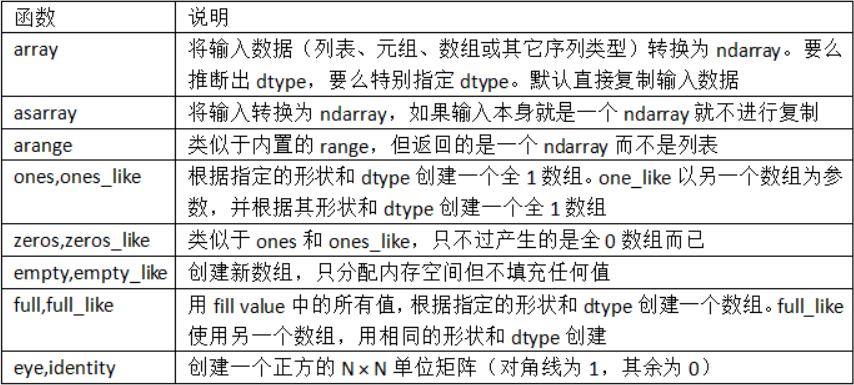
NumPy
NumPy的ndarray
- 一种多维度数组对象
创建ndarry
-
使用array函数。它接受一切序列型的对象(包括其他数组)
-
data2 = [[1, 2, 3, 4], [5, 6, 7, 8]] arr2 = np.array(data2) -
可以使用ndim和shape属性查看维度
-
arr2.ndim arr2.shape -
使用dtype属性查看数据类型
-
-
np.array会尝试为新建的这个数组推断出一个较为合适的数据类型
-
使用zeros和ones创建全是指定形状全0或全1的数组,empty可以创建一个没有任何具体值的数组
-
# 只需传入一个表示形状的元组 np.zeros(10) np.zeros((3, 6)) np.ones((3, 6)) np.empty((2, 3, 2)) # 两个三行二列的数组 -
注:认为np.empty会返回全0数组的想法是不安全的,返回的都是一些未初始化的垃圾值
-
-
arange是Python内置函数range的数组版
- 如果没有特别指定,数据类型基本都是float64(浮点数)
NumPy的数据类型
-
通过ndarray的astype方法将一个数组从一个dtype转换成另一个dtype
-
arr = np.array([1, 2, 3, 4, 5]) float_arr = arr.astype(np.float64) -
某字符串数组表示的全是数字,也可以用astype将其转换为数值形式
-
numeric_strings = np.array(['1.25', '-9.6', '42'], dtype=np.string_) -
使用numpy.string_类型时,一定要小心,因为NumPy的字符串数据是大小固定的,发生截取时,不会发出警告,pandas提供了更多非数值数据的便利的处理方法
-
-
NumPy会将Python类型映射到等价的dtype
NumPy数组的运算
-
大小相等的数组之间的任何算术运算都会将运算应用到元素级
-
大小相等的数组进行四则运算
-
arr = np.array([[1., 2., 3.], [4., 5., 6.]]) arr + arr arr - arr arr * arr arr / arr # 都是对应位置元素进行四则运算
-
-
大小相同的数组之间的比较会生成布尔值数组
基本的索引和切片
一维数组
-
一维索引与切片与Python列表差不多
-
将一个标量值赋值给一个切片时(如arr[5:8]=12),该值会自动传播到整个选区,与列表的区别是数组切片是原始数组的视图。这意味着数据不会被复制,视图上的任何修改都会直接反映到源数组上
-
arr = np.arange(10) # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) arr[5:8] = 12 # array([ 0, 1, 2, 3, 4, 12, 12, 12, 8, 9]) arr_slice = arr[5:8] arr_slice[1] = 123456 arr # array([ 0, 1, 2, 3, 4, 12, 12345, 12, 8, 9]) -
由于NumPy的设计目的是处理大数据,所以你可以想象一下,假如NumPy坚持要将数据复制来复制去的话会产生何等的性能和内存问题
-
多维数组
-
一个二维数组中,各索引位置上的元素不再是标量而是一维数组
-
可以对各个元素进行递归访问,但这样需要做的事情有点多。你可以传入一个以逗号隔开的索引列表来选取单个元素
-
arr2d[0][2] # 等价于 arr2d[0, 2]
-
-
在多维数组中,如果省略了后面的索引,则返回对象会是一个维度低一点的ndarray(它含有高一级维度上的所有数据)
-
arr3d = np.array([[[1, 2, 3], [4, 5, 6]], [[7, 8, 9], [10, 11, 12]]]) arr3d[0] -
标量值和数组都可以被赋值给arr3d[0]
-
old_values = arr3d[0].copy() arr3d[0] = 42 arr3d """ array([[[42, 42, 42], [42, 42, 42]], [[ 7, 8, 9], [10, 11, 12]]]) """ arr3d[0] = old_values arr3d """ array([[[ 1, 2, 3], [ 4, 5, 6]], [[ 7, 8, 9], [10, 11, 12]]]) """ -
选取数组子集,返回的数组都是视图
-
切片索引
-
一维数组的切片与Python差不多
-
二维数组切片不同
-
切片是沿着一个轴向选取元素的
-
可以一次传入多个切片
-
通过将整数索引和切片混合,可以得到低维度的切片
-
注意,“只有冒号”表示选取整个轴
-
arr[:2,1:] # shape (2,2) 选取前两行,一列后的所有数据 arr[2] arr[2,:] arr[2:,:] # 选取第三列 arr[:,:2] # 选取所有行的前两列 arr[1,:2] arr[1:2,:2] # 选取第二行的前两列 -
切片表达式的赋值操作也会被扩散到整个选区
-
布尔索引
-
通过布尔型索引选取数组中的数据,将总是创建数据的副本,即使返回一模一样的数组也是如此
-
names = np.array(['Bob', 'Joe', 'Will', 'Bob', 'Will', 'Joe', 'Joe']) data = np.random.randn(7, 4) names=='Bob' # array([ True, False, False, True, False, False, False], dtype=bool) data[names == 'Bob'] # 即可索引data -
布尔型数组的长度必须跟被索引的轴长度一致,如果布尔型数组的长度不对,布尔型选择就会出错,可以将布尔型数组跟切片、整数混合使用
-
可以使用不等于符号(!=),也可以通过~对条件进行否定
-
names != 'Bob' data[~(names == 'Bob')]
-
-
如需多个布尔条件,使用&(和)、|(或)之类的布尔算术运算符
- Python关键字and和or在布尔型数组中无效。要使用&与|
-
通过布尔型数组设置值是一种经常用到的手段。为了将data中的所有负值都设置为0
-
data[data < 0] = 0
-
花式索引
-
花式索引(Fancy indexing)是一个NumPy术语,它指的是利用整数数组进行索引
-
为了以特定顺序选取行子集,只需传入一个用于指定顺序的整数列表或ndarray即可
-
arr = np.empty((8, 4)) for i in range(8): arr[i] = i arr[[4, 3, 0, 6]] """ array([[ 4., 4., 4., 4.], [ 3., 3., 3., 3.], [ 0., 0., 0., 0.], [ 6., 6., 6., 6.]]) """ -
一次传入多个索引数组会有一点特别。它返回的是一个一维数组,其中的元素对应各个索引形成的元组
-
arr = np.arange(32).reshape((8, 4)) """ array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11], [12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23], [24, 25, 26, 27], [28, 29, 30, 31]]) """ arr[[1, 5, 7, 2], [0, 3, 1, 2]] # array([ 4, 23, 29, 10]) [arr[1,5],arr[5,3],arr[7,1],arr[2,2]]
-
数组的转置与轴对换
-
转置是重塑的一种特殊形式,它返回的是源数据的视图(不会进行任何复制操作)
-
在进行矩阵计算时,经常需要用到该操作,比如利用
np.dot()计算矩阵内积-
np.dot(arr.T, arr)
-
-
对于高维数组,transpose需要得到一个由轴编号组成的元组才能对这些轴进行转置
通用函数
-
通用函数(即ufunc)是一种对ndarray中的数据执行元素级运算的函数
-



利用数组进行数据处理
-
用数组表达式代替循环的做法,通常被称为矢量化。一般来说,矢量化数组运算要比等价的纯Python方式快上一两个数量级(甚至更多)
-
-

线性代数

- numpy.linalg中有一组标准的矩阵分解运算以及诸如求逆和行列式之类的东西
伪随机数

pandas
pandas的数据结构
Series
-
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
-
输出时:索引在左边,值在右边,如果没有指定索引,则自动创建0-N-1的整数型索引,可以通过series的value和index获取数组的表示形式和索引对象
-
添加索引:在index参数中添加与数组同长度的数组,对各个数据点进行标记
-
使用索引进行选取series的单个值或一组值
-
obj2['a'] # 单个值 obj2[['a','b','c']] # 一组值
-
-
使用NumPy函数或类似NumPy的运算(如根据布尔型数组进行过滤、标量乘法、应用数学函数等)都会保留索引值的链接
-
obj2[obj2 > 0] obj2 * 2 np.exp(obj2)
-
-
可以将series看成定长的有序字典,可以将其看成索引值到数据值的映射,可以用在许多原本需要字典参数的函数
-
# 使用字典创建series sdata = {'Ohio': 35000, 'Texas': 71000, 'Oregon': 16000, 'Utah': 5000} obj3 = pd.Series(sdata) -
如果只传入一个字典,则结果Series中的索引就是原字典的键(有序排列)。你可以传入排好序的字典的键以改变顺序:
-
states = ['California', 'Ohio', 'Oregon', 'Texas'] obj4 = pd.Series(sdata, index=states) -
如果传入的index在是sdata中没有找到对应的值,则其结果的值就会为NAN(表示缺失或NA值),如果sdata中有值,而索引未传入,则直接从结果中抹除
-
-
pandas的
isnull和notnull函数可用于检测缺失数据-
pd.isnull(obj4) pd.notnull(obj4)
-
-
series中最重要的一个功能:能根据运算的索引标签自动对齐数字,类似于数据库的join方法
-
series对象本身与其索引都有一个name属性
-
series的索引可以通过赋值的方式就地修改,必须修改全部的索引,不能部分修改
-
obj = pd.Series([4,7,-5,3],index=range(4)) # 0 4 # 1 7 # 2 -5 # 3 3 # dtype: int64 obj.index = ['Bob', 'Steve', 'Jeff', 'Ryan'] # 正确的 # Bob 4 # Steve 7 # Jeff -5 # Ryan 3 # dtype: int64 obj.index[0] = 1 # 错误的
-
Dataframe
-
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
-
建DataFrame:
-
直接传入一个有等长列表或NumPy数组组成的字典
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'], 'year': [2000, 2001, 2002, 2001, 2002, 2003], 'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]} frame = pd.DataFrame(data) -
使用嵌套字典:
- 如果使用嵌套字典,则pandas会被解释为:外层的键作为列,内层的键作为行索引
-
其他:
-
-
head方法:
-
# head方法会选取前5行数据 frame.head()
-
-
建立DataFrame时,如果传入列序列,在DataFrame的列就会按照指定顺序进行排列
-
pd.DataFrame(data, columns=['year', 'state', 'pop']) -
如果传入的列在数据中找不到,则会在结果中产生缺失值
-
-
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series
-
列也可以通过复制的方式进行修改
-
frame2['debt'] = 16.5
-
-
当使用列表或数组进行赋值给某列时,其长度必须与DataFrame的长度相匹配,如果赋值的是Series,则会精确匹配DataFrame的索引。如果为不存在的列赋值则会创建出一个新列,注:不能用frame.eastern创建新的列
-
del方法可以用来删除这列
-
使用类似NumPy数组的方法,对DataFrame进行转置
frame.T -
如果设置的DataFrame的index和columns的name属性,则这些信息会被显示出来
-
与series一样,value属性会以二维ndarry的形式返回DataFrame中的数据
-
如果DataFrame各列的数据类型不同,则值数组的的type会选用能兼容所有列的数据类型

索引对象
-
pandas的索引对象负者管理轴标签和其他元数据,构建Series和DataFrame时,所用到的任何数组或其他序列的标签都会被换成一个Index
-
Index对象是不可变的,因此用户不能对其进行修改
-
不可变可以使Index对象在多个数据结构之间安全共享
-
除了类似于数组,index也类似于一个固定大小的集合,但与Python不同的是,pandas的index可以包含重复的标签,选择重复的标签,会显示所有结果
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vSCns39C-1657024213451)(C:\Users\凉柠\AppData\Roaming\Typora\typora-user-images\image-20220526104649462.png)]
基本功能
重新索引
-
reindex()根据新索引进行重排,如果某个索引值当前不存在,就引入缺失值method='ffill'实现前项值填充
-
借助DataFrame,reindex可以修改(行)索引和列。只传递一个序列时,会重新索引结果的行,重新索引列时,用columns关键字重新索引

