概述:
基于Transformer的端到端检测器(DETR)的高计算成本问题尚未得到有效解决,这限制了它们的实际应用,并使它们无法充分利用无后处理的好处,如非最大值抑制(NMS)。本文首先分析了现代实时目标检测器中NMS对推理速度的影响,并建立了端到端的速度基准。为了避免NMS引起的推理延迟,作者提出了一种实时检测Transformer(RT-DETR),这是第一个实时端到端目标检测器。具体而言,设计了一种高效的混合编码器,通过解耦尺度内交互和跨尺度融合来高效处理多尺度特征,并提出了IoU感知的查询选择,以提高目标查询的初始化。此外,本文提出的检测器支持通过使用不同的解码器层来灵活调整推理速度,而不需要重新训练。
1. 问题
问题1:现有的实时检测器通常采用基于CNN的架构,在检测速度和准确性方面实现了合理的权衡。但是需要NMS进行后处理,这通常难以优化并且不够鲁棒,导致检测器的推理速度延迟。
法1:DETR由于消除了各种手工设计的组件,如非最大值抑制(NMS)。该架构极大地简化了目标检测的流水线,实现了端到端的目标检测。
问题2:DETR的高计算成本问题尚未得到有效解决,这限制了DETR的实际应用,并导致无法充分利用其优势。这意味着,尽管简化了目标检测流水线,但由于模型本身的计算成本高,很难实现实时目标检测。
2. 方法
一种高效的混合编码器+IoU-Aware查询选择
1.作者发现,尽管多尺度特征的引入有利于加速训练收敛和提高性能,但它也会导致编码器中序列长度的显著增加。因此,由于计算成本高,Transformer编码器成为模型的计算瓶颈。为了实现实时目标检测,设计了一种高效的混合编码器来取代原来的Transformer编码器。通过解耦多尺度特征的尺度内交互和尺度间融合,编码器可以有效地处理不同尺度的特征。
2. 而且,先前的工作表明,解码器的目标查询初始化方案对检测性能至关重要。为了进一步提高性能,作者提出了IoU-Aware的查询选择,它通过在训练期间提供IoU约束来向解码器提供更高质量的初始目标查询。
3.此外,作者提出的检测器支持通过使用不同的解码器层来灵活调整推理速度,而不需要重新训练,这得益于DETR架构中解码器的设计,并有助于实时检测器的实际应用。
3. 步骤
