- 实验目的
本次实验的目的是练习使用Python编程语言和相关库进行网络爬虫和数据处理任务。具体来说,您将学习以下内容:
使用Python中的requests库和BeautifulSoup库来爬取当当网某一本书的网页内容,并将其保存为html格式文件。
学习使用Python中的requests库和正则表达式来爬取豆瓣网上某本书的前50条短评内容,并计算评分的平均值。
了解如何使用Python中的requests库和pandas库来爬取https://cs.lianjia.com/上长沙某小区(如名都花园)的二手房信息,并将其保存到Excel文件中。
练习将两个txt文件中的内容根据id合并为一个txt文件,这将涉及文件操作和数据处理。
学习如何按照id将一个txt文件拆分成多个文件,具有相同id的内容放在同一个txt文件中,这将涉及文件操作和数据处理。
- 实验要求
- 爬取并下载当当网某一本书的网页内容,并保存为html格式
- 在豆瓣网上爬取某本书的前50条短评内容并计算评分的平均值(自学正则表达式)
- 从长沙房产网_长沙房地产_长沙房产门户(长沙链家网)上爬取长沙某小区的二手房信息(以名都花园为例),并将其保存到EXCEL文件当中
- 假设有两个txt文件,内容如图1,将这两个文件中的内容根据id(即前面的编号)合并为如下内容,并存放在一个txt文件中,如图2。

