Abstract
虽然深度卷积神经网络 (CNN) 在使用附加高斯白噪声 (AWGN)(Additive White Gaussian Noise,加性的意思是,可以将噪声直接加在原始信号上) 进行图像去噪方面取得了令人印象深刻的成功,但它们的性能主要受限于现实世界的噪声照片。主要原因是他们学习的模型很容易在简化的 AWGN 模型上过拟合,这与复杂的真实噪声模型严重不同。为了证明深度 CNN 降噪器的泛化能力,我们建议使用更真实的噪声模型和真实世界的噪声-干净图像对来训练卷积盲去噪网络 (CBDNet)。一方面,信号相关噪声和相机内信号处理管道都被认为可以合成逼真的噪声图像。另一方面,现实世界的嘈杂照片及其几乎无噪点的照片也包括在内,以训练我们的 CBD 网络。为了进一步提供一种交互式策略来方便地校正去噪结果,在 CBDNet 中嵌入了一个具有非对称学习功能的噪声估计子网络,以抑制对噪声水平的低估。对真实世界噪声照片的三个数据集的广泛实验结果清楚地表明,CBDNet 在定量测量和视觉质量方面的性能优于最先进的技术。该代码已在 https://github.com/GuoShi28/CBDNet 上提供。
1. Introduction
图像去噪是低层次视觉和图像处理中的一个基本问题。经过几十年的研究,许多有前途的方法[3,12,17,53,11,61]已经被开发出来,并实现了接近最优的性能[8,31,50]来去除加性高斯白噪声(AWGN)。然而,在真实的摄像机系统中,图像噪声来自多个来源(如暗电流噪声、短噪声和热噪声),并进一步受到摄像机内处理(ISP)管道的影响(如解识别、伽马校正和压缩)。所有这些都让真正的噪音变得更加不同于AWGN,和真实世界嘈杂照片的盲去噪仍然是一个具有挑战性的问题。
近年来,随着深度cnn[61,38,62]的发展,高斯去噪性能得到了显著提高。然而,用于盲AWGN去除的深度去噪器当应用于真实照片时会显著下降(见图1(d))。另一方面,对于非盲AWGN去除的深度去噪器可以在去除噪声的同时平滑细节(见图1(e))。这种现象可以从深度CNNs [39]的特征来解释,它们的泛化在很大程度上取决于记忆大规模训练数据的能力。换句话说,现有的CNN去噪器往往对高斯噪声过拟合,对具有更复杂噪声的真实噪声图像的推广效果较差。
就是对合成噪声去噪效果还ok,真实的噪声图像就不太行了
在本文中,我们通过开发一个针对真实世界照片的卷积盲去噪网络(CBDNet)来解决这个问题。正如[39]所示,CNN去噪器的成功与否在很大程度上取决于合成噪声和真实噪声的分布是否完全匹配良好。因此,真实噪声模型是真实照片盲去噪的首要问题。根据[14,45],泊松高斯分布可以近似为信号相关的异方差高斯和平稳噪声分量,被认为是比AWGN更适合真实的原始噪声建模的替代。此外,相机内处理将进一步使噪声在空间和色上相关,从而增加噪声的复杂性。因此,我们在我们的噪声模型中同时考虑了泊松-高斯模型和相机内处理管道(例如,去识别、伽马校正和JPEG压缩)。实验表明,摄像机内处理管道在实际噪声建模中起着核心作用,在DND [45]上获得了显著的性能增益(即PSNR的>5 dB)。(DND是数据集)
我们进一步结合了合成的和真实的噪声图像来训练CBDNet。一方面,它很容易获得大量的合成噪声图像。然而,我们的模型并不能完全表征真实照片中的噪声,从而为提高去噪性能提供了一定的回旋余地。另一方面,[43,1]提出的几种方法是通过在同一场景中平均数百幅噪声图像来获得无噪声图像。然而,这种解决方案的成本很昂贵,并受到无噪声图像的过度平滑效应。结合合成和真实噪声图像,DND [45]上的CBDNet可以在PSNR上获得0.3∼0.5 dB增益。
“盲去噪”中的“盲”(Blind)指的是去噪算法在处理图像时并不知道噪声的具体模型或参数。换句话说,算法必须在没有先验知识的情况下工作,即不知道噪声是如何加入到原始图像中的。这与非盲去噪方法形成对比,后者通常需要知道噪声的类型和强度,或者至少有一些关于噪声特性的假设。

图1:不同方法对来自DND的真实世界噪声图像“0002 02”的去噪结果