丢弃指定轴上的项
- 丢弃某条轴上的一个或多个项很简单,只要有一个索引数组或列表即可。由于需要执行一些数据整理和集合逻辑,所以drop方法返回的是一个在指定轴上删除了指定值的新对象
- 对于DataFrame,可以删除任意轴上的索引值,不指定轴,则默认删除行标签(axis=0),要删除列的值,则传递
axis=1或axis=columns - 可以就地修改对象,传入
inplace=True- 小心使用inplace,它会销毁所有被删除的数据
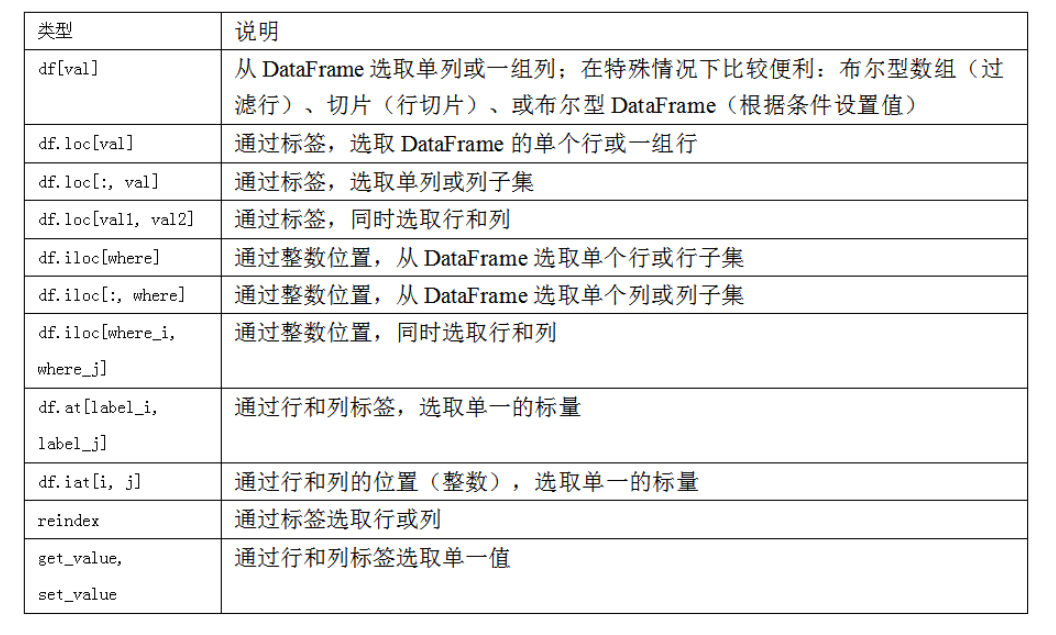
索引、选取和过滤
-
Series索引的工作方式类似于Numpy数组的索引,只不过Series索引值不只是整数
-
obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd']) obj['b'] obj[1] obj[2:4] obj[['b', 'a', 'd']] obj[[1, 3]] obj[obj < 2]
-
-
切片运算与Python切片不同,使用标签进行切片其末端是包含的
obj['b':'c]是包含c的,使用索引切片是不包含末端的obj[0:3],使用用切片可以对Series的相应部分进行设置 -
用一个值或序列对DataFrame进行索引其实就是获取一个或多个列
-
索引方式有几个特殊情况,首先通过切片或布尔型数组选取数据
-
data[:2] data[data['three'] > 5]
-
使用loc和iloc进行选取
-
引入特殊的标签运算符loc和iloc,使用轴标签(loc)和整数索引(iloc)从DataFrame选择行和列的子集
-
data.loc['Colorado', ['two', 'three']] -
data.iloc[2, [3, 0, 1]]
-
整数索引
-
对于整数索引与Python内置的列表和元组的索引语法不同
-
ser = pd.Series(np.arange(3.)) ser ser[-1] # error -
如果是非整数索引
-
ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c']) ser2[-1] # 2.0 -
如果轴索引含有整数,数据选取总会使用标签。为了更准确,请使用loc(标签)或iloc(整数)
-
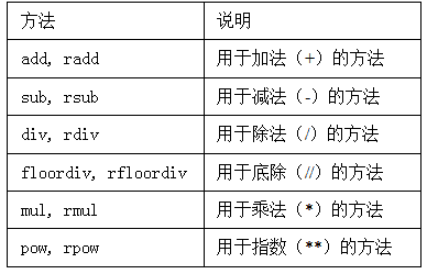
算术运算和数据对齐
- pandas最重要的一个功能是,它可以对不同索引的对象进行算术运算。在将对象相加时,如果存在不同的索引对,则结果的索引就是该索引对的并集。对于有数据库经验的用户,这就像在索引标签上进行自动外连接
- 自动的数据对齐操作在不重叠的索引处引入了NA值。缺失值会在算术运算过程中传播。对于DataFrame,对齐操作会同时发生在行和列上,其索引和列是原来两个DataFrame的并集
在算术方法中填充值
-
使用算术运算,在没有重叠的位置会产生NA值,而使用填充值,避免NA值
-
In [165]: df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)), .....: columns=list('abcd')) In [166]: df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)), .....: columns=list('abcde')) In [167]: df2.loc[1, 'b'] = np.nan In [168]: df1 Out[168]: a b c d 0 0.0 1.0 2.0 3.0 1 4.0 5.0 6.0 7.0 2 8.0 9.0 10.0 11.0 In [169]: df2 Out[169]: a b c d e 0 0.0 1.0 2.0 3.0 4.0 1 5.0 NaN 7.0 8.0 9.0 2 10.0 11.0 12.0 13.0 14.0 3 15.0 16.0 17.0 18.0 19.0 # 使用算术运算会出现NA值 In [170]: df1 + df2 Out[170]: a b c d e 0 0.0 2.0 4.0 6.0 NaN 1 9.0 NaN 13.0 15.0 NaN 2 18.0 20.0 22.0 24.0 NaN 3 NaN NaN NaN NaN NaN # 进行填充,避免出现NA值 In [171]: df1.add(df2, fill_value=0) Out[171]: a b c d e 0 0.0 2.0 4.0 6.0 4.0 1 9.0 5.0 13.0 15.0 9.0 2 18.0 20.0 22.0 24.0 14.0 3 15.0 16.0 17.0 18.0 19.0
-
-
在Series和DataFrame中,都有一个副本,以字母r开头,他会翻转参数,
1/df1等价于df1.rdiv(1))
DataFrame和Series之间的运算
-
DataFrame和Series之间会进行广播运算
-
默认情况下,DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame的列,然后沿着行一直向下广播
-
如果某个索引值在DataFrame的列或Series的索引中找不到,则参与运算的两个对象就会被重新索引以形成并集
-
在列上广播,则必须使用算术运算方法
-
frame.sub(series3, axis='index')
-
函数应用和映射
-
NumPy的ufuncs(元素级数组方法)也可用于操作pandas对象
-
frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),index=['Utah', 'Ohio', 'Texas', 'Oregon']) np.abs(frame)
-
-
将函数应用到由各列或行所形成的一维数组上
-
f = lambda x: x.max() - x.min() frame.apply(f)# 在每列中执行一次, frame.apply(f,axis='columns')# 在每行中执行一次 -
传递到apply的函数不是必须返回一个标量,还可以返回由多个值组成的Series
-
-
将函数应用到元素
-
applymap()将函数应用到元素上format = lambda x: '%.2f' % x frame.applymap(format)
-
排序和排名
- 使用sort_index方法,返回一个已排序的新对象
- 对于Series,使用sort_index可以根据index排序
- 对于DataFrame,使用sort_index可以根据传入参数(axis)来对任意轴的索引进行排序
- 数据默认是升序,但也可以是降序排列
ascending=False - 若要按值进行排序,
sort_values, - 任何缺失值都会默认放到Series末尾,当排序DataFrame时,根据一个或多个列中的值进行排序,那就将一个或多个值的名字传递给sort_values中的by选项,多个值时,先对前一个排序,若其中有相等的,再根据第二个值排序
- rank方法:默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系的
- 默认使用
average,即有相同排名时,取其排名的平均值 min对于相等的值,取较小的排名max对于相等的值,取较大的排名first对于相等的值,取最先出现的排名dense类似于 ”min“,但排名不会出现大于 1 的空隙
- 默认使用
带有重复标签的轴索引
- 索引的is_unique属性,用来判断它的值是否唯一
- 如果索引对应多个值,则会返回一个Series,而对应单个的值,则返回一个标量值,
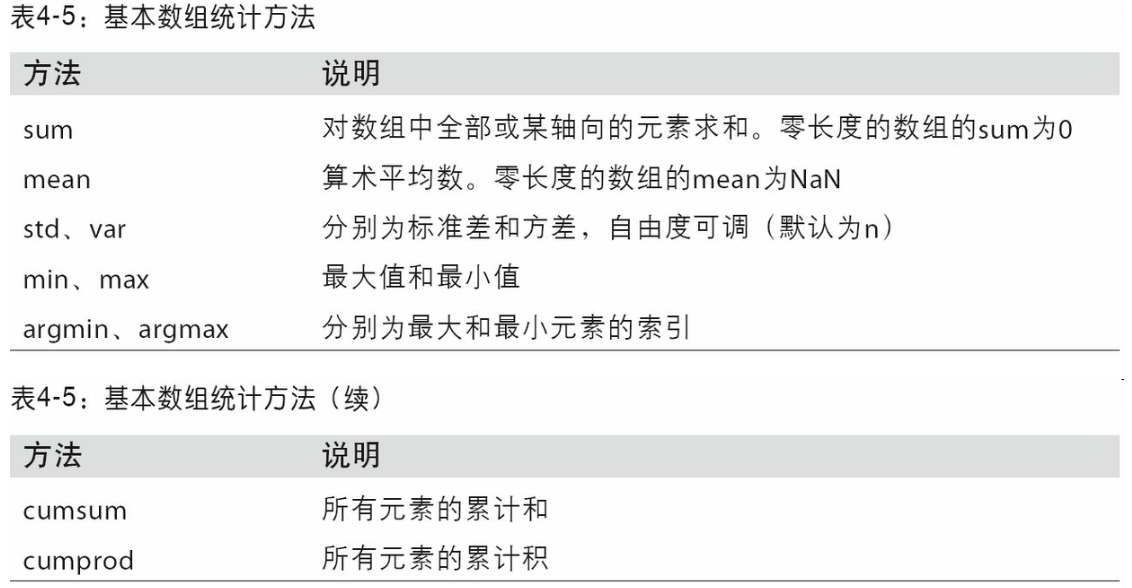
汇总和计算描述统计
- NA值会自动被排除,除非整个切片(这里指的是行或列)都是NA,通过skipna选项可以禁用该功能


相关系数和协方差
- Series的corr方法用于计算两个Series中重叠的、非NA的、按索引对齐的值的相关系数。与此类似,cov用于计算协方差
- DataFrame的corr和cov方法将以DataFrame的形式分别返回完整的相关系数或协方差矩阵
- DataFrame的corrwith方法,计算其列或行跟另一个Series或DataFrame之间的相关系数。传入一个Series将会返回一个相关系数值Series(针对各列进行计算)
唯一性、值计数以及成员资格
unique得到Series中唯一值数组value_counts用于计算一个Series中各值出现的频率,可用于任何数组或序列isin判断矢量化集合的成员资格,可用于过滤Series中或DataFrame列中数据的子index.get_indexer与isin类似的是Index.get_indexer方法,它可以给你一个索引数组,从可能包含重复值的数组到另一个不同值的数组

