C语言笔记
一、常量和变量、数据类型、运算符与表达式
(1)关键字与标识符的概念:关键字的含义,标识符的定 义,常量和变量的分类。
(2)数据类型:数据类型的含义、特点,不同类型常量的表达,不同类型变量的定义、赋初值方法。
(3)运算符:各类运算符的含义、优先级,各类表达式的表示方法、运算特点、值的类型和计算方法,各类公式的表达式 描述和各类表达式的混合运算。
常量和变量
Ⅰ:常量
1.整型常量
正整数、负整数、0都属于整型常量
例如:1000,12345,0,-345
2.实型常量
十进制小数形式,由数字和小数点组成 例如:123.456,0.345,-56.79,0.0,12.0
指数形式,12.34e3(代表12.34的10的3次方),e或E之前必须有数字,且e或E后面必须为整数。
3.字符型常量
1)普通字符
用单引号括起来的一个字符, 字符常量只能是一个字符,一般用ASCLII码存放。
例如’a‘,‘Z’,‘3’‘?’
ASCLII链接: link
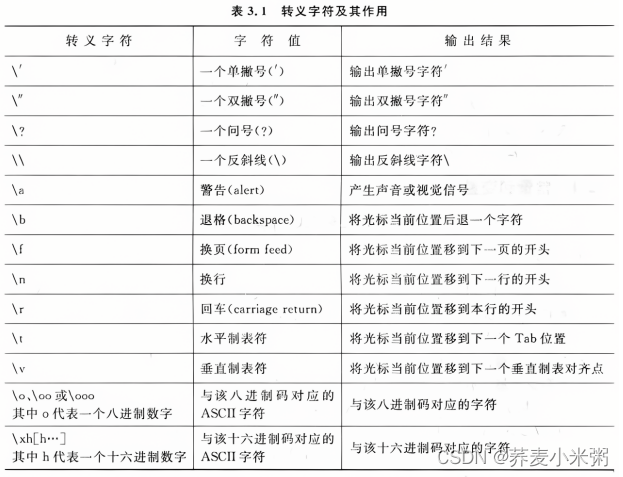
2)转义字符
特殊形式的字符常量以字符’\‘开头,将’\‘后面的字符转换成另外的意义
‘\0’ 是字符串的结束符,任何字符串之后都会自动加上’\0’
4.字符串常量
例如 “boy”,"123"等,用双引号把若干字符括起来称为字符串常量。
单引号内只能包含一个字符,双引号可以包含一个字符串。
5.符号常量
#define,指定用一个符号名称代表一个常量,是预处理指令。
#define PI 3.1415 //注意行末没有分号
此行开始所有的PI都代表3.1415
有2个好处
①含义清楚
②能一改全改
编译时仅仅进行字符替换,编译后符号常量就不存在了(全被替换成3.1415),不分配存储单元
Ⅱ:变量
变量代表一个有名字的、具有特定属性的一个存储单元。
必须先定义,后使用。
变量名就是给变量起的名字。
变量值就是变量所存储的数值。
Ⅲ:常变量const
注意:只在C99允许
常变量就是在定义变量时,前面加一个const关键字
const int a = 3;
这样变量存在的期间值就不能改变了
与符号常量不同,常变量需要占用存储单元,只是值不改变。
常变量有符号常量的优点比符号常量更好。
- const char * p
- char * const p
这里的 const 关键字是用于修饰常量,书上说 const 将修饰离它最近的对象,所以,以上两种声明的意思分别应该是:
- p是一个指向常量字符的指针,不变的是 char 的值,即该字符的值在定义时初始化后就不能再改变。
- p是一个指向字符的常量指针,不变的是 p 的值,即该指针不能再指向别的。
Ⅳ:标识符
对变量、符号常量名、函数、数组、类型等命名的有效字符序列统称为标识符
标识符只能由字母、数字、下划线三种字符组成、第一个字符必须为字母或下划线。
数据类型

基本类型和枚举类型变量的值都是数值,统称为算数类型。
算数类型和指针类型统称为纯量类型。
枚举类型是程序中用户定义的整数类型。
数组类型和结构体类型统称为组合类型,共用体类型不属于组合类型,因为在同一时间内只有一个成员具有值
