目录
1、线程概述
1.1 线程的定义
现代操作系统在运行一个程序时,会为其创建一个进程。例如,启动一个Java程序,操作系统就会创建一个Java进程。现代操作系统调度的最小单元是线程,也叫轻量级进程(Light Weight Process),在一个进程里可以创建多个线程,这些线程都拥有各自的计数器、堆栈和局部变量等属性,并且能够访问共享的内存变量。处理器在这些线程上高速切换,让使用者感觉到这些线程在同时执行。
1.2 多线程的优势
1.2.1 更多的处理器核心
随着处理器上的核心数量越来越多,以及超线程技术的广泛运用,现在大多数计算机都比以往更加擅长并行计算,而处理器性能的提升方式,也从更高的主频向更多的核心发展。如何利用好处理器上的多个核心也成了现在的主要问题。
线程是大多数操作系统调度的基本单元,一个程序作为一个进程来运行,程序运行过程中能够创建多个线程,而一个线程在一个时刻只能运行在一个处理器核心上。试想一下,一个单线程程序在运行时只能使用一个处理器核心,那么再多的处理器核心加入也无法显著提升该程序的执行效率。相反,如果该程序使用多线程技术,将计算逻辑分配到多个处理器核心上,就会显著减少程序的处理时间,并且随着更多处理器核心的加入而变得更有效率。
1.2.2 更快的响应时间
有时我们会编写一些较为复杂的代码(这里的复杂不是说复杂的算法,而是复杂的业务逻辑),例如,一笔订单的创建,它包括插入订单数据、生成订单快照、发送邮件通知卖家和记录货品销售数量等。用户从单击“订购”按钮开始,就要等待这些操作全部完成才能看到订购成功的结果。但是这么多业务操作,如何能够让其更快地完成呢?
在上面的场景中,可以使用多线程技术,即将数据一致性不强的操作派发给其他线程处理(也可以使用消息队列),如生成订单快照、发送邮件等。这样做的好处是响应用户请求的线程能够尽可能快地处理完成,缩短了响应时间,提升了用户体验。
1.3 多线程的挑战
1.3.1 上下文切换
CPU通过时间片分配算法来循环执行任务,当前任务执行一个时间片后会切换到下一个 任务。但是,在切换前会保存上一个任务的状态,以便下次切换回这个任务时,可以再加载这 个任务的状态。所以任务从保存到再加载的过程就是一次上下文切换。由于上下文切换带来的性能开销,当线程数量超过一定的阈值,会导致CPU时间片频繁切换,进而影响整个系统的性能。减少上下文切换的方法有:
- 无锁并发编程: 多线程竞争锁时,会引起上下文切换,所以多线程处理数据时,可以用一些办法来避免使用锁,如将数据的ID按照Hash算法取模分段,不同的线程处理不同段的数据。
- CAS算法: Java的Atomic包使用CAS算法来更新数据,而不需要加锁。
- 使用最少线程: 避免创建不需要的线程,比如任务很少,但是创建了很多线程来处理,这 样会造成大量线程都处于等待状态。
- 协程: 在单线程里实现多任务的调度,并在单线程里维持多个任务间的切换。
1.3.2 死锁
不管是Java还是数据库,产生死锁的原因及避免方法都是相通的,详见:JAVA知识体系之数据库篇——MySQL 6.4 死锁
1.3.3 资源限制
资源限制是指在进行并发编程时,程序的执行速度受限于计算机硬件资源或软件资源。例如,服务器的带宽只有2Mb/s,某个资源的下载速度是1Mb/s每秒,系统启动10个线程下载资源,下载速度不会变成10Mb/s,所以在进行并发编程时,要考虑这些资源的限制。硬件资源限制有带宽的上传/下载速度、硬盘读写速度和CPU的处理速度。软件资源限制有数据库的连接数和socket连接数等。
在并发编程中,将代码执行速度加快的原则是将代码中串行执行的部分变成并发执行,但是如果将某段串行的代码并发执行,因为受限于资源,仍然在串行执行,这时候程序不仅不会加快执行,反而会更慢,因为增加了上下文切换和资源调度的时间。
对于硬件资源限制,可以考虑使用集群并行执行程序。既然单机的资源有限制,那么就让程序在多机上运行。对于软件资源限制,可以考虑使用资源池将资源复用。比如使用连接池将数据库和Socket连接复用,或者在调用对方webservice接口获取数据时,只建立一个连接。
如何在资源限制的情况下,让程序执行得更快呢?方法就是,根据不同的资源限制调整程序的并发度,比如下载文件程序依赖于两个资源——带宽和硬盘读写速度。有数据库操作时,涉及数据库连接数,如果SQL语句执行非常快,而线程的数量比数据库连接数大很多,则某些线程会被阻塞,等待数据库连接。
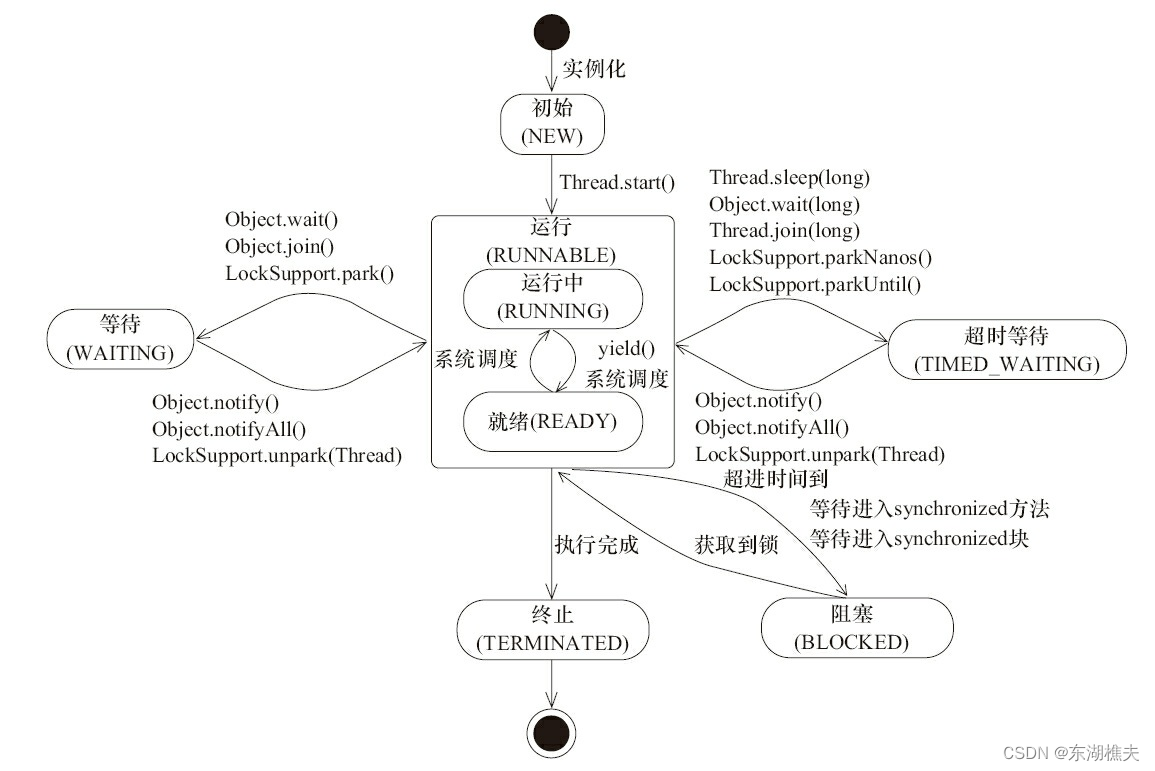
1.4 线程的状态
一般来说,在Java中,线程的状态一共是6种状态,分别是:
- NEW: 初始状态,线程被构建,但是还没有调用start方法。
- RUNNABLED: 运行状态,JAVA线程把操作系统中的就绪和运行两种状态统一称为“运行中”
- BLOCKED: 阻塞状态,表示线程进入等待状态,也就是线程因为某种原因放弃了CPU使用权,阻塞也分为几种情况:
等待阻塞: 运行的线程执行wait方法,jvm会把当前线程放入到等待队列;
同步阻塞: 运行的线程在获取对象的同步锁时,若该同步锁被其他线程锁占用了,那么jvm会把当前的线程放入到锁池中;
其他阻塞: 运行的线程执行Thread.sleep或者t.join方法,或者发出了I/O请求时,JVM会把当前线程设置为阻塞状态,当sleep结束、join线程终止、io处理完毕则线程恢复。 - WAITING: 等待状态。
- TIME_WAITING: 超时等待状态,超时以后自动返回。
- TERMINATED: 终止状态,表示当前线程执行完毕。
1.5 线程的终止
Thread提供了线程的一些操作方法,比如stop、suspend等,这些方法可以终止一个线程或者挂起一个线程,但是这些方法都不建议大家使用。原因比较简单,举个例子,假设一个线程中,有多个任务在执行,此时,如果调用stop方法去强行中断,那么这个时候相当于是发送一个指令告诉操作系统把这个线程结束掉,但是操作系统的这个结束动作完成不代表线程中的任务执行完成,很可能出现线程的任务执行了一般被强制中断,最终导致数据产生问题。这种行为类似于在linux系统中执行 kill -9类似,它是一种不安全的操作。
在正常情况下,线程是不需要人为干预去结束的。如果要强制结束,只能走stop方法。
那在哪些情况下,线程的中断需要外部干预呢?
- 线程中存在无限循环执行,比如while(true)循环。
- 线程中存在一些阻塞的操作,比如sleep、wait、join等。
1.5.1 存在循环的线程
public class MyThread extends Thread {
public void run() {
while (true) {
System.out.println("MyThread.run()");
}
}
}
MyThread myThread1 = new MyThread();
myThread1.start();
按照开发的思维来说,首先要解决的就是,while(true)这个循环,必须要有一个结束条件,其次是
要在其他地方能够修改这个结束条件让该线程感知到变化。假设我们把while(true)改成while(flag),这
个flag可以作为共享变量被外部修改,修改之后使得循环条件无法被满足,从而退出循环并且结束线
程。
这段逻辑其实非常简单,其实就是给了线程一个退出的条件,如果没有这个条件,那么线程将会一直运行。实际上,在Java提供了一个 interrupt 方法,这个方法就是实现线程中断操作的,它的作用和上面讲的这个案例的作用一样。
1.5.2 interrupt方法
当其他线程通过调用当前线程的interrupt方法,表示向当前线程打个招呼,告诉他可以中断线程的执行了,至于什么时候中断,取决于当前线程自己。线程通过检查自身是否被中断来进行相应,可以通过isInterrupted()来判断是否被中断。
这种通过标识位或者中断操作的方式能够使线程在终止时有机会去清理资源,而不是武断地将线程停止,因此这种终止线程的做法显得更加安全和优雅。
public class InterruptDemo {
private static int i;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
//默认情况下 isInterrupted返回false、通过thread.interrupt变成了true
i++;
}
System.out.println("Num:" + i);
}, "interruptDemo");
thread.start();
TimeUnit.SECONDS.sleep(1);
thread.interrupt();
}
}
1.5.3 处于阻塞状态下的线程中断
另外一种情况,就是当线程处于阻塞状态下时,我想要中断这个线程,那怎么做呢?
