此文仅作为本人参考博客以及视频讲解本地部署跑通大模型Qwen1.5B的记录
文章目录
前言
整体参考这篇文章:通义千问Qwen 1.8B以及7B chat模型本地化部署
1.下载代码
首先在GitHub上进行代码的下载,链接:https://github.com/QwenLM/Qwen
下载完以后进行解压
2.部署环境
2.1 创建新环境
为了避免环境出错,选择新建一个部署大模型的新环境
打开Anaconda prompt,然后输入
conda create -n qwen1 python==3.11
conda activate qwen1
2.2 下载GPU
conda install pytorch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 pytorch-cuda=12.1 -c pytorch -c nvidia
2.3 安装依赖环境
pip install -r requirements.txt
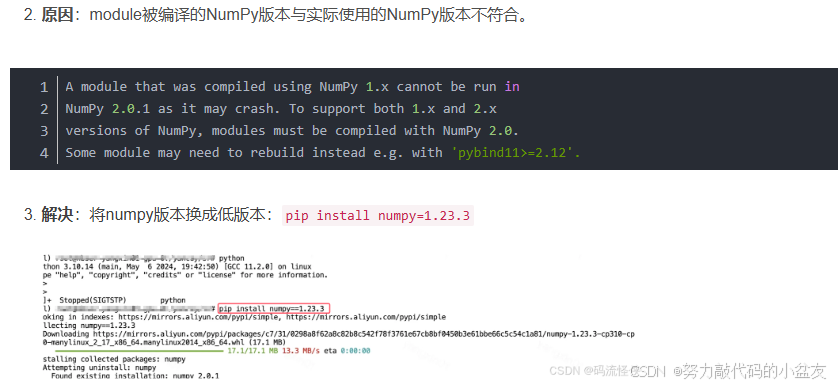
PS:在下载GPU以后,使用import torch进行检查,然后报错
经过搜索以后修改numpy版本即解决
不过在安装依赖环境 requirements.txt的时候显示numpy又安装到2.几.几的版本去了。。。

3. 下载模型文件
参考的文章是使用魔塔进行模型的下载
3.1 安装魔塔
如果未进行魔塔的安装,需要先安装一下魔塔,参考魔塔的官方文档
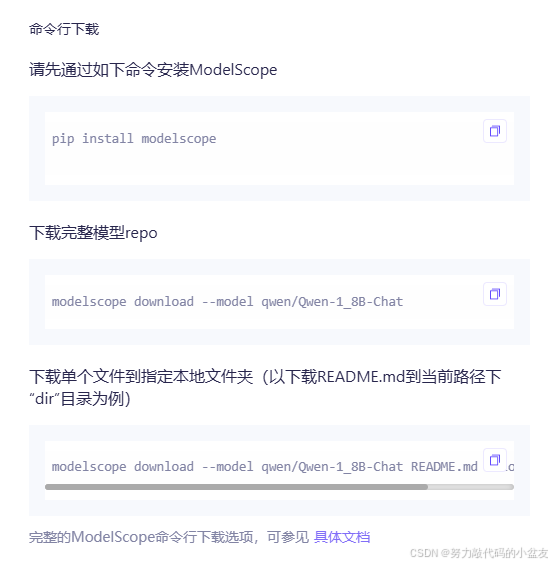
首先pip
pip install modelscope
3.2 下载模型
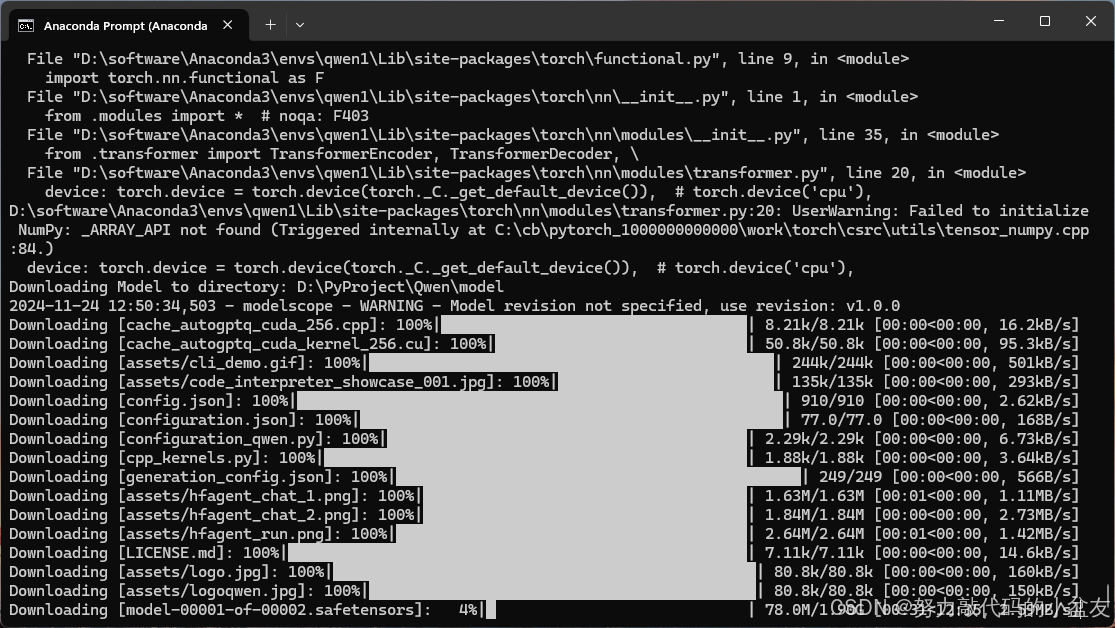
然后下载这个模型,后面的local_dir是指定下载的文件地址
modelscope download --model qwen/Qwen-1_8B-Chat --local_dir ./model
