Openstack Nova计算组件详解与分析
一、概述
Nova是OpenStack中最核心的组件,它负责根据需求提供虚拟机服务并管理虚拟机生命周期,包括虚拟机创建、虚拟机调度和热迁移等。
Nova的子组件包括nova-api、nova-compute、nova-scheduler、nova-conductor、nova-db、nova-console等等。Openstack是分布式的云操作系统,不同的组件可以运行在不同的物理节点上,也可以运行在一个节点上。
- nova-api:对外提供服务接口,接收和响应客户的compute API调用。同时它还兼容AWS EC2 API。
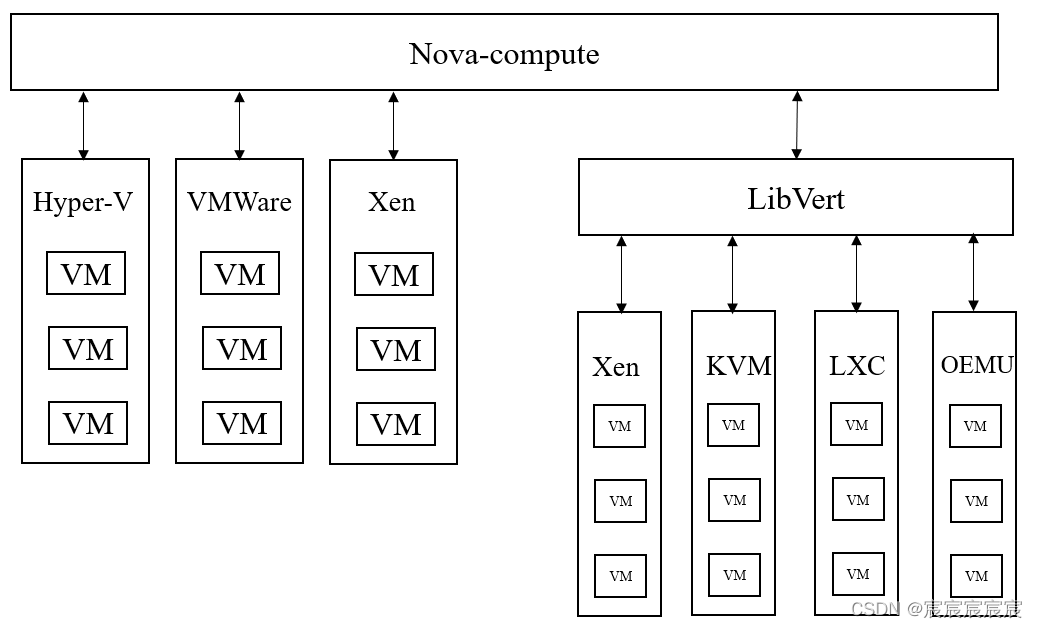
- nova-compute:管理虚拟机的核心服务,通过调用Hypervisor API实现虚拟机生命周期管理,如支持XenServer/XCP的XenAPI、支持KVM和QEMU的Libvert或支持VMware的VMwareAPI等。
- nova-scheduler:接收创建虚拟机的请求,并决定在哪个计算节点上运行虚拟机
- nova-conductor:处于nova-compute与nova-db之间的组件。出于安全性的考虑避免nova-compute直接访问nova-db,而由nova-conduct代为转交。
- nova-db:包含大量数据库表,用于记录虚拟机状态、虚拟机到物理机的映射、租户数据等数据内容。
- nova-console:提供控制台服务。
二、Nova架构与工作流程
1、Nova架构
Nova对外提供HTTP REST API,对内通过RPC进行通信,使用一个中心DB来存储数据。
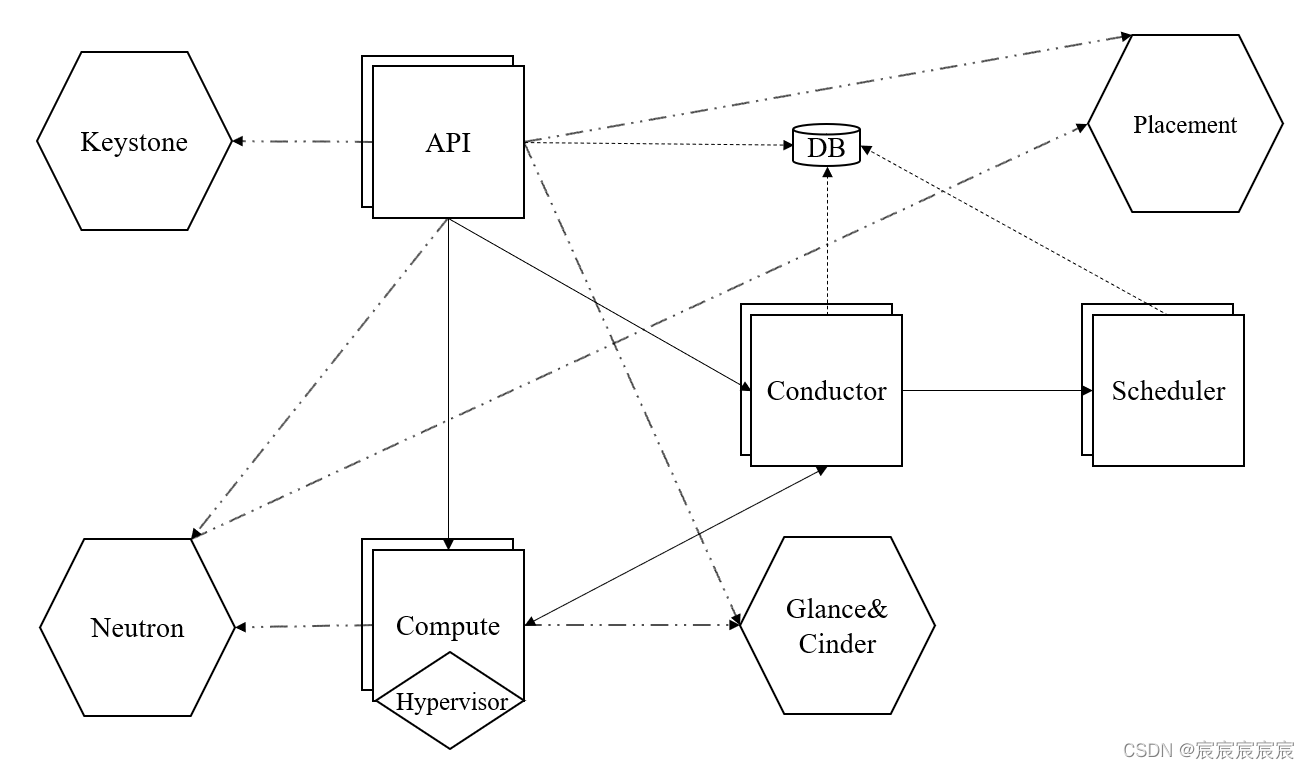
- API是进入Nova的HTTP接口,可以部署多个以实现扩展。API会依据请求是长时任务或短时任务对接收到的HTTP API请求发送给conductor或compute。对于长时任务,会被发送conductor进行全程跟踪和调度。对于需要进行虚拟机调度的请求,如创建虚拟机或迁移,conductor会向scheduler请求一个计算节点并发送请求到上面。
- conductor还负责代理其他节点的数据库访问,为解决安全问题和在线升级功能。
- 最终对虚拟机的操作请求都会被发送到compute,由compute负责与Hypervisor进行通信,管理虚拟机的生命周期。
- compute为Hypervisor定义了统一的接口,hypervisor只需要实现这些接口就可以以driver的形式即插即用到Openstack中
