
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
作者: Le Xue, Manli Shu, Anas Awadalla, Jun Wang, An Yan, Senthil Purushwalkam, Honglu Zhou, Viraj Prabhu, Yutong Dai, Michael S Ryoo, Shrikant Kendre, Jieyu Zhang, Can Qin, Shu Zhang, Chia-Chih Chen, Ning Yu, Juntao Tan, Tulika Manoj Awalgaonkar, Shelby Heinecke, Huan Wang, Yejin Choi, Ludwig Schmidt, Zeyuan Chen, Silvio Savarese, Juan Carlos Niebles, Caiming Xiong, Ran Xu
arXiv: https://arxiv.org/abs/2408.08872
项目主页: https://www.salesforceairesearch.com/opensource/xGen-MM/index.html

摘要
本报告介绍了xGen-MM(也称为BLIP-3),这是一个用于开发大型多模态模型(LMMs)的框架。
该框架包括精心挑选的数据集、训练方案、模型架构以及一系列LMMs。
xGen-MM,即xGen-MultiModal,扩展了Salesforce xGen在基础AI模型上的计划。
我们的模型在各种任务中进行了严格的评估,包括单图和多图基准测试。
我们的预训练基础模型展现出强大的上下文学习能力,而指令微调模型在类似规模的开放源代码LMMs中表现出竞争力。
