我初学正则式时看到一大堆杂乱无章的乱码就头大,但是其实你了解了其中的意义你会觉得正则式很神奇很好用。那么现在我以另外一种比较啰嗦的方式来讲解正则式:
基本知识
正则最大的用途用来从杂乱的信息中抽取自己需要的信息或者进行字符串的验证。而正则式最大的好处是它能够使用某些约定好的正则字符串(这个我们一般称为正则表达式)来匹配有特殊意义的实际字符串。
正则字符:$,(),*,+,.,[,?,\,^, {,|
正则表达式由原生的字符(字符串中本来的字符)和正则表达式字符共同组成。它最大的特点是用规则字符来代替了实际的字符或者数字。一般的格式是一个规则字符加上数量表达式(例如\d{4,7})来匹配。有时候前面还加上位置符号^或者$
看看这个正则表达式[\w-]+@[a-z]{2,6}.com|cn|net
分为五部分:1[\w-]+ 2@ 3[a-z]{2,6} 4. 5com|cn|net
[]在正则式中有特殊含义,方括号是单个匹配 字符集/排除字符集/命名字符集。[]中的字符是定义匹配的字符范围.\w是正则式(它表示从a-z以及A-Z还有_符号这些东西里面的任意挑出一个。请注意这里只有一个。);+表示限定符,表示随机挑选的次数至少大于1。
[\w-]括号里面多了一个-。那么表示的是这个括号匹配的是(a-z加上A-Z加上_加上- 这个范围里面其中任意一个字符),
@和.就是匹配原生字符串中和@和. 除非是特定的正则表达式,一般来说不加任何修饰的字符表示的就是原生字符串中的字符。
[a-z]{2,6}表示的是一个字符串。相当于是从a-z中任意挑选一个字符,挑选2次-6次。
com|cn|net表示的com,cn,net这三个字符串中的任意挑选其中一个都是合法的。
那么,[email protected]我随便编出来的这个字符串是否符合上面的正则式呢?显然是符合的。[email protected]这个字符串也是符合的。正则式的魅力在于只要设定好你需要的规则这个正则式可以匹配成百上千条记录。