2、工作流程
以虚拟机的创建为例来说明Openstack的Nova服务的工作流程
(1)发送请求
客户(用户或其他服务)向nova-api发送REST请求“创建虚拟机”
(2)产生调度
nova-api对请求做一些必要处理后,向Messaging(RabbitMQ)发送一条消息“scheduler执行调度”,nova-scheduler从Messaging接收到消息后执行调度算法,从若干计算节点中选出一个节点用来创建虚拟机,并向Messaging发送消息“在节点A创建虚拟机”。
Messaging:为解耦各个子服务,Nova通过消息队列作为消息中转站,Openstack默认选择RabbitMQ作为Message queue
意义:api通过Messaging过程进行异步调用,发出请求后立即返回无需等待,提高吞吐率,且自服务不需要知道其他服务
在哪里运行,只需要发送消息给Message Queue
(3)启动虚拟机
计算节点A上的nova-compute从Messaging中获取scheduler发送的消息,然后在自己的hypervisor上启动虚拟机。在创建过程中,如果nova-compute需要对数据库进行查询或更新,则通过Messaging向nova-conductor发送信息,由conductor进行数据库访问
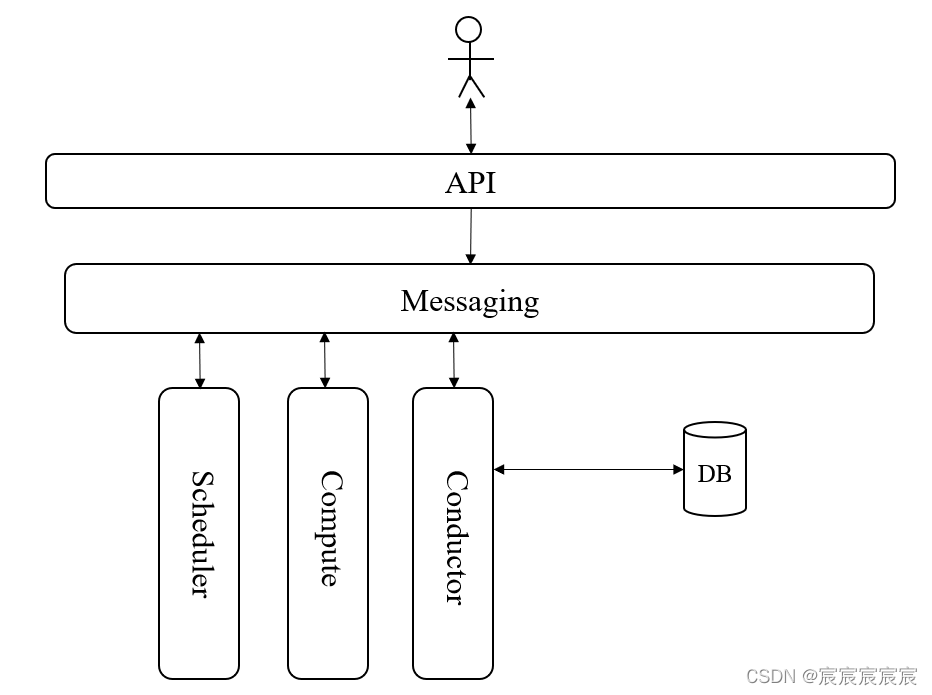
从中可见Openstack的通用设计思路为:
- (1)API前端服务接收客户请求
- (2)Scheduler调度服务
- (3)Worker工作服务
- (4)Messaging消息中转服务
- (5)数据库DB
三、源码分析
1、Nova体系结构
(1)setup.cfg文件
Nova组件的代码目录中包含一个setup.cfg文件,其中entry_points部分中的一个特殊的命名空间console_scripts的每一项都表示一个可执行脚本,即为Nova各个组件的入口
console_scripts =
nova-api = nova.cmd.api:main
nova-api-metadata = nova.cmd.api_metadata:main
nova-api-os-compute = nova.cmd.api_os_compute:main
nova-compute = nova.cmd.compute:main
nova-conductor = nova.cmd.conductor:main
nova-manage = nova.cmd.manage:main
nova-novncproxy = nova.cmd.novncproxy:main