pandas数据加载、存储与文件格式
读取文本格式的数据
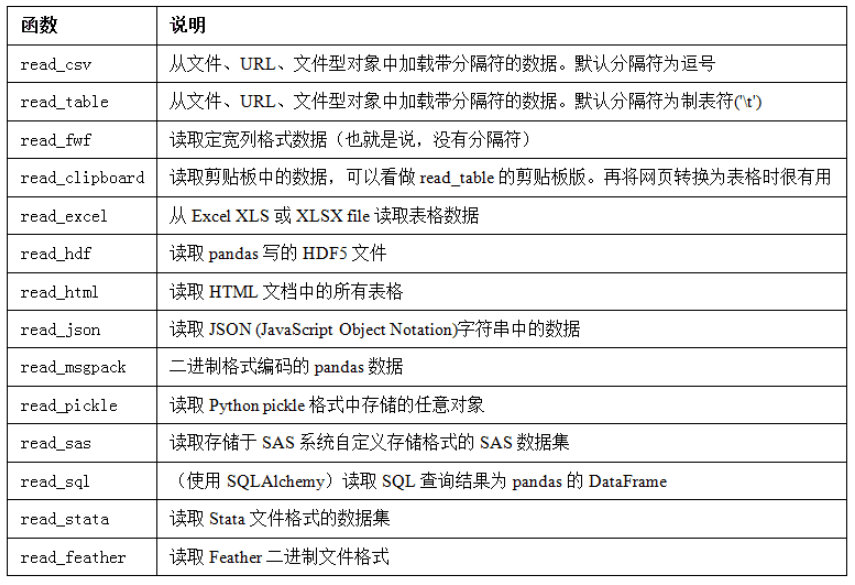
-
函数选项的大致分类
- 索引:将一个或多个列当做返回的DataFrame处理,以及是否从文件、用户获取列名。
- 类型推断和数据转换:包括用户定义值的转换、和自定义的缺失值标记列表等。
- 日期解析:包括组合功能,比如将分散在多个列中的日期时间信息组合成结果中的单个列。
- 迭代:支持对大文件进行逐块迭代。
- 不规整数据问题:跳过一些行、页脚、注释或其他一些不重要的东西(比如由成千上万个逗号隔开的数值数据)。
-
sep='分隔符'指定分隔符 -
header=None让pandas为其分配默认的列名- 可以自己定义列名
name=['a', 'b', 'c', 'd', 'message'] - 如果希望message列作为索引,可以明确表示要将该列放到索引4的位置上,也可以通过index_col参数指定"message"
- 可以自己定义列名
-
做一个层次化索引,传入由列编号,或列名组成的列表即可
-
parsed = pd.read_csv('examples/csv_mindex.csv',index_col=['key1', 'key2'])
-
-
传入正则表达式作为分隔符
result = pd.read_table('examples/ex3.txt', sep='\s+')
-
跳过文件的某些行
pd.read_csv('examples/ex4.csv', skiprows=[0, 2, 3])跳过文件的第一、三、四行
-
对某些值进行标记,将其标记为NA值
-
使用列表或集合的字符串表示缺失值
-
result = pd.read_csv('examples/ex5.csv', na_values=['NULL']) # 将NULL值标记为NA值 -
字典的各列可以使用不同的NA标记值
-
sentinels = {'message': ['foo', 'NA'], 'something': ['two']} -
-

逐块获取文本文件
-
看大文件之前,将pandas显示的更急一些
-
显示10行数据
-
pd.options.display.max_rows = 10 -
只读取几行数据
-
pd.read_csv('examples/ex6.csv', nrows=5)
-
-
逐块读取文件【通过指定chunksize】
-
chunker = pd.read_csv('ch06/ex6.csv', chunksize=1000) -
返回TextParser对象,可以进行迭代
-
tot = pd.Series([]) for piece in chunker: tot = tot.add(piece['key'].value_counts(), fill_value=0)
-
将数据写入到文本格式中
- 利用DataFrame的
to_csv方法将数据写到一个以逗号分隔的文件中sep='字符串'可以指定其他分隔符- 缺失值会被标记为空字符串,也可以标记为其他的标记值
na_rep="NULL"使用na_rep将缺失值标记为NULL - 如果没有设置其他选项,会写出行和列的标签,也可以进行禁用
index=False,header=False - 也可以只写出部分列
data.to_csv(sys.stdout, index=False, columns=['a', 'b', 'c'])不写入索引,并且只写入列为a,b,c,并且按写入的顺序排列
- Series也有
to_csv方法
处理分隔符格式
- 对于任何单字符分隔符文件,直接使用Python内置的CSV模块,将任意已打开的文件或文件型对象传给csv.reader,对reader进行迭代会为每行产生一个元组,并移除了所有引号

JSON数据
- 已经成为通过HTTP请求在Web浏览器和其他应用程序之间发送数据的标准格式之一。它是一种比表格型文本格式(如CSV)灵活得多的数据格式。
json.loads(obj)实现将JSON字符串转换为Python形式json.dumps(obj)实现将Python对象转化为JSON格式pandas.read_json可以自动将特别的JSON数据集转化为Series或DataFrameto_json方法:将数据从pandas输出到JSON
二进制数据格式
-
实现数据的高效二进制格式存储最简单的办法之一是使用Python内置的pickle序列化
-
pandas对象都有一个用于将数据以pickle格式保存到磁盘上的to_pickle方法
frame.to_pickle('examples/frame_pickle')
-
可以通过pickle直接读取被pickle化的数据,或是使用更为方便的pandas.read_pickle
pd.read_pickle('examples/frame_pickle')
读取Microsoft Excel文件
-
pandas的ExcelFile类或pandas.read_excel函数支持读取存储在Excel 2003(或更高版本)中的表格型数据。这两个工具分别使用扩展包xlrd和openpyxl读取XLS和XLSX文件。你可以用pip或conda安装它们
- 要使用ExcelFile,通过传递xls或xlsx路径创建一个实例
xlsx = pd.ExcelFile('examples/ex1.xlsx')
-
使用
read_excel读取到DataFrame中pd.read_excel(xlsx, 'Sheet1')
-
将pandas数据写入为Excel格式
-
首先创建一个ExcelWriter,然后使用pandas对象的
to_excel方法将数据写入其中 -
writer = pd.ExcelWriter('examples/ex2.xlsx') frame.to_excel(writer, 'Sheet1') writer.save() -
也可以不使用ExcelWriter,而是直接传递文件的路径到
to_excel -
frame.to_excel('examples/ex2.xlsx')
-
数据清洗和准备
处理缺失数据
- pandas使用浮点值NaN表示缺失数据
- Python内置的None值在对象数组中也可以作为NA值

滤除缺失数据
-
对于series
-
可以通过pandas.isnull或布尔索引的手工方法
-
dropna会更实用一些,并且返回一个含非空数据和索引值的Series-
data.dropna() # 等价于 data[data.notnull()]
-
-
-
-
对于DataFrame
dropna()默认丢弃任何含有缺失值的行- 指定
axis=1丢弃任何含有缺失值的列 how='all'只丢弃那些全为NA的行或列thesh=2保留至少2行,留下一部分观测数据
填充缺失值
fillna()方法通过一个常数调用fillna将缺失值替换为常数通过子弹调用fillna()可以实现对不同的列填充不同的值fillna会返回新对象,但也可以对现有对象进行就地修改- 对
reindexing有效的插值方法也可用于fillna()df.fillna(method='ffill')# 向前填充df.fillna(method='ffill', limit=2)向前填充,限制为2
数据转换
移除重复数据
-
DataFrame的
duplicated()返回一个布尔型Series,表示各行是否是重复的行(前面出现过的行)-
data.duplicated() -
drop_duplicates()返回一个一个DataFrame,重复的数组会标为False -
默认判断全部列,可以指定部分列进行重复项判断
data.drop_duplicates(['k1'])根据k1列过滤重复项 -
默认保存的是第一次出现的值组合,传入
keep='last'则保留最后一个
-
利用函数或映射进行数据转换
-
map()函数 -
Series的
str.lower()将各个值转换为小写 -
data['animal'] = lowercased.map(meat_to_animal)animal是新建的列,meat_to_animal是不同肉类到动物的映射 -
也可以传入函数
-
data['food'].map(lambda x: meat_to_animal[x.lower()])
-
替换值
-
利用replace来产生一个新的Series(除非传入inplace=True)-
data.replace(-999, np.nan) -
将-999替换为NaN
-
如果需要一次性替换多个值,传入一个待替换组成的列表以及一个替换值
-
data.replace([-999, -1000], np.nan) -
如果要每个值的替换值都不一样则传入一个替换列表
-
data.replace([-999, -1000], [np.nan,0]) -
也可以传入字典
-
data.replace({-999: np.nan, -1000: 0})
-
重命名轴索引
-
跟Series中的值一样,轴标签也可以通过函数或映射进行转换,从而得到一个新的不同标签的对象。轴还可以被就地修改,而无需新建一个数据结构
-
data.index.map() -
将其传给data.index可以实现就地修改
data.index = data.index.map()
-
想要创建数据集的转换版(而不是修改原始数据)比较实用的是
rename()- 可以结合字典型对象实现对部分轴标签的更新
-
rename可以实现复制DataFrame并对其索引和列标签进行赋值。如果希望就地修改某个数据集,传入inplace=True即可
data.rename(index={'OHIO': 'INDIANA'}, inplace=True)将OHIO修改为INDIANA
离散化和面元划分
-
使用
cut()将数据划分-
bins = [18, 25, 35, 60, 100] cats = pd.cut(ages, bins) -
pandas返回的是一个特殊的Categorical对象
-
codes属性中的年龄数据的标签
-
cats.codes # array([0, 0, 0, 1, 0, 0, 2, 1, 3, 2, 2, 1], dtype=int8)
-
-
pd.value_counts(cats)是pandas.cut结果的面元计数。
-
跟“区间”的数学符号一样,圆括号表示开端,而方括号则表示闭端(包括)。哪边是闭端可以通过right=False进行修改
-
可 以通过传递一个列表或数组到labels,设置自己的面元名称
-
group_names = ['Youth', 'YoungAdult', 'MiddleAged', 'Senior'] pd.cut(ages, bins, labels=group_names)
-
-
如果向cut传入的是面元的数量而不是确切的面元边界,则它会根据数据的最小值和最大值计算等长面元
-
data = np.random.rand(20) pd.cut(data, 4, precision=2) # [(0.34, 0.55], (0.34, 0.55], (0.76, 0.97], (0.76, 0.97], (0.34, 0.55], ..., (0.34, 0.55], (0.34, 0.55], (0.55, 0.76], (0.34, 0.55], (0.12, 0.34]] # Length: 20 # Categories (4, interval[float64]): [(0.12, 0.34] < (0.34, 0.55] < (0.55, 0.76] < (0.76, 0.97]] -
precision=2限制小数只有两位
-
-
-
使用
qcut()- 根据样本分位数对数据进行面元划分
- cut可能无法使各个面元中含有相同数量的数据点。而qcut由于使用的是样本分位数,因此可以得到大小基本相等的面元
检测和过滤异常值
- 选出全部含有“超过3或-3的值”的行,你可以在布尔型DataFrame中使用any方法
data[(np.abs(data) > 3).any(1)]显示data中行有绝对值大于3的行data[(np.abs(data) > 3).any(1)]对值进行设置,将值限制在-3到3之间
排列和随机采样
-
利用numpy.random.permutation函数可以轻松实现对Series或DataFrame的列的排列工作(permuting,随机重排序)
-
然后就可以在基于iloc的索引操作或take函数中使用该数组了
-
df = pd.DataFrame(np.arange(5 * 4).reshape((5, 4))) # 创建数组 sampler = np.random.permutation(5) # 创建随机数组 df.take(sampler) #使用take使用随机数组进行排列 -
选取随机子集,在Series和DataFrame上使用
sample() -
要通过替换的方式产生样本(允许重复选择),可以传递replace=True到sample
-
choices = pd.Series([5, 7, -1, 6, 4]) draws = choices.sample(n=10, replace=True)
-
计算指标/哑变量
-
常用于统计建模或机器学习的转换方式是:将分类变量(categorical variable)转换为“哑变量”或“指标矩阵”
-
如果DataFrame的某一列中含有k个不同的值,则可以派生出一个k列矩阵或DataFrame(其值全为1和0)。pandas有一个get_dummies函数可以实现该功能(其实自己动手做一个也不难)。使用之前的一个DataFrame例子
-
df = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'b'],'data1': range(6)}) pd.get_dummies(df['key'])
-
-
DataFrame的列加上一个前缀,以便能够跟其他数据进行合并,get_dummies的prefix参数可以实现该功能
字符串操作
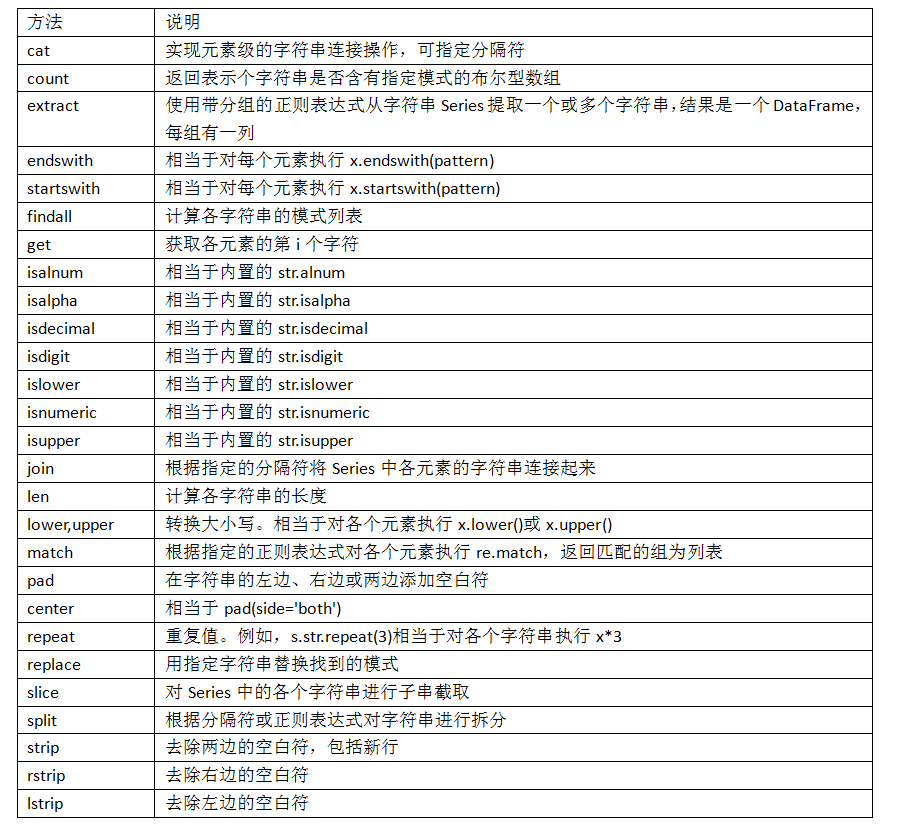
字符串对象方法

