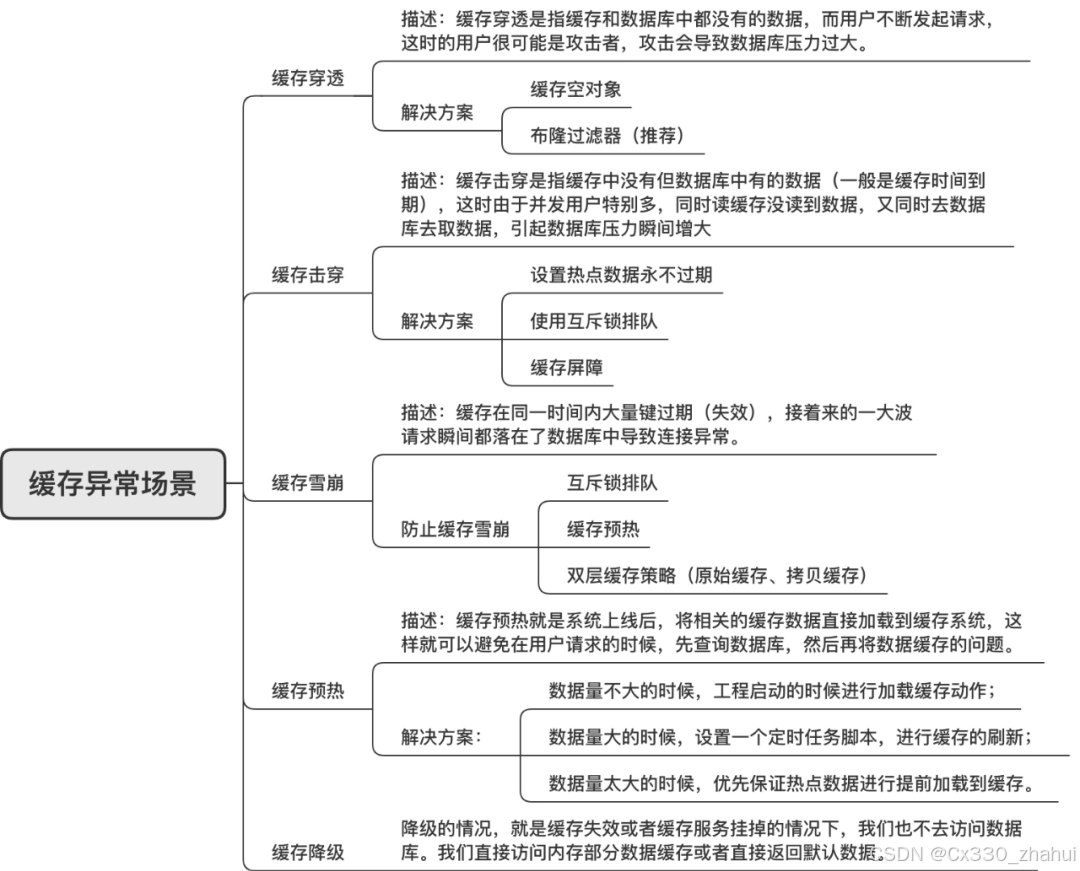
redis笔记
mysql 关系型数据 sql语句
redis 非关系型数据库 kv键值对存储的
1. Redis 简介
在这个部分,我们将学习以下3个部分的内容,分别是:
◆ Redis 简介(NoSQL概念、Redis概念)
◆ Redis 的下载与安装(win linux)
◆ Redis 的基本操作(重点)
◆ java 操作 redis
进阶:集群、哨兵、数据备份、内存穿透问题、击穿问题、热部署问题、数据双删、持久化等
1.1 NoSQL概念
性能和并发
1.1.1 问题现象
在讲解NoSQL的概念之前呢,我们先来看一个现象:
(1)问题现象
- 12306春运买票,刷不到票。
- 11.11淘宝崩盘,访问不了。
- 京东卖书活动,崩盘。刘强东:“再来一次”。在这里插入图片描述

(2)现象特征
再来看这几个现象,有两个非常相似的特征:
- 用户比较多,海量用户
- 高并发
这两个现象出现以后,对应的就会造成我们的服务器瘫痪。核心本质是什么呢?其实并不是我们的应用服务器,而是我们的关系型数据库 IO。关系型数据库才是最终的罪魁祸首!
(3)造成系统崩掉原因
1.性能瓶颈:磁盘IO性能低下
关系型数据库存取数据的时候和读取数据的时候他要走磁盘IO。磁盘这个性能本身是比较低的。
连续读取:
L1CACHE大概是1700GB/s的水平
L3CACHE 大概是200GB/s的水平
DDR4内存大概是60GB/s的水平
nvme ssd大概是2000MB/s的水平
SATA ssd大概是450MB/s的水平
机械硬盘大概是100~150MB/s的水平寻址时间:
DDR4内存寻址时间:6ns左右(1ms=1000000ns)
机械硬盘寻址时间:1/7200 ≈0.14ms
总结:内存与机械硬盘 差 4 个数量级左右。
2.扩展瓶颈:数据关系复杂,扩展性差,不便于大规模集群
所谓关系复杂:一张表,通过它的外键关联了七八张表,这七八张表又通过她的外件,每张又关联了四五张表。想一想好不好写查询 语句,查询效率又在哪?
(4)解决思路
面对这样的现象,我们要想解决怎么版呢。两方面:
一,降低磁盘IO次数,越低越好。
二,去除数据间关系,越简单越好。
》》内存存储、断开关系、只存数据。
把这两个特征一合并一起,就出来了一个新的概念:NoSQL(不仅仅是SQL)
1.1.2 NoSQL的概念
(1)概念
NoSQL:即 Not-Only SQL( 泛指非关系型的数据库),作为关系型数据库的补充。不仅仅是sql
作用:应对基于海量用户和海量数据前提下的数据处理问题。
他说这句话说的非常客气,这个意思就是说我们存储数据,可以不光使用SQL,我们还可以使用非SQL的这种存储方案,这就是所谓的NoSQL。
(2)特征
- **可扩容,可伸缩。**SQL数据关系过于复杂,你扩容一下难度很高,那我们Nosql 这种的,不存关系,所以它的扩容就简单一些。
- **大数据量下高性能。**包数据非常多的时候,它的性能高,因为你不走磁盘IO,你走的是内存,性能肯定要比磁盘IO的性能快一些。
- **灵活的数据模型、高可用。**他设计了自己的一些数据存储格式,这样能保证效率上来说是比较高的,最后一个高可用,我们等到集群内部分再去它!
*(3)常见 Nosql 数据库
目前市面上常见的Nosql产品:Redis、memcache、HBase、MongoDB、es
(4)应用场景-电商为例
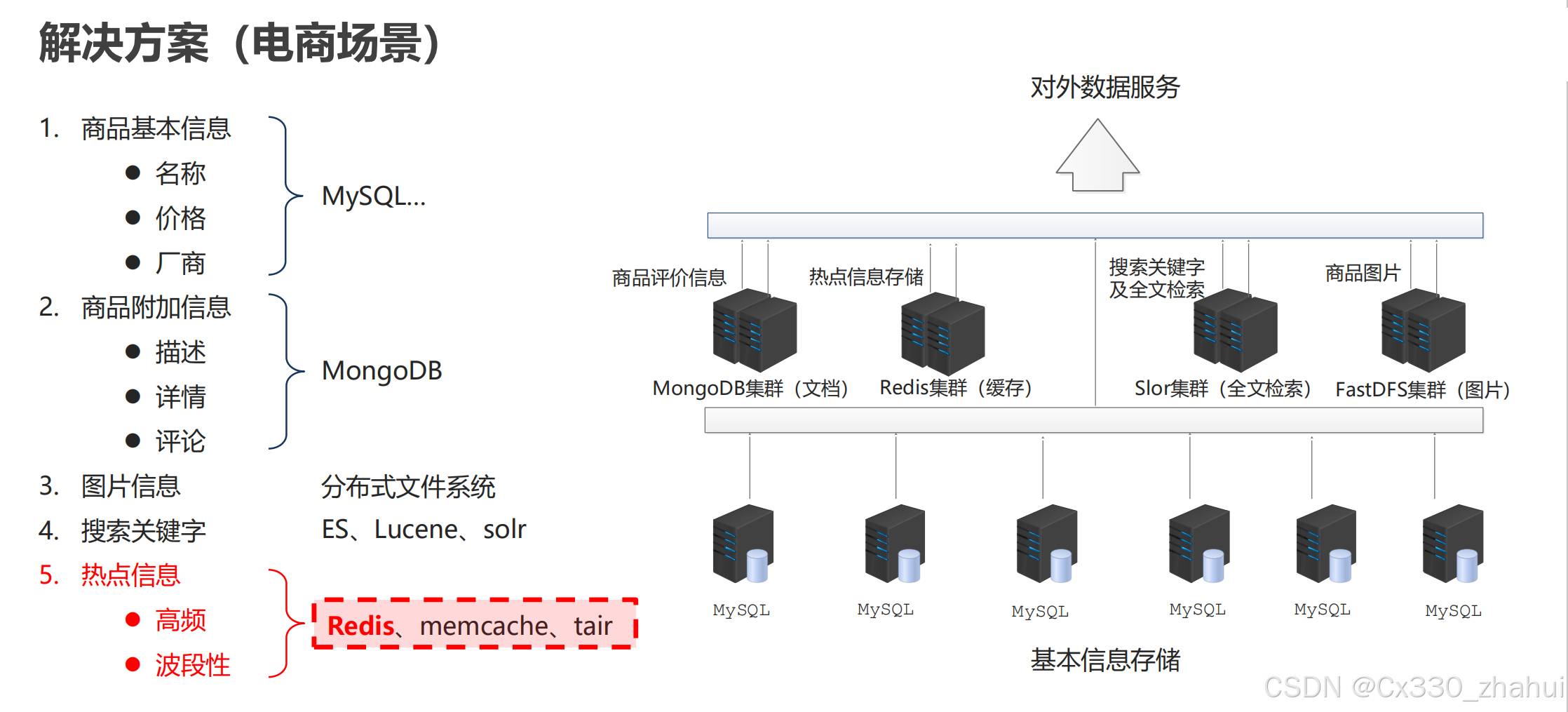
我们以电商为例,来看一看他在这里边起到的作用。
第一类,在电商中我们的基础数据一定要存储起来,比如说商品名称,价格,生产厂商,这些都属于基础数据,这些数据放在MySQL数据库。
第二类,我们商品的附加信息,比如说,你买了一个商品评价了一下,这个评价它不属于商品本身。就像你买一个苹果,“这个苹果很好吃”就是评论,但是你能说很好吃是这个商品的属性嘛?不能这么说,那只是一个人对他的评论而已。这一类数据呢,我们放在另外一个地方,我们放到MongoDB。它也可以用来加快我们的访问,他属于NoSQL的一种。
第三,图片内的信息。注意这种信息相对来说比较固定,他有专用的存储区,我们一般用文件系统来存储。至于是不是分布式,要看你的系统的一个整个 瓶颈 了?如果说你发现你需要做分布式,那就做,不需要的话,一台主机就搞定了。
第四,搜索关键字。为了加快搜索,我们会用到一些技术,有些人可能了解过,像分ES、Lucene、solr都属于搜索技术。那说的这么热闹,我们的电商解决方案中还没出现我们的redis啊!注意第五类信息。
第五,热点信息。访问频度比较高的信息,这种东西的第二特征就是它具有波段性。换句话说他不是稳定的,它具有一个时效性的。那么这类信息放哪儿了,放到我们的redis这个解决方案中来进行存储。
具体的我们从我们的整个数据存储结构的设计上来看一下。
总结:
Nosql:不仅仅是sql.====高并发、高可用

