一、模型整体情况
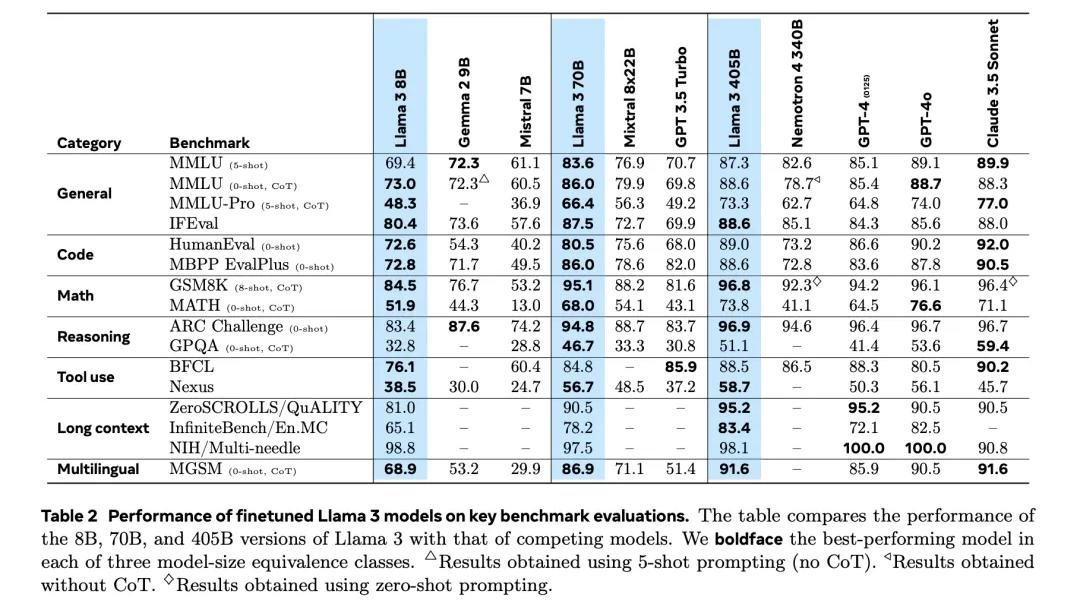
Meta 于 2024 年 7 月 23 日推出的 LLama3.1,在开源大模型的发展进程中树立了新的里程碑。该模型拥有 8B、70B 和 405B 三种参数规模版本,其中 405B 版本的模型参数总量约达 820GB,是目前全球最大的开源模型。在性能表现上,405B 版本在 MMLU、GSM8K、HumanEval 等多个关键基准测试里,已经能够与 GPT-4o、Claude 3.5 等闭源模型相媲美,甚至在部分任务中实现了超越。LLama3.1 的出现,不仅彰显了开源社区在大模型研发领域的强大实力,也对闭源模型长期以来的主导地位发起了有力挑战。
二、数据筹备与处理流程
(一)数据构成及来源
LLama3.1 的预训练数据规模极为庞大,总量超过 15 万亿 token,数据的时间范围截止到 2023 年 12 月。这些数据的来源丰富多样,并且经过了精心的筛选和配比。具体的数据构成比例为:50% 的常识知识类数据、25% 的数学与推理类数据、17% 的代码相关任务数据以及 8% 的多语言数据。其中,多语言数据涵盖了英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语等 8 种语言。这