Ⅰ:整型数据
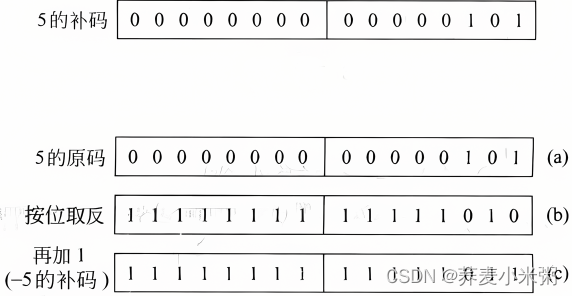
1、基本整形(int型)
4个字节存放,存储单元中的存储方式是用整数的补码形式存放。
2、短整型(short型)
2个字节存放,存储方式与int型相同
3、长整型(long型)
4个字节存放,在一个整数的末尾加大写字母L或者小写字母l代表长整型。
4、双长整型(long型)
8个字节存放,C99新增
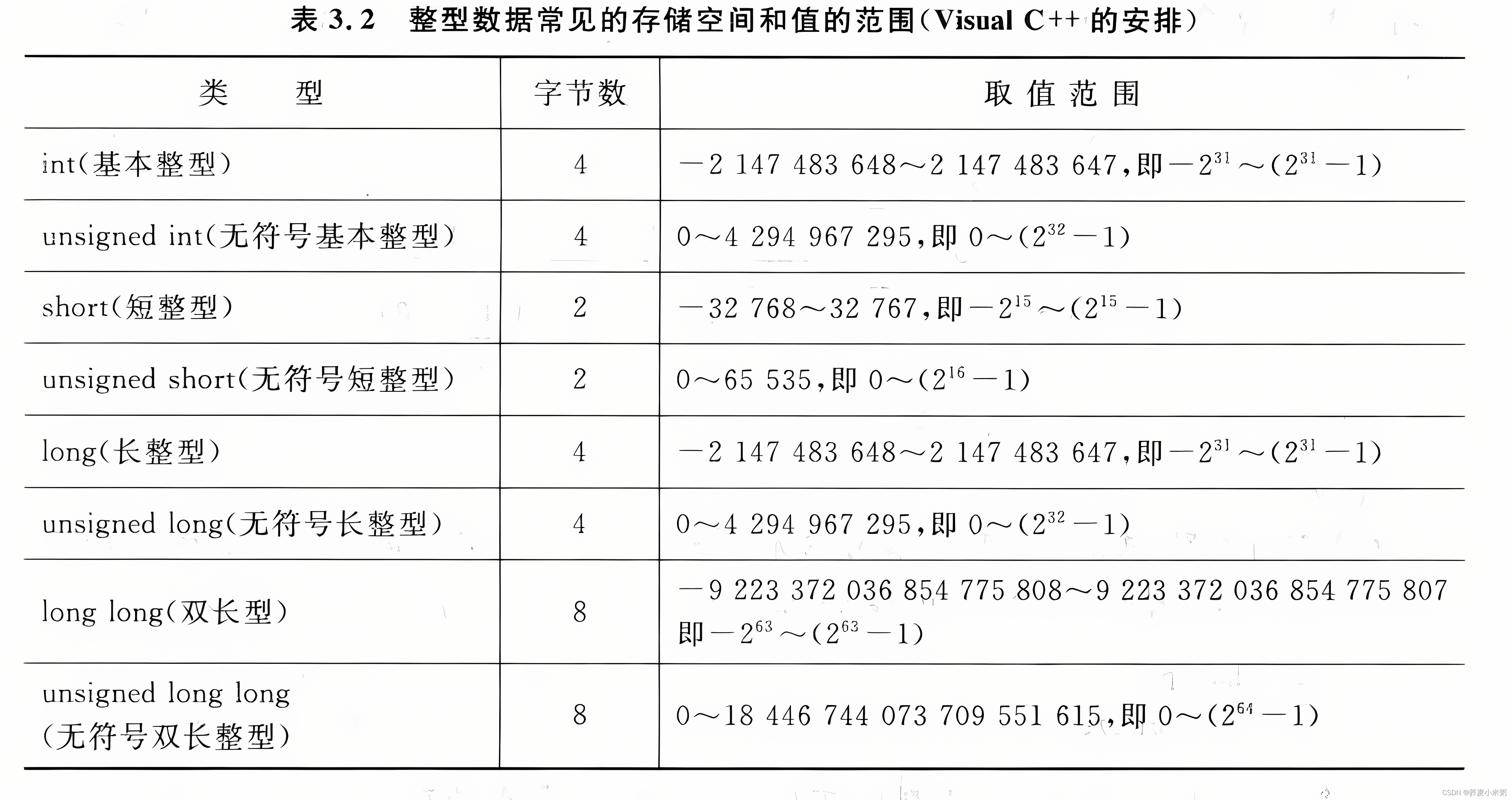
只有整形可以添加无符号unsigned或有符号signed,实型(浮点型)数据不能加
若在无符号整型赋予负数则会得到一个错误结果
Ⅱ:字符型数据
1、字符与字符代码
字符与字符代码不是随便写一个字符,程序都能识别。
目前大多数系统采用ASCII字符集才可以识别,所有字符存储都只占1个字节。
ASCLII链接: link
字符是以整数形式(字符的ASCII码)存储在内存单元中的。
字符‘1’按整数存储占1个字节
整数1按整型存储占2个字节或4个字节
2、字符变量
char c = '?';
定义c为字符型变量,并使初始值为字符'?'
'?'的ASCII码是63,系统把整数63赋给变量c.
printf("%d %c\n",c,c);
c是字符变量,实质上是一个字节的整型变量。
输出字符变量的值时,可以选择十进制整型输出,或以字符形式输出

字符类型也属于整形,也可以使用无符号unsigned或有符号signed
Ⅲ:浮点型数据
浮点型数据是用来表示具有小数点的实数的。
其中 e 或 E 被称为阶码标志,e 或 E 后面的有符号整数被称为阶码。阶码代表 10 的阶码次方。
例如:
-1.56E+12;
2.87e-3;
-8e1.0;错
浮点型常量可以省略正号,可以没有小数点或指数部分。
例如:
2E5;
19.28;
但是不能同时没有二者。
例如:
19;错
浮点型常量可以省略小数或者整数部分,但不能同时省略。
例如:
e3;错
注意:e前后的实数和整数不能省略。
-80.0e;错
注意:浮点型常量中不能有空格!例如:
3.21e -12 /* 有空格,错! /
3.14e5 / 有空格,错! */
注意:浮点型常量有阶码的小数点前面只能有一位非0的数字。
例如:
1.81e7;//对
18.1e6;//错
另外阶码后面只能是整数,不能是整数表达式。
5.0e(1+4);//错
总结: 浮点型常量可以省略正号。字母e或E之前必须要有数字,且e或E后面的指数必须为整数
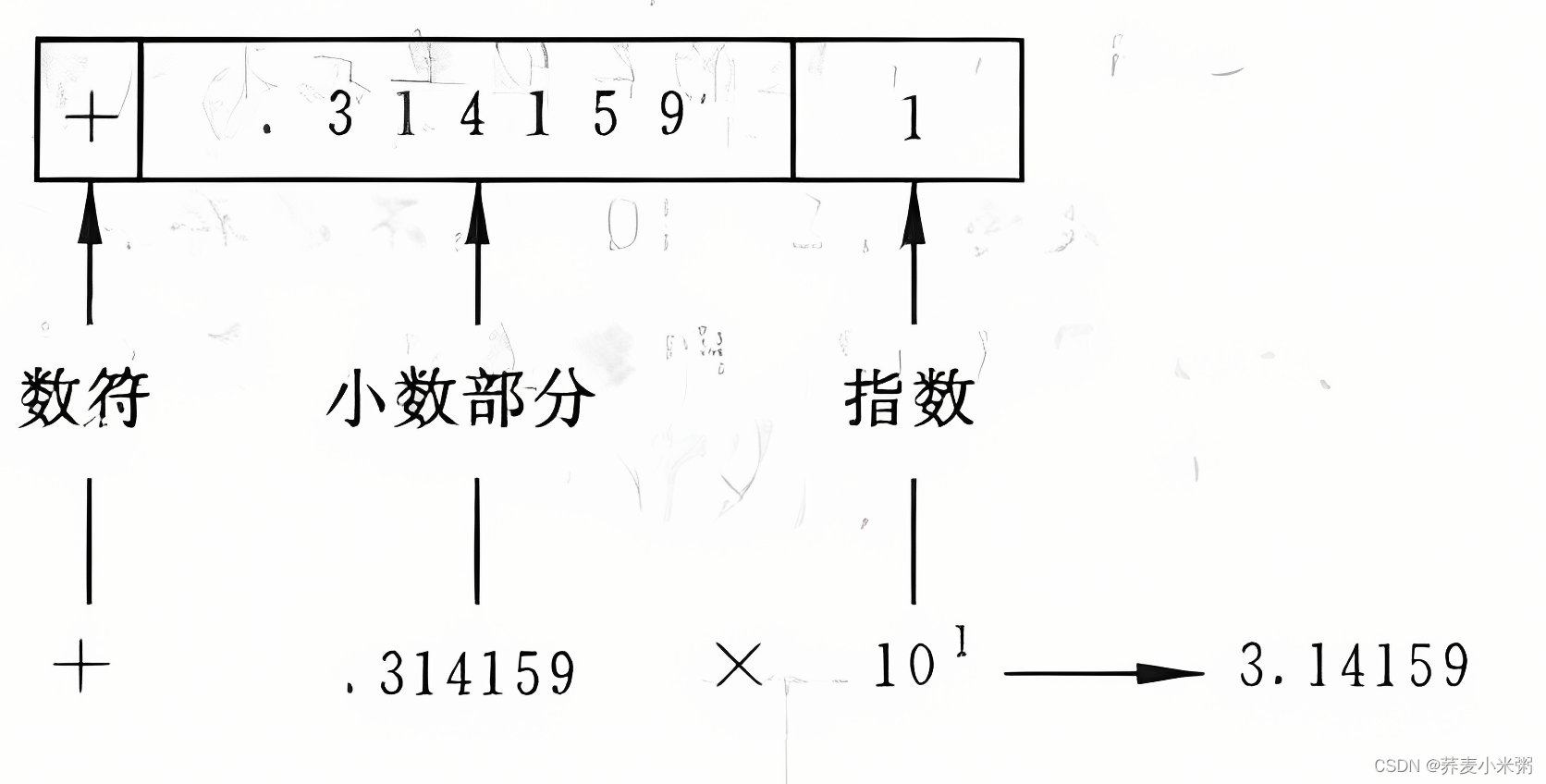
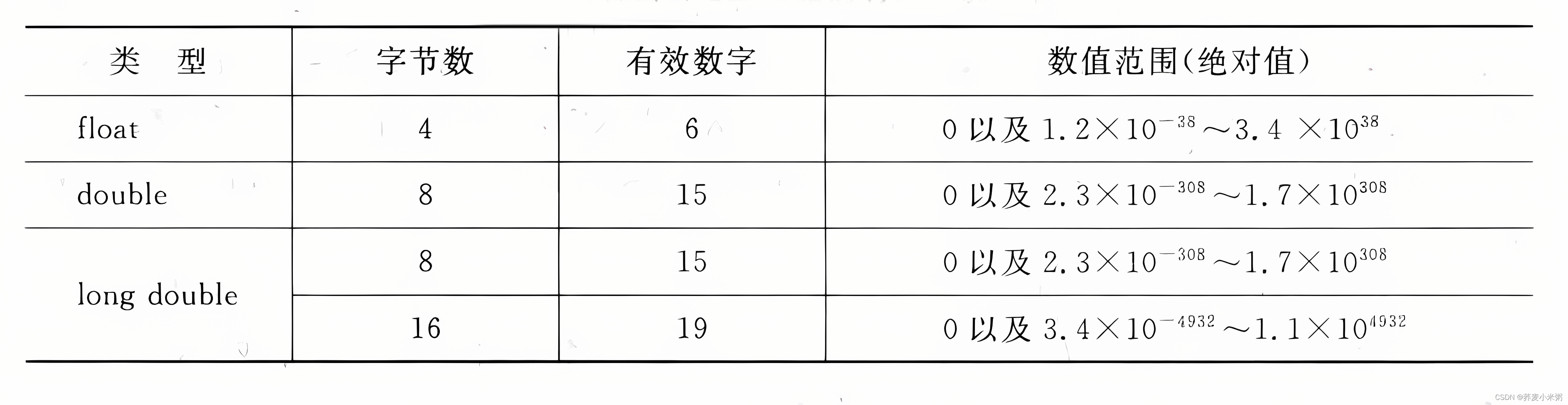
1、float型(单精度浮点型)
编译系统为每一个float型变量分配4个字节,数值以规范化的二进制指数形式存放在存储单元中。
系统将实型数据分成小数部分和指数部分两个部分,分别存放。
小数部分的小数点前面的数为0。例如3.14159
float型数据能得到6位有效数字(小数点后从左到右只有6个数字是精确的,后面就不精确了)
例如3.1415926有效数字只有141592
