🌟个人主页:落叶
🌟当前专栏: 深度学习专栏
目录
1. 引言
无监督学习是机器学习中的一类重要任务,聚类算法是其中的一种经典方法。与监督学习相比,无监督学习没有明确的标签,模型仅通过输入数据来发现数据的潜在结构和模式。聚类算法的核心目标是将数据集中的对象根据其特征进行划分,使得同一组中的对象具有高度的相似性,而不同组之间的对象差异较大。
聚类算法的应用非常广泛,包括市场细分、图像识别、异常检测、文档分类等领域。理解聚类算法的原理、应用及其优缺点,对于从事数据科学、机器学习的研究者和工程师非常重要。
2. 聚类算法概述
2.1 聚类算法的定义
聚类是一种无监督学习任务,其目的是将数据集中的样本分成若干个类别,使得每个类别内部的样本尽可能相似,而不同类别之间的样本差异尽可能大。聚类方法一般不依赖于数据的标签信息,而是通过计算样本间的相似性来实现数据的分组。
常见的聚类算法有:K-means聚类、DBSCAN聚类、层次聚类、高斯混合模型(GMM)和K-medoids聚类等。
2.2 聚类的类型
聚类方法可以根据不同的特点进行分类,主要有以下几种类型:
- 硬聚类(Hard Clustering):每个样本只能属于一个聚类,如K-means聚类。
- 软聚类(Soft Clustering):每个样本可以属于多个聚类,且可以为每个聚类分配一个隶属度,如高斯混合模型(GMM)。
- 层次聚类(Hierarchical Clustering):通过逐步合并或分裂簇来生成聚类层次结构。
3. 聚类算法的数学基础
3.1 距离度量
聚类算法依赖于样本间的距离度量来确定相似性。常见的距离度量有:
- 欧几里得距离(Euclidean Distance):是最常用的距离度量,适用于连续型数据。
- 曼哈顿距离(Manhattan Distance):适用于特征空间中的绝对距离计算。
- 余弦相似度(Cosine Similarity):常用于文本数据中,衡量两个向量夹角的余弦值。
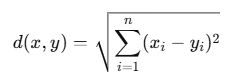
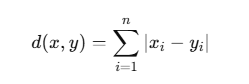
3.2 聚类评估标准
在无监督学习中,由于没有标签信息,我们常常采用内部评估指标来评估聚类结果的质量。常见的评估指标有:
- 轮廓系数(Silhouette Score):衡量每个样本与自己簇内其他样本的相似性和与最近簇的相似性。
- 戴维森堡丁指数(Davies-Bouldin Index):衡量簇内样本的紧密度与簇间分离度。
4. K-means 聚类算法
好的,下面我将继续扩展关于 K-means 聚类 的内容,详细描述其理论、应用以及代码实现。
K-means 聚类的深入分析与扩展
1. K-means 聚类的基本原理
K-means 聚类是基于划分的无监督学习算法,其目的是将数据集划分为 kk 个簇,其中每个簇包含相似的数据点,且簇间的差异较大。K-means 聚类算法的核心思想是通过迭代地分配数据点到最近的簇,并根据簇中数据点的均值更新簇的质心,直到算法收敛。
1.1 算法步骤
K-means 聚类的基本步骤如下:
- 初始化质心:随机选择 kk 个数据点作为初始簇的质心。
- 分配数据点:对于每个数据点,计算其到 kk 个质心的距离,并将其分配到距离最小的簇。
- 更新质心:计算每个簇中所有数据点的均值,更新质心的位置。
- 重复步骤 2 和 3:直到质心不再变化或变化小于某个阈值,或者达到最大迭代次数。
1.2 K-means 算法的目标函数
K-means 聚类的目标函数通常使用 平方误差 来衡量簇内数据点的紧密程度。具体公式为:
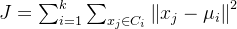
其中:
- J是目标函数,表示总的平方误差;
- k 是簇的个数;
是第 ii 个簇;
是第 ii 个簇中的数据点;
是第 ii 个簇的质心。
通过最小化目标函数 JJ,K-means 聚类算法使得每个簇内的数据点尽量紧凑,簇与簇之间尽量分离。
2. K-means 聚类的优缺点
2.1 优点
- 效率高:K-means 聚类算法的时间复杂度是 O(nk)O(nk),适用于大规模数据集。
- 简单易懂:K-means 是一种直观的聚类算法,易于理解和实现。
- 可扩展性:能够在大数据集上应用,通过迭代优化可以加速计算。
2.2 缺点
- 初始点敏感性:K-means 聚类算法对初始质心的选择非常敏感,可能会导致局部最优解。
- 簇形状限制:K-means 假设簇是球形的,因此对于非球形的簇效果较差。
- 簇数预设:K-means 算法需要事先指定簇的数量 kk,但在实际应用中很难提前知道。
3. K-means 聚类的优化方法
3.1 K-means++初始化
为了避免K-means算法对初始点敏感性的问题,K-means++ 方法提出了一种改进的初始化方式。K-means++ 方法通过选择初始质心,使得每个质心尽量远离现有的质心,从而减少算法陷入局部最优解的风险。
K-means++ 的初始化步骤:
- 随机选择第一个质心;
- 对于每个数据点
,计算其到最近已选择质心的距离 D(xi)D(x_i);
- 以概率