此外,我们引入了一个使用DPO进行安全微调的模型,旨在减轻如幻觉等有害行为并提高安全性。
我们将我们的模型、精心挑选的大规模数据集以及微调代码库开源,以促进LMM研究的进一步发展。
模型架构
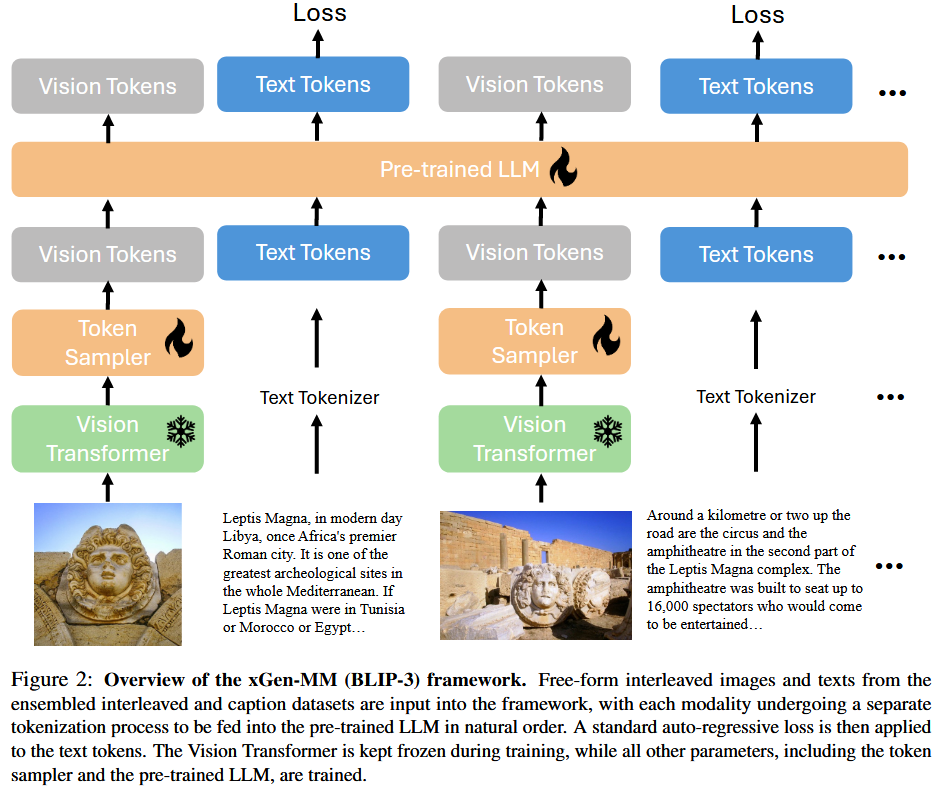
- LLM: Phi-3-mini
- Token Sampler: Perceiver Resampler
- Vision Transformer: SigLIP ViT
训练
Pre-training
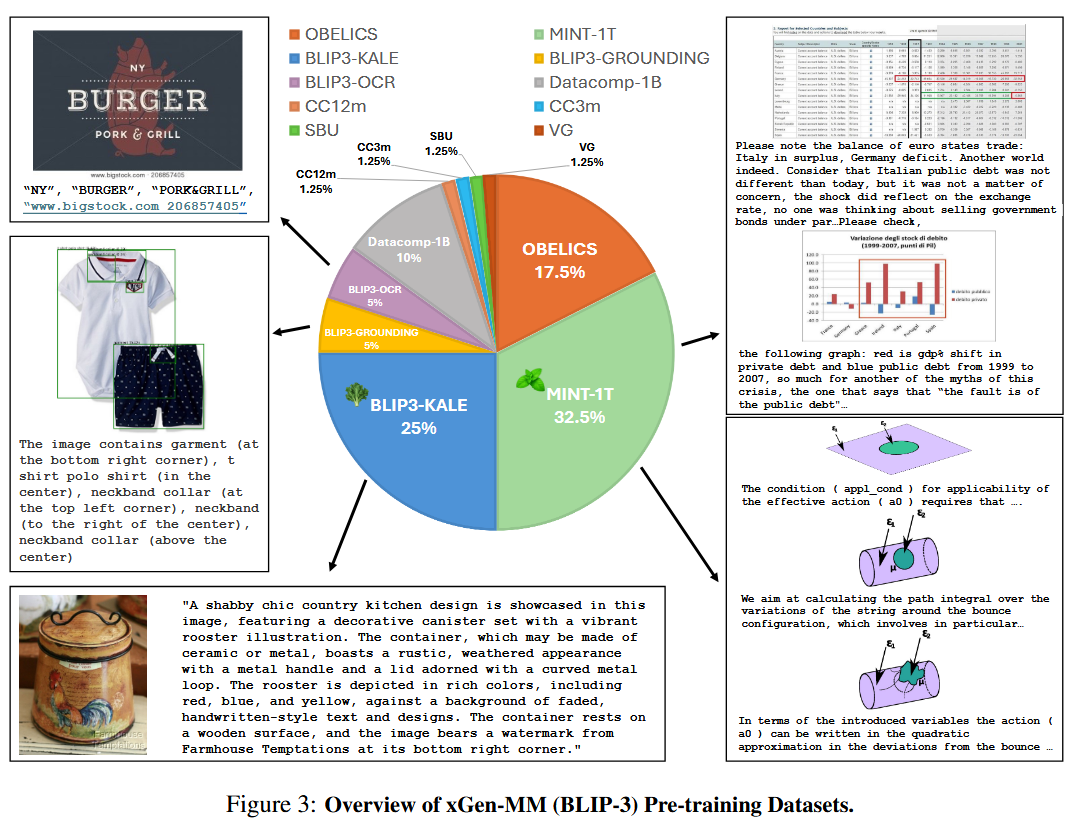
- Interleaved Dataset Mixture
- MINT-1T
- OBELICS
- Caption Dataset Mixture
