- 《datawhale2411组队学习之模型压缩技术1:模型剪枝(上)》:介绍模型压缩的几种技术;模型剪枝基本概念、分类方式、剪枝标准、剪枝频次、剪枝后微调等内容
- 《datawhale11月组队学习 模型压缩技术2:PyTorch模型剪枝教程》:介绍PyTorch的prune模块具体用法
- 《datawhale11月组队学习 模型压缩技术3:2:4结构稀疏化BERT模型》:介绍基于模式的剪枝——2:4结构稀疏化及其在BERT模型上的测试效果
一、 半结构化稀疏性简介
- 全文参考《Accelerating BERT with semi-structured (2:4) sparsity》
- Requirements:PyTorch >= 2.1,A NVIDIA GPU with semi-structured sparsity support (Compute Capability 8.0+).
半结构化稀疏性(Semi-structured Sparsity) 是一种模型优化技术,旨在通过减少神经网络的内存开销和延迟,来加速模型的推理,同时可能会稍微牺牲模型的准确性。它也被称为细粒度结构化稀疏或2:4结构化稀疏。
N:M 稀疏度表示 DNN 的稀疏度,即每M个连续权重中固定有N个非零值,其余元素均置为0。一个简单的想法是,避免使用这些参数进行存储/计算。但仅仅将参数归零不会得到显著提升性能,因为密集矩阵乘法内核(dense kernels)仍会计算包含零的元素。
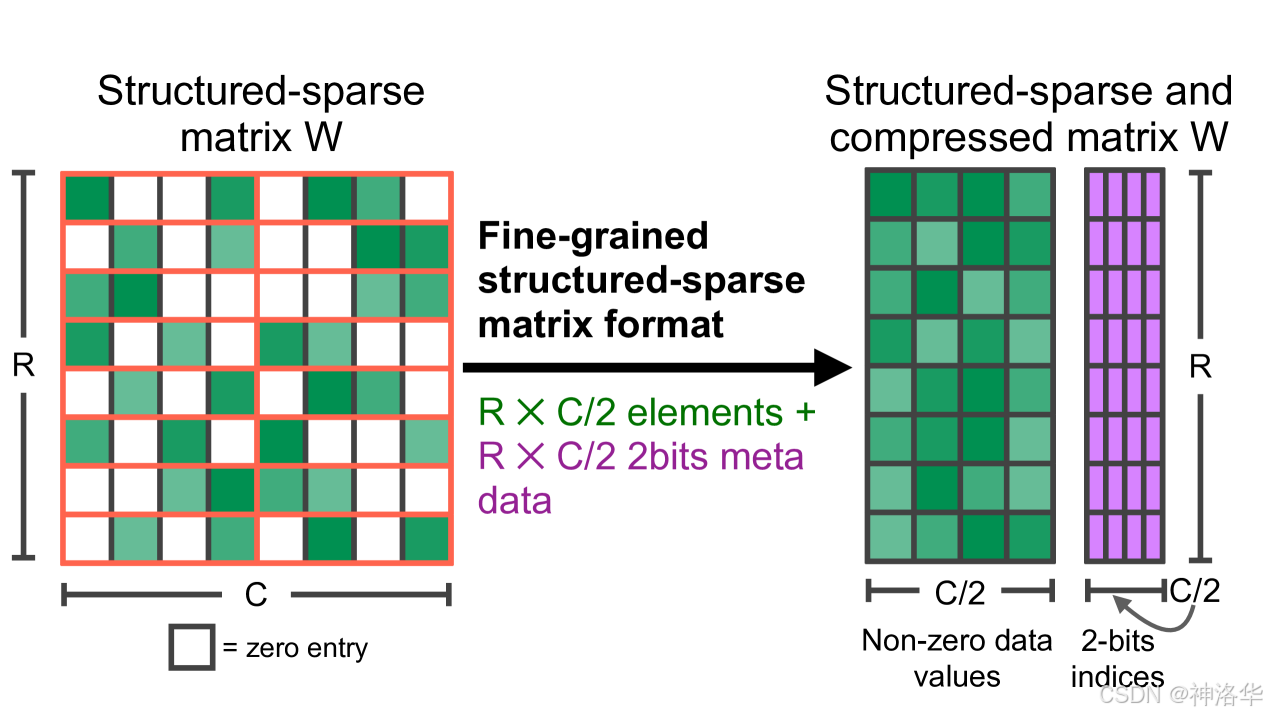
半结构化稀疏性通过采用稀疏矩阵和压缩存储格式来跳过对零元素的计算,从而提升性能。稀疏矩阵W首先会被压缩,压缩后的矩阵存储着非零的数据值,而metadata则存储着对应非零元素在原矩阵W中的索引信息(非零元素的行号和列号压缩成两个独立的一维数组)如下图所示:
NVIDIA在其Ampere架构中引入了对半结构化稀疏性的硬件支持,并发布了快速的稀疏矩阵内核(sparse kernels,例如CUTLASS/cuSPARSELt),使得这种稀疏性模式可以高效加速。另外,与其他稀疏格式相比,半结构化稀疏对模型准确性的影响较小(剪枝后再微调):
| Network | Data Set | Metric | Dense FP16 | Sparse FP16 |
|---|---|---|---|---|
| ResNet-50 | ImageNet | Top-1 | 76.1 | 76.2 |
| ResNeXt-101_32x8d | ImageNet | Top-1 | 79.3 | 79.3 |
| Xception | ImageNet | Top-1 | 79.2 | 79.2 |
| SSD-RN50 | COCO2017 | bbAP | 24.8 | 24.8 |
| MaskRCNN-RN50 | COCO2017 | bbAP | 37.9 | 37.9 |
| FairSeq Transformer | EN-DE WMT14 | BLEU | 28.2 | 28.5 |
| BERT-Large | SQuAD v1.1 | F1 | 91.9 | 91.9 |
从工作流角度看,由于半结构化稀疏性的稀疏度固定为50%,它简化了稀疏化过程,并将其分为两个子问题:一是如何找到最优的2:4稀疏权重以最小化准确性损失;二是如何加速2:4稀疏权重的推理性能并减少内存开销。
在本教程中,我们将对BERT问答模型进行2:4稀疏化。在微调后,模型准确性损失很小(F1得分86.92 vs 86.48),但推理速度提升了1.3倍。
二、 代码实践
2.1 定义辅助函数
import collections
import datasets
import evaluate
import numpy as np
import torch
import torch.utils.benchmark as benchmark
from torch import nn
from torch.sparse import to_sparse_semi_structured, SparseSemiStructuredTensor
from torch.ao.pruning import WeightNormSparsifier
import transformers
# force CUTLASS use if cuSPARSELt is not available
SparseSemiStructuredTensor._FORCE_CUTLASS = True
torch.manual_seed(100)
def preprocess_validation_function(examples, tokenizer):
inputs = tokenizer(
[q.strip() for q in examples["question"]],
examples["context"],
max_length=384,
truncation="only_second",
return_overflowing_tokens=True,
return_offsets_mapping=True,
padding="max_length",
)
sample_map = inputs.pop("overflow_to_sample_mapping")
example_ids = []
for i in range(len(inputs["input_ids"])):