1.2 Redis概念
1.2.1 redis 概念
概念:Redis (REmote DIctionary Server) 是用 C 语言开发的一个开源的高性能 单线程的 键值对(key-value)数据库。
*特征:
-
数据间没有必然的关联关系;
-
内部采用单线程机制进行工作;(重点)
-
高性能。官方提供测试数据,50个并发执行100000 个请求,读的速度是110000 次/s,写的速度是81000次/s。
-
多数据类型支持
- *字符串类型,string
- *列表类型, list
- *散列类型,hash
- *集合类型 set
- 有序集合类型zset/sorted_set(了解)
(5)支持持久化,可以进行数据灾难恢复(aof rdb)
1.2.2 redis的应用场景(重中之重)
高并发:波段性、高频
(1)为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。
(2)即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等。
(3)时效性信息控制。如验证码控制、投票控制等。
(4)分布式数据共享。如分布式集群架构中的 session 分离消息队列.(不常用) MQ
- 秒杀业务

- 热点信息

- 定时消息
- 排行榜信息
1.3 Redis 的下载与安装
《redis安装》
1.4 Redis 的启动服务和客户端访问
配置redis启动的环境变量
1.复制redis路径 在环境变量中path中进行配置。。
方式一:exe文件启动(了解)(小白玩法)
方式二:配置文件启动(架构师玩法)
-
1.服务启动
-
写一个redis-6379.conf配置文件
#ip bind 127.0.0.1 #端口号 port 6379 -
cmd: redis-server redis-6379.conf
-
-
2.进入redis操作的客户端
- cmd: redis-cli
redis-server启动三种方式!!(服务端)
#通过配置文件启动 先修改conf配置文件中的端口路径 (首先进入配置文件夹下)常用!!!!
redis-server 配置文件路径
案例:D:\Redis-x64-5.0.10> redis-server redis-6379.conf
#服务启动(了解,几乎不用) 默认6379
redis-server
#切换端口号启动(运维使用,几乎不用) 6380
redis-server --port 6380
redis-cli启动多方式!!(客户端)
#客户端连接 默认: localhost 6379
redis-cli
#切换端口号连接 6380
redis-cli -p 6380
#指定ip 端口号 访问
redis-cli -h 127.0.0.1 -p 6378
#指定密码访问ip 端口号 密码
redis-cli -h 127.0.0.1 -p 6378 -a gaohe
配置文件参考:
#外部访IP-网卡IP
bind 127.0.0.1
#端口号
port 6379
#密码(没有要求测试阶段不要开启)
requirepass gaohe
2. Redis数据类型
2.1 介绍
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