pandas的矢量化字符串函数
- 通过data.map,所有字符串和正则表达式方法都能被应用于(传入lambda表达式或其他函数)各个值,但是如果存在NA(null)就会报错
data.str.contains('gmail')通过str.contains检查各个电子邮件地址是否含有"gmail"
数据规整:聚合、合并和重塑
层次化索引
-
能以低纬度形式处理高纬度数据
-
对于Series
-
data = pd.Series(np.random.randn(9),index=[['a', 'a', 'a', 'b', 'b', 'c', 'c', 'd', 'd'],[1, 2, 3, 1, 3, 1, 2, 2, 3]]) ''' a 1 1.219769 2 2.002463 3 1.517846 b 1 -1.626634 3 -0.984256 c 1 -1.510162 2 -0.086027 d 2 0.369342 3 -0.042886 ''' -
看到的结果是经过美化的带有Multiindex索引的Series格式
-
这样进行索引会更简单
-
data['b'] # 1 -0.555730 3 1.965781 data['b':'c'] data.loc[['b', 'd']] -
还可以在内部进行索引
-
data.loc[:, 2] # 选取所有的索引为2的数据 -
可以使用
unstack()方法将数据重新排列到DataFrame中-
data.unstack() ''' 1 2 3 a -0.204708 0.478943 -0.519439 b -0.555730 NaN 1.965781 c 1.393406 0.092908 NaN d NaN 0.281746 0.769023 ''' -
unstack()方法的逆运算是stack()方法 -
data.unstack().stack()
-
-
-
对于DataFrame
-
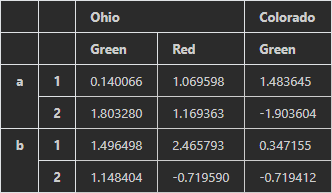
每条轴都可以分层索引
-
frame = pd.DataFrame(np.random.randn(12).reshape((4,3)),index=[['a', 'a', 'b', 'b'], [1, 2, 1, 2]],columns=[['Ohio', 'Ohio', 'Colorado'],['Green', 'Red', 'Green']]) -
-
每层都可以有名字,如果指定了名称则会在控制台中输出
-
有了部分列索引就可以轻松进行分组
-
可以单独创建MultiIndex然后复用。上面那个DataFrame中的(带有分级名称)列可以这样创建
-
a = pd.MultiIndex.from_arrays([['Ohio', 'Ohio', 'Colorado'], ['Green', 'Red', 'Green']],names=['state', 'color']) frame = pd.DataFrame(np.random.randn(12).reshape((4,3)),columns=a)
-
重排与分级排序
-
重新调整某条轴上各级别的顺序,或根据指定级别上的值对数据进行排序,
swaplevel()方法接受两个级别编号或名称,并返回一个互换了级别的新对象(但数据不会发生变化)-
frame.swaplevel('key1', 'key2') ''' state Ohio Colorado color Green Red Green key2 key1 1 a 0 1 2 2 a 3 4 5 1 b 6 7 8 2 b 9 10 11 '''
-
-
sort_index则根据单个级别中的值对数据进行排序。交换级别时,常常也会用到sort_index
-
frame.sort_index(level=1) # 根据level为1的索引进行排序
-
根据级别汇总统计
-
许多对DataFrame和Series的描述和汇总统计都有一个level选项,它用于指定在某条轴上求和的级别。
-
frame.sum(level='key2') frame.sum(level='color', axis=1)
-
使用DataFrame的列进行索引
-
要将DataFrame的一个或多个列当做行索引来用,或者希望将行索引变成DataFrame的列
-
DataFrame的set_index函数会将其一个或多个列转换为行索引,并创建一个新的DataFrame
-
frame2 = frame.set_index(['c', 'd']) ''' a b c d one 0 0 7 1 1 6 2 2 5 two 0 3 4 1 4 3 2 5 2 3 6 1 '''
-
-
reset_index的功能跟set_index刚好相反,层次化索引的级别会被转移到列里面
-
frame2.reset_index() ''' c d a b 0 one 0 0 7 1 one 1 1 6 2 one 2 2 5 3 two 0 3 4 4 two 1 4 3 5 two 2 5 2 6 two 3 6 1 '''
-
合并数据集
-
pandas对象中的数据可以通过一些方式进行合并
- pandas.merge可根据一个或多个键将不同的DataFrame的行连接起来,实现的类似数据库的join操作
- pandas.concat可以沿着一条轴将多个对象堆叠到一起
- combine_first可以将重复的数据拼接到一起,用一个对象的值填充另一个对象的缺失值
-
数据库的合并或连接
-
df1 = pd.DataFrame({'key': ['b', 'b', 'a', 'c', 'a', 'a', 'b'],'data1': range(7)}) df2 = pd.DataFrame({'key': ['a', 'b', 'd'],'data2': range(3)}) -
这是多对一的合并,df1中的数据有多个被标记为a和b的行,而df2中key列的每个值仅对应一行调用merge得到
pd.merge(df1,df2) ''' data1 key data2 0 0 b 1 1 1 b 1 2 6 b 1 3 2 a 0 4 4 a 0 5 5 a 0 ''' -
如果不指定哪个列进行连接,merge就会将重叠的列当做键,可以使用on进行指定
pd.merge(df1, df2, on='key') ''' data1 key data2 0 0 b 1 1 1 b 1 2 6 b 1 3 2 a 0 4 4 a 0 5 5 a 0 ''' -
如果两个对象的列名不同,也可以进行分别指定
-
pd.merge(df3, df4, left_on='lkey', right_on='rkey') -
默认情况下,merge做的是“内连接”;结果中的键是交集。其他方式还有"left"、“right"以及"outer”。外连接求取的是键的并集,组合了左连接和右连接的效果
pd.merge(df1, df2, how='outer') ''' inner 使用两个表都有的键 left 使用左表中所有的键 right 使用右表中所有的键 outer 使用两个表中所有的键 ''' -
多对多连接产生的是行的笛卡尔积
-
要根据多个键进行合并,传入一个由列名组成的列表即可
pd.merge(left, right, on=['key1', 'key2'], how='outer') -
在进行列-列连接时,DataFrame对象中的索引会被丢弃。
-
suffixes选项,用于指定附加到左右两个DataFrame对象的重叠列名上的字符串
pd.merge(left, right, on='key1', suffixes=('_left', '_right')) -
-

索引上的合并
-
DataFrame中的连接键位于其索引中。在这种情况下,你可以传入left_index=True或right_index=True(或两个都传)以说明索引应该被用作连接键
-
left1 = pd.DataFrame({'key': ['a', 'b', 'a', 'a', 'b', 'c'],'value': range(6)}) right1 = pd.DataFrame({'group_val': [3.5, 7]}, index=['a', 'b']) pd.merge(left1, right1, left_on='key', right_index=True) ''' key value group_val 0 a 0 3.5 2 a 2 3.5 3 a 3 3.5 1 b 1 7.0 4 b 4 7.0 ''' -
对于层次化索引,因为索引的合并默认是多键合并,必须以列表的形式指明用作合并键的多个列(注意用how='outer’对重复索引值的处理)
-
lefth = pd.DataFrame({'key1': ['Ohio', 'Ohio', 'Ohio','Nevada', 'Nevada'],'key2': [2000, 2001, 2002, 2001, 2002],'data': np.arange(5.)}) righth = pd.DataFrame(np.arange(12).reshape((6, 2)),index=[['Nevada', 'Nevada', 'Ohio', 'Ohio','Ohio', 'Ohio'], [2001, 2000, 2000, 2000, 2001, 2002]],columns=['event1', 'event2']) pd.merge(lefth,righth,left_on=['key1','key2'],right_index=True)
-
-
合并双方的索引
-
pd.merge(left2, right2, how='outer', left_index=True, right_index=True)
-
-
DataFrame还有一个便捷的join实例方法,它能更为方便地实现按索引合并。它还可用于合并多个带有相同或相似索引的DataFrame对象,但要求没有重叠的列。
轴向连接
-
NumPy的concatenation函数可以用NumPy数组来做
-
对于pandas对象(如Series和DataFrame),带有标签的的轴能够进一步推广数组的连接运算
- 如果对象在其它轴上的索引不同,我们应该合并这些轴的不同元素还是只使用交集?
- 连接的数据集是否需要在结果对象中可识别?
- 连接轴中保存的数据是否需要保留?许多情况下,DataFrame默认的整数标签最好在连接时删掉。
-
pandas的concat函数提供了一种能够解决这些问题的可靠方式
-
# 有三个没有重叠索引的Series 调用concat可以将值和索引粘合在一起 pd.concat([s1, s2, s3])
-
-
默认情况下,concat是在axis=0上工作的,最终产生一个新的series,而传入axis=1,则结果就会变成DataFrame
-
pd.concat([s1, s2, s3], axis=1) ''' 0 1 2 a 0.0 NaN NaN b 1.0 NaN NaN c NaN 2.0 NaN d NaN 3.0 NaN e NaN 4.0 NaN f NaN NaN 5.0 g NaN NaN 6.0 ''' -
传入join='inner’即可得到它们的交集
-
s4 = pd.concat([s1, s3]) pd.concat([s1, s4], axis=1, join='inner') ''' 0 1 a 0 0 b 1 1 ''' -
通过join_axes指定要在其它轴上使用的索引
-
pd.concat([s1, s4], axis=1, join_axes=[['a', 'c', 'b', 'e']])
-
-
如果参与连接的片段在结果中区分不开。假设你想要在连接轴上创建一个层次化索引。使用keys参数即可达到这个目的
-
result = pd.concat([s1, s1, s3], keys=['one','two', 'three']) ''' one a 0 b 1 two a 0 b 1 three f 5 g 6 '''
-
-
如果沿着axis=1对Series进行合并,则keys就会成为DataFrame的列头
-
pd.concat([s1, s2, s3], axis=1, keys=['one','two', 'three']) ''' one two three a 0.0 NaN NaN b 1.0 NaN NaN c NaN 2.0 NaN d NaN 3.0 NaN e NaN 4.0 NaN f NaN NaN 5.0 g NaN NaN 6.0 '''
-
-
同样的逻辑也适用于DataFrame
-
如果传入的不是列表而是字典,则字典的键就会被当做keys选项的值
-
可以用names参数命名创建的轴级别
-
pd.concat([df1, df2], axis=1, keys=['level1', 'level2'],names=['upper', 'lower'])
-
-
DataFrame的行索引不包含任何相关数据,在将两个DataFrame进行列连接时,如果行索引不包含任何相关数据,则传入ingore_index=True即可
-
df1 = pd.DataFrame(np.random.randn(3, 4), columns=['a', 'b', 'c', 'd']) df2 = pd.DataFrame(np.random.randn(2, 3), columns=['b', 'd', 'a']) pd.concat([df1, df2],ignore_index=True)
-
-

