目录
0 关于本文
- 本文是一篇LangChain入门教程,是本人学习LangChain官方文档(v0.3)过程的知识总结。
- 目的有二:一者供自己日后快速回顾;二者供大家快速上手(毕竟中文比英文顺眼吧~)。
- 什么是LangChain:其实就是一个开源框架,提供一些工具、接口帮你快速创建由大语言模型(Large Language Model,即后文的llm)和聊天模型支持的应用程序。也就是说它本身只是帮你调用大模型构建特定功能的应用,所以你还需要有大模型,一般我们都是使用其他公司的大模型api,如OpenAI,Gemini等。
1 准备环境
1.1 安装LangChain的相关Python包
pip install langchain
pip install -qU langchain-openai
pip install "langserve[all]"
1.2 准备LangSmith的API Key(不是必要步骤,但是是免费的)
- 什么是LangSmith:就是一个可以调试、测试、评估和监控基于任何LLM框架构建的链和智能代理的框架,他能与LangChain无缝集成。其实就是用它来观察大模型进行了哪些调用,让你清楚你的大模型内部咋工作的。所以其实这在开发LangChain应用中不是必须的。
- 怎么监控的?就是你可以进入这个监控页面,看到你提问了什么,大模型回答了什么。
- 怎么进入监控页面
- 登录LangChain官网,点击“sign up”登录,没有账号就注册一个
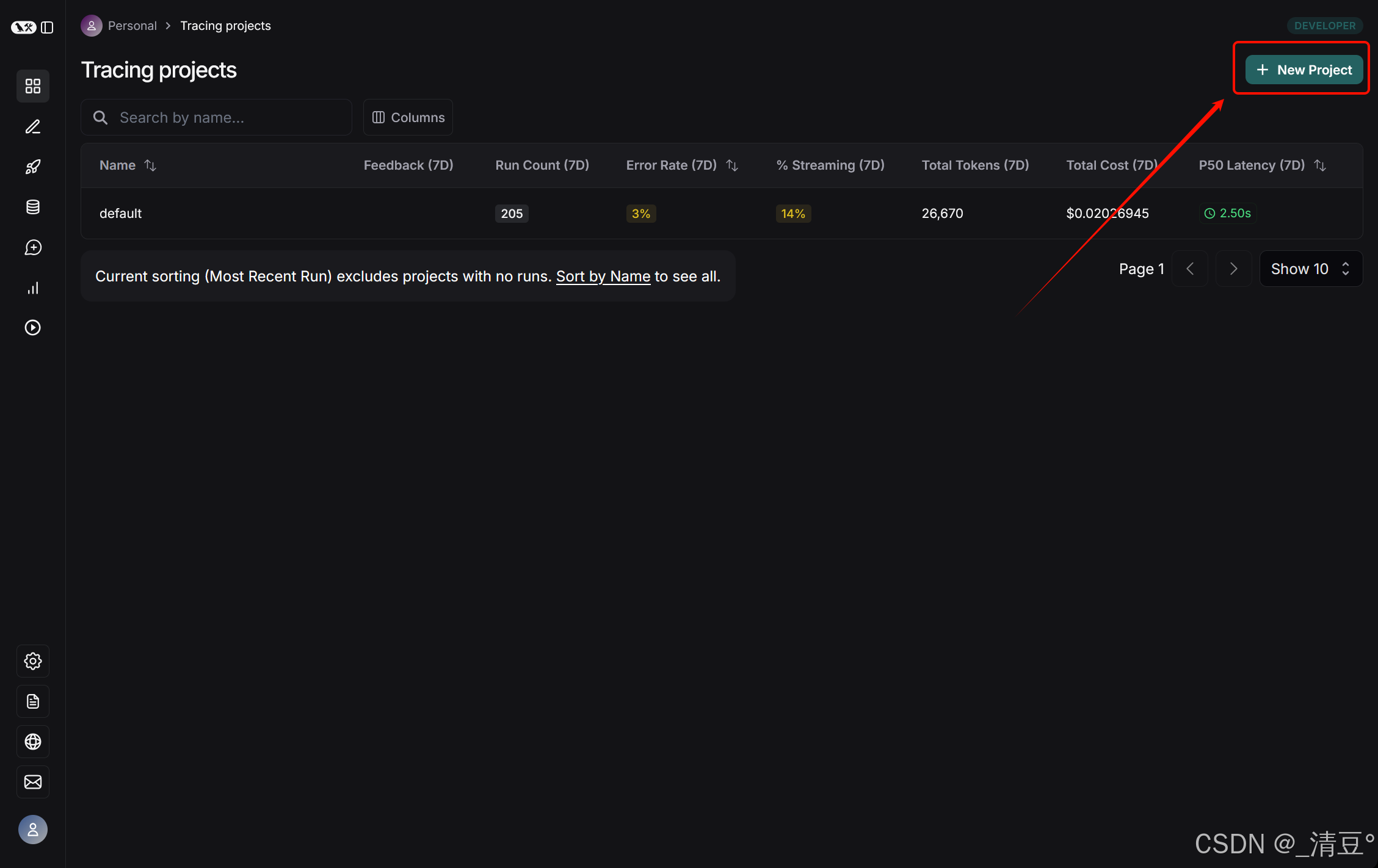
- 点击“Tracing Projects”
- 点击要监控的项目即可进入前面的监控画面,这儿一个项目应该对应的是一个LangSmith的API
- 登录LangChain官网,点击“sign up”登录,没有账号就注册一个
- 如何申请LangSmith的API?