- 字符串 string(最重点)
- 哈希 hash(掌握)
- 列表 list(掌握)
- 集合 set(掌握)
- 有序集合 sorted set / zset(了解)
2.2 Redis 5种常用数据类型
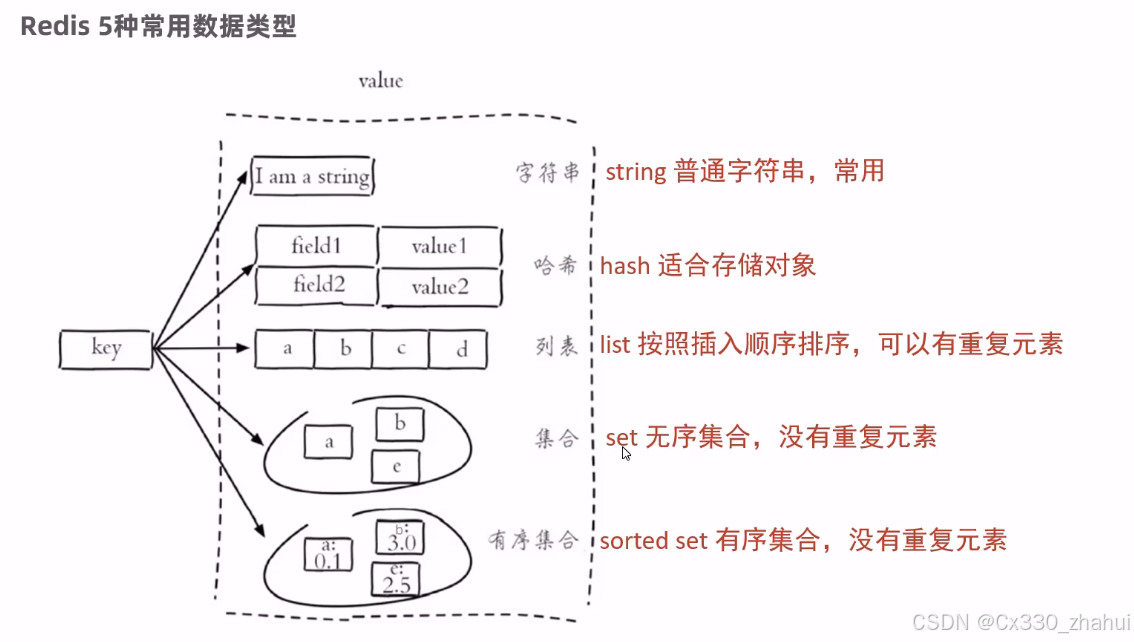
解释说明:
字符串(string):普通字符串,常用
哈希(hash):适合存储对象
列表(list):按照插入顺序排序,可以有重复元素
集合(set):无序集合,没有重复元素
有序集合(sorted set / zset):集合中每个元素关联一个分数(score),根据分数升序排序,没有重复元素
更多命令可以参考Redis中文网:https://www.redis.net.cn
3. Redis常用命令
3.1 字符串string操作命令
Redis 中字符串类型常用命令:
-
SET key value 设置指定key的值(重点)
-
GET key 获取指定key的值(重点)
-
SETEX key seconds value 设置指定key的值,并将 key 的过期时间设为 seconds 秒(重点)
-
SETNX key value 只有在 key 不存在时设置 key 的值
应用场景
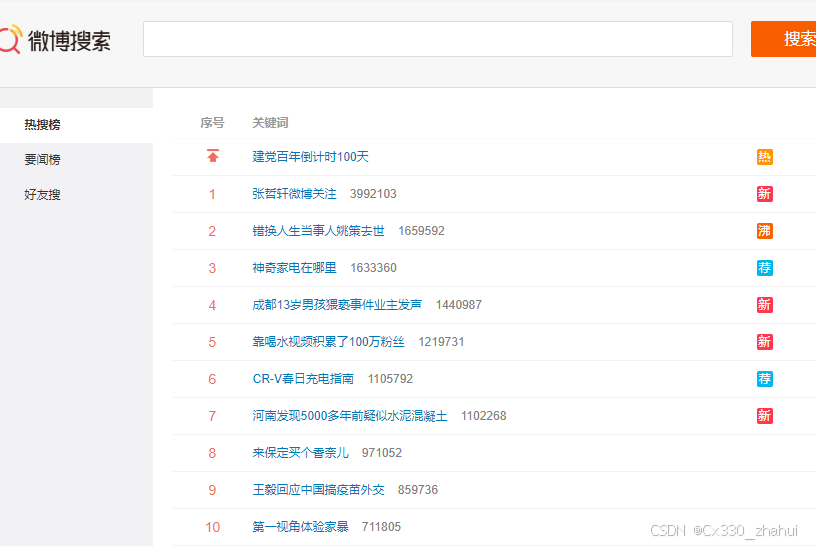
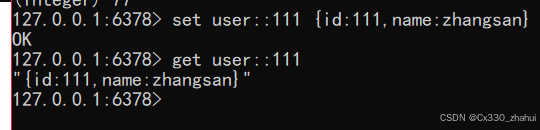
它的应用场景在于:主页高频访问信息显示控制,例如新浪微博大V主页显示粉丝数与微博数量。json
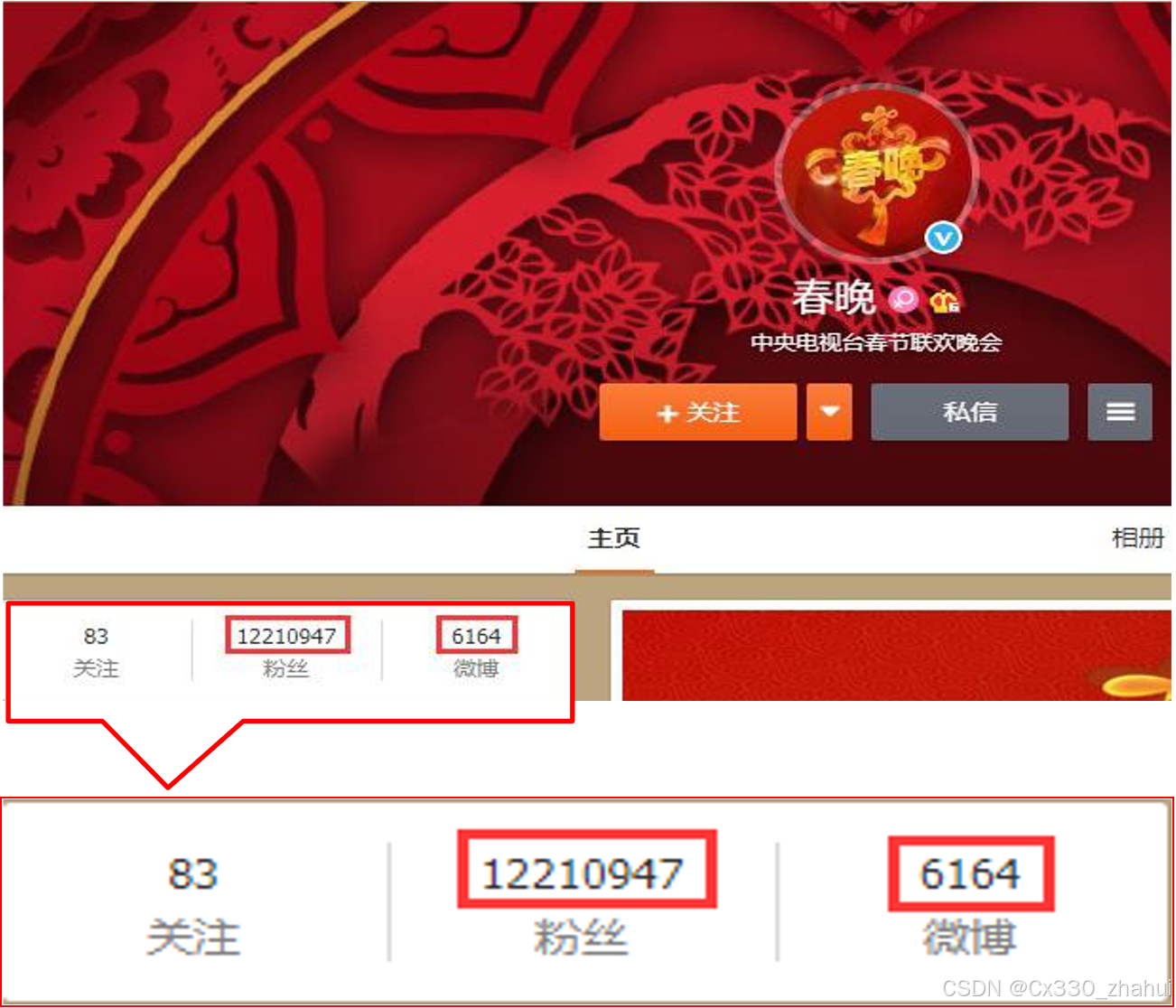
我们来思考一下:这些信息是不是你进入大V的页面儿以后就要读取这写信息的啊,那这种信息一定要存储到我们的redis中,因为他的访问量太高了!那这种数据应该怎么存呢?我们来一块儿看一下方案!
热点广告信息JSON
排行榜json
更多命令可以参考Redis中文网:https://www.redis.net.cn
练习1:
验证码定时过期案例!!
ttl
用户信息缓存
练习2:秒杀业务 减 操作
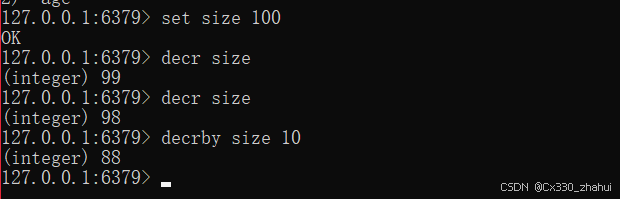
decr key 数量自减
decrby key increment 数量减少指定数量
练习3:json存储
3.2 哈希hash操作命令
Redis hash 是一个string类型的 field 和 value 的映射表,hash特别适合用于存储对象,常用命令:
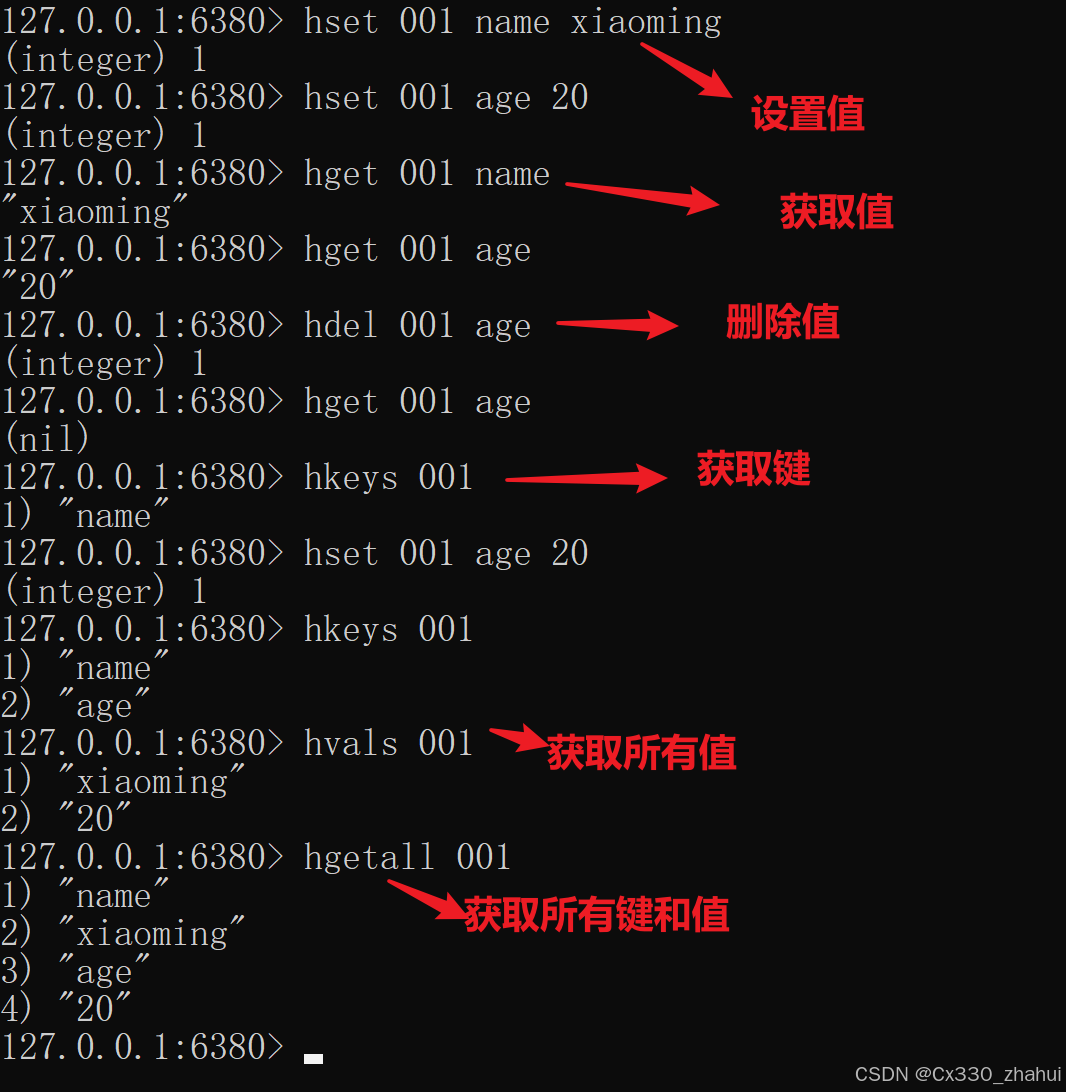
- HSET key field value 将哈希表 key 中的字段 field 的值设为 value
- HGET key field 获取存储在哈希表中指定字段的值
- HDEL key field 删除存储在哈希表中的指定字段
- HKEYS key 获取哈希表中所有字段
- HVALS key 获取哈希表中所有值
- HGETALL key 获取在哈希表中指定 key 的所有字段和值
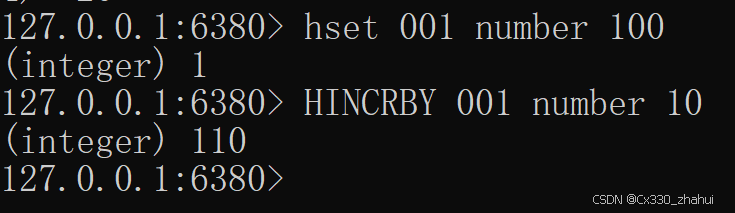
- hincrby key field increment 数量增加指定值(负数就是减)