public class InterruptDemo {
private static int i;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
while (!Thread.currentThread().isInterrupted()) {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
Thread.currentThread().interrupt(); //再次中断
}
}
System.out.println("Num:" + i);
}, "interruptDemo");
thread.start();
TimeUnit.SECONDS.sleep(1);
thread.interrupt();
System.out.println(thread.isInterrupted());
}
}
从这个例子中反馈出一个问题,我们平时在线程中使用的sleep、wait、join等操作,它都会抛出一个InterruptedException异常,为什么会抛出异常,是因为它在阻塞期间,必须要能够响应被其他线程发起中断请求之后的一个响应,而这个响应是通过InterruptedException来体现的。
但是这里需要注意的是,在这个异常中如果不做任何处理的话,我们是无法去中断线程的,因为当前的异常只是响应了外部对于这个线程的中断命令,同时,线程的中断状态也会复位。所以,InterruptedException异常的抛出并不意味着线程必须终止,而是提醒当前线程有中断的操作发
生,至于接下来怎么处理取决于线程本身,比如:
- 直接捕获异常不做任何处理。
- 将异常往外抛出
- 停止当前线程,并打印异常信息
1.6 线程的通信
线程开始运行,拥有自己的栈空间,就如同一个脚本一样,按照既定的代码一步一步地执 行,直到终止。但是,每个运行中的线程,如果仅仅是孤立地运行,那么没有一点儿价值,或者说价值很少,如果多个线程能够相互配合完成工作,这将会带来巨大的价值。
线程间通信的方式有许多种,这里仅做一个总结,具体原理将嵌套在后续章节对应的内容中:
- volatile: 关键字volatile可以用来修饰字段(成员变量),就是告知程序任何对该变量的访问均需要从共享内存中获取,而对它的改变必须同步刷新回共享内存,它能保证所有线程对变量访问的可见性。
- synchronized: 关键字synchronized可以修饰方法或者以同步块的形式来进行使用,它主要确保多个线程在同一个时刻,只能有一个线程处于方法或者同步块中,它保证了线程对变量访问的可见性和排他性。
- wait/notify: 等待/通知机制,是指一个线程A调用了对象O的wait()方法进入等待状态,而另一个线程B调用了对象O的notify()或者notifyAll()方法,线程A收到通知后从对象O的wait()方法返回,进而 执行后续操作。上述两个线程通过对象O来完成交互,而对象上的wait()和notify/notifyAll()的关系就如同开关信号一样,用来完成等待方和通知方之间的交互工作。
- join: 如果一个线程A执行了thread.join()语句,其含义是:当前线程A等待thread线程终止之后才 从thread.join()返回。线程Thread除了提供join()方法之外,还提供了join(long millis)和join(long millis,int nanos)两个具备超时特性的方法。这两个超时方法表示,如果线程thread在给定的超时时间里没有终止,那么将会从该超时方法中返回。
- Condition: Condition实际上就是J.U.C版本的wait/notify。可以让线程基于某个条件去等待和唤醒。
2、并发编程的安全性
2.1 原子性问题
2.1.1 原子性问题的现象
在下面的案例中,演示了两个线程分别去去调用 demo.incr 方法来对 i 这个变量进行叠加,预期结果应该是20000,但是实际结果却是小于等于20000的值。
public class Demo {
int i = 0;
public void incr() {
i++;
}
public static void main(String[] args) {
Demo demo = new Demo();
Thread[] threads = new Thread[2];
for (int j = 0; j < 2; j++) {
threads[j] = new Thread(() -> {
// 创建两个线程
for (int k = 0; k < 10000; k++) {
// 每个线程跑10000次
demo.incr();
}
});
threads[j].start();
}
try {
threads[0].join();
threads[1].join();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(demo.i);
}
}
2.1.2 原子性问题的本质
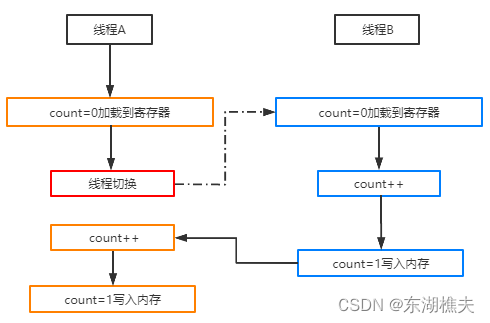
count++是属于Java高级语言中的编程指令,而这些指令最终可能会有多条CPU指令来组成,而count++最终会生成3条指令, 通过javap -v xxx.class 查看字节码指令如下:
public incr()V
L0
LINENUMBER 13 L0
ALOAD 0
DUP
GETFIELD com/gupaoedu/pb/Demo.i : I // 访问变量i
ICONST_1 // 将整形常量1放入操作数栈
IADD // 把操作数栈中的常量1出栈并相加,将相加的结果放入操作数栈
PUTFIELD com/gupaoedu/pb/Demo.i : I // 访问类字段(类变量),复制给Demo.i这个变量
一个CPU核心在同一时刻只能执行一个线程,如果线程数量远远大于CPU核心数,就会发生线程的切换,这个切换动作可以发生在任何一条CPU指令执行完之前。对于 i++ 这三个cpu指令来说,如果线程A在执行指令1之后,做了线程切换,假设切换到线程B,线程B同样执行CPU指令,就会导致最终的结果是1,而不是2。
2.1.3 原子性问题的解决方案(乐观锁CAS)
原子性的解决方案有两种,一种是悲观锁例如synchronized,一种是乐观锁CAS(也叫自旋锁)。由于除了synchronized的偏向锁,其他几乎所有的锁抢锁过程都涉及到CAS,且synchronized在第3章有重点介绍,这里主要讲CAS。
CAS(Compare-And-Swap),它是一条CPU并发原语,用于判断内存中某个位置的值是否为预期值,如果是则更改为新的值,这个过程是原子的。CAS并发原语体现在Java中就是sun.misc.Unsafe类中的各个方法。调用UnSafe类中的CAS方法,JVM会帮我们实现CAS汇编指令。这是一套完全依赖于硬件的功能,通过它实现了原子操作。
JVM中的CAS操作正是利用了处理器提供的CMPXCHG指令实现的。自旋CAS实现的基本思路就是循环进行CAS操作直到成功为止。
2.2 从硬件层面分析JVM的可见性、有序性问题
在整个计算机的发展历程中,除了CPU、内存以及I/O设备不断迭代升级来提升计算机处理性能之外,还有一个非常核心的矛盾点,就是这三者在处理速度的差异。CPU的计算速度是非常快的,其次是内存、最后是IO设备(比如磁盘),也就是CPU的计算速度远远高于内存以及磁盘设备的I/O速度。为了平衡这三者之间的速度差异,最大化的利用CPU。所以在硬件层面、操作系统层面、编译器层面做出了很多的优化:
- CPU增加了高速缓存。
- 操作系统增加了进程、线程。通过CPU的时间片切换最大化的提升CPU的使用率。
- 编译器的指令优化,更合理的去利用好CPU的高速缓存。
2.2.1 CPU高速缓存
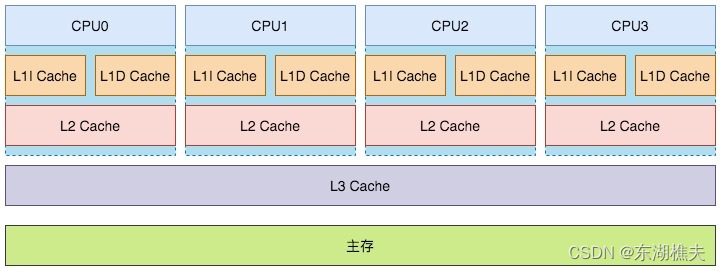
CPU在做计算时,和内存的IO操作是无法避免的,而这个IO过程相对于CPU的计算速度来说是非常耗时,基于这样一个问题,所以在CPU层面设计了高速缓存,这个缓存行可以缓存存储在内存中的数据,CPU每次会先从缓存行中读取需要运算的数据,如果缓存行中不存在该数据,才会从内存中加载,通过这样一个机制可以减少CPU和内存的交互开销从而提升CPU的利用率。对于主流的x86平台,cpu的缓存行(cache)分为L1、L2、L3总共3级。
2.2.2 缓存一致性问题的解决方案
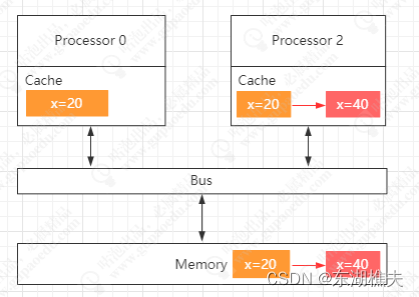
在多线程环境中,当多个线程并行执行加载同一块内存数据时,由于每个CPU都有自己独立的L1、L2缓存,所以每个CPU的这部分缓存空间都会缓存到相同的数据,并且每个CPU执行相关指令时,彼此之间不可见,就会导致缓存的一致性问题,具体流程如下图所示:
为了解决缓存不一致的问题,在 CPU 层面做了很多事情, 主要提供了两种解决办法。
总线锁
在多 cpu 下,当其中一个处理器要对共享内存进行操作的时候,在总线上发出一个 LOCK# 信号,这个信号使得其他处理器无法通过总线来访问到共享内存中的数据,总线锁定把 CPU 和内存之间的通信锁住了,这使得锁定期间,其他处理器不能操作其他内存地址的数据,总线锁定的开销比较大,这种机制显然是不合适的。
缓存锁
相比总线锁,缓存锁即降低了锁的力度。核心机制是基于缓存一致性协议来实现的。为了达到数据访问的一致,需要各个处理器在访问缓存时遵循一些协议,在读写时根据协议来操作,常见的协议有 MSI、MESI、MOSI 等。最常见的就是 MESI协议。MESI表示缓存行的四种状态,分别是:
- M(Modify) 表示共享数据只缓存在当前 CPU 缓存中, 并且是被修改状态,也就是缓存的数据和主内存中的数据不一致。
- E(Exclusive) 表示缓存的独占状态,数据只缓存在当前 CPU 缓存中,并且没有被修改。
- S(Shared) 表示数据可能被多个 CPU 缓存,并且各个缓存中的数据和主内存数据一致。
- I(Invalid) 表示缓存已经失效。
MESI协议执行流程示例:
- CPU1从内存中将变量a加载到缓存中,并将变量a的状态改为E(独享),并通过总线嗅探机制对内存中变量a的操作进行嗅探。
- 此时,CPU2读取变量a,总线嗅探机制会将CPU1中的变量a的状态置为S(共享),并将变量a加载到CPU2的缓存中,状态为S。
- CPU1对变量a进行修改操作,此时CPU1中的变量a会被置为M(修改)状态,而CPU2中的变量a会被通知,改为I(无效)状态,此时CPU2中的变量a做的任何修改都不会被写回内存中。
- CPU1将修改后的数据写回内存,并将变量a置为E(独占)状态。
- 此时,CPU2通过总线嗅探机制得知变量a已被修改,会重新去内存中加载变量a,同时CPU1和CPU2中的变量a都改为S状态。
MESI失效的场景:
- CPU不支持缓存一致性协议。
- MESI是对单独一个缓存行进行加锁,此时如果这个数据的大小超出了一个缓存行的大小,那么也会无效。
需要注意的是,缓存锁与缓存一致性协议并不是相同的,在《Intel® 64 and IA-32 Architectures Software Developer’s Manual》中原文如下(详见第六章):通过lock前缀指令,会锁定变量缓存⾏区域并写回主内存,这个操作称为“缓存锁定”,缓存⼀致性机制会阻⽌同时修改被两个以上处理器缓存的内存区域数据。⼀个处理器的缓存回写到内存会导致其他处理器的缓存⽆效。 说明缓存锁的作用是让缓存中的数据立刻写入内存,进而通过MESI协议让其他CPU的缓存立即失效。并且还有一个非常重要的区分就是,MESI是CPU自动实现的,对任何变量都会生效。而缓存锁或者总线锁只对加了汇编指令Lock前缀的变量生效(volatile的关键作用之一就是在这个变量前面加入了Lock前缀)。
以上这段是精华中的精华,本人花了数十个小时翻阅了大量资料得到的结论。
2.2.3 伪共享
缓存是由缓存行组成的,通常是64字节(常用处理器的缓存行是64字节的,比较旧的处理器缓存行是32字节的),并且它有效地引用主内存中的一块地址。一个java的long类型是8字节,因此在一个缓存行中可以存8个long类型的变量。
在程序运行的过程中,缓存每次更新都从主内存中加载连续的64个字节。因此,如果访问一个long类型的数组时,当数组中的一个值被加载到缓存中时,另外7个元素也会被加载到缓存中。但是,如果使用的数据结构中的项在内存中不是彼此相邻的,比如链表,那么将得不到免费缓存加载带来的好处。
不过,这种免费加载也有一个问题。如果一个cpu核心的线程在对a进行修改,另一个cpu核心的线程却在对b进行读取。当前者修改a时,会把a和b同时加载到前者核心的缓存行中,更新完a后其它所有包含a的缓存行都将失效,因为其它缓存中的a不是最新值了。而当后者读取b时,发现这个缓存行已经失效了,需要从主内存中重新加载。
这样就出现了一个问题,b和a完全不相干,每次却要因为a的更新需要从主内存重新读取,它被缓存未命中给拖慢了。这就是传说中的伪共享。
public class FalseSharingTest {
static class Pointer {
volatile long x;
volatile long y;
}
public static void main(String[] args) throws InterruptedException {
testPointer(new Pointer());
}
private static void testPointer(Pointer pointer) throws InterruptedException {
long start = System.currentTimeMillis();
Thread t1 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.x++;
}
});
Thread t2 = new Thread(() -> {
for (int i = 0; i < 100000000; i++) {
pointer.y++;
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(System.currentTimeMillis() - start);
System.out.println(pointer);
}
}
上述代码中,我们在内部类中声明了x,y两个变量,然后启动了两个线程分别的x,y进行1亿次累加,由于伪共享的原因,上述代码的执行时间是3268ms。
解决伪共享的方式有两种,一种是在两个long类型之间增加缓存行填充,确保这两个变量不在同一个缓存行。这种方式由于p1-p7变量没有真正使用,有可能被JVM优化掉。
static class Pointer {
volatile long x;
long p1, p2, p3, p4, p5, p6, p7;
volatile long y;
}
另一种就是通过注解@sun.misc.Contended实现(本质是一样的)。通过这种方式需要在JVM启动参数里配置-XX:-RestrictContended才能生效。
static class Pointer {
@sun.misc.Contended
volatile long x;
volatile long y;
}
2.2.4 MESI优化带来的可见性问题
2.2.4.1 Store buffer
缓存的消息传递是要时间的,这就使其切换时会产生延迟。当一个缓存被切换状态时其他缓存收到消息完成各自的切换并且发出回应消息这么一长串的时间中CPU都会等待所有缓存响应完成。可能出现的阻塞都会导致各种各样的性能问题和稳定性问题。
比如你需要修改本地缓存中的一条信息,那么你必须将 I(无效)状态通知到其他拥有该缓存数据的CPU缓存中,并且等待确认。 等待确认的过程会阻塞处理器,这会降低处理器的性能。应为这个等待远远比一个指令的执行时间长的多。
为了避免这种CPU运算能力的浪费,Store Bufferes被引入使用。处理器把它想要写入到主存的值写到缓存,然后继续去处理其他事情。当所有失效确认(Invalidate Acknowledge)都接收到时,数据才会最终被提交。
这么做有个问题:当写操作被存入Store buffer并且未刷入缓存时,CPU执行了下一条读指令,就会读到缓存中的脏数据。为了解决这个问题,处理器会尝试从Store buffer中读取值,这个的解决方案称为Store Forwarding,它使得加载的时候,如果Store buffer中存在,则进行返回。
但是由于Store buffer本身是异步的,就没有办法保证其他CPU准时接收并处理该CPU的失效请求,从而导致自己的脏数据没有被置位I(Invalid)(就算接收并处理了请求将缓存状态更新为I,此时也可能存在新数据未同步到内存,导致从内存中继续读取老数据)。
2.2.4.2 Invalid queue
执行失效也不是一个简单的操作,它需要处理器去处理。此外,存储缓存(Store Buffers)并不是无穷大的, 所以处理器有时需要等待失效确认的返回。这两个操作都会使得性能大幅降低。为了应付这种情况,引入了失效队列。它们的约定如下:
- 对于所有的收到的Invalidate请求,Invalidate Acknowlege消息 必须立刻发送。
- Invalidate并不真正执行,而是 被放在一个特殊的队列中,在方便的时候才会去执行。
- 处理器不会发送任何消息给所处理的缓存条目,直到它处理Invalidate。
2.2.4.3 可见性问题的解决方案
由于Store buffer和Invalid queue的存在,使得缓存的同步出现延迟。从用户的角度上讲,看起来就像是指令重排序导致的可见性问题。例如:
value = 3;
void exeToCPUA(){
value = 10;
isFinsh = true;
}
void exeToCPUB(){
if(isFinsh){
//value一定等于10?!