- BLIP3-KALE
- BLIP3-OCR-200M
- BLIP3-GROUNDING-50M
- Other Public Datasets Mixture
- Datacomp-1B image-text pairs
- CC12M
- CC3M
- VG
- SBU


Supervised Fine-tuning (SFT)
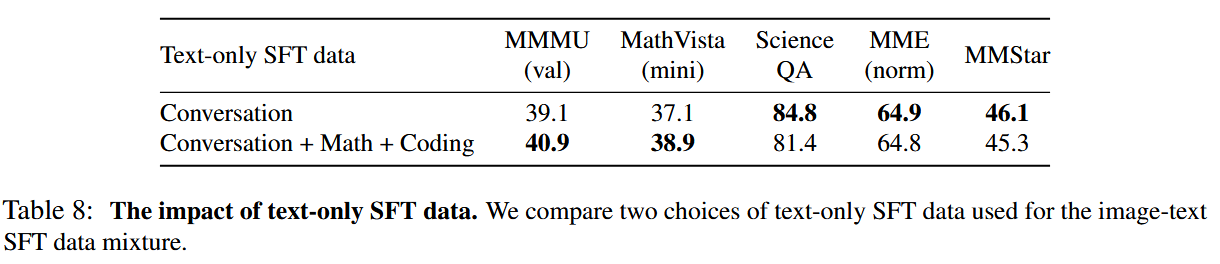
多模态对话、图像描述、视觉问答、图表/文档理解、科学和数学。除了多模态图像-文本数据外,还混合了纯文本指令数据。共100万个公开可用的指令微调样本。
Interleaved Multi-Image Supervised Fine-tuning
多图/图文交错数据: MANTIS、MMDU
为了防止模型退化,混合了SFT阶段训练数据的子集。
