💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
摘要 — 牙齿龋齿是人类最常见的传染性疾病,影响着97%的人口终身。本文应用模糊认知图(FCMs)来分类患者的龋齿个人风险。文章讨论了两种开发FCM的方法。首先,基于领域专家定义概念之间的因果关系及其权重。然后,通过实值编码遗传算法(RCGA)和历史数据确定这些因果权重,无需专家干预。这两种FCM通过将86名样本患者分为“有龋齿”和“健康”两类进行了比较。尽管传统的FCM成功地将67.44%的案例正确分类,但基于RCGA的FCM达到了83.72%的正确分类率。结果显示,与传统FCM相比,基于RCGA的FCM的效率更高。
关键词 — 模糊认知图;牙齿龋齿;实值编码遗传算法;患者分类
牙齿龋齿诊断中最有效的方法是临床检查[1];这需要患者前往牙医处。这通常发生在患者感受到剧烈的牙痛时。在本研究提出的方案中,开发了一种医疗决策支持系统;患者可以提交有关自身状况的所需信息,并查看受牙齿蛀牙影响程度。此外,提出了一些临床指南以供治疗或预防之用。
为构建这一医疗决策支持系统,采用了模糊认知图(FCMs)。牙齿龋齿是一种多因素的牙科疾病,这些因素及其相互影响的严重性无法限制在少数几条规则和指南中[2, 3]。此外,牙医对于这些因素之间的某些关系可能存在明显的差异。另一方面,通过将神经网络和模糊逻辑的概念结合起来,FCM 是对复杂和动态系统进行建模和分析的有效方法。它们还能在一定程度上消除专家意见对某个问题的分歧[4]。