nova-policy = nova.cmd.policy:main
nova-rootwrap = oslo_rootwrap.cmd:main
nova-rootwrap-daemon = oslo_rootwrap.cmd:daemon
nova-scheduler = nova.cmd.scheduler:main
nova-serialproxy = nova.cmd.serialproxy:main
nova-spicehtml5proxy = nova.cmd.spicehtml5proxy:main
nova-status = nova.cmd.status:main
wsgi_scripts =
nova-api-wsgi = nova.api.openstack.compute.wsgi:init_application
nova-metadata-wsgi = nova.api.metadata.wsgi:init_application
(2)rpc通信机制
Nova组件内部之间通过rpc机制(remote procedure calling 远程过程调用)进行通信。其中,nova-scheduler、nova-compute、nova-conductor在启动时都会注册一个rpc server。以nova-compute为例:
class ComputeAPI(object):
def start_instance(self, ctxt, instance):
version = self._ver(ctxt, '5.0')
cctxt = self.router.client(ctxt).prepare(
server=_compute_host(None, instance), version=version)
cctxt.cast(ctxt, 'start_instance', instance=instance)
nova.compute.rpcapi.ComputeAPI类中的函数即为nova-compute提供给其他组件的rpc接口。
class ComputeManager(manager.Manager):
@wrap_exception()
@reverts_task_state
@wrap_instance_event(prefix='compute')
@wrap_instance_fault
def start_instance(self, context, instance):
"""Starting an instance on this host."""