选择下一个质心,即离当前质心最远的点有更大的概率被选为下一个质心;
- 重复步骤 2 和 3,直到选定 kk 个质心。
3.2 Mini-batch K-means
对于大规模数据集,标准的 K-means 聚类算法可能会遇到内存和计算瓶颈。Mini-batch K-means 是一种变种,它使用小批量(mini-batch)数据来更新质心,而不是使用整个数据集进行计算。这样可以大大提高算法的计算效率,并能处理大规模数据集。
在每次迭代中,Mini-batch K-means 从数据集中随机选择一个小批量的样本,计算这些样本的质心,并通过这些样本来更新质心的位置。Mini-batch K-means 能够以较低的计算成本获得较好的聚类结果。
3.3 多次运行
由于 K-means 聚类算法容易陷入局部最优解,因此在实际应用中,通常会运行多次算法,每次随机初始化质心,最后选择损失函数最小的结果。
4. K-means 聚类的应用
K-means 聚类算法广泛应用于各个领域,以下是一些常见的应用场景:
4.1 图像分割
在计算机视觉领域,K-means 聚类可以用于图像分割。图像分割的目标是将图像划分为若干个区域,使得同一区域的像素具有相似的颜色或特征。通过将图像像素视为数据点,并使用 K-means 聚类算法,可以有效地实现图像分割。
4.2 客户分群
在市场营销中,K-means 聚类可以帮助企业根据客户的消费行为、年龄、收入等特征进行分群,从而进行精准营销。K-means 聚类能够将客户分为不同的群体,以便为每个群体定制不同的产品和服务。
4.3 文本聚类
K-means 聚类也被广泛应用于文本分析中。通过将文本表示为向量(如使用TF-IDF或Word2Vec),可以将相似的文本聚类在一起。文本聚类在文档分类、新闻推荐、舆情分析等领域有广泛的应用。
4.4 异常检测
在异常检测领域,K-means 聚类可以用于识别数据集中的异常点(outlier)。如果某个数据点远离所有簇的质心,它可能是一个异常点。通过聚类分析,能够自动识别这些异常数据。
5. K-means 聚类的代码实现
接下来,我们通过一个具体的示例来实现 K-means 聚类算法。假设我们有一个简单的二维数据集,并使用 Python 代码实现 K-means 聚类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
# K-means 聚类实现
class KMeans:
def __init__(self, n_clusters=3, max_iter=300, tol=1e-4):
self.n_clusters = n_clusters
self.max_iter = max_iter
self.tol = tol
self.centroids = None
def fit(self, X):
# 随机初始化质心
np.random.seed(42)
self.centroids = X[np.random.choice(X.shape[0], self.n_clusters, replace=False)]
for _ in range(self.max_iter):
# 步骤1: 为每个点分配最近的簇
distances = np.linalg.norm(X[:, np.newaxis] - self.centroids, axis=2)
labels = np.argmin(distances, axis=1)
# 步骤2: 更新质心
new_centroids = np.array([X[labels == i].mean(axis=0) for i in range(self.n_clusters)])
# 判断是否收敛
if np.linalg.norm(new_centroids - self.centroids) < self.tol:
break
self.centroids = new_centroids
return labels
# 生成数据
X, _ = make_blobs(n_samples=300, centers=3, random_state=42)
X = StandardScaler().fit_transform(X)
# 使用KMeans算法进行聚类
kmeans = KMeans(n_clusters=3)
labels = kmeans.fit(X)
# 可视化聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis')
plt.scatter(kmeans.centroids[:, 0], kmeans.centroids[:, 1], s=300, c='red', marker='x')
plt.title('K-means Clustering')
plt.show()
6. 结论与展望
K-means 聚类作为一种经典的聚类算法,在许多领域得到了广泛应用。它的优点包括简单、快速和高效,但也存在一些不足,如对初始质心敏感和无法处理非球形簇。通过改进初始化方法(如 K-means++)、使用 Mini-batch K-me。