开始下载
4.本地模型推理
4.1 安装依赖包
pip install -r requirements_web_demo.txt
4.2 修改模型路径(可选)
通过修改web_demo.py文件进行修改
vim web_demo.py
4.3 推理
GPU推理
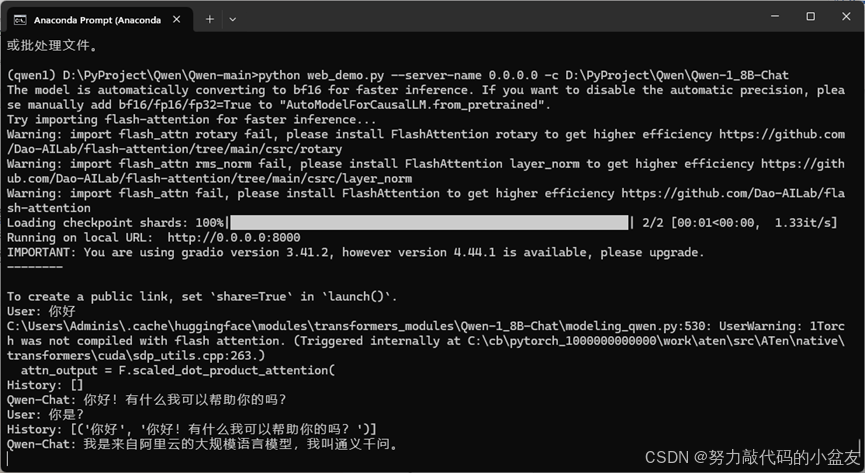
D:\PyProject\Qwen\Qwen-main>python web_demo.py --server-name 0.0.0.0 -c D:\PyProject\Qwen\Qwen-1_8B-Chat
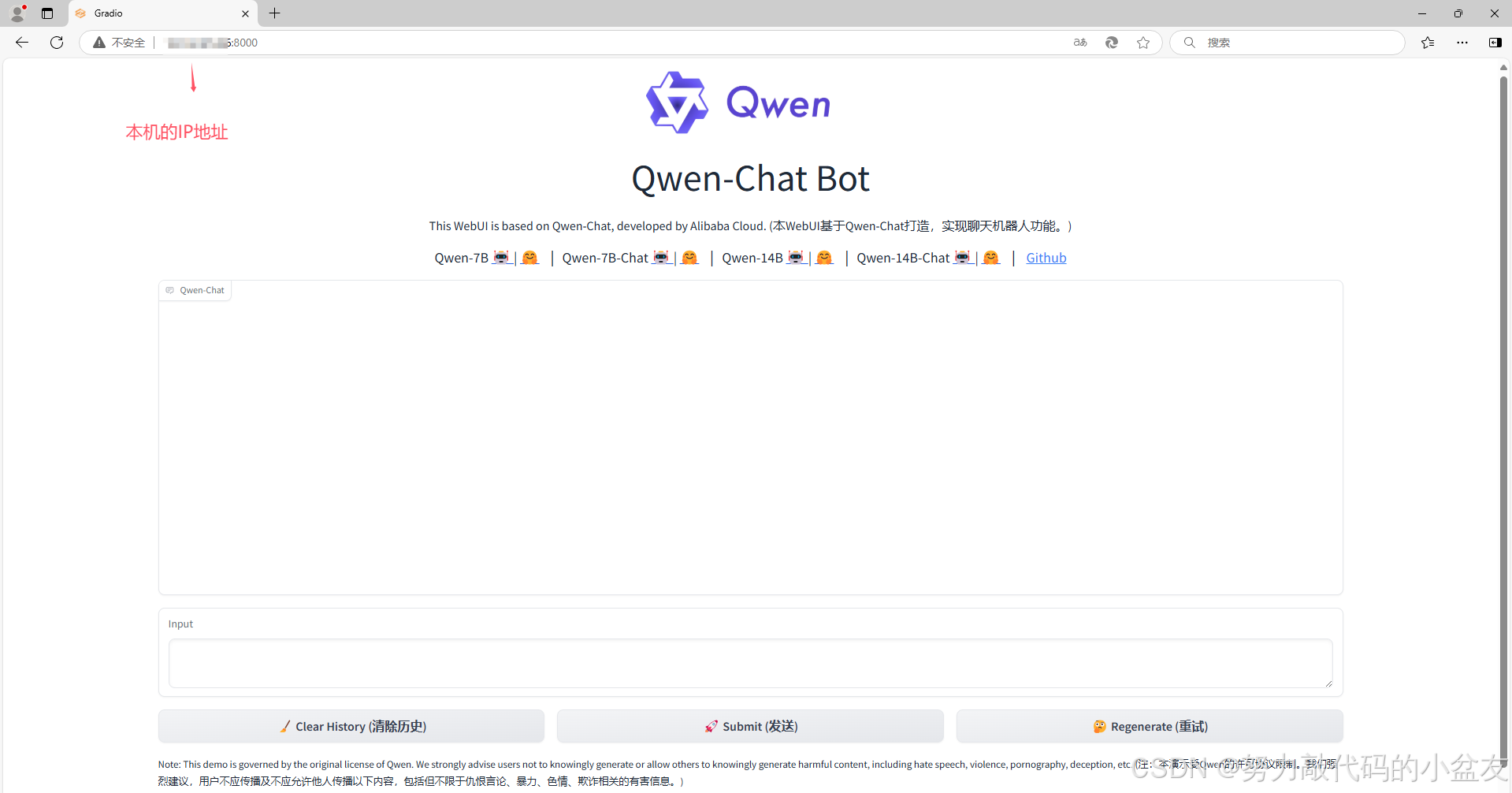
使用本机的IP地址加上提供的端口号进行访问
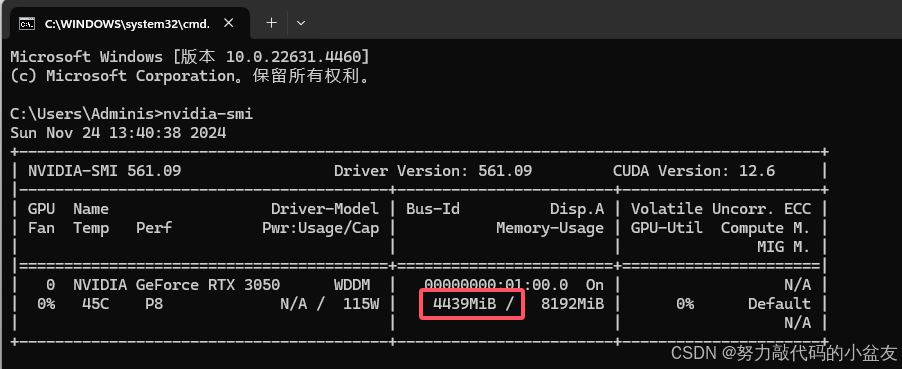
占用内存差不多4个G
结束语
浅浅记录第一次部署大模型的流程