sample_idx = sample_map[i]
example_ids.append(examples["id"][sample_idx])
sequence_ids = inputs.sequence_ids(i)
offset = inputs["offset_mapping"][i]
inputs["offset_mapping"][i] = [
o if sequence_ids[k] == 1 else None for k, o in enumerate(offset)
]
inputs["example_id"] = example_ids
return inputs
def preprocess_train_function(examples, tokenizer):
inputs = tokenizer(
[q.strip() for q in examples["question"]],
examples["context"],
max_length=384,
truncation="only_second",
return_offsets_mapping=True,
padding="max_length",
)
offset_mapping = inputs["offset_mapping"]
answers = examples["answers"]
start_positions = []
end_positions = []
for i, (offset, answer) in enumerate(zip(offset_mapping, answers)):
start_char = answer["answer_start"][0]
end_char = start_char + len(answer["text"][0])
sequence_ids = inputs.sequence_ids(i)
# Find the start and end of the context
idx = 0
while sequence_ids[idx] != 1:
idx += 1
context_start = idx
while sequence_ids[idx] == 1:
idx += 1
context_end = idx - 1
# If the answer is not fully inside the context, label it (0, 0)
if offset[context_start][0] > end_char or offset[context_end][1] < start_char:
start_positions.append(0)
end_positions.append(0)
else:
# Otherwise it's the start and end token positions
idx = context_start
while idx <= context_end and offset[idx][0] <= start_char:
idx += 1
start_positions.append(idx - 1)
idx = context_end
while idx >= context_start and offset[idx][1] >= end_char:
idx -= 1
end_positions.append(idx + 1)
inputs["start_positions"] = start_positions
inputs["end_positions"] = end_positions
return inputs
def compute_metrics(start_logits, end_logits, features, examples):
n_best = 20
max_answer_length = 30
metric = evaluate.load("squad")
example_to_features = collections.defaultdict(list)
for idx, feature in enumerate(features):
example_to_features[feature["example_id"]].append(idx)
predicted_answers = []
# for example in tqdm(examples):
for example in examples:
example_id = example["id"]
context = example["context"]
answers = []
# Loop through all features associated with that example
for feature_index in example_to_features[example_id]:
start_logit = start_logits[feature_index]
end_logit = end_logits[feature_index]
offsets = features[feature_index]["offset_mapping"]
start_indexes = np.argsort(start_logit)[-1 : -n_best - 1 : -1].tolist()
end_indexes = np.argsort(end_logit)[-1 : -n_best - 1 : -1].tolist()