在3.14159后加字母f或F,表示float型常量
2、double型(双精度浮点型)
8个字节存储一个double型数据,可以得到15位有效数字。
在进行浮点数的算数运算时,将float型数据自动转换位double型,进行运算。
3、long double型(长双精度型)
8个字节存储一个数据,可以得到15位有效数字。Visual C++环境
16个字节存储一个数据,可以得到19位有效数字。Turbo环境
布尔类型
非零值,无论正负,均为真
运算符与表达式
算数操作符
+ - * / %
1. 除了 % 操作符之外,其他的几个操作符可以作用于整数和浮点数。
2. 对于 / 操作符如果两个操作数都为整数,执行整数除法。而只要有浮点数执行的就是浮点数除法。
3. % 操作符的两个操作数必须为整数。返回的是整除之后的余数。
/
整型/整型=整型
整型/实型=实型
实型/整型=实型
实型/实型=实型%
取余左右两边都为整形
5%2=1
5%-2=1
-5%2=-1
-5%-2=-1
移位操作符
<< 左移操作符
>> 右移操作符
注:移位操作符的操作数只能是整数。
左移操作符
移位规则:
左边抛弃、右边补0
右移操作符
移位规则:
首先右移运算分两种:
- 逻辑移位:左边用0填充,右边丢弃
- 算术移位:左边用原该值的符号位填充,右边丢弃
对于移位运算符,不要移动负数位,这个是标准未定义的。移动时原值并未改变例如:1<<-3
整数的二进制表示形式(原码反码补码)
原码:直接根据数值写出的二进制序列就是原码
反码:原码的符号位不变,其他位按位取反就是反码
补码:反码+1,就是补码
负数符号位是1负数原码反码补码如上所示
正数符号位是0正数原码反码补码都是原码
位操作符
位操作符有:
& 按位与
| 按位或
^ 按位异或
注:他们的操作数必须是整数。
& 按位与
0000 0011
0000 0101
两个数的结果为
0000 0001
上下都有则为真
| 按位或
0000 0011
0000 0101
两个数的结果为
0000 0111
上下有则为真
^ 按位异或
0000 0011
0000 0101
两个数的结果为
0000 0110
相同为0,相异为1
赋值操作符
+=
-=
*=
/=
%=
>>=
<<=
&=
|=
^=
单目操作符
! 逻辑反操作
- 负值
+ 正值
& 取地址
sizeof 操作数的类型长度(以字节为单位)
~ 对一个数的二进制按位取反
~n = -(n+1)
-- 前置、后置--
++ 前置、后置++
* 间接访问操作符(解引用操作符) (类型)
* 强制类型转换
关系操作符
>
>=
<
<=
!= 用于测试“不相等”
== 用于测试“相等”
逻辑操作符
&& 逻辑与
前为假后面不计算
|| 逻辑或
前为真后面不计算
按位与
1&2----->0
逻辑与
1&&2---->1
按位或
1|2----->3
逻辑或
1||2---->1
条件操作符
exp1 ? exp2 : exp3
max = ( a > b ? a : b )
逗号表达式
exp1, exp2, exp3, …expN
逗号表达式,就是用逗号隔开的多个表达式。
