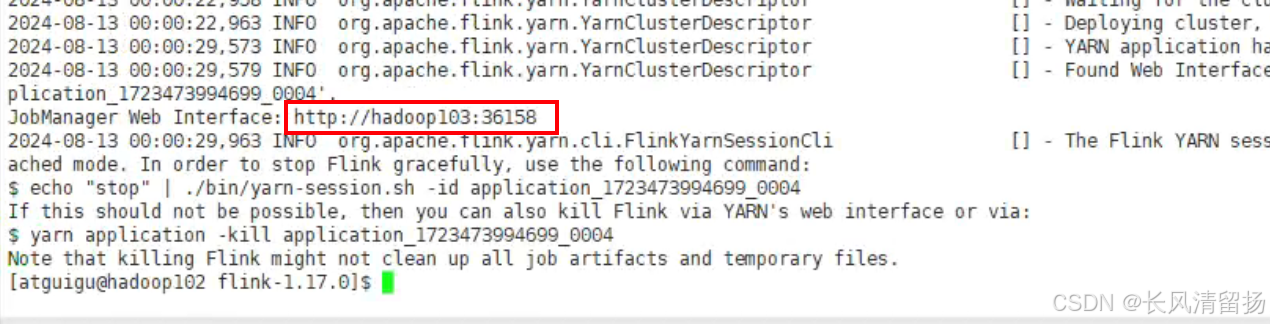
启动flink程序
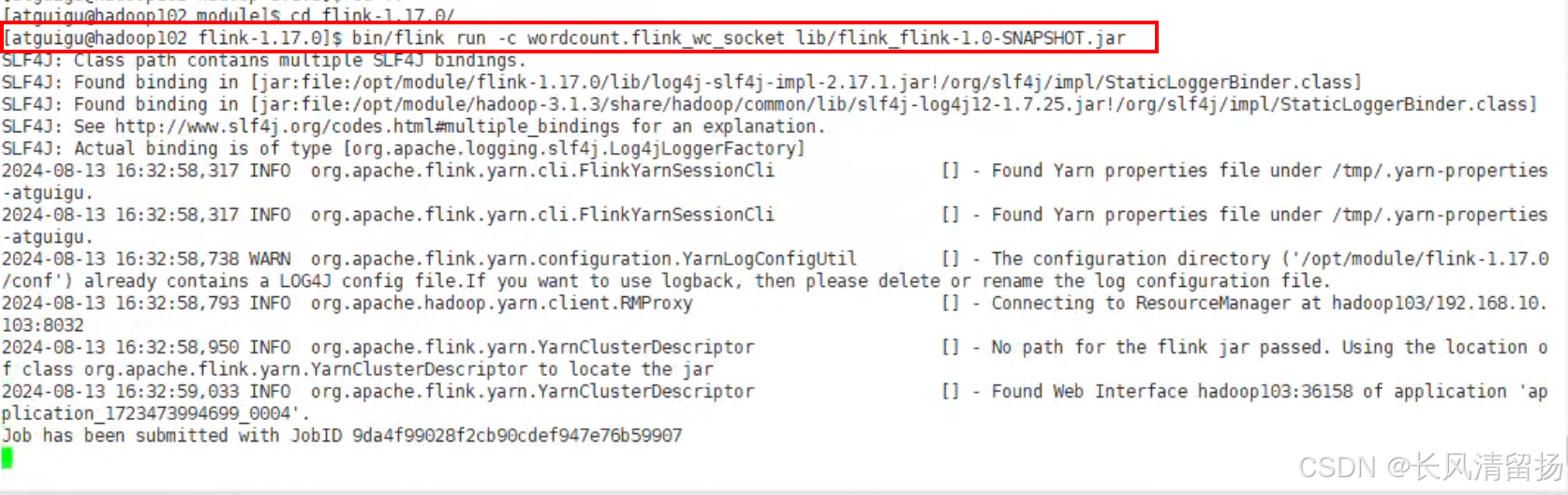
启动之后,这地址的文件就是指定了applicationID所以不需要我们写-m去找JobManager
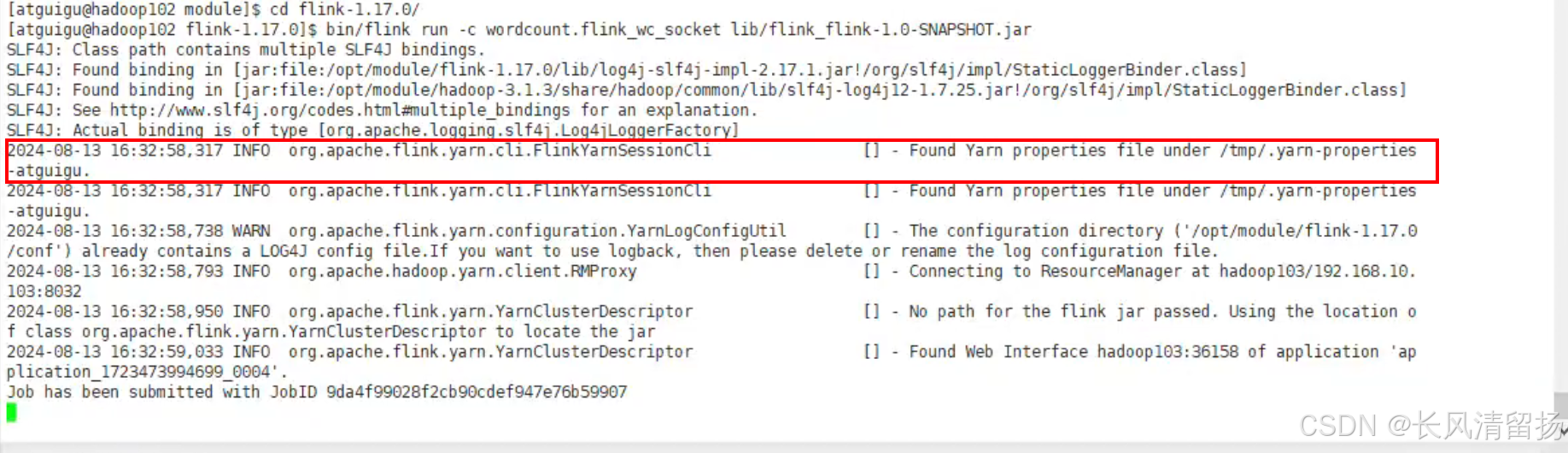
在UI页面上已经可以看到任务了
在netcat上输入内容,查看flink程序的输出信息
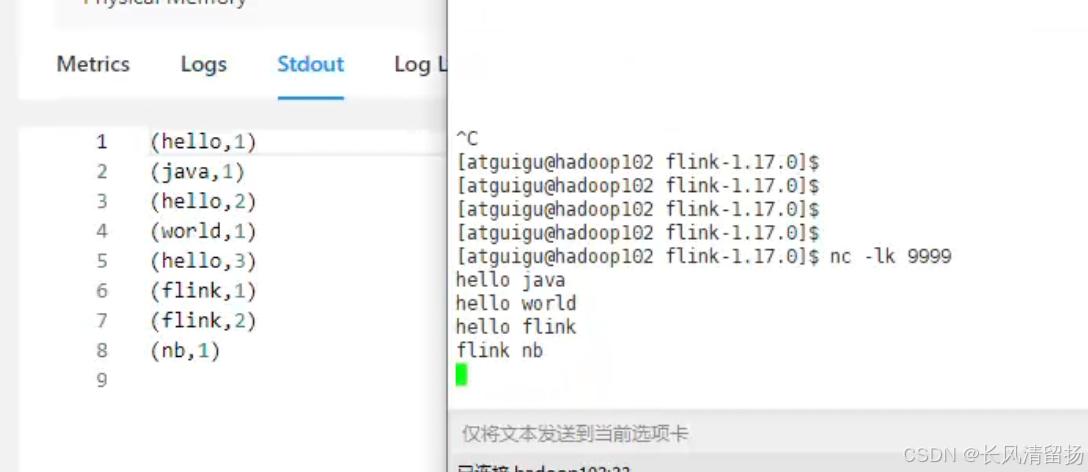
单作业模式部署
在YARN环境中,由于有了外部平台做资源调度,所以我们也可以直接向YARN提交一个单独的作业,从而启动一个Flink集群。相当于提交一个作业就启动一个集群,每一个作业都有一个单独的集群,另外代码解析是由客户端解析
(0)首先停止掉上面的flink程序,以及申请的yarn session会话资源
停止flink程序还是跟上面一样的操作,如何停止申请的yarn session会话资源呢
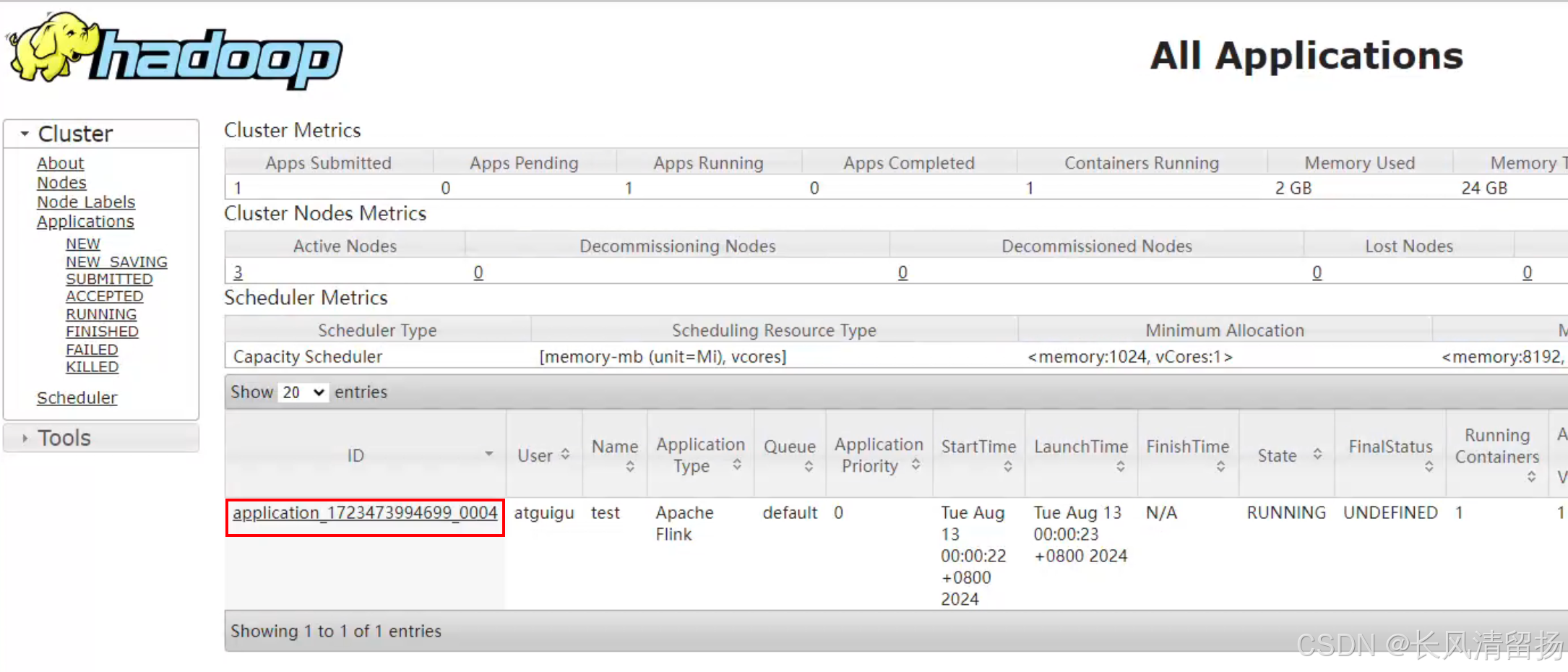
第一种方式