合并重叠数据
-
还有一种数据组合问题不能用简单的合并(merge)或连接(concatenation)运算来处理
-
numpy.where(condition,1,2)如果满足condition,则返回1,如果不满足则返回2-
np.where(pd.isnull(a), b, a)
-
-
Series有个conbine_first方法,实现的功能是一样的,然后还自带pandas的数据对齐
-
b[:-2].combine_first(a[2:])
-
-
对于DataFrame,combine_first自然也会在列上做同样的事情,因此你可以将其看做:用传递对象中的数据为调用对象的缺失数据“打补丁“
重塑和轴向选转
有许多用于重新排列表格型数据的基础运算。这些函数也称作重塑(reshape)或轴向旋转(pivot)运算
重塑层次化索引
- 层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的方式,主要方式有二:
stack():将数据的列”旋转“为行unstack():将数据的行”旋转“为列
- 对于层次化索引的Series,可以使用unstack将其重排为一个DataFrame
- 默认情况下,unstack操作的是最内层的(stack也是如此),传入分层级别的编号或名称即可对其他级别进行unstack操作
- 如果不是所有的级别值都能在各分组中找到的话,则unstack操作可能会引入缺失数据
- stack默认会滤除缺失数据,因此该运算是可逆的
- 对于DataFrame进行unstack操作时,作为旋转轴的级别将会成为结果中最低的级别,当调用时,可以指明轴的名字
将长格式旋转为宽格式
-
多个时间序列数据通常是以所谓的“长格式”(long)或“堆叠格式”(stacked)存储在数据库和CSV中的
-
DataFrame的pivot方法完全可以实现这个转换
-
pivoted = ldata.pivot('date', 'item', 'value') -
前两个传递的值分别用作行和列索引,最后一个可选值则是用于填充DataFrame的数据列
-
如果忽略最后一个参数,得到的DataFrame就会带有层次化的列
-
pivot其实就是用set_index创建层次化索引,再用unstack重塑
-
将宽格式旋转为长格式
-
旋转DataFrame的逆运算是pandas.melt,不是将一列转换到多个新的DataFrame,而是合并多个列成为一个,产生一个比输入长的DataFrame
-
key列可能是分组指标,其它的列是数据值。当使用pandas.melt,我们必须指明哪些列是分组指标。下面使用key作为唯一的分组指标
-
melted = pd.melt(df, ['key']) ''' key variable value 0 foo A 1 1 bar A 2 2 baz A 3 3 foo B 4 4 bar B 5 5 baz B 6 6 foo C 7 7 bar C 8 8 baz C 9 ''' -
可以使用pivot,重塑回原来的样子
-
reshaped = melted.pivot('key', 'variable', 'value') reshaped.reset_index()
-
-
可以指定列的子集,作为值的列
-
pd.melt(df, id_vars=['key'], value_vars=['A', 'B']) ''' key variable value 0 foo A 1 1 bar A 2 2 baz A 3 3 foo B 4 4 bar B 5 5 baz B 6 '''
-
-
pandas.melt也可以不用分组指标
-
pd.melt(df, value_vars=['A', 'B', 'C']) ''' variable value 0 A 1 1 A 2 2 A 3 3 B 4 4 B 5 5 B 6 6 C 7 7 C 8 8 C 9 ''' pd.melt(df, value_vars=['key', 'A', 'B']) ''' variable value 0 key foo 1 key bar 2 key baz 3 A 1 4 A 2 5 A 3 6 B 4 7 B 5 8 B 6 '''
-
数据聚合与分组运算
GroupBy机制
- 分组运算的术语"split-apply-combine"(拆分-应用-合并)
- 第一个阶段,pandas对象(无论是Series、DataFrame还是其他的)中的数据会根据你所提供的一个或多个键被拆分(split)为多组。拆分操作是在对象的特定轴上执行的。然后,将一个函数应用(apply)到各个分组并产生一个新值。最后,所有这些函数的执行结果会被合并(combine)到最终的结果对象中
- 变量grouped是一个GroupBy对象。它实际上还没有进行任何计算,只是含有一些有关分组键df[‘key1’]的中间数据而已
- GroupBy的size方法,它可以返回一个含有分组大小的Series
对分组进行迭代
-
GroupBy对象支持迭代,可以产生一组二元元组(由分组名和数据块组成)
-
for name, group in df.groupby('key1'): print(name) print(group) -
对于多重键的情况,元组的第一个元素将会是由键值组成的元组
-
for name, group in df.groupby(['key1', 'key2']): print(name) print(group) -
可以对这些数据片段做任何操作
-
groupby默认是在axis=0上进行分组的,通过设置也可以在其他任何轴上进行分组
-
选取一行或一列的子集
-
对于由DataFrame产生的GroupBy对象,如果用一个(单个字符串)或一组(字符串数组)列名对其进行索引,就能实现选取部分列进行聚合的目的
-
df.groupby('key1')['data1'] df.groupby('key1')[['data2']] # 等价于 df['data1'].groupby(df['key1']) df[['data2']].groupby(df['key1'])
-
-
已知列的分组关系,并希望根据分组计算列的和
-
将分组关系字典传给groupby,来构造数组,也可以直接传递字典,存在未使用的分组键压缩可以的
-
people = pd.DataFrame(np.random.randn(5, 5),columns=['a', 'b', 'c', 'd', 'e'],index=['Joe', 'Steve', 'Wes', 'Jim', 'Travis']) people.iloc[2:3, [1, 2]] = np.nan mapping = {'a': 'red', 'b': 'red', 'c': 'blue','d': 'blue', 'e': 'red', 'f' : 'orange'} by_column = people.groupby(mapping, axis=1) # print(people.rename(columns=mapping)) for name,group in by_column: print(name) print("----------------------") print(group)
-
-
Series也有同样的功能,它可以被看做一个固定大小的映射
-
map_series = pd.Series(mapping) people.groupby(map_series, axis=1).count()
-
根据索引级别分组
-
层次化索引数据集最方便的地方就在于它能够根据轴索引的一个级别进行聚合
-
columns = pd.MultiIndex.from_arrays([['US', 'US', 'US', 'JP', 'JP'],[1, 3, 5, 1, 3]],names=['cty', 'tenor']) hier_df = pd.DataFrame(np.random.randn(4, 5), columns=columns) hier_df.groupby(level='cty',axis=1).count() # hier_df.groupby(level='tenor',axis=1).count()
-
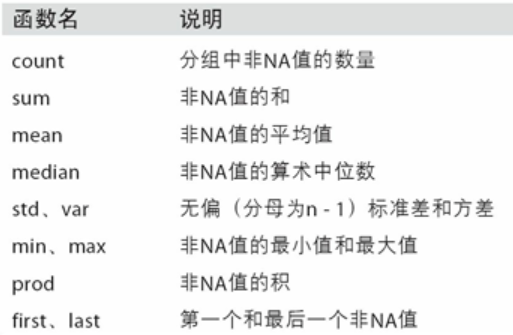
数据聚合
-
聚合指的是任何能够从数组产生标量值的数据转换过程
-
如果要使用你自己的聚合函数,只需将其传入aggregate或agg方法即可
-
def peak_to_peak(arr): return arr.max() - arr.min() grouped.agg(peak_to_peak)
-
-
有些方法(如describe)也是可以用在这里的,即使严格来讲,它们并非聚合运算
-
自定义聚合函数要比表中那些经过优化的函数慢得多。这是因为在构造中间分组数据块时存在非常大的开销(函数调用、数据重排等)。
面向列的多函数应用
-
传入一组函数或函数名,得到的DataFrame的列就会以相应的函数命名
-
grouped_pct.agg(['mean', 'std', peak_to_peak])
-
-
并非一定要接受GroupBy自动给出的那些列名,特别是lambda函数,它们的名称是’',这样的辨识度就很低了(通过函数的
__name__属性看看就知道了)。因此,如果传入的是一个由(name,function)元组组成的列表,则各元组的第一个元素就会被用作DataFrame的列名(可以将这种二元元组列表看做一个有序映射)-
grouped_pct.agg([('foo', 'mean'), ('bar', np.std)])
-
-
对于DataFrame,你还有更多选择,你可以定义一组应用于全部列的一组函数,或不同的列应用不同的函数
-
functions = ['count', 'mean', 'max'] result = grouped['tip_pct', 'total_bill'].agg(functions)
-
-
要对一个列或不同的列应用不同的函数。具体的办法是向agg传入一个从列名映射到函数的字典
-
grouped.agg({'tip' : np.max, 'size' : 'sum'}) grouped.agg({'tip_pct' : ['min', 'max', 'mean', 'std'],'size' : 'sum'})
-
以“没有行索引”的形式返回聚合函数
-
聚合数据都有由唯一的分组键组成的索引(可能还是层次化的)。由于并不总是需要如此,所以你可以向groupby传入as_index=False以禁用该功能
-
tips.groupby(['day', 'smoker'], as_index=False).mean()
-
apply:一般性的“拆分-应用-合并”
-
最通用的GroupBy方法是apply,apply会将待处理的对象拆分成多个片段,然后对各片段调用传入的函数,最后尝试将各片段组合到一起
-
对smoker分组并用该函数调用apply
-
def top(df, n=5, column='tip_pct'): return df.sort_values(by=column)[-n:] tips.groupby('smoker').apply(top) -
如果传给apply的函数能够接受其他参数或关键字,则可以将这些内容放在函数名后面一并传入
tips.groupby(['smoker', 'day']).apply(top, n=1, column='total_bill')
-
-
在GroupBy中,当你调用诸如describe之类的方法时,实际上只是应用了下面两条代码的快捷方式而已
-
f = lambda x: x.describe() grouped.apply(f)
-
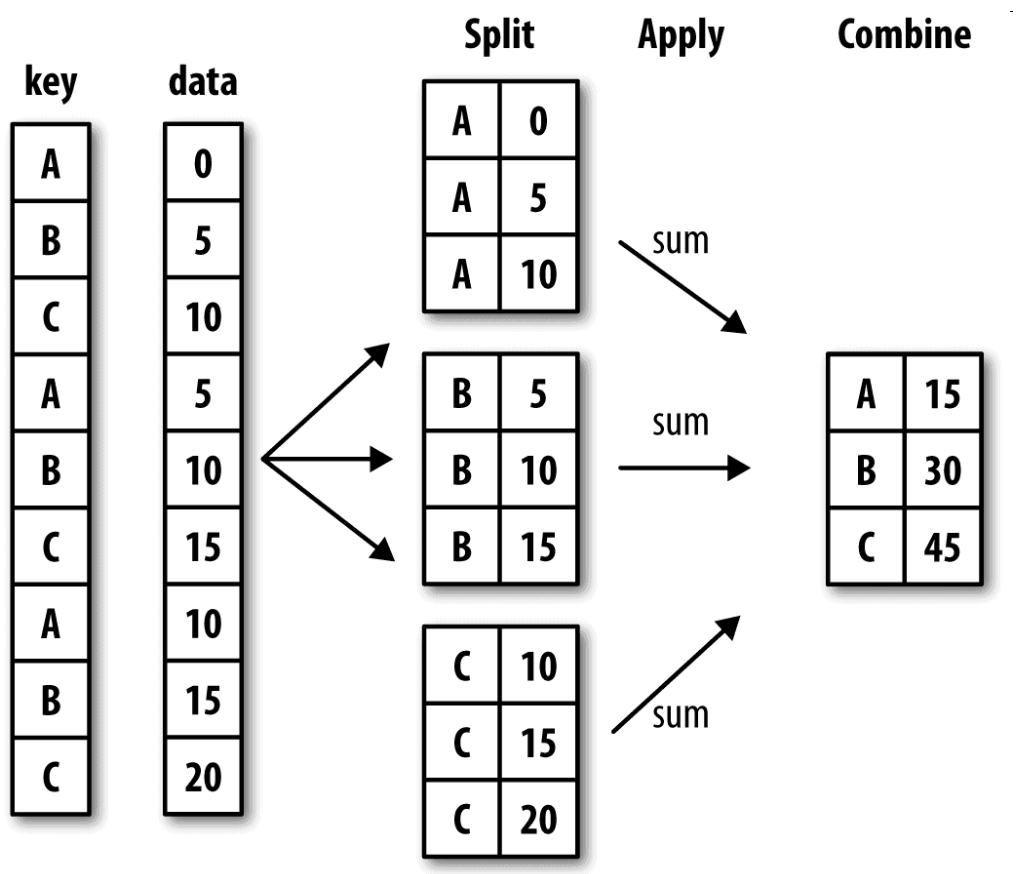
禁止分组键
-
分组键会跟原始对象的索引共同构成结果对象中的层次化索引。将group_keys=False传入groupby即可禁止该效果
-
tips.groupby('smoker', group_keys=False).apply(top)
-
分位数和桶分析
- 利用cut和qcut实现对数据集的桶或分位数的分析
- 由cut返回的Categorical对象可直接传递到groupby
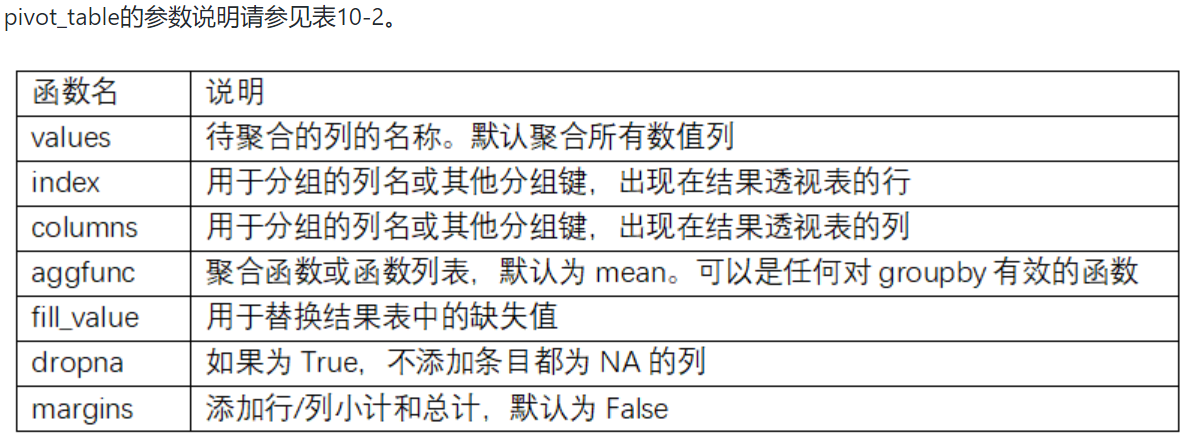
透视表和交叉表
-
透视表(pivot table)是各种电子表格程序和其他数据分析软件中一种常见的数据汇总工具,根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中
-
DataFrame有一个pivot_table方法,此外还有一个顶级的pandas.pivot_table函数。除能为groupby提供便利之外,pivot_table还可以添加分项小计,也叫做margins
-
tips.pivot_table(index=['day', 'smoker'])
-
-
只聚合tip_pct和size,而且想根据time进行分组。将smoker放到列上,把day放到行上
-
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],columns='smoker')
-
-
传入margins=True添加分项小计。这将会添加标签为All的行和列,其值对应于单个等级中所有数据的分组统计
-
tips.pivot_table(['tip_pct', 'size'], index=['time', 'day'],columns='smoker', margins=True) -
这里All为平均数
-
-
要使用其他的聚合函数,将其传给aggfunc即可
-
交叉表:crosstab
-
交叉表(cross-tabulation,简称crosstab)是一种用于计算分组频率的特殊透视表。看下面的例子
-
pd.crosstab(data.Nationality, data.Handedness, margins=True) # crosstab的前两个参数可以是数组或Series,或是数组列表
时间序列
- 时间戳(timestamp),特定的时刻
- 固定时期(period),如2007年1月或2010年全年。
- 时间间隔(interval),由起始和结束时间戳表示。时期(period)可以被看做间隔(interval)的特例
- 实验或过程时间,每个时间点都是相对于特定起始时间的一个度量。例如,从放入烤箱时起,每秒钟饼干的直径
日期和时间数据类型及工具
-
Python标准库包含用于日期(date)和时间(time)数据的数据类型
-
datetime.datetime(也可以简写为datetime)是用得最多的数据类型
-
from datetime import datetime
-
-
datetime以毫秒形式存储日期和时间。timedelta表示两个datetime对象之间的时间差
-
delta = datetime(2011, 1, 7) - datetime(2008, 6, 24, 8, 15) delta.days # 表示相差的天数 delta.seconds # 表示除去天数之后,相差的秒数
-
-
可以给datetime对象加上(或减去)一个或多个timedelta,这样会产生一个新对象
-