逗号表达式,从左向右依次执行。整个表达式的结果是最后一个表达式的结果。
如何进行运算: link
下标引用、函数调用和结构成员
1. [ ] 下标引用操作符
操作数:一个数组名 + 一个索引值
int arr[10];//创建数组
arr[9] = 10;//实用下标引用操作符。
[ ]的两个操作数是arr和9。
2. ( ) 函数调用操作符
接受一个或者多个操作数:第一个操作数是函数名,
剩余的操作数就是传递给函数的参数。
#include <stdio.h>
void test1()
{
printf("hehe\n");
}
void test2(const char *str)
{
printf("%s\n", str);
}
int main()
{
test1(); //实用()作为函数调用操作符。
//test1是操作数
test2("hello bit.");//实用()作为函数调用操作符。
//test2与hello bit.都是操作数
return 0;
}
3. 访问一个结构的成员
. 结构体.成员名
-> 结构体指针->成员名
#include<stdio.h>
struct Book
{
char name[20];
char id[20];
int price;
}
int main()
{
struct Book b = {"C语言","c123",51};
struct Book * pb = &b;//将b的存储地址取出来赋值给pb
printf("书名:%s\n",b.name);
printf("书号:%s\n",b.id);
printf("定价:%d\n",b.price);
*pb进行解引用等同于b
printf("书名:%s\n",(*pb).name);
printf("书号:%s\n",(*pb).id);
printf("定价:%d\n",(*pb).price);
指针进行指向
printf("书名:%s\n",pb -> name);
printf("书号:%s\n",pb -> id);
printf("定价:%d\n",pb -> price);
}
表达式求值
表达式求值的顺序一部分是由操作符的优先级和结合性决定。
同样,有些表达式的操作数在求值的过程中可能需要转换为其他类型。
隐式类型转换
C的整型算术运算总是至少以缺省整型类型的精度来进行的。
为了获得这个精度,表达式中的字符和短整型操作数在使用之前被转换为普通整型,这种转换称为整型提升。
整型提升的意义:
表达式的整型运算要在CPU的相应运算器件内执行,CPU内整型运算器(ALU)的操作数的字节长度
一般就是int的字节长度,同时也是CPU的通用寄存器的长度。
因此,即使两个char类型的相加,在CPU执行时实际上也要先转换为CPU内整型操作数的标准长 度。
通用CPU(general-purpose CPU)是难以直接实现两个8比特字节直接相加运算(虽然机器指令中可能有这种字节相加指令)。所以,表达式中各种长度可能小于int长度的整型值,都必须先转 换为int或unsigned int,然后才能送入CPU去执行运算。
如何进行整体提升呢?
