本文为李沐老师《动手学深度学习》笔记小结,用于个人复习并记录学习历程,适用于初学者
之前首次介绍神经网络时,我们关注的是具有单一输出的线性模型然后,当考虑具有多个输出的网络时, 我们利用矢量化算法来描述整层神经元。
在讨论下去,我们就会发现,研究讨论“比单个层大”但“比整个模型小”的组件很有价值,故而引入了神经网络块的概念。
块(block)可以描述单个层、由多个层组成的组件或整个模型本身。 使用块进行抽象的一个好处是可以将一些块组合成更大的组件, 这一过程通常是递归的, 通过定义代码来按需生成任意复杂度的块, 我们可以通过简洁的代码实现复杂的神经网络。
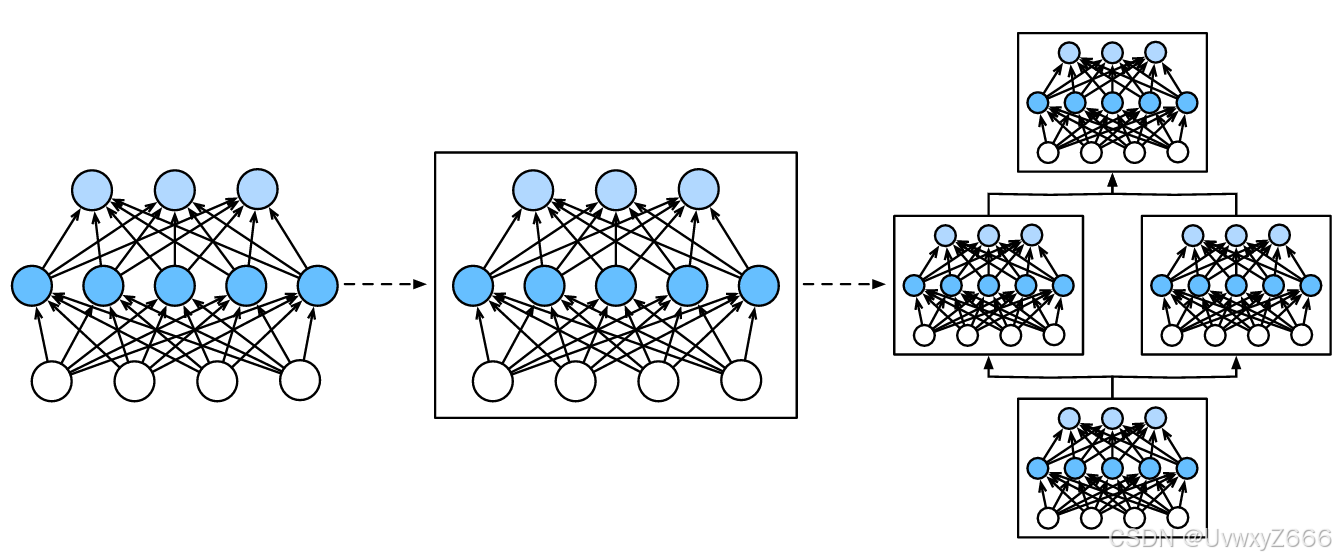
自定义块
想要深入了解“块”,我们可以自己动手实现一个:
class MLP(nn.Module):
# 用模型参数声明层。这里,我们声明两个全连接的层
def __init__(self):
# 调用MLP的父类Module的构造函数来执行必要的初始化。
# 这样,在类实例化时也可以指定其他函数参数,例如模型参数params(稍后将介绍)
super().__init__()
self.hidden = nn.Linear(20, 256) # 隐藏层
self.out = nn.Linear(256, 10) # 输出层
# 定义模型的前向传播,即如何根据输入X返回所需的模型输出
def forward(self, X):
# 注意,这里我们使用ReLU的函数版本,其在nn.functional模块中定义。
return self.out(F.relu(self.hidden(X)))实例化这个类:
net = MLP()
net.forward(X) #等效于net(X)输出:
tensor([[ 0.2535, -0.1106, 0.1944, -0.1779, -0.1540, 0.0939, 0.2560, 0.1141,
0.0368, -0.1281],
[ 0.0286, 0.0554, 0.1914, 0.0065, -0.0017, 0.2003, 0.0707, 0.0512,
-0.0016, -0.0085]], grad_fn=<AddmmBackward0>)
这个例子十分简单,唯一值得注意的是我们在执行net(X)的时候实际上就是在调用net.forward(x)。
顺序快
来看看Sequential类是如何工作的。
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
# 这里,module是Module子类的一个实例。我们把它保存在'Module'类的成员
# 变量_modules中。_module的类型是OrderedDict
self._modules[str(idx)] = module
def forward(self, X):
# OrderedDict保证了按照成员添加的顺序遍历它们
for block in self._modules.values():
X = block(X)
return X调用:
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10))
net(X)输出:
tensor([[ 0.0011, 0.1545, -0.0147, -0.0517, -0.1129, 0.1292, 0.3381, 0.0989,
-0.0893, -0.0295],