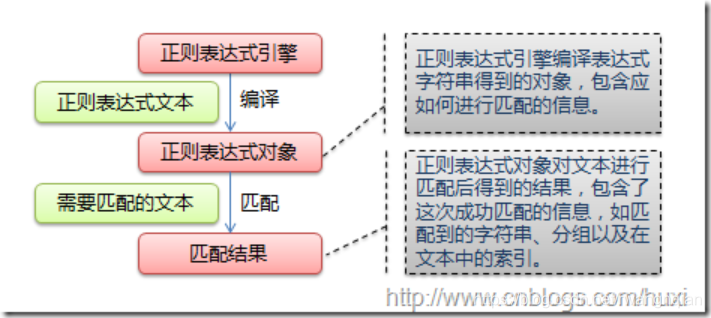
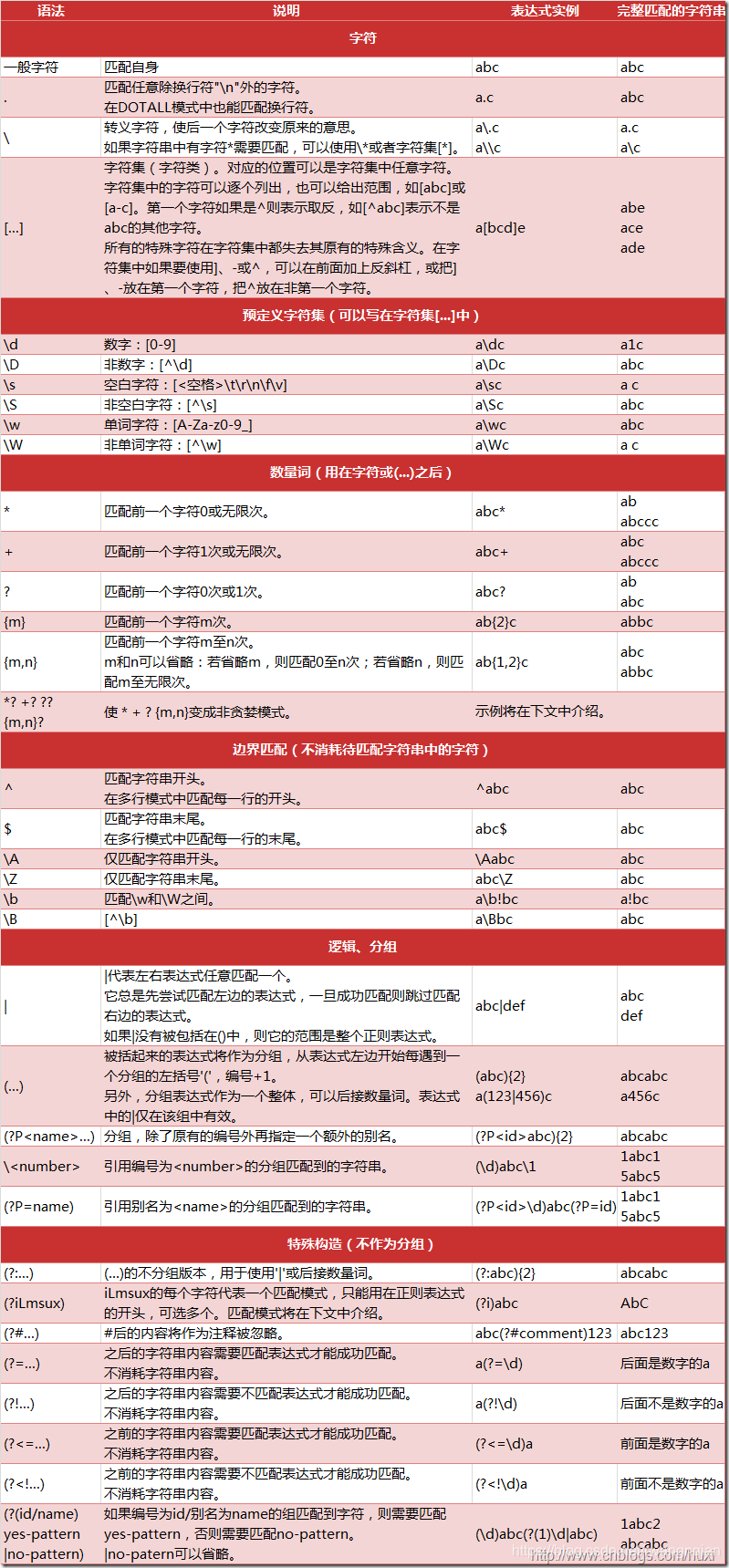
那么正则式的重点在于区别于原生字符串和正则表达式符号,下图列出了Python支持的正则表达式元字符和语法:
捕获组和非捕获组
捕获组就是把正则表达式中子表达式匹配的内容,保存到内存中以数字编号或显式命名的组里,方便后面引用。
例如: /(a)(b)(c)/中的捕获组编号为
- 组
0:abc - 组
1:a - 组
2:b - 组
3:c
其中,组0是正则表达式整体匹配结果,组1,2,3才是子表达式匹配结果
- 子表达式捕获组编号从
1开始,顺序从左到右(例如编号1是左侧第一个()包裹的子表达式的结果) - 可以在正则表达式中对前面捕获的内容进行引用(反向引用)
- 也可以在程序中,对捕获组捕获的内容进行引用(比如
replace中)
str="2017-07-29"
pal=re.compile(r'(\d{4})-(\d{2})-(\d{2})')
bb=re.search(pal,str)
print(bb.groups())
上述可以看到()包括的内容默认匹配时都在捕获组中
但是有时候,因为特殊原因用到了(),但又没有引用它的必要,这时候就可以用非捕获组声明,防止它作为捕获组,降低内存浪费
?:可以声明一个子表达式为非捕获组
a_str='abcd0123ABCD'
a_pal=re.compile(r'(?:[a-z]+)(\d+)([A-Z]+)')
cc=re.search(a_pal,a_str)
print(cc.groups())可以看到,(?:[a-z]+)将这个子表达式声明成了非捕获组,因此捕获组的编号直接跳过了它,从下一个(\d+)开始
在捕获字符串设置条件的时候使用了[a-z]+,但是我们不需要用到这个子组,所以使用非捕获组跳过它。
re模块中的特殊符号 元符号用法和例子
.