在yarn的UI接上面,hadoop103:8088,点击我们申请的session会话的applicationID
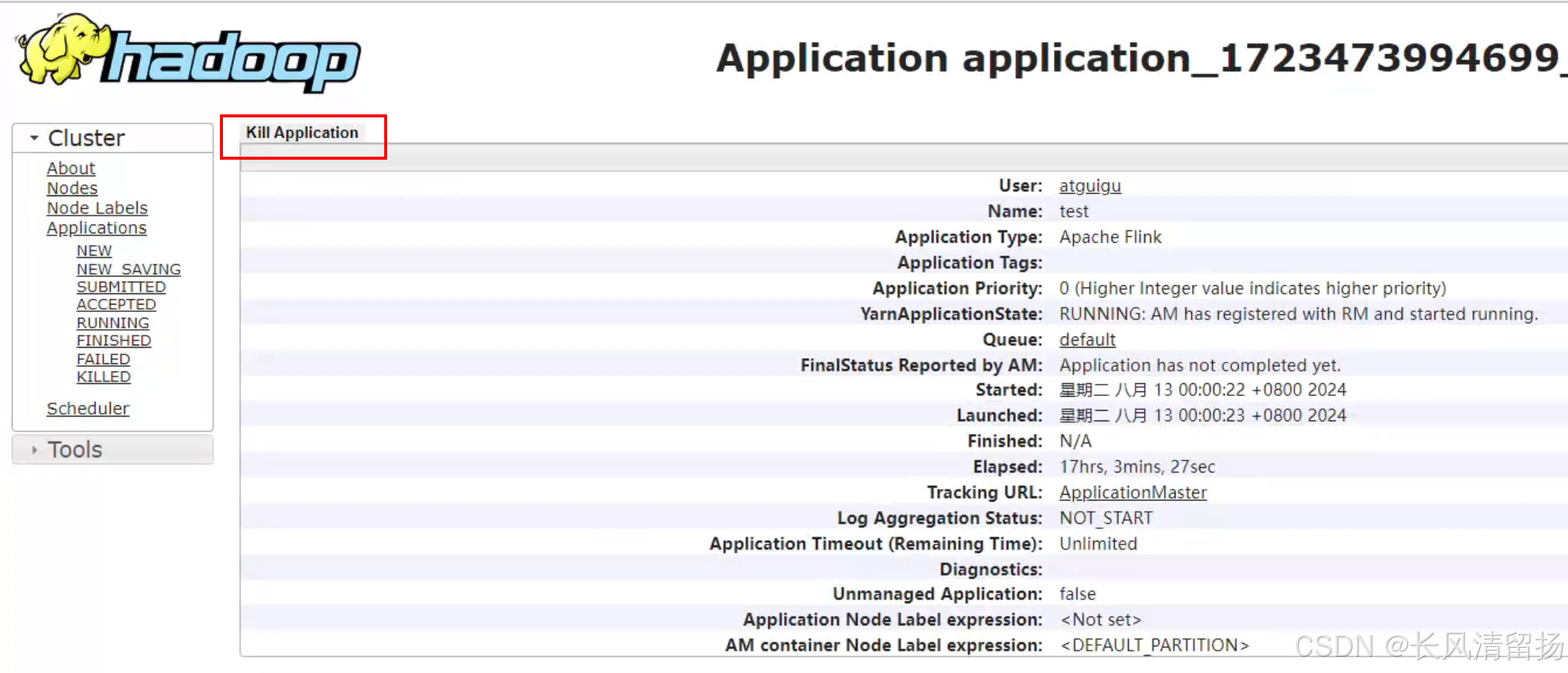
然后点击kill Application就可以了
第二种方式
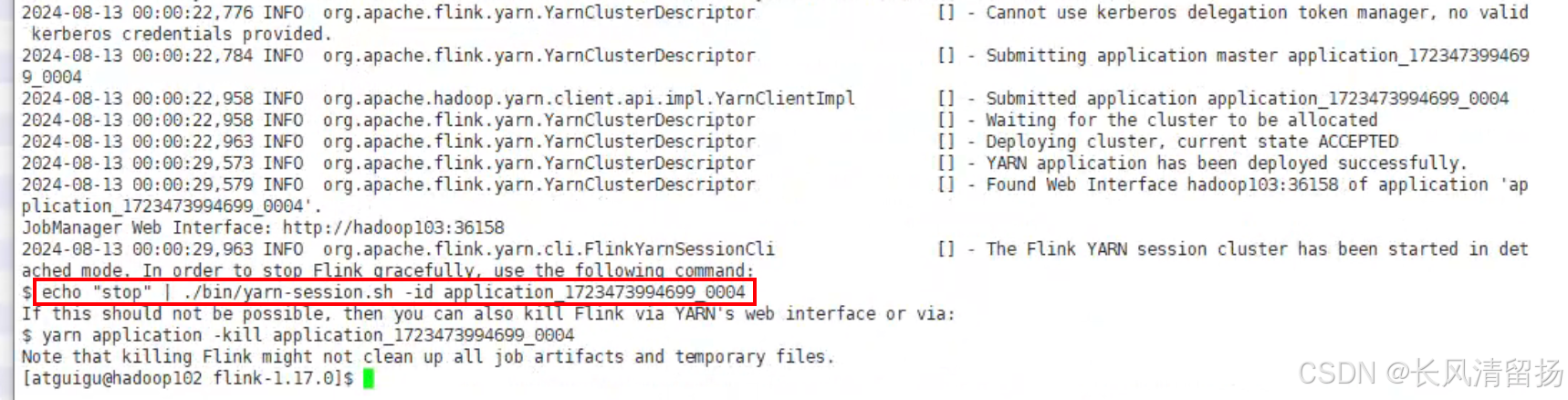
通过在终端上输入命令
我们在申请yarn session会话资源的时候,输入命令bin/yarn-session.sh -d -nm test
然后去看终端上给我们显示出来的日志信息,会提供一段代码,执行这段代码也是可以把申请的yarn session会话资源停止掉的
(1)执行命令提交作业。
bin/flink run -d -t yarn-per-job -c wordcount.flink_wc_socket flink_flink-1.0-SNAPSHOT.jar启动flink程序跟上面的没什么区别,唯一有区别的就是 -t yarn-per-job,意思就是使用yarn-per-job模式,这个是固定的写法,一定要按照这个来写
注意:如果启动过程中报如下异常。
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’.