我们的CBDNet由两个子网组成,即噪声估计和非盲去噪。随着噪声估计子网络的引入,我们采用了非对称损失,对噪声水平的低估误差施加更大的惩罚,使CBDNet在噪声模型与真实噪声的不匹配时性能稳健。此外,它还允许用户通过调整估计的噪声水平图来交互式地校正去噪结果。在NC12 [29]、DND [45]和Nam [43]三个真实噪声图像数据集上进行了广泛的实验。在定量指标和感知质量方面,我们的CBDNet的表现优于现有的艺术水平。如图1所示,盲的AWGN [61]的非盲BM3D [12]和DnCNN都不能对真实世界的噪声照片进行去噪。相比之下,我们的CBDNet通过保留大部分结构和细节,同时消除复杂的真实噪声,实现了非常令人满意的去噪结果。
综上所述,该工作的贡献是四方面的:通过同时考虑异方差高斯噪声和摄像机内处理管道,提出了一个真实的噪声模型,极大地提高了去噪性能。•合成噪声图像和真实噪声照片,以更好地表征真实图像噪声和提高去噪性能。•利用噪声估计子网络的引入,提出了非对称损失来提高对真实噪声的泛化能力,并通过调整噪声水平图来允许交互式去噪。在三个真实世界的噪声图像数据集上进行的•实验表明,我们的CBDNet在定量指标和视觉质量方面都取得了最先进的结果。
异方差高斯噪声是指噪声的方差(即强度)在图像的不同区域是不一样的。例如,在较亮的图像区域,噪声水平可能会更高;而在较暗的区域,噪声水平可能会更低。这种噪声模型更符合实际场景中的噪声分布,因为在实际成像过程中,噪声通常不是均匀分布的,而是与光照条件、曝光时间和传感器灵敏度等因素有关。
2.Related Work
2.1. Deep CNN Denoisers
深度神经网络(DNNs)的出现使高斯去噪得到了很大的改进。在Burger等人使用[6]之前,大多数早期的深度模型都无法达到最先进的去噪性能[22,49,57]。随后,脑脊液[53]和TNRD [11]展开了求解专家模型领域的优化算法,以学习阶段推理过程。通过结合残差学习[19]和批处理归一化[21],Zhang等人[61]提出了一种去噪CNN(DnCNN),它可以优于传统的基于非CNN的方法。没有使用干净的数据,噪声2噪声[30]也取得了最先进的水平。最近,其他CNN方法,如RED30 [38]、MemNet [55]、BM3D-Net [60]、MWCNN [33]和FFDNet [62],也开发出了良好的去噪性能。
得益于[61,38,55]神经网络的建模能力,研究表明,学习单一的盲高斯去噪模型是可行的。然而,这些盲模型可能过度适合AWGN,无法处理真正的噪音。相比之下,非盲的CNN去噪器,如FFDNet [62],通过手动设置适当的或相对较高的噪声水平,可以在大多数真实的噪声图像上获得令人满意的结果。为了利用这一特性,我们的CBDNet包括一个噪声估计子网络和一个非对称损失,以抑制噪声水平的欠估计误差。
2.2. Image Noise Modeling
大多数去噪方法是针对非盲高斯去噪。然而,真实图像中的噪声来自于各种来源(暗电流噪声、短噪声、热噪声等),而且是更复杂的[44]。利用泊松光子传感和高斯剩余平稳扰动,采用泊松-高斯噪声模型[14]对成像传感器的原始数据进行建模。在[14,32]中,相机响应函数(CRF)和量化噪声也被考虑用于更实用的噪声建模。而不是泊松高斯。提出了一种用于泊松光子噪声建模的条件分布。此外,当考虑到相机内图像处理管道时,与信道无关的噪声假设可能不成立,并提出了几种方法[25,43]的跨信道噪声建模方法。在这项工作中,我们证明了真实噪声模型在基于cnn的真实照片去噪中起着轴心作用,并且泊松-高斯噪声和相机内图像处理管道都有利于去噪性能。
在图像处理中,量化噪声通常发生在从相机传感器接收到的原始信号(通常是模拟信号)转换为数字信号的过程中。例如,当相机传感器捕获的光线强度被转换为数字图像时,每个像素的亮度值都会被量化为一个固定的数字等级。如果量化级别不够精细,那么每个像素的实际亮度值与量化后的值之间的差异就会产生噪声。
量化噪声的特点是它通常呈现出一种均匀分布的形式,而不是高斯分布。在某些情况下,量化噪声可以被视为一种加性噪声,但它也可能表现出非线性特性,尤其是在亮度较低的区域。
在构建更实用的噪声模型时,考虑到量化噪声是非常重要的,因为它直接影响了图像的质量,并且在低光照条件下尤其明显。通过将量化噪声纳入模型,可以使得去噪算法更加精确地处理图像中的各种噪声成分,从而提升图像的总体质量
2.3. Blind Denoising of Real Images