String和hash
- 一个商品信息,用户总是查看,但是不修改用哪个(给了推广费的商品)?json-字符串
- 秒杀时候的商品数量(一个值)?string
- 买不同品种的卡(30 50 100)?hash
- 一个大V的各种热点信息(粉丝数、点击量、关注度等都是实时变化的)?hash
练习1:
练习2:
hincrby key field increment
案例: hincrby val c1 -2
练习3
双11活动日,销售手机充值卡的商家对移动、联通、电信的30元、50元、100元商品推出抢购活动,每种商品抢购上限1000 张。

也就是商家有了,商品有了,数量有了。最终我们的用户买东西就是在改变这个数量。那你说这个结构应该怎么存呢?对应的商家的ID作为key,然后这些充值卡的ID作为field,最后这些数量作为value。而我们所谓的操作是其实就是hincrby这个操作,只不过你传负值就行了。看一看对应的解决方案:
案例演示:
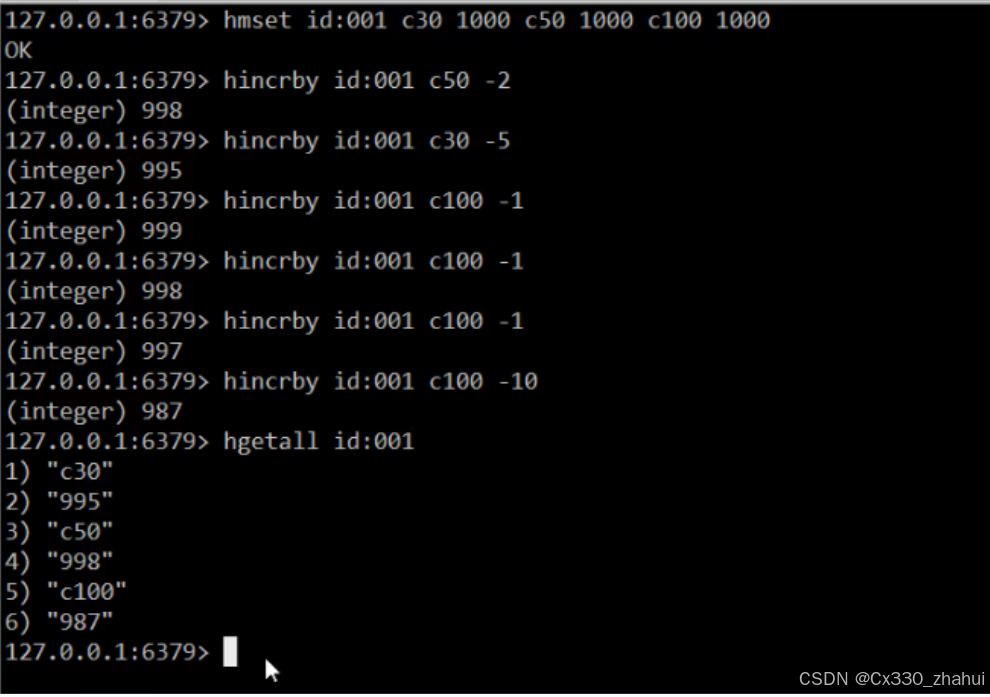
解决方案
以商家id作为key
将参与抢购的商品id作为field
将参与抢购的商品数量作为对应的value
抢购时使用降值的方式控制产品数量
注意:实际业务中还有超卖等实际问题,这里不做讨论
3.3 列表list操作命令
应用场景: 1. 分页查询 2. 排行榜信息 3. 成绩单
- 队列
Redis 列表是简单的字符串列表,按照插入顺序排序,常用命令:
- LPUSH key value1 [value2] 将一个或多个值插入到列表头部
- LRANGE key start stop 获取列表指定范围内的元素
- RPOP key 移除并获取列表最后一个元素
- LLEN key 获取列表长度
- BRPOP key1 [key2 ] timeout 移出并获取列表的最后一个元素, 如果列表没有元素会阻塞列表直到等待超时或发现可弹出元素为止
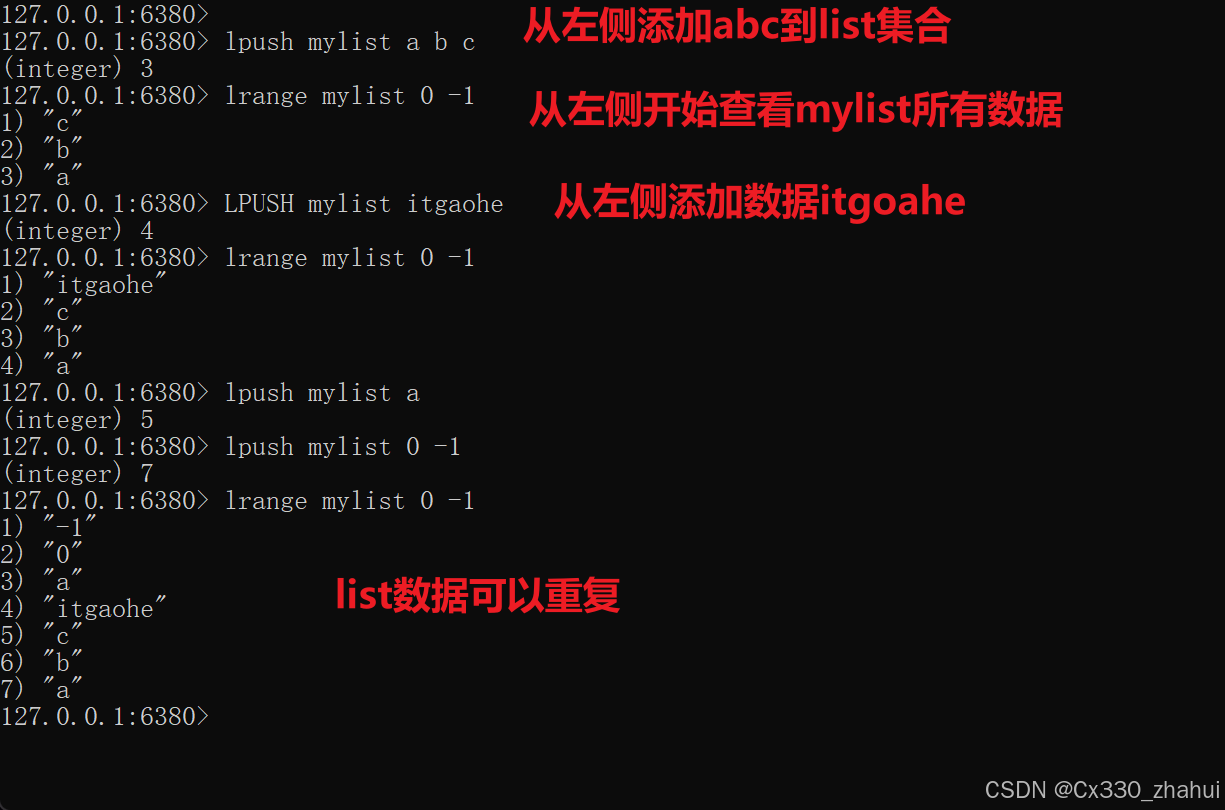
应用场景:
- 分页查询
- 排行榜信息
- 成绩单
练习1:


3.4 集合set操作命令
特点: 无序 不重复
应用场景: 黑白名单、电话薄、排行榜
Redis set 是string类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据,常用命令:
- SADD key member1 [member2] 向集合添加一个或多个成员
- SMEMBERS key 返回集合中的所有成员
- SCARD key 获取集合的成员数
- SINTER key1 [key2] 返回给定所有集合的交集
- SUNION key1 [key2] 返回所有给定集合的并集
- SDIFF key1 [key2] 返回给定所有集合的差集
- SREM key member1 [member2] 移除集合中一个或多个成员
应用场景:
1. 黑白名单:防火墙机制
2. 队列:
3. 不可重复队列
练习1:

**练习2:**交并差(了解即可)
- SINTER key1 [key2] 返回给定所有集合的交集
- SUNION key1 [key2] 返回所有给定集合的并集
- SDIFF key1 [key2] 返回给定所有集合的差集
3.5 有序集合sorted set操作命令
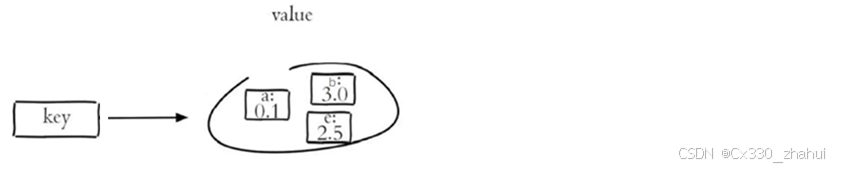
Redis sorted set 有序集合是 string 类型元素的集合,且不允许重复的成员。每个元素都会关联一个double类型的分数(score) 。redis正是通过分数来为集合中的成员进行从小到大排序。有序集合的成员是唯一的,但分数却可以重复。
常用命令:
- ZADD key score1 member1 [score2 member2] 向有序集合添加一个或多个成员,或者更新已存在成员的 分数
- ZRANGE key start stop [WITHSCORES] 通过索引区间返回有序集合中指定区间内的成员
- ZINCRBY key increment member 有序集合中对指定成员的分数加上增量 increment
- ZREM key member [member …] 移除有序集合中的一个或多个成员
应用场景:
- 小时排行榜
- 延迟加载
练习1:

3.6 通用命令
Redis中的通用命令,主要是针对key进行操作的相关命令:
- KEYS pattern 查找所有符合给定模式( pattern)的 key
- EXISTS key 检查给定 key 是否存在
- TYPE key 返回 key 所储存的值的类型
- TTL key 返回给定 key 的剩余生存时间(TTL, time to live),以秒为单位
- DEL key 该命令用于在 key 存在是删除 key
- select 15 切换数据库到15;0-15(一共16个,默认为0)
练习1:


4. 在Java中操作Redis
4.1 介绍
前面我们讲解了Redis的常用命令,这些命令是我们操作Redis的基础,那么我们在java程序中应该如何操作Redis呢?这就需要使用Redis的Java客户端,就如同我们使用JDBC操作MySQL数据库一样。
Redis 的 Java 客户端很多,官方推荐的有三种:
- Jedis
- Lettuce
- Redisson
Spring 对 Redis 客户端进行了整合,提供了 Spring Data Redis,在Spring Boot项目中还提供了对应的Starter,即 spring-boot-starter-data-redis。
4.2 Jedis
Jedis 是 Redis 的 Java 版本的客户端实现。
maven坐标:
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.0</version>
</dependency>
使用 Jedis 操作 Redis 的步骤:
- 获取连接
- 执行操作
- 关闭连接
示例代码:
package com.gaohe.test;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import java.util.Set;
/**
* 使用Jedis操作Redis
*/
public class JedisTest {
@Test
public void testRedis(){
//1 获取连接
Jedis jedis = new Jedis("localhost",6379);
//2 执行具体的操作
jedis.set("username","xiaoming");
String value = jedis.get("username");
System.out.println(value);
//jedis.del("username");
jedis.hset("myhash","addr","bj");
String hValue = jedis.hget("myhash", "addr");
System.out.println(hValue);
Set<String> keys = jedis.keys("*");
for (String key : keys) {
System.out.println(key);
}
//3 关闭连接
jedis.close();
}
}
4.3 Spring Data Redis
4.3.1 介绍
Spring Data Redis 是 Spring 的一部分,提供了在 Spring 应用中通过简单的配置就可以访问 Redis 服务,对 Redis 底层开发包进行了高度封装。在 Spring 项目中,可以使用Spring Data Redis来简化 Redis 操作。
网址:https://spring.io/projects/spring-data-redis
maven坐标:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>2.4.8</version>
</dependency>
Spring Boot提供了对应的Starter,maven坐标:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
Spring Data Redis中提供了一个高度封装的类:RedisTemplate,针对 Jedis 客户端中大量api进行了归类封装,将同一类型操作封装为operation接口,具体分类如下:
- ValueOperations:简单K-V操作
- SetOperations:set类型数据操作
- ZSetOperations:zset类型数据操作
- HashOperations:针对hash类型的数据操作
- ListOperations:针对list类型的数据操作
4.3.2 使用方式
4.3.2.1 环境搭建
第一步:创建maven项目springdataredis_demo,配置pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<artifactId>spring-boot-starter-parent</artifactId>
<groupId>org.springframework.boot</groupId>
<version>2.7.0</version>
</parent>
<groupId>com.gaohe</groupId>
<artifactId>springdataredis_demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.springframework.boot</groupId>-->
<!-- <artifactId>spring-boot-starter-jdbc</artifactId>-->
<!-- <exclusions>-->
<!-- <exclusion>-->
<!-- <groupId>com.zaxxer</groupId>-->
<!-- <artifactId>HikariCP</artifactId>-->
<!-- </exclusion>-->
<!-- </exclusions>-->
<!-- </dependency>-->
</dependencies>
</project>
第二步:编写启动类
package com.gaohe;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
//@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class,args);
}
}
第三步:配置application.yml
spring:
# redis配置
redis:
# 数据库索引
database: 0
# 服务器地址
host: localhost
# 服务器连接端口
port: 6380
# 数据库密码
# password: 123456
# 连接超时时间
timeout: 10000ms
# jedis配置
jedis:
pool:
# 连接池最大连接数(负数表示没有限制)
max-active: -1
# 连接池最大阻塞等待时间(负数表示没有限制)
max-wait: -1ms
# 连接池最大空闲链接数
max-idle: 10
# 连接池最小空闲数
min-idle: 0
解释说明:
spring.redis.database:指定使用Redis的哪个数据库,Redis服务启动后默认有16个数据库,编号分别是从0到15。
可以通过修改Redis配置文件来指定数据库的数量。
第四步:提供配置类
package com.gaohe.config;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.StringRedisSerializer;
/**
* Redis配置类
*/
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
/*2.4.5版本 不会爆红 2.7版本爆红 但是不会影响使用*/
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
//对value值的序列化 但是一般不要设置 会对以后开发中数据的兼容性产生影响
redisTemplate.setValueSerializer(new StringRedisSerializer());
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
解释说明:
当前配置类不是必须的,因为 Spring Boot 框架会自动装配 RedisTemplate 对象,但是默认的key序列化器为JdkSerializationRedisSerializer,导致我们存到Redis中后的数据和原始数据有差别
key值的问题 value值不需要管
第五步:提供测试类
package com.gaohe.test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
@SpringBootTest
@RunWith(SpringRunner.class)
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
}
4.3.2.2 操作字符串类型数据
/**
* 操作String类型数据
*/
@Test
public void testString(){
//存值
redisTemplate.opsForValue().set("city123","beijing");
//取值
String value = (String) redisTemplate.opsForValue().get("city123");
System.out.println(value);
//存值,同时设置过期时间
redisTemplate.opsForValue().set("key1","value1",10l, TimeUnit.SECONDS);
//存值,如果存在则不执行任何操作
Boolean aBoolean = redisTemplate.opsForValue().setIfAbsent("city1234", "nanjing");
System.out.println(aBoolean);
}
4.3.2.3 操作哈希类型数据
/**
* 操作Hash类型数据
*/
@Test
public void testHash(){