at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders
这个错误信息来自于 Apache Flink 运行时环境,特别是在处理用户代码类加载器(ClassLoader)时遇到的问题。错误提示 java.lang.IllegalStateException: Trying to access closed classloader 表明有一个已经关闭的类加载器被尝试访问,这通常是因为类加载器被不当地存储或管理。
解决办法:在flink的/opt/module/flink-1.17.0/conf/flink-conf.yaml配置文件中设置
[atguigu@hadoop102 conf]$ vim flink-conf.yaml
classloader.check-leaked-classloader: false- 在 Flink 的配置文件中设置
classloader.check-leaked-classloader为false。但请注意,这只是一个权宜之计,应该尽快找到并修复根本原因。不过就算不管这个报错其实也不影响正常的作业启动,在yarnUI页面还是可以看到启动了一个任务
注意:如果在启动的时候,在控制台一直循环出现这个信息
Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster
那么很有可能是因为yarn资源不足,如果当前yarn任务中有已经启动了的任务,那么就先全部关闭,然后再启动,或者重新再配置文件里面设置yarn的资源
启动成功
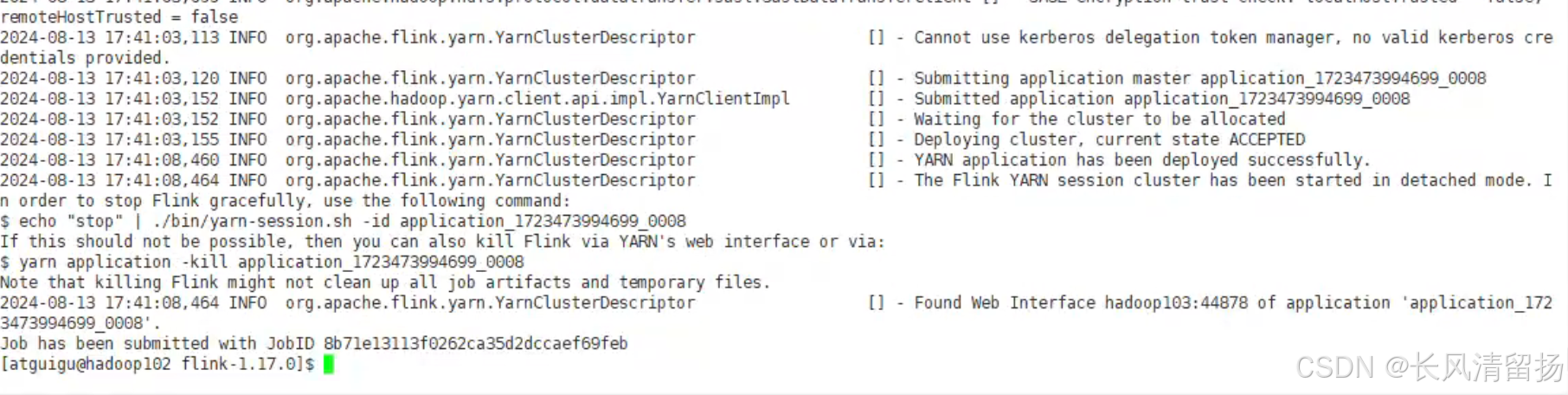
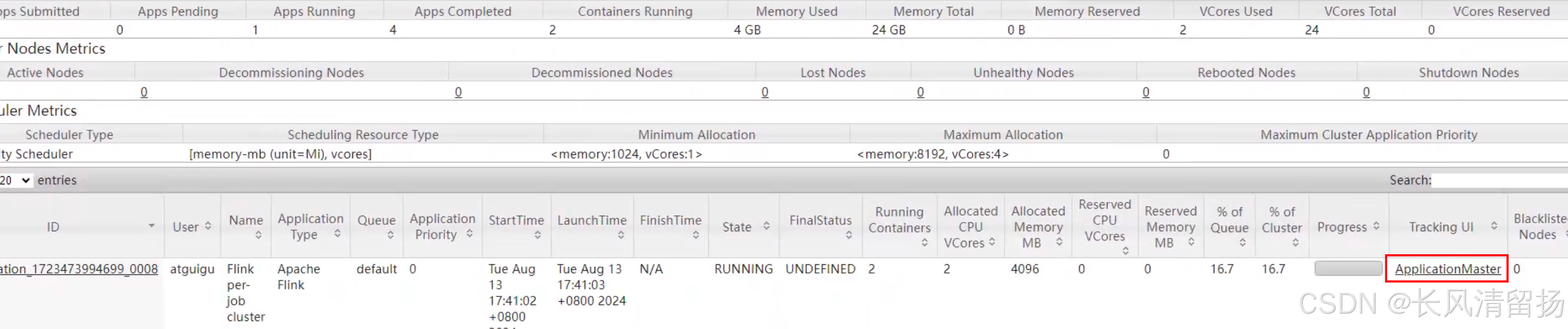
(2)在YARN的ResourceManager界面查看执行情况。
在netcat上输入内容,然后查看输出
(3)可以使用命令行查看或取消作业,命令如下。
[atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-per-job -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_XXXX_YY <jobId>这里的application_XXXX_YY是当前应用的ID,<jobId>是作业的ID。注意如果取消作业,整个Flink集群也会停掉。
查看任务的applicationID
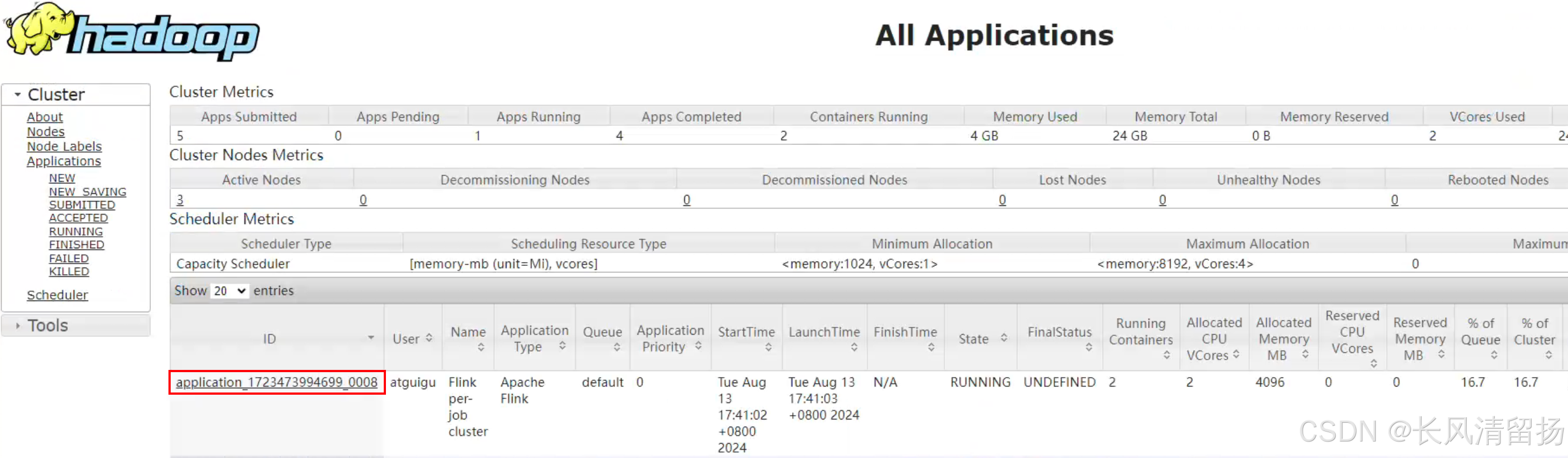