真实噪声图像的盲去噪通常更具有挑战性,可能涉及噪声估计和非盲去噪两个阶段。对于AWGN,已经开发了几种基于PCA的[48,34,9]方法来估计噪声标准偏差(SD.)。Rabie [49]将有噪声的像素建模为离群值,并利用洛伦兹鲁棒估计器进行AWGN估计。对于泊松-高斯模型,Foi等人提出了一种两阶段方案,即多期望/标准差对的局部估计和全局参数模型拟合。
PCA 是 Principal Component Analysis(主成分分析)的缩写。在图像处理和计算机视觉中,PCA 可以用于特征提取、降维和数据压缩等任务。对于图像去噪任务,PCA 可以帮助估计图像中的噪声特性,尤其是噪声的标准偏差(SD)。
在大多数盲去噪方法中,噪声估计与非盲去噪密切耦合。波蒂亚[46,47]采用高斯尺度混合对各尺度的小波块进行建模,利用贝叶斯最小二乘估计干净小波块。基于分段平滑图像模型,Liu等人[32]提出了一个统一的框架来估计和去除颜色噪声。Gong等人[15]将数据拟合项建模为L1和L2范数的加权和,并利用小波域的稀疏正则器处理混合或未知噪声。Lebrun等人[28,29]提出了一种非局部贝叶斯方法[27]的扩展,即将每个斑块组的噪声建模为零均值相关高斯分布。Zhu等人[63]提出了一种贝叶斯非参数技术,通过低秩高斯混合(LR-MoG)模型来去除噪声。Nam等人的[43]将跨信道噪声建模为一个多元高斯模型,并使用贝叶斯非局部均值滤波器[24]进行去噪。Xu等人[59]提出了一种多通道加权核范数最小化(MCWNNM)模型来利用信道冗余性。他们进一步提出了一种三边加权稀疏编码(TWSC)方法,以更好地建模噪声和图像先验[58]。除噪声诊所(NC)[28,29]、MCWNNM [59]和TWSC [58]外,大多数盲去噪器的代码都不可用。我们的实验表明,它们在去除真实图像中的噪声方面仍然是有限的。
3. Proposed Method
本节介绍了我们由一个噪声估计子网和一个非盲去噪子网组成的CBDNet。首先,我们引入了噪声模型来生成合成的噪声图像。然后,研究了网络体系结构和非对称损耗。最后,我们解释了结合合成的和真实的噪声图像来训练CBDNet。
3.1. Realistic Noise Model
正如在[39]中所指出的,CNN的泛化在很大程度上取决于对训练数据的记忆能力。现有的CNN去噪器,如DnCNN [61],通常不能很好地处理真实噪声图像,主要是因为它们可能过拟合AWGN,而真实噪声分布与高斯分布有很大不同。另一方面,当使用一个真实的噪声模型进行训练时,CNN的记忆能力将有助于使学习到的模型能够很好地推广到真实的照片中。因此,噪声模型对保证CNN去噪器的性能起着至关重要的作用。与AWGN不同的是,真实的图像噪声通常是更复杂的和信号依赖的[35,14]。通常,光子感知产生的噪声可以被建模为泊松分布,而剩余的平稳扰动可以被建模为高斯分布。因此,泊松-高斯模型为成像传感器[14]的原始数据提供了一个合理的噪声模型,并可以进一步用一个异方差高斯来定义为
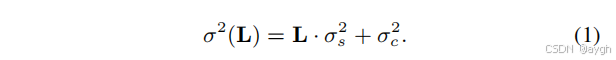
其中,L为原始像素的辐照度图像。涉及两个分量,即噪声方差
的平稳噪声分量nc和一个与信号相关的噪声分量
具有空间变化的噪声方差
这段话是在描述一种噪声模型——Poisson-Gaussian模型,该模型用于模拟成像传感器的原始数据中的噪声。它给出了一个异方差(heteroscedastic)高斯分布的定义,即n(L)~N(0,σ²(L))。其中L表示像素的辐照度图像,σ²(L)是噪声方差,它由两部分组成:信号依赖的部分L·σ²_s和常数部分σ²_c。这个公式(1)说明了噪声方差是如何随着像素的辐照度变化的。最后,它指出n(L)=n_s(L)+n_c包括两个组成部分:一个是与信号相关的空间变异性噪声成分n_s,其噪声方差为L·σ²_s;另一个是固定噪声成分n_c,其噪声方差为σ²_c。总的来说,这段话主要介绍了Poisson-Gaussian噪声模型的基本概念及其数学表达式,强调了在处理成像数据时考虑噪声的重要性。
然而,真实的照片通常是在相机内处理(ISP)后获得的,这进一步增加了噪声的复杂性,使其在空间和色度上相关。因此,我们考虑了ISP管道的两个主要步骤,即解波和伽马校正,从而得到了真实的噪声模型,