默认模式下,匹配换行符以外的任何字符。若 re.DOTALL标志被指定,则它匹配换行符在内的任何字符。
例:>>> re.search('.',"I love China")
<_sre.SRE_Match object; span=(0, 1), match='I'>
^
从字符串的开始匹配, 在 re.MULTILINE模式下每个换行符后面立即开始匹配。
例:>>> re.search(r'^ab',"abcdefg")
<_sre.SRE_Match object; span=(0, 2), match='ab'>
$
与上面的相对,匹配字符串的结尾或只是之前换行符结尾的字符串,并在 re.MULTILINE 模式下也匹配在换行符之前。
例:>>> re.search(r'fg$',"abcdefg")
<_sre.SRE_Match object; span=(5, 7), match='fg'>
*
匹配前面的子表达式零次或多次(贪婪模式1),等价于{0}。
例:>>> re.search(r'a*','aaaaaab')
<_sre.SRE_Match object; span=(0, 6), match='aaaaaa'>
+
匹配前面的子表达式一次或多次(贪婪模式),等价于{1}。
例:>>> re.search(r'a+','aaaaaab')
<_sre.SRE_Match object; span=(0, 6), match='aaaaaa'>
?
匹配前面的子表达式零次或一次,等价于{0,1}。
例:ab?将匹配'a'或'ab'。
*?,+?,??
默认情况下,*,+,?是贪婪模式,后面再加个?可以启用非贪婪模式。
例:>>> re.search(r'a*?','aaaaaab')
<_sre.SRE_Match object; span=(0, 0), match=''>
{m}
精确的指定RE应该被匹配m次,少于m次将导致RE不会被匹配上。
例:>>> print(re.search(r'a{5}','aaaab'))
None
{m,n}
m和n都为非负数,且m<n,其表示前面的RE匹配[m,n],默认也为贪婪模式,后面加上?后可启用非贪婪模式。省略m指定零为下限,省略n指定无穷大为上限。2
例:>>> re.search(r'a{1,4}','aaaaaaab')
<_sre.SRE_Match object; span=(0, 4), match='aaaa'>
\
特殊符号消除术,消除特殊字符含义(允许匹配像'*', '?',等特殊字符), 或者发出特殊序列信号。
例:>>> re.search(r'\.','www.aoxiangzhonghua.com')
<_sre.SRE_Match object; span=(3, 4), match='.'>
[]
用来表示一个字符集合。在这个集合中:
例如:>>> re.search(r'[\[]',"[]")
<_sre.SRE_Match object; span=(0, 1), match='['>
字符可以被单独罗列,例如:[amk] 会匹配 'a', 'm', 或 'k'.
字符范围可以表明通过给予两个字符和分离他们的 '-'。例如 [a-z] 将匹配任何小写字母的 ASCII 字母,[0-5] [0-9] 将匹配所有两位数数字从 00 到 59,和 [0-9A-Fa-f] 将都匹配任何十六进制数字。如果-被转义(例如,[a\-z]),或者将它放置为第一个或最后一个字符(例如,[a-]),它将匹配字符'-'。
在集合内,特殊字符失去特殊意义。例如,[(+*)] 将匹配任何字符 '(','+','* ',或 '')''。
如\w or \S等字符类别也是可以被接受的,并且不会失去特殊意义,尽管匹配的这些字符取决于re.ASCII or re.LOCALE 模式是否被设置。
如果这个集合的第一个字符是'^', 那么所有不在集合内的将会被匹配上。例如, [^5]将会配对除 '5'以外的任何字符,并且和[^^]将会匹配除'^'以外的任何字符。如果^不在集合的第一个位置那么它将没有特殊意义。
想要在一个集合内匹配']',需要在它的前面使用一个反斜杠转义,或者在集合开头处将它替换。
|
类似于C语言中的或操作,A|B表示匹配正则表达式A或者B。
例:>>> re.search(r'ab|cd','acdf')
<_sre.SRE_Match object; span=(1, 3), match='cd'>
(...)
子组,将匹配圆括号内的正则表达式,并指明子组的开始和结束。子组的内容可以在后面通过\number再次引用(稍后提及)。
例:>>> re.search(r'(efg)','abcdefghj')
<_sre.SRE_Match object; span=(4, 7), match='efg'>
特殊语法:
(?aiLmsux)
例:>>> re.search(r'(?i)CHINA','我爱China')
<_sre.SRE_Match object; span=(2, 7), match='China'>
?后可跟'a', 'i', 'L', 'm', 's', 'u', 'x'中的一个或多个
用来设置正则表达式的标志,每个字符对应一种匹配标志:a (仅匹配ASCII), i (不管大小写), L (区域设置), m (多行模式), s (不匹配所有), and x (详细表达式)。
(?:...)
非捕获组,即该子组匹配的字符串无法从后面获得。
例:>>> re.search(r'(?:China)\1','ChinaChina