-
还是这个界面,点击“New Project”
-
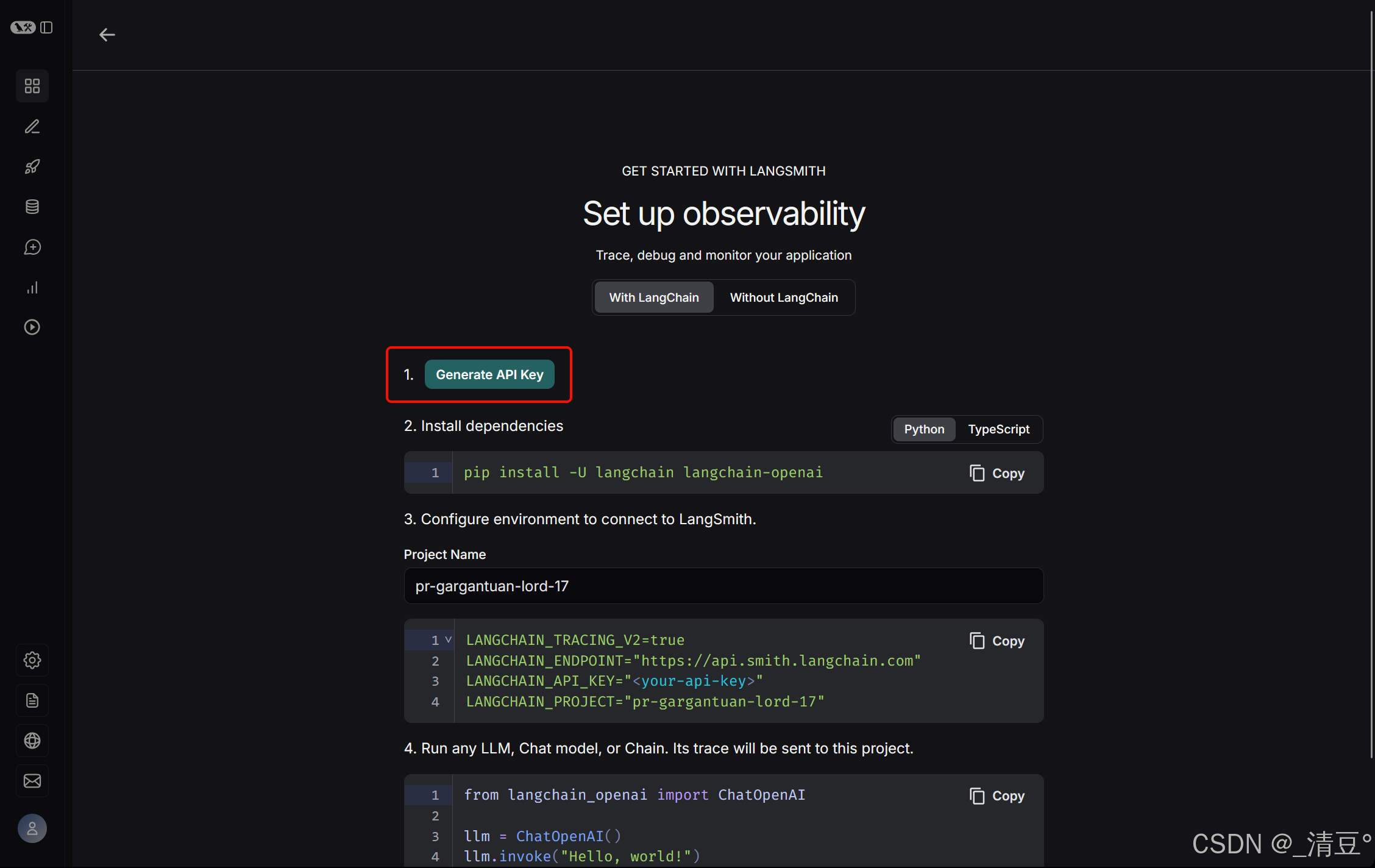
点击“Generate API Key”
-
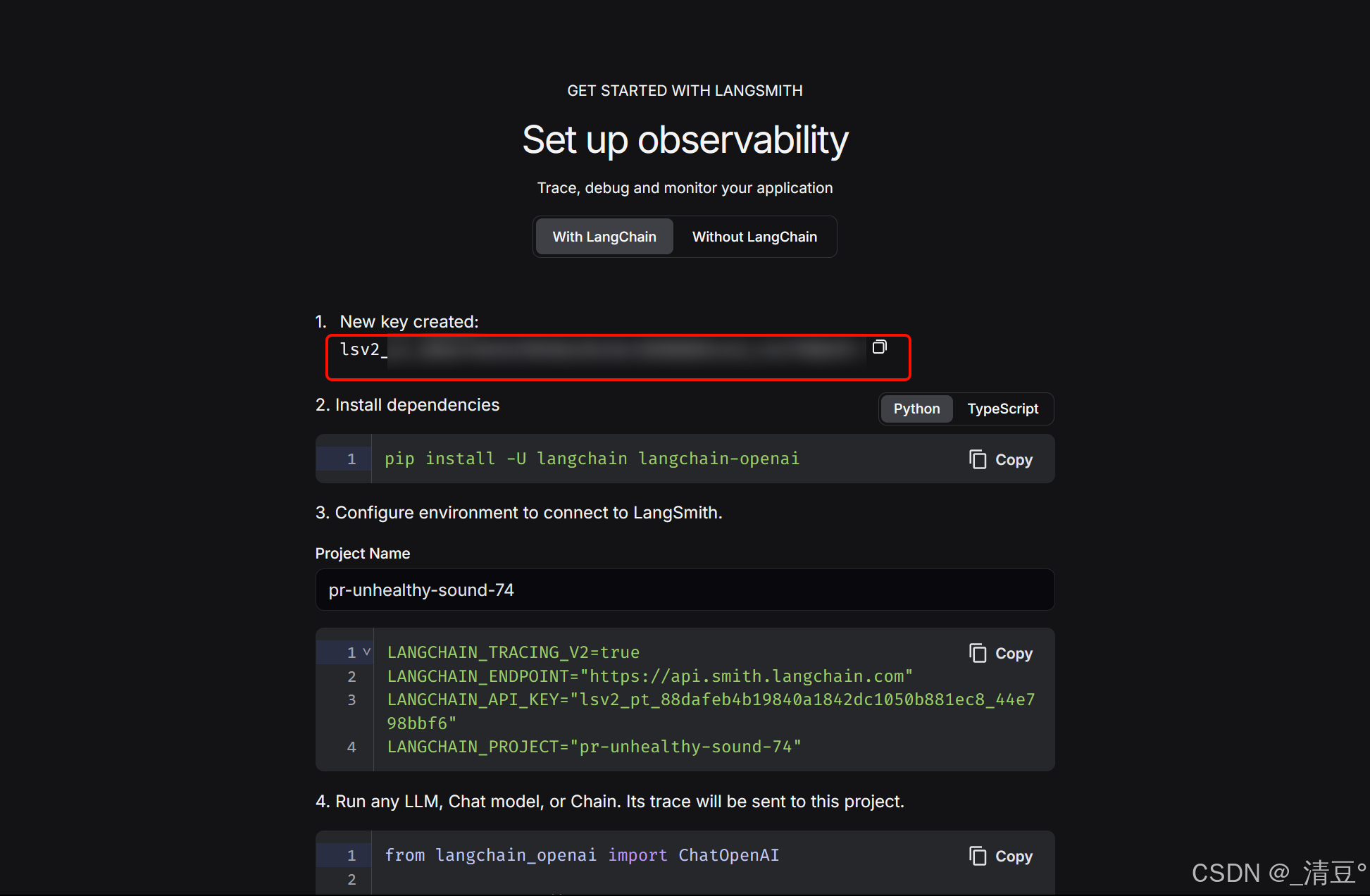
复制保存好你的API Key
-
- 怎么使用?就是配置为Python程序的环境变量,参见1.4节。
1.3 准备语言模型的API
- 前文提到开发LangChain应用需要一个大模型,我们通常是调用其他厂商提供的api,如Openai、Gemini、通义千问等。
- LangChain官方教程使用的是OpenAI,本文使用OpenAI的中转API进行演示。OpenAI的API是收费的且访问不方便,通义千问等国内厂商的api一般有免费额度。
- 如何获取OpenAI的API?