字符串和datetime的相互转换
-
利用str或strftime方法(传入一个格式化字符串),datetime对象和pandas的Timestamp对象可以被格式化为字符串
- datetime.strptime可以用上诉格式化编码将字符串转换为日期
- datetime.strptime是通过已知格式进行日期解析的最佳方式
-
用dateutil这个第三方包中的parser.parse方法,dateutil可以解析几乎所有人类能够理解的日期表示形式
-
from dateutil.parser import parse parse('Jan 31, 1997 10:45 PM') parse('Jan 31, 1997 10:45 PM') -
在国际通用格式中,日出现在月的前面很普遍,传入dayfirst=True即可解决
-
dateutil.parser是一个实用但不完美的工具。比如说,它会把一些原本不是日期的字符串认作是日期(比如"42"会被解析为2042年的今天)
-
-
pandas通常是用于处理成组日期的,不管这些日期是DataFrame的轴索引还是列。to_datetime方法可以解析多种不同的日期表示形式。对标准日期格式(如ISO8601)的解析非常快
-
datestrs = ['2011-07-06 12:00:00', '2011-08-06 00:00:00'] -
还可以处理缺失值(None,空字符串)
-
idx = pd.to_datetime(datestrs + [None]) idx # DatetimeIndex(['2011-07-06 12:00:00', '2011-08-06 00:00:00', 'NaT'], dty pe='datetime64[ns]', freq=None) -
NaT(Not a Time) 是pandas中时间戳数据中的null值
-