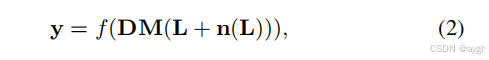
式中,y为合成的噪声图像,f(·)表示从[16]中提供的201个CRFs中均匀采样的相机响应函数(CRF)。并采用L = Mf−1(x)从一个干净的图像x中生成辐照度图像。M(·)表示将sRGB图像转换为Bayer图像的函数,DM(·)表示解识别函数[37]。请注意,DM(·)中的插值涉及到不同通道和空间位置的像素。方程式中的合成噪声。(2)因此,它是依赖于通道和空间的。
此外,为了扩展CBDNet来处理压缩图像,我们可以在生成合成噪声图像中包括JPEG压缩,
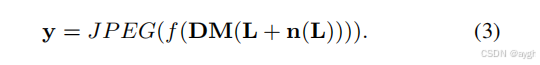
对于有噪声的未压缩图像,我们采用Eqn中的模型(2)生成合成的噪声图像。对于有噪声的压缩图像,我们利用了Eqn中的模型 (3).具体来说,σs和σc分别从[0,0.16]和[0,0.06]的范围内均匀采样。在JPEG压缩中,质量因子从[60,100]范围内采样。我们注意到,没有考虑量化噪声,因为它是最小的,可以被忽略,而对去噪结果[62]没有任何明显的影响。
3.2. Network Architecture
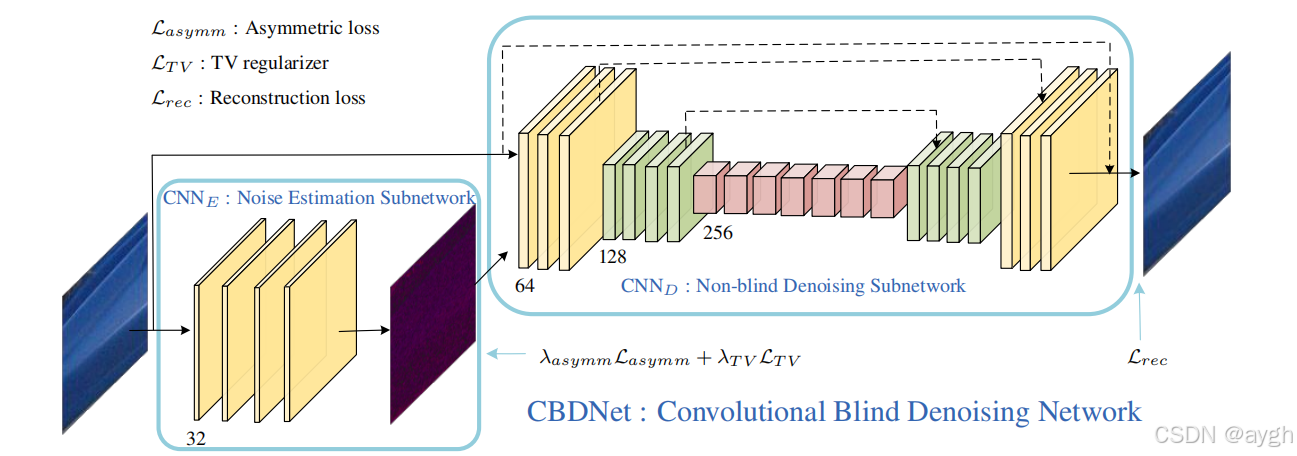
图2:我们的CBDNet的真实噪声照片
该网络由两个子网络组成:噪声估计子网络(CNN_E),非盲降噪子网络(CNN_D),输入带有噪声的照片首先经过噪声估计子网络,输出一个噪声纹理(噪声纹理(Noise Texture)是指图像中随机出现的不规则图案或者斑点)。然后,噪声纹理和原始带噪声图片一起作为非盲降噪子网络的输入。
如图2所示,所提出的CBDNet包括一个噪声估计子网CNNE和一个非盲去噪子网CNND。首先,CNNE采用一个噪声观测y来产生估计的噪声水平图,其中WE表示CNNE的网络参数。我们让CNNE的输出为噪声水平映射,因为它与输入y的大小相同,并且可以用一个完全卷积网络进行估计。然后,CNND同时以y和σˆ(y)作为输入,得到最终的去噪结果
,其中WD为CNND的网络参数。此外,CNNE的引入还允许我们在调整估计的噪声水平图σˆ(y)之前,再将其放到非盲去噪子网CNND中。在这项工作中,我们提出了一个简单的策略,让
进行交互式去噪。
我们进一步解释了CNNE和CNND的网络结构。CNNE采用普通的五层全卷积网络,不需要池化和批一化操作。在每个卷积(Conv)层中,特征通道数设置为32个,滤波器大小为3×3个。ReLU非线性[42]部署在每个Conv层之后。对于CNND,我们采用U-Net [51]架构,以y和σˆ(y)作为输入,给出无噪声干净图像的预测xˆ。在[61]之后,采用残差学习,首先学习残差映射,然后预测xˆ=
。图2中还给出了CNNE的16层U-Net体系结构,其中引入了对称跳跃连接、分支卷积和转置卷积,以利用多尺度信息,扩大接受域。所有滤波器大小均为3×3,除最后一个层外,每个Conv层之后都应用ReLU非线性[42]。此外,我们根据经验发现,批处理归一化对真实照片的噪声去除帮助不大,部分原因是真实的噪声分布与高斯分布有根本上的不同。
最后,我们注意到,通过学习从噪声观测到干净图像的直接映射,也可以训练一个单个盲的CNN去噪器。然而,正如[62,41]中所指出的,将噪声图像和噪声水平图作为输入有助于将学习到的模型推广到噪声模型之外的图像,从而有利于盲去噪。结果表明,单盲CNN去噪器的性能与CBDNet相当,而对于高噪声图像则不如CBDNet。此外,噪声估计子网络的引入也使得交互式去噪和非对称学习成为允许的。因此,我们建议在我们的CBDNet中包含噪声估计子网络。
交互式去噪是指一种用户可以参与到去噪过程中的方法。在这种模式下,用户可以通过标记或者选择图像中的某些区域来帮助算法更好地理解和学习哪些部分是噪声,哪些部分是需要保留的细节。
非对称式学习在这个上下文中可能指的是在训练去噪模型时采用的一种策略,即在损失函数中加入不对称的惩罚机制,以便更好地处理去噪过程中的一些挑战。
3.3. Asymmetric Loss and Model Objective