self._notify_about_instance_usage(context, instance, "power_on.start")
compute_utils.notify_about_instance_action(context, instance,
self.host, action=fields.NotificationAction.POWER_ON,
phase=fields.NotificationPhase.START)
self._power_on(context, instance)
instance.power_state = self._get_power_state(instance)
instance.vm_state = vm_states.ACTIVE
instance.task_state = None
# Delete an image(VM snapshot) for a shelved instance
snapshot_id = instance.system_metadata.get('shelved_image_id')
if snapshot_id:
self._delete_snapshot_of_shelved_instance(context, instance,
snapshot_id)
# Delete system_metadata for a shelved instance
compute_utils.remove_shelved_keys_from_system_metadata(instance)
instance.save(expected_task_state=task_states.POWERING_ON)
self._notify_about_instance_usage(context, instance, "power_on.end")
compute_utils.notify_about_instance_action(context, instance,
self.host, action=fields.NotificationAction.POWER_ON,
phase=fields.NotificationPhase.END)
nova.compute.rpcapi.ComputeAPI仅仅是暴露给其他服务的rpc接口,nova-conpute服务的rpc server在接收到rpc请
求后,由nova.compute.manager来完成任务。从nova.compute.rpcapi.ComputeAPI到nova.compute.manager即为
rpc调用的过程。
2、各组件分析
(1)nova-api
目录结构
- metadata
metadata目录下对应的是Metadata API,用于获取虚拟机的配置信息。 - openstack
openstack目录下对应的是Nova v2.1的API,包含WSGI基础架构的代码。
在nova/api/openstack/compute中可以获取每个对应API的入口点
nova/api/openstack/schema包括JSON-schema来验证输入。
nova-api请求路由
nova使用Python Paste加载WSGI stack,WSGI stack通过etc/nova/api-paste.ini来配置,如:
[composite:osapi_compute]
use = call:nova.api.openstack.urlmap:urlmap_factory
/: oscomputeversions
/v2: oscomputeversion_legacy_v2
/v2.1: oscomputeversion_v2
# v21 is an exactly feature match for v2, except it has more stringent
# input validation on the wsgi surface (prevents fuzzing early on the
# API). It also provides new features via API microversions which are
# opt into for clients. Unaware clients will receive the same frozen
# v2 API feature set, but with some relaxed validation
/v2/+: openstack_compute_api_v21_legacy_v2_compatible
/v2.1/+: openstack_compute_api_v21
其中的/v2.1就是Nova当前的API
[composite:openstack_compute_api_v21]
use = call:nova.api.auth:pipeline_factory_v21
keystone = cors http_proxy_to_wsgi compute_req_id faultwrap request_log sizelimit osprofiler authtoken keystonecontext osapi_compute_app_v21
# DEPRECATED: The [api]auth_strategy conf option is deprecated and will be
# removed in a subsequent release, whereupon this pipeline will be unreachable.
noauth2 = cors http_proxy_to_wsgi compute_req_id faultwrap request_log sizelimit osprofiler noauth2 osapi_compute_app_v21
osapi_compute_app_v21即为v2.1本身,其他的middleware会对请求或返回 作出一些处理
[app:osapi_compute_app_v21]
paste.app_factory = nova.api.openstack.compute:APIRouterV21.factory
最后可以找到nova api的入口,nova.api.openstack.compute:APIRouterV21.factory用于创建Nova v2.1 API
ROUTE_LIST = (
('/', {
'GET': [version_controller, 'show']
}),
('/versions/{id}', {
'GET': [version_controller, 'show']
}),
...
)
class APIRouterV21(base_wsgi.Router):
"""Routes requests on the OpenStack API to the appropriate controller
and method. The URL mapping based on the plain list `ROUTE_LIST` is built
at here.
"""
def __init__(self, custom_routes=None):
""":param custom_routes: the additional routes can be added by this
parameter. This parameter is used to test on some fake routes
primarily.
