我们中说删库跑路,那么数据库删除后,里面的数据怎么恢复呢?
这里就涉及到了redolog和binlog了
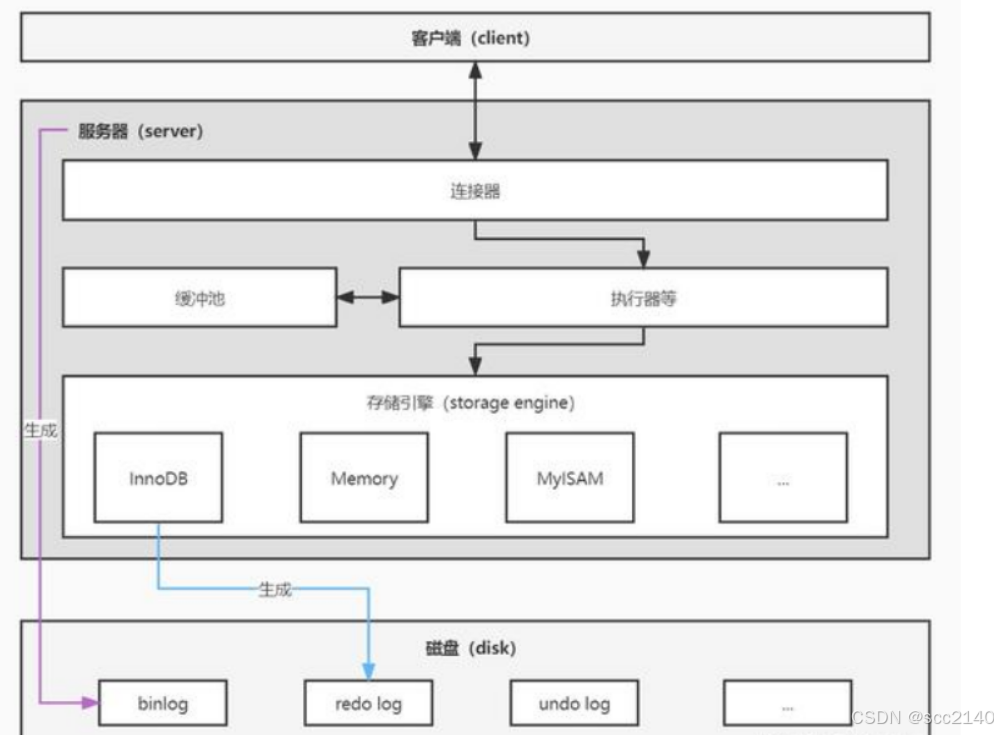
一、什么是存储引擎和缓冲池
存储引擎是 MySQL 中直接与磁盘交互部分。也是存储引擎读写数据的最小单位,一个页里可以有一条或多条表记录。MySQL 中的存储引擎有很多种,比如 InnoDB、MyISAM、Memory 等。其中最常用的是 InnoDB。而 InnoDB 是 MySQL 中唯一能够完整支持事务特性的存储引擎,也是一个高性能的存储引擎。「两段式提交」就发生在 InnoDB 中。
缓冲池
首先,关系型数据库是基于磁盘的,而非关系型数据库是基于内存的。
mysql就是一个基于磁盘的数据库,关系型数据库的特点就是需要对磁盘中大量的数据进行存取,所以有时候也被叫做基于磁盘的数据库。正是因为数据库需要频繁对磁盘进行 IO 操作,为了改善因为直接读写磁盘导致的 IO 性能问题,所以引入了缓冲池。mysql每次查询时是按页进行查询的,每个页中会有大量的数据,将这些数据加载到内存中的缓冲池中,下次再进行查找的时候,会先去内存中进行查找,若找不到才会去磁盘中读取。这种方式是很好的,但是会出现缓冲池污染和预读失效的问题
二、刷脏页
对于mysql来说,那么查询的效率是有了,但是另一个问题是增删改的在缓冲池的基础上是怎么解决的,以下以修改进行说明。在修改的时候,mysql会首先将缓冲池中的数据进行修改,而磁盘上的数据和内存中的数据不一致了,此时该页就是脏页,然后需要将缓冲池中的数据页刷到磁盘中,这个被称为刷脏页。
刷脏页的时机:
-
每 10 秒必刷新一次
-
脏页太多时(默认占比超过 innodb_max_dirty_pages_pct 配置的值时刷新)
-
redo log 空间不足时
-
数据库关闭时
三、什么是binlog
binlog 是 MySQL 服务器层面实现的一种二进制日志,用于记录所有对数据库的增删改操作(这种日志被称为逻辑日志)。比如你 update 一条记录,服务器就会记录一条对应的信息到 binlog。但在 InnoDB 中,这个 binlog 是以事务为单位刷新到磁盘的。基于 binlog 的这种特性,一般我们会将 binlog 用于以下几个方面:
-
数据库增量备份与恢复:在使用备份还原数据后,可以使用 binlog 中记录的内容对备份时间点(简称备份点)后的数据进行恢复。因为 binlog 会还会记录下更改操作的时间,所以 binlog 可以恢复到某一具体时间点的数据。但是不可避免的还是会造成数据丢失(如果被删库跑路的话)
-
主从复制:MySQL 从服务器可以通过订阅 binlog 实现对主服务器的增量复制。
-
审计:通过对 binlog 中的数据进行审计,判断是否存在安全问题,比如 SQL 注入。
binlog 进行恢复的流程
-
先通过最新的备份恢复数据库的数据,并记录下备份文件备份的时间点。
-
在 binlog 中找到这个时间点,提取这个时间点以后的数据用于实现对备份点后数据的恢复(这个特性被称为 Point in Time,简称 PIT)。
各个部分之间的关系
什么是随机 IO 和顺序 IO?
