简介
本文主要是讲解flink on yarn的部署过程,然后yarn-session的基本原理,如何启动多个yarn-session的话如何部署应用到指定的yarn-session上,然后是用户jar的管理配置及故障恢复相关的参数。
交互过程概览
flink on yarn的整个交互过程图,如下:
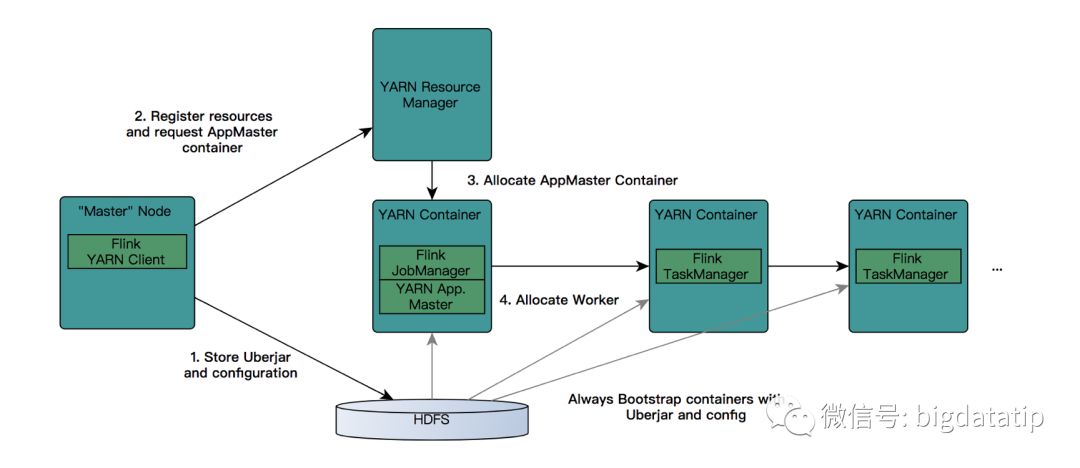
要使得flink运行于yarn上,flink要能找到hadoop配置,因为要连接到yarn的resourcemanager和hdfs。可以使用下面的策略来指定hadoop配置:
1.会查看YARN_CONF_DIR,HADOOP_CONF_DIR或者HADOOP_CONF_PATH是否设置,按照顺序检查的。然后,假如配置了就会从该文件夹下读取配置。
2.如果上面环境变量都没有配置的话,会使用HADOOP_HOME环境变量。对于hadoop2的话会查找的配置路径是$HADOOP_HOME/etc/hadoop;对于hadoop1会查找的路径是$HADOOP_HOME/conf.
每当常见一个新flink的yarn session的时候,客户端会首先检查要请求的资源(containers和memory)是否可用。然后,将包含flink相关的jar包盒配置上传到hdfs。
接下来就是客户端会向resourcemanager申请一个yarn container 用以启动ApplicationMaster。由于客户端已经将配置和jar文件注册为了container的资源,所以nodemanager会直接使用这些资源准备好container(例如,下载文件等)。一旦该过程结束,AM就被启动了。
Jobmanager和AM运行于同一个container。一旦创建成功,AM就知道了Jobmanager的地址。它会生成一个新的flink配置文件,这个配置文件是给将要启动的taskManager用的,该配置文件也会上传到hdfs。另外,AM的container也提供了Flink的web接口。Yarn代码申请的端口都是临时端口,目的是为了让用户并行启动多个Flink YARN Session。
最后,AM开始申请启动Flink Taskmanager的containers,这些container会从hdfs上下载jar文件和已修改的配置文件。一旦这些步骤完成,flink就可以接受任务了。
部署启动yarn-session
这个就是yarn-session脚本启动的整个过程吧。