- 方法一(推荐):像我一样,去某宝或某多多买个中转的api,价格便宜,几块钱就可以开始学习,搜索关键字是“中转api”。
- 方法二:申请官方的API,要钱比较麻烦,我没申请过,可查看其他博客教程。
- 如何获取OpenAI的API?
1.4 准备环境变量
-
使用你的IDE创建一个Python项目,这个你应该会,不会就建议先学好基础再来学本教程。
-
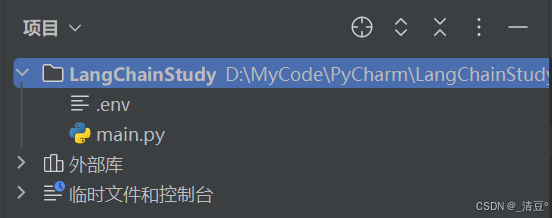
在.py文件(就是你书写大模型代码的Python文件,后文无特殊说明使用main.py。同理,如果你使用的是Jupyter NoteBook,就是在.ipynb文件同级目录)的同级目录下创建一个全名为.env的文件,这个文件是用于存放环境变量的,我们把环境变量定义在里面,然后py文件可通过load_dotenv()方法快速加载这些环境变量,例如我的项目文件结构是这样的:
-
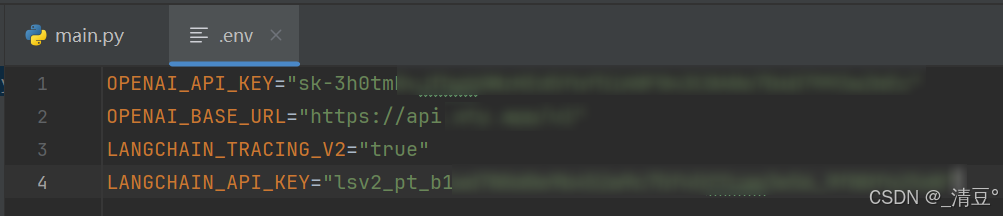
在.env文件(全名就是“.env”,不能做任何修改)中书写定义环境变量:
- OPENAI_API_KEY:就是你的大模型的API Key,一般是sk开头。
- OPENAI_BASE_URL:指定 OpenAI API 的基础 URL 地址。如果你购买的OpenAI的直连API就不需要设置这个环境变量,如果是某宝某多购买的中转API则一般会提供给你一个中转地址,形为https://api…/v1,这个时候就需要设置OPENAI_BASE_URL为该网站。
- LANGCHAIN_TRACING_V2:设置为true。