在[9]中提出了一种基于FCM和可能性模糊c均值聚类算法的混合方法,用于分类腹部疾病(CD)。在[9]中,为了提高FCM的效率和分类能力,应用了非线性Hebbian学习(NHL)算法来调整FCM权重。在另一项研究[10]中,基于FCM和支持向量机的组合对CD进行了分级。FCMs还被应用于不同类型癌症的分类和预测:在[11]中,使用具有主动Hebbian学习(AHL)算法的FCM对导管内乳腺病变进行了分类,该算法应用于86名患者的数据。在[12]中,作者们描述了所有概念及其之间连接链的权重,基于区间类型-2成员函数。在口腔病学领域,Anuradha和Uma [13]应用了AHL-FCM进行口腔肿瘤分级。此外,为选择适当的牙齿种植体基台开发了基于FCM的决策系统[14]。而[15]的作者们则利用FCM评估牙周病。
在这项研究中,我们的目标是将FCM与遗传算法结合,基于牙齿龋齿的风险对患者进行分类。这里的目标是为患者开发一个虚拟医疗访问系统,患者可以输入自己的信息,并了解是否需要预防牙齿龋齿,以免在感受到严重的牙痛之前。
本文的结构如下。第二部分介绍了牙齿龋齿的医学背景概述。第三部分是关于FCMs的简要回顾。第四部分还讨论了实值编码遗传算法(RCGA)。第五部分介绍了本项目使用的材料。第六部分还扩展了应用的方法。第七部分讨论了整体结果。最后,第八部分致力于结论。详细文章见第4部分。
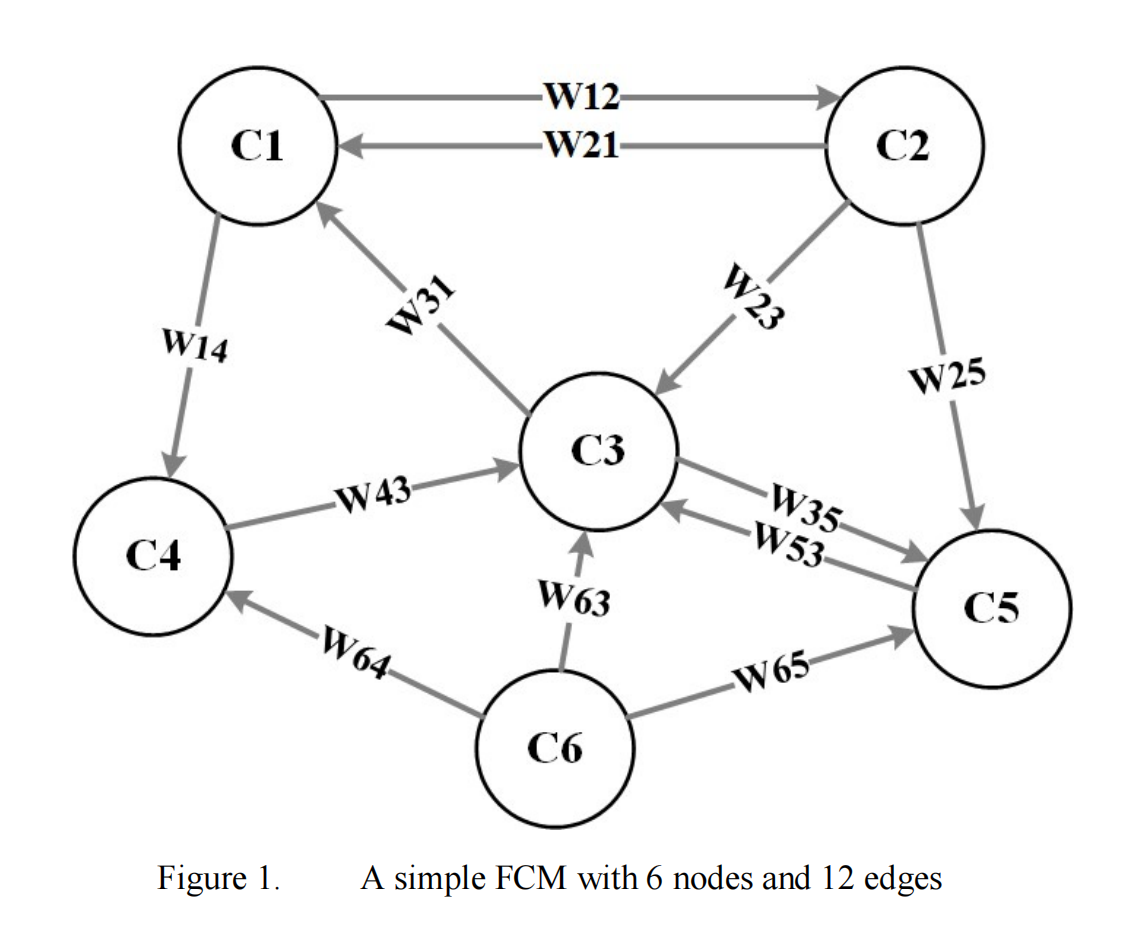
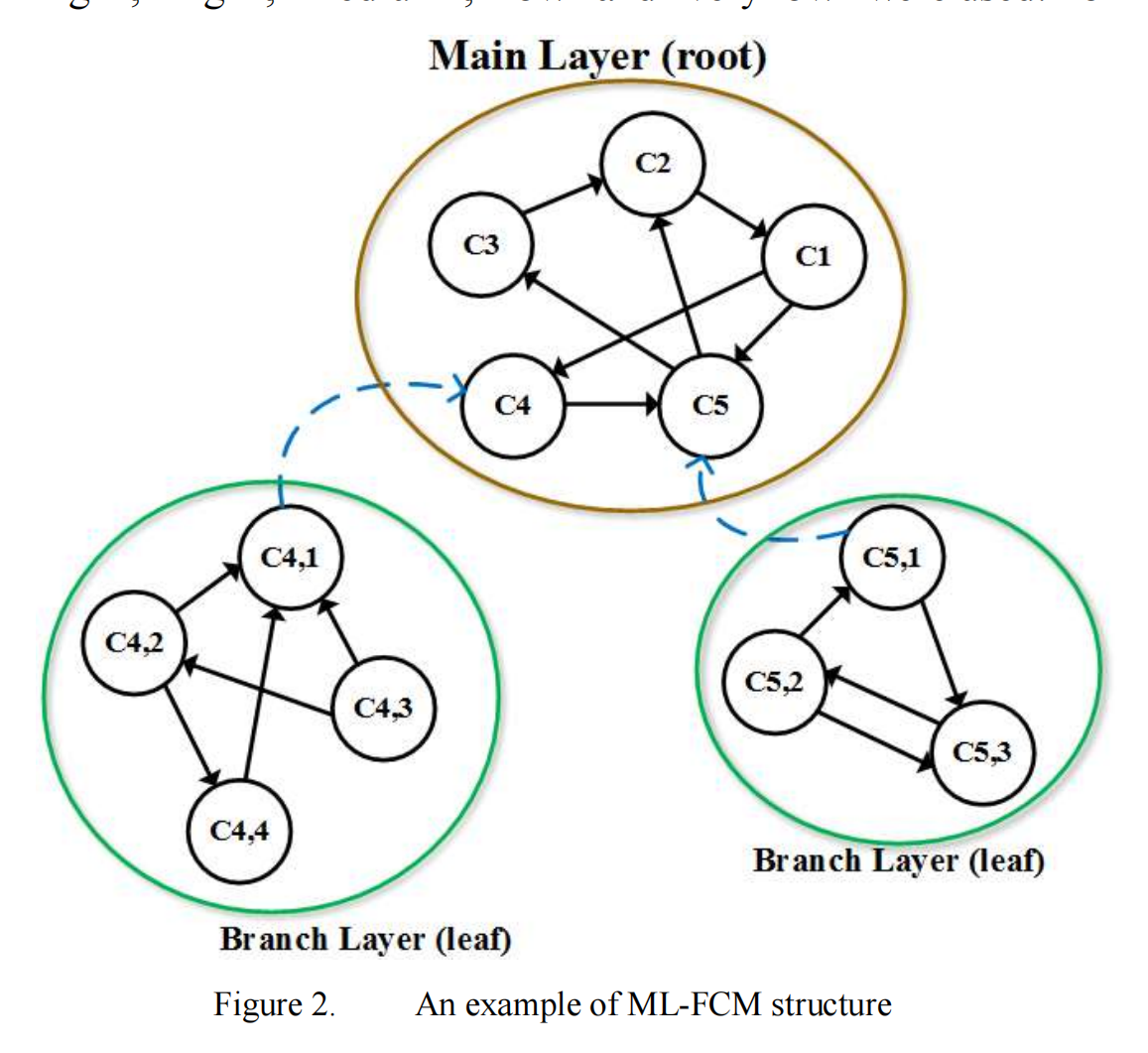
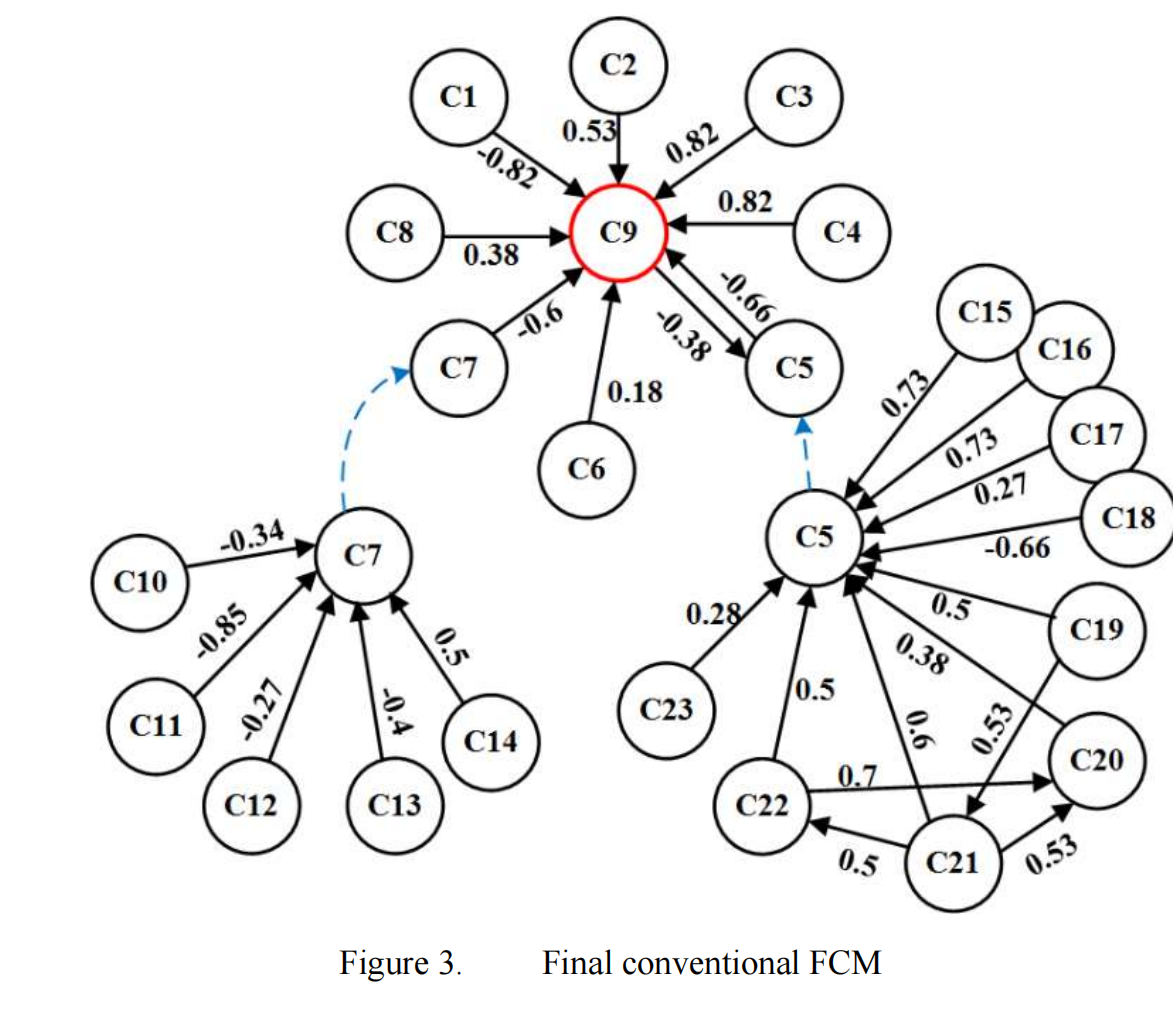
📚2 运行结果

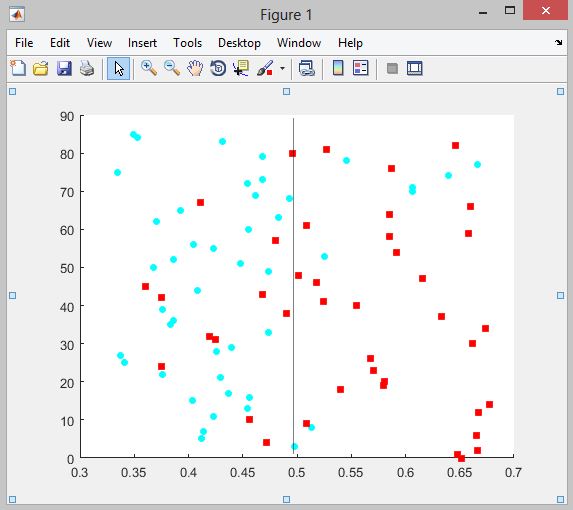
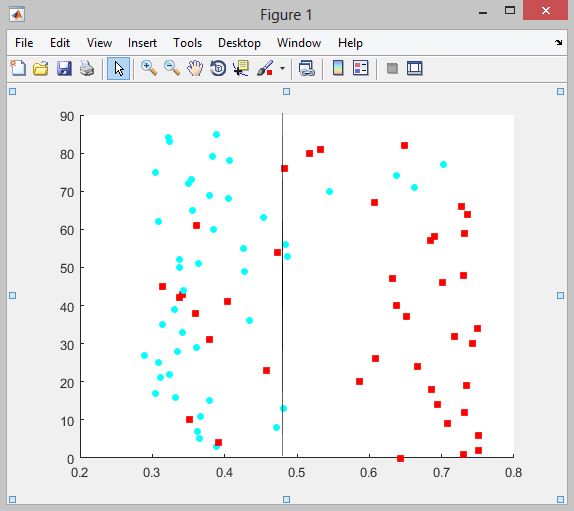
部分代码:
function [ costValue ] = FitnessFcn(weightVector)