通过applicationID查询任务的jobID
bin/flink list -t yarn-per-job -Dyarn.application.id=application_1723473994699_0008-t表示我们指定的模式是 yarn-per-job
-D表示指定applicationID
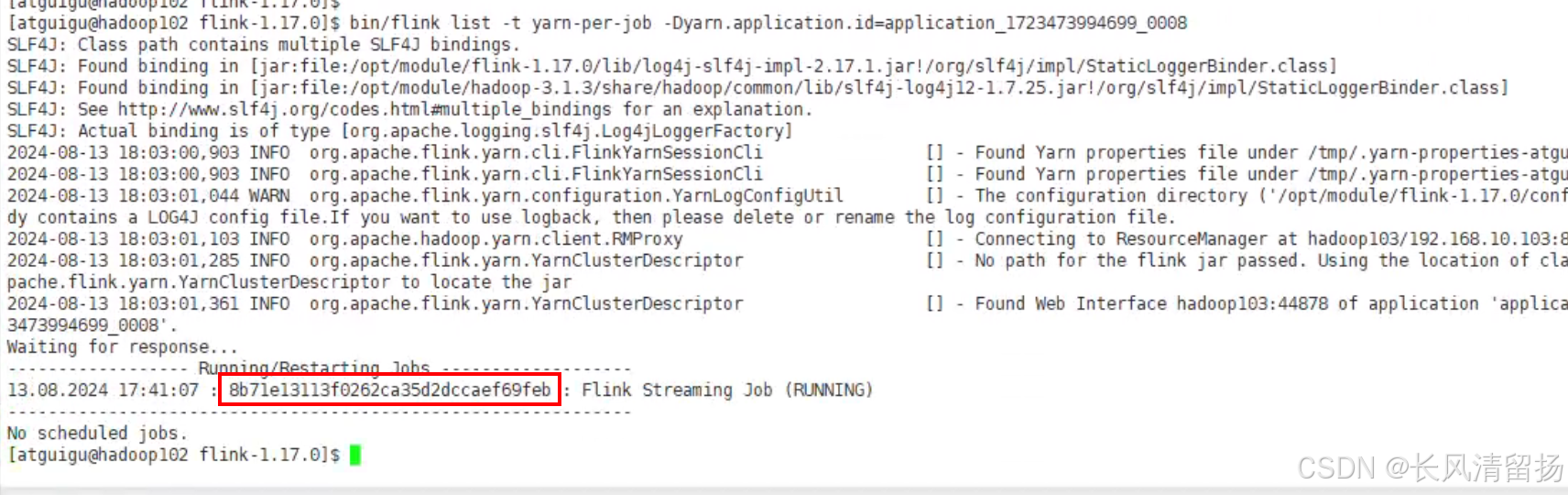
可以看到能够查询到正在运行的一个任务,红框里面的就是这个任务的jobID
通过applicationID和jobID停止任务
bin/flink cancel -t yarn-per-job -Dyarn.application.id=application_1723473994699_0008 8b71e13113f0262ca35d2dccaef69feb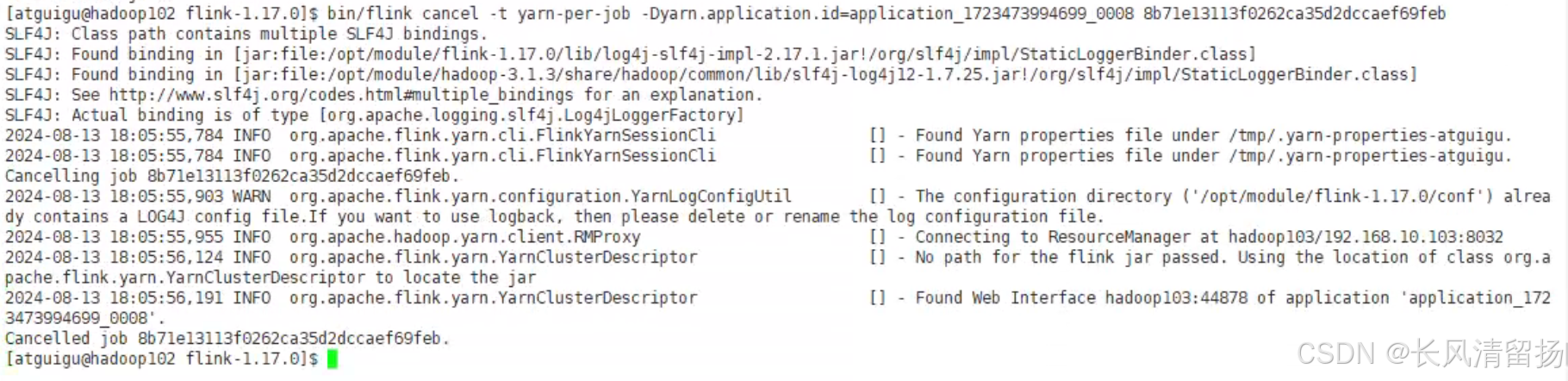

不过也可以在flinkUI页面停止flink程序,单作业模式的特点就是,程序停止之后集群也会关闭,资源会被回收掉
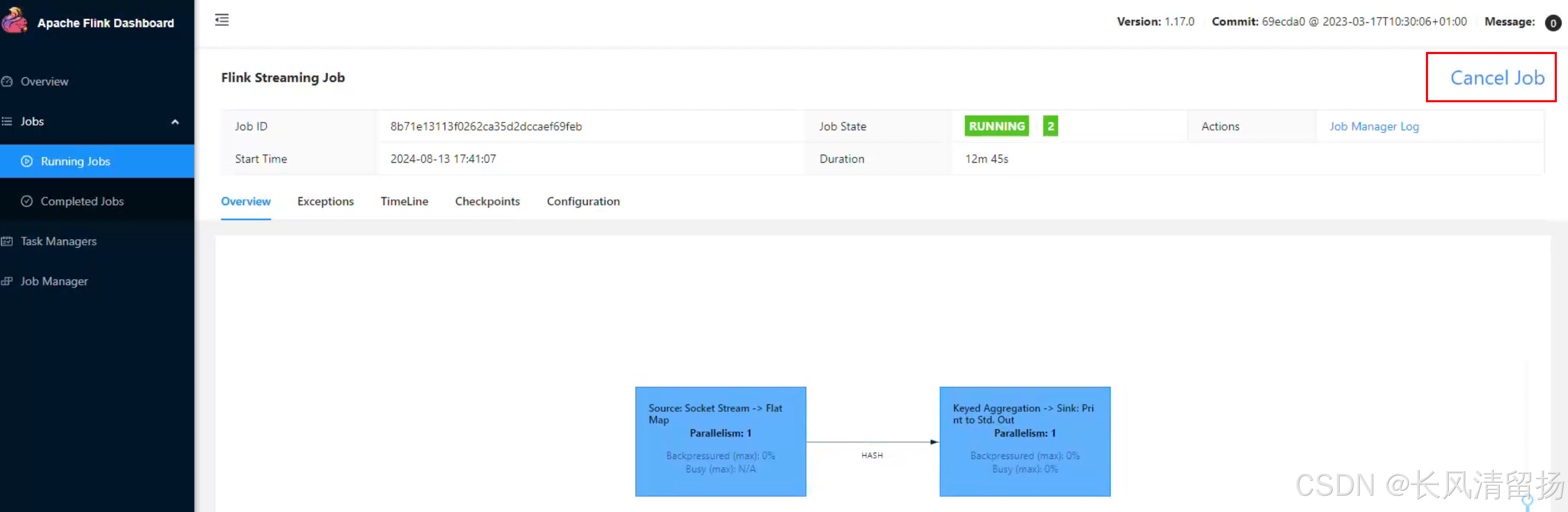
应用模式部署(实际场景中推荐使用)
应用模式(application模式,在flink1.1之后才有的)同样非常简单,与单作业模式类似,直接执行flink run-application命令即可。
推荐使用这种方式,用户的代码是在jobmanager解析的,而不是在客户端解析的
1)命令行提交
(1)执行命令提交作业。
bin/flink run-application -t yarn-application -c wordcount.flink_wc_socket flink_flink-1.0-SNAPSHOT.jar以前都是run 现在是run-application
之前-t 指定的是yarn-per-job 模式,现在是yarn-application模式
(2)执行成功
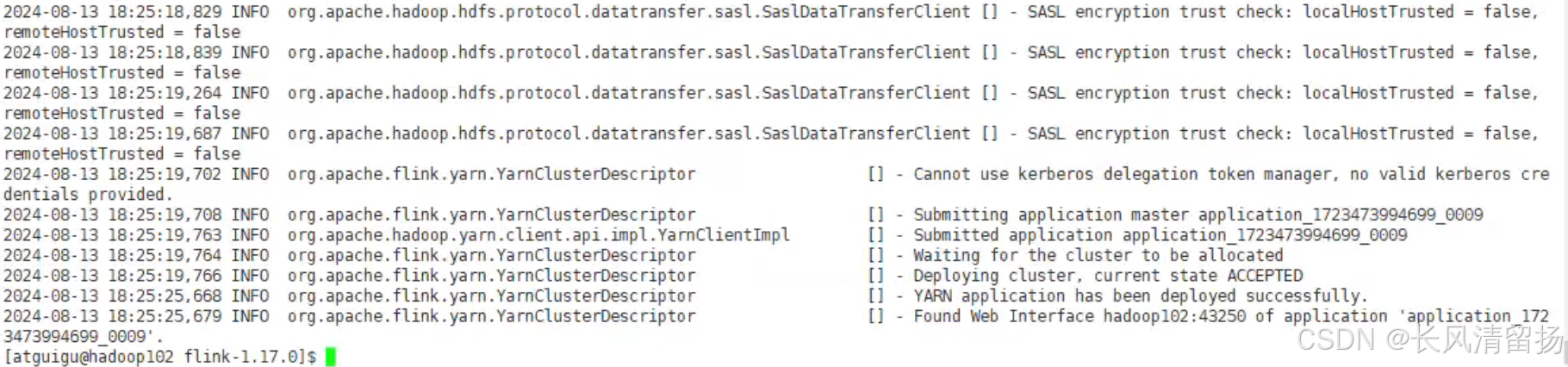
在yarn UI上查看作业,并且在netcat上输入内容并查看flink输出
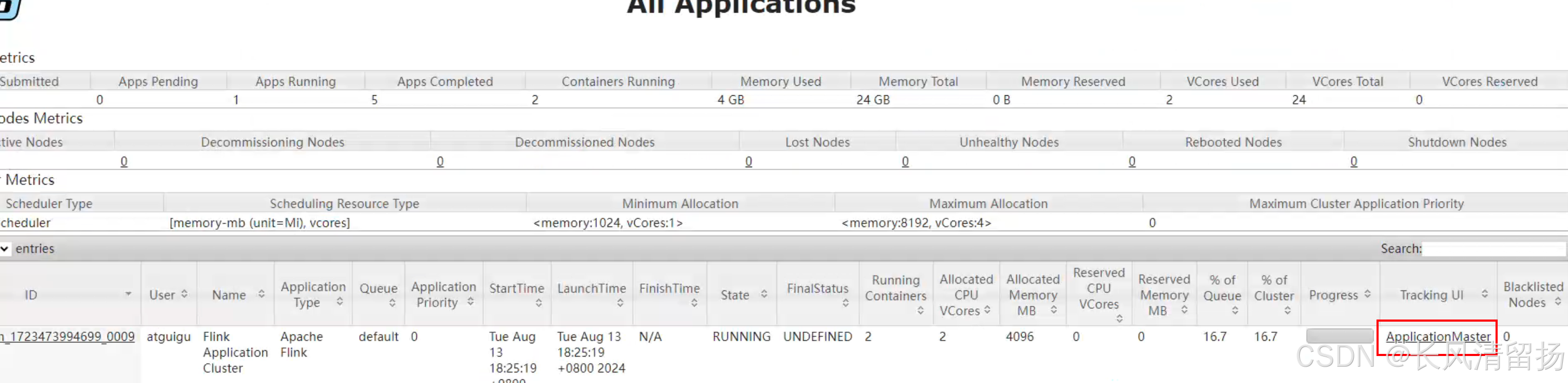

(3)在命令行中查看或取消作业。
atguigu@hadoop102 flink-1.17.0]$ bin/flink list -t yarn-application -Dyarn.application.id=application_XXXX_YY