CNN和传统的非盲去噪器都输入良好在高于GT值(即过高估计误差),这使我们不得不采用非对称损失来提高CBDNet的一般泛化能力。如FFDNet [62]所示,BM3D/FFDNet在输入噪声SD时获得了最好的结果。和GT噪声SD匹配时。当输入噪声为SD时 低于GT值,BM3D/FFDNet的包含可感知的噪声。当输入噪声为SD时。与BM3D/FFDNET相比,随着输入噪声SD的增加,逐步消除一些低对比度结构,仍然可以获得令人满意的结果。因此,非盲去噪器对噪声SD的过估计误差很敏感,但对过估计误差具有鲁棒性。具有这种特性,BM3D/FFDNnet可以通过设置相对较高的输入噪声SD来去噪真实照片,这可能解释了BM3D在DND基准[45]上的合理性能。(DND是一个用于评估图像去噪算法性能的数据集)
这段话讨论了图像去噪算法在处理不同噪声标准差(SD,Standard Deviation)情况下的表现,特别是当输入噪声的标准差与实际(地面真值)噪声标准差不匹配时的行为。这里提到了几种去噪算法,包括CNN(卷积神经网络)、传统的非盲去噪器(non-blind denoisers)、BM3D以及FFDNet。
-
过估计误差(Over-estimation Error):
- 当输入噪声的标准差高于实际噪声标准差时,无论是CNN还是传统的非盲去噪器都能够表现得相当好。这意味着算法在处理比实际情况更多的噪声时仍然有效,不会导致严重的性能下降。
-
非盲去噪器的特性:
- 当输入噪声的标准差与实际噪声标准差匹配时,BM3D和FFDNet能够达到最佳效果。
- 如果输入噪声的标准差低于实际噪声标准差,则BM3D/FFDNet的结果中会包含明显的噪声残留。
- 反之,如果输入噪声的标准差高于实际噪声标准差,BM3D/FFDNet仍然能够获得令人满意的结果,虽然它可能会逐渐去除一些低对比度的结构。
-
非盲去噪器对噪声标准差低估的敏感性:
- 非盲去噪器对噪声标准差的低估比较敏感,但对过估计较为鲁棒。这意味着当估计的噪声水平低于实际水平时,结果可能会较差;而当估计的噪声水平高于实际水平时,虽然可能会影响一些细节,但总体上仍然能够提供较好的去噪效果。
-
应用于实际照片去噪:
- 基于上述性质,可以将BM3D/FFDNet用于实际照片的去噪,通过设置相对较高的输入噪声标准差来避免低估噪声的问题。这也可以解释为什么BM3D在DND基准测试中,在非盲去噪场景下有合理的性能表现。
综上所述,非盲去噪算法在处理实际应用中的噪声时,通常建议设置较高的输入噪声标准差以确保去噪过程的有效性,尤其是在噪声水平不确定的情况下。这样可以避免由于低估噪声而导致的去噪效果不佳的问题。
为了利用盲去噪中的非对称灵敏度,我们提出了一种噪声估计的非对称损失,以避免在噪声水平映射上出现的低估误差。考虑到像素i处的估计噪声水平σˆ(yi)和地面真实σ(yi),当σˆ(yi)<σ(yi)时,应该对他们的MSE施加更多的惩罚。因此,我们将噪声估计子网络上的非对称损失定义为:


这段话主要介绍了在盲去噪任务中,为了利用噪声估计的不对称敏感性,提出了一种不对称损失函数。以下是详细解释:
-
背景介绍:
- 盲去噪是指在不知道图像噪声水平的情况下进行去噪。
- 传统方法通常使用均方误差(MSE)作为损失函数,但这种方法可能会导致对噪声水平的低估。
-
不对称损失函数:
- 提出了一种新的不对称损失函数 𝐿𝑎𝑠𝑦𝑚𝑚Lasymm,用于避免噪声水平图中的低估错误。
- 当估计的噪声水平 𝜎^(𝑦𝑖)σ^(yi) 小于真实值 𝜎(𝑦𝑖)σ(yi) 时,会施加更多的惩罚。
-
公式描述:
- 不对称损失函数定义为:
𝐿𝑎𝑠𝑦𝑚𝑚=∑𝑖∣𝛼−𝐼(𝜎^(𝑦𝑖)−𝜎(𝑦𝑖))<0∣⋅(𝜎^(𝑦𝑖)−𝜎(𝑦𝑖))2,Lasymm=i∑∣α−I(σ^(yi)−σ(yi))<0∣⋅(σ^(yi)−σ(yi))2,
其中 𝐼𝑒Ie 是指示函数,当 𝑒<0e<0 时取值为1,否则为0。 - 参数 𝛼α 的范围是 0<𝛼<0.50<α<0.5,这样可以对低估误差施加更多惩罚,使模型更好地泛化到实际噪声。
- 不对称损失函数定义为:
-
总变分正则化:
- 引入了总变分(TV)正则化项 𝐿𝑇𝑉LTV,以约束噪声估计 𝜎^(y)σ^(y) 的平滑度。
- TV正则化的计算公式为:
𝐿𝑇𝑉=∣∣∇ℎ𝜎^(y)∣∣22+∣∣∇𝑣𝜎^(y)∣∣22,LTV=∣∣∇hσ^(y)∣∣22+∣∣∇vσ^(y)∣∣22,