- LANGCHAIN_API_KEY:前文申请到的LangSmith的API,这就是LangSmith的用法。
2 一个简单的案例
为了让大家先感受一下LangChain框架,这里给出一个最简单的案例。注意,这个案例一定是正确的,如果报错则一定是环境缺少包或者环境变量没配置等问题。
- main.py文件内容:
from dotenv import load_dotenv
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_openai import ChatOpenAI
# 加载.env文件的环境变量
load_dotenv()
# 创建一个大语言模型,model指定了大语言模型的种类
model = ChatOpenAI(model="gpt-3.5-turbo")
# 定义传递给模型的消息队列
# SystemMessage的content指定了大语言模型的身份,即他应该做什么,对他进行设定
# HumanMessage的content是我们要对大语言模型说的话,即用户的输入
messages = [
SystemMessage(content="把下面的语句翻译为英文。"),
HumanMessage(content="今天天气怎么样?"),
]
# 打印模型的输出结果
print(model.invoke(messages).content)
-
结合代码中的注释我相信你能看懂这个简单案例的功能(调用大模型,让他把“今天天气怎么样?”这句话翻译为英文并输出)。这其实就是一个最基本的LangChain程序逻辑,相信你已经有了一定的感受。
-
执行结果(输出类似,模型成功翻译):
-
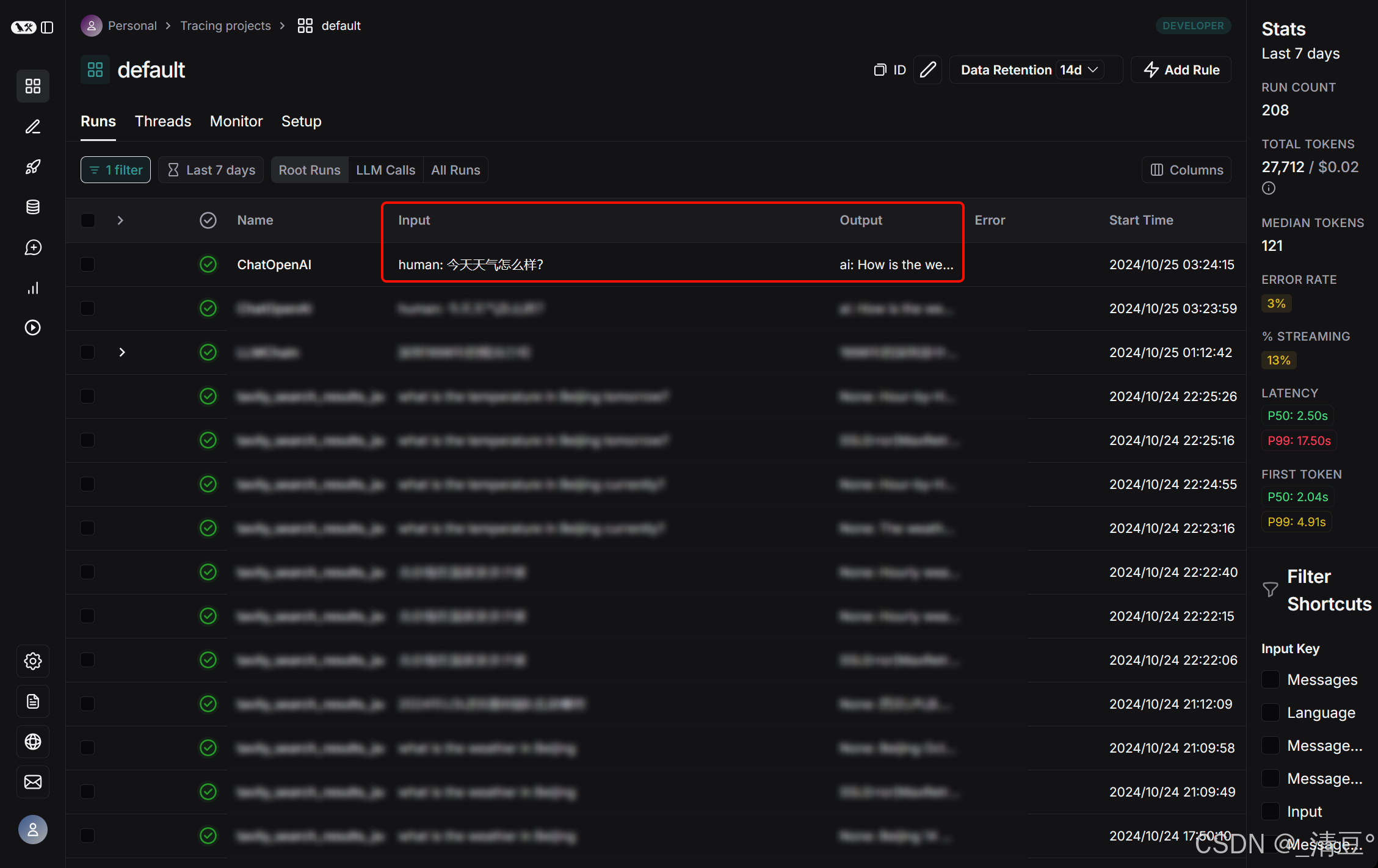
如果你设置了LangSmith的API进行跟踪,则还可以查看LangSmith的结果:
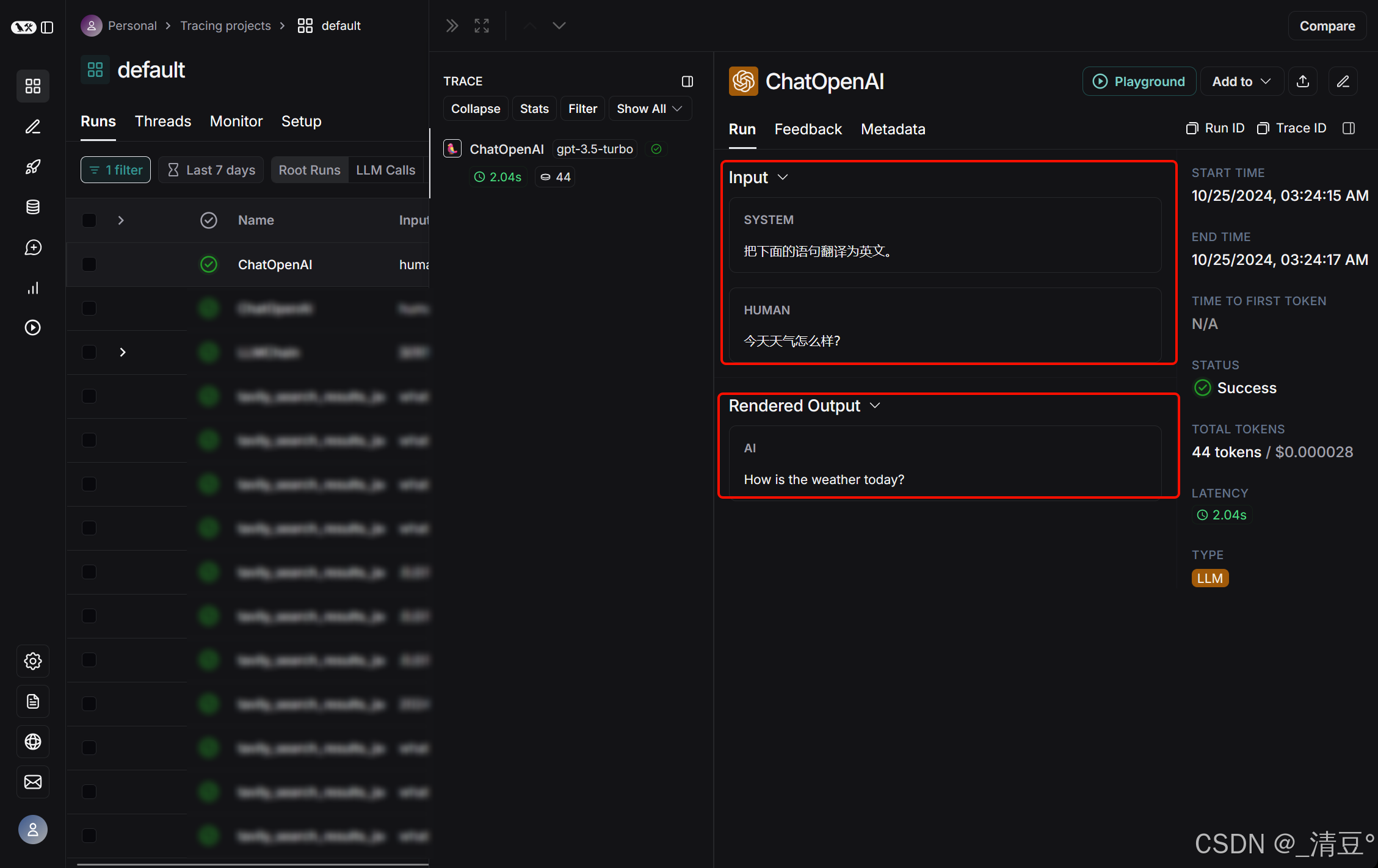
点击每一行的Name可以查看该跟踪对话的详情:
接下来,后文将以此为案例为基础进行扩展,介绍一些更强大的功能。

3 使用StrOutputParser对模型结果进行解析
- 注意前文打印大模型返回结果的方法:print(model.invoke(messages).content),其中model.invoke(messages)的结果是一个AIMessage对象,该对象的content值记录了大模型的输出结果。
- 但其实LangChain提供了一个类StrOutputParser专门解析出这部分内容进行打印
- 使用方法:
from langchain_core.output_parsers import StrOutputParser
# ...省略的代码
# 使用result接收模型的输出,result就是一个AIMessage对象
result = model.invoke(messages)
# 定义一个解析器对象
parser = StrOutputParser()
# 使用解析器对result进行解析
parser.invoke(result)

- 但其实AIMessage对象也有专门的方法打印模型的输出:
model.invoke(messages).pretty_print()