[atguigu@hadoop102 flink-1.17.0]$ bin/flink cancel -t yarn-application -Dyarn.application.id=application_XXXX_YY <jobId>获取任务的applicationID
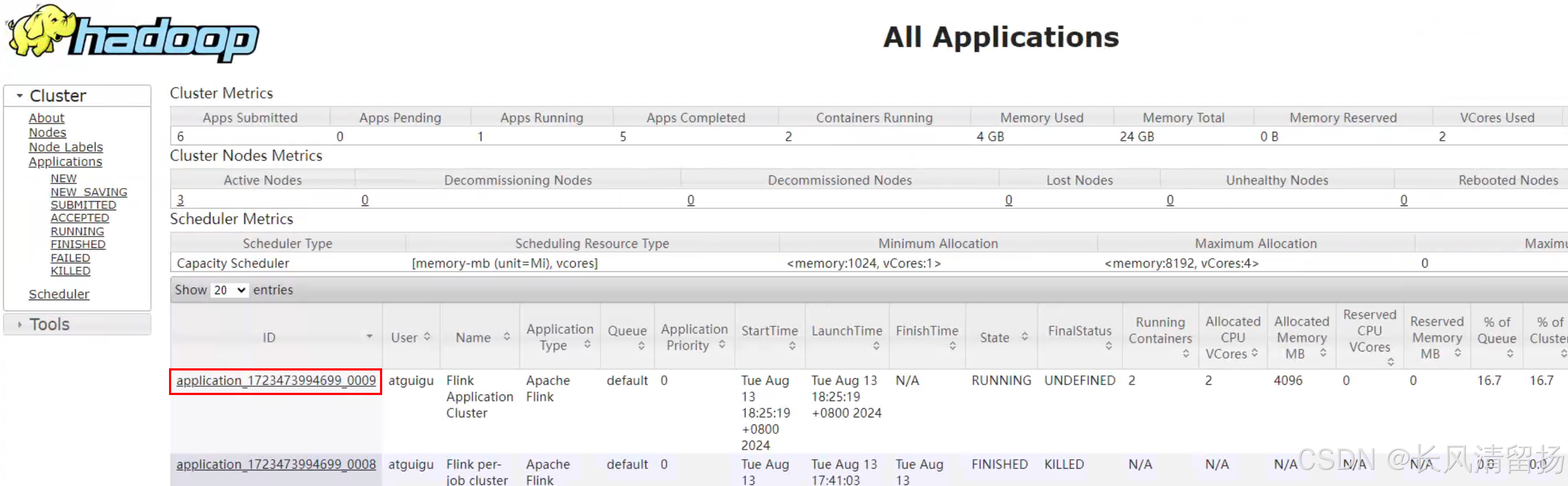
根据applicationID执行命令,获取正在执行的任务以及任务的jobID
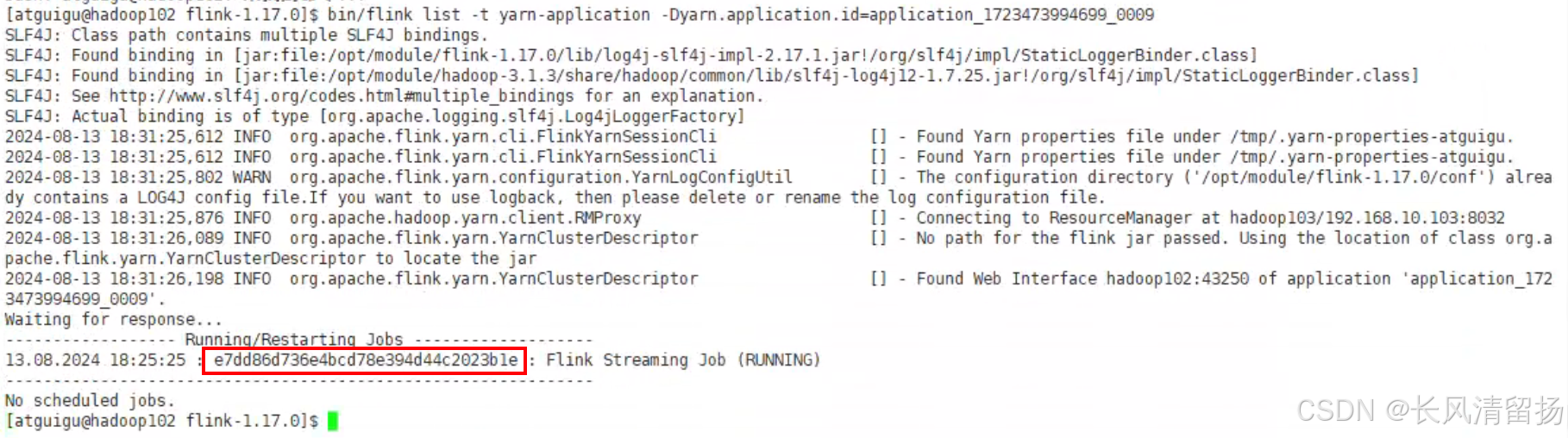
bin/flink list -t yarn-application -Dyarn.application.id=application_1723473994699_0009查看到正在执行的一个任务,红框中的就是这个任务的jobID
根据applicationID和jobID停止任务
bin/flink cancel -t yarn-application -Dyarn.application.id=application_1723473994699_0009 e7dd86d736e4bcd78e394d44c2023b1e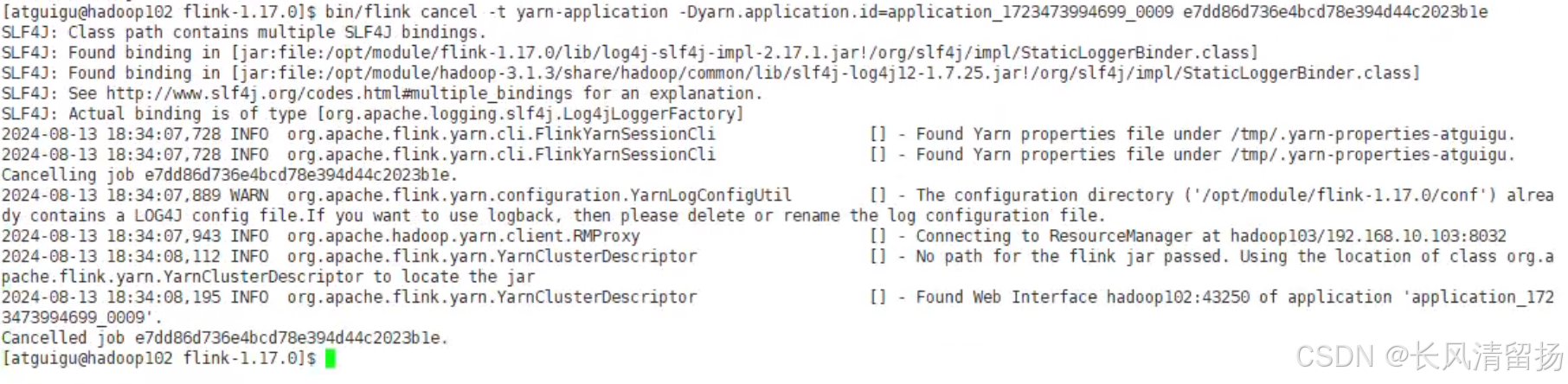

2)上传HDFS提交
可以通过yarn.provided.lib.dirs配置选项指定位置,将flink的依赖上传到远程。
(0)在hdfs中创建一个文件夹
hadoop fs -mkdir /flink_test
(1)上传flink的lib和plugins到HDFS上
就是把flink自身的相关依赖上传到HDFS上
hadoop fs -put lib/ /flink_test
hadoop fs -put plugins/ /flink_test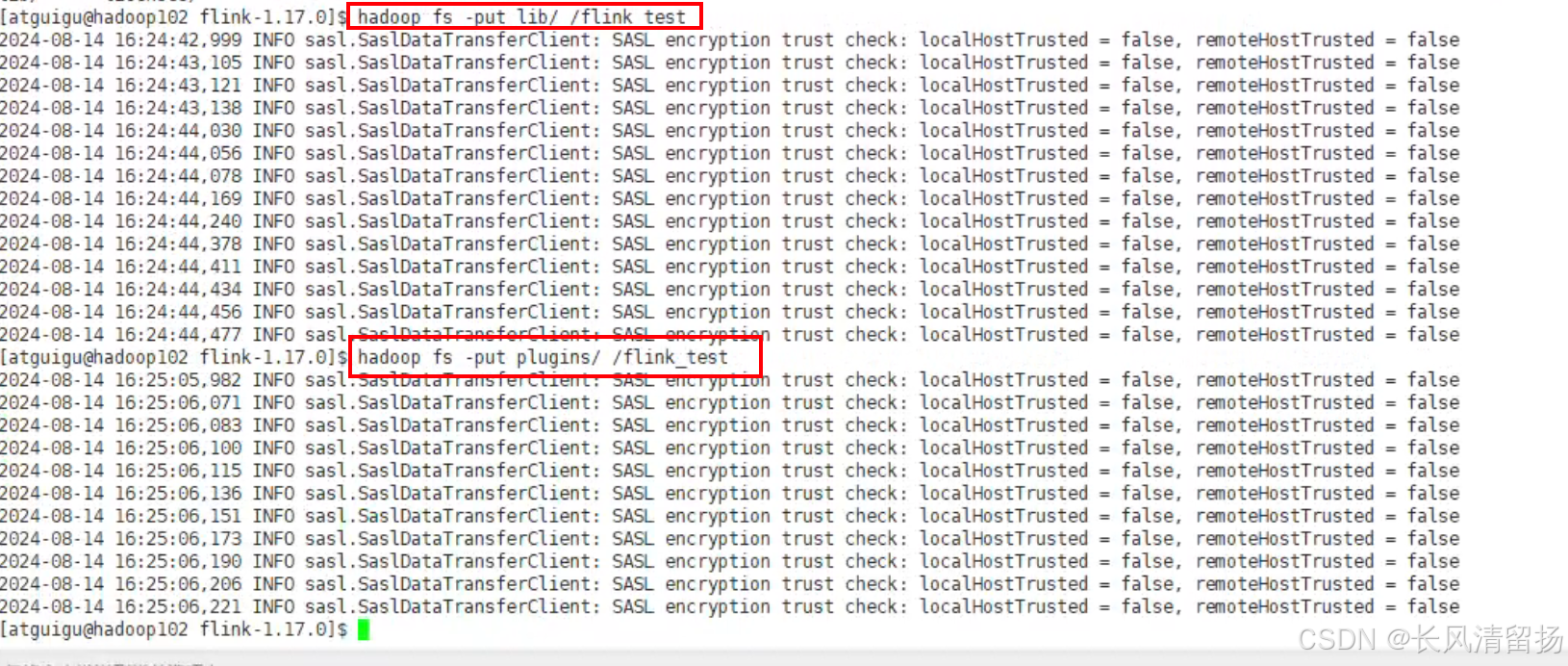
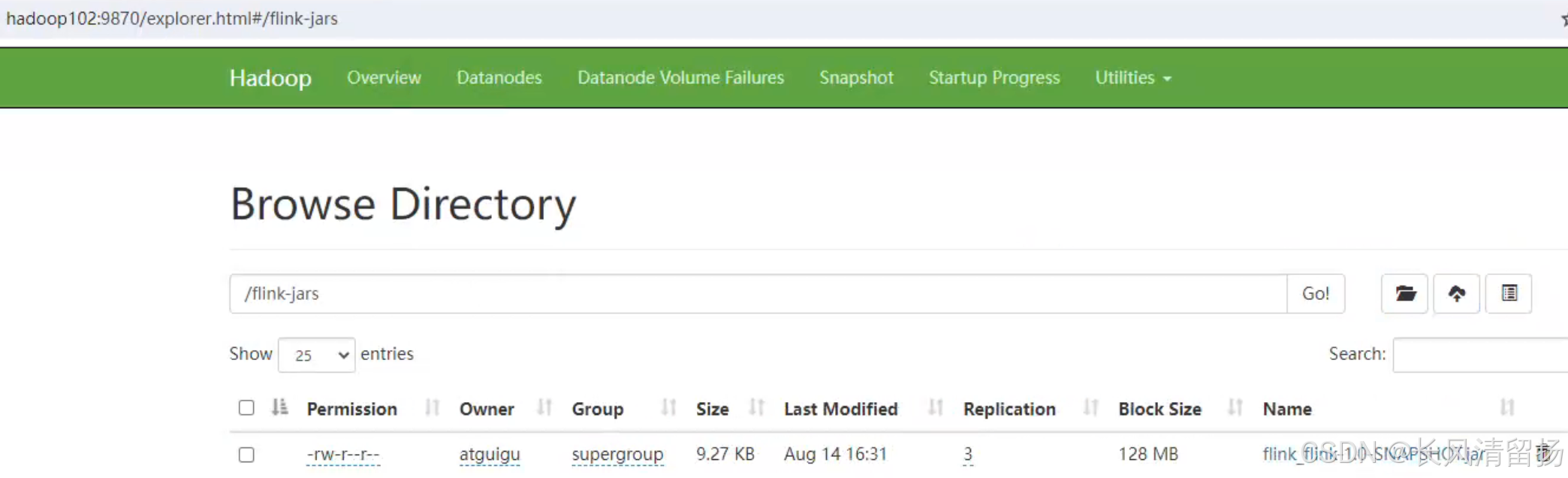
(2)上传自己的jar包到HDFS
在HDFS上创建一个目录用来存放jar包
hadoop fs -mkdir /flink-jars将flink jar包上传到flink-jars目录中
hadoop fs -put flink_flink-1.0-SNAPSHOT.jar /flink-jars
(3)提交作业