默认可以直接执行bin/yarn-session.sh 默认启动的配置是
{masterMemoryMB=1024, taskManagerMemoryMB=1024,numberTaskManagers=1, slotsPerTaskManager=1}需要自己自定义配置的话,可以使用来查看参数:
bin/yarn-session.sh –help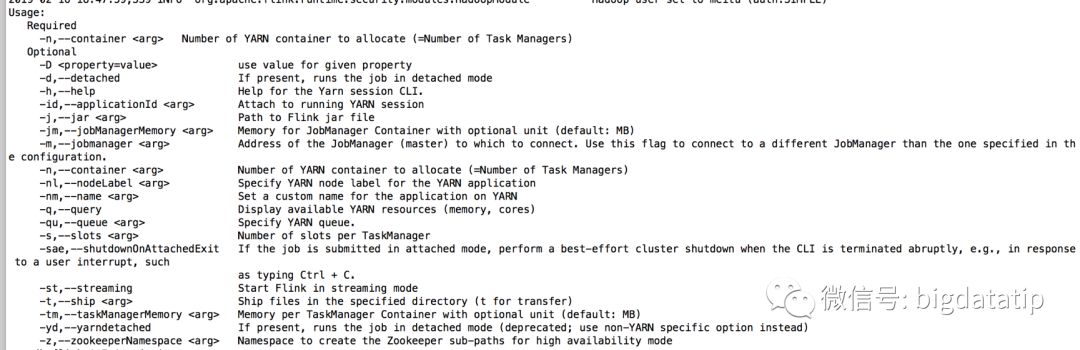
比如,我们启动一个yarn-session有10个Taskmanager,8GB内存,32处理slot,那么脚本编写应该是这样的:
./bin/yarn-session.sh-n 10 -tm 8192 -s 32
系统默认使用con/flink-conf.yaml里的配置。Flink onyarn将会覆盖掉几个参数:jobmanager.rpc.address因为jobmanager的在集群的运行位置并不是实现确定的,前面也说到了就是am的地址;taskmanager.tmp.dirs使用yarn给定的临时目录;parallelism.default也会被覆盖掉,如果在命令行里指定了slot数。
如果你想保证conf/flink-conf.yaml仅是全局末日配置,然后针对要启动的每一个yarn-session.sh都设置自己的配置,那么可以考虑使用-D修饰。
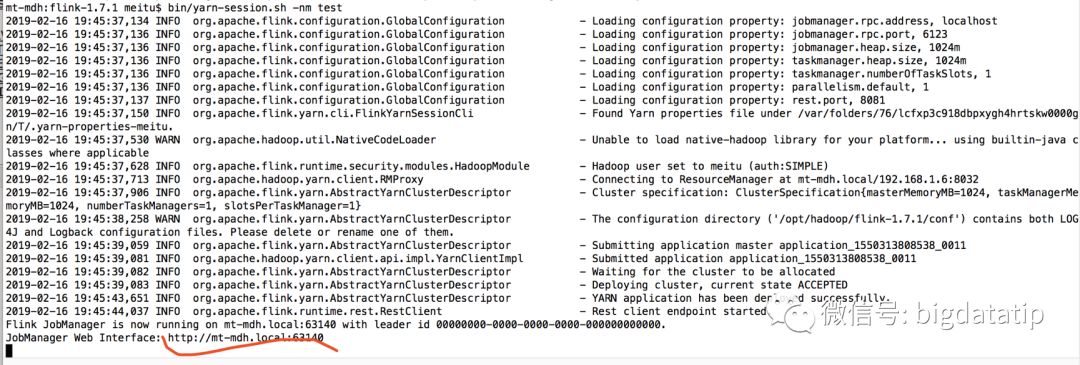
这种情况下启动完成yarn-session.sh会在会话窗口结尾
输入stop然后回车就会停掉整个应用。
官网说的是CTRL+C可以会在杀死yarn-session.sh的客户端的时候停止整个应用,max os下实测,不行的。
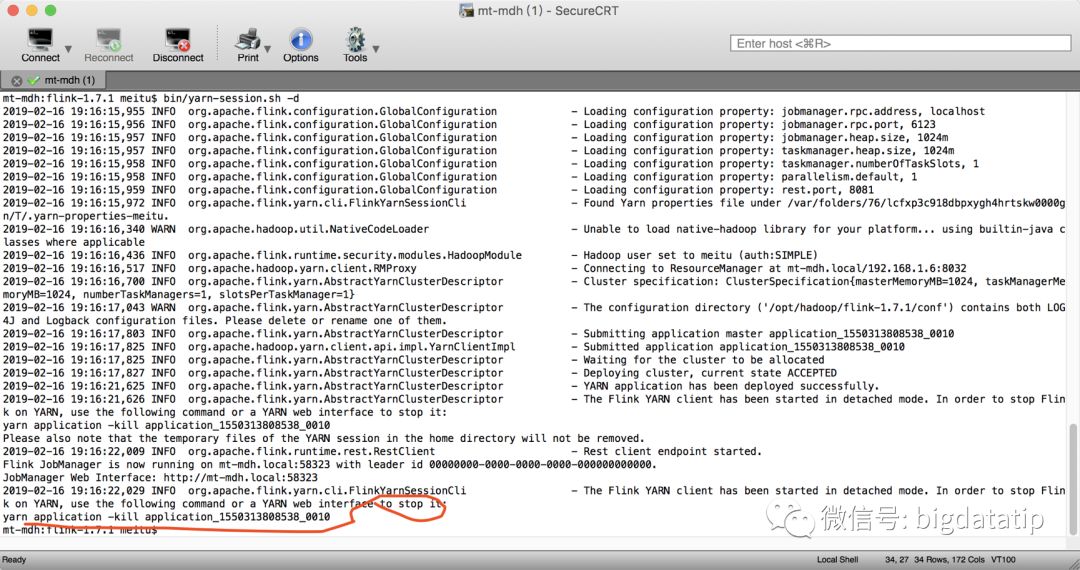
假如要启动多个需要多个shell会话窗口,那么假如想在启动完yarn-session.sh脚本之后使其退出,那么只需要加上-d或者-detached参数即可。这种情况下,客户端在提交flink到集群之后就会退出,这个时候要停止该yarn-session.sh必须要用yarn的命令了yarn application –kill <appid>
提交job到yarn-session
启动完yarn-session就是提交应用了,那么一个集群中可以存在多个yarn-session如何提交到自己的yarn-session呢?