整形提升是按照变量的数据类型的符号位来提升的
//负数的整形提升
char c1 = -1;
变量c1的二进制位(补码)中只有8个比特位:
1111111
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为1
提升之后的结果是:
11111111111111111111111111111111
//正数的整形提升
char c2 = 1;
变量c2的二进制位(补码)中只有8个比特位:
00000001
因为 char 为有符号的 char
所以整形提升的时候,高位补充符号位,即为0
提升之后的结果是:
00000000000000000000000000000001
//无符号整形提升,高位补0
算术转换
如果某个操作符的各个操作数属于不同的类型,那么除非其中一个操作数的转换为另一个操作数的类型,否则操作就无法进行。下面的层次体系称为寻常算术转换。
long double
double
float
unsigned long int
long int
unsigned int
int
如果某个操作数的类型在上面这个列表中排名较低,那么首先要转换为另外一个操作数的类型后执行运
算。
操作符的属性
- 操作符的优先级
- 操作符的结合性
- 是否控制求值顺序。
优先级
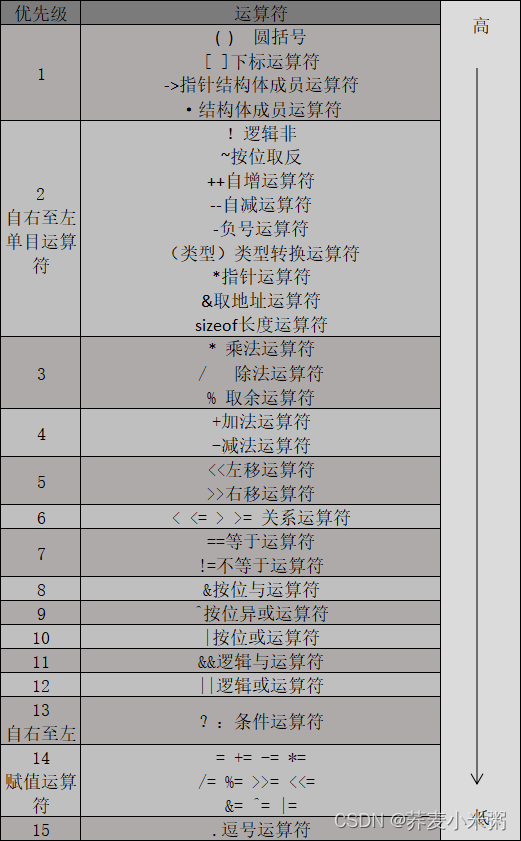
2是唯一的单目运算符,13是唯一的三目运算符,其余全是二目运算符。
三目运算符要有3个参数,二目运算符则需要2个参数。
单目运算符(2)、赋值运算符(14)、条件运算符(13)是右结合性(从右至左运算),其余全是左结合性(从左至右运算)。
二、顺序结构程序设计
(1)输入输出:常用的输入输出函数,基本的输入输出格式。
(2)赋值语句:赋值语句功能和表达方法。
(3)顺序程序设计:编写顺序结构语句及程序。
数据格式在scanf中的应用
1) 比给定的数据格式小或相等
如输入 12 ,输出到屏幕上为 n=12;
如输入 123,输出到屏幕上为 n=123;
在scanf中,当输入的数据长度比给定的数据格式小或者相等时时,常规存取值到指定的地址处。
2) 比给定的数据格式大
如输入 12345, 输出到屏幕上为 n =123。
在scanf中,当输入的数据长度比给定的数据格式大时scanf函数会截取值存入指定的地址处。
“%(数字)d”(或者其他转换字符)此数字在scanf中表示 最大字段宽度 。意思为,你不能输入字段比此数字还大的。即输入到达最大字段宽度时,超过宽度后面的将不再作为输入内容(相当于作废),在最大宽度内的为输入内容。
scanf总结
1、scanf只能限定宽度不允许限定精度
2、scanf不允许添加\n换行符
3、scanf不允许能忘记添加取地址符&
4、scanf的普通字符一定要原样输入
数据格式在printf中的应用
%3d是C语言中格式化输出字符,代表的意思是指的输出3个字符长度的整数。
可以在“%”和字母之间插进数字表示最大场宽。
1)数据格式小于变量长度
如printf直接用 %3d 打印 n ,输出为 12345 。
如printf直接用 %3s 打印数组 arr,输出为 Hello 。
就是说,在printf中,当变量长度比数据格式大时,printf与用"%d"数据格式输入完全相同,即原样输出。
2)数据格式大于变量长度
如printf用 %8d 打印 n ,输出为 - - -12345 。
如printf用 %-8d 打印 n ,输出为 12345- - -。
如printf用 %8s 打印 arr ,输出为 - - -Hello
如printf用 %-8s 打印 arr ,输出为 Hello- - -
例:%5d表示输出5位整型数,不够5位右对齐,左补空格。
而在"%-3d"中,-号表示对齐方式,即左对齐,右补空格。如果是+号或者不写,表示右对齐。
printf既能限定宽度又能限定小数位数(宽度要包括小数点)
特别提示
0开头是8进制
0x或0X开头是16进制数字
三、选择结构程序设计
(1)条件的表达方式:算术表达式、关系表达式、逻辑表 达式,各种运算结果的表达与判别。
(2)条件语句:if 语句、if…else 语句、if…else 嵌套 结构以及 switch…case 和 break 语句的使用方法。
(3)选择结构程序设计:编写带有选择结构的语句及程序。
四、循环结构程序设计
(1)循环语句 while、do…while 和 for 语句的格式、循环条件的设置以及在循环结构中使用 break 和 continue 语句。
(2)循环程序设计:编写带有循环结构语句及程序。
while(n)等同于while(n!=0)
五、数组
(1)数组的概念:数组的概念、一维数组和二维数组。
(2)数组的使用:数组的定义、数组的初始化、数组元素的引用,数组的一般编程方法。
一维数组
数组的创建
type_t arr_name [const_n];
//type_t 是指数组的元素类型
//const_n 是一个常量表达式,用来指定数组的大小
数组创建的实例
//代码1
int arr1[10];
//代码2
int count = 10;
int arr2[count];//数组时候可以正常创建?