Post-training
- Improving Truthfulness by Direct Preference Optimization: VLFeedback
- Improving Harmlessness by Safety Fine-tuning: VLGuard
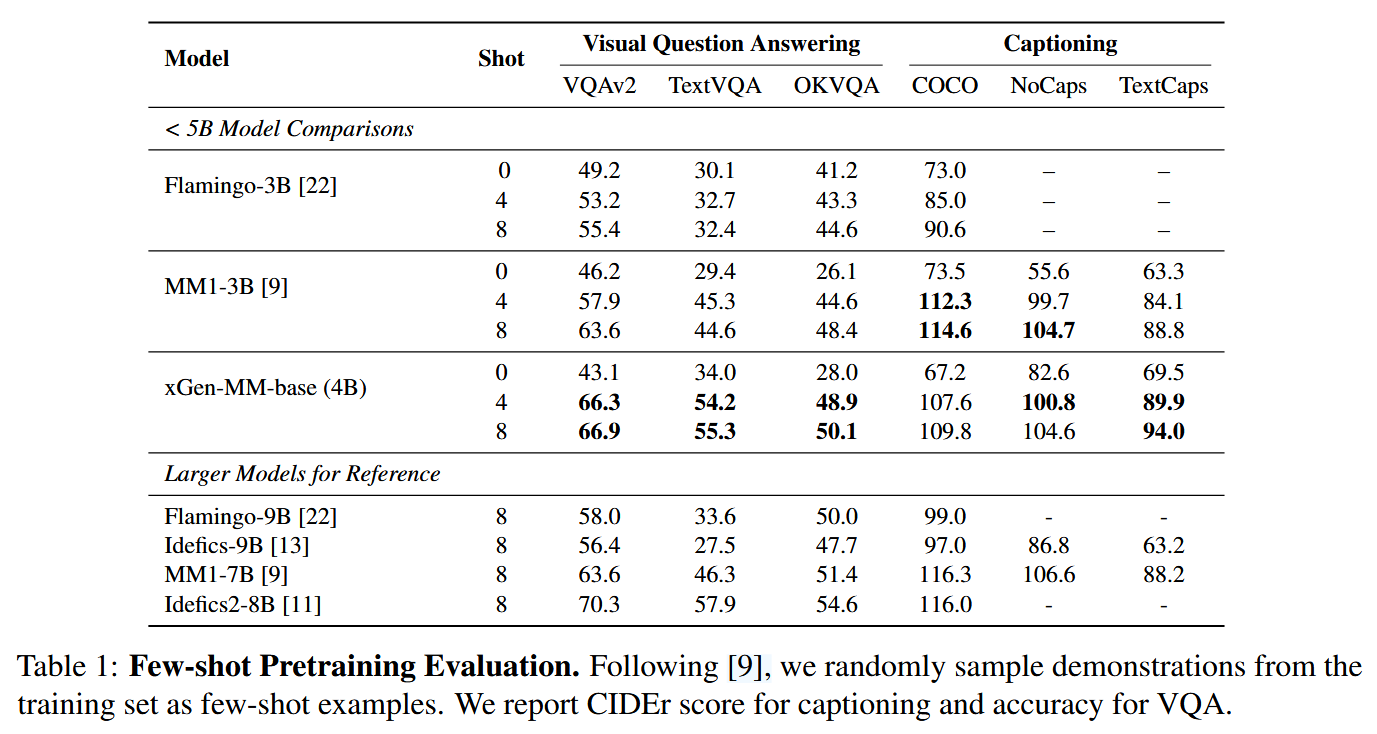
主实验
Pre-training
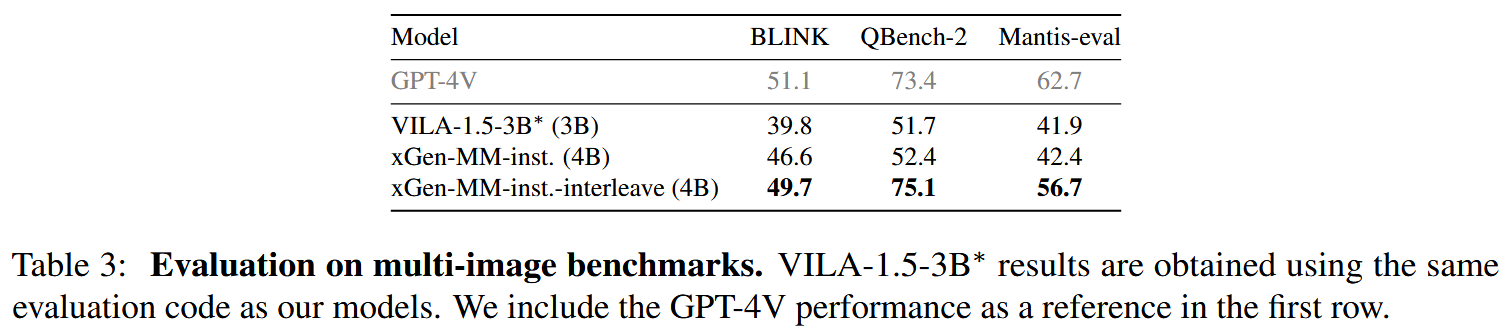
Supervised Fine-tuning
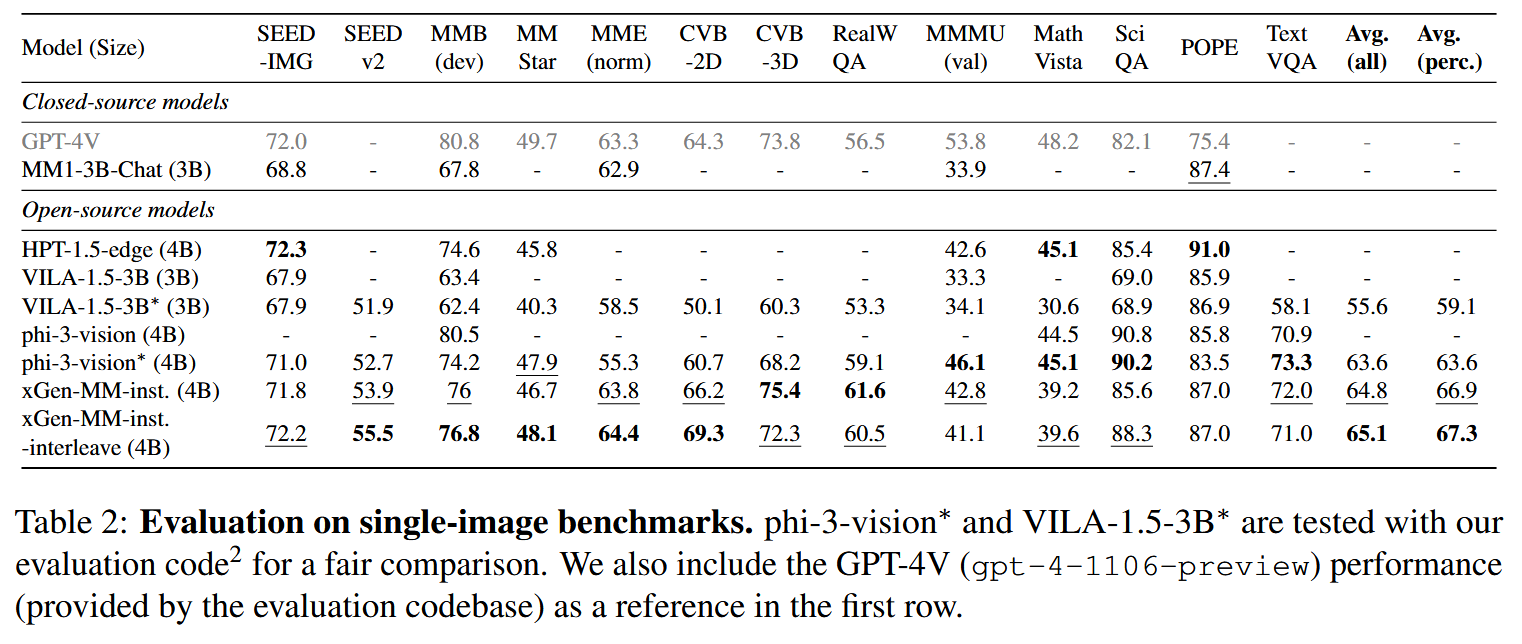

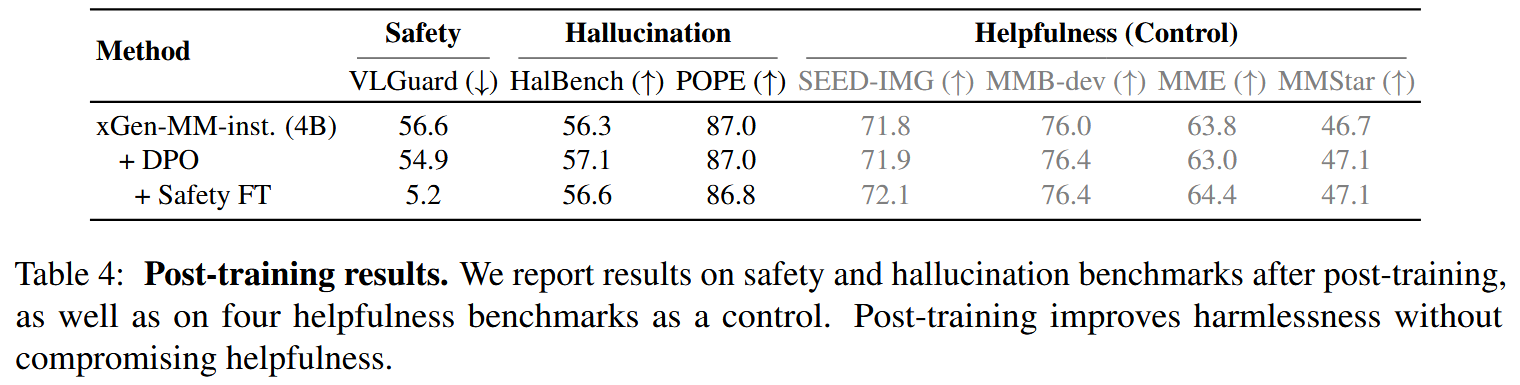
Post-training
消融实验
