目录
摘要
Stable Diffusion是一种深度学习模型,专门设计用于生成高质量的图像。该模型结合了扩散模型和Transformer架构的特点,通过文本处理、初始化、扩散过程、U-Net生成最终的图像。本篇博客将着重介绍SD模型生成过程使用到的技术,并通过最新的模型进行图像生成展示。
Abstract
Stable Diffusion is a deep learning model specifically designed to generate high-quality images. This model combines the characteristics of diffusion model and Transformer architecture, and generates the final image through text processing, initialization, diffusion process, and U-Net. This blog will focus on introducing the technologies used in the SD model generation process and showcase image generation through the latest models.
1. Stable Diffusion
论文地址:High-Resolution Image Synthesis with Latent Diffusion Models
为了更好的介绍Stable Diffusion,我们先上一张整体的结构图,如下图1所示:
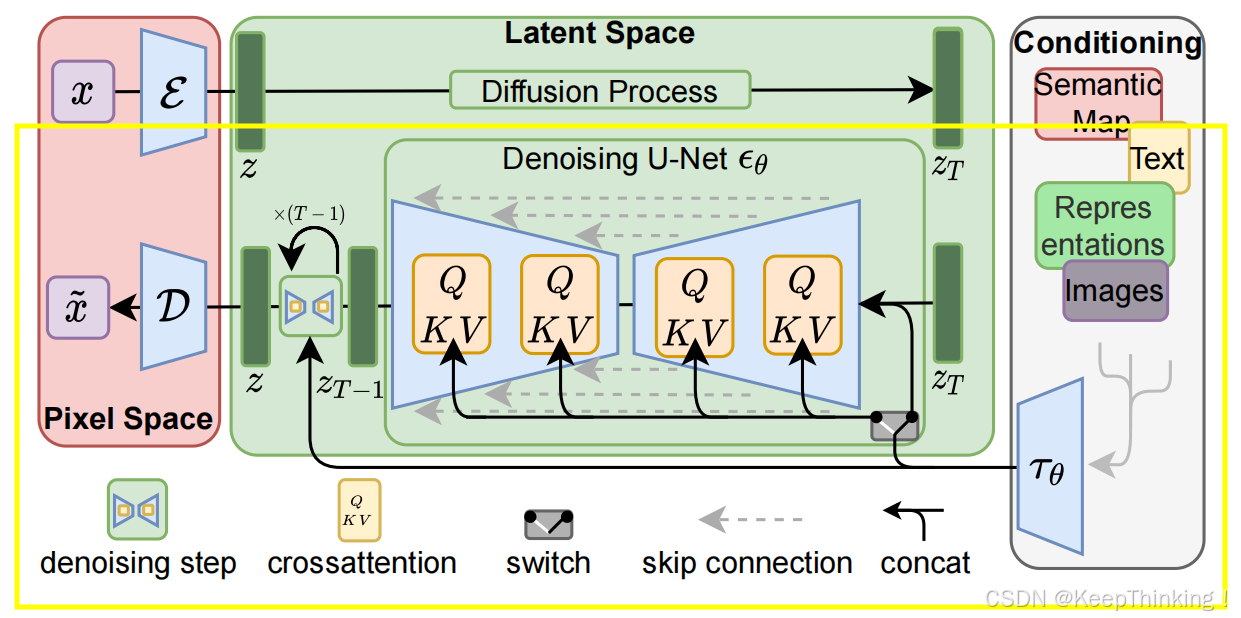
Stable Diffusion是基于Latent Diffusion的结构而来,主要在于上图的Latent Space部分。在上图黄色框的上半部分主要是用于训练的,对原始图像进行加噪处理直至变为纯噪声。而黄框部分才是用于文本生成图像的,所以本篇博客将侧重介绍文生图部分的内容。
好,让我们来看看SD是如何实现通过文本提示生成图像的吧!