[-0.0605, 0.1350, -0.0213, -0.1577, -0.0175, 0.0041, 0.2423, -0.0636,
-0.0778, 0.0949]], grad_fn=<AddmmBackward0>)
代码解释
如果对代码有疑问,或者想深入了解一下,不妨看一下ai的解释。(注:下面一段由ai生成)
这段代码定义了一个名为 `MySequential` 的类,它继承自 PyTorch 的 `nn.Module` 类。这个类实现了一个自定义的序列模型,类似于 PyTorch 的 `nn.Sequential`,但是提供了一种自定义的方式来添加模块。下面是代码的逐行解释:
1. `class MySequential(nn.Module)`:定义了一个名为 `MySequential` 的类,它继承自 `nn.Module`。
2. `__init__(self, *args)`:构造函数接受任意数量的位置参数 `*args`。这些参数应该是 `nn.Module` 的子类实例。
3. `super().__init__()`:调用父类 `nn.Module` 的构造函数来执行必要的初始化。
4. `for idx, module in enumerate(args):`:遍历所有传入的参数。`enumerate` 函数返回每个参数的索引(`idx`)和参数本身(`module`)。
5. `self._modules[str(idx)] = module`:将每个模块实例添加到 `_modules` 字典中。索引被转换为字符串,因为 `_modules` 字典的键需要是字符串类型。这里使用字符串索引而不是数字索引是为了保持模块添加的顺序,类似于 `OrderedDict`。
6. `def forward(self, X)`:定义了模型的前向传播方法。
7. `for block in self._modules.values():`:遍历 `_modules` 字典中的所有值(即所有模块实例)。
8. `X = block(X)`:对输入 `X` 应用当前模块 `block`,并更新 `X` 为模块的输出。
9. `return X`:返回经过所有模块处理后的最终输出。
这个自定义的 `MySequential` 类允许你以顺序的方式堆叠多个神经网络模块。每个模块将按照它们添加到 `MySequential` 实例中的顺序依次应用于输入数据 `X`。这与 PyTorch 的内置 `nn.Sequential` 类的功能类似,但提供了更多的灵活性,例如通过索引访问特定的模块或修改模块的顺序。
enumerate()
enumerate()是 Python 中的一个内置函数,它用于将一个可迭代对象(如列表、元组、字符串等)组合为一个索引序列,同时返回元素的索引和值。这个函数经常用于 for 循环中,使得你可以在遍历列表或其它序列的同时获得元素的索引和值。
my_list = ['apple', 'banana', 'cherry']
for index, value in enumerate(my_list):
print(index, value)
#输出:
#0 apple
#1 banana
#2 cherry如果你想从非零索引开始计数,可以传递 start参数:
for index, value in enumerate(my_list, start=1):
print(index, value)
#输出:
#1 apple
#2 banana
#3 cherry