1.1 机器学习模型
机器学习(Machine Learning)是以人工智能为研究对象的科学。通过对数据进行学习获取经验,再使用学习到的经验对原算法的性能进行迭代优化,从而不断提高算法效果。
机器学习的过程与人类学习过程类似,例如识别图像需要几个步骤: 首先要收集大量样本图像,并标明这些图像的类别,这个过程称为样本标注。样本标注的过程就像给幼儿展示一些轮船图片,并告诉他这是轮船。这些样本图像就是数据集。 把样本和标注送给算法学习的过程称为训练。训练完成之后得到一个模型,这个模型是通过对这些样本进行总结归纳,最后得到的知识。 接下来,可以用这个模型对新的图像进行识别,称为预测。
1.1.1 线性模型与非线性模型
按机器学习算法函数是否线性,可以将模型分为线性模型和非线性模型。 线性模型(Linear Model)是指模型建立的函数是线性的。常见的线性模型包括:线性回归(Linear regression )、逻辑回归(Logistic regression)、线性判别分析(Linear Discriminant Analysis,简称LDA)等。 反之,如果预测的模型不是基于线性函数,则属于非线性模型。 随着算法的发展,目前也有许多非线性的模型是通过线性模型的高维映射或多层复合而来。
1.1.2 监督学习、非监督学习和强化学习
机器学习算法决策的过程可以从已有的数据、知识和经验中得来。而有些情况下,没有任何经验可循。根据这种学习方式,可以将模型分为监督学习模型、非监督学习模型和强化学习模型
1.监督学习
监督学习(Supervised Learning)是使用已有的数据进行学习的机器学习方法。已有的数据是成对的——输入数据和对应的输出数据所组成的数据对。算法通过自动分析,找到输入和输出数据之间的关系。此后对于新数据,算法也能够自动给出判断结果。
2.非监督学习
与监督学习相对的是非监督学习(Unsupervised Learning),也称为无监督学习。非监督学习直接对没有标记的训练数据进行建模学习。 与监督学习的最基本的区别是建模的数据没有标签。 非监督学习算法中,没有经验数据可供学习。算法可以在缺乏经验数据的情况下使用,可以用于认识新问题、探索新领域。因此一直是人工智能的一个重要研究方向。
3.强化学习
强化学习(Reinforcement Learning)的概念来自行为心理学。强化学习属于试错学习。智能体不断与环境进行交互,以获得最佳策略。算法根据当前环境状态确定所要执行的动作,并进入下一个状态,目标是让收益最大化。 强化学习根据系统状态和优化目标进行自主学习,不需要预备知识也不依赖“老师”的帮助。系统的输出是连续的动作,事先并不知道要采取什么动作,通过尝试去确定哪个动作可以带来最大回报。 学习也称为增强学习,强化学习没有标签,系统只会给算法执行的动作一个评分反馈。