4 使用ChatPromptTemplate构建输入消息列表
- 在简单案例中,我们是向模型的invoke方法直接传入的构建的消息列表(即,messages=[…]),这是这种列表无法从用户处获得变量对消息列表进行设置,故引入ChatPromptTemplate
- ChatPromptTemplate能从用户输入中获取变量构建Prompt传给大模型进行调用,其使用方法如下:
- 这里(“system”, “把下面的语句翻译为{language}。”)等价于SystemMessage(content=“把下面的语句翻译为英文。”);(“user”, “{text}”)等价于HumanMessage(content=“今天天气怎么样?”)。但是在定义ChatPromptTemplate时只能使用前者,即下面的方法
prompt_template = ChatPromptTemplate.from_messages([
("system", "把下面的语句翻译为{language}。"),
("user", "{text}")]
)
prompt = prompt_template.invoke({"language": "英文", "text": "今天天气怎么样?"})
print(prompt)
打印结果如下,可以看见同样构建了和简单案例一样的消息队列作为Prompt,但是具有了更高的可定制性。你可能还不理解这种参数化可定制性的好处,不过后面你会慢慢感受到,比如我可以把该应用包装为一个服务,调用者只需要传给我相应参数,而不需要多余的文字。

5 通过LCEL连接各组件
- LECL的全称是LangChain Expression Language。其实他的用处就是使用“|”运算符链接LangChain应用的各个组件,如提示词模版ChatPromptTemplate、大语言模型ChatOpenAI、输出解析器StrOutputParser。连接的方法如下:
chain = prompt_template | model | parser
print(chain.invoke({"language": "英文", "text": "今天天气怎么样?"}))
- 此时直接向chain的invoke方法传入参数即可调用大模型得到一样的输出结果。

6 使用LangServe把大模型包装成可供调用的服务
- LangServe可以把我们的LangChain应用包装为一个服务供别人调用,包装方法如下:
# 安装并引入需要的包
from fastapi import FastAPI
from langserve import add_routes
import uvicorn
# 使用FastAPI创建一个可访问的应用
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# 将该应用包装为一个服务
add_routes(
app,
chain,
path="/chain",
)
# 通过unicorn启动服务
uvicorn.run(app, host="localhost", port=8000)
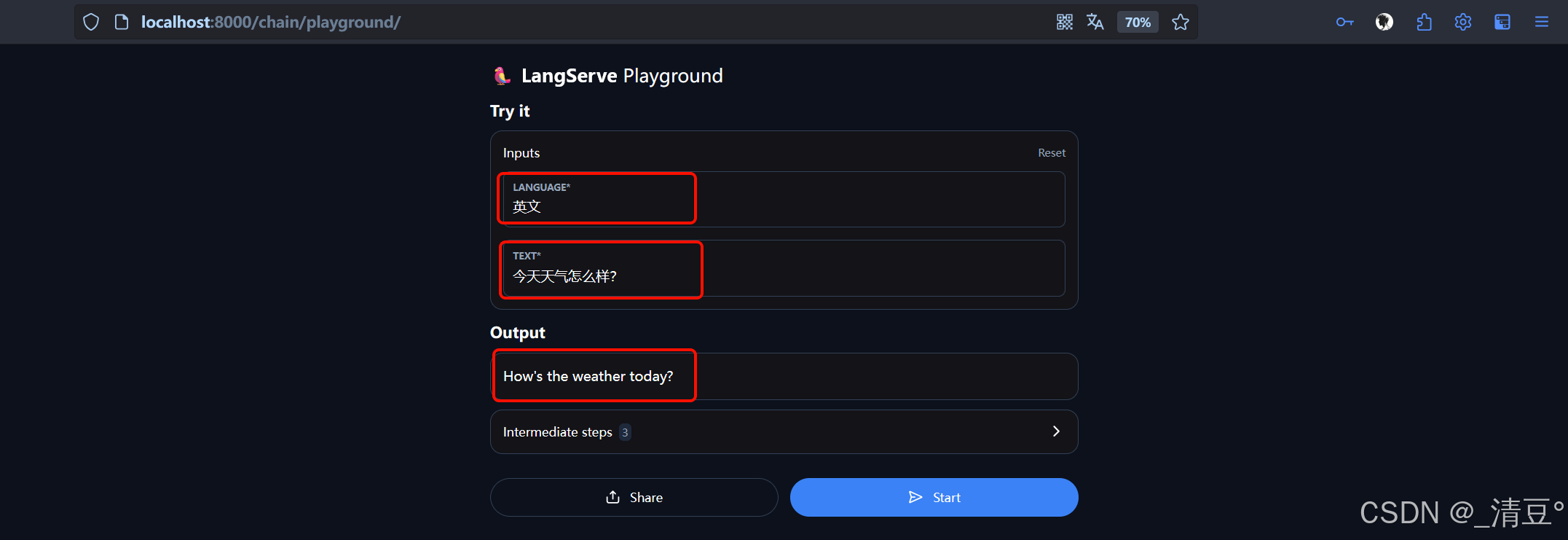
