| 二维条形码编码与译码的计算机实现 戴 扬,于盛林 (南京航空航天大学自动化学院,南京,210016)
二维条形码在国外的使用已经相当普遍。在我国,由于大部分技术及设备目前仍是从国外引进,导致二维条码使用成本较高,实际应用范围很小。进口的条码识读设备必须和与它对应的编码软件配套使用,只有知道编码格式才能建立对应的译码软件。本文通过实例探讨如何使用计算机实现二维条形码的编码和译码。
1 PDF417计算机编码
计算机编码过程就是将可读信息转换成用于绘制条码的码字,然后加上必要的附加信息。其流程为:运用编码算法将有用信息转换成PDF417码字,再通过数据库查询把码字转换成对应的条空相间的符号字符,最后在计算机上将那些层层相叠的条空绘出。即二维条形码图像。
PDF417条码符号是一个多行可变长结构,每行数据符号字符数相同,行与行左右对齐,直接衔接。其最小行数为3,最大行数为90。以下为一个7行的PDF417条码,每行自左向右结构如图1所示。
PDF417条形码有三种数据压缩模式:文本压缩模式(TC);字节压缩模式(BC);数字压缩模式(NC)。其中文本压缩模式将两个字符以30为基组合成一个码字,该模式在表述文本时效率较高。码字=30×H+L,H,L依次表示字符对中的高位和低位字符值。
 数字压缩模式通过从基10到基900的转换压缩数据。将约3个数字位用一个码字表示,在表示数字时效率最高。 数字压缩模式通过从基10到基900的转换压缩数据。将约3个数字位用一个码字表示,在表示数字时效率最高。
字节压缩模式通过基256到基900的转换,将6个字节转换成5个码字,从左到右进行转换。它有两个模式锁定(901,924)。当要表示的字节总数不是6的倍数时,用模式锁定901;当所要表示的字节总数为6的倍数时,用模式锁定924。如6个字节A1,A2,A3,A4,A5,A6转换为5个码字S1,S2,S3,S4,S5,方法为
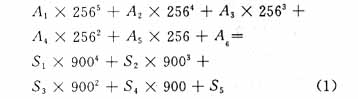
上式中A1~A6均以十进制数形式带入。
若所要表示的字节数不是6的倍数,除模式锁定码字用901外,对于被6整除所剩余的字节,每个字节对应一个码字,逐字节用码字表示。另外,以上三种预定义的压缩模式可以结合使用,通过应用模式锁定/转移(Latch/shift)码字,可在一个四一七条码符号中应用多种模式表示数据。字节压缩模式的算法较为复杂,所以本文中将采用字节压缩模式为例。
1.1 数据码字的生成
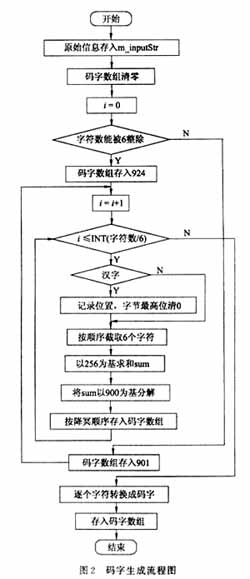
在话框中输入待编码的原始信息,将其转换成PDF417码字序列。我国国标规定汉字用内码表示,内码为两个字节。为保证和西文兼容且不冲突,目前规定每个字节只用7位,若两个字节的最高位均为1,则改字符为汉字。在PDF417编码过程中,对读入的字节进行最高位校验,若连续两个最高位为1,则记录其位置,并将该位清0。这部分包含较多烦琐的计算,软件流程图见图2。
 1.2 纠错码字的生成 1.2 纠错码字的生成
根据已得的数据码字和选择的纠错等级计算纠错码字。纠错码字的计算包括以下步骤:
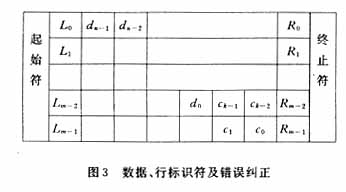
(1)建立符号数据多项式,表达式见式(2)。式中多项式系数由数据码字区的码字成,包括符号长度码字、数据码字和填充码字,排列位置如图3[4]。其中Li,Ri为左、右行指示符,di为数据码字,Ci为纠错码字。
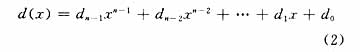
(2)建立纠错码字的生成多项式,具有k个错误纠正码字的生成多项式为
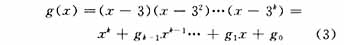