RT-DETR:Backbone+混合编码器+带有辅助预测头的Transformer解码器组成
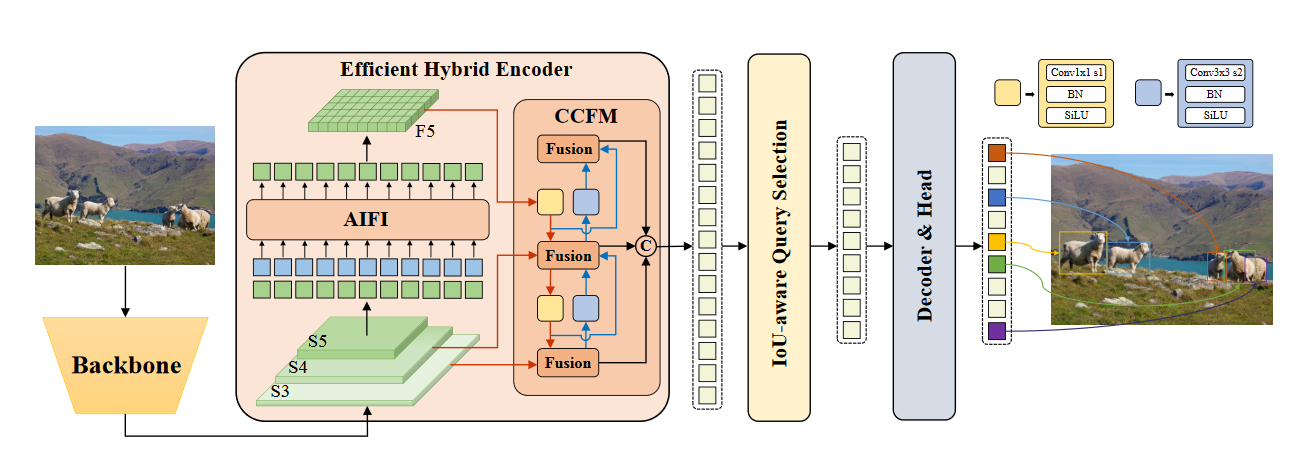
1、首先,利用Backbone的S3,S4,S5最后3个阶段的输出特征作为编码器的输入;
2、然后,混合编码器通过尺度内交互和跨尺度融合将多尺度特征转换为一系列图像特征(如第4.2节所述);
3、随后,采用IoU-Aware查询选择从编码器输出序列中选择固定数量的图像特征,作为解码器的初始目标查询;
4、最后,具有辅助预测头的解码器迭代地优化对象查询以生成框和置信度得分。
RT-Detr网络首先利用骨干网络{S3,S4,S5}的最后三个阶段的特征作为encoder的输入。encoder通过尺度内特征交互(AIFI,按文中的说法其实就是一个transformer layer)和跨尺度特征融合模块(CCFM)将多尺度特征转换为图像特征序列。IoU感知查询选择用于选择固定数量的图像特征以用作解码器的初始对象查询。最后,具有辅助预测头的decoder(与DINO的decoder相同)迭代地优化对象查询,以生成框和置信度分数。
从包含关于图像中的对象的丰富语义信息的低级特征中提取高级特征。直观地说,对连接的多尺度特征进行特征交互是多余的。如图所示,为了验证这一观点,作者重新思考编码器结构,并设计了一系列具有不同编码器的变体(5组)
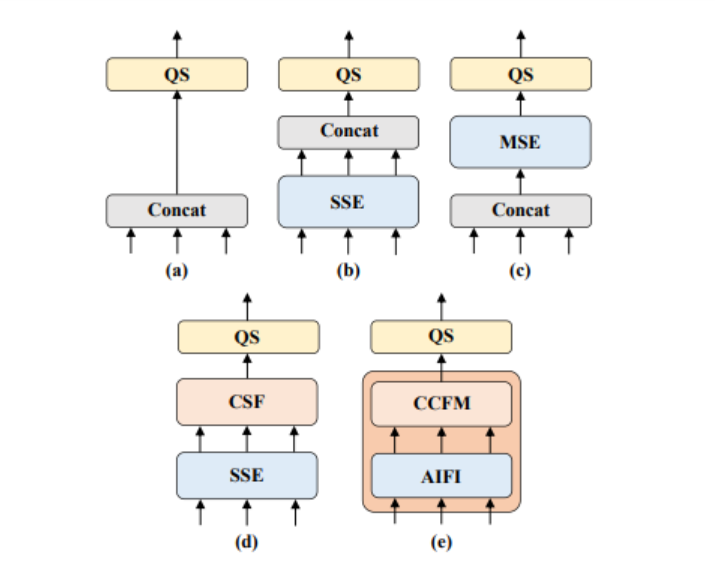
该组变体通过将多尺度特征交互解耦为尺度内交互和跨尺度融合的两步操作,逐步提高模型精度,同时显著降低计算成本。首先删除了DINO-R50中的多尺度变换编码器作为基线A。接下来,插入不同形式的编码器,以产生基于基线A的一系列变体,具体如下:
A→ B: 变体B插入一个单尺度Transformer编码器,该编码器使用一层Transformer Block。每个尺度的特征共享编码器,用于尺度内特征交互,然后连接输出的多尺度特征
B→ C: 变体C引入了基于B的跨尺度特征融合,并将连接的多尺度特征输入编码器以执行特征交互
C→ D: 变体D解耦了多尺度特征的尺度内交互和跨尺度融合。首先,使用单尺度Transformer编码器进行尺度内交互,然后使用类PANet结构进行跨尺度融合