HashOperations hashOperations = redisTemplate.opsForHash();
//存值
hashOperations.put("002","name","xiaoming");
hashOperations.put("002","age","20");
hashOperations.put("002","address","bj");
//取值
String age = (String) hashOperations.get("002", "age");
System.out.println(age);
//获得hash结构中的所有字段
Set keys = hashOperations.keys("002");
for (Object key : keys) {
System.out.println(key);
}
//获得hash结构中的所有值
List values = hashOperations.values("002");
for (Object value : values) {
System.out.println(value);
}
}
4.3.2.4 操作List列表类型数据
/**
* 操作List类型的数据
*/
@Test
public void testList(){
ListOperations listOperations = redisTemplate.opsForList();
//存值
listOperations.leftPush("mylist","a");
listOperations.leftPushAll("mylist","b","c","d");
//取值
List<String> mylist = listOperations.range("mylist", 0, -1);
for (String value : mylist) {
System.out.println(value);
}
//获得列表长度 llen
Long size = listOperations.size("mylist");
int lSize = size.intValue();
for (int i = 0; i < lSize; i++) {
//出队列
String element = (String) listOperations.rightPop("mylist");
System.out.println(element);
}
}
4.3.2.5 操作Set集合类型数据
/**
* 操作Set类型的数据
*/
@Test
public void testSet(){
SetOperations setOperations = redisTemplate.opsForSet();
//存值
setOperations.add("myset","a","b","c","a");
//取值
Set<String> myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
//删除成员
setOperations.remove("myset","a","b");
//取值
myset = setOperations.members("myset");
for (String o : myset) {
System.out.println(o);
}
}
4.3.2.6 操作有序集合类型数据
/**
* 操作ZSet类型的数据
*/
@Test
public void testZset(){
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
//存值
zSetOperations.add("myZset","a",10.0);
zSetOperations.add("myZset","b",11.0);
zSetOperations.add("myZset","c",12.0);
zSetOperations.add("myZset","a",13.0);
//取值
Set<String> myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//修改分数
zSetOperations.incrementScore("myZset","b",20.0);
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
//删除成员
zSetOperations.remove("myZset","a","b");
//取值
myZset = zSetOperations.range("myZset", 0, -1);
for (String s : myZset) {
System.out.println(s);
}
}
4.3.2.7 通用操作
/**
* 通用操作,针对不同的数据类型都可以操作
*/
@Test
public void testCommon(){
//获取Redis中所有的key
Set<String> keys = redisTemplate.keys("*");
for (String key : keys) {
System.out.println(key);
}
//判断某个key是否存在
Boolean gaohe = redisTemplate.hasKey("gaohe");
System.out.println(gaohe);
//删除指定key
redisTemplate.delete("myZset");
//获取指定key对应的value的数据类型
DataType dataType = redisTemplate.type("myset");
System.out.println(dataType.name());
}
5. 项目中redis环境搭建
1). 在项目的pom.xml文件中导入spring data redis的maven坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
2). 在项目的application.yml中加入redis相关配置
redis:
host: localhost
port: 6379
password: itgaohe
database: 0
注意: 引入上述依赖时,需要注意yml文件前面的缩进,上述配置应该配置在spring层级下面。
3). 编写Redis的配置类RedisConfig,定义RedisTemplate
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory connectionFactory) {
RedisTemplate<Object, Object> redisTemplate = new RedisTemplate<>();
//默认的Key序列化器为:JdkSerializationRedisSerializer
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setConnectionFactory(connectionFactory);
return redisTemplate;
}
}
解释说明:
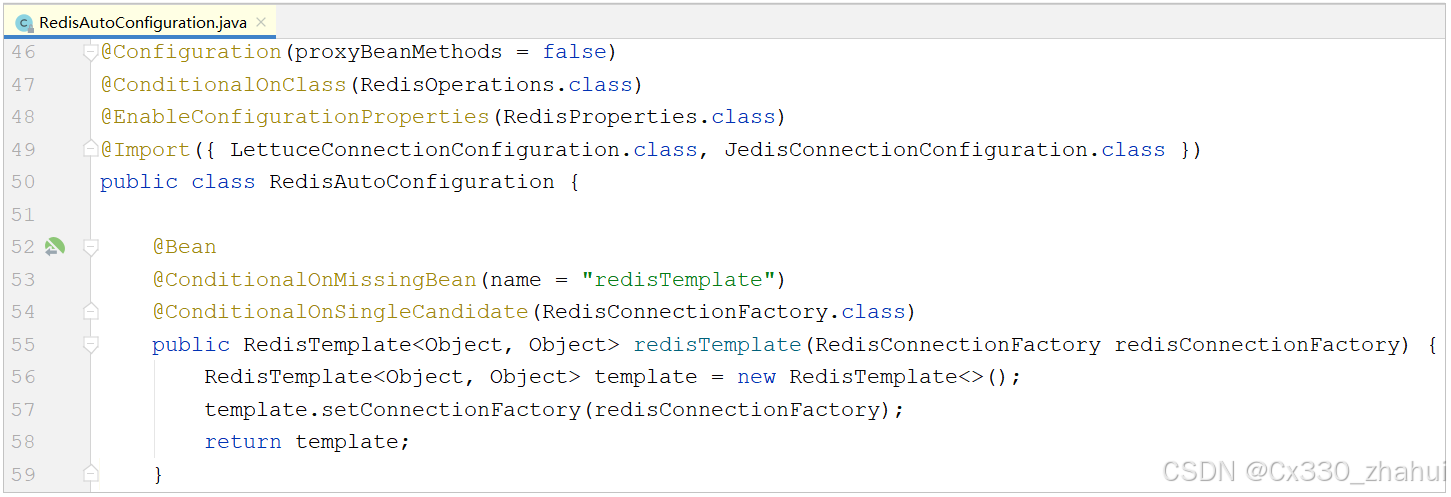
1). 在SpringBoot工程启动时, 会加载一个自动配置类 RedisAutoConfiguration, 在里面已经声明了RedisTemplate这个bean
6. 缓存短信验证码
1 思路分析
前面我们已经实现了移动端手机验证码登录,随机生成的验证码我们是保存在HttpSession中的。但是在我们实际的业务场景中,一般验证码都是需要设置过期时间的,如果存在HttpSession中就无法设置过期时间,此时我们就需要对这一块的功能进行优化。
现在需要改造为将验证码缓存在Redis中,具体的实现思路如下:
1). 在服务端UserController中注入RedisTemplate对象,用于操作Redis;
2). 在服务端UserController的sendMsg方法中,将随机生成的验证码缓存到Redis中,并设置有效期为5分钟;
3). 在服务端UserController的login方法中,从Redis中获取缓存的验证码,如果登录成功则删除Redis中的验证码;
2 代码改造
1). 在UserController中注入RedisTemplate对象,用于操作Redis
@Autowired
private RedisTemplate redisTemplate;
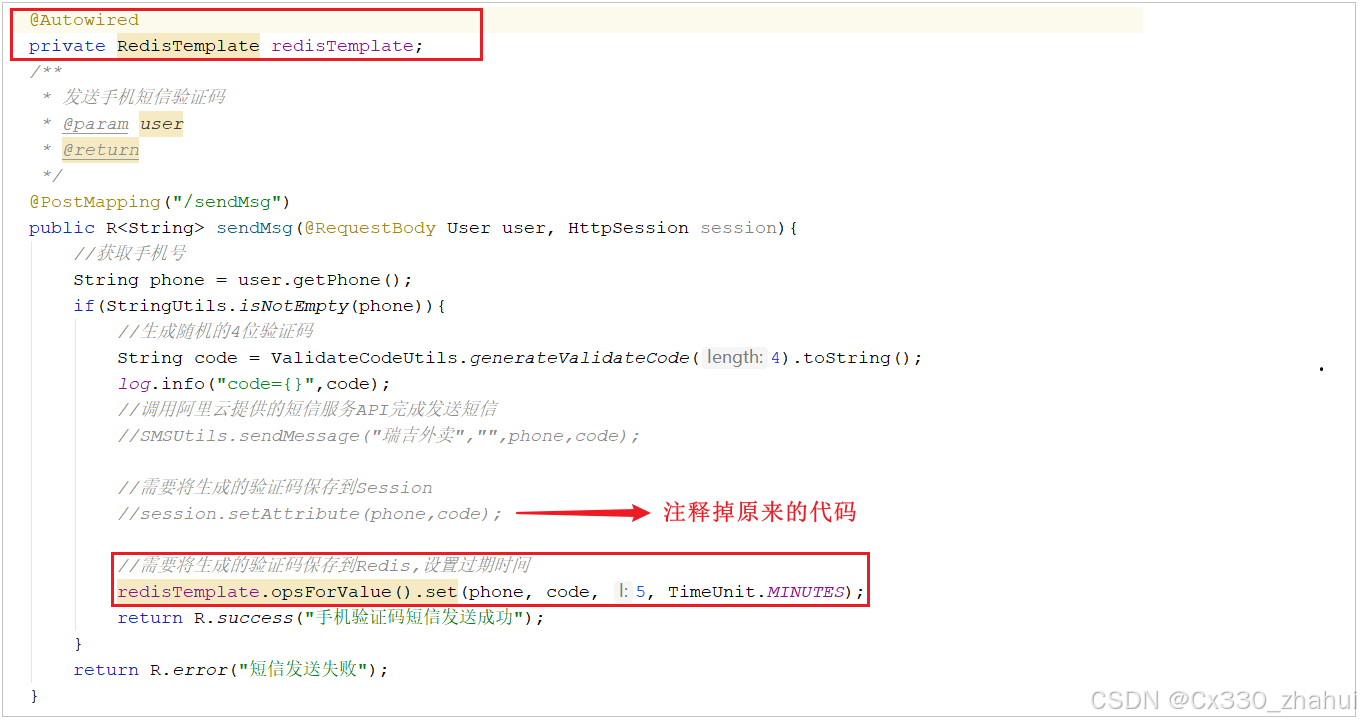
2). 在UserController的sendMsg方法中,将生成的验证码保存到Redis
//需要将生成的验证码保存到Redis,设置过期时间
redisTemplate.opsForValue().set(phone, code, 5, TimeUnit.MINUTES);
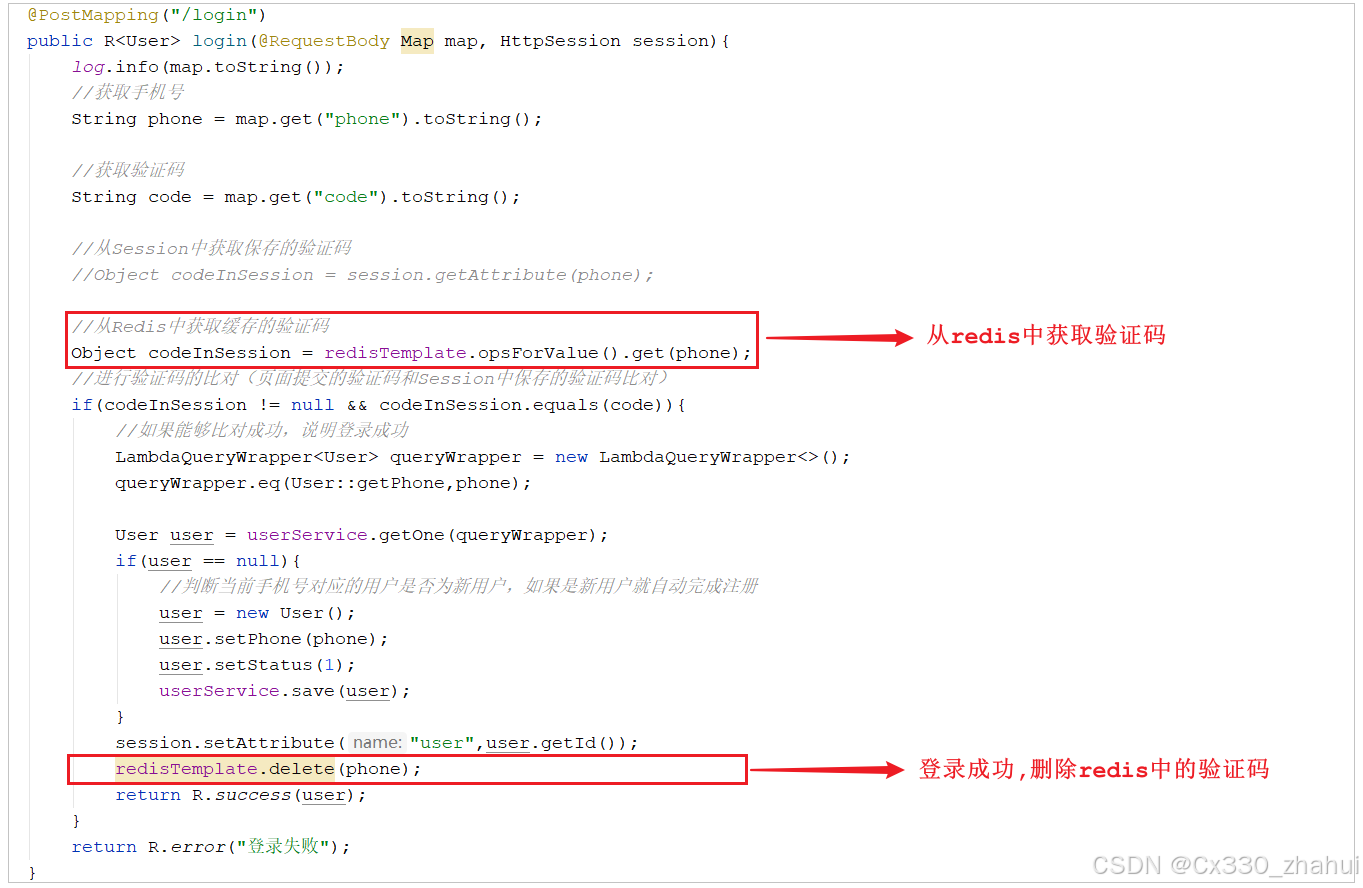
3). 在UserController的login方法中,从Redis中获取生成的验证码,如果登录成功则删除Redis中缓存的验证码
//从Redis中获取缓存的验证码
Object codeInSession = redisTemplate.opsForValue().get(phone);
//如果用户登录成功,从Redis中删除缓存的验证码
redisTemplate.delete(phone);
3 功能测试
代码编写完毕之后,重启服务。
1). 访问前端工程,获取验证码
通过控制台的日志,我们可以看到生成的验证码:

2). 通过Redis的图形化界面工具查看Redis中的数据
3). 在登录界面填写验证码登录完成后,查看Redis中的数据是否删除

tips:报错解决:DENIED Redis is running in protected mode because protected mode is enabled
需要修改配置文件:
#外部访IP-- 这个ip地址为通过ip addr 查出来的ip
bind 0.0.0.0
#端口号
port 6379
#密码
#requirepass itgaohe
然后通过配置文件启动就OK了:
启动server:

客户端cli:

7. 缓存菜品信息
1 实现思路
前面我们已经实现了移动端菜品查看功能,对应的服务端方法为DishController的list方法,此方法会根据前端提交的查询条件(categoryId)进行数据库查询操作。在高并发的情况下,频繁查询数据库会导致系统性能下降,服务端响应时间增长。现在需要对此方法进行缓存优化,提高系统的性能。

具体的实现思路如下:
1). 改造DishController的list方法,先从Redis中获取分类对应的菜品数据,如果有则直接返回,无需查询数据库;如果没有则查询数据库,并将查询到的菜品数据存入Redis。
2). 改造DishController的save和update方法,加入清理缓存的逻辑。
注意:
在使用缓存过程中,要注意保证数据库中的数据和缓存中的数据一致,如果数据库中的数据发生变化,需要及时清理缓存数据。否则就会造成缓存数据与数据库数据不一致的情况。
2 代码改造
2.1 查询菜品缓存
| 改造的方法 | redis的数据类型 | redis缓存的key | redis缓存的value |
|---|---|---|---|
| list | string | dish_分类Id_状态 , 比如: dish_12323232323_1 | List |
1). 在DishController中注入RedisTemplate
@Autowired
private RedisTemplate redisTemplate;
2). 在list方法中,查询数据库之前,先查询缓存, 缓存中有数据, 直接返回
List<DishDto> dishDtoList = null;
//动态构造key
String key = "dish_" + dish.getCategoryId() + "_" + dish.getStatus();//dish_1397844391040167938_1
//先从redis中获取缓存数据
dishDtoList = (List<DishDto>) redisTemplate.opsForValue().get(key);
if(dishDtoList != null){
//如果存在,直接返回,无需查询数据库
return R.success(dishDtoList);
}

3). 如果redis不存在,查询数据库,并将数据库查询结果,缓存在redis,并设置过期时间
//如果不存在,需要查询数据库,将查询到的菜品数据缓存到Redis
redisTemplate.opsForValue().set(key,dishDtoList,60, TimeUnit.MINUTES);

3.2.2 清理菜品缓存
为了保证数据库中的数据和缓存中的数据一致,如果数据库中的数据发生变化,需要及时清理缓存数据。所以,我们需要在添加菜品、更新菜品时清空缓存数据。
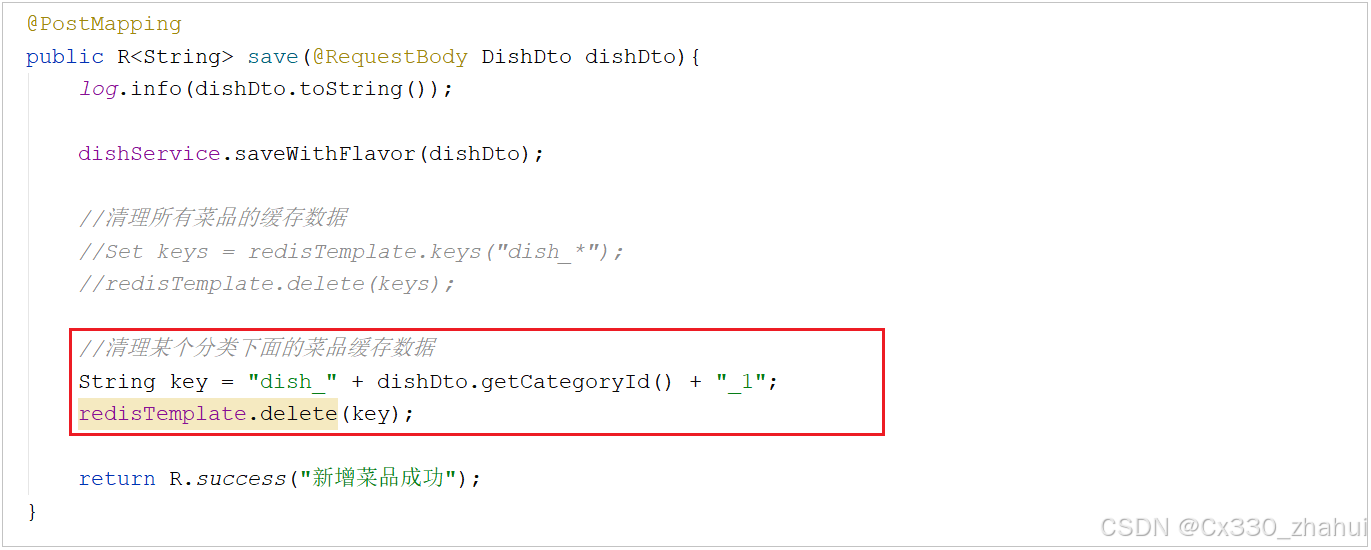
1). 保存菜品,清空缓存
在保存菜品的方法save中,当菜品数据保存完毕之后,需要清空菜品的缓存。那么这里清理菜品缓存的方式存在两种:
A. 清理所有分类下的菜品缓存
//清理所有菜品的缓存数据
Set keys = redisTemplate.keys("dish_*"); //获取所有以dish_xxx开头的key
redisTemplate.delete(keys); //删除这些key
B. 清理当前添加菜品分类下的缓存
//清理某个分类下面的菜品缓存数据
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
此处, 我们推荐使用第二种清理的方式, 只清理当前菜品关联的分类下的菜品数据。
2). 更新菜品,清空缓存
在更新菜品的方法update中,当菜品数据更新完毕之后,需要清空菜品的缓存。这里清理缓存的方式和上述基本一致。
A. 清理所有分类下的菜品缓存
//清理所有菜品的缓存数据
Set keys = redisTemplate.keys("dish_*"); //获取所有以dish_xxx开头的key
redisTemplate.delete(keys); //删除这些key
B. 清理当前添加菜品分类下的缓存
//清理某个分类下面的菜品缓存数据
String key = "dish_" + dishDto.getCategoryId() + "_1";
redisTemplate.delete(key);
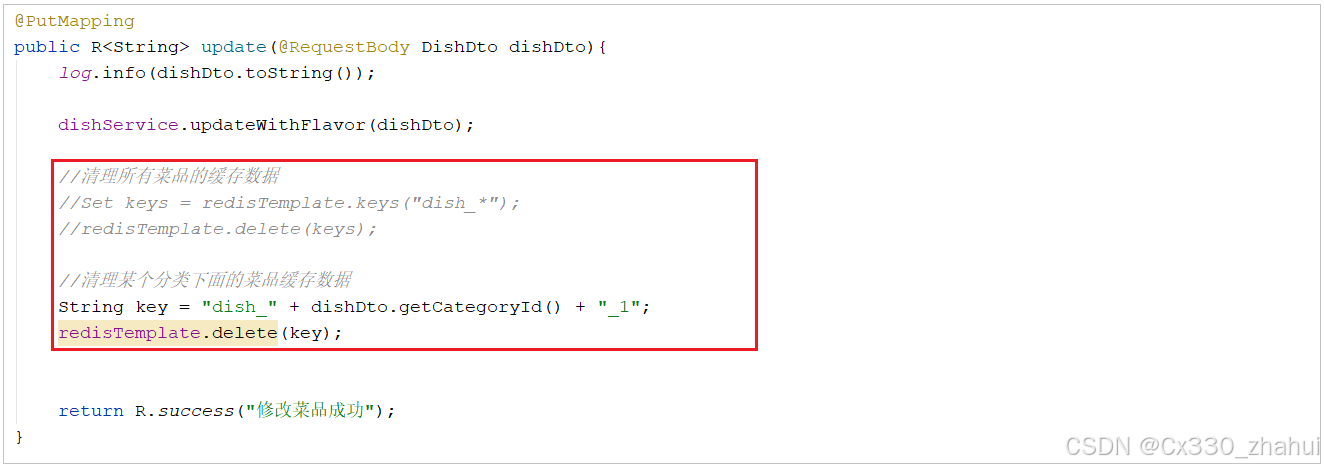
注意: 在这里我们推荐使用第一种方式进行清理,这样逻辑更加严谨。 因为对于修改操作,用户是可以修改菜品的分类的,如果用户修改了菜品的分类,那么原来分类下将少一个菜品,新的分类下将多一个菜品,这样的话,两个分类下的菜品列表数据都发生了变化。
3 功能测试
代码编写完毕之后,重新启动服务。
1). 访问移动端,根据分类查询菜品列表,然后再检查Redis的缓存数据,是否可以正常缓存;

我们也可以在服务端,通过debug断点的形式一步一步的跟踪代码的执行。
2). 当我们在进行新增及修改菜品时, 查询Redis中的缓存数据, 是否被清除;
总结:
-
NoSQL:不仅仅是sql。redis :高频、热点
-
redis特征:1.键值存储 2. 单线程3.高并发 4. 5种数据类型
-
redis应用场景:
(1)为热点数据加速查询(主要场景)。如热点商品、热点新闻、热点资讯、推广类等高访问量信息等。
(2)即时信息查询。如各位排行榜、各类网站访问统计、公交到站信息、在线人数信息(聊天室、网站)、设备信号等。
(3)时效性信息控制。如验证码控制、投票控制等。
(4)分布式数据共享。如分布式集群架构中的 session 分离消息队列.(了解)
-
redis启动服务器 redis-server redis-6380.conf redis-cli -h 127.0.0.1 -p 6380 -a gaohe
-
redis 基本数据类型:string hash list set zset
-
Jedis
- jedis
- redisTemplate(重点)