bin/flink run-application -t yarn-application -Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink_test" -c wordcount.flink_wc_socket hdfs://hadoop102:8020/flink-jars/flink_flink-1.0-SNAPSHOT.jar-Dyarn.provided.lib.dirs="hdfs://hadoop102:8020/flink_test" 绑定flink的自身依赖
-c wordcount.flink_wc_socket flink程序入口的全类名
最后指定一下jar包路径
这种方式下,flink本身的依赖和用户jar可以预先上传到HDFS,而不需要单独发送到集群,这就使得作业提交更加轻量了。

四、K8S 运行模式(了解)
容器化部署是如今业界流行的一项技术,基于Docker镜像运行能够让用户更加方便地对应用进行管理和运维。容器管理工具中最为流行的就是Kubernetes(k8s),而Flink也在最近的版本中支持了k8s部署模式。基本原理与YARN是类似的,具体配置可以参见官网说明,
五、历史服务器
运行 Flink job 的集群一旦停止(例如yarn模式,程序一旦停止,集群也就关闭了),只能去 yarn 或本地磁盘上查看日志,不再可以查看作业挂掉之前的运行的 Web UI,很难清楚知道作业在挂的那一刻到底发生了什么。如果我们还没有 Metrics 监控的话,那么完全就只能通过日志去分析和定位问题了,所以如果能还原之前的 Web UI,我们可以通过 UI 发现和定位一些问题。
Flink提供了历史服务器,用来在相应的 Flink 集群关闭后查询已完成作业的统计信息。我们都知道只有当作业处于运行中的状态,才能够查看到相关的WebUI统计信息。通过 History Server 我们才能查询这些已完成作业的统计信息,无论是正常退出还是异常退出。
此外,它对外提供了 REST API,它接受 HTTP 请求并使用 JSON 数据进行响应。Flink 任务停止后,JobManager 会将已经完成任务的统计信息进行存档,History Server 进程则在任务停止后可以对任务统计信息进行查询。比如:最后一次的 Checkpoint、任务运行时的相关配置。
1)创建存储目录
hadoop fs -mkdir -p /logs/flink-job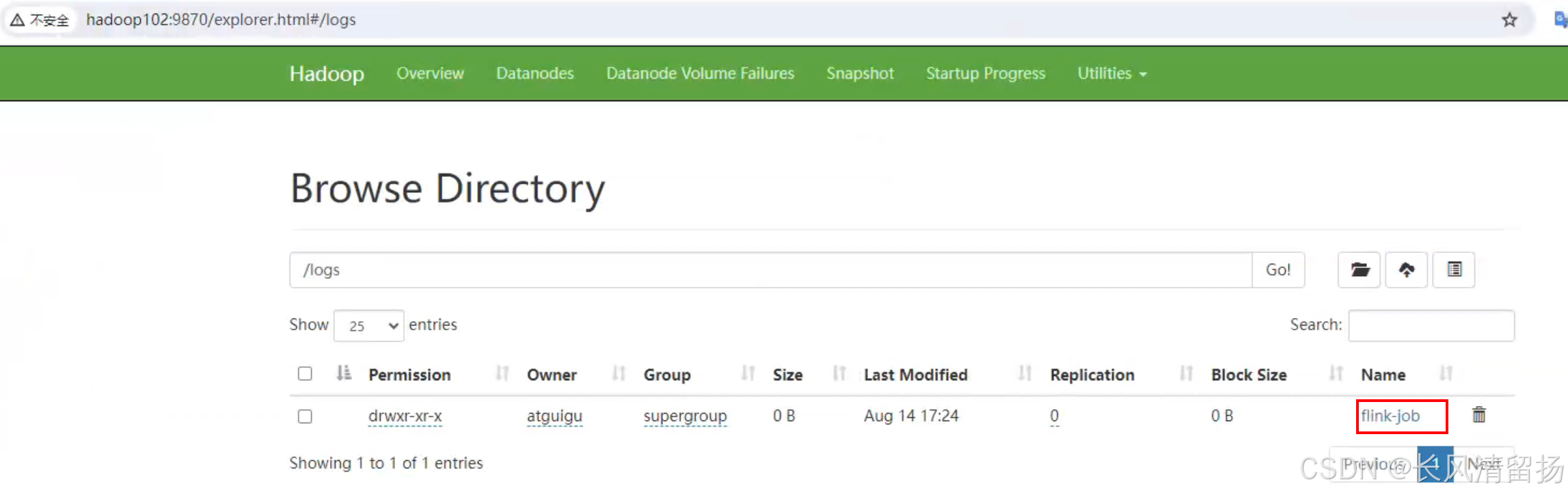
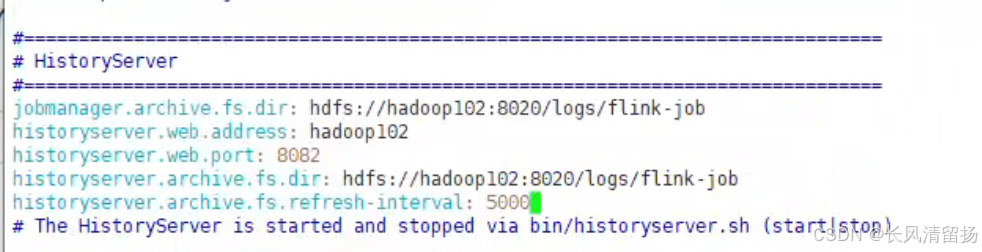
2)在 flink-config.yaml中添加如下配置