1.1 CLIP
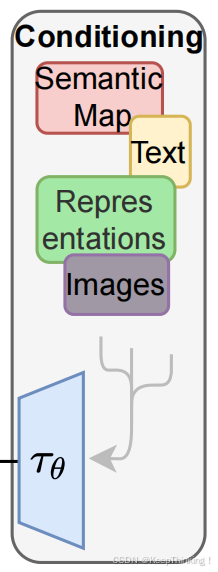
在图1的右边我们可以看到Conditioniong模块,该模块主要功能是将条件输入(文本)转换为机器可以理解的上乘条件。于是,在SD模型中使用CLIP模型实现此功能,结构图如下:
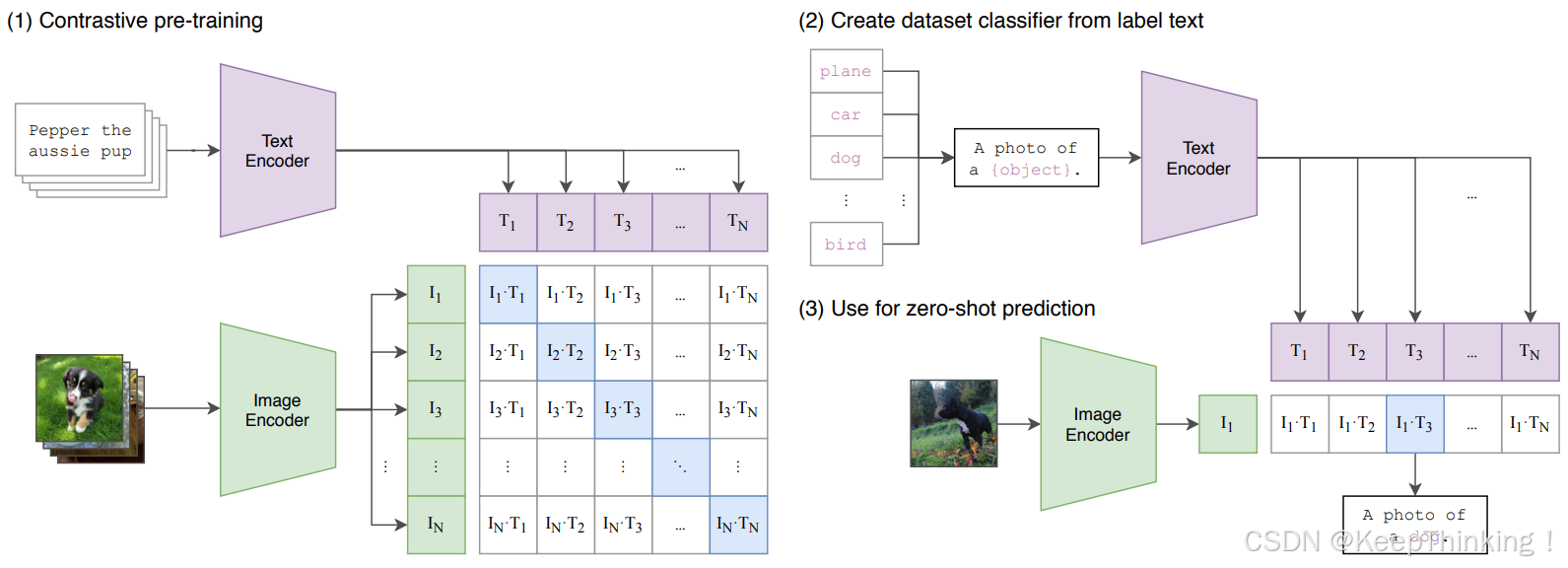
CLIP模型的Text Encoder部分被用来将用户的文本输入转换成一个固定长度的向量序列,这个向量序列包含了文本的语义信息,并且与现实世界中的图像有相关性 。在Stable Diffusion的图像生成过程中,这些文本特征向量与随机噪声图像一起被送入模型的后续部分,以生成与文本描述相匹配的图像 。
通过CLIP便可将文本提示转化为能够被SD模型理解的上乘条件,用于指导U-Net对随机噪声图像进行降噪处理。
1.2 U-Net
隐空间(Latent Space)稍后再解释,我们先看看隐空间的U-Net。在SD模型中的U-Net和DDPM中的U-Net有所不同。在DDPM中U-Net是接收噪声图像和时间步两个输入,显然在SD中还需要接收文本描述指导去噪过程。
暂且将latent特征视为噪声图像特征,其结构大致如下图所示:

但是原始U-Net并不能嵌入文本信息,于是SD模型对该结构进行了改造,如下图所示:
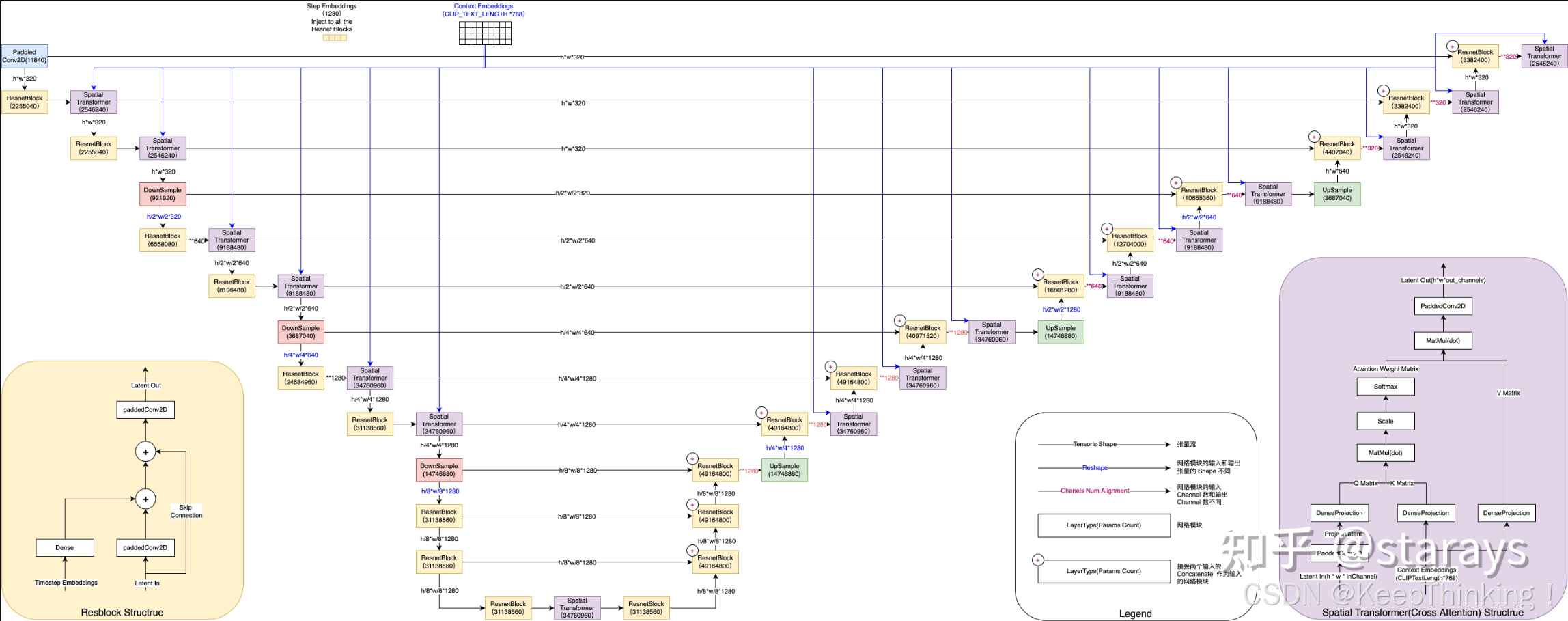
在改进后U-Net模型中,主要添加了Transformer模块。该模块在处理图像的全局和局部特征方面拥有重要作用。
- 特征融合:Transformer模块通过自注意力和交叉注意力机制,使得U-Net能够有效地融合图像的局部特征和全局特征。这种融合有助于模型在恢复图像尺寸的同时,也能够精确地恢复图像的细节和结构 。