for start_index in start_indexes:
for end_index in end_indexes:
# Skip answers that are not fully in the context
if offsets[start_index] is None or offsets[end_index] is None:
continue
# Skip answers with a length that is either < 0
# or > max_answer_length
if (
end_index < start_index
or end_index - start_index + 1 > max_answer_length
):
continue
answer = {
"text": context[
offsets[start_index][0] : offsets[end_index][1]
],
"logit_score": start_logit[start_index] + end_logit[end_index],
}
answers.append(answer)
# Select the answer with the best score
if len(answers) > 0:
best_answer = max(answers, key=lambda x: x["logit_score"])
predicted_answers.append(
{"id": example_id, "prediction_text": best_answer["text"]}
)
else:
predicted_answers.append({"id": example_id, "prediction_text": ""})
theoretical_answers = [
{"id": ex["id"], "answers": ex["answers"]} for ex in examples
]
return metric.compute(predictions=predicted_answers, references=theoretical_answers)
定义模型基准测试(benchmark)函数:
def measure_execution_time(model, batch_sizes, dataset):
dataset_for_model = dataset.remove_columns(["example_id", "offset_mapping"])
dataset_for_model.set_format("torch")
model.cuda()
batch_size_to_time_sec = {}
for batch_size in batch_sizes:
batch = {
k: dataset_for_model[k][:batch_size].to(model.device)
for k in dataset_for_model.column_names
}
with torch.inference_mode():
timer = benchmark.Timer(
stmt="model(**batch)", globals={"model": model, "batch": batch}
)
p50 = timer.blocked_autorange().median * 1000
batch_size_to_time_sec[batch_size] = p50
return batch_size_to_time_sec
2.2 加载模型、tokenizer和数据集
# load model
model_name = "bert-base-cased"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_name)
model = transformers.AutoModelForQuestionAnswering.from_pretrained(model_name)
print(f"Loading tokenizer: {model_name}")
print(f"Loading model: {model_name}")
# set up train and val dataset
squad_dataset = datasets.load_dataset("squad")
tokenized_squad_dataset = {}
tokenized_squad_dataset["train"] = squad_dataset["train"].map(
lambda x: preprocess_train_function(x, tokenizer), batched=True
)
tokenized_squad_dataset["validation"] = squad_dataset["validation"].map(
lambda x: preprocess_validation_function(x, tokenizer),
batched=True,
remove_columns=squad_dataset["train"].column_names,
)
data_collator = transformers.DataCollatorWithPadding(tokenizer=tokenizer)
2.3 测试baseline模型指标