其中 ∇ℎ∇h 和 ∇𝑣∇v 分别表示沿水平和垂直方向的梯度算子。
-
重建损失:
- 对于非盲去噪的输出 𝑥^x^,定义重建损失 𝐿𝑟𝑒𝑐Lrec 为:
𝐿𝑟𝑒𝑐=∣∣x^−x∣∣22.Lrec=∣∣x^−x∣∣22.
- 对于非盲去噪的输出 𝑥^x^,定义重建损失 𝐿𝑟𝑒𝑐Lrec 为:
-
总体目标函数:
- 总体目标函数 𝐿L 定义为:
𝐿=𝐿𝑟𝑒𝑐+𝜆𝑎𝑠𝑦𝑚𝑚𝐿𝑎𝑠𝑦𝑚𝑚+𝜆𝑇𝑉𝐿𝑇𝑉,L=Lrec+λasymmLasymm+λTVLTV,
其中 𝜆𝑎𝑠𝑦𝑚𝑚λasymm 和 𝜆𝑇𝑉λTV 分别是对称损失和TV正则化的权衡参数。
- 总体目标函数 𝐿L 定义为:
-
实验结果:
- 实验结果显示,通过最小化上述目标函数,CBDNet可以获得更好的PSNR/SSIM指标。
- 为了进一步提高视觉质量评估,还可以添加感知损失,并在VGG-16网络的relu3_3层上训练CBDNet。
总结来说,这段话介绍了如何通过引入不对称损失函数、总变分正则化以及重建损失来优化盲去噪任务中的噪声估计和图像恢复效果。
总变分正则化 (Total Variation Regularization, TV regularization) 在图像处理和计算机视觉领域中起着关键的作用,特别是在去噪和边缘保持方面。其核心思想是在保留图像重要特征的同时减少噪声的影响。具体而言,它通过最小化一个包含图像像素间差异之和的目标函数来实现这一目的。
3.4. Training with Synthetic and Real Noisy Images
第二节中的噪声模型。3.1可以用来合成任意数量的噪声图像。同时,我们也可以保证干净图像的高质量。尽管如此,真实照片中的噪声也不能被噪声模型完全地描述出来。幸运的是,根据[43,45,1]的研究,通过对来自同一场景的数百幅噪声图像进行平均,可以获得近噪声级的图像,并且在文献中已经建立了一些数据集。在这种情况下,场景被限制为静态的,并且获取数百张有噪声的图像通常是昂贵的。此外,由于平均效应,几乎无噪声的图像趋于过度平滑。因此,可以将合成噪声图像和真实噪声图像相结合,以提高对真实照片的泛化能力。

这段话描述了一个深度学习模型的训练过程,该模型旨在解决图像去噪问题。以下是一些关键点的解释:
-
噪声模型: 使用第3.1节中的噪声模型生成合成的噪声图像。
-
训练数据:
- 来自BSD500数据集的400张图像。
- 来自Waterloo数据集的1600张图像。
- 来自MIT-Adobe FiveK数据集的1600张图像。
-
RGB图像转RAW图像: 使用逆ISP(Image Signal Processing)过程将RGB图像转换成干净的RAW图像。这里使用了一个预设的函数𝑓−1f−1来完成这个转换。
-
生成噪声图像: 利用相同的函数𝑓f生成带有噪声的图像。函数𝑓f是从一组预先定义好的CRFs(Condition Response Functions)中随机选择的一个。
-
真实噪声图像: 使用RENOIR数据集中采样出来的120张图像作为真实世界的噪声图像。
-
交替使用数据批次: 训练过程中交替使用合成的噪声图像和真实世界中的噪声图像的数据批次。
-
损失函数:
- 对于合成的噪声图像,所有在等式(7)中定义的损失都会被最小化。
- 对于真实世界的噪声图像,由于缺乏地面真值噪声级别地图,只考虑重建损失𝐿𝑟𝑒𝑐Lrec和TV正则化损失𝐿𝑇𝑉LTV。
4. Experimental Results
4.1. Test Datasets
采用NC12的真实噪声图像[29]、DND [45]和Nam [43]三个数据集: NC12包含12张噪声图像。地面真实的图像是不可用的,我们只报告去噪结果定性评价。DND包含50对真实的有噪声的图像和相应的几乎无噪声的图像。与[4]类似,几乎无噪声的图像是通过对低iso图像的仔细后处理而获得的。PSNR/SSIM结果通过在线提交系统获得。Nam包含11个静态场景,每个场景的几乎无噪声图像是500个JPEG噪声图像的平均图像。我们将这些图像裁剪为512个×512个补丁,并随机选择25个补丁进行评估。
4.2. Implementation Details