assert value == 10;
}
}
试想一下开始执行时,CPU A保存着finished在E(独享)状态,而value并没有保存在它的缓存中。(例如,Invalid)。在这种情况下,value会比finished更迟地抛弃存储缓存。完全有可能CPU B读取finished的值为true,而value的值不等于10。即isFinsh的赋值在value赋值之前。
由于处理器并不知道什么时候优化是允许的,而什么时候并不允许。干脆将这个任务丢给了写代码的人。这就是内存屏障(Memory Barriers)。
- 写屏障 Store Memory Barrier 是一条告诉处理器在执行这之后的指令之前,先执行所有已经在store buffer中的保存的指令。
- 读屏障Load Memory Barrier 是一条告诉处理器在执行任何的加载前,先执行所有已经在Invalid Queue中的失效操作的指令。
2.3 Java内存模型
2.3.1 JMM定义
在Java中,所有实例域、静态域和数组元素都存储在堆内存中,堆内存在线程之间共享 。局部变量(Local Variables),方法定义参数和异常处理器参数不会在线程之间共享,它们不会有内存可见性问题,也不受内存模型的影响。
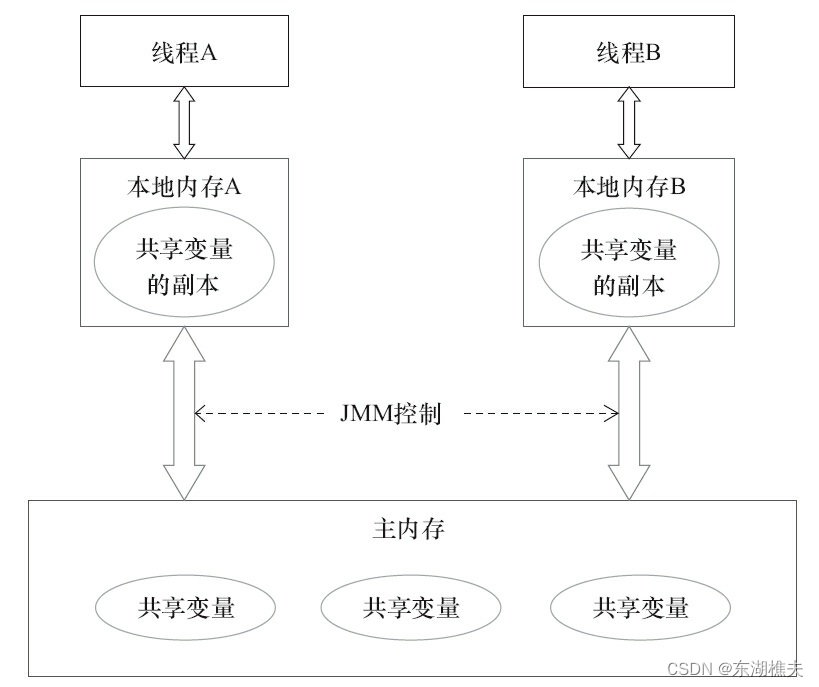
Java线程之间的通信由Java内存模型(JMM)控制,JMM决定一个线程对共享变量的写入何时对另一个线程可见。从抽象的角度来看,JMM定义了线程和主内存之间的抽象关系:线程之间的共享变量存储在主内存(Main Memory)中,每个线程都有一个私有的本地内存(Local Memory),本地内存中存储了该线程以读/写共享变量的副本。本地内存是JMM的一个抽象概念,并不真实存在。它涵盖了缓存、写缓冲区、寄存器以及其他的硬件和编译器优化。Java内存模型的抽象示意如图所示。
2.3.2 重排序
在执行程序时,为了提高性能,编译器和处理器常常会对指令做重排序。
重排序遵循的原则:
- 数据依赖性:例如a=1;b=a;由于下一条指令依赖上一条指令的结果,此时不会进行重排序。
- as-if-serial:不管怎么重排序,单线程程序的执行结果不能被改变。
重排序分3种类型:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
- 指令级并行的重排序。现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。(前面重点介绍过)
上述的1属于编译器重排序,2和3属于处理器重排序。这些重排序可能会导致多线程程序 出现内存可见性问题。对于编译器,JMM的编译器重排序规则会禁止特定类型的编译器重排序(不是所有的编译器重排序都要禁止)。对于处理器重排序,JMM的处理器重排序规则会要求Java编译器在生成指令序列时,插入特定类型的内存屏障指令,通过内存屏障指令来禁止特定类型的处理器重排序。
JMM属于语言级的内存模型,它确保在不同的编译器和不同的处理器平台之上,通过禁止特定类型的编译器重排序和处理器重排序,为程序员提供一致的内存可见性保证。
2.3.3 顺序一致性
当程序未正确同步时,就会存在数据竞争。JMM规范对数据竞争的定义如下:
- 在一个线程中写一个变量,
- 在另一个线程读同一个变量,
- 而且写和读没有通过同步来排序。
当代码中包含数据竞争时,程序的执行往往产生违反直觉的结果。如果一个多线程程序能正确同步,这个程序将是一个没有数据竞争的程序。顺序一致性是程序执行过程中可见性和顺序的强有力保证。在顺序一致的执行过程中,所有操作(如读和写)间存在一个全序关系,与程序的顺序一致。每个操作都是原子的且立即对所有线程可见。如果一个程序没有数据竞争,那么该程序的执行看起来将是顺序一致的。
如果一组操作要保持原子性而未得到保证时,无论它的顺序一致性和数据竞争是怎样的状态,仍然可能会出现错误。所以内存模型中操作不仅仅需要有顺序一致性,还需要有原子性。
2.3.4 happens-before
- 程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的 读。
- 传递性规则:如果A happens-before B,且B happens-before C,那么A happens-before C。
- start()规则:如果线程A执行操作ThreadB.start()(启动线程B),那么A线程的 ThreadB.start()操作happens-before于线程B中的任意操作。
- join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before于线程A从ThreadB.join()操作成功返回。
2.3.5 volatile
volatile的内存语义:
- 在每个volatile写操作的前面插入一个StoreStore屏障。
- 在每个volatile写操作的后面插入一个StoreLoad屏障。
- 在每个volatile读操作的后面插入一个LoadLoad屏障。
- 在每个volatile读操作的后面插入一个LoadStore屏障。
volatile的实际作用:
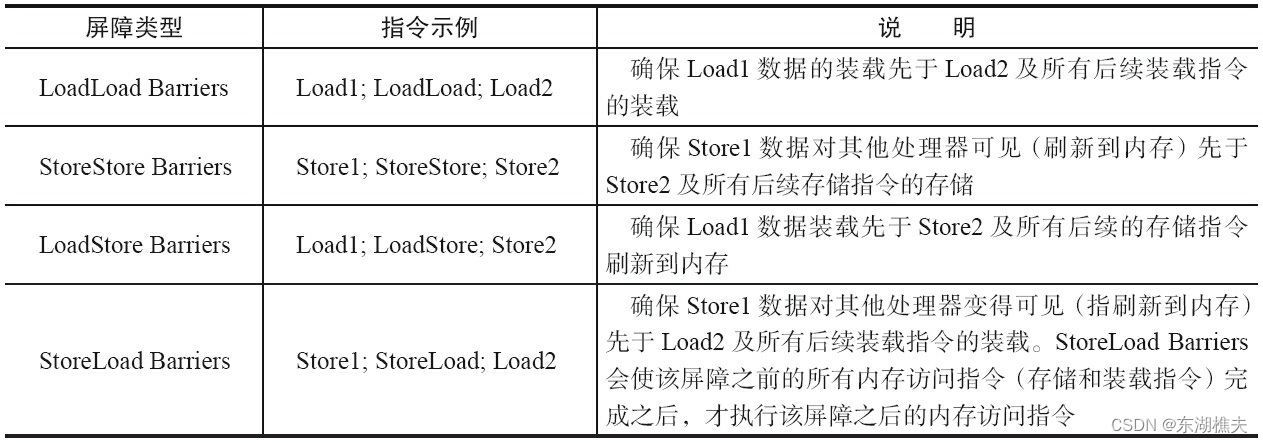
- 禁止了编译器优化重排序和指令级并行重排序。
- 向CPU发出lock指令,通过总线锁(缓存锁+缓存一致性协议)的方式保证可见性。
3、synchronized关键字
3.1 synchronized的基本应用
synchronized有三种方式来加锁,不同的修饰类型,代表锁的控制粒度:
- 修饰实例方法,作用于当前实例加锁,进入同步代码前要获得当前实例的锁。
- 静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁。
- 修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
3.2 synchronized的原理
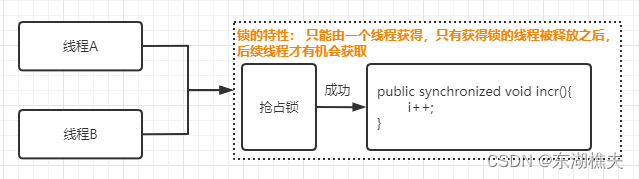
Synchronized到底帮我们做了什么,为什么能够解决原子性呢?在没有加锁之前,多个线程去调用incr()方法时,没有任何限制,都是可以同时拿到这个i的值进行 ++ 操作,但是当加了Synchronized锁之后,线程A和B就由并行执行变成了串行执行。
synchronized用的锁是存在Java对象头的MarkWord里,内容详见:JAVA知识体系之JVM篇(新)4.2.2 对象的内存布局
3.3 synchronized锁的升级
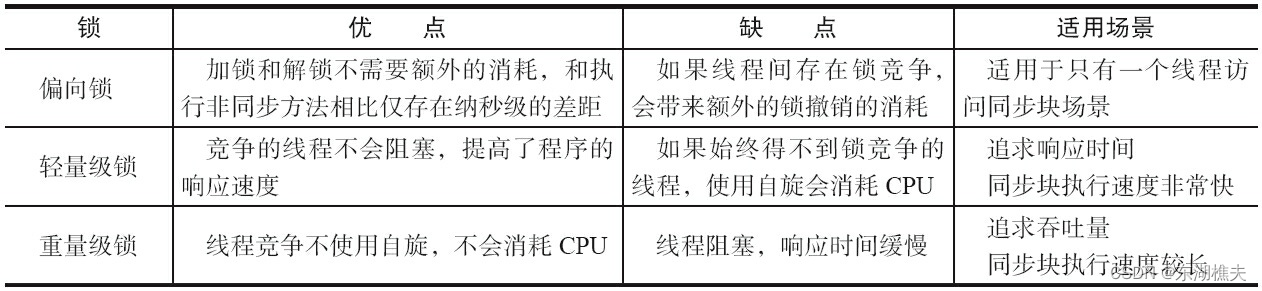
JDK1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,在JDK1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
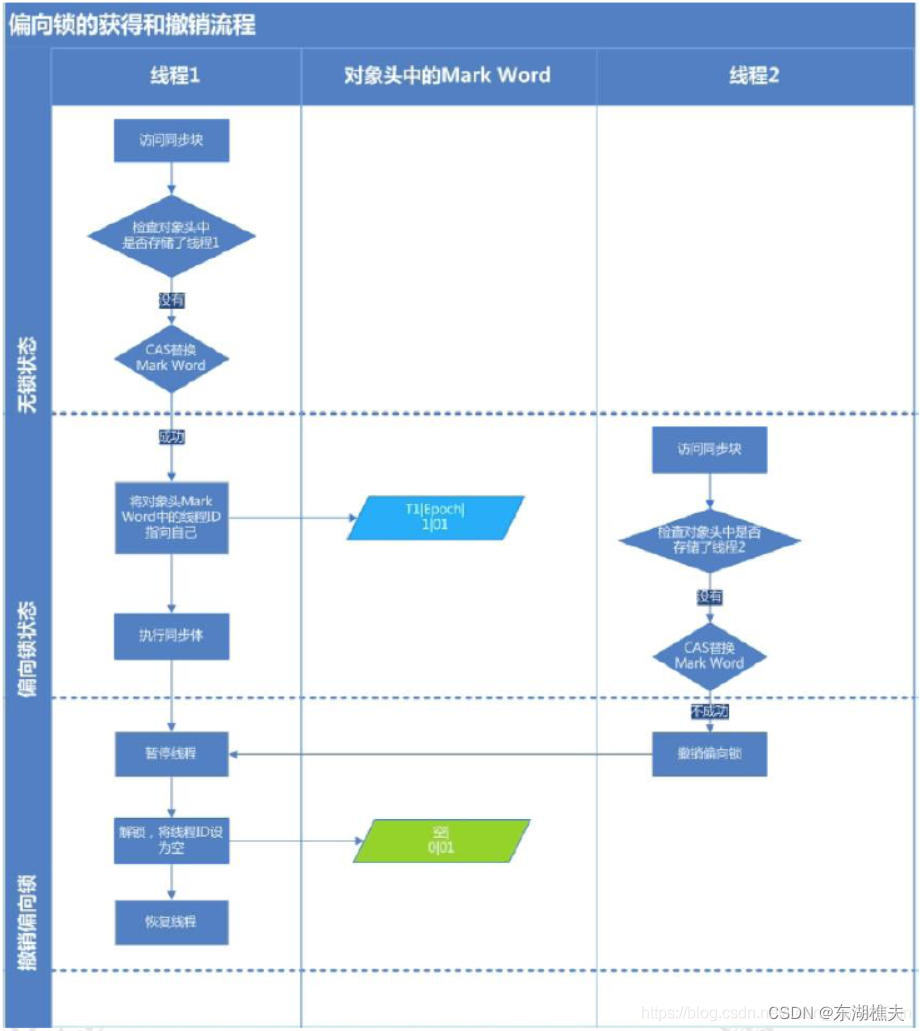
3.3.1 偏向锁
HotSpot的作者经过研究发现,大多数情况下,锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程ID,以后该线程在进入和退出同步块时不需要进行CAS操作来加锁和解锁,只需简单地测试一下对象头的Mark Word里是否存储着指向当前线程的偏向锁。如果测试成功,表示线程已经获得了锁。如果测试失败,则需要再测试一下Mark Word中偏向锁的标识是否设置成1(表示当前是偏向锁):如果没有设置,则使用CAS竞争锁;如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
偏向锁的撤销(revoke)是⼀个很特殊的操作,为了执⾏撤销操作,需要等待全局安全点,此时所有的⼯作线程都停⽌了执⾏。执行过程如下:
- 查看偏向的线程是否存活,如果已经死亡,则直接撤销偏向锁。
- 偏向的线程是否还在同步块中,如果不在,则撤销偏向锁。如果在同步块中,升级为轻量级锁。
3.3.2 轻量级锁
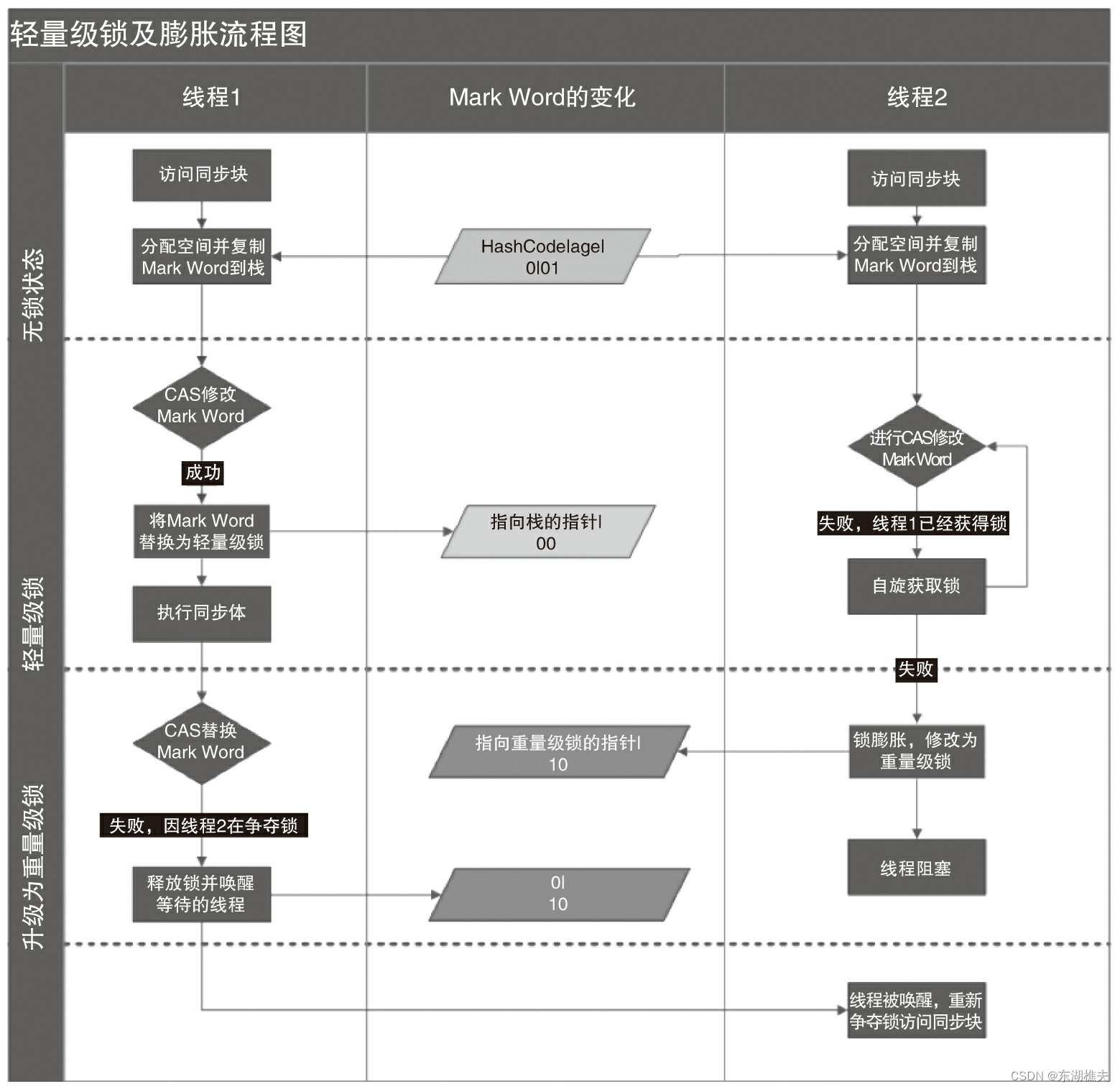
线程在执行同步块之前,JVM会先在当前线程的栈桢中创建用于存储锁记录的空间,并将对象头中的Mark Word复制到锁记录中,官方称为Displaced Mark Word。然后线程尝试使用CAS将对象头中的Mark Word替换为指向锁记录的指针。如果成功,当前线程获得锁,如果失败,表示其他线程竞争锁,当前线程便尝试使用自旋来获取锁。
轻量级解锁时,会使用原子的CAS操作将Displaced Mark Word替换回到对象头,如果成功,则表示没有竞争发生。如果失败,表示当前锁存在竞争,锁就会膨胀成重量级锁。
因为自旋会消耗CPU,为了避免无用的自旋(比如获得锁的线程被阻塞住了),一旦锁升级成重量级锁,就不会再恢复到轻量级锁状态。当锁处于这个状态下,其他线程试图获取锁时, 都会被阻塞住,当持有锁的线程释放锁之后会唤醒这些线程,被唤醒的线程就会进行新一轮的夺锁之争。
3.3.3 各级别锁的对比
4、J.U.C
4.1 Lock
4.1.1 Lock API
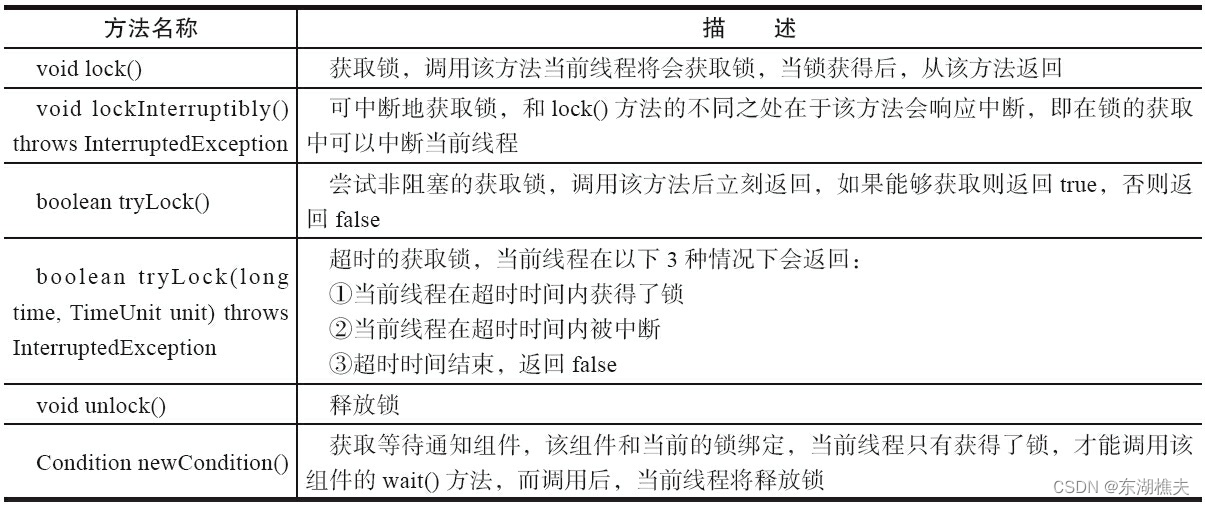
JDK1.5之后,并发包中新增 了Lock接口(以及相关实现类)用来实现锁功能,它提供了与synchronized关键字类似的同步功能,只是在使用时需要显式地获取和释放锁。虽然它缺少了(通过synchronized块或者方法所提供的)隐式获取释放锁的便捷性,但是却拥有了锁获取与释放的可操作性、可中断的获取锁以及超时获取锁等多种synchronized关键字所不具备的同步特性。
Lock是一个接口,它定义了锁获取和释放的基本操作,API如下:
4.1.2 ReentrantLock基于AQS的抢锁和释放锁的过程(以非公平锁为例)
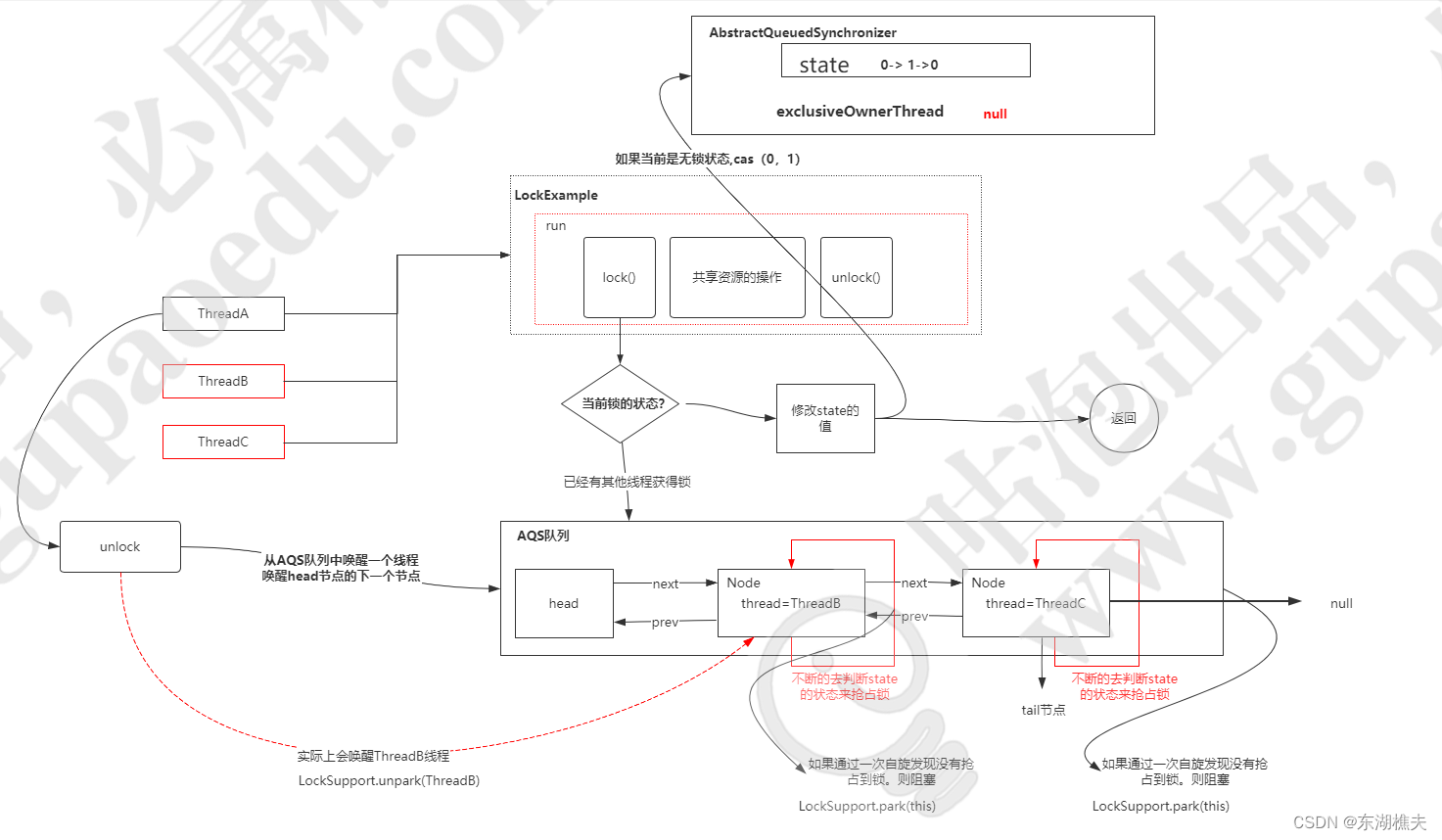
抢锁过程
1、先基于CAS尝试两次抢锁
// 抢锁入口
final void lock() {
// CAS更新状态
if (compareAndSetState(0, 1))
// 更新成功则把当前持锁线程更新为自己
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
public final void acquire(int arg) {
//再次尝试抢锁
if (!tryAcquire(arg) &&
// 再次抢锁失败则包装成Node节点并加入AQS队列
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
// 判断当前锁是否已释放,已释放再次抢锁
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
// 判断当前锁是否为自己持有(重入锁)
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
// 若为重入锁则重入次数增加
setState(nextc);
return true;
}
return false;
}
2、加入队列并进行自旋等待
// 回到第一次抢锁失败的代码
public final void acquire(int arg) {
if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
// 添加一个排它锁Node
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
// 队列不为空,直接入队
if (pred != null) {
node.prev = pred;
// 节点插入到队列尾部
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
// 队列为空,需要初始化头节点再入队
enq(node);
return node;
}
// 初始化头结点再入队
private Node enq(final Node node) {
// 死循环
for (;;) {
Node t = tail;
// 初始化头节点
if (t == null) {
if (compareAndSetHead(new Node()))
tail = head;
} else {
// 节点插入到队列尾部
node.prev = t;
if (compareAndSetTail(t, node)) {
t.next = node;
return t;
}
}
}
}
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
// 若该节点在AQS队列头部则再次尝试抢锁
final Node p = node.predecessor();
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
// 判断是否需要进行中断,需要则调用parkAndCheckInterrupt进行中断
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
// 抢锁成功,将节点置位失效
if (failed)
cancelAcquire(node);
}
}
// 判断是否进行中断,如果因为原因返回false,则会通过上一个方法继续进入下一次循环
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;
// 上一个节点有效,则直接中断(说明不在队列头部,且前面还有需要抢锁的线程)
if (ws == Node.SIGNAL)
return true;
// 上一个节点无效,则删除上一个节点,循环遍历
if (ws > 0) {
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
// 看起来跟共享锁有关,0或者-3都需要更新为-1
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;
}
//ThreadB、 ThreadC、ThreadD、ThreadE -> 都会阻塞在下面这个代码的位置.
private final boolean parkAndCheckInterrupt() {
//被唤醒. (interrupt()->)
LockSupport.park(this);
//中断状态(是否因为中断被唤醒的.)
return Thread.interrupted();
}
释放过程
public final boolean release(int arg) {
// 尝试释放锁
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
// 唤醒队列的第一个线程(对应第二个节点,头结点是个空节点)
unparkSuccessor(h);
return true;
}
return false;
}
// 正常重入锁是逐层释放,releases=1,有特殊情况直接全部释放,例如await
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
// 线程是否空闲,如果是重入锁为释放完应该是false
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
// 唤醒队列的第一个线程
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
// 如果s节点失效则取下一个
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
4.1.3 condition
基本用法
1、ConditionDemoAwait.java
public class ConditionDemoAwait implements Runnable {
private Lock lock;
private Condition condition;
public ConditionDemoAwait(Lock lock, Condition condition) {
this.lock = lock;
this.condition = condition;
}
@Override
public void run() {
System.out.println("begin - ConditionDemoWait");
lock.lock();
try {
condition.await();
//让当前线程阻塞,Object.wait();
System.out.println("end - ConditionDemoWait");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
2、ConditionDemoSignal.java
public class ConditionDemoSignal implements Runnable {
private Lock lock;
private Condition condition;
public ConditionDemoSignal(Lock lock, Condition condition) {
this.lock = lock;
this.condition = condition;
}
@Override
public void run() {
System.out.println("begin - ConditionDemeNotify");
lock.lock();
try {
condition.signal();
System.out.println("end - ConditionDemeNotify");
} catch (Exception e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
}
源码分析
1、执行await方法
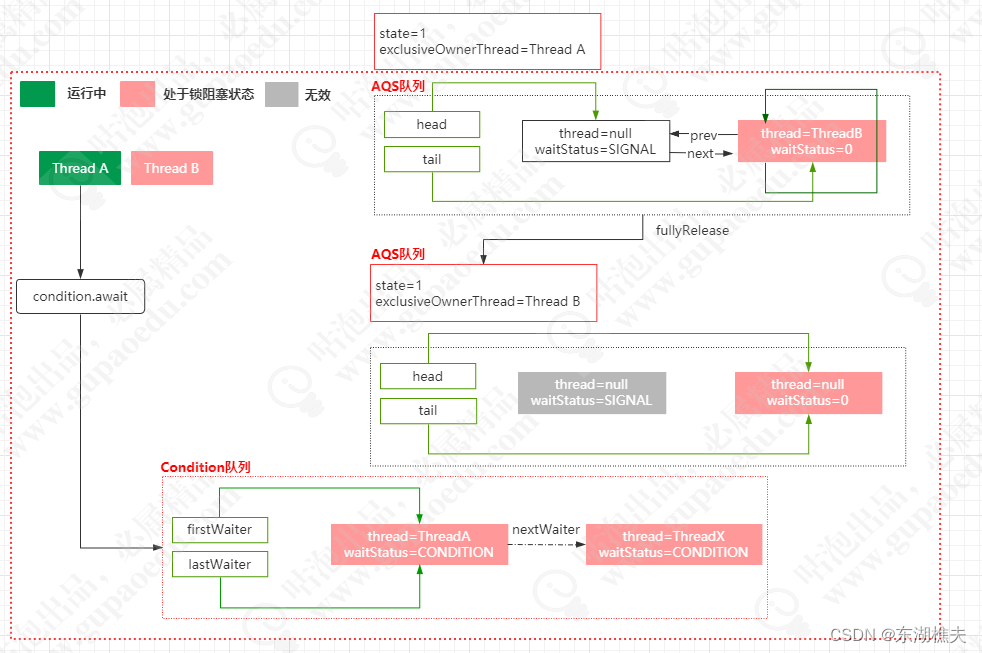
public final void await() throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
// 添加到condition队列
Node node = addConditionWaiter();
//完全释放锁(考虑重入问题)
long savedState = fullyRelease(node);
int interruptMode = 0;
// 判断当前线程是否进入AQS,signal的时候会把该线程移入AQS
while (!isOnSyncQueue(node)) {
//阻塞当前线程(当其他线程调用signal()方法时,该线程会从这个位置去执行)
LockSupport.park(this);
//要判断当前被阻塞的线程是否是因为interrupt()唤醒,是则直接break
if ((interruptMode = checkInterruptWhileWaiting(node)) != 0)
break;
}
//重新竞争锁,savedState表示的是被释放的锁的重入次数.
if (acquireQueued(node, savedState) && interruptMode != THROW_IE)
interruptMode = REINTERRUPT;
// clean up if cancelled
if (node.nextWaiter != null)
unlinkCancelledWaiters();
if (interruptMode != 0)
reportInterruptAfterWait(interruptMode);
}
// 添加到condition队列
private Node addConditionWaiter() {
Node t = lastWaiter;
// If lastWaiter is cancelled, clean out.
if (t != null && t.waitStatus != Node.CONDITION) {
unlinkCancelledWaiters();
t = lastWaiter;
}
Node node = new Node(Thread.currentThread(), Node.CONDITION);
if (t == null)
firstWaiter = node;
else
t.nextWaiter = node;
lastWaiter = node;
return node;
}
// 判断是否被中断唤醒
private int checkInterruptWhileWaiting(Node node) {
return Thread.interrupted() ?
// 若被interrupt唤醒则更新节点,更新成功抛异常,更新失败则等待其他线程更新成功后再次中断
(transferAfterCancelledWait(node) ? THROW_IE : REINTERRUPT) :
0;
}
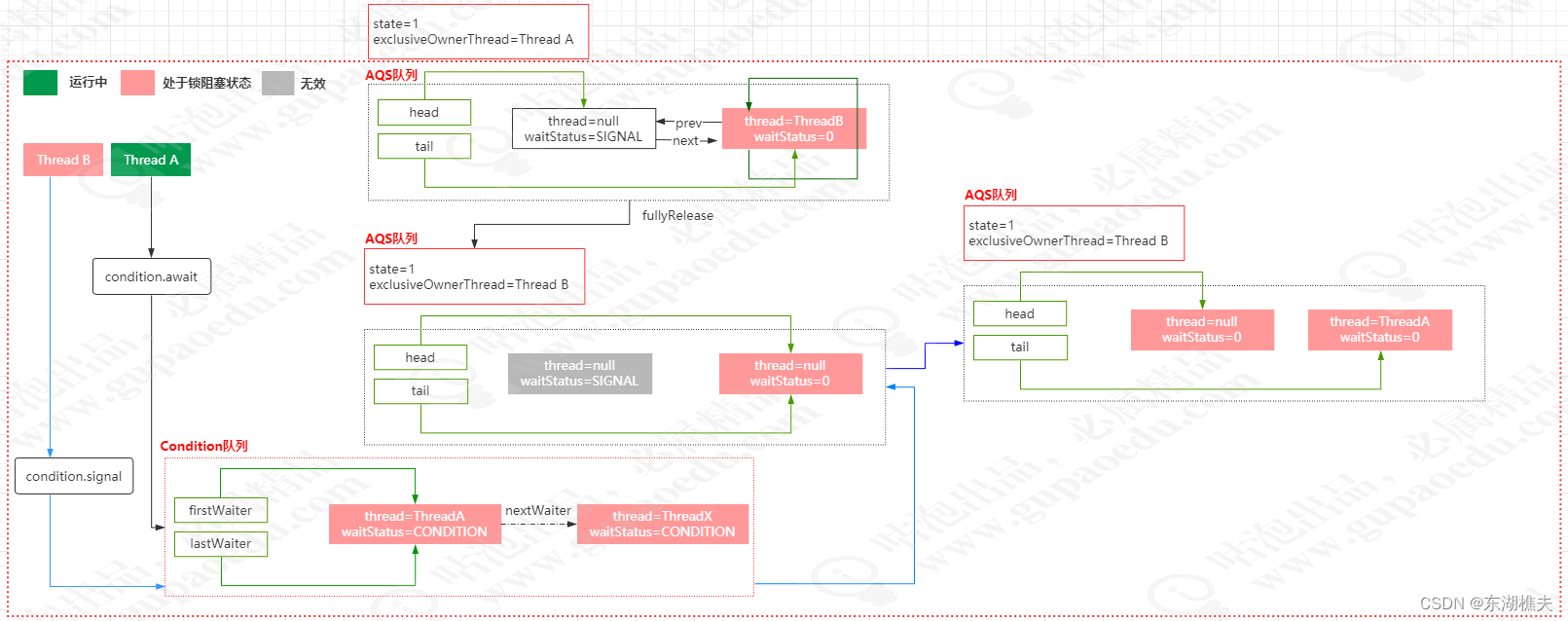
2、执行signal方法
public final void signal() {
// 如果当前线程没有获取到锁抛异常
if (!isHeldExclusively())
throw new IllegalMonitorStateException();
Node first = firstWaiter;
if (first != null)
doSignal(first);
}
private void doSignal(Node first) {
do {
if ( (firstWaiter = first.nextWaiter) == null)
lastWaiter = null;
first.nextWaiter = null;
// 把condition队列里的节点移动到sync队列
} while (!transferForSignal(first) &&
(first = firstWaiter) != null);
}
final boolean transferForSignal(Node node) {
// 如果更新失败说明节点已失效
if (!compareAndSetWaitStatus(node, Node.CONDITION, 0))
return false;
// 节点插入同步队列
Node p = enq(node);
int ws = p.waitStatus;
// 如果上一个节点已失效,则唤醒当前节点对应的线程
if (ws > 0 || !compareAndSetWaitStatus(p, ws, Node.SIGNAL))
LockSupport.unpark(node.thread);
return true;
}
4.2 原子操作类
当程序更新一个变量时,如果多线程同时更新这个变量,可能得到期望之外的值,比如变 量i=1,A线程更新i+1,B线程也更新i+1,经过两个线程操作之后可能i不等于3,而是等于2。因 为A和B线程在更新变量i的时候拿到的i都是1,这就是线程不安全的更新操作,通常我们会使 用synchronized来解决这个问题,synchronized会保证多线程不会同时更新变量i。
而Java从JDK 1.5开始提供了java.util.concurrent.atomic包(以下简称Atomic包),这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式,他们都是基于CAS实现的原子操作。
- AtomicBoolean:原子更新布尔类型。
- AtomicInteger:原子更新整型。
- AtomicLong:原子更新长整型。
- AtomicIntegerArray:原子更新整型数组里的元素。
- AtomicLongArray:原子更新长整型数组里的元素。
- AtomicReferenceArray:原子更新引用类型数组里的元素。
- AtomicIntegerArray:原子更新整型数组里的元素。
- AtomicReference:原子更新引用类型。
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
- AtomicMarkableReference:原子更新带有标记位的引用类型。
- AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicStampedReference:原子更新带有版本号的引用类型。
4.3 并发工具类
4.3.1 CountDownLatch
假如有这样一个需求:我们需要解析一个Excel里多个sheet的数据,此时可以考虑使用多线程,每个线程解析一个sheet里的数据,等到所有的sheet都解析完之后,程序需要提示解析完成。这个需求中,主线程等待所有线程完成sheet的解析操作,可以通过JDK 1.5之后的并发包中提供的CountDownLatch来实现。
import java.util.concurrent.CountDownLatch;
public class CountDownLatchDemo {
static CountDownLatch c = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " countDown");
c.countDown();
}
}).start();
new Thread(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName() + " countDown");
c.countDown();
}
}).start();
c.await();
System.out.println("3");
}
}
CountDownLatch的构造函数接收一个int类型的参数作为计数器,如果你想等待N个点完成,这里就传入N。当我们调用CountDownLatch的countDown方法时,N就会减1,CountDownLatch的await方法 会阻塞当前线程,直到N变成零。由于countDown方法可以用在任何地方,所以这里说的N个 点,可以是N个线程,也可以是1个线程里的N个执行步骤。用在多个线程时,只需要把这个 CountDownLatch的引用传递到线程里即可。
4.3.2 Semaphore
Semaphore(信号量)是用来控制同时访问特定资源的线程数量,它通过协调各个线程,以保证合理的使用公共资源。
Semaphore可以用于做流量控制,特别是公用资源有限的应用场景,比如数据库连接。假如有一个需求,要读取几万个文件的数据,因为都是IO密集型任务,我们可以启动几十个线程并发地读取,但是如果读到内存后,还需要存储到数据库中,而数据库的连接数只有10个,这时我们必须控制只有10个线程同时获取数据库连接保存数据,否则会报错无法获取数据库连接。这个时候,就可以使用Semaphore来做流量控制。
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
private static final int THREAD_COUNT = 30;
private static ExecutorService threadPool = Executors.newFixedThreadPool(THREAD_COUNT);
private static Semaphore s = new Semaphore(10);
public static void main(String[] args) {
for (int i = 0; i < THREAD_COUNT; i++) {
threadPool.execute(new Runnable() {
@Override
public void run() {
try {
s.acquire();
System.out.println("save data");
s.release();
} catch (InterruptedException e) {
}
}
});
}
threadPool.shutdown();
}
}
在代码中,虽然有30个线程在执行,但是只允许10个并发执行。Semaphore的构造方法Semaphore(int permits)接受一个整型的数字,表示可用的许可证数量。Semaphore(10)表示允许10个线程获取许可证,也就是最大并发数是10。Semaphore的用法也很简单,首先线程使用Semaphore的acquire()方法获取一个许可证,使用完之后调用release()方法归还许可证。还可以用tryAcquire()方法尝试获取许可证。
4.3.3 CyclicBarrier
CyclicBarrier可以用于多线程计算数据,最后合并计算结果的场景。例如,用一个Excel保存了用户所有银行流水,每个Sheet保存一个账户近一年的每笔银行流水,现在需要统计用户的日均银行流水,先用多线程处理每个sheet里的银行流水,都执行完之后,得到每个sheet的日均银行流水,最后,再用barrierAction用这些线程的计算结果,计算出整个Excel的日均银行流水。
import java.util.Map;
import java.util.concurrent.*;
public class BankWaterService implements Runnable {
/*** 创建4个屏障,处理完之后执行当前类的run方法 */
private CyclicBarrier c = new CyclicBarrier(4, this);