% fitness function obtains the weights (a chromosome) and
% returns its cost value (1 means best & 0 means worst)
maxIt = 8;
finalValue = 0.0;
E = weightVector;
% obtaining each case's data (concepts' initial state vector)
% & putting them into the concepts (respectively)
% p stands for patient
for numOfPatients = 0:85
theCase = csvread("dataset.dat", numOfPatients, 0, [numOfPatients, 0, numOfPatients, 20]);
coca = theCase(1);
sweet = theCase(2);
gums = theCase(3);
brushFreq = theCase(4);
brushTime = theCase(5);
floss = theCase(6);
fluoride = theCase(7);
livingArea = theCase(8);
education = theCase(9);
parentsEdu = theCase(10);
income = theCase(11);
fruitAndMilk = theCase(12);
teethSpot = theCase(13);
calmativeDrugs = theCase(14);
salivaryPoverty = theCase(15);
oralBreathing = theCase(16);
cigarette = theCase(17);
previousCaries = theCase(18);
familyCaries = theCase(19);
teethDistance = theCase(20);
saliva = 0.0;
dentalHygiene = 0.0;
dentalCaries = 0.0;
knownDentalCaries = theCase(21);
A = [ cigarette, oralBreathing, salivaryPoverty, ...
calmativeDrugs, teethSpot, fruitAndMilk, income, ...
parentsEdu, education, livingArea, brushTime, floss, ...
fluoride, brushFreq, sweet, coca, gums, previousCaries, ...
teethDistance, familyCaries, saliva, dentalHygiene, ...
dentalCaries];
%temp = size(E);
%n = temp(1,1);
n = 23;
% computing the state vector's next value (using nextState Fcn)
for numOfIterations = 1:maxIt
for i=1:n
A(i) = nextState (A,E,i);
end
% disp( 'State Vector :');
% disp(A);
end
finalValueOfFCM = A(23);
% obtaining the final value of the goal concept (here: saliva)
% which was known before and was included in the dataset
finalValueOfDataset = knownDentalCaries;
% computing the Error_L2
fitnessFcnValue = (finalValueOfFCM - finalValueOfDataset).^2;
finalValue = finalValue + fitnessFcnValue;
end
% when we used the pop(1) for all dataset (patients 1 to z)
% we have the final fitnessFcnValue, now we have to compute
% the Fitness Function Value(Score) which is returned to the
% ga algorithm function as 'costValue'
% first procedure:
%alpha = 0.1;
%Error_L2 = alpha * finalValue;
%h = 1/((Error_L2)+1);
%costValue = 1- h;
% second procedure:
costValue = finalValue;
end
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