"""
super(APIRouterV21, self).__init__(nova.api.openstack.ProjectMapper())
if custom_routes is None:
custom_routes = tuple()
for path, methods in ROUTE_LIST + custom_routes:
# NOTE(alex_xu): The variable 'methods' is a dict in normal, since
# the dict includes all the methods supported in the path. But
# if the variable 'method' is a string, it means a redirection.
# For example, the request to the '' will be redirect to the '/' in
# the Nova API. To indicate that, using the target path instead of
# a dict. The route entry just writes as "('', '/)".
if isinstance(methods, str):
self.map.redirect(path, methods)
continue
for method, controller_info in methods.items():
# TODO(alex_xu): In the end, I want to create single controller
# instance instead of create controller instance for each
# route.
controller = controller_info[0]()
action = controller_info[1]
self.map.create_route(path, method, controller, action)
ROUTER_LIST中保存了URL与Controller之间的映射,APIRouterV21基于ROUTE_LIST使用Routes模块将各个API注册到
maper中,并封装成一个nova.api.openstack.wsgi.Resource对象
nova-api的实现
Router对象会将请求的API映射到对应的Controller方法上,每个API对应的Controller方法都在nova/api/openstack/compute/目录下的各个模块中。例如,migriations API可以从ROUTE_LIST定位到对应的migrations API Controller为nova.api.openstack.compute.migrations.MigrationsController。
class MigrationsController(wsgi.Controller):
"""Controller for accessing migrations in OpenStack API."""
_view_builder_class = migrations_view.ViewBuilder
_collection_name = "servers/%s/migrations"
def __init__(self):
super(MigrationsController, self).__init__()
self.compute_api = compute.API()
def _output(self, req, migrations_obj, add_link=False,
add_uuid=False, add_user_project=False):
"""Returns the desired output of the API from an object.
From a MigrationsList's object this method returns a list of
primitive objects with the only necessary fields.
"""
detail_keys = ['memory_total', 'memory_processed', 'memory_remaining',
'disk_total', 'disk_processed', 'disk_remaining']
# TODO(Shaohe Feng) we should share the in-progress list.
live_migration_in_progress = ['queued', 'preparing',
'running', 'post-migrating']
# Note(Shaohe Feng): We need to leverage the oslo.versionedobjects.
# Then we can pass the target version to it's obj_to_primitive.
objects = obj_base.obj_to_primitive(migrations_obj)
objects = [x for x in objects if not x['hidden']]
for obj in objects:
del obj['deleted']
del obj['deleted_at']
del obj['hidden']
del obj['cross_cell_move']
if not add_uuid:
del obj['uuid']
if 'memory_total' in obj:
for key in detail_keys:
del obj[key]
if not add_user_project:
if 'user_id' in obj:
del obj['user_id']
if 'project_id' in obj:
del obj['project_id']
# NOTE(Shaohe Feng) above version 2.23, add migration_type for all
# kinds of migration, but we only add links just for in-progress
# live-migration.
if (add_link and
obj['migration_type'] ==
fields.MigrationType.LIVE_MIGRATION and
obj["status"] in live_migration_in_progress):
obj["links"] = self._view_builder._get_links(
req, obj["id"],
self._collection_name % obj['instance_uuid'])
elif add_link is False:
del obj['migration_type']
return objects
def _index(self, req, add_link=False, next_link=False, add_uuid=False,
sort_dirs=None, sort_keys=None, limit=None, marker=None,
allow_changes_since=False, allow_changes_before=False):
context = req.environ['nova.context']
context.can(migrations_policies.POLICY_ROOT % 'index')
search_opts = {}
search_opts.update(req.GET)
if 'changes-since' in search_opts:
if allow_changes_since:
search_opts['changes-since'] = timeutils.parse_isotime(
search_opts['changes-since'])
else:
# Before microversion 2.59, the changes-since filter was not
# supported in the DB API. However, the schema allowed
# additionalProperties=True, so a user could pass it before
# 2.59 and filter by the updated_at field if we don't remove
# it from search_opts.
del search_opts['changes-since']
if 'changes-before' in search_opts:
if allow_changes_before:
search_opts['changes-before'] = timeutils.parse_isotime(
search_opts['changes-before'])
changes_since = search_opts.get('changes-since')
if (changes_since and search_opts['changes-before'] <
search_opts['changes-since']):
msg = _('The value of changes-since must be less than '
'or equal to changes-before.')