/*** 假设只有4个sheet,所以只启动4个线程 */
private Executor executor = Executors.newFixedThreadPool(4);
/*** 保存每个sheet计算出的银流结果 */
private ConcurrentHashMap<String, Integer> sheetBankWaterCount = new ConcurrentHashMap<String, Integer>();
private void count() {
for (int i = 0; i < 4; i++) {
executor.execute(new Runnable() {
@Override
public void run() {
// 计算当前sheet的银流数据,计算代码省略
sheetBankWaterCount.put(Thread.currentThread().getName(), 1);
// 银流计算完成,插入一个屏障
try {
c.await();
} catch (InterruptedException | BrokenBarrierException e) {
e.printStackTrace();
}
}
});
}
}
@Override
public void run() {
int result = 0;
// 汇总每个sheet计算出的结果
for (Map.Entry<String, Integer> sheet : sheetBankWaterCount.entrySet()) {
result += sheet.getValue();
}
// 将结果输出
sheetBankWaterCount.put("result", result);
System.out.println(result);
}
public static void main(String[] args) {
BankWaterService bankWaterCount = new BankWaterService();
bankWaterCount.count();
}
}
4.4 ConcurrentHashMap
4.4.1 put方法源码分析
1、方法入口
public V put(K key, V value) {
// 详见步骤2
return putVal(key, value, false);
}
2、核心流程
final V putVal(K key, V value, boolean onlyIfAbsent) {
// CHM不允许为空
if (key == null || value == null) throw new NullPointerException();
// 计算hash值
int hash = spread(key.hashCode());
// 该数组节点上元素个数
int binCount = 0;
// 失败重试,直到put成功
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
// 延迟初始化,第一次put进行table初始化
if (tab == null || (n = tab.length) == 0)
// 初始化数组,详见步骤3
tab = initTable();
// 如果数组下标位置为空,直接尝试CAS写入
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 尝试将table的i下标位置由null更新为当前节点
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
// CAS成功,结束循环
break;
}
// ForwardingNode的hash值,代表当前table正在扩容
else if ((fh = f.hash) == MOVED)
// 进行协助扩容
tab = helpTransfer(tab, f);
// 数组下标已有节点,且没有在扩容阶段,此时应该遍历链表/红黑树进行节点插入
// 插入后还需判断是否进行链表转红黑树或者扩容
else {
V oldVal = null;
// 锁住该下标,比JDK1.7的分段锁粒度更小,效率更高
synchronized (f) {
// 前面赋值了这里要重新判断,类似DoubleCheckLock
if (tabAt(tab, i) == f) {
// 链表的处理逻辑
// 小于0的情况:出于扩容中(-1),红黑树根节点(-2),其他特殊情况
if (fh >= 0) {
// 有一个非空节点,开始计算节点数
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果key相同则覆盖value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
// 如果到了链表最后一个节点,则插入
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 如果是红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 遍历红黑树,如果key相同则覆盖value
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
// 只要成功插入,这个分支都会进入
if (binCount != 0) {
// 总结点数大于8就需要进行处理,根据条件确定是要扩容还是转化为红黑树
if (binCount >= TREEIFY_THRESHOLD)
// 链表长度大于8的处理逻辑,详见步骤4
treeifyBin(tab, i);
// oldVal不为空,说明key已存在进行了覆盖,无需增加size,直接return
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加节点计数,计算size,详见步骤7
addCount(1L, binCount);
return null;
}
3、初始化数组
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
// 数组未初始化完成,所有线程都必须进入该循环,等待其中一个线程初始化完成,此处也采用CAS
while ((tab = table) == null || tab.length == 0) {
// 第一次不走这个分支,有线程抢占标量成功后会将sizeCtl更新为-1
if ((sc = sizeCtl) < 0)
Thread.yield(); // lost initialization race; just spin
// CAS尝试抢占标量SIZECTL,将其更新为-1,抢占成功初始化表
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 再次判断table,还是DoubleCheckLock
if ((tab = table) == null || tab.length == 0) {
// sc > 0 代表初始化容量,没有设置则使用默认容量16
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 新建Node数组,这就是Hash桶
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
// sc设置为下次扩容阈值,为n*0.75
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
4、链表长度大于8的处理逻辑
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
if (tab != null) {
// table长度小于64则进行扩容
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
// 翻倍扩容:n<<1等价于2n,详见步骤5
tryPresize(n << 1);
// 否则转化为红黑树
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p =
new TreeNode<K,V>(e.hash, e.key, e.val,
null, null);
if ((p.prev = tl) == null)
hd = p;
else
tl.next = p;
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
5、扩容(由于treeifyBin调用时传进来的size=2n,所以扩容结果是原来的4倍,直接从16扩容到64)
private final void tryPresize(int size) {
// 要扩容的值size如果大于等于最大容量的一半,则直接扩容到最大容量
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 初始化操作
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c;
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
// 扩容目标小于初始化后容量,或者当前已经超过最大容量则结束
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
// 生成扩容戳,高16位表示当前扩容标记,低16位表示当前扩容线程数
int rs = resizeStamp(n);
// 协助扩容走这段逻辑
if (sc < 0) {
Node<K,V>[] nt;
// 扩容结束
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
// 进行数据迁移,详见步骤6
transfer(tab, nt);
}
// 第一次循环走这段逻辑,因为sizectl为1表示初始化,所以第一次直接+2
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
// 进行数据迁移,详见步骤6
transfer(tab, null);
}
}
}
6、扩容后数据迁移(这200行代码看了一天)
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
// stride代表每个线程处理的数据的区间大小,如果是单线程直接等于n
// 如果是多线程则为n/8/CPU核数(应该是根据计算资源默认一个CPU用8个扩容线程并发可以达到较高的效率)
// 最小是16。
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
// 初始化扩容后数组
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
// n<<1 扩容目标是当前数组的两倍
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) {
sizeCtl = Integer.MAX_VALUE;
return;
}
// 扩容后数组
nextTable = nextTab;
// 表示待分配处理的数组长度,初始化时为old数组总长度,每分配一段区间出去,就减去该长度
transferIndex = n;
}
// 扩容后数组长度
int nextn = nextTab.length;
// 用来表示已经迁移完的状态,也就是说,如果某个old数组的节点完成了迁移,则需要更改成fwd。
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
// 推进标记,是否推进下一组区间
boolean advance = true;
// 完成标记
boolean finishing = false; // to ensure sweep before committing nextTab
// i 表示分配给当前线程任务,执行到的桶位
// bound 表示分配给当前线程任务的下界限制
for (int i = 0, bound = 0;;) {
// f 桶位的头结点
// fh 头结点的hash
Node<K,V> f; int fh;
// 总的来说,这个循环就是为了分配任务,如果确认没有任务可分配则通过标量设置i=-1,以便后续流程退出
while (advance) {
// nextIndex 分配任务的开始下标
// nextBound 分配任务的结束下标
int nextIndex, nextBound;
// --i,每次一个位置处理完成后i往前移动一位,i>=bound表示当前区间还有下标未处理完
// 假设old数组长度64,每次处理16,那么线程第一个处理的区间是48-63,bound=48,i=63
// 处理完63这个节点后,处理62,等到处理完区间最后一个节点48时,i变成47,此时条件不满足
// 执行下面的CAS TRANSFERINDEX,将bound变成32
// finishing表示任务完全处理完
if (--i >= bound || finishing)
advance = false;
// transferIndex被更新为0,表示当前没有区间可以分配给该线程
// 意味着扩容即将结束,设置i=-1,以便后续流程直接退出
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
// 能走到这里说明当前线程空闲且还存在待分配区间需要处理
// 通过CAS抢占区间,抢到了就执行该区间数据的迁移
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
// 如果未分配到任务(即扩容即将完成或已经完成,无需当前线程继续处理),
// 进行退出前处理并结束扩容
if (i < 0 || i >= n || i + n >= nextn) {
// 保存sizeCtl 的变量
int sc;
// 最后一个执行完成的线程会进入该方法,进行变量赋值操作再退出
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
// 将当前处理的线程数-1
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
// 条件成立:说明当前线程不是最后一个退出transfer任务的线程,这时候直接返回即可
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n;
}
}
// 走到这里说明当前线程的任务尚未处理完,正在进行中
// 如果当前桶位未存放数据,将此处设置为fwd节点。
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
// hash=MOVED说明当前节点已经是fwd节点,进入下一次循环处理下个节点
else if ((fh = f.hash) == MOVED)
advance = true;
// 该节点数据需要处理
else {
synchronized (f) {
// 随处可见的DCL,防止在加锁头对象之前,当前桶位的头对象被其它写线程修改过,导致目前加锁对象错误...