其实,前面在讲yarn-session启动的时候应该强调一下那个叫做-nm的参数,这个就是给你的yarn-session起一个名字。比如
bin/yarn-session.sh -nm test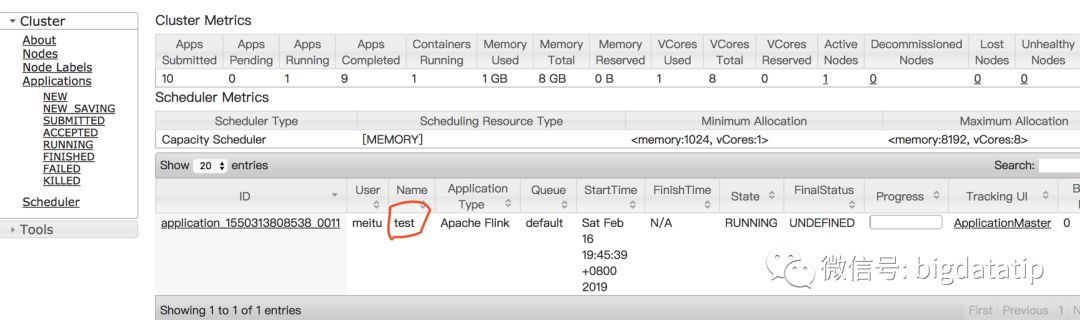
这样根据你的业务需求特点,可以自己起一个名字,然后就可以确定那个yarn-session可以用来提交job了。
当然,前面我们也说了
运行bin/flink run –help 可以产看flink提交到yarn的相关参数其中有一个叫做

然后就可以提交任务了
./bin/flink run./examples/batch/WordCount.jar --input /input/test.txt --output/output/result.txt
假如只启动了一个yarn-session的话,那么就是他会找到默认的,否则的话就用-m参数指定了。
jobmanager的地址也可以从下面页面查询。
用户依赖与classlpath
用户依赖管理还是有一定的注意事项的,默认情况下当单个job在运行的时候flink会将用户jar包含进系统chasspath内部。该行为也可以通过yarn.per-job-cluster.include-user-jar参数进行控制。
当将该参数设置为 DISABLED,flink会将jar放入到用户classpath里面(这里要强调一下,前面说的是系统classpath,而这里是用户classpath)。
用户jar的在classpath的位置顺序是由该参数的下面几个值决定的:
1).ORDER:(默认)按照字典顺序将jar添加到系统classpath里。
2).FIRST:将jar添加到系统classpath的开始位置。
3).LAST:将jar添加到系统classpath里的结束位置。
故障恢复
Flink的yarn客户端有一些配置可以控制在containers失败的情况下应该怎么做。可以在conf/flink-conf.yaml或者启动YARN session以-D形式指定。
yarn.reallocate-failed: 默认值是true,该参数控制flink是否会重新申请失败的taskmanager的container。
yarn.maximum-failed-containers: 在整个yarn-session挂掉之前,ApplicationMaster最大接受失败containers的数目。默认是最初请求的taskmanager数(-n)
yarn.application-attempts: yarn的applicationMaster失败后尝试的次数,如果此值设置为1,默认值,则当AM失败时,整个yarn session就失败了,所以该值可以设置为一个较大的值。
推荐阅读:
2019与近550位球友一起进步~