(3)错误纠正码字的计算。对于一组给定的数据码字和一选定的错误纠正等级,错误纠正码字为符号数据多项式d(x)乘以xk,然后除以生成多项式g(x),所得余式的各项系数的补数。实现程序较长,请参见文[4]。这部分数据码字只是原始信息转换,还没有包括条码的标识符号。由于标识符号的多少是根据条码行数确定,由此先绘制主信息部分,以后再使用同样的绘制流程绘制标识部分。
得到纠错码字之后,根据码字数量选择条码的行数和列数,在码字数组中适当加入少量填充码字,使图形成工整的长方行。此例中选用900为填充码。
PDF417条形码的符号字符集分为3个簇,每一簇包括以不同的条、空形式表示的929个417条码的码字。对应的簇号为0,3,6。每行只使用一个簇中的符号字符,同一簇每三行重复一次。这样的目的是在译码时,形成一条无形的分行符,便于译码器识别。
在进行PDF417符号字符查询时,除了要知道码字值外,还要知道该码字在条码图形中的位置,从而确定它所在的簇。这需要预先设计好条码的行数和每行所含的码字数。簇号与层号的关系为
簇号=[(层号-1)mod3]×3(4)
1.3 条码行指示符的计算
左、右行指示符号字符的值由下式确定,其位置亦可参见图3。
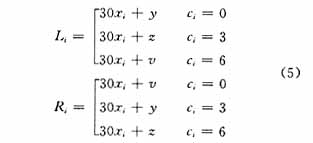
其中X=INT[(行号-1)/3]i=1,2,3,…,90,y=INT[(行数-1)/3];z=错误纠正等级*3 (行数mod3;v=数据区的列数-1;Ci=第i行的簇号。
1.4 符号字符查询的实现
现在要把数据码字转换成PDF417条码的符号字符。这一过程可以通过用查询数据库来实现。这里所指的数据库与一维条形码使用时所附带的信息数据库不同,所记录不是产品或服务对象信息,而是码字与PDF417符号字符的对应关系。符号字符数据库共包含929×3=2787条记录,是一个比较小的数据库。
在VisualC++中使用ODBC(开放式数据库连接Open database connectivity)进行数据查询是比较方便的。建立与ODBC数据源相连的数据库类CBarSet,它派生自MFCCRecordSet类,属性为snapshot。在进行数据检索时的要依据两个检索值,分别是每一个码字的数值和它所在的簇。其中,码字的数值在之前的编码流程中就已实现。另一方面,由于我们在知道数据码字和纠错码字的数量之后已经确定了条码图形的行数和列数,此时可依据式(4)计算出其簇号。利用Query语句查出与它相应的 PDF417符号字符。除了完成查询之外,为便于在以后的绘图过程中进行信息读取和处理,我们还需要转换所得结果的形式,把以字符串为元素的数组转换为以单个字符为元素的数组。
在源程序中,我们将查询到的符号字符按顺序存入CStringArray类型(字符串数组)变量m-StringArray中。在以后绘制条码图形时会注意到,需要知道每个符号字符的条和空所对应的模块宽度,以确定它们的相对位置,所以要把符号字符转换单个字符。于是建立CString类型(字符串)变量wholestr,将m-StringArray 中的符号字符首尾相连存入wholestr中。选用strcat函数,进行字符拷贝,它的原形为:char*strcat (char*strDestination,const*strSource)。注意,执行strcat之前需要为wholestr开辟数据缓冲区,执行结束后需将缓冲区释放。
为增加程序的通用性,实现查询功能的程序参数选用指针类型变量pArray,它当前为指向记录原始信息码字的数组的指针,以后它还可以根据需要指向记录左右层指示符或者起始终止符的数组。
1.5 条码图形的绘制
同数据库检索符号字符一样,绘制条码图形之前也要确定图形的行数和每行的码字数,进而确定每个符号字符在图形上的位置。在这里我们选用的方法为:将wholestr中的单个字符转化为整形数,选用字符数“1”所对应的条的宽度(即1个模块宽度)作为绘图的“笔宽”m-intWidth,根据所需条码图形的高度选定模块的长度m-intHeight。再依据其黑白相间的特性确定各个条空的起始点和终止点的坐标(注意考虑每个码字的位置)。最后运用Visual C++GDI绘图功能中的CDC函数在屏幕上实现条码的绘制。
假如wholestr字符串中有一个符号字符51121322,对它的处理过程应是,将每个条和空所包含的模块数转换成整数,即:5个模块(条),1 个模块(空),1个模块(条),2个模块(空)…再按这个顺序绘图:画5笔黑,跳过1个模块宽度,再画1笔黑,跳过2个模块宽度…在这里,使用画笔的概念来描述是为了便于读者理解,在编程时,鉴于条码图像的大小要具有可调节性,使用GDI画笔(CPen)可能会导致图像在被放得较大时边缘出现毛刺。所以使用黑色GDI画刷(CBrush)来填充包含数个模块宽的“条”。可见,问题的关键是根据符号字符和它的位置确定每一个“条”所对应的矩形框的四个顶点的坐标。
由PDF417每个符号字符包含8个条空,且条空相间的特性可知,如果某符号字符在wholestr字符串中的顺序位置号能被2整除,则它必为 “条”。假设wholester字符串中某一“条”符号字符为c,c=wholestr.GetAt(i).将符号字符转换为整数形式,int k=atoi(c);CPoint类型变量m-UpPos记录某一“条”(黑色矩形)的左上角顶点A的坐标;m-BottomPos记录该“条”的左下角顶点B的坐标,则m-BottomPos.x=m-UpPos.x;m-BottomPos.y=m-OldPos.y+m-intHeight;C为矩形的右上角,此时m-UpPos更新为C点坐标,即m-UpPos.x=m-UpPos.x+k*m-intWidth。我们需要将所有顶点的坐标都保存入点数组CPointArray。除此之外,还要注意不同行的各个码字之间相对位置的差别,以整个条码图像的左上顶点m-LeftStartPos为参照点,第j行第一个“条”矩形的起点就是m-UpPos.x=m-LeftStartPos.x;m-UpPos.y=m-LeftStartPos.y+j*m-intHeight。在确定每点的坐标之后,就可以用Microsoft VC++MFC的画刷(CBrush)对象为各个“条”矩形着色,连接各点,绘制出二维条形码的图形。
图4就是该程序的编码结果,一个25行的二维条码图像,图像的大小可根据使用需要任意调节。
 2 PDF417二维条行码的计算机译码 2 PDF417二维条行码的计算机译码
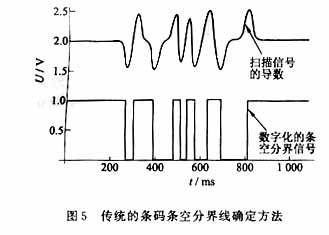
译码过程的重点在于对条码图形的条空分界线的扫描。现有的条码扫描仪大多采用模数转换的方法探测条码图形上的黑和白(条和空)。其中常见的光束式条码扫描仪,直接采用模拟电路探测条码的条空分界信号,其原理如下:扫描光被黑部分吸收,被白部分反射,于是可将黑白视觉信号转化为电信号,再经整形,滤波。黑和白对应不同的电压值。由于在条和空的分界线处将出现较大的电压跳变,于是它的导数会出现极大值或极小值,因此使原始扫描信号经过微分滤波器后,只要探测到大于门限电压的跳变电压,就视为一个条空分界线(边缘信号)。这样,可将模拟信号转化为数字信号,条码的条空宽度与所得的边缘信号的间距成正比。如图5所示[2]。然后再使用定时计数器计算条空的宽度比。但是,光束式条码扫描仪的频域特性相当于一个高斯低通滤波器,扫描结果将使条空分界线钝化,降低以后操作中对信号检测的准确性[2]。所以它多用于信息密度较低的一维条形码。