//变长数组gcc编译可以正常创建
//代码3
char arr3[10];
float arr4[1];
double arr5[20];
注:数组创建,在C99标准之前, [] 中要给一个常量才可以,不能使用变量。在C99标准支持了变长数组的概念。
数组的初始化
数组的初始化是指,在创建数组的同时给数组的内容一些合理初始值(初始化)。
//整形数组
int arr1[10] = {1,2,3,4,5,6,7,8,9,10};//完全初始化
int arr2[10] = {1,2,3,4,5};//不完全初始化
int arr3[] = {1,2,3,4,5};//等同于int arr3[5] = {1,2,3,4,5};
//字符数组
char ch4[5] = {'b','i', 't'};//会在之后补0
char ch5[] = {'a','b','c'}; //等同于char ch5[3] = {'a','b','c'};
char ch6[5] = "bit";//b i t \0 0
char ch7[] = "bit";//b i t \0
一维数组的使用
#include <stdio.h>
int main()
{
int arr[10] = {0};//数组的不完全初始化
//计算数组的元素个数
int sz = sizeof(arr)/sizeof(arr[0]);
//对数组内容赋值,数组是使用下标来访问的,下标从0开始。所以:
int i = 0;//做下标
for(i=0; i<10; i++)
{
arr[i] = i;
}
//输出数组的内容
for(i=0; i<10; ++i)//如果数组的大小改变,下标无法改变
{
printf("%d ", arr[i]);
}
return 0; }
总结:
- 数组是使用下标来访问的,下标是从0开始。
- 数组的大小可以通过计算得到。
一维数组在内存中的存储
#include <stdio.h>
int main()
{
//%p输出指定参数的16进制地址(完整的8位地址)
//%x可以输出指定参数的16进制
int arr[10] = {0};
int i = 0;
int sz = sizeof(arr)/sizeof(arr[0]);
for(i=0; i<sz; ++i)
{
printf("&arr[%d] = %p\n", i, &arr[i]);
}
return 0; }
数组在内存中是连续存放的。
二维数组
二维数组的创建
//数组创建
int arr[3][4];
char arr[3][5];
double arr[2][4];
二维数组的初始化
//数组初始化
int arr[3][4] = {1,2,3,4};
int arr[3][4] = {{1,2},{4,5}};
int arr[][4] = {{2,3},{4,5}};
//二维数组如果有初始化,行可以省略,列不能省略
二维数组的使用
#include <stdio.h>
int main()
{
int arr[3][4] = {0};
int i = 0;
for(i=0; i<3; i++)
{
int j = 0;
for(j=0; j<4; j++)
{
arr[i][j] = i*4+j;
}
}
for(i=0; i<3; i++)
{
int j = 0;
for(j=0; j<4; j++)
{
printf("%d ", arr[i][j]);
}
}
return 0;
}
二维数组在内存中的存储
#include <stdio.h>
int main()
{
int arr[3][4];
int i = 0;
for(i=0; i<3; i++)
{
int j = 0;
for(j=0; j<4; j++)
{
printf("&arr[%d][%d] = %p\n", i, j,&arr[i][j]);
}
}
return 0; }
二维数组在内存中也是连续存储的。
数组越界
数组的下标是有范围限制的。 数组的下规定是从0开始的,如果数组有n个元素,最后一个元素的下标就是n-1。
所以数组的下标如果小于0,或者大于n-1,就是数组越界访问了,超出了数组合法空间的访问。
C语言本身是不做数组下标的越界检查,编译器也不一定报错,但是编译器不报错,并不意味着程序就 是正确的。
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int i = 0;
for(i=0; i<=10; i++)
{
printf("%d\n", arr[i]);//当i等于10的时候,越界访问了
}
return 0; }
二维数组的行和列也可能存在越界。
数组作为函数参数
冒泡排序
//方法1:
#include <stdio.h>
void bubble_sort(int arr[],int sz)
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
int main()
{
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr, sz);//是否可以正常排序?
for(int i=0; i<sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
数组名是什么?
#include <stdio.h>
int main()
{
int arr[10] = {1,2,3,4,5};
int sz = sizeof(arr);
//数组名表示整个数组
//计算整个数组的大小
//单位是字节
printf("%p\n", arr);//数组首元素的地址
printf("%p\n", &arr[0]);//数组首元素的地址等同于第一个
printf("%d\n", *arr);//数组名表示整个数组,取出数组的地址
//输出结果
return 0;
}
数组名是数组首元素的地址。(有两个例外)
1. sizeof(数组名),计算整个数组的大小,sizeof内部单独放一个数组名,数组名表示整个数组。
2. &数组名,取出的是数组的地址。&数组名,数组名表示整个数组。
六、函数
(1)函数:函数定义的格式,包括类型、参数及返回值。
(2)存储类别:存储类别的含义、使用方法。
(3)函数的运用:定义函数、调用函数、递归函数
sizeof关键字
sizeof的功能是计算一个数据类型的大小,这个类型可以是数组、函数、指针、对象等,单位为字节,它的返回值是size_t类型,也就是unsigned int类型,是一个无符号整数。注意:sizeof不是一个函数,它是一个运算符,所以它不需要包含任何头文件。
strlen函数
strlen的功能是计算一个指定字符串的长度,函数原型是size_t strlen(const char *s),它的返回值是size_t类型,也就是unsigned int类型,返回的是字符串的长度,需要包含头文件#inlude <string.h>,参数s是字符串首地址。
strlen函数与sizeof关键字的比较
1、sizeof会将空字符\0计算在内,而strlen不会将空字符\0计算在内;
2、sizeof会计算到字符串最后一个空字符\0并结束,而strlen如果遇到第一个空字符\0的话就会停止并计算遇到的第一个空字符\0前面的长度。
库函数
库函数的常用种类
简单的总结,C语言常用的库函数都有:
IO函数
字符串操作函数
字符操作函数
内存操作函数
时间/日期函数
数学函数
其他库函数
学习库函数的网站:链接: link
库函数的举例
strcpy(复制数组)
strcpy库函数的作用复制数组内容
char * strcpy ( char * destination, const char * source );
要复制到的地方 要复制的内容
/* strcpy example */
#include <stdio.h>
使用库函数,必须包含 #include 对应的头文件。example:strcpy的库函数就是string.h
#include <string.h>
int main ()
{
char str1[]="Sample string";
char str2[40];
char str3[40];
strcpy (str2,str1);
strcpy (str3,"copy successful");
printf ("str1: %s\nstr2: %s\nstr3: %s\n",str1,str2,str3);
return 0;
}
输出结果如下
str1: Sample string
str2: Sample string
str3: copy successful
memset(内存设置)
void * memset ( void * ptr, int value, size_t num );
需要设置的地方 设置的内容 设置的个数(从左到右数有几个就更改几个)
/* memset example */
#include <stdio.h>
#include <string.h>
int main ()
{
char str[] = "almost every programmer should know memset!";
memset (str,'-',6);
puts (str);
return 0;
}
输出结果如下
------ every programmer should know memset!