Eqn中的模型参数。(7)由α = 0.3,λ1 = 0.5,和λ2 = 0.05给出。请注意,来自Nam [43]的噪声图像是JPEG压缩的,而来自DND [45]的噪声图像是未压缩的。因此,我们采用了Eqn中的噪声模型。(2)对DND和NC12的模型,以及Eqn中的模型。(3)为南大学提供CBDNet(JPEG)的培训。
为了训练我们的CBDNet,我们采用了使用β1 = 0.9的ADAM [26]算法。模型的初始化采用了[18]中的方法。小批量的大小为32,每个补丁的大小为128×128。所有模型都采用40个epoch进行训练,其中前20个epoch的学习速率为10−3,然后使用学习速率5×10−4对模型进行进一步微调。在NvidiaGifeGe GTX 1080 Ti GPU上使用MatConvNet包[56]训练我们的CBDNet大约需要三天时间。
4.3. Comparison with State-of-the-arts
我们在比较中考虑了四种盲去噪方法,即NC [29,28]、NI [2]、MCWNNM [59]和TWSC [58]。NI [2]是一个商业软件,并已被包括到ps和Corel油漆店。此外,我们还包括了一种盲高斯去噪方法(即CDnCNN-B [61])和三种非盲去噪方法(即CBM3D [12],WNNM [17],FFDNet [62])。当对真实照片应用非盲去噪器时,我们利用[9]来估计噪声SD。
NC12。图3为NC12图像的结果。所有的竞争方法在去除黑暗区域的噪声方面都是有限的。相比之下,CBDNet在保持显著图像结构的同时,在去除噪声方面表现良好。
DND。表1列出了在DND基准测试网站上发布的PSNR/SSIM结果。毫无疑问,CDnCNNB [61]不能推广到真实的噪声照片,而且性能很差。虽然噪音是SD级的。提供了非盲高斯去噪器,如WNNM [17]、BM3D [12]和FoE [52],只能实现有限的性能,主要是因为实际噪声与AWGN有很大的不同。MCWNNM [59]和TWSC [58]是专门为真实照片的盲去噪而设计的,也取得了很好的效果。得益于真实的噪声模型和与真实的噪声图像的结合,我们的CBDNet获得了最高的PSNR/SSIM结果,略优于MCWNNM [59]和TWSC [58]。CBDNet的性能也显著优于另一种基于cnn的去噪器,即CIMM [5]。至于运行时间,CBDNet处理一个512×512的图像大约需要0.4秒。图4提供了一个DND图像的去噪结果。BM3D和CDnCNN-B无法去除真实照片中的大部分噪声,NC、NI、MCWNNM和TWSC仍然不能去除所有噪声,NI也存在过平滑效应。相比之下,我们的CBDNet在平衡噪声去除和结构保存方面表现良好。
Nam。定量和定性结果见表2和图5。CBDNet(JPEG)的性能远远优于CBDNet(即PSNR的∼1.3 dB),并且与最先进的技术相比,取得了最好的性能。
4.4. Ablation Studies
作者提出了四种不同的噪声模型,并将其应用于DND和Nam数据集上的CBDNet模型。这些噪声模型分别是高斯噪声(CBDNet(G))、异质高斯噪声(CBDNet(HG))、高斯噪声+ISP(CBDNet(G+ISP))和异质高斯噪声+ISP(CBDNet(HG+ISP))。此外,对于Nam数据集,还包括了JPEG压缩的版本。
作者发现,在没有ISP的情况下,CBDNet(HG)相比CBDNet(G)提高了约0.8~1 dB的增益。而在包含了ISP之后,虽然HG带来的增益有所减弱,但CBDNet(HG+ISP)仍能略微优于CBDNet(G+ISP)(约0.15 dB)。
进一步地,作者指出ISP在模拟真实图像噪声方面显得尤为重要。例如,在DND数据集上,CBDNet(G+ISP)相比于CBDNet(G)提升了4.88 dB,而CBDNet(HG+ISP)相对于CBDNet(HG)也有3.87 dB的提升。对于Nam数据集,JPEG压缩的加入使得ISP带来了额外的1.31 dB的增益。
