52 | 算法实战(一):剖析 Redis 数据类型对应的数据结构
1. Redis 是一种键值(Key-Value)数据库。相对于关系型数据库(比如 MySQL),Redis 也被叫作非关系型数据库。
2. Redis 中,键的数据类型是字符串,值的类型有 字符串、列表、字典、集合、有序集合。
2.1 列表
(1) 列表是简单的字符串列表,按照插入顺序排序。常用指令:
LPUSH keyname v1
LPUSH keyname v2
LINDEX keyname 0 //取索引号为0的数据
LRANGE runoobkey 0 1 //取索引号为0到1的数据(2) 它的内部数据存储方式,有两种:一种是压缩列表(ziplist),另一种是双向循环链表。
压缩列表的说明在后面。
双向循环链表是一个list结构,包含首尾指针,以及数据长度信息。
2.2 字典 (又称 hash)
(1) 字典是一个 string 类型的 field(字段) 和 value(值) 的映射表,用来存储一组数据对。
HGET key field
HSET key field value
HMSET key field1 value1 [field2 value2 ]
HMGET key field1 [field2]
HGETALL key(2) 对应两种实现方法:压缩列表,和 散列表。
存储的数据量比较小的情况下使用压缩列表,否则使用散列表。
2.3 集合(set)
(1) 用来存储一组不重复的数据,是无序的。
SADD key member1 [member2] //向集合添加一个或多个成员
SMEMBERS key //返回集合中的所有成员(2) 对应两种实现方法:一种是有序数组(保证不重复),另一种是散列表。
当 存储的数据都是整数 且 存储的数据元素个数不超过 512个,就采用有序数组。
否则使用散列表。
2.4 有序集合(sortedset)
(1) 用来存储一组数据,是排序的。并且每个数据会附带一个得分。
ZADD key score1 member1 [score2 member2] //向有序集合添加一个或多个成员,或者更新已存在成员的分数
ZRANGE key start stop [WITHSCORES] //通过索引区间返回有序集合指定区间内的成员
(2) 对应两种实现方法:一种是压缩列表,另一种是跳表。
3. 数据结构持久化 即把数据存储到硬盘,有两个方式:
(1) 清除原有的存储结构,只将数据存储到磁盘中。
节省空间,但耗费时间大。
(2) 保留原来的存储格式,将数据按照原有的格式存储在磁盘中。
节省时间,但耗费空间大。
4. 压缩列表 的存储方式说明
压缩列表是 Redis 自己设计的一种数据存储结构。
类似数组,通过一片连续的内存空间来存储数据。但它的结构是 数量+数据1长度+数据1内容+数据2长度+数据2内容的方式存储。如下图所示:
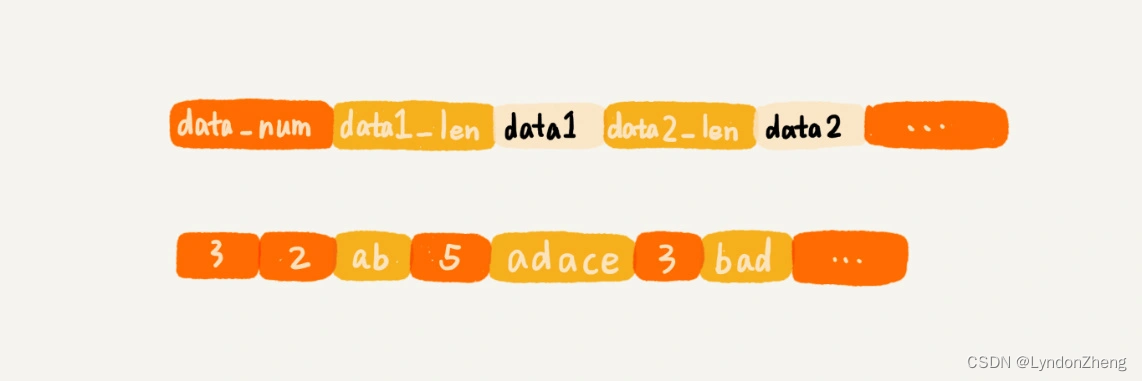
好处是节省空间,允许存储不同的数据结构,但数据量比较大时,就不适用了。
53 | 算法实战(二):剖析 搜索引擎 的数据结构和算法
1. 总体思路: 搜索引擎大致可以分为四个部分:搜集、分析、索引、查询。
(1) 搜集:利用爬虫爬取网页
(2) 分析:网页内容抽取、分词,构建临时索引
(3) 索引:通过临时索引,构建倒排索引
(4) 查询:响应用户的请求,根据倒排索引获取相关网页,返回查询结果给用户
2. 搜集
把整个互联网看作数据结构中的有向图,把每个页面看作一个顶点。
如果某个页面中包含另外一个页面的链接,那就在两个顶点之间连一条有向边。
利用图的广度遍历搜索算法,来遍历整个互联网中的网页。
2.1 将网页的链接内容,直接存储到 links.bin 文件中
2.2 使用布隆过滤器,把重复的网页链接剔除掉
2.3 把网页原始内容,存储到doc_raw.bin 文件中,并记录好网页编号。控制每个文件大小1G。

2.4 网页链接和对应编号的关系,村粗到 doc_id.bin 文件中
3. 分析
网页爬取下来之后,我们需要对网页进行离线分析。
3.1 抽取网页文本信息
通过字符串匹配算法,去掉 JavaScript 代码、CSS 格式、下拉框内容和HTML 标签。
3.2 分词并创建临时索引
文本信息在分词完成之后,得到一组单词列表。单词与网页之间的对应关系,写入到一个临时索引文件中 tmp_Index.bin
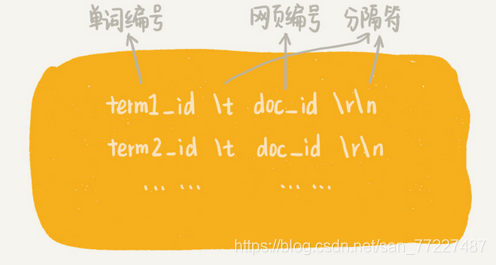
存储的是单词编号,也就是图中的 term_id,而非单词本身。 另外使用散列表来建立单词和单词编号的对应关系。
写入到磁盘文件term_id.bin 中
4. 索引
4.1 将分析阶段产生的临时索引,构建成倒排索引。即从单词编号,查询网页编号
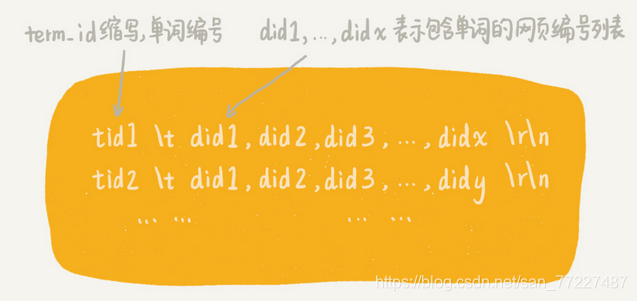
4.2 对临时索引文件,按照单词编号的大小进行排序。
因为临时索引很大,基于内存的排序算法就没法处理。
可以用归并排序的处理思想,将其分割成多个小文件,先对每个小文件独立排序,最后合并在一起。
4.3 排序完成之后,相同的单词就被排列到一起。这时做合并处理。
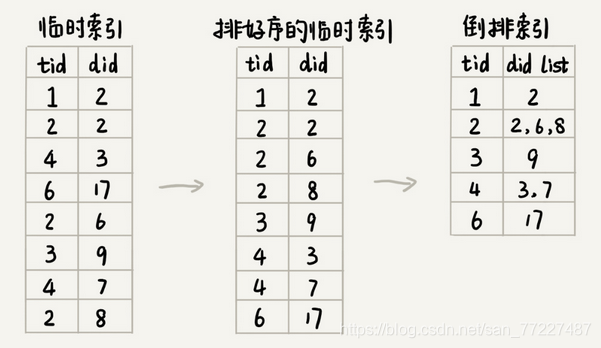
4.4 记录每个单词编号在倒排索引文件中的偏移位置,写入文件 term_offset.bin中。
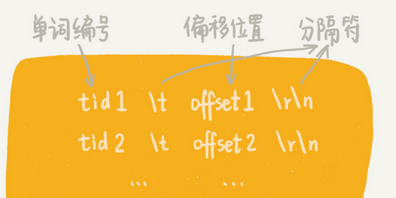
5. 查询
用户输入查询文本 ==> 分词处理,得到k个单词 ==> 获得k个单词的单词编号 ==>
获得倒排索引文件中的偏移位置 ==> 获得网页编号列表 ==> 获得网页链接 (快照内容原理大致相同)
54 | 算法实战(三):剖析 高性能队列Disruptor 的数据结构和算法
1. 高性能队列Disruptor: 就是多线程的生产消费者队列。
2. 常见的内存队列往往采用循环队列来实现。只有一个生产者和一个消费者的场景,已经足够了。
但是,当存在多个生产者或者多个消费者的时候,就无法正确工作了。
3. Disruptor队列的处理方法是,分开两步,先事先申请内存空间(多个),然后再写数据。
申请内存空间时加锁,写数据时不用加锁。
这样处理的方法效率高很多。
55 | 算法实战(四):剖析 微服务接口鉴权限流 的数据结构和算法
1. 微服务定义:
把复杂的大应用,解耦拆分成几个小的应用。
每个应用都可以独立运维,独立扩容,独立上线,各个应用之间互不...
2. 鉴权
实现接口鉴权功能,需要事先将应用对接口的访问权限规则设置好。
可以拿应用的请求 URL,在规则中进行匹配。有三种方式:
2.1 精确匹配: 整个url做字符串匹配,
2.2 前缀匹配:Trie 树非常适合用来做前缀匹配,每个节点存储接口被“/”分割之后的子目录。
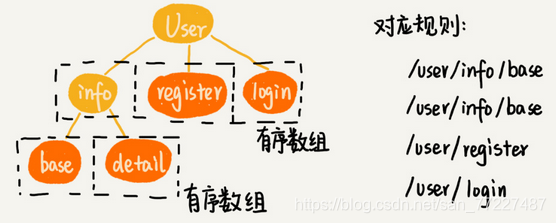
2.3 模糊匹配:规则中包含通配符,比如“**”表示匹配任意多个子目录
采用回溯算法,拿请求 URL 跟每条规则逐一进行匹配。
3. 限流
对接口调用的频率进行限制。
3.1 固定时间窗口限流算法
3.2 滑动时间窗口限流算法:流量的整形效果更好,流量更加平滑。