自定义函数
ret_type fun_name(para1, * )
{
statement;//语句项
}//函数体
ret_type 返回类型
fun_name 函数名
para1 函数参数
自定义函数举例
求一个最大值
#include <stdio.h>
//get_max函数的设计
int get_max(int x, int y) {
return (x>y)?(x):(y);
}
int main()
{
int num1 = 10;
int num2 = 20;
int max = get_max(num1, num2);
printf("max = %d\n", max);
return 0;
}
(重点)函数只能返回一个值
#include <stdio.h>
//实现成函数,但是不能完成任务
void Swap1(int x, int y) {//形式参数//传值调用
int tmp = 0;
tmp = x;
x = y;
y = tmp; }
//正确的版本采用指针的方法将地址传过来
void Swap2(int *px, int *py) {//形式参数//传址调用
int tmp = 0;
tmp = *px;
*px = *py;
*py = tmp; }
int main()
{
int num1 = 1;
int num2 = 2;
Swap1(num1, num2);//实际参数
printf("Swap1::num1 = %d num2 = %d\n", num1, num2);
Swap2(&num1, &num2);//实际参数
printf("Swap2::num1 = %d num2 = %d\n", num1, num2);
return 0;
}
函数的参数(重点)
实际参数(实参)
真实传给函数的参数,叫实参。 实参可以是:常量、变量、表达式、函数等。 无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形 参。
形式参数(形参)
重点:形参实例化之后其实相当于实参的一份临时拷贝。(实参和形参使用的不是同一空间)
形式参数是指函数名后括号中的变量,因为形式参数只有在函数被调用的过程中才实例化(分配内 存单元),所以叫形式参数。形式参数当函数调用完成之后就自动销毁了。因此形式参数只在函数中有 效。
举例如上(函数只能返回一个值):
上面 Swap1 和 Swap2 函数中的参数 x,y,px,py 都是形式参数。
在main函数中传给 Swap1 的 num1 ,num2 和传给 Swap2 函数的 &num1,&num2 是实际参数。
函数的调用
传值调用
函数的形参和实参分别占有不同内存块,对形参的修改不会影响实参。
传址调用
传址调用是把函数外部创建变量的内存地址传递给函数参数的一种调用函数的方式。 这种传参方式可以让函数和函数外边的变量建立起真正的联系,也就是函数内部可以直接操 作函数外部的变量。
举例:
#include <stdio.h>
void Add(int*p)//修改的是地址里面的值
{
(*p)++;
}
int main()
{
int num = 0;
//调用函数,使得num每次增加1
Add(&num);//将变量num的地址值传过去
printf("%d\n",num);
return 0; }
函数的嵌套调用和链式访问
嵌套调用
函数和函数之间可以根据实际的需求进行组合的,也就是互相调用的。
函数可以嵌套调用,但是不能嵌套定义。
#include <stdio.h>
void new_line()
{
printf("hehe\n");
}
void three_line()
{
int i = 0;
for(i=0; i<3; i++)
{
new_line();//嵌套调用
}
}
int main()
{
three_line();//嵌套调用
return 0;
}
链式访问
把一个函数的返回值作为另外一个函数的参数。
#include <stdio.h>
#include <string.h>
int main()
{
char arr[20] = "hello";
int ret = strlen(strcat(arr,"bit"));
//strcat函数表示追加字符串arr表示目标数组"bit"表示追加到结尾的内容
//strlen计算字符串的长度,直到空结束字符,但不包括空结束字符。
printf("%d\n", ret);
return 0; }
#include <stdio.h>
int main()
{
printf("%d", printf("%d", printf("%d", 43)));
//打印为4321
//printf返回的是打印的个数
return 0; }
函数的声明和定义(重点)
函数声明
- 告诉编译器有一个函数叫什么,参数是什么,返回类型是什么。但是具体是不是存在,函数声明决定不了。
- 函数的声明一般出现在函数的使用之前。要满足先声明后使用。
- 函数的声明一般要放在头文件中的(重点)
链接: link
函数的定义
函数的定义是指函数的具体实现,交待函数的功能实现。
int main()
{
int a = 10;
int b = 20;
//函数声明
//当函数写在main函数之后时需要提前声明函数*不然会报错
//当函数的定义写在main函数之前则不需要声明
int Add(int,int)
int c = Add(a,b);
printf("%d",c);
return 0;
}
//函数的定义
int Add(int x,int y)
{
return x+y;
}
函数的递归(重点)
递归是什么
程序调用自身的编程技巧称为递归( recursion)。 递归做为一种算法在程序设计语言中广泛应用。
一个过程或函数在其定义或说明中有直接或间接 调用自身的
一种方法,它通常把一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解, 递归策略
只需少量的程序就可描述出解题过程所需要的多次重复计算,大大地减少了程序的代码量。 递归的主要思考方式在于:把大事化小
递归的条件
存在限制条件,当满足这个限制条件的时候,递归便不再继续。