结合合成的和真实的图像。我们实现了两个基线: (i)只在合成图像上训练的CBDNet(合成图像),以及(ii)只在真实图像上训练的CBDNet(真实图像),并将我们的完整CBDNet重命名为CBDNet(所有)。图7显示了这三种方法在NC12图像上的去噪结果。即使在大规模的合成图像数据集上进行训练,CBDNet(Syn)仍然不能去除所有的真实噪声,部分原因是真实的噪声不能完全被噪声模型所表征。CBDNet(Real)可能会产生过平滑的结果,部分原因是不完美的影响。相比之下,CBDNet(All)可以在保持锐边的同时,有效地去除真实的噪声。三种模型对DND的定量结果也见表1。CBDNet(All)比CBDNet(Syn)和CBDNet(Real)获得更好的PSNR/SSIM结果。意思就是合成图像+真实图像 好
不对称损失。图8比较了不同α值下CBDNet的去噪结果,即α=分别为0.5、0.4和0.3。当α=为0.5时,CBDNet对低估和高估误差施加相同的惩罚,当α<为0.5时,对低估误差施加更多的惩罚。可以看出,较小的α(即0.3)有助于提高CBDNet对未知真实噪声的泛化能力。
4.5. Interactive Image Denoising
给定估计的噪声水平图σˆ(y),我们引入一个系数γ(> 0)来交互式地将σˆ(y)修改为%ˆ=γ·σˆ(y)。通过允许用户调整γ,非盲去噪子网络以%ˆ和有噪声的图像作为输入,获得去噪结果。图6显示了两幅真实的噪声DND图像以及使用不同的γ值得到的结果。通过指定γ = 0.7到第一个图像和从γ = 1.3到第二种,CBDNet可以分别在保留详细的纹理和去除复杂的噪声方面获得更好的视觉质量的结果。这种交互方案为在实际场景中调整去噪结果提供了一种方便的方法。
这段话描述了一种交互式的图像去噪方法。给定估计的噪声水平图σ̂(y),引入系数γ(>0)来修改σ̂(y)到σ̂' = γ·σ̂(y)。用户可以通过调整γ来改变σ̂(y)到σ̂'。交互式图像去噪是一种允许用户参与去噪过程的技术。在这个过程中,用户可以根据自己的需求调整某些参数,例如噪声水平图的系数γ,以达到更好的视觉效果。
5. Conclusion
我们提出了一种用于真实世界噪声照片盲去噪的CBDNet。这项工作的主要发现有两方面。首先,真实的噪声模型,包括异质高斯管道和ISP管道,是使从合成图像中学习到的模型适用于真实世界的噪声照片的关键。其次,通过在训练中结合合成图像和真实噪声图像,可以提高网络的去噪性能。此外,通过在CBDNet中引入噪声估计子网络,我们可以利用非对称损失来提高其对真实噪声的泛化能力,并方便地进行交互式去噪。
论文《Toward Convolutional Blind Denoising of Real Photographs》探讨了如何通过卷积神经网络(CNN)实现真实照片的盲去噪。传统的方法在处理加性白高斯噪声(AWGN)时表现良好,但对于复杂的真实世界噪声模型却显得力不从心。为了解决这一问题,作者们提出了一个卷积盲去噪网络(CBDNet),旨在提高在真实世界噪声环境下的去噪性能。
主要创新点:
-
现实的噪声模型:不同于仅处理AWGN的传统方法,CBDNet考虑了更为复杂的噪声模型,包括信号依赖的噪声和相机处理管道产生的噪声。特别地,论文采用异方差高斯噪声模型,结合相机内部处理流程(如去马赛克、Gamma校正、JPEG压缩等)来合成更真实的噪声图像。
-
嵌入式噪声估计子网络:CBDNet中集成了一个噪声估计子网络(CNNE),该网络负责估计输入图像的噪声水平,并生成噪声水平图。该图与输入图像一起传递给非盲去噪子网络(CNND),从而允许交互式的去噪调整。
-
不对称损失函数:为了抑制噪声水平估计的低估,采用了不对称损失函数。
网络结构:
CBDNet由两部分组成:噪声估计子网络(CNNE)和非盲去噪子网络(CNND)。
-
CNNE:是一个五层的全卷积网络,每层都包含32个特征通道和3x3大小的滤波器,没有池化和批量归一化操作。ReLU激活函数部署在每一层之后。
-
CNND:采用了U-Net架构,该架构引入了对称的跳跃连接、步幅卷积和转置卷积,以利用多尺度信息并扩大感受野。网络还采用了残差学习机制,首先学习残差映射,然后预测去噪后的图像。
实验结果:
实验表明,CBDNet在三个真实世界噪声图像数据集上的表现优于现有方法,无论是在定量指标还是视觉质量方面都有所提升。此外,实验还显示了相机内部处理管道在合成真实噪声模型中的重要性,这对于提高去噪性能至关重要。
综上所述,CBDNet通过采用更接近现实的噪声模型、嵌入式噪声估计以及创新的网络架构,成功实现了对真实世界图像的高效盲去噪。