进入到conf下编辑flink-config.yaml
jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.web.address: hadoop102
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
historyserver.archive.fs.refresh-interval: 50001. jobmanager.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
含义:这个参数指定了JobManager用于存储作业完成后的归档日志的HDFS目录。当Flink作业完成后,其日志和状态信息会被归档到这个指定的HDFS路径下,以便后续的分析和审计。
用途:
- 日志归档:确保作业执行后的日志和状态信息不会立即被删除,而是被安全地存储在HDFS上。
- 审计和调试:在需要时,可以从HDFS上检索这些归档的日志,用于审计作业的执行情况或调试问题。
2. historyserver.web.address: hadoop102
含义:这个参数指定了Flink HistoryServer绑定的主机名或IP地址。HistoryServer是一个Web服务,用于展示Flink作业的历史记录,包括作业的图、状态、持续时间等信息。
用途:
- 访问HistoryServer:用户可以通过浏览器访问这个地址(通常是
http://<hostname>:<port>),来查看Flink作业的历史记录。 - 作业监控:方便用户监控和分析作业的执行情况,包括作业的成功、失败、重启等信息。
3. historyserver.web.port: 8082
含义:这个参数指定了Flink HistoryServer监听的端口号。用户需要通过这个端口来访问HistoryServer提供的Web服务。
用途:
- Web服务端口:确保HistoryServer能够在一个特定的端口上监听HTTP请求,从而提供Web界面供用户访问。
- 配置防火墙和安全组:在配置网络防火墙或安全组时,需要确保这个端口是开放的,以便外部用户能够访问HistoryServer。
4. historyserver.archive.fs.dir: hdfs://hadoop102:8020/logs/flink-job
含义:这个参数与jobmanager.archive.fs.dir类似,但它专门用于HistoryServer。它指定了HistoryServer用于读取作业归档日志的HDFS目录。HistoryServer会从这个目录中读取作业的历史记录,并在Web界面上展示。