raise exc.HTTPBadRequest(explanation=msg)
else:
# Before microversion 2.59 the schema allowed
# additionalProperties=True, so a user could pass
# changes-before before 2.59 and filter by the updated_at
# field if we don't remove it from search_opts.
del search_opts['changes-before']
if sort_keys:
try:
migrations = self.compute_api.get_migrations_sorted(
context, search_opts,
sort_dirs=sort_dirs, sort_keys=sort_keys,
limit=limit, marker=marker)
except exception.MarkerNotFound as e:
raise exc.HTTPBadRequest(explanation=e.format_message())
else:
migrations = self.compute_api.get_migrations(
context, search_opts)
add_user_project = api_version_request.is_supported(req, '2.80')
migrations = self._output(req, migrations, add_link,
add_uuid, add_user_project)
migrations_dict = {'migrations': migrations}
if next_link:
migrations_links = self._view_builder.get_links(req, migrations)
if migrations_links:
migrations_dict['migrations_links'] = migrations_links
return migrations_dict
@wsgi.Controller.api_version("2.1", "2.22") # noqa
@wsgi.expected_errors(())
@validation.query_schema(schema_migrations.list_query_schema_v20,
"2.0", "2.22")
def index(self, req):
"""Return all migrations using the query parameters as filters."""
return self._index(req)
@wsgi.Controller.api_version("2.23", "2.58") # noqa
@wsgi.expected_errors(())
@validation.query_schema(schema_migrations.list_query_schema_v20,
"2.23", "2.58")
def index(self, req): # noqa
"""Return all migrations using the query parameters as filters."""
return self._index(req, add_link=True)
@wsgi.Controller.api_version("2.59", "2.65") # noqa
@wsgi.expected_errors(400)
@validation.query_schema(schema_migrations.list_query_params_v259,
"2.59", "2.65")
def index(self, req): # noqa
"""Return all migrations using the query parameters as filters."""
limit, marker = common.get_limit_and_marker(req)
return self._index(req, add_link=True, next_link=True, add_uuid=True,
sort_keys=['created_at', 'id'],
sort_dirs=['desc', 'desc'],
limit=limit, marker=marker,
allow_changes_since=True)
@wsgi.Controller.api_version("2.66") # noqa
@wsgi.expected_errors(400)
@validation.query_schema(schema_migrations.list_query_params_v266,
"2.66", "2.79")
@validation.query_schema(schema_migrations.list_query_params_v280,
"2.80")
def index(self, req): # noqa
"""Return all migrations using the query parameters as filters."""
limit, marker = common.get_limit_and_marker(req)
return self._index(req, add_link=True, next_link=True, add_uuid=True,
sort_keys=['created_at', 'id'],
sort_dirs=['desc', 'desc'],
limit=limit, marker=marker,
allow_changes_since=True,
allow_changes_before=True)
在MigrationsController,公共方法仅有index一类,但存在多个声明,代表不同版本的API。方法对应的版本通过注解“wsgi.Controller.api_version”指定,其他注解的意思是:
- @wsgi.expected_errors:返回的错误码
- @validation.query_schema:请求JSON-Schema
API输入请求的格式验证通过JSON文件指定,如list_query_schema_v20方法:
list_query_schema_v20 = {
'type': 'object',
'properties': {
'hidden': parameter_types.common_query_param,
'host': parameter_types.common_query_param,
'instance_uuid': parameter_types.common_query_param,
'source_compute': parameter_types.common_query_param,
'status': parameter_types.common_query_param,
'migration_type': parameter_types.common_query_param,
},
# For backward compatible changes
'additionalProperties': True
}
该JSON-schema表示接受六个参数:‘hidden’、‘host‘、’status‘等等,这些参数接收的类型在parameter_types.common_query_param中指定
