day03 大模型实战-embedding
1.生成 Embedding (基于 text-embedding-ada-002 模型)
嵌入对于处理自然语言和代码非常有用,因为其他机器学习模型和算法(如聚类或搜索)可以轻松地使用和比较它们。

亚马逊美食评论数据集(amazon-fine-food-reviews)
Source:美食评论数据集
该数据集包含截至2012年10月用户在亚马逊上留下的共计568,454条美食评论。为了说明目的,我们将使用该数据集的一个子集,其中包括最近1,000条评论。这些评论都是用英语撰写的,并且倾向于积极或消极。每个评论都有一个产品ID、用户ID、评分、标题(摘要)和正文。
我们将把评论摘要和正文合并成一个单一的组合文本。模型将对这个组合文本进行编码,并输出一个单一的向量嵌入。
1.1 基本步骤
第一步:加载数据集并简单处理
import pandas as pd
import tiktoken
# 读取数据:使用 pd.read_csv 从指定路径加载 CSV 文件,并将第一列(索引为 0 的列)设置为数据框的索引。
input_datapath = ("data/fine_food_reviews_1k.csv")
df = pd.read_csv(input_datapath,index_col=0)
# 选择特定列:选择数据框中的六列:"Time", "ProductId", "UserId", "Score", "Summary" 和 "Text"。
df = df[["Time","ProductId","UserId","Score","Summary","Text"]]
# 删除缺失值:删除任何包含缺失值的行
df.dropna()
# 合字段:将 "Summary" 和 "Text" 字段组合成一个新的字段 "combined",格式为 "Title: " + 摘要 + "; Content: " + 正文。
df["combined"] = ("Title: " + df.Summary.str.strip() + "; Content: " + df.Text.str.strip())
# 显示前两行:显示处理后的数据框的前两行
df.head(2)
print(df.head(2))
| Time | ProductId | UserId | Score | Summary | Text | combined | |
|---|---|---|---|---|---|---|---|
| 0 | 1351123200 | B003XPF9BO | A3R7JR3FMEBXQB | 5 | where does one start…and stop… with a tre… | Wanted to save some to bring to my Chicago fam… | Title: where does one start…and stop… wit… |
| 1 | 1351123200 | B003JK537S | A3JBPC3WFUT5ZP | 1 | Arrived in pieces | Not pleased at all. When I opened the box, mos… | Title: Arrived in pieces; Content: Not pleased. |
代码解析:
1.为何是两个中括号?
df[["Time","ProductId","UserId","Score","Summary","Text"]]
单个中括号:df["column_name"] 用于选择单个列,返回一个 Pandas Series。
双重中括号:df[["col1", "col2", "col3"]] 用于选择多个列,返回一个 Pandas DataFrame。
选择多个列: 当你想从数据框中选择多个列时,需要提供一个包含列名的列表。外层的中括号表示选择操作,内层的中括号表示列名列表。这样 Pandas 可以理解你想要的结果是一个新的数据框,而不是一个 Series。
2.df.dropna() 的作用?