磁盘读写数据的两种方式。随机 IO 需要先找到地址,再读写数据,每次拿到的地址都是随机的。就像送外卖,每一单送的地址都不一样,到处跑,效率极低。而顺序 IO,由于地址是连贯的,找到地址后,一次可以读写许多数据,效率比较高。就像送外卖,所有的单子地址都在一栋楼,一下可以送很多,效率很高。
四、什么是redo log
前面我们讲到数据页在缓冲池中被修改会变成脏页。如果这时宕机,脏页就会失效,这就导致我们修改的数据丢失了,也就无法保证事务的持久性。保证数据不丢,就是 redo log 的一个重要功能。
如果我们修改了缓冲池中的数据页就立刻刷脏页,会产生大量随机 IO,导致磁盘性能变差;但如果我们先写缓冲,一段时间后再刷脏页,就有可能造成数据丢失,无法保证事务的持久性。
WAL(Write-Ahead Logging,日志先行)。即:事务提交前先写日志,再修改页(修改页的时机就是刷脏页的时机)。这里所谓的日志,就是 redo log。
然后一旦脏页刷新,那么redo log中的相关记录就会失效,所以redo log该文件可以回头继续使用。
redo log的持久化(将redo log文件放在磁盘中)
redo log buffer 是内存中的一片区域,即先在内存中存放redo log 的记录,然后等到事务结束会将redo log buffer 写入磁盘中的redo log文件中。
总结:开始事务——用户写sql修改数据——修改内存中的数据——每修改一次就会写到redo log buffer 中一条数据——用户sql执行完毕,事务结束——将redo log buffer 中的所有数据写入到磁盘中——mysql的服务器会在合适的时候将脏页刷入磁盘中——此时redo log 中的记录这些操作的相关数据就失效了——下次将redo log buffer中的数据写入磁盘中时,可以从头开始。
redo_log buffer并不一定是每次都是在事务结束后才把数据写入磁盘中的,那样有的情况下就太慢了。
可以在以下时机将 redo log buffer 中的记录刷新到磁盘
-
每秒刷新一次
-
事务提交时
-
redo log buffer 剩余空间小于 1/2 时
为什么redolog就能保证数据不丢失呢:
由于 redo log 是顺序写(顺序 IO),因此能有效提升 IO 效率;又因为每次事务提交前会先写 redo log,因此可以保障更新的数据不丢失。
五、如何利用redo log恢复宕机的数据呢
InnoDB 为 redo log 记录了序列号,这被称为 LSN(Log Sequence Number),可以理解为偏移量,越新的日志 LSN 越大。InnoDB 用检查点(checkpoint_lsn)指示未被刷脏页的 redo log 数据从这里开始,用 lsn 指示下一个应该被写入日志的位置。不过由于有 redo log buffer 的缘故,实际被写入磁盘的位置往往比 lsn 要小。
有 binlog 为什么还要 redo log ?
-
binlog 不知道数据库究竟是在哪一时刻丢失了哪部分数据,只能从备份点开始对 binlog 记录重放来恢复数据,比较耗时。
-
binlog 恢复是需要我们手动执行的,而 redo log 可以在服务器重启后自动恢复数据。
-
WAL + 先写缓冲 + 异步刷脏页有效提升了磁盘的 IO 效率。
有 redo log 为什么还要 binlog?
-
binlog 是服务器层面的功能,redo log 是 innoDB 的功能。redo log 帮助 InnoDB 实现了性能提升、自动恢复。但其他存储引擎是无法使用 redo log 的能力的。
-
我们也可以关闭 binlog,但大多数情况下我们都会开启,因为开启的好处更多。比如,主从模式需要订阅 binlog 进行主从复制,以及可以通过 binlog 进行数据库的增量备份和恢复。
redo log 有很多好处,所以我们不能放弃;binlog 也有很多好处,我们也不能放弃。也就是说,这两个功能我们都需要开启。既然都要开启,那么我们必须保证 redo log 和 binlog 数据的一致性。
六、执行updata中 InnoDB内部的流程
当我们执行如下 update 语句时,InnoDB 内部的流程是这样的:
-
服务器收到事务开始的指令,为事务生成一个全局唯一的事务 id。这个事务 id 在记录 binlog 和 redo log 时都会使用。
-
如果缓存池中没有 no=1 所在数据页的数据,从磁盘中找到对应的数据页(注意,这里是一个数据页,不是一条记录),把数据页加载到缓存。
-
修改缓存数据页中 no=1 的数据。
-
记录数据到 redo log buffer、binlog cache。根据 redo log 刷盘的策略,这个过程中 redo log buffer 可能会被刷新到磁盘。
-
服务器收到事务提交的指令。
-
刷新 redo log buffer 到磁盘,并标记该事务的状态为 prepare。此操作称为 redo log prepare。
-
刷新 binlog cache 到磁盘。
-
刷新 redo log buffer 到磁盘,并标记该事务的状态为 commit。此操作称为 redo log commit。
-
向客户端返回事务执行的结果。
参考文章: