
🍎个人主页:小嗷犬的个人主页
🍊个人网站:小嗷犬的技术小站
🥭个人信条:为天地立心,为生民立命,为往圣继绝学,为万世开太平。
基本信息
标题: Improved Baselines with Visual Instruction Tuning
作者: Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee
发表: CVPR 2024
arXiv: https://arxiv.org/abs/2310.03744

摘要
大型多模态模型(LMM)最近在视觉指令调整方面取得了令人鼓舞的进展。
在本文中,我们首次系统地研究了在LLaVA框架下,LMM在受控环境中的设计选择。
我们表明,LLaVA中的全连接视觉-语言连接器出人意料地强大且数据高效。通过简单的LLaVA修改,即使用CLIP-ViT-L-336px进行MLP投影,并添加以学术任务为导向的VQA数据以及带有响应格式提示,我们建立了更强的基线,在11个基准测试中达到了最先进水平。
我们的最终13B检查点仅使用了120万条公开数据,并在单个8-A100节点上完成完整训练仅需大约1天。
此外,我们还对LMM中的开放性问题进行了初步探索,包括扩展到更高分辨率的输入、组合能力以及模型幻觉等。
我们希望这使最先进的LMM研究更加易于获取。
代码和模型将公开提供。
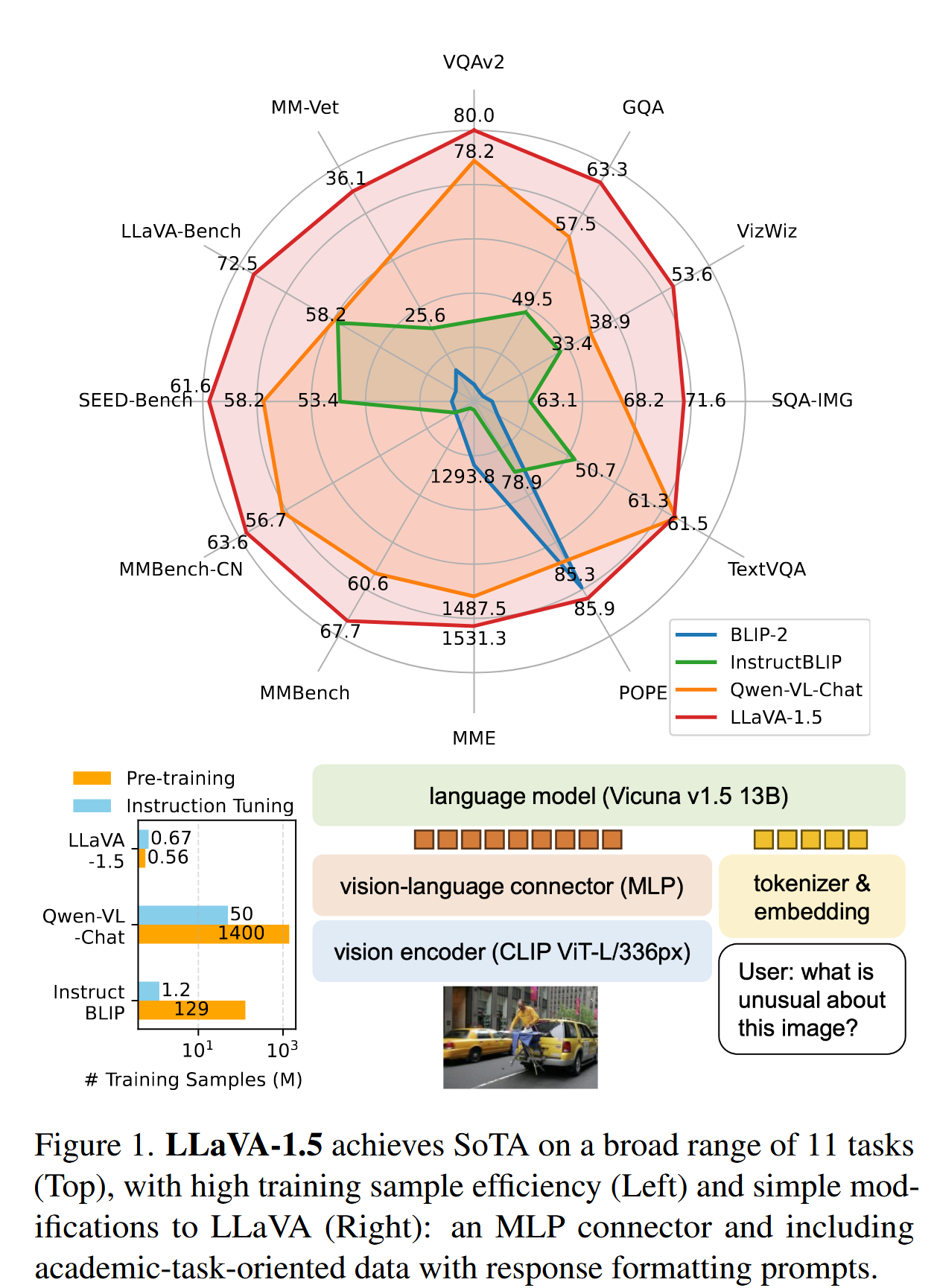
方法
Preliminaries
作为视觉指令调优的开创性工作,LLaVA在视觉推理能力方面表现出色,甚至在各种基准测试中超越了更近期的模型,用于现实生活中的视觉指令跟随任务。
LLaVA使用单个线性层将视觉特征投影到语言空间,并优化整个LLM以进行视觉指令调优。
然而,LLaVA在通常需要简短答案(例如单字)的学术基准测试中表现不足,并且由于训练分布中缺乏此类数据,往往对是/否问题回答“是”。
另一方面,InstructBLIP是第一个将学术任务导向的数据集(如VQA-v2)与LLaVA-Instruct结合起来的先驱,并在VQA基准测试中展现出改进的性能。
它在1.29亿个图像-文本对上预训练了Qformer,并且仅对指令感知的Qformer进行微调以进行视觉指令调整。
然而,最近的研究表明,它在参与现实生活中的视觉对话任务方面并不如LLaVA表现得好。

更具体地说,如表1a所示,它甚至对需要详细回答的请求,也会对VQA训练集中的简短答案过度拟合。
Response Format Prompting
我们发现,对于像InstructBLIP这样的方法,由于无法平衡短形式和长形式VQA,其利用包含自然回答和简短回答的指令遵循数据,主要原因如下。
首先,对回答格式的提示模糊。例如,Q: {Question} A: {Answer}。这样的提示没有明确指出期望的输出格式,甚至对于自然视觉对话,也可能使LLM过度拟合短形式答案。
其次,没有微调LLM。第一个问题因InstructBLIP仅微调Qformer进行指令微调而加剧。它要求Qformer的视觉输出token控制LLM的输出长度为长形式或短形式,如前缀微调所示,但由于与LLaMA等LLM相比,Qformer的能力有限,可能无法正确执行。
因此,为了使LLaVA更好地处理简短答案并解决InstructBLIP的问题,我们提出使用一个单独的响应格式提示,该提示明确指示输出格式。当推广简短答案时,将其附加在VQA问题的末尾:用单个单词或短语回答问题。
我们发现,当LLM使用此类提示微调时,LLaVA能够根据用户的指示正确调整输出格式(见表1b),并且不需要使用ChatGPT对VQA答案进行额外处理,这进一步实现了对各种数据源的扩展。
如表2所示,仅将VQAv2纳入训练,LLaVA在MME上的性能显著提高(1323.8 vs 809.6),并且比InstructBLIP高出111分。
Scaling the Data and Model
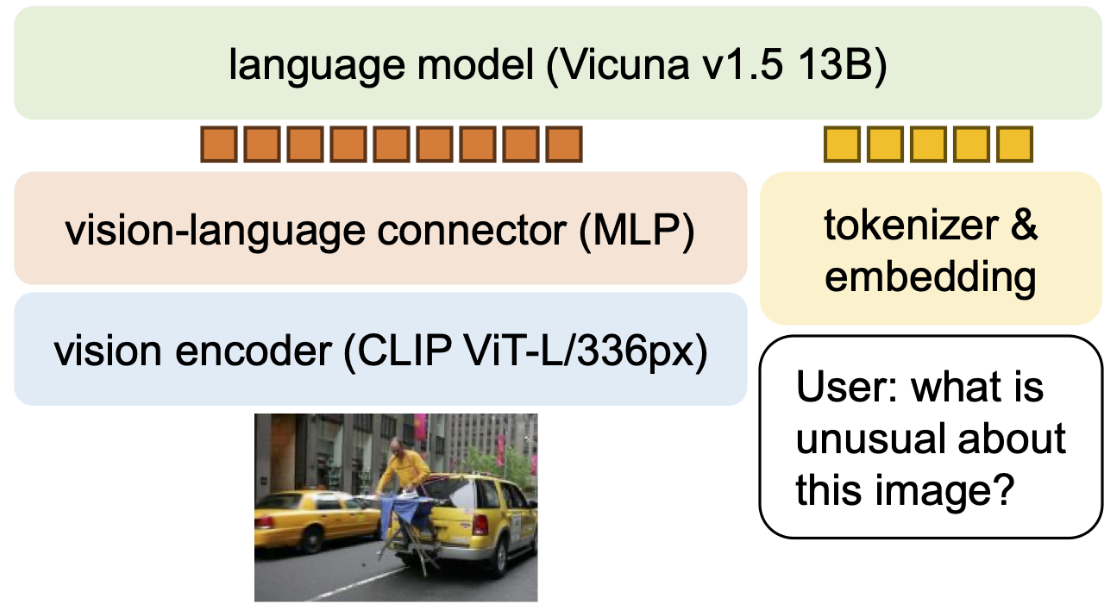
MLP vision-language connector
受改进的自监督学习性能的启发,我们从线性投影改为MLP,发现使用两层MLP提高视觉-语言连接器的表征能力,与原始线性投影相比,可以提升LLaVA的多模态能力。
Academic task oriented data
我们进一步包括额外的学术任务导向VQA数据集,用于VQA、OCR和区域级感知,以多种方式增强模型的能力,如表2所示。
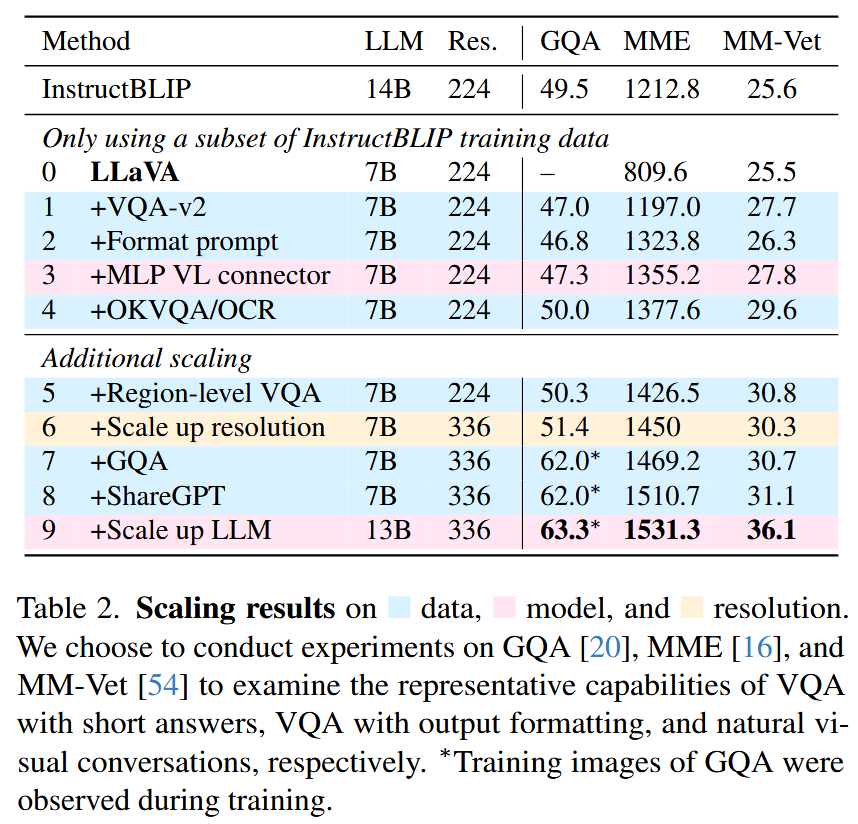
我们首先包括四个额外的数据集,这些数据集在InstructBLIP中使用:open-knowledge VQA(OKVQA,A-OKVQA)和OCR(OCRVQA,TextCaps)。
A-OKVQA被转换为多项选择题,并使用特定的响应格式提示:直接用给定选项的字母回答。
仅使用InstructBLIP使用的数据集的子集,LLaVA已经在表2中的三个任务上超越了它,这表明LLaVA的有效设计。
此外,我们发现进一步添加区域级VQA数据集(Visual Genome,RefCOCO)提高了模型定位精细视觉细节的能力。
Additional scaling
通过将视觉编码器更换为CLIP ViT-L-336px(CLIP可用的最高分辨率),我们进一步将输入图像分辨率提升至 33 6 2 336^2 3362,以便让LLM能够清晰地“看到”图像的细节。
此外,我们添加了GQA数据集作为额外的视觉知识来源。我们还引入了ShareGPT数据,并将LLM扩展至13B。
在MM Vet上的结果表明,当将LLM扩展至13B时,效果提升最为显著,这表明基础LLM在视觉对话方面的能力至关重要。
LLaVA-1.5
我们称经过所有修改的最终模型为LLaVA-1.5(表2的最后两行),它实现了令人印象深刻的性能,显著优于原始的LLaVA。
Computational cost
对于LLaVA-1.5,我们使用相同的预训练数据集,并将训练迭代次数和批量大小与LLaVA大致保持一致,用于指令微调。
由于图像输入分辨率提高到 33 6 2 336^2 3362,LLaVA-1.5的训练时间约为LLaVA的2倍:大约6小时的预训练和大约20小时的视觉指令微调,使用8张A100 GPU。
Scaling to Higher Resolutions
在前文中,我们观察到提高输入图像分辨率可以提升模型的性能。
然而,现有开源CLIP视觉编码器的图像分辨率限制在 33 6 2 336^2 3362,这阻止了我们像在前文中所做的那样,仅通过替换视觉编码器来支持更高分辨率的图像。
在本节中,我们展示了将LMM扩展到更高分辨率的一个早期探索,同时保持LLaVA1.5的数据效率。
当使用ViT作为视觉编码器时,为了提升分辨率,先前的方法大多选择执行位置嵌入插值,并在微调期间将ViT骨干网络适配到新的分辨率。
然而,这通常需要模型在大型图像-文本配对数据集上进行微调,并限制了图像分辨率在推理期间LMM可以接受的固定大小。
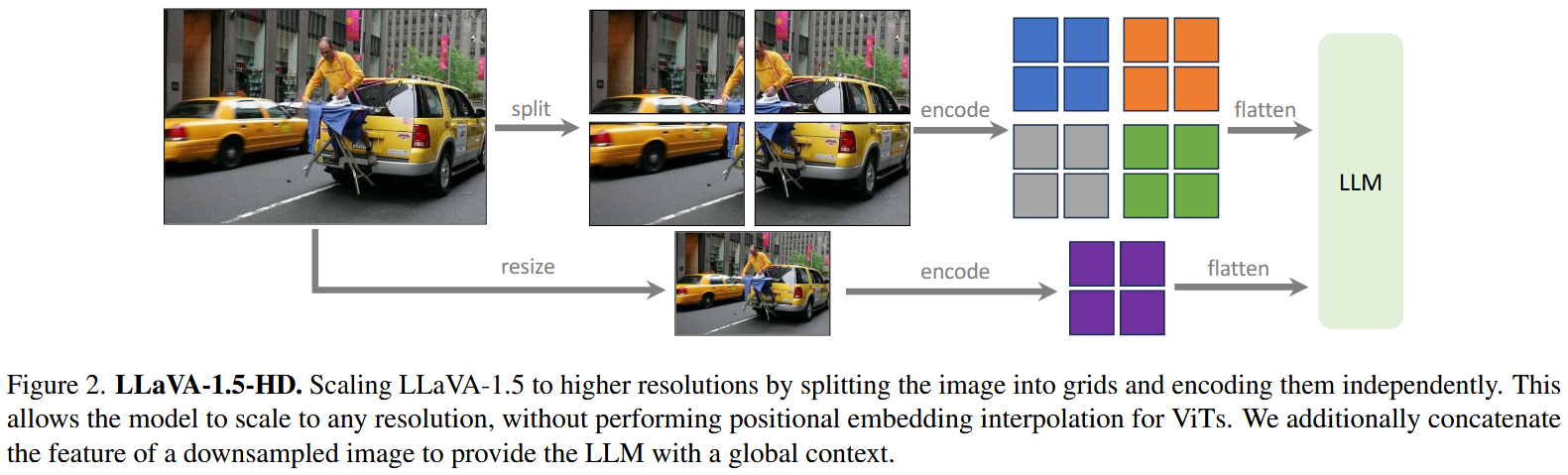
相反,如图2所示,我们通过将图像划分为视觉编码器最初训练的分辨率的小图像块来克服这个问题,并独立地对它们进行编码。
在获得各个图像块的特征图后,我们将它们组合成一个单一的大特征图,其分辨率为目标分辨率,并将其输入到LLM中。
为了向LLM提供全局上下文并减少分割-编码-合并操作的伪影,我们还将下采样图像的特征附加到合并后的特征图上。
这使得我们可以将输入缩放到任意分辨率,并保持LLaVA-1.5的数据效率。
我们将这个结果模型称为LLaVA-1.5-HD。
这个方法现在通常被称为 AnyRes
实验
主实验

![LLaVA-1.5 can extract information from the image and answer following the required format, despite a few errors compared with GPT-4V. GPT-4V results are obtained from [51]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9kaXJlY3QvODA3NmZlZjJiMmRlNDZmN2E2OWU2NTMwZWZkY2FmMGYuanBlZw%3D%3D)
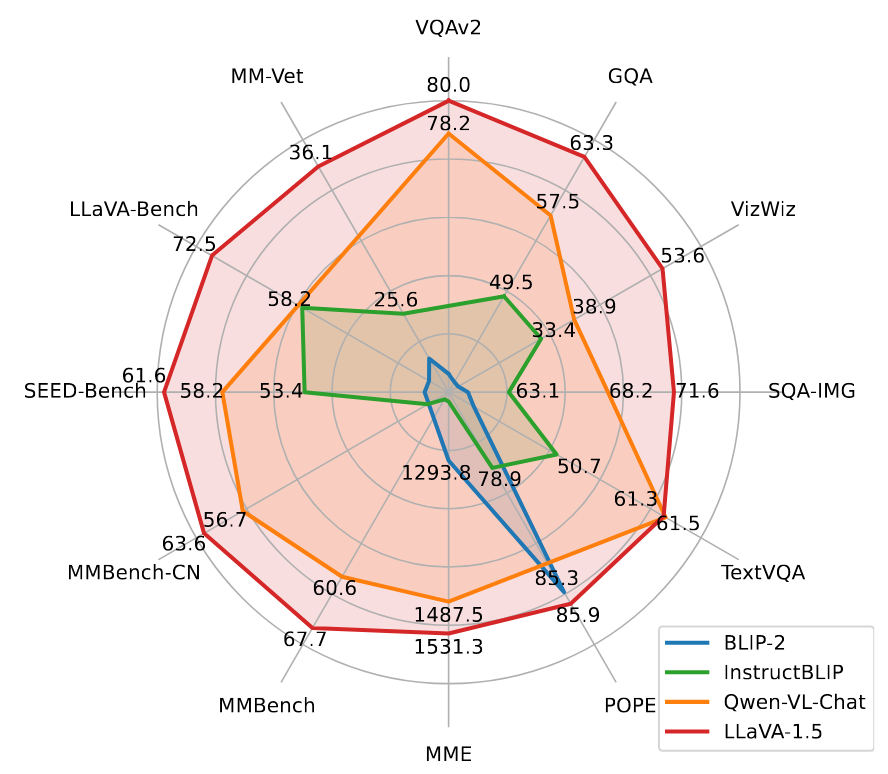
消融实验

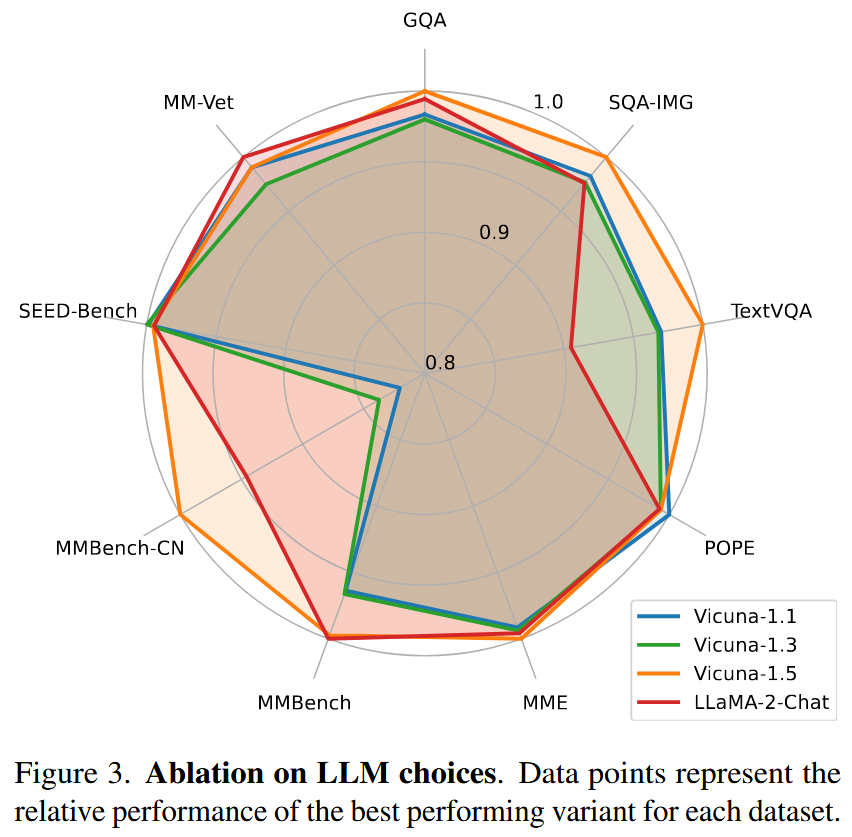
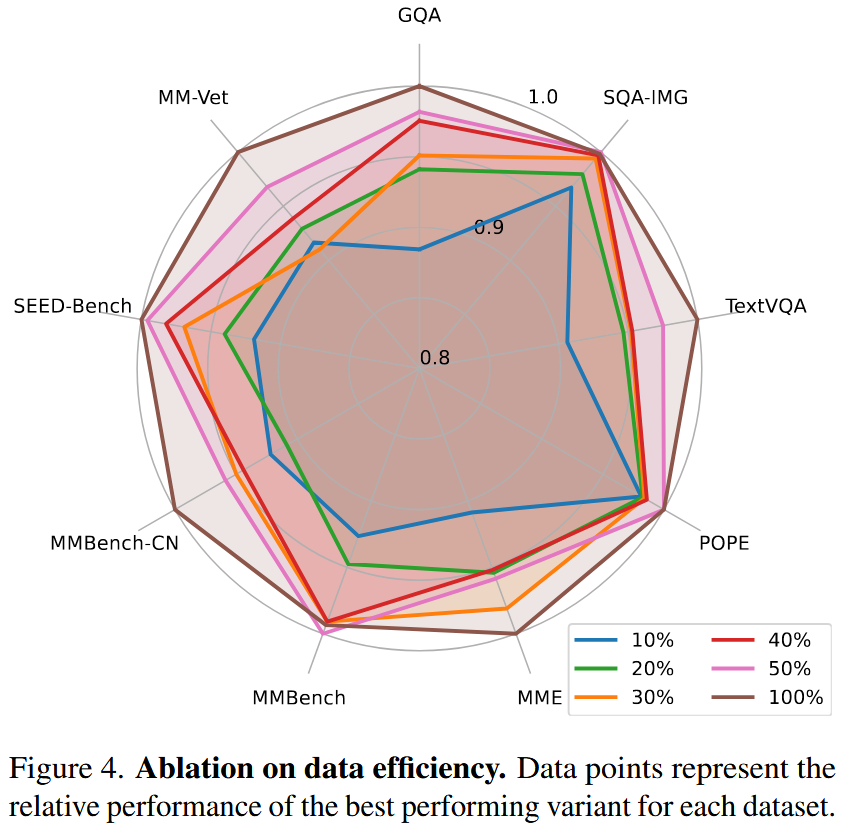
总结
在这篇论文中,我们迈出了揭开大型多模态模型设计神秘面纱的一步,并提出了一种简单、有效且数据高效的基线,即LLaVA-1.5,用于大型多模态模型。
此外,我们探讨了视觉指令微调中的开放性问题,将大规模多模态模型扩展到更高分辨率,并在模型幻觉和LMM的组成能力方面呈现了一些有趣的研究发现。
我们希望这些改进的、易于复制的基线以及新的发现能为开源LMM的未来研究提供参考。
局限性。尽管LLaVA-1.5展示了有希望的结果,但它仍存在局限性,包括对高分辨率图像进行长期训练、缺乏多图像理解、在特定领域的解决问题能力有限。它也无法避免产生幻觉,因此在关键应用(例如医疗)中应谨慎使用。详见附录中的详细讨论。