使用 df.dropna() 的目的是删除数据框中包含缺失值的行。这在数据预处理中是一个常见步骤,以确保后续的数据分析和处理不会因为缺失数据而出现错误或不准确的结果。
dropna()函数解释
dropna()是 Pandas 数据框的一种方法,用于删除包含缺失值的行或列。具体参数和用法如下:
axis: 选择是删除行还是删除列。axis=0(默认值)表示删除行,axis=1表示删除列。how: 确定删除标准。how='any'(默认值)表示只要有一个缺失值就删除该行或列,how='all'表示该行或列的所有值都缺失时才删除。thresh: 需要非缺失值的数量,若没有达到该数量则删除。subset: 指定仅考虑特定列进行缺失值检查。inplace: 是否在原数据框上进行操作,True表示直接修改原数据框,False(默认值)表示返回一个新的数据框。
举例说明:
假设我们有一个包含四行数据的小型数据框,其中有一些缺失值:
import pandas as pd
import numpy as np
# 创建一个包含缺失值的数据框
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
print("原始数据框:")
print(df)
输出:
A B C
0 1.0 5.0 9
1 2.0 NaN 10
2 NaN NaN 11
3 4.0 8.0 12
在这个数据框中,第 1 行和第 2 行有缺失值。如果我们使用 dropna() 删除包含缺失值的行:
# 默认 inplace=False 即不替代原始数据,产生一个新的对象,可以设置inplace=True来代替
df_cleaned = df.dropna()
print("删除缺失值后的数据框:")
print(df_cleaned)
输出:
A B C
0 1.0 5.0 9
3 4.0 8.0 12
可以看到,包含缺失值的第 1 行和第 2 行被删除,只剩下了第 0 行和第 3 行,因为这两行没有缺失值。
参数示例
删除包含任何缺失值的行(默认)
df_cleaned = df.dropna()
删除并替代原始数据
df.dropna(inplace=True) #df已重新赋值
删除所有值都缺失的行
如果只有那些所有值都缺失的行需要被删除,可以使用 how='all':
df_all_cleaned = df.dropna(how='all')
删除包含缺失值的列
如果要删除包含任何缺失值的列,可以设置 axis=1:
df_columns_cleaned = df.dropna(axis=1)
仅考虑特定列的缺失值
如果只需要检查特定列的缺失值,可以使用 subset 参数:
df_specific_cleaned = df.dropna(subset=['A', 'B'])
3.str.strip()的作用?
str.strip() 是 Python 字符串方法,用于移除字符串开头和结尾的空白字符(包括空格、制表符和换行符等)。该方法不改变原字符串,而是返回一个新的字符串。
text = " hello world "
text_stripped = text.strip()
# 在 Python 中,f 字符用于创建格式化字符串,通常称为 f-strings 或格式化字符串字面量。
# 它是在字符串前添加一个 f 或 F,然后可以在字符串中直接嵌入表达式,并将其计算结果插入字符串。
print(f"原字符:{text}")
print(f"去除空白后的字符:{text_stripped}")
原字符: hello world
去除空白后的字符:hello world
去除特定字符:
str.strip([chars]) 可以接受一个可选参数 chars,用于指定要移除的字符。只要这些字符出现在字符串的开头或结尾,就会被移除
text = "***Hello, World!***"
stripped_text = text.strip("*")
print(f"原字符串: '{text}'")
print(f"去除'*'后的字符串: '{stripped_text}'")
原字符串: '***Hello, World!***'
去除'*'后的字符串: 'Hello, World!'
第二步 将样本减少到最近的1,000个评论,并删除过长的样本
模型关键参数:
# 2.1 设置参数
# 建议使用官方推荐的第二代嵌入模型:text-embeding-ada-002
# 该模型可以实现更高的准确率和更快的训练速度
embedding_model = "text-embedding-ada-002"
# text-embeding-ada-002 模型对应的分词器 (tokenizer)
embedding_encoding = ("cl100k_base")
# text-embeding-ada-002 模型支持的输入最大Token数是8191,向量维度是1536
# 在我们的demo中过滤Token超过8000的文本
max_tokens = 8000
将样本减少到最近的1,000个评论,并删除过长的样本
# 2.2 筛选
# 设置要筛选的评论数量为1000
top_n = 1000
# 对DataFrame进行排序,基于“Time”列,然后选取最后的2000条评论
# 这个假设是,我们认为最近的评论可能更相关,因此我们将对他进行初始筛选
df = df.sort_values("Time").tail(top_n * 2)
# 丢弃Time列 因为我们在这个分析中不在需要它
df.drop("Time",axis = 1, inplace = True)
# 从embedding_encoding获取编码
encoding = tiktoken.get_encoding(embedding_encoding)
# 计算每条评论的token数量,我们通过使用encoding.encode方法获取每条评论的token数,
# 然后把结果存储在新的n_tokens中
df["n_tokens"] = df.combined.apply(lambda x: len(encoding.encode(x)))
# 如果评论的token数量超过最大允许的token数量,我们将忽略并删除该评论
# 我们使用.tail 方法获取token数量在允许范围内的最后top_n (1000) 条评论
df = df[df.n_tokens <= max_tokens].tail(top_n)
# 打印出剩余评论的数量
len(df)
代码解析:
1.df.drop()用法?
df = pd.DataFrame({'name':['张三','李四','王二','麻子','杜甫'],'mark':[120,111,135,150,151],'gender':['male','female','female','male',np.nan]})
df1 = df.drop(['mark','name'], axis=1) # 删除列需加上axis参数
print(df1)
gender
0 male
1 female
2 female
3 male
4 NaN
2.df.drop与df.dropna区别?
drop()主要针对于删除普通行列
dropna()主要针对于删除筛选有空值的行列
3.tiktoken的基本用法?
tiktoken 的 Encoding (编码方式)用于展示文本是如何被转化为token的。不同的模型使用不同类型的编码方式。tiktoken支持如下三种OpenAl模型的编码方式:
| 编码方式 | OpenAI模型 |
|---|---|
| cl100k_base | gpt-4, gpt-3.5-turbo, text-embedding-ada-002 |
| p50k_base | Codex模型,如 text-davinci-002, text-davinci-003 |
| r50k_base (或gpt2) | GPT-3模型,如davinci |
编码与解码
编码(encode)是指将文本映射为token的数字列表,解码(decode)是指将token的数字列表转化为文本。参看以下的Python代码实现
import tiktoken
enc = tiktoken.get_encoding("cl100k_base")
print(enc.encode("hello world"))
print(enc.decode([15339, 1917]))
输出:
[15339, 1917]
hello world
-
计算Token数
token的数量等于字符串编码后得到的集合的长度。
例如
[15339, 1917] hello world hello world 的token数为2 即 集合的len
import tiktoken
def num_tokens_from_string(string, encoding_name):
# Returns the number of tokens in a text string.
encoding = tiktoken.get_encoding(encoding_name)
num_tokens = len(encoding.encode(string))
return num_tokens
print(num_tokens_from_string('tiktoken is great!', 'cl100k_base'))
print(num_tokens_from_string('大模型是什么?', 'cl100k_base'))
6
8
5.apply(lambda x: …) 函数的作用?
Pandas中’apply’方法的用法,它会对DataFrame的每一行应用一个函数,’lambda x:‘是一个匿名函数, 接收一行(这里接收的是combined的值)作为输入,交给len(encoding.encode(x))计算token数量。
第三步:生成 Embeddings 并保存
# 3.1 生成 Embeddings 并保存
client = OpenAI(
base_url="https://api.xty.app/v1",
api_key=".......",
)
def embedding_text(text,embedding_model):
res = client.embeddings.create(input=text,model=embedding_model)
df["embedding"] = df.combined.apply(embedding_text)
output_datapath = "data/fine_food_reviews_with_embeddings_1k_0716.csv"
df.to_csv(output_datapath)
第四步: 将str类型的embedding转换成向量
type(df_embedded["embedding"][0])
# 输出 str 并没有生成向量,而是易于表示的str
import ast
embedding_datapath = "data/fine_food_reviews_with_embeddings_1k.csv"
df_embedded = pd.read_csv(embedding_datapath)
print(df_embedded["embedding"])
# 转化成向量
df_embedded["embedding_vec"] = (df_embedded["embedding"].apply(ast.literal_eval))
# print(len(df_embedded["embedding_vec"][0]))
print(df_embedded.head(2))
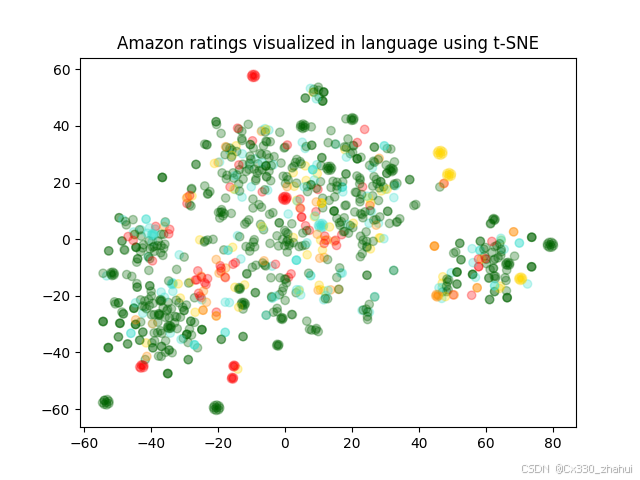
2.使用 t-SNE 可视化 1536 维 Embedding 美食评论
# 导入 NumPy 包,NumPy 是 Python 的一个开源数值计算扩展。这种工具可用来存储和处理大型矩阵,
# 比 Python 自身的嵌套列表(nested list structure)结构要高效的多。
import numpy as np
# 从 matplotlib 包中导入 pyplot 子库,并将其别名设置为 plt。
# matplotlib 是一个 Python 的 2D 绘图库,pyplot 是其子库,提供了一种类似 MATLAB 的绘图框架。
import matplotlib.pyplot as plt
import matplotlib
# 从 sklearn.manifold 模块中导入 TSNE 类。
# TSNE (t-Distributed Stochastic Neighbor Embedding) 是一种用于数据可视化的降维方法,尤其擅长处理高维数据的可视化。
# 它可以将高维度的数据映射到 2D 或 3D 的空间中,以便我们可以直观地观察和理解数据的结构。
from sklearn.manifold import TSNE
# 首先,确保你的嵌入向量都是等长的
assert df_embedded['embedding_vec'].apply(len).nunique() == 1
# 将嵌入向量列表转换为二维numpy数组
matrix = np.vstack(df_embedded['embedding_vec'].values)
# 创建一个 t-SNE 模型,t-SNE 是一种非线性降维方法,常用于高维数据的可视化。
# n_components 表示降维后的维度(在这里是2D)
# perplexity 可以被理解为近邻的数量
# random_state 是随机数生成器的种子
# init 设置初始化方式
# learning_rate 是学习率。
tsne = TSNE(n_components=2, perplexity=15, random_state=42, init='random', learning_rate=200)
# 对数据进行降维 得到每个数据点在新的2D空间的坐标
vis_dims = tsne.fit_transform(matrix)
# 定义五种颜色,用于在可视化中表示不同的等级
colors = ["red", "darkorange", "gold", "turquoise", "darkgreen"]
# 从降维后的坐标中分别获取所有数据点的横坐标和纵坐标
x = [x for x,y in vis_dims]
y = [y for x,y in vis_dims]
# 根据数据点的评分(减1是因为评分是从1开始的,而颜色索引是从0开始的)获取对应的颜色索引
color_indices = df_embedded.Score.values - 1
# 确保你的数据点和颜色索引的数量匹配
assert len(vis_dims) == len(df_embedded.Score.values)
# 创建一个基于预定义颜色的颜色映射对象
colormap = matplotlib.colors.ListedColormap(colors)
#使用 matplotlib 创建散点图,其中颜色由颜色映射对象和颜色索引共同决定,alpha 是点的透明度
plt.scatter(x,y, c=color_indices, cmap=colormap, alpha=0.3)
# 为图形添加标题
plt.title("Amazon ratings visualized in language using t-SNE")
plt.show()
代码解析:
1.assert 作用?
assert 是一个 Python 关键字,用于调试程序时进行条件检查。它的基本用法是 assert <条件表达式>, <错误信息>。
如果 <条件表达式> 为真,程序将继续执行。如果 <条件表达式> 为假,程序将引发一个 AssertionError 异常,并输出可选的 <错误信息>
x = 5
assert x > 0, "x 必须大于 0"
在这个例子中,如果 x 大于 0,程序将继续执行。如果 x 不大于 0,程序将引发一个 AssertionError,并输出消息 “x 必须大于 0”。
assert 的作用主要是在开发和调试过程中用来捕获不符合预期的情况,帮助开发者及时发现和修正潜在的错误。
2.为什么向量长度要保持一样?