时间序列基础
-
pandas最基本的时间序列类型就是以时间戳(通常以Python字符串或datatime对象表示)为索引的Series
-
from datetime import datetime dates = [datetime(2011, 1, 2), datetime(2011, 1, 5),datetime(2011, 1, 7), datetime(2011, 1, 8),datetime(2011, 1, 10), datetime(2011, 1, 12)] ts = pd.Series(np.random.randn(6), index=dates) -
这些datetime对象实际上是被放在一个DatetimeIndex中
-
ts.index # DatetimeIndex(['2011-01-02', '2011-01-05', '2011-01-07', '2011-01-08','2011-01-10', '2011-01-12'],dtype='datetime64[ns]', freq=None) -
跟其他Series一样,不同索引的时间序列之间的算术运算会自动按日期对齐
-
ts + ts[::2]
-
-
pandas用Numpy的datetime64数据类型以纳秒形式存储时间戳
-
ts.index.dtype
-
-
DatetimeIndex中的各个标量值是pandas的Timestamp对象
-
stamp = ts.index[0] -
只要有需要,TimeStamp可以随时自动转换为datetime对象。此外,它还可以存储频率信息(如果有的话),且知道如何执行时区转换以及其他操作
-
索引、选取、子集构造
-
当你根据标签索引选取数据时,时间序列和其它的pandas.Series很像
-
对于较长的时间序列,只需传入“年”或“年月”即可轻松选取数据的切片
-
longer_ts = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2000', periods=1000)) longer_ts['2001'] # 传入年进行索引进行索引 longer_ts['2001-05'] # 传入月进行索引
-
-
datetime对象也可以进行切片
-
ts[datetime(2011, 1, 7):]
-
-
由于大部分时间序列数据都是按照时间先后排序的,因此你也可以用不存在于该时间序列中的时间戳对其进行切片(即范围查询)
-
ts['1/6/2011':'1/11/2011'] # 所选日期可以不在数据中
-
-
你可以传入字符串日期、datetime或Timestamp。注意,这样切片所产生的是原时间序列的视图,跟NumPy数组的切片运算是一样的
-
这意味着,没有数据被复制,对切片进行修改会反映到原始数据上
-
有一个等价的实例方法也可以截取两个日期之间TimeSeries
-
ts.truncate(after='1/9/2011') # 2011-01-02 -0.204708 # 2011-01-05 0.478943 # 2011-01-07 -0.519439 # 2011-01-08 -0.555730
-
-
这些操作对DataFrame也有效
-
dates = pd.date_range('1/1/2000', periods=100, freq='W-WED') long_df = pd.DataFrame(np.random.randn(100, 4),index=dates,columns=['Colorado', 'Texas','New York', 'Ohio']) long_df.loc['5-2001']
-
带有重复索引的时间序列
-
可能会存在多个观测数据落在同一个时间点上的情况
-
通过检查索引的is_unique属性,我们就可以知道它是不是唯一的
-
对时间序列进行索引,要么产生标量值,要么产生切片,具体要看所选的时间点是否重复
-
对具有非唯一时间戳的数据进行聚合。一个办法是使用groupby,并传入level=0
-
dates = pd.DatetimeIndex(['1/1/2000', '1/2/2000', '1/2/2000', '1/2/2000', '1/3/2000']) dup_ts = pd.Series(np.arange(5), index=dates) dup_ts.index.is_unique grouped = dup_ts.groupby(level=0)
-
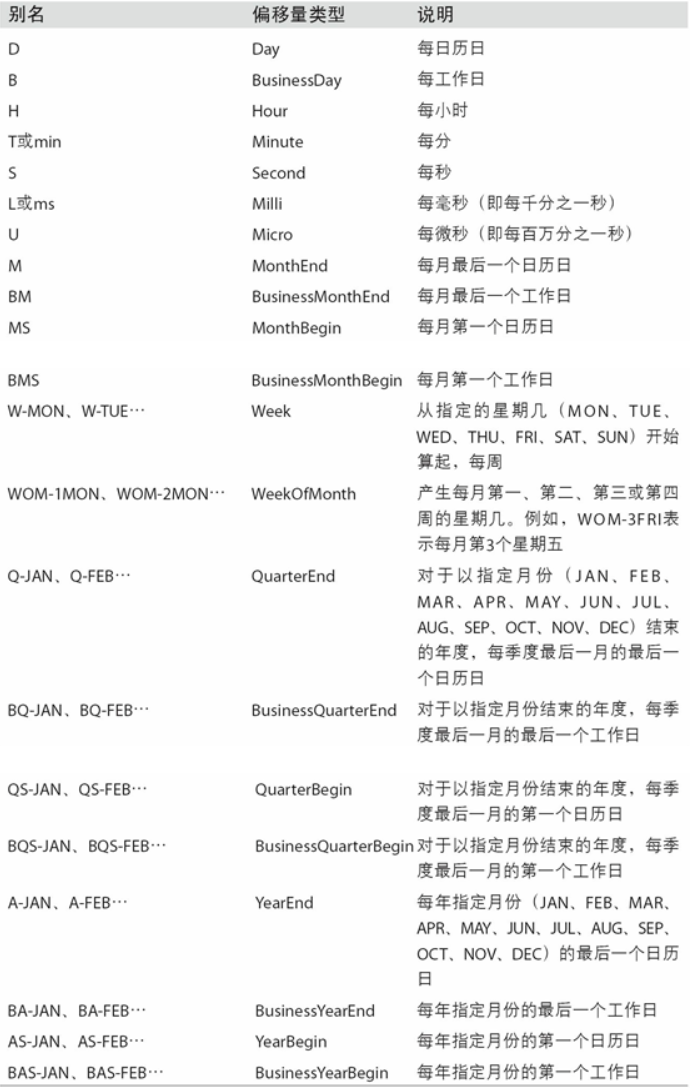
日期的范围、频率以及移动
- pandas中的原生时间序列一般被认为是不规则的,也就是说,它们没有固定的频率
- resample,一整套标准时间序列频率以及用于重采样、频率推断、生成固定频率日期范围的工具
生成日期范围
-
pandas.date_range可用于根据指定的频率生成指定长度的DatetimeIndex
-
index = pd.date_range('2012-04-01', '2012-06-01') -
date_range会产生按天计算的时间点。如果只传入起始或结束日期,那就还得传入一个表示一段时间的数字
-
pd.date_range(start='2012-04-01', periods=20) pd.date_range(end='2012-06-01', periods=20) -
起始和结束日期定义了日期索引的严格边界。例如,如果你想要生成一个由每月最后一个工作日组成的日期索引,可以传入"BM"频率
-
pd.date_range('2000-01-01', '2000-12-01', freq='BM') -
-
-
date_range默认会保留起始和结束时间戳的时间信息(如果有的话)
-
有时,虽然起始和结束日期带有时间信息,但你希望产生一组被规范化(normalize)到午夜的时间戳。normalize选项即可实现该功能
频率和日期偏移量
-
pandas中的频率是由一个基础频率(base frequency)和一个乘数组成的。基础频率通常以一个字符串别名表示,比如"M"表示每月,"H"表示每小时。对于每个基础频率,都有一个被称为日期偏移量(date offset)的对象与之对应
-
from pandas.tseries.offsets import Hour, Minute -
传入一个整数即可定义偏移量的倍数
-
four_hours = Hour(4) -
一般来说,无需明确创建这样的对象,只需使用诸如"H"或"4H"这样的字符串别名即可。在基础频率前面放上一个整数即可创建倍数
-
pd.date_range('2000-01-01', '2000-01-03 23:59', freq='4h') -
大部分偏移量对象都可通过加法进行连接
-
Hour(2) + Minute(30) -
可以传入频率字符串(如"2h30min"),这种字符串可以被高效地解析为等效的表达式
-
pd.date_range('2000-01-01', periods=10, freq='1h30min')
-
移动(超前和滞后)数据
-
移动(shifting)指的是沿着时间轴将数据前移或后移。Series和DataFrame都有一个shift方法用于执行单纯的前移或后移操作,保持索引不变
-
ts.shift(2) -
shift通常用于计算一个时间序列或多个时间序列(如DataFrame的列)中的百分比变化。可以这样表达
-
ts / ts.shift(1) - 1
-
-
单纯的移位操作不会修改索引,所以部分数据会被丢弃。如果频率已知,则可以将其传给shift以便实现对时间戳进行位移而不是对数据进行简单位移
-
ts.shift(2, freq='M') -
也能使用其他评率
-
通过偏移量对日期进行位移
-
pandas的日期偏移量还可以用在datetime或Timestamp对象上
-
from pandas.tseries.offsets import Day, MonthEnd now = datetime(2011, 11, 17) now + 3 * Day() -
如果加的是锚点偏移量(比如MonthEnd)第一次增量会将原日期向前滚动到符合频率规则的下一个日期
-
now + MonthEnd() -
通过锚点偏移量的rollforward和rollback方法,可明确地将日期向前或向后“滚动”
-
offset = MonthEnd() offset.rollforward(now) offset.rollback(now)
-
-
日期偏移量还有一个巧妙的用法,即结合groupby使用这两个“滚动”方法
-
ts = pd.Series(np.random.randn(20),index=pd.date_range('1/15/2000', periods=20, freq='4d')) ts.groupby(offset.rollforward).mean() -
更简单、更快速地实现该功能的办法是使用resample
-
时区处理
时区本地化和转换
-
默认情况下,pandas中的时间序列是单纯(naive)的时区
-
用时区生成日期范围
-
pd.date_range('3/9/2012 9:30', periods=10, freq='D', tz='UTC')
-
-
从单纯到本地化的转换是通过tz_localize方法
-
ts_utc = ts.tz_localize('UTC')
-
-
一旦时间序列被本地化到某个特定时区,就可以用tz_convert将其转换到别的时区
-
ts_utc.tz_convert('America/New_York')
-
操作时区意识型Timestamp对象
-
冬令时通常代表使用当地的标准时间,夏令时实施期间时钟拨快一小时,相当于时区往前(东)进一个,每年都会对时间进行两次调整。
-
时间序列和日期范围差不多,独立的Timestamp对象也能被从单纯型(naive)本地化为时区意识型(time zone-aware),并从一个时区转换到另一个时区
-
stamp = pd.Timestamp('2011-03-12 04:00') stamp_utc = stamp.tz_localize('utc') stamp_utc.tz_convert('America/New_York')
-
-
创建Timestamp时,还可以传入时区信息
-
stamp_moscow = pd.Timestamp('2011-03-12 04:00', tz='Europe/Moscow')
-
-
时区意识型Timestamp对象在内部保存了一个UTC时间戳值(自UNIX纪元(1970年1月1日)算起的纳秒数)。这个UTC值在时区转换过程中是不会发生变化的
-
stamp_utc.value # 1299902400000000000 stamp_utc.tz_convert('America/New_York').value # 1299902400000000000
-
-
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期
-
from pandas.tseries.offsets import Hour stamp = pd.Timestamp('2012-03-12 01:30', tz='US/Eastern')
-
不同时区时间的运算
-
如果两个时间序列的时区不同,在将它们合并到一起时,最终结果就会是[UTC](协调世界时_百度百科 (baidu.com))
-
ts1 = ts[:7].tz_localize('Europe/London') ts2 = ts1[2:].tz_convert('Europe/Moscow') result = ts1 + ts2
-
时间及其算术运算
-
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数
-
p = pd.Period(2007, freq='A-DEC') -
这个Period对象表示的是从2007年1月1日到2007年12月31日之间的整段时间
-
-
对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果
-
p + 5 p - 2
-
-
如果两个Period对象拥有相同的频率,则它们的差就是它们之间的单位数量
-
pd.Period('2014', freq='A-DEC') - p # 7
-
-
period_range函数可用于创建规则的时期范围
-
rng = pd.period_range('2000-01-01', '2000-06-30', freq='M')
-
-
PeriodIndex类保存了一组Period,它可以在任何pandas数据结构中被用作轴索引
-
pd.Series(np.random.randn(6), index=rng)
-
-
如果有一个字符串数组,也可以使用PeriodIndex类
-
values = ['2001Q3', '2002Q2', '2003Q1'] index = pd.PeriodIndex(values, freq='Q-DEC')
-
时期的频率转换
-
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率
-
p = pd.Period('2007', freq='A-DEC') p.asfreq('M', how='start') # Period('2007-01', 'M') p.asfreq('M', how='end') # Period('2007-12', 'M')
-
-
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2007年8月”实际上是属于周期“2008年”的
-
p = pd.Period('Aug-2007', 'M')
-
按季度计算的时期频率
-
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义
-
p = pd.Period('2012Q4', freq='Q-JAN')
-
-
period_range可用于生成季度型范围
-
rng = pd.period_range('2011Q3', '2012Q4', freq='Q-JAN') ts = pd.Series(np.arange(len(rng)), index=rng)
-
将Timestamp转换为Period(及其反向过程)
-
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引
-
rng = pd.date_range('2000-01-01', periods=3, freq='M') ts = pd.Series(np.random.randn(3), index=rng) pts = ts.to_period()
-
-
新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期
-
rng = pd.date_range('1/29/2000', periods=6, freq='D') ts2 = pd.Series(np.random.randn(6), index=rng) ts2.to_period('M')
-
-
要转换回时间戳,使用to_timestamp即可
-
pts.to_timestamp(how='end')
-
使用数据创建PeriodIndex
-
固定频率的数据集通常会将时间信息分开存放在多个列中
-
通过将这些数组以及一个频率传入PeriodIndex
-
index = pd.PeriodIndex(year=data.year, quarter=data.quarter,freq='Q-DEC') # data.year是数据中的标签
-
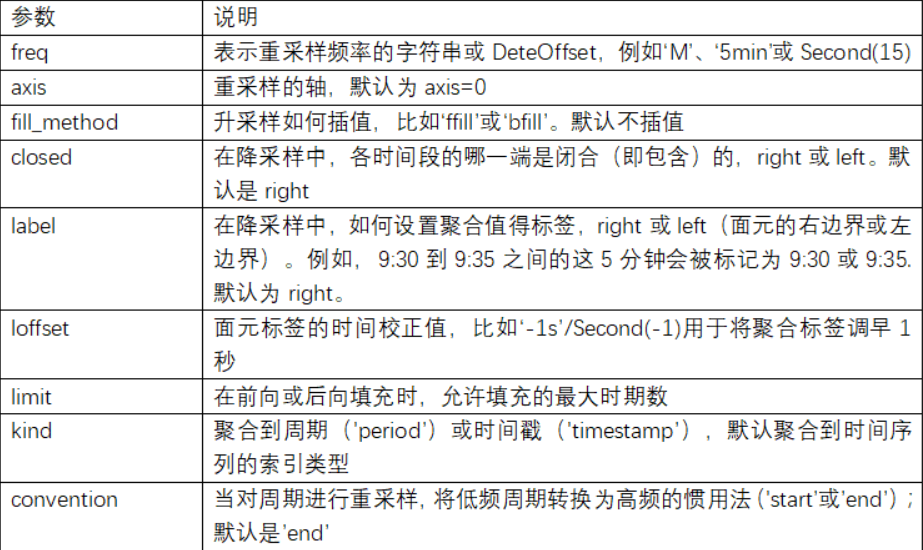
重采样及频率转换
-
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)
-
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数
-
resample有一个类似于groupby的API,调用resample可以分组数据,然后会调用一个聚合函数
-
rng = pd.date_range('2000-01-01', periods=100, freq='D') ts = pd.Series(np.random.randn(len(rng)), index=rng) ts.resample('M').mean() ts.resample('M', kind='period').mean() # kind='period'是采用时期 -
-
降采样
-
将数据聚合到规律的低频率是一件非常普通的时间序列处理任务
-
待聚合的数据不必拥有固定的频率,期望的频率会自动定义聚合的面元边界,这些面元用于将时间序列拆分为多个片段
-
所有时间段的并集必须能组成整个时间帧。在用resample对数据进行降采样时,需要考虑两样东西:
- 各区间哪边是闭合的
- 如何标记各个聚合面元,用区间的开头还是末尾
-
resample
- 默认情况下,面元的右边界是包含的
- 传入closed='left’会让区间以左边界闭合
-
通过loffset设置一个字符串或日期偏移量
-
ts.resample('5min', closed='right',label='right', loffset='-1s').sum()
-
OHLC重采样
-
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低,调用ohlc方法即可即可得到一个含有这四种聚合值的DataFrame。整个过程很高效,只需一次扫描即可计算出结果
-
ts.resample('5min').ohlc()
-
升采样和插值
-
在将数据从低频率转换到高频率时,就不需要聚合了
-
frame = pd.DataFrame(np.random.randn(2, 4),index=pd.date_range('1/1/2000', periods=2,freq='W-WED'),columns=['Colorado', 'Texas', 'New York', 'Ohio']) -
当你对这个数据进行聚合,每组只有一个值,这样就会引入缺失值。我们使用asfreq方法转换成高频,不经过聚合
-
df_daily = frame.resample('D').asfreq() -
resample的填充和插值方式跟fillna和reindex的一样
-
frame.resample('D').ffill()
-
通过时期进行重采样
-
对那些使用时期索引的数据进行重采样与时间戳很像
-
frame = pd.DataFrame(np.random.randn(24, 4),index=pd.period_range('1-2000', '12-2001',freq='M'),columns=['Colorado', 'Texas', 'New York', 'Ohio']) annual_frame = frame.resample('A-DEC').mean()
-
-
升采样要稍微麻烦一些,因为你必须决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法那样。convention参数默认为’start’,也可设置为’end’
-
annual_frame.resample('Q-DEC').ffill() annual_frame.resample('Q-DEC', convention='end').ffill()
-
-
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格
- 在降采样中,目标频率必须是源频率的子时期(subperiod)
- 在升采样中,目标频率必须是源频率的超时期(superperiod)
-
如果不满足这些条件,就会引发异常。这主要影响的是按季、年、周计算的频率。
移动窗口函数
-
在移动窗口(可以带有指数衰减权数)上计算的各种统计函数也是一类常见于时间序列的数组变换。这样可以圆滑噪音数据或断裂数据。我将它们称为移动窗口函数(moving window function)
-
引入rolling运算符,它与resample和groupby很像。可以在TimeSeries或DataFrame以及一个window(表示期数,见图11-4)上调用它
-
close_px.AAPL.rolling(250).mean().plot()
-
pandas高级应用
分类数据
背景和目的
-
表中的一列通常会有重复的包含不同值的小集合的情况。我们已经学过了unique和value_counts,它们可以从数组提取出不同的值,并分别计算频率
-
import numpy as np; import pandas as pd values = pd.Series(['apple', 'orange', 'apple','apple'] * 2) pd.unique(values) pd.value_counts(values)
-
-
许多数据系统(数据仓库、统计计算或其它应用)都发展出了特定的表征重复值的方法,以进行高效的存储和计算。在数据仓库中,最好的方法是使用所谓的包含不同值的维表(Dimension Table),将主要的参数存储为引用维表整数键
-
values = pd.Series([0, 1, 0, 0] * 2) dim = pd.Series(['apple', 'orange']) # take() 不根据对象的索引属性进行索引,而是根据传递进来的值进行索引 dim.take(values) """ 0 apple 1 orange 0 apple 0 apple 0 apple 1 orange 0 apple 0 apple """ # take根据元素在对象中的实际位置建立索引 df = pd.DataFrame([('falcon', 'bird', 389.0),('parrot', 'bird', 24.0),('lion', 'mammal', 80.5),('monkey', 'mammal', np.nan)],columns=['name', 'class', 'max_speed'],index=[0, 2, 3, 1]) df """ name class max_speed 0 falcon bird 389.0 2 parrot bird 24.0 3 lion mammal 80.5 1 monkey mammal NaN """ df.take([0, 3]) """ name class max_speed 0 falcon bird 389.0 1 monkey mammal NaN 根据对象实际位置进行索引 """
-
pandas的分类类型
-
pandas有一个特殊的分类类型,用于保存使用整数分类表示法的数据
-
df[‘fruit’]是一个Python字符串对象的数组。我们可以通过调用它,将它转变为分类
-
fruit_cat = df['fruit'].astype('category') -
fruit_cat的值不是NumPy数组,而是一个pandas.Categorical实例
-
分类对象有categories和codes属性
-
可将DataFrame的列通过分配转换结果,转换为分类
-
可以从其它Python序列直接创建pandas.Categorical
-
my_categories = pd.Categorical(['foo', 'bar', 'baz', 'foo', 'bar']) -
已经从其它源获得了分类编码,你还可以使用from_codes构造器
-
categories = ['foo', 'bar', 'baz'] codes = [0, 1, 2, 0, 0, 1] my_cats_2 = pd.Categorical.from_codes(codes, categories) -
可以指定分类一个有意义的顺序
-
ordered_cat = pd.Categorical.from_codes(codes, categories,ordered=True)
-
用分类进行计算
-
在计算数据的分位面元时,直接使用qcut会导致确切的样本分位数与分位的名称不同,不利于生成汇总,可以使用labels参数qcut
-
bins = pd.qcut(draws, 4, labels=['Q1', 'Q2', 'Q3', 'Q4'])
-
使用分类提高性能
-
GroupBy使用分类操作更快,是因为底层的算法使用整数编码数组,而不是字符串数组
-
将标签转化为分类
-
categories = labels.astype('category')
-
分类方法
-
特别的cat属性提供了分类方法的入口
-
s = pd.Series(['a', 'b', 'c', 'd'] * 2) cat_s = s.astype('category') cat_s.cat.codes """ 0 0 1 1 2 2 3 3 4 0 5 1 6 2 7 3 dtype: int8 """
-
-
假设数据的实际分类集,超出了数据中的四个值。可以使用set_categories方法改变它们
-
actual_categories = ['a', 'b', 'c', 'd', 'e'] cat_s2 = cat_s.cat.set_categories(actual_categories)
-
-
在大数据集中,分类经常作为节省内存和高性能的便捷工具。过滤完大DataFrame或Series之后,许多分类可能不会出现在数据中。我们可以使用remove_unused_categories方法删除没看到的分类
-
cat_s3.cat.remove_unused_categories() -
-
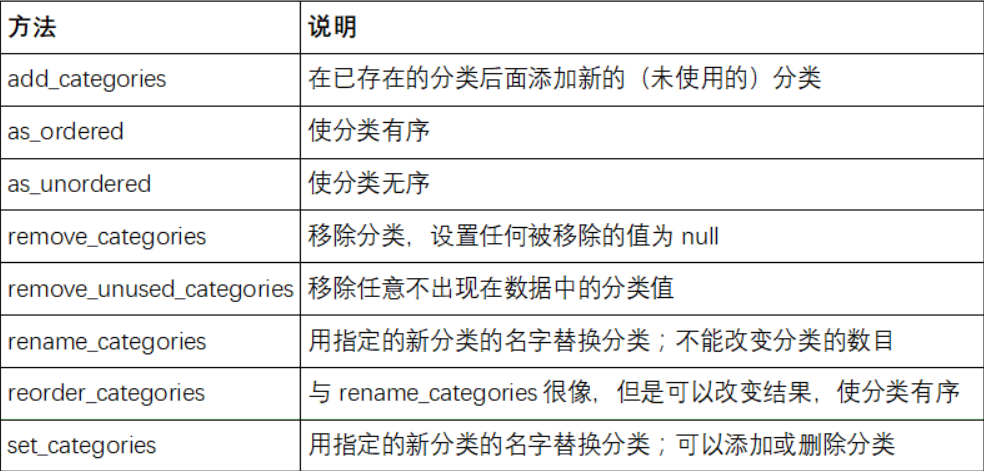
Pandas与建模库介绍
- pandas与其它分析库通常是靠NumPy的数组联系起来的。将DataFrame转换为NumPy数组,可以使用.values属性
- 要转换回DataFrame,可以传递一个二维ndarray,可带有列名
- 最好当数据是均匀的时候使用.values属性。例如,全是数值类型。如果数据是不均匀的,结果会是Python对象的ndarray
- 即dtype为object
matplotlib 入门
Figure和Subplot
-
matplotlib的图像都位于Figure对象中,可以用plt.figure创建一个新的Figure
-
fig = plt.figure() -
不能使用空Figure绘图,必须用add_subplot创建一个或多个subplot才行
-
ax1 = fig.add_subplot(2,2,1) # 图像应该是2×2的(即最多4张图),且当前选中的是4个subplot中的第一个(编号从1开始) ax2 = fig.add_subplot(2,2,2) ax2 = fig.add_subplot(2,2,3) -
如果这时执行绘图命令,matplotlib就会在最后一个使用过的subplot(如果没有则创建一个)上绘制,隐藏创建figure和subplot的过程
plt.plot(np.random.randn(50).cumsum(), 'k--') # "k--"是一个线型选项,用于告诉matplotlib绘制黑色虚线图 -
由fig.add_subplot所返回的对象是AxesSubplot对象,直接调用它们的实例方法就可以在其它空着的格子里面画图了
ax1.hist(np.random.randn(100), bins=20, color='k', alpha=0.3) ax2.scatter(np.arange(30), np.arange(30) + 3 * np.random.randn(30))
-
-
matplotlib有一个更为方便的方法plt.subplots,它可以创建一个新的Figure,并返回一个含有已创建的subplot对象的NumPy数组
-
fig, axes = plt.subplots(2, 3) axes[0,1] # 像二维数组一样
-
调整subplot周围的间距
-
如果你调整了图像大小(不管是编程还是手工),间距也会自动调整。利用Figure的subplots_adjust方法可以轻而易举地修改间距
-
subplots_adjust(left=None, bottom=None, right=None, top=None,wspace=None, hspace=None) # wspace和hspace用于控制宽度和高度的百分比,可以用作subplot之间的间距
-
颜色、标记和线型
-
matplotlib的plot函数接受一组X和Y坐标,还可以接受一个表示颜色和线型的字符串缩写
-
ax.plot(x, y, 'g--') # 根据x和y绘制绿色虚线 也可以指定颜色码 -
也可以在一个字符串中指定颜色和线型的方式
-
ax.plot(x, y, linestyle='--', color='g') -
标记类型和线型必须放在颜色后面
-
plt.plot(randn(30).cumsum(), 'ko--') -
也可以写成更加明确的形式
plot(randn(30).cumsum(), color='k', linestyle='dashed', marker='o') -
你必须调用plt.legend(或使用ax.legend,如果引用了轴的话)来创建图例,无论你绘图时是否传递label标签选项
data = np.random.randn(30).cumsum() np.random.seed(42) plt.plot(data, 'k--', label='Default') plt.plot(data, 'k-', drawstyle='steps-post', label='steps-post') plt.legend(loc='best') # 用于传递label标签
-
设置标题、轴标签、刻度以及刻度标签
-
设置标题
set_title()
-
设置轴标签
- x轴标签
set_xticks()默认为刻度标签 set_xtickslabels()将任何其他值用作标签,rotation=30, fontsize='small'选项rotation用来设定倾斜30°
- x轴标签
-
也可以进行批量设置
-
props = { 'title': 'My first matplotlib plot', 'xlabel': 'Stages' } ax.set(**props)
-
-
使用set_xlim和set_ylim人工设定起始和结束边界
-
ax.set_xlim(['1/1/2007', '1/1/2011']) ax.set_ylim([600, 1800])
-
添加图例
-
图例(legend)是另一种用于标识图表元素的重要工具。添加图例的方式有多种。最简单的是在添加subplot的时候传入label参数
-
可以调用ax.legend()或plt.legend()来自动创建图例
-
ax.legend(loc='best') # loc选择将图例放在哪里,best会选择将图例放在最不碍事的位置
注解以及在Subplot上绘图
-
注解和文字可以通过text、arrow和annotate函数进行添加
-
text可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式
-
ax.text(x, y, 'Hello world!', family='monospace', fontsize=10) # x,y 传入坐标值,后面跟着text文本,
-
-
如果要在matplotlib上绘制图形,这些对象被称为块,完整的集合在matplotlib.patches,要在图表中添加一个图形,需要创建一个块对象,然后通过ax.add_patch(shp)将其添加到subplot中
将图表保存到文件
-
利用plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig
-
plt.savefig('figpath.svg') # 将图片保存为svg文件 -
参数:dpi(控制“每英寸点数”分辨率)和bbox_inches(可以剪除当前图表周围的空白部分)
-
matplotlib配置
-
使用rc方法,管理图像大小、subplot边距、配色方案、字体大小、网格类型等
-
plt.rc('figure', figsize=(10, 10)) -
rc的第一个参数是希望自定义的对象,如’figure’、‘axes’、‘xtick’、‘ytick’、‘grid’、'legend’等。其后可以跟上一系列的关键字参数。一个简单的办法是将这些选项写成一个字典
-
font_options = {'family' : 'monospace', 'weight' : 'bold', 'size' : 'small'} plt.rc('font', **font_options)
-
使用pandas和seaborn绘图
线形图
-
Series和DataFrame都有一个用于生成各类图表的plot方法。默认情况下,它们所生成的是线型图
-
Series
-
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) s.plot() -
Series对象的索引会被传给matplotlib,并绘制X轴,可以通过use_index=False禁用该功能,X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim
-
-
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这使你能够在网格布局中更为灵活地处理subplot的位置
-
-
DataFrame
- DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例
- df.plot()等价于df.plot.line()