# NOTE: We don't check actual values of queries on params
# which are defined as the following common_param.
# Please note those are for backward compatible existing
# query parameters because previously multiple parameters
# might be input and accepted.
common_query_param = multi_params({'type': 'string'})
(2)nova-scheduler
概述
nova-scheduler决定虚拟机的生存空间和资源分配,综合考虑内存使用率、CPU负载均衡等多种因素为虚拟机选择合适的主机。
社区致力于将Scheduler与nova服务解耦合为独立的Placement,从而提供通用调度服务被多项目使用。目前Placement已经成为独立的项目,但无法完全取代nova-scheduler,可以与nova-scheduler协同使用。
调度器
将不同的调度算法称为调度器,nova实现的所有调度器均在setup.cfg中可以找到。
-
FilterScheduler:默认调度器,根据指定过滤,使用最多
-
CachingScheduler:与FilterScheduler相似,可以在其基础上将主机资源信息缓存下来,并通过后台的定时任务定时从数据库中获取最新的主机资源信息。
-
ChanceScheduler:随机选取
自定义调度器:继承虚类nova.scheduler.driver.Scheduler并实现所有接口
FilterScheduler详解
工作流程
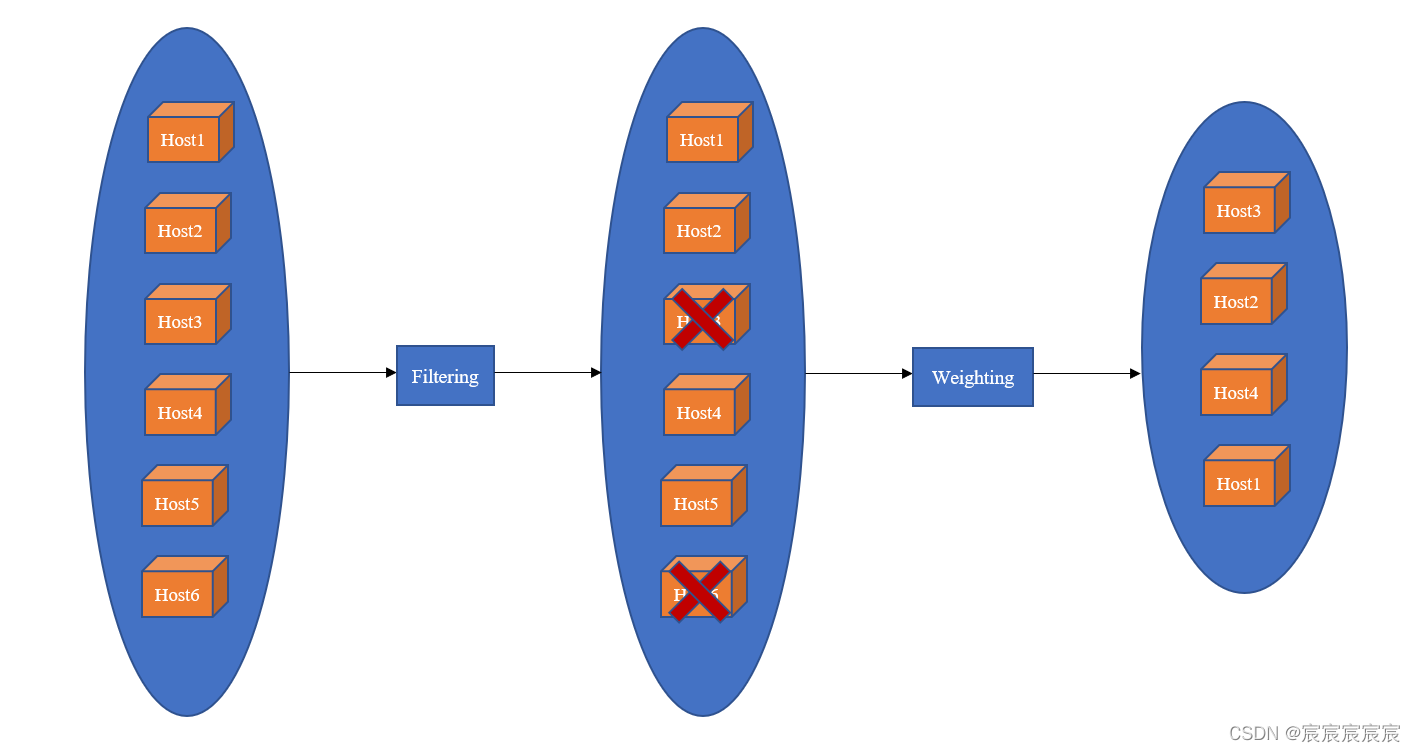
首先使用Filter过滤掉不适合的主机(内存使用率过大、CPU负载过大等等),得到符合条件的主机,然后通过权重排序Weighting以获得最佳的一台主机,引入Placement后,调度流程需要先通过Placement进行一次预筛选。
调度器缓存更新
nova-scheduler在进行调度决策前需要从db中获取各主机的资源数据,这些数据的收集与存储由nova-compute负责。nova-compute进行数据更新并保证其有效性,nova-scheduler无法跟新db,故在调度之前,需要在内存中保存之前的决策情况,这通过单独维护一份缓存实现。
缓存内容包含最近读取的数据库情况以及最近调度器决策导致的资源变化。由HostState进行实现。
class HostState(object):
def update(self, compute=None, service=None, aggregates=None,
inst_dict=None):
"""Update all information about a host."""