保证向量长度一样在数据处理和机器学习中非常重要,原因如下:
- 统一性和规范性:机器学习算法通常要求输入数据的格式一致。向量长度统一可以确保数据在处理和计算时的规范性,避免因为数据格式不一致而导致的错误。
- 算法需求:许多机器学习算法(如神经网络、支持向量机等)要求输入的特征向量具有相同的维度。只有在向量长度一致的情况下,这些算法才能正确地训练模型和进行预测。
- 矩阵运算:在深度学习和其他需要矩阵运算的场景中,向量长度一致是进行矩阵加法、乘法等运算的前提条件。如果向量长度不一致,矩阵运算将无法进行。
- 比较和度量:在比较两个或多个向量的相似度或距离时(例如使用欧氏距离或余弦相似度),需要保证这些向量的长度一致,否则这些度量方法将失效或产生错误结果。
- 数据一致性检查:保证向量长度一致也是一种数据一致性检查的方法。它可以帮助检测数据预处理过程中是否有错误或异常情况,例如数据缺失或错误填充。
例如,在文本嵌入(Text Embeddings)中,每个词或句子的向量表示需要具有相同的维度,以便在进行分类、聚类或其他文本分析任务时能够被算法正确处理和利用。
3.nunique()作用?
计算唯一值个数:返回一个数值,表示列(或行)中不同值的数量。
df = pd.DataFrame({
'A': [1, 2, 2, 3, 4],
'B': [1, 1, 2, 3, 3],
'C': [5, 6, 7, 8, 9]
})
# 对每列计算唯一值的个数
unique_counts_per_column = df.nunique()
print(unique_counts_per_column)
# 输出:
# A 4
# B 3
# C 5
# dtype: int64
# 对每行计算唯一值的个数
unique_counts_per_row = df.nunique(axis=1)
print(unique_counts_per_row)
# 输出:
# 0 2
# 1 3
# 2 3
# 3 3
# 4 3
# dtype: int64
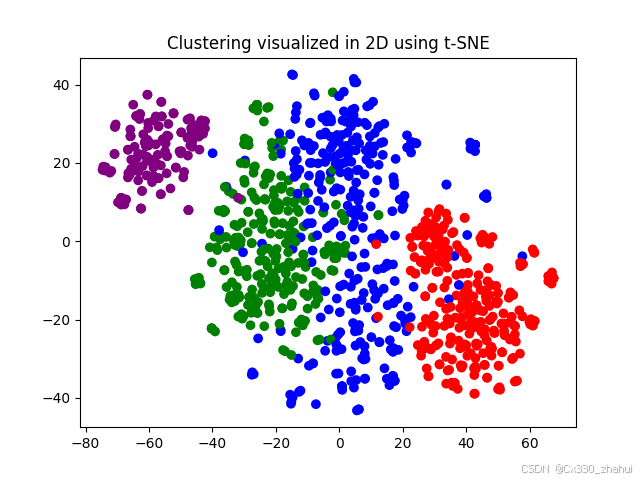
3.使用 K-Means 聚类,然后使用 t-SNE 可视化
import numpy as np
# 从 scikit-learn中导入 KMeans 类。KMeans 是一个实现 K-Means 聚类算法的类。
from sklearn.cluster import KMeans
# np.vstack 是一个将输入数据堆叠到一个数组的函数(在垂直方向)。
# 这里它用于将所有的 ada_embedding 值堆叠成一个矩阵。
# matrix = np.vstack(df.ada_embedding.values)
# 定义要生成的聚类数。
n_clusters = 4
# 创建一个 KMeans 对象,用于进行 K-Means 聚类。
# n_clusters 参数指定了要创建的聚类的数量;
# init 参数指定了初始化方法(在这种情况下是 'k-means++');
# random_state 参数为随机数生成器设定了种子值,用于生成初始聚类中心。
# n_init=10 消除警告 'FutureWarning: The default value of `n_init` will change from 10 to 'auto' in 1.4'
kmeans = KMeans(n_clusters = n_clusters, init='k-means++', random_state=42, n_init=10)
# 使用 matrix(我们之前创建的矩阵)来训练 KMeans 模型。这将执行 K-Means 聚类算法。
kmeans.fit(matrix)
# kmeans.labels_ 属性包含每个输入数据点所属的聚类的索引。
# 这里,我们创建一个新的 'Cluster' 列,在这个列中,每个数据点都被赋予其所属的聚类的标签。
df_embedded['Cluster'] = kmeans.labels_
# 首先为每个聚类定义一个颜色。
colors = ["red", "green", "blue", "purple"]
# 然后,你可以使用 t-SNE 来降维数据。这里,我们只考虑 'embedding_vec' 列。
tsne_model = TSNE(n_components=2, random_state=42)
vis_data = tsne_model.fit_transform(matrix)
# 现在,你可以从降维后的数据中获取 x 和 y 坐标。
x = vis_data[:, 0]
y = vis_data[:, 1]
# 'Cluster' 列中的值将被用作颜色索引。
color_indices = df_embedded['cluster'].values
# 创建一个基于预定义颜色的颜色映射对象
colormap = matplotlib.colors.ListedColormap(colors)
# 使用 matplotlib 创建散点图,其中颜色由颜色映射对象和颜色索引共同决定
plt.scatter(x, y, c=color_indices, cmap=colormap)