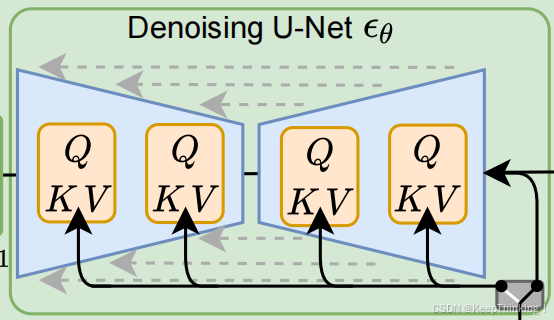
- 多模态信息整合:在Stable Diffusion中,Transformer模块通过交叉注意力机制,将文本信息与图像信息进行有效整合。这允许模型在生成过程中考虑文本条件,从而生成与文本描述相匹配的图像 。
- 增强表达能力:Transformer模块中的FeedForward网络和LayerNorm层增强了模型的表达能力,使得UNet能够捕捉更复杂的图像特征和模式 。
- 时间嵌入:UNet中的Transformer模块还结合了时间嵌入技术,这有助于模型在扩散过程中更好地理解和预测噪声,从而提高生成图像的质量和准确性 。
- 残差连接:Transformer模块通常与残差连接结合使用,这种结构使得信息能够在网络中更有效地流动,有助于避免深层网络训练中的梯度消失问题 。
- 编码器-解码器结构:在U-Net的编码器-解码器结构中,Transformer模块不仅用于下采样阶段以捕获图像的上下文信息,也用于上采样阶段以逐步恢复图像的细节 。
- 迭代去噪:在Stable Diffusion的迭代去噪过程中,Transformer模块有助于U-Net逐步精细化地去除噪声,生成清晰的图像 。
1.3 VAE
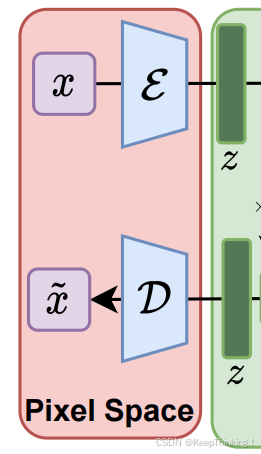
在图1的左侧部分,我们不难发现输入图像和输出图像都做了某些处理,然后再进入了Latent Space。其实就是通过变分自编码器(Variational Auto-Encoders)实现像素空间与隐空间的转换,VAE是一种深度生成模型,基于变分贝叶斯推断的生成式网络结构,与传统的自编码器不同,它以概率的方式描述对潜在空间的观察,将真实样本通过编码器网络变换成一个理想的数据分布。通过如下步骤实现:
- 压缩与编码(latent空间):VAE的编码器部分将输入的图像(像素空间)转换为一个低维的隐空间表示。编码器输出的是潜在变量的均值和方差,这些变量遵循一个概率分布,通常是高斯分布。通过这种方式,VAE能够捕捉到数据的重要特征,并忽略无关的噪声 。
- 重参数化技巧:在隐空间中,VAE使用了一个重参数化技巧来确保模型的可微性,从而可以利用标准的梯度下降方法进行训练。这个技巧涉及到从均值和方差中采样隐变量,然后通过解码器重建图像。这种方法允许模型在训练过程中通过反向传播算法学习隐空间的分布 。
- 重建与生成(像素空间):VAE的解码器部分将隐空间的潜在表示转换回像素空间,生成与原始输入相似或全新的图像。解码器的任务是从隐空间的低维表示中重建图像,这要求它学习如何从压缩的隐变量中恢复出图像的主要结构和细节 。
- 概率建模与生成:VAE通过概率建模的方式,不仅能够重建输入数据,还能生成新的数据样本。在latent空间中,可以通过对潜在变量进行操作(如插值、添加噪声等)来生成新的图像样本,这些样本在像素空间中表现为新颖的图像。
- 数据压缩与去噪:VAE可以将高维数据压缩到低维隐空间,实现数据的有损压缩。这在数据存储和传输中起到了积极的作用。同时,VAE的编码器能够学习到数据的有意义特征表示,有助于在监督学习任务中提取更好的特征,改善模型性能 。
- 图像生成与编辑:在隐空间中,VAE可以进行图像的生成和编辑。例如,通过调整隐空间中的点,可以改变生成图像的某些属性,如人脸的年龄、表情等。这种方法允许对图像进行精细的控制和编辑,而不需要直接在像素级别上操作 。
Latent Space通常指的是一个高维空间,其中每个点代表了一个图像的压缩表示或编码 。这个空间是通过模型学习得到的,它能够捕捉到数据的重要特征,并忽略无关的噪声,从而实现数据的简化表示。
为什么要使用隐空间?