@utils.synchronized(self._lock_name)
def _locked_update(self, compute, service, aggregates, inst_dict):
# Scheduler API is inherently multi-threaded as every incoming RPC
# message will be dispatched in it's own green thread. So the
# shared host state should be updated in a consistent way to make
# sure its data is valid under concurrent write operations.
if compute is not None:
LOG.debug("Update host state from compute node: %s", compute)
self._update_from_compute_node(compute)
if aggregates is not None:
LOG.debug("Update host state with aggregates: %s", aggregates)
self.aggregates = aggregates
if service is not None:
LOG.debug("Update host state with service dict: %s", service)
self.service = ReadOnlyDict(service)
if inst_dict is not None:
LOG.debug("Update host state with instances: %s",
list(inst_dict))
self.instances = inst_dict
return _locked_update(self, compute, service, aggregates, inst_dict)
调度器可以同时处理多个调度请求,故为了避免冲突,需要上锁(@utils.synchronized(self._lock_name))。HoseState会从数据库和缓存中更新主机数据(compute)、服务状态(service)、主机分组信息(aggregates)以及虚拟机状态(inst_dict)。
Filtering
根据各台主机当前可用的资源情况,过滤掉不符合条件的主机。
Nova支持多个过滤算法,能够处理各类信息
- 主机可用资源:内存、磁盘、CPU等等
- 主机类型:CPU类型和指令集、虚拟机类型和版本
- 主机状态:主机是否处于active状态、CPU使用率、虚拟机启动数量、繁忙程度、是否可信等
- …
所有Filter实现均位于nova/scheduler/filters目录,为提高扩展性和灵活性,每个Filter均继承自nova.scheduler.filters.BaseHostFilter:
class BaseHostFilter(filters.BaseFilter):
"""Base class for host filters."""
# This is set to True if this filter should be run for rebuild.
# For example, with rebuild, we need to ask the scheduler if the
# existing host is still legit for a rebuild with the new image and
# other parameters. We care about running policy filters (i.e.
# ImagePropertiesFilter) but not things that check usage on the
# existing compute node, etc.
RUN_ON_REBUILD = False
def _filter_one(self, obj, spec):
"""Return True if the object passes the filter, otherwise False."""
# Do this here so we don't get scheduler.filters.utils
from nova.scheduler import utils
if not self.RUN_ON_REBUILD and utils.request_is_rebuild(spec):
# If we don't filter, default to passing the host.
return True
else:
# We are either a rebuild filter, in which case we always run,
# or this request is not rebuild in which case all filters
# should run.
return self.host_passes(obj, spec)
def host_passes(self, host_state, filter_properties):
"""Return True if the HostState passes the filter, otherwise False.
Override this in a subclass.
"""
raise NotImplementedError()
例如ComputeFilter的实现:它会过滤掉nova-compute不可用的节点
class ComputeFilter(filters.BaseHostFilter):
"""Filter on active Compute nodes."""
RUN_ON_REBUILD = False
def __init__(self):
self.servicegroup_api = servicegroup.API()
# Host state does not change within a request
run_filter_once_per_request = True
def host_passes(self, host_state, spec_obj):
"""Returns True for only active compute nodes."""
service = host_state.service
if service['disabled']:
LOG.debug("%(host_state)s is disabled, reason: %(reason)s",
{'host_state': host_state,
'reason': service.get('disabled_reason')})
return False
else:
if not self.servicegroup_api.service_is_up(service):
LOG.warning("%(host_state)s has not been heard from in a "
"while", {'host_state': host_state})
return False
return True
不同的Filter也可以共存,按照Filter的顺序依次过滤,具体使用那些Filter需要在配置文件中指定。
[filter_scheduler]
available_filters = nova.scheduler.filters.all_filters
available_filters = myfilter.MyFilter
enabled_filters=ComputeFilter,AvailabilityZoneFilter,ComputeCapabilitiesFilter,ImagePropertiesFilter,PciPassthroughFilter,NUMATopologyFilter
Weighting
对过滤后的所有符合条件的主机计算权重并排序,得到最适合的主机。所有的weigher实现都位于nova/scheduler/weights目录下,例如RAMWeigher
class RAMWeigher(weights.BaseHostWeigher):
minval = 0
#权重的系数,最终排序时需要将每种weighter得到的权重乘上它的系数
def weight_multiplier(self, host_state):
"""Override the weight multiplier."""
return utils.get_weight_multiplier(
host_state, 'ram_weight_multiplier',
CONF.filter_scheduler.ram_weight_multiplier)
#计算权重值:此处权重即为可以内存的大小(free_ram_mb)
def _weigh_object(self, host_state, weight_properties):
"""Higher weights win. We want spreading to be the default."""
return host_state.free_ram_mb