# 为图形添加标题
plt.title("Clustering visualized in 2D using t-SNE")
# 显示图形
plt.show()
Kmeans.labels_:
labels_是 KMeans 模型的一个属性。它包含了聚类模型对数据进行聚类后的标签结果,是一个数组,其中的每个元素表示对应数据点的聚类标签(即该数据点被分配到的簇)
4.使用 Embedding 进行文本搜索
4.1 计算两个嵌入向量之间的余弦相似度。
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
解释:
np.dot(a, b)
- 计算向量
a和b的点积。点积是两个向量对应元素的乘积之和。 - 例如,若
a = [a1, a2, a3]和b = [b1, b2, b3],则点积为a1*b1 + a2*b2 + a3*b3。
np.linalg.norm(a) 和 np.linalg.norm(b)
- 计算向量
a和b的范数(即向量的长度或模)。默认情况下,这是欧几里得范数(L2范数)。 - 例如,对于向量
a = [a1, a2, a3],其范数为sqrt(a1^2 + a2^2 + a3^2)
def embedding_text(text, model="text-embedding-ada-002"):
res = client.embeddings.create(input=text, model=model)
return res.data[0].embedding
def search_reviews(df, product_description, n=3, pprint=True):
product_embedding = embedding_text(product_description)
df["similarity"] = df.embedding_vec.apply(lambda x: cosine_similarity(x, product_embedding))
results = (
df.sort_values("similarity", ascending=False)
.head(n)
# 去掉评论中标题部分的 "Title: " 和内容部分的 "; Content:",使得评论更易读。
.combined.str.replace("Title: ", "")
.str.replace("; Content:", ": ")
)
if pprint:
for r in results:
# 如果 pprint 为 True,则打印每条评论的前 200 个字符
print(r[:200])
print()
return results
res = search_reviews(df_embedded, 'dog food', n=3)
输出:
Healthy Dog Food: This is a very healthy dog food. Good for their digestion. Also good for small puppies. My dog eats her required amount at every feeding.
Doggy snacks: My dog loves these snacks. However they are made in China and as far as I am concerned, suspect!!!! I found an abundance of American made ,human grade chicken dog snacks. Just Google fo
Dogs Love Them!: My Maltese and Cavalier King Charles love these treats! I feel good about feeding them a healthier treat.<br />Not made in China!
ults
res = search_reviews(df_embedded, ‘dog food’, n=3)
输出:
```python
Healthy Dog Food: This is a very healthy dog food. Good for their digestion. Also good for small puppies. My dog eats her required amount at every feeding.
Doggy snacks: My dog loves these snacks. However they are made in China and as far as I am concerned, suspect!!!! I found an abundance of American made ,human grade chicken dog snacks. Just Google fo
Dogs Love Them!: My Maltese and Cavalier King Charles love these treats! I feel good about feeding them a healthier treat.<br />Not made in China!