用途:
- 历史记录读取:确保HistoryServer能够找到并读取作业的历史记录,以便在Web界面上展示给用户。
- 数据一致性:确保JobManager和HistoryServer使用相同的HDFS目录来存储和读取作业的历史记录,以保持数据的一致性。
5. historyserver.archive.fs.refresh-interval: 5000
含义:这个参数指定了HistoryServer刷新HDFS上作业归档日志的间隔时间(以毫秒为单位)。在这个时间间隔内,HistoryServer会定期检查HDFS上的归档日志目录,以获取最新的作业历史记录。
用途:
- 实时性:确保HistoryServer能够及时地获取到最新的作业历史记录,并在Web界面上展示给用户。
- 性能调优:通过调整这个参数,可以在实时性和系统性能之间找到一个平衡点。如果设置得太短,可能会增加HDFS的访问压力;如果设置得太长,则可能导致用户无法及时看到最新的作业历史记录。
3)启动历史服务器
bin/historyserver.sh start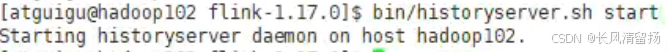
4)停止历史服务器
bin/historyserver.sh stop5)查看历史服务器
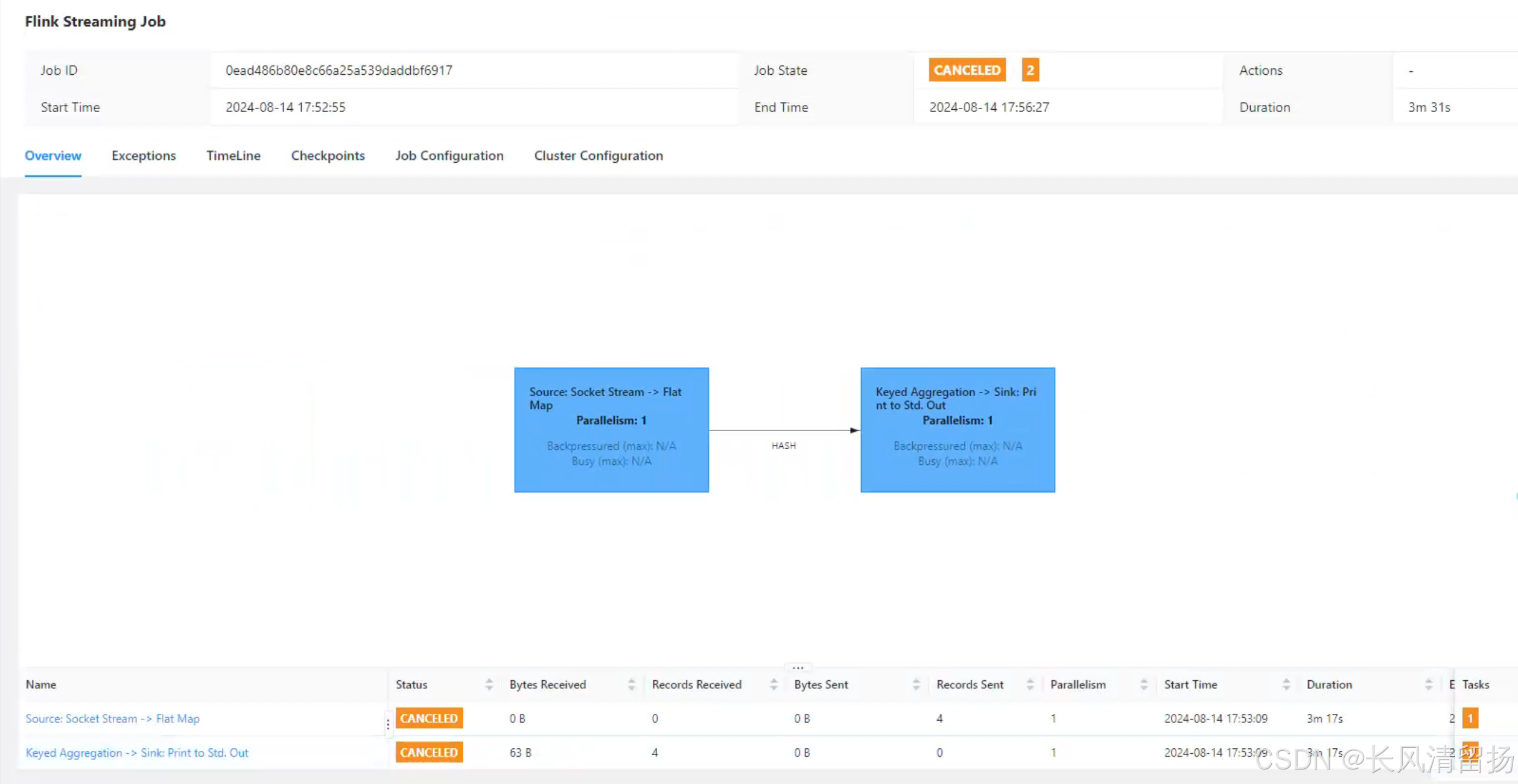
在浏览器地址栏输入:http://hadoop102:8082 查看已经停止的 job 的统计信息
6)启动一个per-job Flink程序
bin/flink run -d -t yarn-per-job -c wordcount.flink_wc_socket flink_flink-1.0-SNAPSHOT.jar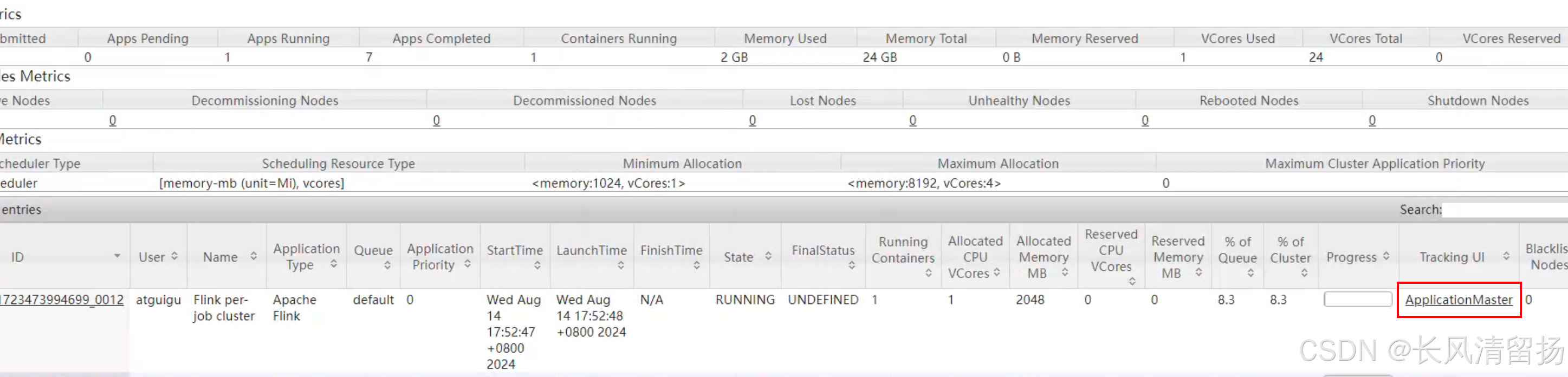
在netcat上输入内容并查看输出结果
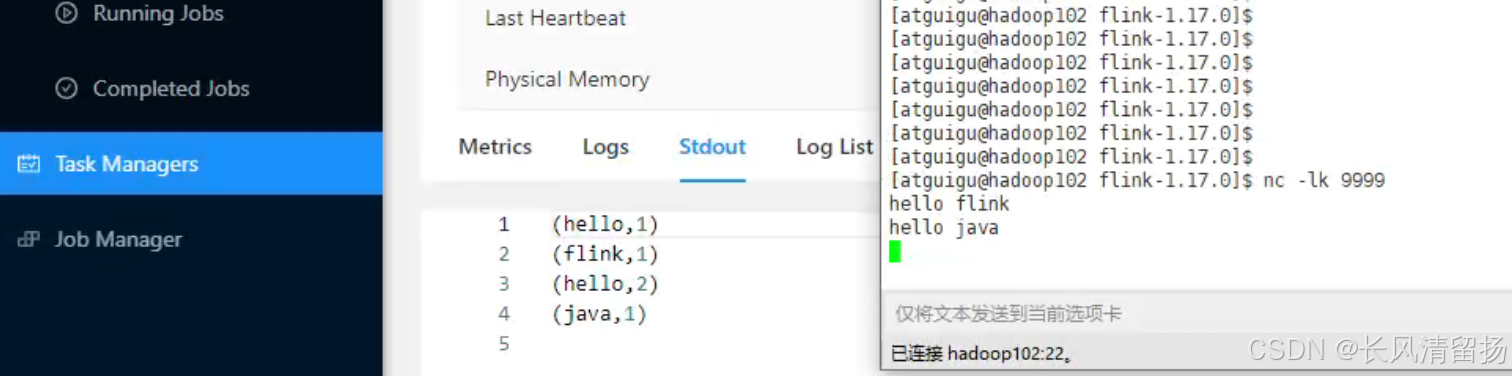
然后停止任务

点击History查看历史服务器
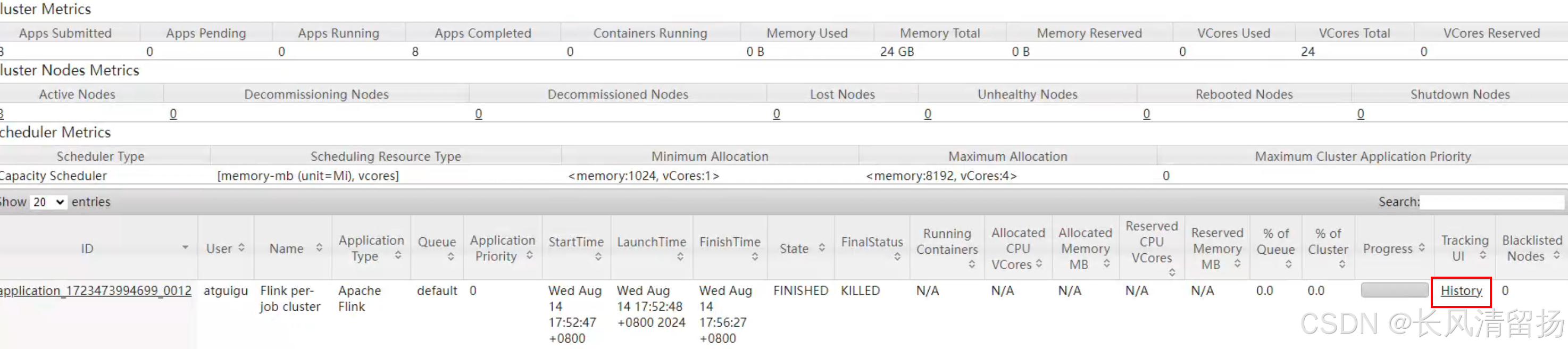
可以看到之前运行的flink程序
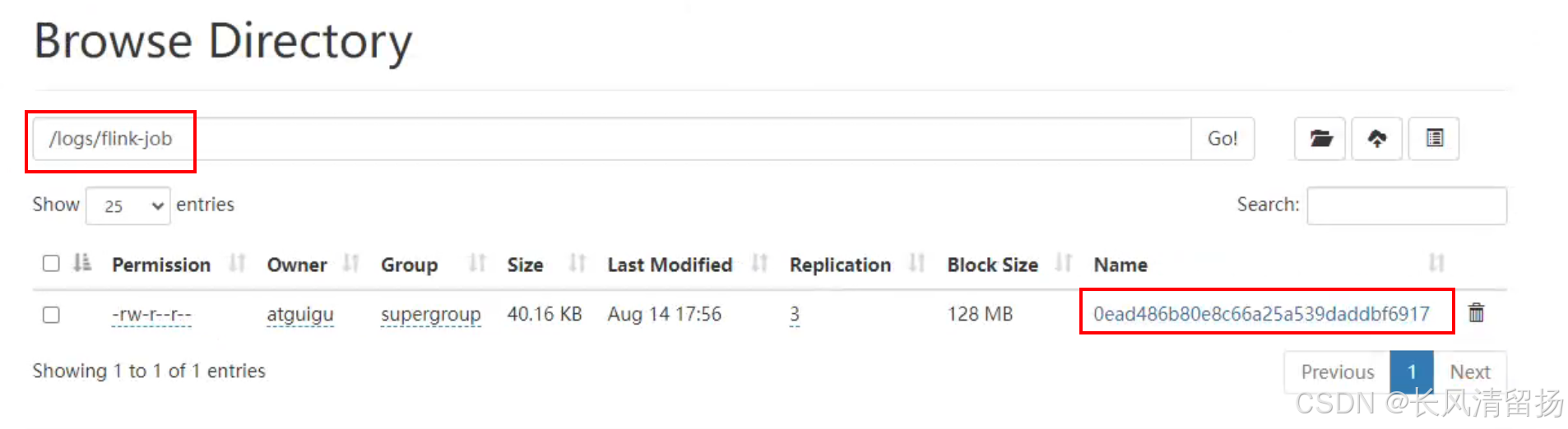
在Hadoop的flink-job目录下可以看到多了一个归档文件
本篇结束,喜欢的小伙伴可以一起学习,有疑问或者需要源代码和资料的可以评论区留言哦