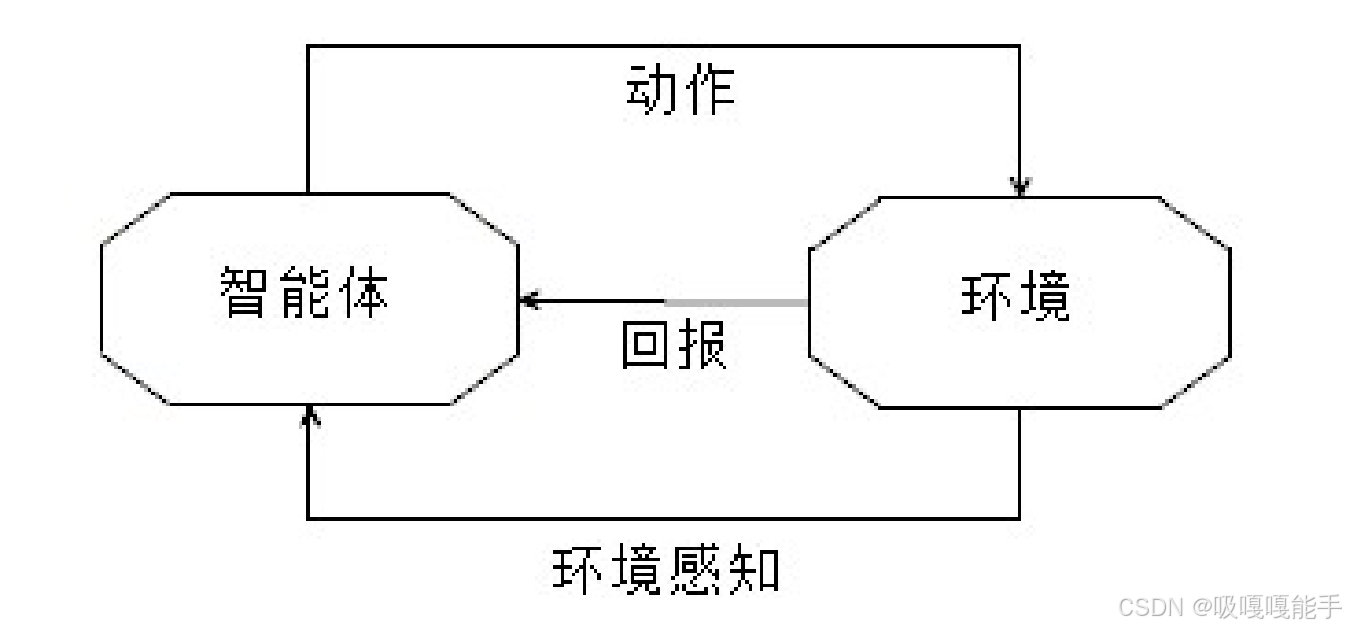
1.2 机器学习算法的选择
在机器学习中,数据集中的每个实体(通常为一行)称作一个样本或数据点;每个属性(通常为一列)则被称为一个特征。如果这些样本是具有类别的,那么每个样本的类别称为这个样本的标签。
1.2.1 模型的确定
算法就是“模型”,建立这个模型的过程称为“训练”。例如,我们可以通过训练来创建辨别猫和狗的模型。
1.搜集数据
表4.1 猫的特征信息数据
| No | Lwsk | LEar | color | Weight |
| 1 | 34 | 82 | Black | 3520 |
| 2 | 63 | Brown | 4490 | |
| 3 | 45 | 90 | Black | 2480 |
| 4 | 28 | 91 | Black | 4030 |
| 5 | 37 | 59 | Yellow | 8000 |
| 6 | 39 | 52 | Brown | 6130 |
| 7 | 48 | 52 | White | 5310 |
| 8 | 47 | 49 | Brown | 5280 |
No—编号;Lwsk—胡须长,单位mm;LEar—耳朵长度,单位mm;color—毛色;Weight—体重,单位g
体重与前两列数值的尺度不同,无法对比。如果绘制在同一幅图中,相对位置也很难给出,这时可以通过归一化进行数据标准化,方便后面处理。
数据标准化:为了让不同数量级的数据具备可比性,需要采用标准化方法进行处理,通常用于消除不同量纲单位带来的数据偏差。 标准化处理后,各数据指标处于同一数量级,适合进行综合对比评价,这就是数据标准化操作。
归一化:归一化是一种数据标准化方法。为方便处理,把需要处理的数据经过处理,数值限制在一定范围内,通常是将数据范围调整到[0,1]之间。 对数值x进行归一化处理,可以使用本列数据(同一特征的数据)的最大、最小值,计算方法为:
(x-最小值)/(最大值-最小值) (1.1)
例如:1号猫的体重x=3520克,体重数据中最小值为2480克,最大体重数据为8000克,归一化处理,1号猫的新体重数值为:
x′=(3520-2480)/(8000-2480)≈0.18841 (4.2)
1号猫的胡须长数据归一化结果为:
(34-28)/(48-28)= 0.3 (4.3)
可以看出,归一化后的数据在同一数量级,更方便对比。