每次递归调用之后越来越接近这个限制条件。
递归的举例
#include <stdio.h>
接受一个整型值(无符号),按照顺序打印它的每一位。
例如:
输入:123,输出 1 2 3
void print(int n) 将值传入这
{
if(n>9)
{
print(n/10);
}
printf("%d ", n%10);
}
int main()//主函数
{
int num = 123;
print(num);运行到这时
return 0; }
1.当主函数的开始运行到print(num);时
2. 会将num的值传入print函数
3.开始判断是否大于9
4.123大于9则采用递归
5.123/10之后再次进入print函数
6.12大于9则采用递归
7.12/10之后再次进入print函数
8.1小于9则执行printf函数1%10后打印进行得到1
9.函数执行完毕后回到第七步的12/10进行递归的地方
10.然后执行printf函数12%10后打印进行得到2
11.函数执行完毕后回到第5步的123/10进行递归的地方
12.然后执行printf函数123%10后打印进行得到3
函数执行完毕以后要回到函数开始执行的地方
七、指针
(1)指针概念:指针的概念,指针的类型、指针的分类。
(2)指针的运用:运用指针处理变量、数组、字符串、函 数等。
指针的定义
1.指针就是地址,口语中说的指针通常指的是指针变量
2.我们可以通过&(取地址操作符)取出变量的内存其实地址,把地址可以存放到一个变量中,这个变量就是指针变量
3.指针是用来存放地址的,地址是唯一标示一块地址空间的。
4.指针的大小在32位平台是4个字节,在64位平台是8个字节
指针类型的意义
指针±整数
指针的类型决定了指针向前或者向后走一步有多大(距离)。
#include <stdio.h>
//演示实例
int main()
{
int n = 10;
char *pc = (char*)&n;
int *pi = &n;
printf("%p\n", &n);
printf("%p\n", pc);
printf("%p\n", pc+1);指针类型为字符型大小加1个字节
printf("%p\n", pi);
printf("%p\n", pi+1);指针类型为整型大小加4个字节
return 0;
}
指针的解引用
指针的类型决定了,对指针解引用的时候有多大的权限(能操作几个字节)。
比如:
char* 的指针解引用就只能访问一个字节
int*的指针的解引用就能访问四个字节。
//演示实例
#include <stdio.h>
int main()
{
int n = 0x11223344;
char *pc = (char *)&n;
int *pi = &n;
*pc = 0; //重点在调试的过程中观察内存的变化。
*pi = 0; //重点在调试的过程中观察内存的变化。
return 0;
}
野指针
概念: 野指针就是指针指向的位置是不可知的(随机的、不正确的、没有明确限制的)
野指针成因
1. 指针未初始化
#include <stdio.h>
int main()
{
int *p;//局部变量指针未初始化,默认为随机值
*p = 20;
return 0;
}
如果不知道指针初始化什么就初始化为int *p = NULL;
2. 指针越界访问
#include <stdio.h>
int main()
{
int arr[10] = {0};
int *p = arr;
int i = 0;
for(i=0; i<=11; i++)
{
//当指针指向的范围超出数组arr的范围时,p就是野指针
*(p++) = i;
}
return 0;
}
3. 指针指向的空间释放
#include <stdio.h>
int* test()
{
int a = 10;
return &a;//将a的地址传递回去
}
int main()
{
int* p = test();//a的地址在接收时a的地址已经被内存收回
*p = 20;
return 0;
}
如何规避野指针
- 指针初始化
- 小心指针越界
- 指针指向空间释放即使置NULL
- 避免返回局部变量的地址
- 指针使用之前检查有效性
#include <stdio.h>
int main()
{
int *p = NULL;
//....
int a = 10;
p = &a;
if(p != NULL)
{
*p = 20;
}
return 0;
}
指针运算
指针±整数
加减整数看数据类型
char型加减1个字节
int型加减4个字节
#define N_VALUES 5
float values[N_VALUES];
float *vp;
//指针+-整数;指针的关系运算
for (vp = &values[0]; vp < &values[N_VALUES];)
{
*vp++ = 0;
}
指针-指针
指针-指针的前提是两指针指向同一块空间
返回的是两个指针之间的元素个数
int my_strlen(char *s)
{
char *p = s;
while(*p != '\0' )
p++;
return p-s;
}
指针的关系运算
for(vp = &values[N_VALUES]; vp > &values[0];)
{
*--vp = 0;
}
允许指向数组元素的指针与指向数组最后一个元素后面的那个内存位置的指针比较,但是不允许与 指向第一个元素之前的那个内存位置的指针进行比较。
指针和数组
数组名表示的是数组首元素的地址。
二级指针
int main()
{
int a = 10;
int *pa = &a;取a的地址给指针变量pa
int * *ppa = &pa;取一级指针变量pa的地址给二级指针ppa
return 0;
}
八、预处理命令
(1)预处理概念:宏的含义,文件包含的含义。
(2)预处理的运用:无参宏和有参宏,系统头文件的加载。
九、结构体、共用体和枚举类型
(1)结构体与共用体的概念:结构体的含义,共用体的含 义。
(2)结构体与共用体的运用:结构体与共用体的类型声明、 初始化和引用。
十、文件
(1)文件的概念:文件的定义、分类和特点。
(2)文件的基本操作:文件打开与关闭、文件读/写操作, 出错检测。