这里,不采用这种直接使用模拟电路来确定边缘信号的方法,而是将条码图形通过内置CCD扫描仪整图读取,然后通过计算机编程来完成条空分界的扫描过程。实验证明,该方法的译码准确率非常高。另一方面,由于模拟电路实现的译码器对扫描角度有一定要求,角度太大则不能译码[1]。采用计算机编程的方法就不会存在类似问题。条码图片以.bmp文件格式读入,通过编程对该图像直接进行处理。
译码流程为:
 (1)对图像进行二值化处理。 (1)对图像进行二值化处理。
(2)扫描二维图片,根据灰度变化定位条形码。
(3)对每一层的不同位置作多次扫描,确定起始和终止符中所包含的单位模块的宽度。
(4)根据PDF417码的特性,如条空宽度皆为单位模块宽的整数倍,每个码字对应的条空宽度和为17等,选出每一层中最合适的扫描结果,并对其做规格化修正,得到符号字符。然后,再按8个符号字符与一个码字相对应的关系分割,得到全部码字信息,然后将以上编码所进行的各步运算逆转,除去左右标志符等附加信息就可以完整的实现译码。
下面给出一部分实现扫描功能的程序的具体说明。利用MFCCDC类中的GetPixel()函数,它的作用是读取某点的颜色值,以RGB值表示。扫描该位图的过程是:从扫描起始点开始,返回该点的颜色信息,若某点是黑,则存入数组中,紧接着扫描颜色不是黑的点(因为图像在从数码相机或扫描仪读入的过程中,颜色的灰度可能会发生细微变化,所以在此之前对图像进行二值化处理。为确保可靠性,我们只选一个参照色,用是、非来区分。)扫描到颜色不是黑色的点后,比较该点与该点前一像素点颜色是否相同,若不同,则它必是条码条空变化的分界点,则将其记录入数组。由此继续下去,一行扫描完后,数组记录的各点均为黑白色的分界点横坐标,它们的差值就是条空的宽度,除以单位模块宽,所得即为PDF417的符号字符。一行扫描结束后再转入下一行。
3 结 论
本文介绍的方法经实验证明可以有效地进行信息的编码和译码。该程序可以运行在 Windows98,2000及NT操作系统下。利用计算机进行编码译码可以有效的利用廉价的打印、识读设备。由于我们建立了自己的编码译码系统,就可以在编码过程中加入各种加密形式。比如采用混沌方法对原始信息随机排序或在二维条形码表面加上水印加密处理等等。相应地,在译码时采用同一个混沌序列或者水印解密方法就可以实现条码信息的加密与防伪。由此可见,二维条码的计算机编码译码方法具有很高的实用价值。
[1] Pavlidis T,Swartz J,Wang Y P.Information en-coding with two-dimensional bar codes[J].IEEE Computer Magazine,1992,25:18~28.
[2] Shellhammer SJ,Goren D P,Pavlids T.Novel sig-nal-processing techniques in barcode scanning[J].IEEERobotic&Automation Magazine,1999,1070:57~65.
[3] Pavlidis T.A new paper/computer interface:two-dimensional symbologies[M].IEEE Computer Maganize,2000.145~150.
[4] 中华人民共和国国家标准GB/T 17172-1997四一七条码[S].国家技术监督局1997-12-25批准,1998-08-01实施.
[5] 朱卫东,张艳树.二维条码技术与应用.北方交通大学学报,1999,21(3):372~374. |