目录
1、首先需要安装和配置PyTorch环境,具体可参考此文:CUDA安装教程以及torch torchvision torchaudio的安装-CSDN博客
1、MINIST数据集(Modified National Institute of Standards and Technology database)
一、引言
在当今信息化的时代,手写数字识别技术在日常生活中的应用日益广泛,例如在邮件分类、银行支票处理以及数字化文档管理中。而深度学习在手写数字识别领域取得了显著的成果。PyTorch作为一种流行的深度学习框架,以其直观易用的语法和强大的功能,吸引了众多研究人员和开发者的关注。
本文旨在通过PyTorch框架构建一个手写数字识别模型。我们将从数据预处理、模型构建、训练到模型改进,一步步解析如何利用深度学习技术解决这一经典问题。
二、准备工作
1、首先需要安装和配置PyTorch环境,具体可参考此文:CUDA安装教程以及torch torchvision torchaudio的安装-CSDN博客
2、其次需要导入所需的库和模块,如下所示
import torch
# print(torch.__version__)
from torch import nn
from torch.utils.data import DataLoader # torch中的数据管理工具
from torchvision import datasets # datasets中封装了许多与图像相关的模型以及数据集
from torchvision.transforms import ToTensor # 将其他数据类型转换为张量(tensor)
from matplotlib import pyplot as plt三,数据预处理
1、MINIST数据集(Modified National Institute of Standards and Technology database)
(1)、MINIST介绍
此次模型的数据来源于MINIST数据集,MNIST数据集是一个广泛使用的手写数字识别数据集,它是由美国国家标准与技术研究院(NIST)的原始数据集修改而来的。MNIST数据集因其简洁性和实用性,被广泛应用于机器学习和深度学习领域的教育和研究中。MNIST数据集包含60,000个训练样本和10,000个测试样本。每个样本都是一个28x28像素的灰度图像,代表一个手写的数字(0到9)。
(2)、导入
MINIST是封装在torchvision库下datasets中的一个数据集,导入方法如下
from torchvision import datasets
training_data = datasets.MNIST()
2、数据加载和转换
(1)、下载训练数据集(图片以及标签)
注:张量(Tensor)是深度学习中的基本数据结构,在进行深度学习数据处理是需要把其他数据类型转换为张量。
转换方法:Totensor()是位于torchvision.transforms中的一种图像转换方法,将下载下来的数据转换为tensor类型。
(2)、数据划分:训练集和测试集
training_data = datasets.MNIST( # MNIST数据库
root="data", # 将数据下载并存入data文件夹
train=True, # 提取训练集数据
download=True,
transform=ToTensor() # 接受PIL图片并返回转换后的版本,转换为张量类型的数据
)
test_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)(3)、数据可视化
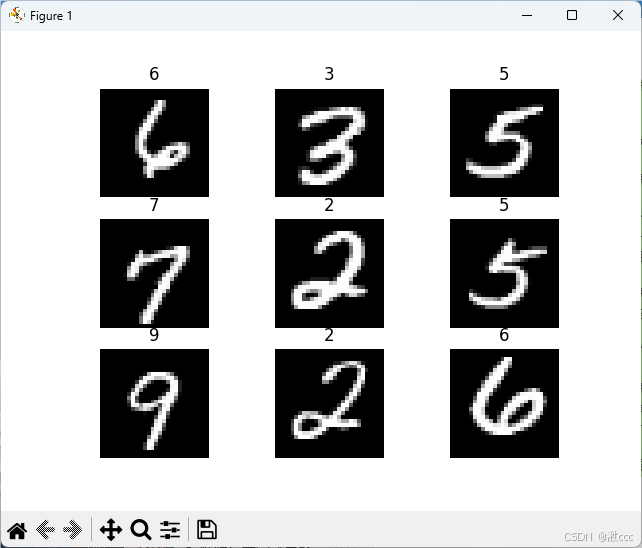
这里需要借助matplotlib库对下载的图片进行可视化,验证是否下载成功。
'''显示手写图片'''
from matplotlib import pyplot as plt
figure = plt.figure() # 创建空白画布
for i in range(9):
img, label = training_data[i + 59000] # label标签
figure.add_subplot(3, 3, i + 1) # 在图像窗口中创建多个小窗口, 3*3个
plt.title(label)
plt.axis("off") # 关闭坐标轴
plt.imshow(img.squeeze(), cmap='gray') # img.squeeze()从张量img中去掉维度为1的-->变为28*28
plt.show()运行结果
(4)、数据打包
我们需要训练的数据包含60,000个训练样本和10,000个测试样本,如果一张张传入模型进行训练耗时间又耗资源,所以需要将数据进行打包,以包为单位进行训练。这里推荐用2的指数作为一个包中数据的数量。
train_dataloader = DataLoader(training_data, batch_size=64) # 建议用2的指数当作一个包的数量
test_dataloader = DataLoader(test_data, batch_size=64)
for X, y in test_dataloader:
print(f'Shape of X [N,C,H,W]:{X.shape}')
print(f'Shape of y:{y.shape},{y.dtype}')
break(5)、判断训练位置
这里用了一个判断语句来判断使用的是GPU还是IOS系统的mps。
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")四、构建模型
1、预构建神经网络
在构建模型之前我们需要根据训练数据以及训练目的来设计神经网络。我们用到的数据集是由很多28*28像素的灰度图片构成,将每张图片展开就会得到28*28=784个数据,所以我们要设计的神经网络输入层就要有784个神经元。关于输出层,手写数字图片一共有10种结果(0-9),所以输出层要设计10个神经元。至于隐藏层没有固定要求,这里我们设计4个隐藏层(可自己尝试增加或减少。注:不宜过多或过少)
2、构建神经网络模型
构建思路完成,代码实现
# 构建神经网络模型
class NeuralNetwork(nn.Module): # 神经网络模型nn.Module
def __init__(self): # python基础关于类,self类本身
super().__init__() # 继承的父类初始化
self.flatten = nn.Flatten() # 展开
self.hidden1 = nn.Linear(28 * 28, 128) # 第一个隐藏层(前一层神经元数量,本层神经元数量)