5.按id(即前面的编号)将一个txt文件拆分成多个文件,要求具有同一个id的内容放在一个txt文件中。例如:
merge.txt

拆分为如下3个文件

- 实验代码
题目一源代码:
| import requests url = 'https://product.dangdang.com/410275442.html' header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0', # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' } response = requests.get(url,headers=header) with open('book_page.html', 'w', encoding='gbk') as file: file.write(response.text) print('网页内容已保存为book_page.html') |
题目二源代码:
| import re from urllib import request from bs4 import BeautifulSoup comments = [] comments_list = [] def get_comment(comment): count = 0 for i in comment: count = count + 1 comments.append(i.string) def get_score(score): pattern = re.compile('<span class="user-stars allstar(.*?) rating"') res = re.findall(pattern, str(score)) for irr in res: comments_list.append(float(irr)) header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0', # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8' } url_base = 'https://book.douban.com/subject/1255625/comments/?start={}&limit={}&status=P&sort=new_score' for i in range(0, 3): url = url_base.format(i * 20, (i + 1) * 20) try: req = request.Request(url, headers=header) html = request.urlopen(req).read() soup = BeautifulSoup(html, 'html.parser') get_score(soup) get_comment(soup.find_all("span", class_="short")) except Exception as e: print("出现了一个问题:", e) for j in range(0, 50): print(comments[j]) sum = 0.0 for j in range(0, 50): sum += float(comments_list[j]) print(sum / 50 * 2 / 10) |
题目三源代码:
| import re import requests header = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36 Edg/117.0.2045.60" } url="https://cs.lianjia.com/ershoufang/c3511059937033rs%E5%90%8D%E9%83%BD%E8%8A%B1%E5%9B%AD/" response = requests.get(url=url, headers=header).text name = re.findall('data-is_focus="" data-sl="">(.*?)</a>', response, re.S) # 名称介绍 region = re.findall('data-el="region">(.*?)</a>.*?target="_blank">(.*?)</a>', response, re.S) # 所在区域 price = re.findall('class="totalPrice totalPrice2".*?<span class="">(.*?)</span>', response, re.S) # 房价 information = re.findall('class="houseIcon"></span>(.*?)<', response, re.S) # 基本信息 unit_price = re.findall('class="unitPrice".*?<span>(.*?平)</span>', response, re.S) # 单价 arr=[] for n, r, p, i, u in zip(name, region, price, information, unit_price): r = r[0] + '-' + r[1] i = i.split('|') if len(i) == 7: data = { "名称介绍": n, "所在区域": r, "房价(W)": p, "房屋户型": i[0], "建筑面积": i[1], "房屋朝向": i[2], "装修情况": i[3], "所在层数": i[4], "房建": i[5], "建筑类型": i[6], "单价": u } if len(i) == 6: data = { "名称介绍": n, "所在区域": r, "房价(W)": p, "房屋户型": i[0], "建筑面积": i[1], "房屋朝向": i[2], "装修情况": i[3], "所在层数": i[4], "房建": '', "建筑类型": i[5], "单价": u } arr.append(data) import pandas as pd df = pd.DataFrame(arr) # 把数据放进表格中 df.drop_duplicates(inplace=True) # 进行去重 df.to_csv("D:/Temp/house.csv") # 保存的地址 |
题目四源代码:
| import os list1 = [] list2 = [] res = [] # 读取并处理文件seg1.txt with open('seg1.txt', 'r', encoding='utf-8') as f1: for line in f1: list1.append(line.strip('\n')) # 读取并处理文件seg2.txt with open('seg2.txt', 'r', encoding='utf-8') as f2: for line in f2: list2.append(line) # 结果处理 for i in range(0, min(len(list1), len(list2))): res.append(list1[i] + ' ' + list2[i][2] + '\n') # 写入结果 if not os.path.exists('seg.txt'): with open('seg.txt', 'w') as f: for i in res: f.write(i) else: print('文件已经存在!') |
题目五源代码:
| import os info_dict = dict() key = [] with open('merge.txt', 'r', encoding='utf-8') as f: for line in f: parts = line.split() num = parts[0] name = parts[1] count = parts[2] if info_dict.get(num) is None: key.append(num) info_dict[num] = count else: file_path = f"Seg{num} .txt" if not os.path.exists(file_path): with open(file_path, 'w', encoding='utf-8') as f1: f1.write(num + ' ' + name + ' ' + str(info_dict[num]) + ' ' + count + '\n') |
- 实验结果
题目一运行代码后生成book_page.html文件图:
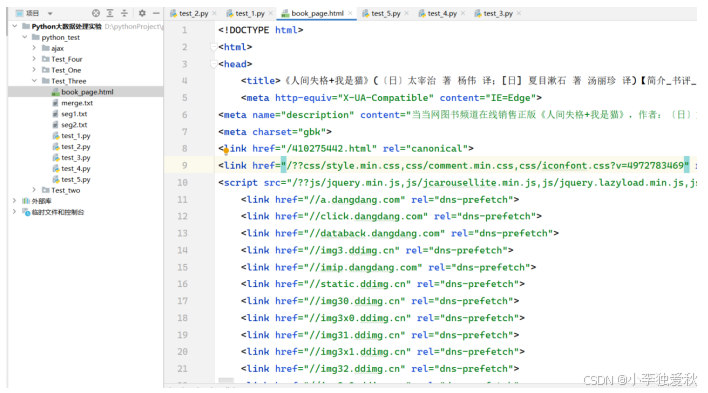
图 1.1 题目一运行代码后生成book_page.html文件图
题目一打开book_page.html页面的效果图:
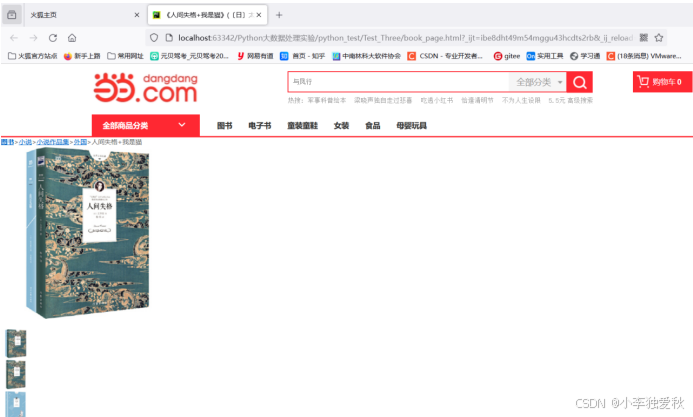
图 1.2 爬取结果图
题目二代码运行结果图(10分为满分):


图 3.1 题目三运行结果截图
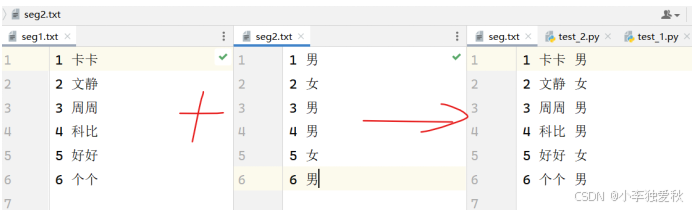
图 4.1题目四代码运行截图

- 实验体会
通过本次实验,我学会了如何使用Python编程语言和相关库进行网络爬虫和数据处理任务。具体来说,我掌握了以下技能和知识点:
1. 使用Python中的requests库和BeautifulSoup库来爬取网页内容,并保存为html格式文件。
2. 使用Python中的requests库和正则表达式来爬取特定内容并进行数据处理,例如计算评分的平均值。
3. 学习了如何爬取特定网站上的信息,并将其保存为Excel文件。
4. 熟悉了文件操作和数据处理技巧,如合并和拆分txt文件内容。
5. 掌握了如何使用pandas库来处理和保存数据。
总的来说,这次实验让我更熟练地掌握了Python编程语言的基础知识和相关库的使用方法,为我今后在数据处理和网络爬虫方面的工作提供了很好的基础和实践经验。希望能够通过不断的练习和实践,进一步提升自己的编程能力和解决问题的能力。