接下来,我们在SQuAD数据集上训练一个快速的基线模型。SQuAD任务要求模型在给定的上下文(如维基百科文章)中识别出回答问题的文本片段。运行以下代码,我们得到了86.9的F1得分,这个结果与NVIDIA报告的得分非常接近。差异可能来源于使用的是BERT-base而不是BERT-large,或者是微调的超参数不同。
training_args = transformers.TrainingArguments(
"trainer",
num_train_epochs=1,
lr_scheduler_type="constant",
per_device_train_batch_size=64,
per_device_eval_batch_size=512,
)
trainer = transformers.Trainer(
model,
training_args,
train_dataset=tokenized_squad_dataset["train"],
eval_dataset=tokenized_squad_dataset["validation"],
data_collator=data_collator,
tokenizer=tokenizer,
)
trainer.train()
# batch sizes to compare for eval
batch_sizes = [4, 16, 64, 256]
# 2:4 sparsity require fp16, so we cast here for a fair comparison
with torch.autocast("cuda"):
with torch.inference_mode():
predictions = trainer.predict(tokenized_squad_dataset["validation"])
start_logits, end_logits = predictions.predictions
fp16_baseline = compute_metrics(
start_logits,
end_logits,
tokenized_squad_dataset["validation"],
squad_dataset["validation"],
)
fp16_time = measure_execution_time(
model,
batch_sizes,
tokenized_squad_dataset["validation"],
)
print("fp16", fp16_baseline)
print("cuda_fp16 time", fp16_time)
fp16 {'exact_match': 78.53358561967833, 'f1': 86.9280493093186}
cuda_fp16 time {4: 10.927572380751371, 16: 19.607915310189128, 64: 73.18846387788653, 256: 286.91255673766136}
2.4 对BERT-base模型进行半结构稀疏化
剪枝策略有很多,我们通过幅度剪枝(magnitude pruning)来修剪BERT模型。幅度剪枝的目标是移除L1范数最小的权重,这也是NVIDIA在所有实验中使用的剪枝策略。
我们将使用torch.ao.pruning包中的权重范数稀疏化器( weight-norm sparsifier)来实现这一过程。该稀疏化器通过对模型的权重张量应用掩码(mask)来执行剪枝操作。整个剪枝流程如下:
-
选择剪枝层:首先选择哪些层应用剪枝。在这个案例中,我们对所有的
nn.Linear层进行剪枝,除了任务特定的头部输出层,因为后者的形状约束不适用于半结构化稀疏性。 -
插入参数化:通过
torch.ao.pruning包中的工具,插入一个mask参数化来标记每个权重。在剪枝前,权重矩阵被标记为mask * weight,通过掩码来控制哪些权重被剪除。 -
进行剪枝:调用
pruner.update_mask()方法,更新模型中指定层的权重掩码。update_mask()方法会根据剪枝策略(如幅度剪枝)更新每个权重的掩码,将最小的L1范数的权重设置为零。 -
评估剪枝后的模型:在不进行微调的情况下,评估剪枝后的模型的性能,以查看zero-shot剪枝(即未进行微调)的准确性损失。这个步骤主要是为了观察剪枝后的模型精度的下降情况。
-
微调模型:对剪枝后的模型进行微调,以恢复剪枝导致的精度损失。在这个过程中,未被剪枝的权重会得到更新,从而提高整体模型的准确性。
-
剪枝永久化:一旦微调完成并且模型的性能恢复到满意水平,可以调用
squash_mask()方法。该方法将掩码与权重融合,移除所有参数化操作,留下最终的剪枝模型。 -
加速推理:使用已经剪枝并融合掩码的模型进行加速推理。此时,模型不再需要计算零权重,推理速度得以提高。在某些情况下,尤其是在批量较小的情况下,稀疏内核可能比密集内核慢,但在适当的条件下可以带来加速效果。
# 1. 选择剪枝层和剪枝策略
sparsifier = WeightNormSparsifier(
# apply sparsity to all blocks
sparsity_level=1.0,
# shape of 4 elemens is a block
sparse_block_shape=(1, 4),
# two zeros for every block of 4
zeros_per_block=2
)