- 随后便可以对该服务进行访问,LangChain提供了一个网页界面实现对LangServe服务的快速访问,网页地址为http://localhost:8000/chain/playground/,注意端口,path值与代码一一对应。同样能得到类似的结果。
补充一:使用其他大模型
1、阿里云百炼平台(免费,推荐)
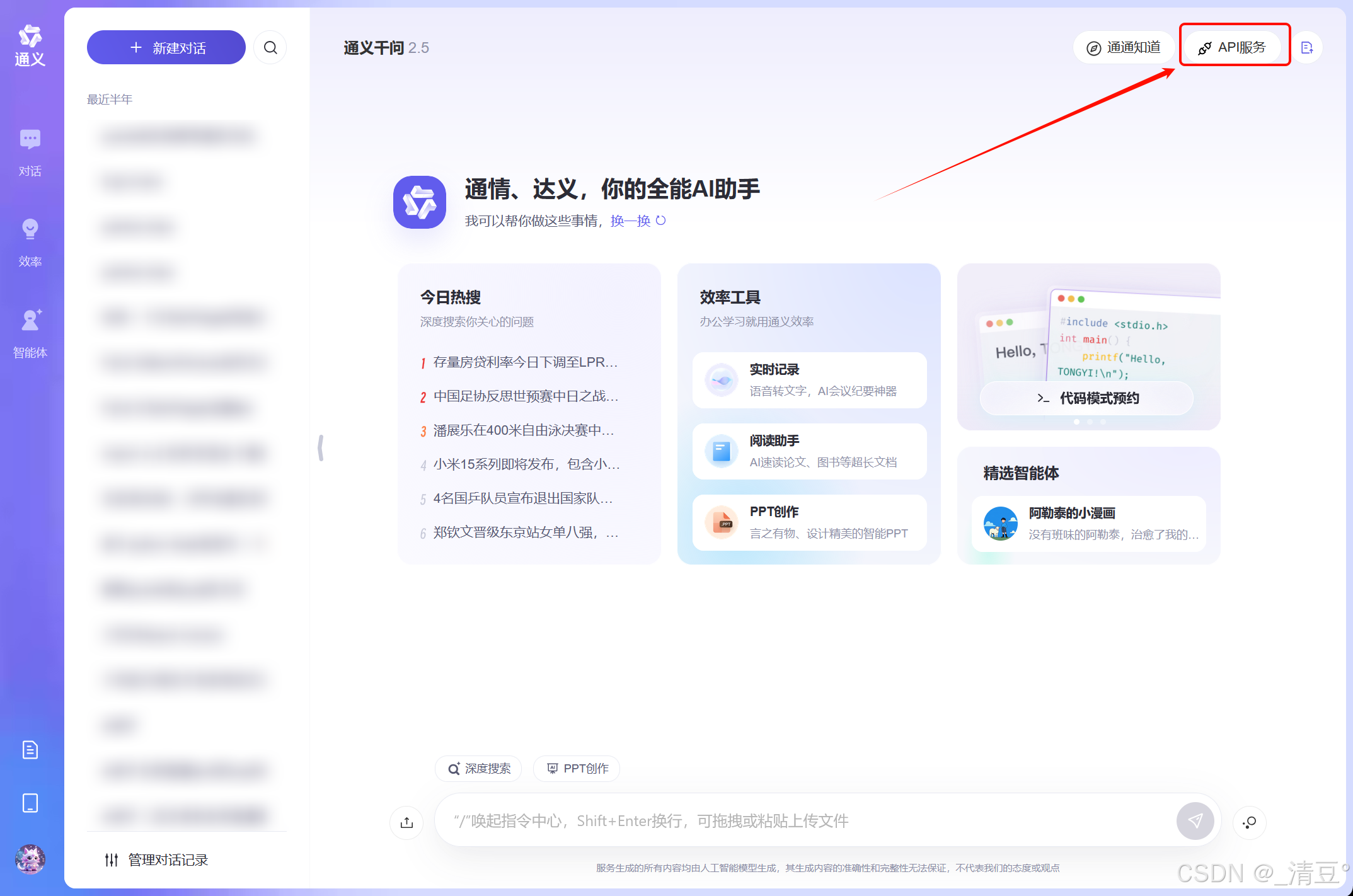
- 进入通义千问网页,点击API服务
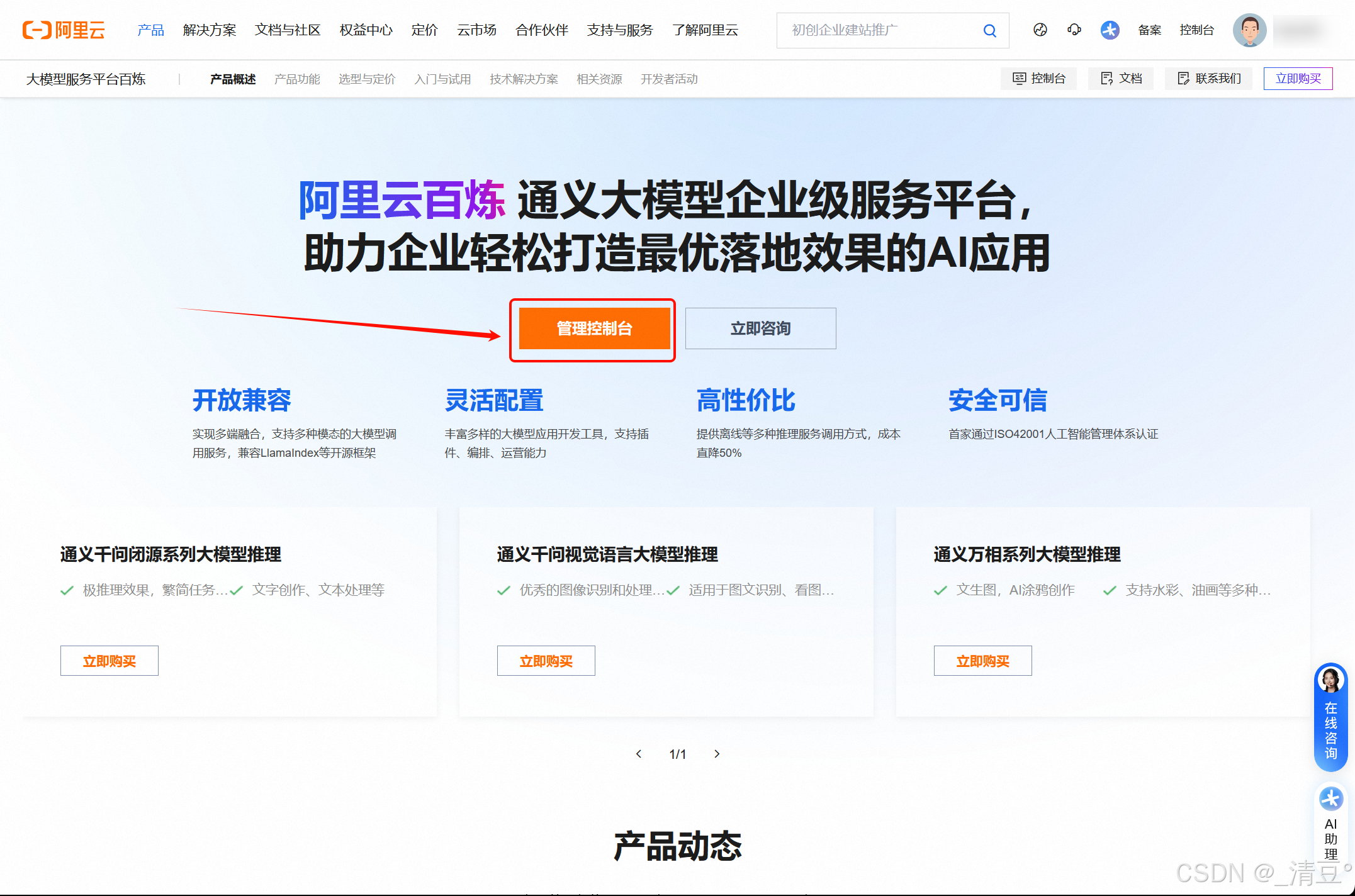
- 使用阿里云账号登录(没有就注册一个)后点击管理控制台
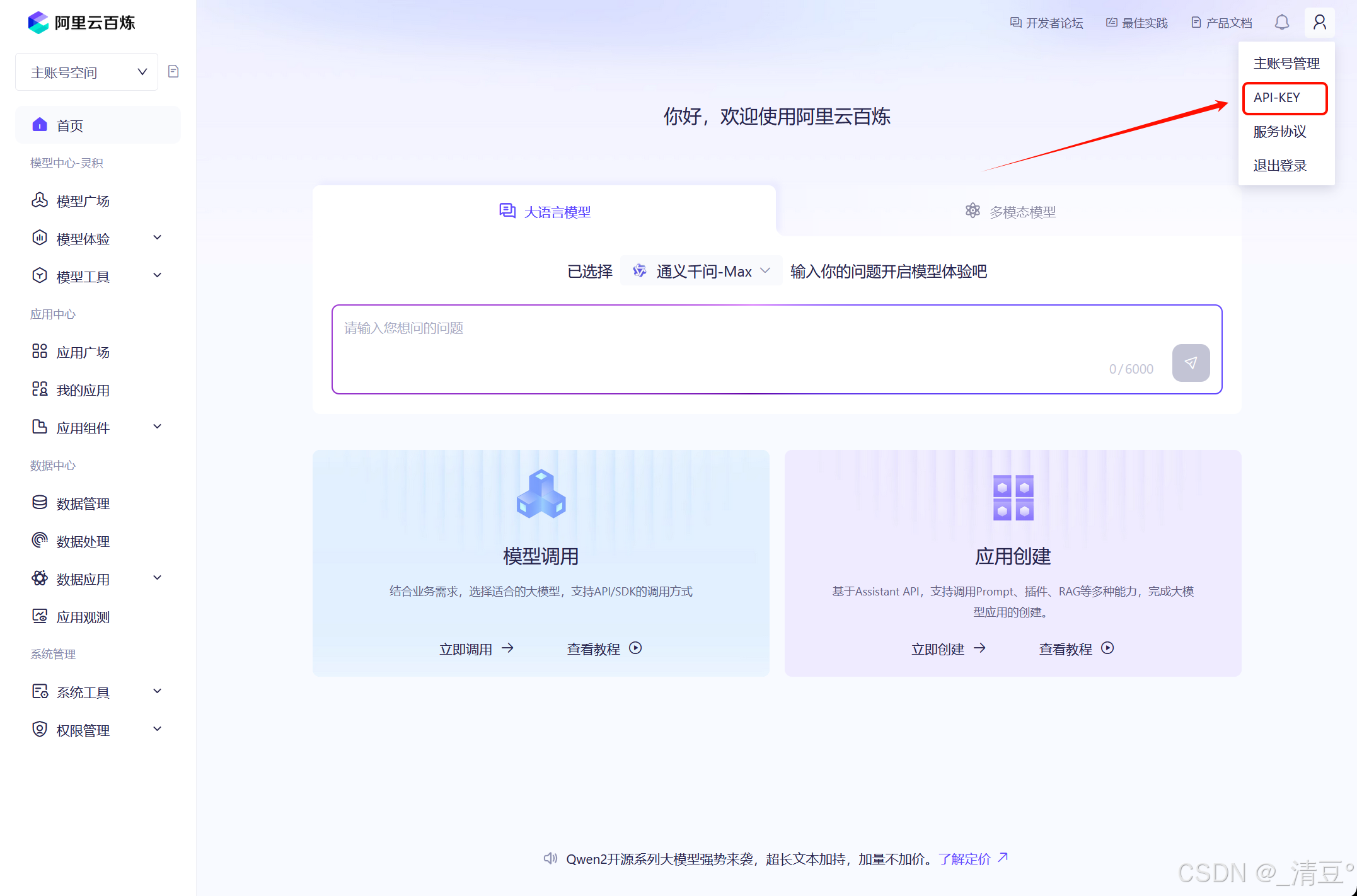
- 右上角点击API-KEY
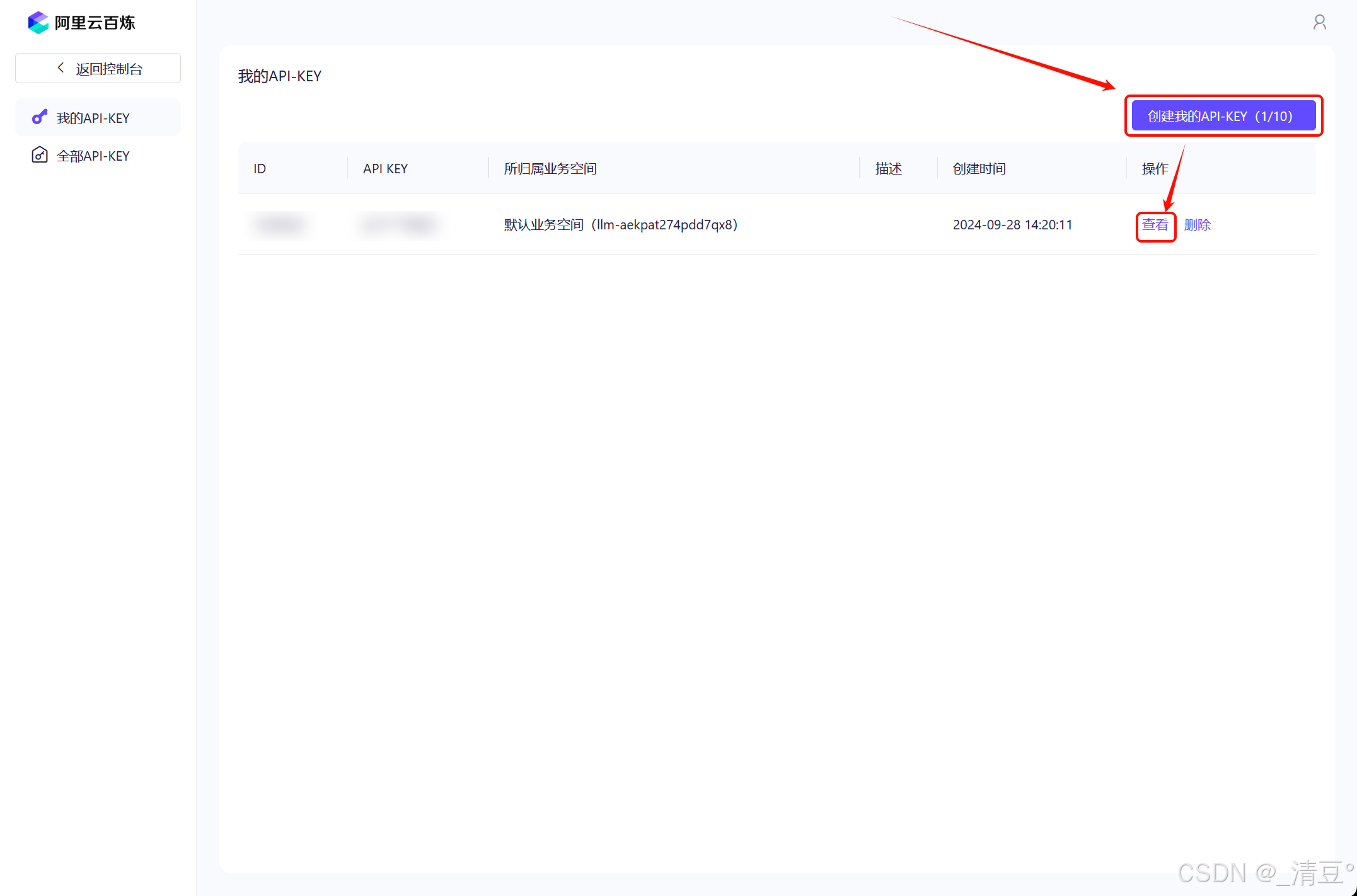
- 点击创建我的API-KEY,创建好之后点击查看可以复制该API-KEY
- 然后在千问代码中作如下修改:
- 在.env文件定义环境变量:DASHSCOPE_API_KEY=“sk-ff817b7f4…”
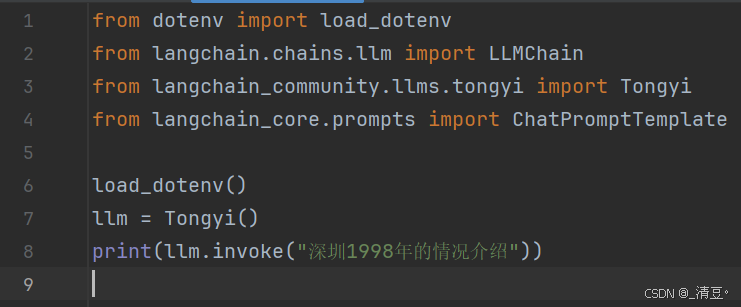
- main.py创建大模型时使用:llm = Tongyi(),一个简单的演示如下:
- 其他步骤不用改变。
2、使用OpenAI官方的API
- 有了官方api在进行访问时通常需要代理,只需要在.env环境对程序的代理进行设置即可(把代理的地址替换为你的代理地址即可):
HTTP_PROXY='http://your_http_proxy:port'
HTTPS_PROXY='https://your_https_proxy:port'