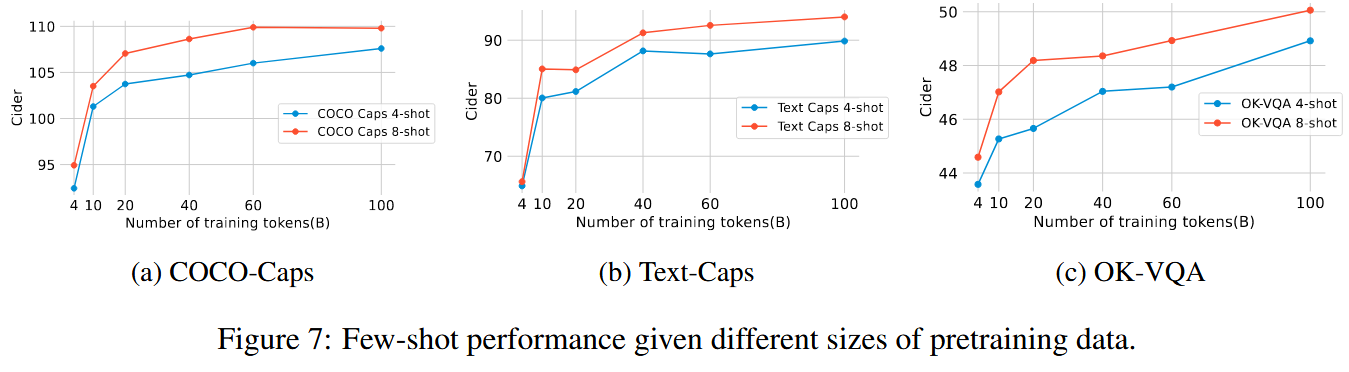
Pre-training Ablation
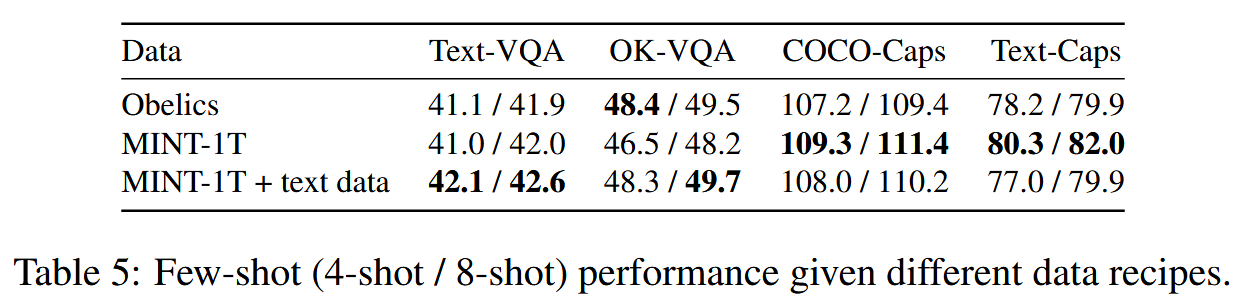


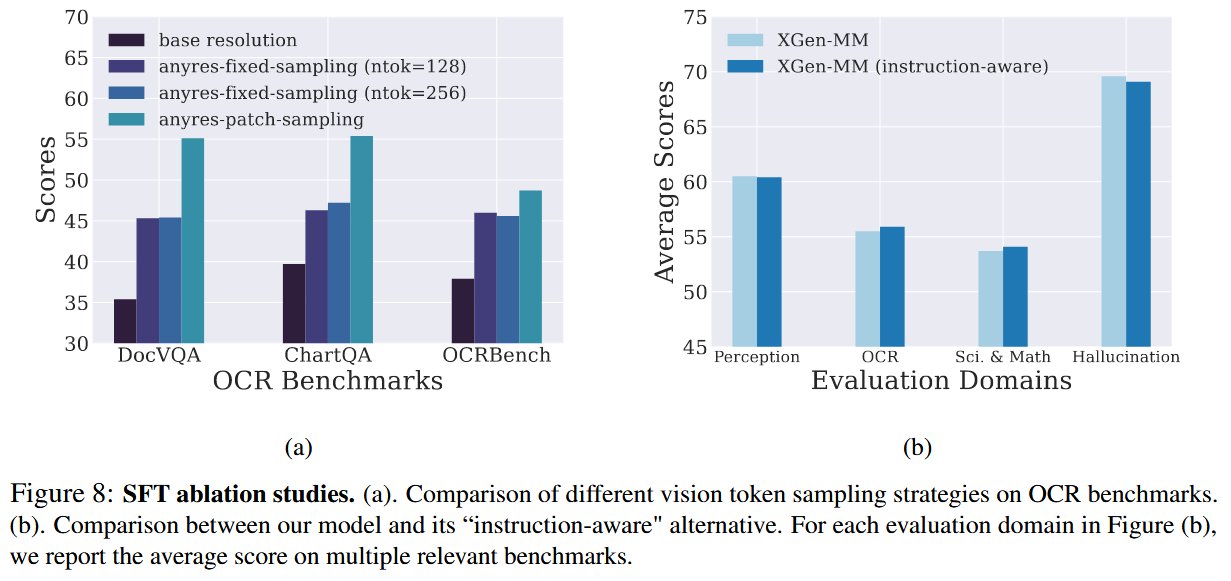
SFT Ablation
总结
我们引入了xGen-MM(BLIP-3),这是一个用于在精心挑选的大型数据集混合体上训练一系列开源大型多模态模型的综合框架。
xGen-MM(BLIP-3)展示了诸如多模态情境学习等新兴能力,并在多模态基准测试中取得了令人印象深刻的成果。
通过开源xGen-MM(BLIP-3)、我们的精选数据集以及我们的SFT微调代码库,我们希望赋予研究社区可访问的多模态基础模型和数据集,使从业者能够进一步探索并提升大型多模态模型(LMMs)的潜力和新兴能力。