# add to config if nn.Linear and in the BERT model.
sparse_config = [
{"tensor_fqn": f"{fqn}.weight"}
for fqn, module in model.named_modules()
if isinstance(module, nn.Linear) and "layer" in fqn
]
# 2. 修剪模型的第一步是插入参数化以屏蔽模型的权重,这是通过prepare step完成的。
# 每当我们试图访问.weight时,我们都会得到mask*weight。
sparsifier.prepare(model, sparse_config)
print(model.bert.encoder.layer[0].output)
BertOutput(
(dense): ParametrizedLinear(
in_features=3072, out_features=768, bias=True
(parametrizations): ModuleDict(
(weight): ParametrizationList(
(0-5): 6 x FakeSparsity()
)
)
)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
# 3. 进行剪枝
sparsifier.step()
# 4. 评估剪枝后的模型性能
with torch.autocast("cuda"):
with torch.inference_mode():
predictions = trainer.predict(tokenized_squad_dataset["validation"])
pruned = compute_metrics(
*predictions.predictions,
tokenized_squad_dataset["validation"],
squad_dataset["validation"],
)
print("pruned eval metrics:", pruned)
pruned eval metrics: {'exact_match': 40.59602649006622, 'f1': 56.51610004515979}
# 5. 微调模型
trainer.train()
# 6. 剪枝永久化
sparsifier.squash_mask()
torch.set_printoptions(edgeitems=4)
print(model.bert.encoder.layer[0].intermediate.dense.weight)
Parameter containing:
tensor([[ 0.0000, -0.0237, 0.0000, 0.0130, ..., -0.0462, -0.0000, 0.0000, -0.0272],
[ 0.0436, -0.0000, -0.0000, 0.0492, ..., -0.0000, 0.0844, 0.0340, -0.0000],
[-0.0302, -0.0350, 0.0000, 0.0000, ..., 0.0303, 0.0175, -0.0000, 0.0000],
[ 0.0000, -0.0000, -0.0529, 0.0327, ..., 0.0213, 0.0000, -0.0000, 0.0735],
...,
[ 0.0000, -0.0000, -0.0258, -0.0239, ..., -0.0000, -0.0000, 0.0380, 0.0562],
[-0.0432, -0.0000, 0.0000, -0.0598, ..., 0.0000, -0.0000, 0.0262 -0.0227],
[ 0.0244, 0.0921, -0.0000, -0.0000, ..., -0.0000, -0.0784, 0.0000, 0.0761],
[ 0.0000, 0.0225, -0.0395, -0.0000, ..., -0.0000, 0.0684, -0.0344, -0.0000]], device='cuda:0', requires_grad=True)
# 7. 评估微调后的剪枝模型
model = model.cuda().half()
# accelerate for sparsity
for fqn, module in model.named_modules():
if isinstance(module, nn.Linear) and "layer" in fqn:
module.weight = nn.Parameter(to_sparse_semi_structured(module.weight))
with torch.inference_mode():
predictions = trainer.predict(tokenized_squad_dataset["validation"])
start_logits, end_logits = predictions.predictions
metrics_sparse = compute_metrics(
start_logits,
end_logits,
tokenized_squad_dataset["validation"],
squad_dataset["validation"],
)
print("sparse eval metrics: ", metrics_sparse)
sparse_perf = measure_execution_time(
model,
batch_sizes,
tokenized_squad_dataset["validation"],
)
print("sparse perf metrics: ", sparse_perf)
sparse eval metrics: {'exact_match': 78.43897824030275, 'f1': 86.48718950090766}
sparse perf metrics: {4: 12.621004460379481, 16: 15.368514601141214, 64: 58.702805917710066, 256: 244.19364519417286}
下面是进一步的测试结果:
| Metric | fp16 | 2:4 sparse | Delta / Speedup |
|---|---|---|---|
| Exact Match (%) | 78.53 | 78.44 | -0.09 |
| F1 (%) | 86.93 | 86.49 | -0.44 |
| Time (bs=4) | 10.93 | 12.62 | 0.87x |
| Time (bs=16) | 19.61 | 15.37 | 1.28x |
| Time (bs=64) | 73.19 | 58.70 | 1.25x |
| Time (bs=256) | 286.91 | 244.19 | 1.18x |
可见,在剪枝后进行微调,模型恢复了几乎所有因剪枝造成的F1得分损失,这意味着微调后的剪枝模型并没有显著的精度损失。另外,在batch_size较小的情况下,稀疏内核的计算可能不如密集内核高效,无法带来加速效果。本次测试中,在batch_size=16时,加速效果最好,加速比为1.28x。