- 数据压缩:隐空间可以看作是一种数据压缩的形式,它通过去除数据中的冗余信息和噪声,将高维数据映射到低维空间,从而简化了数据表示 。
- 提高计算效率:通过在隐空间中而不是在高维的像素空间中工作,Stable Diffusion模型可以显著减少计算资源的消耗,提高模型的运行速度 。隐空间的维度远低于像素空间,因此可以节省大量的计算资源 。
- 发现隐藏模式和规律:隐空间允许模型学习数据中的抽象特征和潜在结构,提取数据中的有用信息。通过学习隐变量表示,模型可以发现数据中的隐藏模式和规律,提高模型对数据的理解和表达能力 。
1.4 图像生成测试
使用秋叶整合包,Stable Diffusion模型使用Realism Engine SDXL,让我们来看看生成效果如何。
- Realism Engine SDXL
提示词:一辆飞驰的摩托车
生成效果:

提示词:一个程序员坐在电脑面前
生成效果:

模型及LoRa下载:https://civitai.com/
2. LoRA
Low-Rank Adaptation是一种针对大型预训练模型的参数高效微调技术。其核心思想是在预训练模型的基础上,通过引入低秩矩阵来模拟全参数微调,从而减少微调所需的参数量,提高训练效率并避免过拟合 。
LoRA并不是传统的全参微调,而是只更新U-Net中的Transformer部分。
- 参数减少与计算效率:LoRA通过低秩分解大幅减少了模型的参数量,降低了模型训练和推理时的计算需求 。这意味着在隐空间中,LoRA可以有效地压缩模型的参数,使得模型更加轻量化,同时保持了模型的性能。
- 灵活性与适应性:LoRA能够快速适应不同的应用场景,提高了模型的灵活性和适应性 。在latent空间中,LoRA通过引入低秩结构,使得模型能够更好地捕捉数据的重要特征,从而在像素空间中生成更准确的图像或执行更精确的任务。
- 微调过程:LoRA微调技术在保持预训练模型大部分参数不变的情况下,通过添加低秩矩阵来模拟参数的变化量,实现对特定任务的适应 。在隐空间中,LoRA通过调整低秩矩阵的参数来微调模型,而不是调整整个权重矩阵,这样可以在不显著增加参数量的情况下,实现对模型的定制化调整。
- 图像生成与编辑:LoRA可以应用于图像生成和编辑任务,在隐空间中调整隐变量,然后在像素空间中生成新的图像样本 。这种方法允许对图像进行精细的控制和编辑,而不需要直接在像素级别上操作。
- 模型性能提升:LoRA微调后的模型在特定任务上的表现力和准确性显著提升 。在隐空间中,LoRA通过聚焦大模型的Transformer注意力块,使用低秩矩阵来模拟全参数微调,从而在像素空间中实现更高质量的图像生成或更准确的任务执行。
- 避免过拟合:LoRA微调方法通过只训练一小部分参数,保持大部分预训练权重不变,有效避免了过拟合问题 。这在隐空间中意味着模型可以更好地泛化到新数据,同时在像素空间中保持稳定的性能。
总结
本周的学习到此结束,下周将会继续扩散生成模型有关内容的学习。
如有错误,请各位大佬指出,谢谢!