2.模型选择
模型选择(model selection)包含两层含义,一层含义是指机器学习算法众多,对同一个问题,从多种算法中进行选择;另一层含义是,对同一个算法来说,设置不同的参数后,算法效果可能发生很大变化,甚至变成不同的模型。
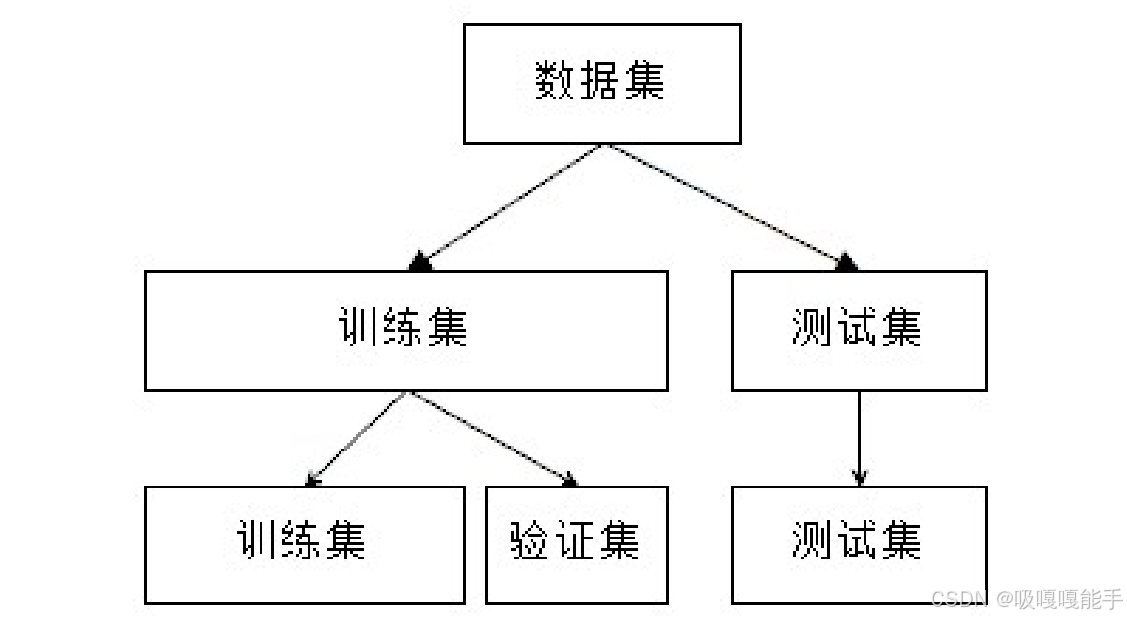
3.模型训练与测试
使用数据、通过最优化等方法确定模型算法中的参数,这个过程就是模型训练。模型训练时需要测定模型的准确程度。因此建立模型需要两个数据集——训练用数据集和测试用数据集。训练用数据集称为训练集(training set),测试用数据集称为测试集(testing set)。
然而,如果每次训练都用测试集来评估,测试集已经反复参与到了模型训练过程,就削弱了其测试的效果,影响模型的实际使用。 因此,有时还使用到一个验证集。验证集(Validation Set)是模型训练过程中单独留出的样本集,可以用于调整模型的超参数和用于对模型的能力进行初步评估。一般在训练集中单独划分出一块作为验证集。使用验证集能减少过拟合。
4.过拟合月欠拟合
过拟合(overfitting)也称为过学习,指模型过度学习了训练数据的固有关系。它的直观表现是算法在训练集上表现好,但在测试集上表现不好,泛化性能差,如下图所示。
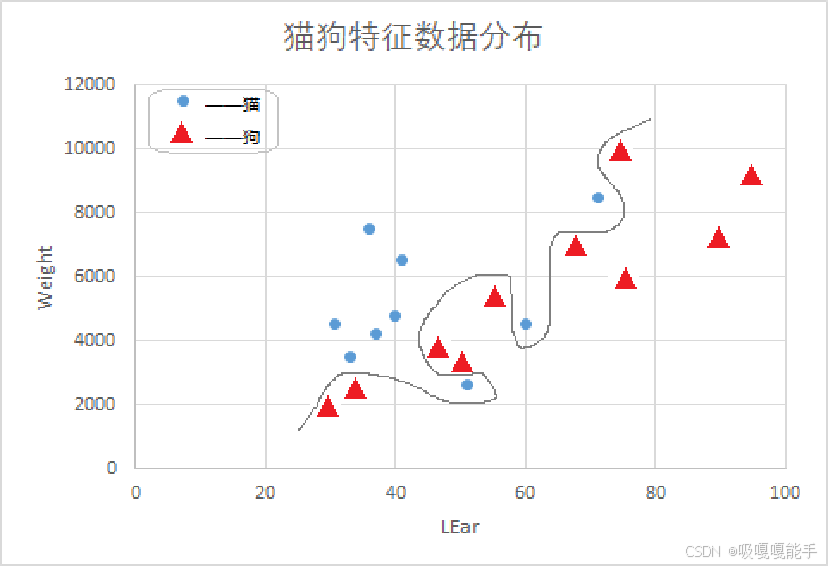
与此相反的是欠拟合(underfitting),即欠学习,指模型没有学到训练数据的内在关系,对样本的一般性质学习不足。例如,“耳朵长度超过56毫米的是狗”的判断模型就属于欠拟合。
为避免过拟合,通常采用交叉验证法,使模型对样本进行充分、科学的学习。 交叉验证(Cross Validation)也称作循环估计,是一个统计学的实用方法。即将训练集分成若干个互补的子集,然后模型使用这些子集的不同组合训练,之后用剩下的子集进行验证。
1.2.2 性能评估
机器学习模型对某个数据的预测结果与该样本的真实结果之间的差异称为误差(error)。 对模型的评价有很多方法,常用的指标如:准确率(Accuracy)、错误率(Error rate)、精确率(Precision)、召回率(Recall)和均方误差等。不同的测量方法也会产生不同的判断结果。
1.错误率(Error rate)
在分类任务中,经常使用错误率与精确率对算法进行评价。分类错误的样本数占样本总数的比例称为错误率。 用e代表错误率,其计算方法如下:
e = 分类错误的样本数 / 样本总数
| 真实结果 | 预测结果(只) | ||
| 猫 | 狗 | 兔 | |