D→ E: 变体E进一步优化了基于D的多尺度特征的尺度内交互和跨尺度融合,采用了设计的高效混合编码器
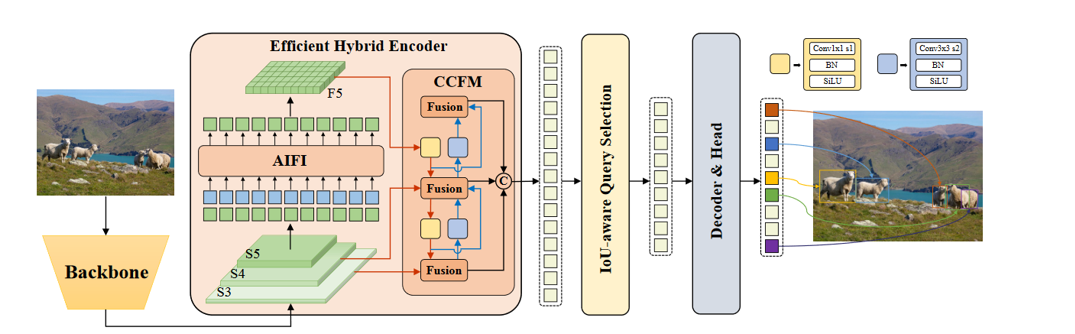
基于上述分析,作者重新思考了编码器的结构,并提出了一种新的高效混合编码器。如图所示,所提出的编码器由两个模块组成,即基于注意力的尺度内特征交互(AIFI)模块和基于神经网络的跨尺度特征融合模块(CCFM)。AIFI进一步减少了基于变体D的计算冗余,变体D仅在S5上执行尺度内交互。作者认为,将自注意力操作应用于具有更丰富语义概念的高级特征可以捕捉图像中概念实体之间的联系,这有助于后续模块对图像中目标的检测和识别。同时,由于缺乏语义概念以及与高级特征的交互存在重复和混淆的风险,较低级别特征的尺度内交互是不必要的。
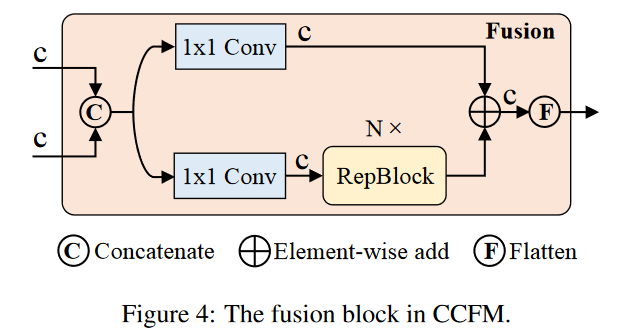
CCFM也基于变体D进行了优化,在融合路径中插入了几个由卷积层组成的融合块。融合块的作用是将相邻的特征融合成一个新的特征,其结构如图4所示。融合块包含N个RepBlock,两个路径输出通过元素相加进行融合
可以将这个过程表述如下:
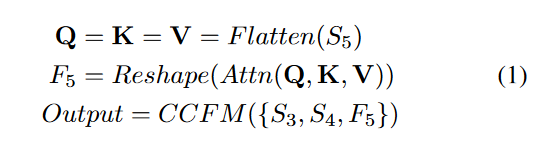
其中Attn表示多头自注意力,Reshape表示将特征的形状恢复到与S5相同的形状,这是Faltten的inverse操作
IoU-Aware查询选择
DETR中的目标查询是一组可学习的嵌入,这些嵌入由解码器优化,并由预测头映射到分类分数和边界框。然而,这些目标查询很难解释和优化,因为它们没有明确的物理意义
后续工作改进了目标查询的初始化,并将其扩展到内容查询和位置查询(Anchor点)
其中,Effificient detr、Dino以及Deformable detr都提出了查询选择方案,它们的共同点是利用分类得分从编码器中选择Top-K个特征来初始化目标查询(或仅位置查询)。然而,由于分类得分和位置置信度的分布不一致,一些预测框具有高分类得分,但不接近GT框,这导致选择了分类得分高、IoU得分低的框,而分类得分低、IoU分数高的框被丢弃。