柱状图
- plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度
- 设置stacked=True即可为DataFrame生成堆积柱状图
- 利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts().plot.bar()
直方图和密度图
-
Series使用plot.hist方法绘制,直方图
-
tips['tip_pct'].plot.hist(bins=50) # hist绘制直方图
-
-
Series使用plot.density()方法绘制,密度图
-
tips['tip_pct'].plot.density()
-
散布图或者点图
-
使用seaborn的regplot方法,它可以做一个散布图,并加上一条线性回归的线
-
sns.regplot('m1', 'unemp', data=trans_data)
-
-
seaborn提供了一个便捷的pairplot函数,它支持在对角线上放置每个变量的直方图或密度估计
-
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})
-
-
seaborn有一个有用的内置函数factorplot,可以简化制作多种分面图
-
sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker',kind='bar', data=tips[tips.tip_pct < 1])
-
egend()来自动创建图例
-
ax.legend(loc='best') # loc选择将图例放在哪里,best会选择将图例放在最不碍事的位置
注解以及在Subplot上绘图
-
注解和文字可以通过text、arrow和annotate函数进行添加
-
text可以将文本绘制在图表的指定坐标(x,y),还可以加上一些自定义格式
-
ax.text(x, y, 'Hello world!', family='monospace', fontsize=10) # x,y 传入坐标值,后面跟着text文本,
-
-
如果要在matplotlib上绘制图形,这些对象被称为块,完整的集合在matplotlib.patches,要在图表中添加一个图形,需要创建一个块对象,然后通过ax.add_patch(shp)将其添加到subplot中
将图表保存到文件
-
利用plt.savefig可以将当前图表保存到文件。该方法相当于Figure对象的实例方法savefig
-
plt.savefig('figpath.svg') # 将图片保存为svg文件 -
参数:dpi(控制“每英寸点数”分辨率)和bbox_inches(可以剪除当前图表周围的空白部分)
-
matplotlib配置
-
使用rc方法,管理图像大小、subplot边距、配色方案、字体大小、网格类型等
-
plt.rc('figure', figsize=(10, 10)) -
rc的第一个参数是希望自定义的对象,如’figure’、‘axes’、‘xtick’、‘ytick’、‘grid’、'legend’等。其后可以跟上一系列的关键字参数。一个简单的办法是将这些选项写成一个字典
-
font_options = {'family' : 'monospace', 'weight' : 'bold', 'size' : 'small'} plt.rc('font', **font_options)
-
使用pandas和seaborn绘图
线形图
-
Series和DataFrame都有一个用于生成各类图表的plot方法。默认情况下,它们所生成的是线型图
-
Series
-
s = pd.Series(np.random.randn(10).cumsum(), index=np.arange(0, 100, 10)) s.plot() -
Series对象的索引会被传给matplotlib,并绘制X轴,可以通过use_index=False禁用该功能,X轴的刻度和界限可以通过xticks和xlim选项进行调节,Y轴就用yticks和ylim
-
[外链图片转存中…(img-g0WEj4LD-1657024213468)]
-
pandas的大部分绘图方法都有一个可选的ax参数,它可以是一个matplotlib的subplot对象。这使你能够在网格布局中更为灵活地处理subplot的位置
-
-
DataFrame
- DataFrame的plot方法会在一个subplot中为各列绘制一条线,并自动创建图例
- df.plot()等价于df.plot.line()
- [外链图片转存中…(img-Ok2I6gJr-1657024213468)]
柱状图
- plot.bar()和plot.barh()分别绘制水平和垂直的柱状图。这时,Series和DataFrame的索引将会被用作X(bar)或Y(barh)刻度
- 设置stacked=True即可为DataFrame生成堆积柱状图
- 利用value_counts图形化显示Series中各值的出现频率,比如s.value_counts().plot.bar()
直方图和密度图
-
Series使用plot.hist方法绘制,直方图
-
tips['tip_pct'].plot.hist(bins=50) # hist绘制直方图
-
-
Series使用plot.density()方法绘制,密度图
-
tips['tip_pct'].plot.density()
-
散布图或者点图
-
使用seaborn的regplot方法,它可以做一个散布图,并加上一条线性回归的线
-
sns.regplot('m1', 'unemp', data=trans_data)
-
-
seaborn提供了一个便捷的pairplot函数,它支持在对角线上放置每个变量的直方图或密度估计
-
sns.pairplot(trans_data, diag_kind='kde', plot_kws={'alpha': 0.2})
-
-
seaborn有一个有用的内置函数factorplot,可以简化制作多种分面图
-
sns.factorplot(x='day', y='tip_pct', hue='time', col='smoker',kind='bar', data=tips[tips.tip_pct < 1])
-