| 猫 | 2 | 0 | 0 |
| 狗 | 0 | 1 | 1 |
| 兔 | 2 | 0 | 0 |
对于上表的数据:
- 可以计算模型总的分类错误率e为: e=(1+2)/6=0.5
- 模型对猫的分类错误率ecat为: ecat=0/2=0
- 模型对狗的分类错误率edog为: edog=1/2=0.5
- 模型对兔的分类错误率erabbit为: erabbit=2/2=1
可见,模型对猫的分类效果最好。
2.精确率、召回率、F-measure指数
- 精确率(Precision):查准率,可以表达系统的效用。
- 召回率(Recall):查全率,可以表达系统的完整性。
- F-measure指数:也称为f1指数,是精确率和召回率的调和平均值。
用公式表达如下: 精确率(p) = 正确识别的个体总数 / 识别出的个体总数
召回率:(r) = 正确识别的个体总数 / 测试集中存在的个体总数
调和平均值:(f1) = 2pr / (p+r)
| 真实结果 | 预测结果 | ||
| 猫 | 狗 | 兔 | |
| 猫 | 2 | 0 | 0 |
| 狗 | 0 | 1 | 1 |
| 兔 | 2 | 0 | 0 |
计算动物分类模型的精确率、召回率和f1指数
(1)对猫进行预测时——实际有2只猫;预测结果中有2只猫、2只兔被判断为猫,合计找到4只猫。其中2只预测正确,2只预测错误。 精确率p=2/4=0.5,召回率r=2/2=1,调和均值f1=2pr/(p+r)≈0.667。
(2)对狗进行预测时——实际有2条狗;预测结果中有1条狗被判断为狗,合计找到1条狗。这1条狗预测正确,但另1条没找到。 精确率p=1/1=1,召回率r=1/2=0.5,调和均值f1=2pr/(p+r)≈0.667。
(3)对兔进行预测时——实际有2只兔;预测结果中有1条狗被判断为兔,合计找到1只兔,但是判断错误。 精确率p=0/1=0,召回率r=0/2=0,调和均值f1=0。
| 类别 | 精确率p | 召回率r | f1指数 |
| 猫 | 0.5 | 1 | 0.667 |
| 狗 | 1 | 0.5 | 0.667 |
| 兔 | 0 | 0 | 0 |
3.评价指标
常用的指标有均方误差MSE(mean square error)、平均绝对误差MAE(Mean Absolute Deviation)。MSE值越小,说明机器学习模型的精确度越高。 还有R2(也称为R平方)指标,常用于回归问题。 还有ROC/AUC指标,适合数据集样本类不平衡的情况,其中ROC是接收者操作特征,AUC是Roc曲线下的面积。