这会削弱探测器的性能。为了解决这个问题,作者提出了IoU-Aware查询选择,通过约束模型在训练期间为具有高IoU分数的特征产生高分类分数,并为具有低IoU得分的特征产生低分类分数。因此,与模型根据分类得分选择的Top-K个编码器特征相对应的预测框具有高分类得分和高IoU得分。将检测器的优化目标重新表述如下:

其中ˆy和y表示预测和基本事实,ˆy={ˆc,ˆb}和y={c,b}分别表示类别和边界框。我们将IOU分数引入分类分支的目标函数(类似于VFL[41]),以实现对阳性样本的分类和定位的一致性约束。
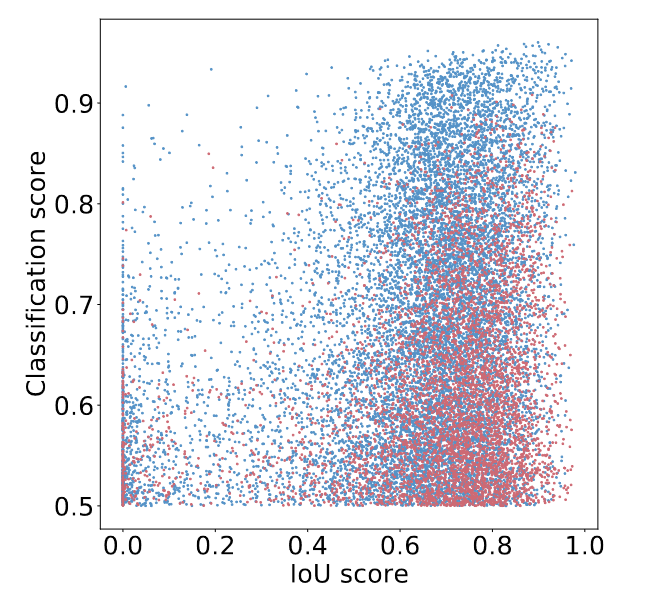
首先根据分类得分选择前K个(在实验中K=300)编码器特征,然后可视化分类得分大于0.5的散点图。红点和蓝点是根据分别应用普通查询选择和IoU感知查询选择训练的模型计算的。点越靠近图的右上角,对应特征的质量就越高,即分类标签和边界框更有可能描述图像中的真实对象。根据可视化结果发现最引人注目的特征是大量蓝色点集中在图的右上角,而红色点集中在右下角。这表明,使用IoU感知查询选择训练的模型可以产生更多高质量的编码器特征。
此外,还定量分析了这两类点的分布特征。图中蓝色点比红色点多138%,即分类得分小于或等于0.5的红色点更多,这可以被视为低质量特征。然后,分析分类得分大于0.5的特征的IoU得分,发现IoU得分大于0.5时,蓝色点比红色点多120%。定量结果进一步表明,IoU感知查询选择可以为对象查询提供更多具有准确分类(高分类分数)和精确定位(高IoU分数)的编码器特征,从而提高检测器的准确性。
Scaled RT-DETR
为了提供RT-DETR的可扩展版本,将ResNet网替换为HGNetv2。使用depth multiplier和width multiplier将Backbone和混合编码器一起缩放。因此,得到了具有不同数量的参数和FPS的RT-DETR的两个版本。对于混合编码器,通过分别调整CCFM中RepBlock的数量和编码器的嵌入维度来控制depth multiplier和width multiplier。值得注意的是,提出的不同规模的RT-DETR保持了同质解码器,这有助于使用高精度大型DETR模型对轻型检测器进行蒸馏。这将是一个可探索的未来方向