if (tabAt(tab, i) == f) {
// ln 表示低位链表引用
// hn 表示高位链表引用
// 此处是由于扩容后节点可能会分配到其他节点
// 用低位链连接扩容后处在原节点的数据
// 用高位链连接扩容后被移动到另一个节点的数据
// 例如原来数组长度为16,此时4和20都在table[3]的位置
// 扩容到32后,4的位置不变,20会移动到table[19]的位置
Node<K,V> ln, hn;
// 节点的hash值大于0,说明是链表,另一个分支是红黑树的处理逻辑
if (fh >= 0) {
// 用fh & n 来表示迁移后位置是否会发生变化,结果为0说明不会发生变化,结果为1说明会发生变化
int runBit = fh & n;
// 用来获取最后一段runBit相等的第一个节点,有点抽象,举个例子,还是假设数组由16扩容到32
// 如果链表是4,20,36,68,100,这时候36,68,100的runBit都为0(即迁移后位置不会发生变化)
// 此时lastRun就是36
// 如果链表是4,36,20,52,这时候20,52的runBit都为1(即迁移后位置不会发生变化)
// 此时lastRun就是20
// 有lastRun的目的就是后续遍历进行高低链处理的时候只需要处理到runBit就行
// runBit后面的数组是一条天然链表,无需重复进行断链重组
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
// 如果下个节点的runBit跟上一个不一样,则把下个节点当做lastRun,继续遍历
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
// 根据runBit判断这个lastRun是高位链还是低位链
if (runBit == 0) {
ln = lastRun;
hn = null;
}
// 根据runBit判断这个lastRun是高位链还是低位链
else {
hn = lastRun;
ln = null;
}
// 重新遍历一次,完善高低链
// 此时只需要遍历到lastRun即可
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
// CAS设置高低链
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
// 处理完成,将当前节点更新为fwd
setTabAt(tab, i, fwd);
advance = true;
}
//条件成立:表示当前桶位是 红黑树 代理结点TreeBin
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}
7、统计元素个数size
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
// 如果counterCells不是空,或者CAS增加baseCount失败,说明需要通过counterCells计数
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) {
CounterCell a; long v; int m;
boolean uncontended = true;
// 如果CounterCell是空(尚未出现并发)
if (as == null || (m = as.length - 1) < 0 ||
// 如果随机取余一个数组位置为空或者
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// 修改这个槽位的变量失败(前两个条件都不满足,即CounterCell不为空且随机位置也不为空才会走到这里)
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
// 死循环处理,完成CounterCell的初始化以及元素的累加,详见步骤8
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
s = sumCount();
}
// 检查是否需要扩容,在putVal方法调用时,默认就是要检查的。
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
// 总数大于需要扩容的阈值sizeCtl且table不为空,且长度未达到上限,进行扩容
// 这段代码跟之前的扩容代码一样
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
8、竞争激烈情况下的保成功计数
private final void fullAddCount(long x, boolean wasUncontended) {
int h;
if ((h = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit(); // force initialization
h = ThreadLocalRandom.getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
for (;;) {
CounterCell[] as; CounterCell a; int n; long v;
// 如果counterCells已经初始化
if ((as = counterCells) != null && (n = as.length) > 0) {
// 通过该值与当前线程probe求与,获得cells的下标元素,和hash表获取索引是一样的
// 如果下标为空,说明可以尝试直接存入counterCell
if ((a = as[(n - 1) & h]) == null) {
// 说明当前CounterCell没有被其他线程占用
if (cellsBusy == 0) { // Try to attach new Cell
CounterCell r = new CounterCell(x); // Optimistic create
// 通过cas设置cellsBusy标识,防止其他线程来对counterCells并发处理
if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean created = false;
try {
CounterCell[] rs; int m, j;
// 将初始化的r对象的元素个数放在对应下标的位置
if ((rs = counterCells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
// 说明指定cells下标位置的数据不为空,则进行下一次循环
continue;
}
}
collide = false;
}
// 说明在addCount方法中cas失败了,并且获取probe的值不为空
else if (!wasUncontended)
// 设置为未冲突标识,进入下一次自旋
wasUncontended = true;
// 由于指定下标位置的cell值不为空,则直接通过cas进行原子累加,如果成功,则直接退出
else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
break;
// 如果已经有其他线程建立了新的counterCells或者CounterCells大于CPU核心数(很巧妙,线程的并发数不会超过cpu核心数)
else if (counterCells != as || n >= NCPU)
// 设置当前线程的循环失败不进行扩容
collide = false;
// 恢复collide状态,标识下次循环会进行扩容
else if (!collide)
collide = true;
// 进入这个步骤,说明CounterCell数组容量不够,线程竞争较大,所以先设置一个标识表示为正在扩容
else if (cellsBusy == 0 &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
try {
if (counterCells == as) {
//扩容一倍2变成4,这个扩容比较简单
CounterCell[] rs = new CounterCell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
counterCells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
// 继续下一次自旋
continue; // Retry with expanded table
}
h = ThreadLocalRandom.advanceProbe(h);
}
// cellsBusy=0表示没有在做初始化,通过cas更新cellsbusy的值标注当前线程正在做初始化操作
else if (cellsBusy == 0 && counterCells == as &&
U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) {
boolean init = false;
try { // Initialize table
if (counterCells == as) {
// 初始化CounterCell
CounterCell[] rs = new CounterCell[2];
// 将x也就是元素的个数 放在指定的数组下标位置
rs[h & 1] = new CounterCell(x);
counterCells = rs;
init = true;
}
} finally {
// 回复标识
cellsBusy = 0;
}
// 初始化完成,结束流程
if (init)
break;
}
// 竞争激烈,其它线程占据cell数组,尝试直接累加在base变量中
else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x))
break;
}
}
4.4.2 红黑树原理
4.4.2.1 红黑树基本规则
- 每个节点要么是红色,要么是黑色。
- 根节点必须是黑色。
- 红色节点不能连续(如果当前的节点是红色,那么它的子节点必须是黑色)。
- 从任意节点出发,到其所有叶子节点的简单路径上都包含相同数目的黑色节点.(非常重要)。
- 每个红色节点的两个子节点一定都是黑色(叶子节点包含NULL)。
4.4.2.2 红黑树插入过程中情况
1、当前插入节点的父节点为黑色,或者当前插入节点为根节点,则无需旋转
2、当前节点的父节点为红色
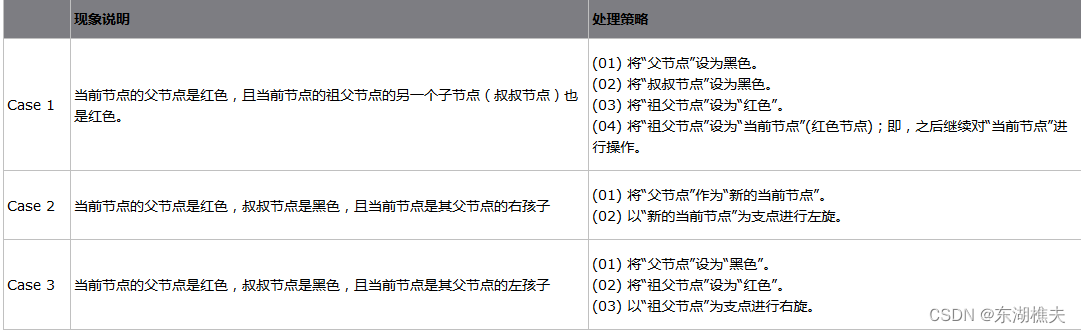
4.4.2.3 红黑树的优势
红黑树能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作。此外,任何不平衡都会在3次旋转之内解决。这一点是AVL所不具备的。
4.5 阻塞队列
4.5.1 阻塞队列概述
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。支持阻塞的插入方法是指当队列满时,队列会阻塞插入元素的线程,直到队列不满。支持阻塞的移除方法是指在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。
4.5.2 阻塞队列中的方法
添加元素
- add -> 如果队列满了,抛出异常
- offer -> true/false , 添加成功返回true,否则返回false
- put -> 如果队列满了,则一直阻塞
- offer(timeout) , 带了一个超时时间。如果添加一个元素,队列满了,此时会阻塞timeout
时长,超过阻塞时长,返回false。
删除元素
- element-> 队列为空,抛异常
- peek -> true/false , 移除成功返回true,否则返回false
- take -> 一直阻塞
- poll(timeout) -> 如果超时了,还没有元素,则返回null
4.5.3 J.U.C 中的阻塞队列
- ArrayBlockingQueue 基于数组结构
- LinkedBlockingQueue 基于链表结构
- PriorityBlcokingQueue 基于优先级队列
- DelayQueue 允许延时执行的队列
- SynchronousQueue 没有任何存储结构的的队列
4.5.4 基于condition实现一个简单的阻塞队列
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class ConditionBlockedQueueExample {
//表示阻塞队列中的容器
private List<String> items;
//元素个数(表示已经添加的元素个数)
private volatile int size;
//数组的容量
private volatile int count;
private Lock lock=new ReentrantLock();
//让take方法阻塞 ->wait/notify
private final Condition notEmpty=lock.newCondition();
//放add方法阻塞
private final Condition notFull=lock.newCondition();
public ConditionBlockedQueueExample(int count){
this.count=count;
items=new ArrayList<>(count); //写死了
}
//添加一个元素,并且阻塞添加
public void put(String item) throws InterruptedException {
lock.lock();
try{
if(size>=count){
System.out.println("队列满了,需要先等一会");
notFull.await();
}
++size; //增加元素个数
items.add(item);
notEmpty.signal();
}finally {
lock.unlock();
}
}
public String take() throws InterruptedException {
lock.lock();
try{
if(size==0){
System.out.println("阻塞队列空了,先等一会");
notEmpty.await();
}
--size;
String item=items.remove(0);
notFull.signal();
return item;
}finally {
lock.unlock();
}
}
public static void main(String[] args) throws InterruptedException {
ConditionBlockedQueueExample cbqe=new ConditionBlockedQueueExample(10);
//生产者线程
Thread t1=new Thread(()->{
Random random=new Random();
for (int i = 0; i < 1000; i++) {
String item="item-"+i;
try {
cbqe.put(item); //如果队列满了,put会阻塞
System.out.println("生产一个元素:"+item);
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t1.start();
Thread.sleep(100);
Thread t2=new Thread(()->{
Random random=new Random();
for (;;) {
try {
String item=cbqe.take();
System.out.println("消费者线程消费一个元素:"+item);
Thread.sleep(random.nextInt(1000));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
t2.start();
}
}
4.6 线程池
4.6.1 线程池的作用
- 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
- 提高线程的可管理性。线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源, 还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须对其实现原理了如指掌。
4.6.2 线程池创建参数详解
- corePoolSize:当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到需要执行的任务数大于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
- workQueue:用于保存等待执行的任务的阻塞队列。
- maximumPoolSize:线程池允许创建的最大线程数。如果队列满了,并 且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
- ThreadFactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设 置更有意义的名字。
- RejectedExecutionHandler:当队列和线程池都满了,说明线程池处于饱和状 态,那么必须采取一种策略处理提交的新任务。在JDK 1.5中Java线程池框架提供了以下4种策略。AbortPolicy:直接抛出异常。CallerRunsPolicy:只用调用者所在线程来运行任务。DiscardOldestPolicy:丢弃队列里最近的一个任务,并执行当前任务。DiscardPolicy:不处理,丢弃掉。 当然,也可以根据应用场景需要来实现RejectedExecutionHandler接口自定义策略。如记录日志或持久化存储不能处理的任务。
- keepAliveTime:线程池的工作线程空闲后,保持存活的时间。所以, 如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
- TimeUnit:线程活动保持时间的单位,可选的单位有天(DAYS)、小时(HOURS)、分钟 (MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)。
4.6.3 线程池的状态流转
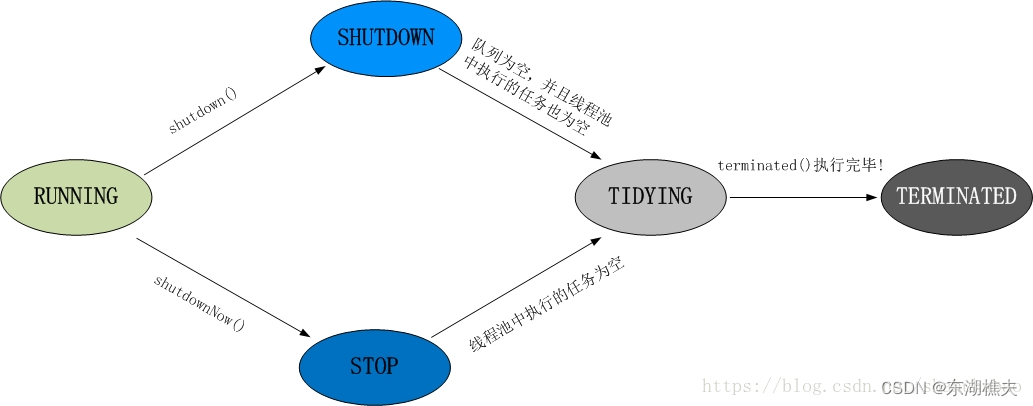
4.6.4 execute源码解析
1、方法入口
public void execute(Runnable command) {
// 命令不可为空
if (command == null)
throw new NullPointerException();
//获取ctl对应的int值
int c = ctl.get();
// c是一个32位int变量,前3位表示线程池状态,后29位表示线程数量
// workerCountOf是将c与上1<<29-1,获取线程数量
// 如果小于核心线程数,则新建线程并将任务丢给新线程处理(延迟初始化)
if (workerCountOf(c) < corePoolSize) {
// 尝试创建核心线程并执行
if (addWorker(command, true))
return;
// ctl发生变化,重新获取
c = ctl.get();
}
// isRunning是判断c的线程池状态(前3位)是否为running(大于0)状态
// private static final int RUNNING = -1 << COUNT_BITS;
// private static final int SHUTDOWN = 0 << COUNT_BITS;
// private static final int STOP = 1 << COUNT_BITS;
// private static final int TIDYING = 2 << COUNT_BITS;
// private static final int TERMINATED = 3 << COUNT_BITS;
// 线程池状态正常则提交任务,由于此处需要对提交结果进行处理,使用offer,失败表示队列已满
if (isRunning(c) && workQueue.offer(command)) {
// 再次获取ctl的int值
// 任务入队的过程中,线程池状态可能已经被修改
int recheck = ctl.get();
// 如果线程池状态不是RUNNING,并且成功删除刚刚入队的任务
if (!isRunning(recheck) && remove(command))
// 直接执行拒绝策略
reject(command);
// 进入本分支有几种情况:
// 1.线程池处于RUNNING状态,但工作线程数为0
// 2.线程池处于非RUNNING状态,但是任务从阻塞队列删除失败,此时工作线程数为0
else if (workerCountOf(recheck) == 0)
// 创建新的非核心线程
addWorker(null, false);
}
// 尝试创建非核心线程并执行
else if (!addWorker(command, false))
// 执行拒绝策略
reject(command);
}
2、创建并启动线程
private boolean addWorker(Runnable firstTask, boolean core) {
// 外层循环标记
retry:
for (;;) {
int c = ctl.get();
// 获取线程池的运行状态
int rs = runStateOf(c);
// 线程池状态不为运行中(参数见execute方法内注释)
// 且不存在线程池状态为SHUTDOWN,任务为空但队列不为空
// 逻辑有点拗口,翻译过来就是当线程池状态不为RUNNING的时候,只有一种情况可以继续执行
// 就是线程池状态为SHUTDOWN,传进来的任务为空(不再传任务)但队列中还有任务
// 再翻译过来就是说,线程池被SHUTDOWN的时候workQueue内的任务需要执行完成
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
// 获取工作线程数
int wc = workerCountOf(c);
// 如果工作线程数大于CAPACITY
// 或者创建的是核心线程且工作线程数大于等于corePoolSize
// 或者创建的是非核心线程且工作线程数大于等于maximumPoolSize
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
// 如果是核心线程超过,此处返回false,由execute继续调用创建非核心线程
return false;
// CAS增加线程数
if (compareAndIncrementWorkerCount(c))
// 增加成功,退出retry循环,去创建线程、处理任务
break retry;
c = ctl.get();
if (runStateOf(c) != rs)
// 状态发生变化,进入retry循环重新执行
continue retry;
}
}
// 标记工作线程是否被启动
boolean workerStarted = false;
// 标记工作线程是否被添加成功
boolean workerAdded = false;
// 工作线程
Worker w = null;
try {
// 创建一个工作线程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 如果线程池状态正常或者为SHUTDOWN但是还有任务待处理
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
// 工作线程的HashSet中添加此工作线程
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
// 启动线程
t.start();
workerStarted = true;
}
}
} finally {
// 如果workerStarted为false即工作线程启动失败
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
3、获取并执行任务
public void run() {
runWorker(this);
}
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
// 这里不是解锁操作,这里是为了设置state = 0 以及 ExclusiveOwnerThread = null.因为起始状态state = -1,
// 不允许任何线程抢占锁,这里就是初始化操作。
w.unlock();
boolean completedAbruptly = true;
try {
// task如果执行后还是为null,说明无法再获取任务,说明任务队列为空
while (task != null || (task = getTask()) != null) {
// 加锁,防止线程未处理完任务被线程池shutdown
w.lock();
// 这里有两个作用:
// 1、线程池处于STOP/TIDYING/TERMINATION状态时需要设置线程的中断标志位
// 2、强制刷新标志位,通过Thread.interrupted()方法,因为有可能上一次执行task时,
// 当先线程的中断标志位被设置为了true,且没有处理,这里就需要处理一下。
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
// 响应中断
wt.interrupt();
try {
// 钩子方法,留给子类实现
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
4、从阻塞队列获取任务
private Runnable getTask() {
// 表示当前线程获取任务是否超时,默认是false,true表示已超时。
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 这里判断如果说线程池状态是非Running状态 && (队列中没有任务了 || 线程池当前最低状态也是STOP)
// 就会使用CAS的方式将ctl值-1,即减少一个工作线程数。最后直接返回NULL。
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
// timed表示当前线程在从队列中获取任务的时候是否有超时时间。
// 设置此参数的主要依据就是,判断allowCoreThreadTimeOut是否允许核心线程超时被回收
// 当前线程数的数量已经大于了核心线程数,说明当前线程当获取任务超时时一定可以被回收。
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 判断当前线程是否达到了回收的标准
// 当工作线程数大于最大线程数或者获取任务超时
// 并且当前线程池线程数量大于1或者队列中没有任务了,当前线程就达到回收标准了
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
// CAS有可能会失败,为什么会失败?