self.hidden2 = nn.Linear(128, 256) # 第二个隐藏层
self.hidden3 = nn.Linear(256, 128)
self.hidden4 = nn.Linear(128, 256)
self.out = nn.Linear(256, 10) # 输出层
def forward(self, x):
x = self.flatten(x) # 图像进行展开28*28个数据传入神经元
x = self.hidden1(x)
x = torch.sigmoid(x)
x = self.hidden2(x)
x = torch.sigmoid(x)
x = self.hidden3(x)
x = torch.sigmoid(x)
x = self.hidden4(x)
x = torch.sigmoid(x)
x = self.out(x)
return x
model = NeuralNetwork().to(device) #将模型传入GPU
print(model) #打印模型代码解析:(1)、nn.Flatten() 将每张图片28*28个像素展开,方便传入输入层;
(2)、nn.Linear() 将每层神经元全连接;
(3)、torch.sigmoid() 此为激活函数,数据经过神经元传播后经过激活函数进行非线性映射;
注:常见的激活函数有很多种,比如:Sigmoid函数、Tanh函数、ReLU函数、Softmax函数等,此处使用sigmoid函数不是最优,后续可进行更换。
构建结果如下,可以看到我们设计的模型的信息

五、模型训练
构建好模型后,我们要对模型进行训练。
1、定义损失函数和优化器
(1)、定义损失函数
损失函数(Loss Function)扮演着至关重要的角色,它是评价模型性能的指标,也是指导模型训练过程的重要依据。因为手写数字识别是多分类问题,所以我们这里使用交叉熵损失函数(Cross-Entropy Loss)
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数(2)、定义优化器
此处使用随机梯度下降算法(SGD),后续可以更改其他优化算法。
lr为学习率,也就是梯度下降的步长,可以根据调节步长来寻找最快寻找最优解的优化算法。
optimizer = torch.optim.SGD(model.parameters(), lr=0.005) # 优化器,SGD为随机梯度下降算法,lr为步长学习率2、训练集
# 训练集
def train(dataloader, model, loss_fn, optimizer):
model.train() # 开始训练,w可以改变,与测试中的model.eval()相对应
batch_size_num = 1 # batch为每个数据的编号
for X, y in dataloader: # 开始打包
X, y = X.to(device), y.to(device) # 将数据传入Gpu
pred = model.forward(X) # 前向传输,model的数据来自模型的out
loss = loss_fn(pred, y) # 通过交叉熵损失函数计算loss,pred为预测值,y为真实值
optimizer.zero_grad() # 优化,梯度值清零
loss.backward() # 反向传播计算每个参数的梯度值W
optimizer.step() # 根据梯度更新W
# 每轮的损失值可视化
loss_value = loss.item() # 从tensor数据中提取数据出来,转换成对应的整数或者浮点数
if batch_size_num % 200 == 0:
print(f"loss: {loss_value:>7f} [number:{batch_size_num}]")
batch_size_num += 1由于反复打印会占用CPU资源,所以借助循环实现每训练200次返回一次损失值。
3、测试集
# 测试集
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 检测测试集有多少个数据
num_batches = len(dataloader) # 检测有多少个包,64个图为一个包
model.eval() # 测试,w不可更新
test_loss, correct = 0, 0 # 初始化损失值以及正确率
with torch.no_grad(): # 一个上下文管理器,关闭梯度计算
for X, y in dataloader: # 提取测试集的数据
X, y = X.to(device), y.to(device)
pred = model.forward(X) # 预测结果
test_loss += loss_fn(pred, y).item() # test_loss会自动累加每一批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # pred.argmax(1)返回每一行中最大值对应的索引号
a = (pred.argmax(1) == y) # 比较预测值与正确标签是否相同,返回True或者False
b = (pred.argmax(1) == y).type(torch.float) # 将True-->1,False-->0,便于统计正确率
test_loss /= num_batches
correct /= size
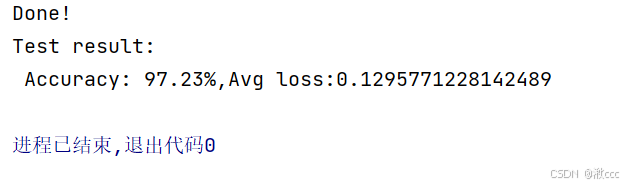
print(f"Test result: \n Accuracy: {(100 * correct)}%,Avg loss:{test_loss}")
4、训练轮数
由于使用一轮训练集一轮测试集的模式效率较低,所以用一个循环来实现进行n轮训练1轮测试的模式来提高训练效率。
epochs = 5
for t in range(epochs):
print(f"Epoch {t + 1}\n**********************************")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
# 进行epochs轮train,一轮test
test(test_dataloader, model, loss_fn)
可以自行调试epochs标量来寻找最佳训练模式。
六、模型调试
以下给出调试模型的建议
(1)、增加或减少隐藏层的数量,调节每层神经元的数量;
(2)、选用不同的激活函数;
(3)、选用不同的优化器;
(4)、调节学习率步长;
(5)、改变训练集训练的轮次.
七、训练结果
这是我训练模型的正确率,评论区展示一下你们的吧!