// 1.其他线程先你一步退出
// 2.线程池状态发生了变化。
if (compareAndDecrementWorkerCount(c))
return null;
// 如果CAS失败,再次自旋,timed就有可能是false了,因为当前线程CAS失败,
// 很有可能是因为其他线程成功退出导致的,再次自旋时检查发现,当前线程就可能不属于回收范围了。
continue;
}
try {
// 根据timed的值,判断去队列中获取任务是使用带超时时间的还是不带超时时间的。
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
// 说明当前线程超时了。继续进行自旋。
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
4.6.4 executor框架(阿里规范不建议使用)
1、固定数量的线程池
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
2、只有一个线程的线程池
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
3、可以缓存的线程池 (理论上来说,有多少请求,该线程池就可以创建多少的线程来处理)
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
4、按照周期执行的线程池
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
5、其他
这些没什么意思,略。
5.1 ThreadLocal
5.2 fork/join
5.3 Future/Callable
6、补充:关于MESI协议是CPU自动实现的还是针对Lock前缀的变量有效
这个问题我探究了好几天,最终还是从最权威的手册《Intel® 64 and IA-32 Architectures Software Developer’s Manual》《英特尔®64和IA-32架构软件开发人员手册》中找到答案。节选内容如下:
The 32-bit IA-32 processors support locked atomic operations on locations in system memory. These operations are typically used to manage shared data structures (such as semaphores, segment descriptors, system segments, or page tables) in which two or more processors may try simultaneously to modify the same field or flag. The processor uses three interdependent mechanisms for carrying out locked atomic operations:
• Guaranteed atomic operations
• Bus locking, using the LOCK# signal and the LOCK instruction prefix
• Cache coherency protocols that ensure that atomic operations can be carried out on cached data structures (cache lock); this mechanism is present in the Pentium 4, Intel Xeon, and P6 family processors
These mechanisms are interdependent in the following ways. Certain basic memory transactions (such as reading or writing a byte in system memory) are always guaranteed to be handled atomically. That is, once started, the processor guarantees that the operation will be completed before another processor or bus agent is allowed access to the memory location. The processor also supports bus locking for performing selected memory operations (such as a read-modify-write operation in a shared area of memory) that typically need to be handled atomically, but are not automatically handled this way. Because frequently used memory locations are often cached in a processor’s L1 or L2 caches, atomic operations can often be carried out inside a processor’s caches without asserting the bus lock. Here the processor’s cache coherency protocols ensure that other processors that are caching the same memory locations are managed properly while atomic operations are performed on cached memory locations.
32位IA-32处理器支持对系统内存中位置的锁定原子操作。 这些操作通常用于管理共享数据结构(如信号量、段描述符、系统段或页表),其中两个或多个处理器可能试图同时修改相同的字段或标记。 处理器使用三种相互依赖的机制来执行锁定的原子操作:
• 保证原子操作
• 总线锁定,使用LOCK#信号和LOCK指令前缀
• 缓存一致性协议,确保原子操作可以在缓存的数据结构上执行(缓存锁); 这种机制存在于奔腾4、Intel Xeon和P6系列处理器中
这些机制在以下方面相互依存。 某些基本的内存事务(例如在系统内存中读或写一个字节)总是保证以原子方式处理。 也就是说,一旦启动,处理器保证操作将在另一个处理器或总线代理被允许访问内存位置之前完成。 处理器还支持总线锁定,以执行选定的内存操作(例如内存共享区域中的读-修改-写操作),这些操作通常需要自动处理,但不会自动以这种方式处理。 因为经常使用的内存位置通常缓存在处理器的L1或L2缓存中,原子操作通常可以在处理器的缓存中执行,而无需断言总线锁。 在这里,处理器的缓存一致性协议确保在对缓存的内存位置执行原子操作时,对缓存相同内存位置的其他处理器进行正确的管理。
The processor’s caches are for the most part transparent to software. When enabled, instructions and data flow through these caches without the need for explicit software control. However, knowledge of the behavior of these caches may be useful in optimizing software performance. For example, knowledge of cache dimensions and replacement algorithms gives an indication of how large of a data structure can be operated on at once without causing cache thrashing. In multiprocessor systems, maintenance of cache consistency may, in rare circumstances, require intervention by system software. For these rare cases, the processor provides privileged cache control instructions for use in flushing caches and forcing memory ordering. There are several instructions that software can use to improve the performance of the L1, L2, and L3 caches, including the PREFETCHh, CLFLUSH, and CLFLUSHOPT instructions and the non-temporal move instructions (MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD). The use of these instructions are discussed in Section 11.5.5, “Cache Management Instructions.”
处理器的缓存大部分对软件是透明的。 当启用时,指令和数据流通过这些缓存,而不需要显式的软件控制。 然而,了解这些缓存的行为可能有助于优化软件性能。 例如,了解缓存维数和替换算法可以指示一次可以操作多大的数据结构,而不会造成缓存抖动。 在多处理器系统中,在很少的情况下,维护缓存一致性可能需要系统软件的干预。 对于这些罕见的情况,处理器提供了特权缓存控制指令,用于刷新缓存和强制内存排序。 软件可以使用一些指令来提高L1、L2和L3缓存的性能,包括PREFETCHh、CLFLUSH和CLFLUSHOPT指令和非时间移动指令(MOVNTI、MOVNTQ、MOVNTDQ、MOVNTPS和MOVNTPD)。 这些指令的使用将在第11.5.5节“缓存管理指令”中讨论。
IA-32 processors (beginning with the Pentium processor) and Intel 64 processors use the MESI (modified, exclusive, shared, invalid) cache protocol to maintain consistency with internal caches and caches in other processors (see Section 11.4, “Cache Control Protocol”). When the processor recognizes that an operand being read from memory is cacheable, the processor reads an entire cache line into the appropriate cache (L1, L2, L3, or all). This operation is called a cache line fill. If the memory location containing that operand is still cached the next time the processor attempts to access the operand, the processor can read the operand from the cache instead of going back to memory. This operation is called a cache hit. When the processor attempts to write an operand to a cacheable area of memory, it first checks if a cache line for that memory location exists in the cache. If a valid cache line does exist, the processor (depending on the write policy currently in force) can write the operand into the cache instead of writing it out to system memory. This operation is called a write hit. If a write misses the cache (that is, a valid cache line is not present for area of memory being written to), the processor performs a cache line fill, write allocation. Then it writes the operand into the cache line and (depending on the write policy currently in force) can also write it out to memory. If the operand is to be written out to memory, it is written first into the store buffer, and then written from the store buffer to memory when the system bus is available. (Note that for the Pentium processor, write misses do not result in a cache line fill; they always result in a write to memory. For this processor, only read misses result in cache line fills.)
IA-32处理器(从奔腾处理器开始)和Intel 64处理器使用MESI(modify,exclusive, shared, invalid)缓存协议来保持内部缓存和其他处理器中的缓存的一致性(见章节11.4,“缓存控制协议”)。 当处理器意识到正在从内存中读取的操作数是可缓存的时,处理器将整个缓存行读入相应的缓存(L1、L2、L3或全部)。 这个操作被称为高速缓存线填充。 如果包含操作数的内存位置在下一次处理器试图访问操作数时仍然被缓存,那么处理器可以从缓存中读取操作数,而不是回到内存中。 此操作称为缓存命中。 当处理器试图向内存的可缓存区域写入操作数时,它首先检查该内存位置的缓存线是否存在。 如果存在有效的缓存线,处理器(取决于当前生效的写策略)可以将操作数写入缓存,而不是将其写入系统内存。 这个操作称为写命中。 如果一个写操作错过了缓存(也就是说,一个有效的缓存线没有出现在要写入的内存区域中),处理器执行一个缓存线填充,写分配。 然后,它将操作数写入缓存行,并且(取决于当前生效的写策略)也可以将操作数写入内存。 如果要将操作数写入内存,则首先将其写入存储缓冲区,然后在系统总线可用时从存储缓冲区写入内存。 (注意,对于奔腾处理器,写错误不会导致缓存线被填满; 它们总是导致写入内存。 对于这个处理器,只有读未命中才会导致缓存行填充。)
When operating in an MP system, IA-32 processors (beginning with the Intel486 processor) and Intel 64 processors have the ability to snoop other processor’s accesses to system memory and to their internal caches. They use this snooping ability to keep their internal caches consistent both with system memory and with the caches in other processors on the bus. For example, in the Pentium and P6 family processors, if through snooping one processor detects that another processor intends to write to a memory location that it currently has cached in shared state, the snooping processor will invalidate its cache line forcing it to perform a cache line fill the next time it accesses the same memory location. Beginning with the P6 family processors, if a processor detects (through snooping) that another processor is trying to access a memory location that it has modified in its cache, but has not yet written back to system memory, the snooping processor will signal the other processor (by means of the HITM# signal) that the cache line is held in modified state and will preform an implicit write-back of the modified data. The implicit write-back is transferred directly to the initial requesting processor and snooped by the memory controller to assure that system memory has been updated. Here, the processor with the valid data may pass the data to the other processors without actually writing it to system memory; however, it is the responsibility of the memory controller to snoop this operation and update memory.
在MP系统中运行时,IA-32处理器(从Intel486处理器开始)和Intel 64处理器有能力窥探其他处理器对系统内存和内部缓存的访问。 它们使用这种窥探能力来保持内部缓存与系统内存以及总线上其他处理器中的缓存一致。 例如,在Pentium和P6系列处理器中,如果通过窥探一个处理器检测到另一个处理器打算写入一个它当前以共享状态缓存的内存位置, 窥探处理器将使它的缓存线失效,迫使它在下次访问相同的内存位置时执行缓存线填充。 从P6系列处理器开始,如果一个处理器(通过窥探)检测到另一个处理器试图访问它在缓存中修改过但还没有写回系统内存的内存位置, 窥探处理器将通知另一个处理器(通过hitm#信号)缓存线保持在修改状态,并将对修改后的数据进行隐式回写。 隐式回写直接传输到初始请求处理器,并由内存控制器探测以确保系统内存已经更新。 在这种情况下,拥有有效数据的处理器可以将数据传递给其他处理器,而无需实际将数据写入系统内存; 然而,它是内存控制器的责任嗅探这个操作和更新内存。
The following section describes the cache control protocol currently defined for the Intel 64 and IA-32 architectures. In the L1 data cache and in the L2/L3 unified caches, the MESI (modified, exclusive, shared, invalid) cache protocol maintains consistency with caches of other processors. The L1 data cache and the L2/L3 unified caches have two MESI status flags per cache line. Each line can be marked as being in one of the states defined in Table 11-4. In general, the operation of the MESI protocol is transparent to programs.
下面的章节描述了Intel 64和IA-32架构tures目前定义的缓存控制协议。 在L1和L2/L3统一缓存中,MESI (modified, exclusive, shared, invalid)协议与其他处理器的缓存保持一致。 L1数据缓存和L2/L3统一缓存每条缓存线有两个MESI状态标志。 每一行都可以标记为表11-4中定义的一种状态。 一般来说,MESI协议的操作对程序是透明的。