前言
本文讲解的BERT系列模型主要是自编码语言模型-AE LM(AutoEncoder Language Model):通过在输入X中随机掩码(mask)一部分单词,然后预训练的主要任务之一就是根据上下文单词来预测这些单词,从而得到的预训练语言模型。
而不是关于自回归语言模型-AR LM(AutoRegressive Language Model):根据上文内容来预测下一个单词,或者根据下文内容来预测上一个单词,即自左向右或自右向左的语言模型。
在某些垂直领域,直接微调开源BERT模型或许效果不是很理想,可以使用该领域的无标注文本数据继续预训练,然后再用标注数据进行微调。这个github仓库提供了tensorflow和pytorch两种版本的预训练代码。
起源发展
谷歌在2017年发表的论文《Attention Is All You Need》中,针对序列问题,例如机器翻译、语言模型等,沿用encoder-decoder的经典思想,但是Encoder和Decoder不再是以往的LSTM或者门控神经网络,而是提出了一种Transformer的网络结构,在 WMT 2014 English-to-German translation task、WMT 2014 English-to-French translation task都超过了当时最好的成绩。
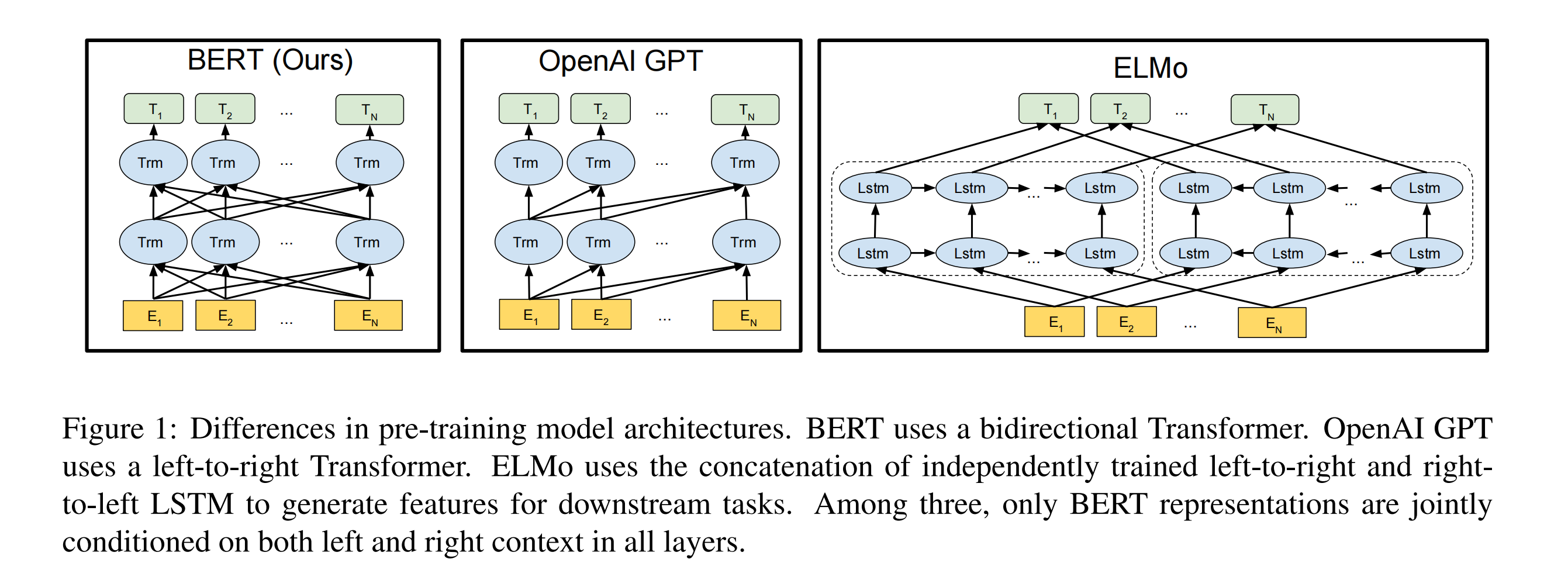
后面,2018年的ELMo和OpenAI GPT把预训练带入NLP领域。
- 其中,ELMo是feature-based的形式,在大型语料上训练好一个Bi-LSTM模型,然后利用这个预训练语言模型提取的词向量作为额外特征,补充到down-stream的具体序列模型中;
- 而OpenAI GPT则是如今更为普遍的形式:fine-tuning,down-stream的任务直接使用预训练的模型,加上少量的具体任务参数,进行微调。
接着,谷歌在2018年的论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》中,继续沿用Transformer的结构,并且是bidirectional Transformer,仅使用Encoder部分,并取名为BERT(Bidirectional Encoder Representations from Transformers),彻底将Transformer和预训练推广开来,被许多人知晓,洗刷了许多NLP的数据集榜单。
- 预训练可以认为是一种“自监督”的方式,不需要昂贵的标注数据,而是从数据自身中构建标签进行预训练。然后预训练模型在具体的下流任务,使用少量的标签数据进行微调,大大缓解了标注数据稀缺问题。
- 而Transformer至今仍是NLP领域的强大基础结构,许多最为先进的模型都是基于其进行改造,甚至已经推广到CV领域,如Vit。
因此,下面我们将会着重介绍BERT,接着再认识下其他BERT衍生出来的变种模型。
Transformer优势
在Transformer之前的序列任务模型一般是RNN、LSTM、GRU其中一种,它们的特点就是:每个时刻的输出是根据上一时刻隐藏层state和当前时刻的输入,由这样的方式来实现产生序列。
- 那这样的特点就会导致无法并行计算,因为每次计算都需要等待上一时刻的计算完成。
- 每个时刻的输出只与上一时刻的输出和当前时刻的输入相关,这会导致两个问题:
-
对于长序列,这样一层一层地传递,前面时刻的信息到了后面基本就消失了;
-
对于文本问题,每个时刻的输出不仅与上一时刻相关,还可能与前n个时刻相关。以上两个问题也导致了循环神经网络难以学习相对位置较远的文本之间的关系。
而Transformer中大部分都是矩阵相乘,容易并行。
其中的self-attention机制则是所有上下文的交互,而不仅仅是与上一个时刻的交互;并且比RNN&LSTM有着更强的长距离建模能力。
并且,BERT中的双向Transformer真正实现了上下文的双向交互,而双向LSTM其实是由一个前向LSTM和一个后向LSTM组成。
BERT
论文地址:https://arxiv.org/abs/1810.04805
github地址:https://github.com/google-research/bert
BERT全称为Bidirectional Encoder Representations from Transformers,单从名字就可以看出:
- BERT的基础结构仍然是Transformer,并且仅有Encoder部分,因为它并不是生成式模型;
- BERT是一种双向的Transformer,这其实是由它的语言模型性质决定,它提出了一种掩码语言模型-MLM(masked language model)
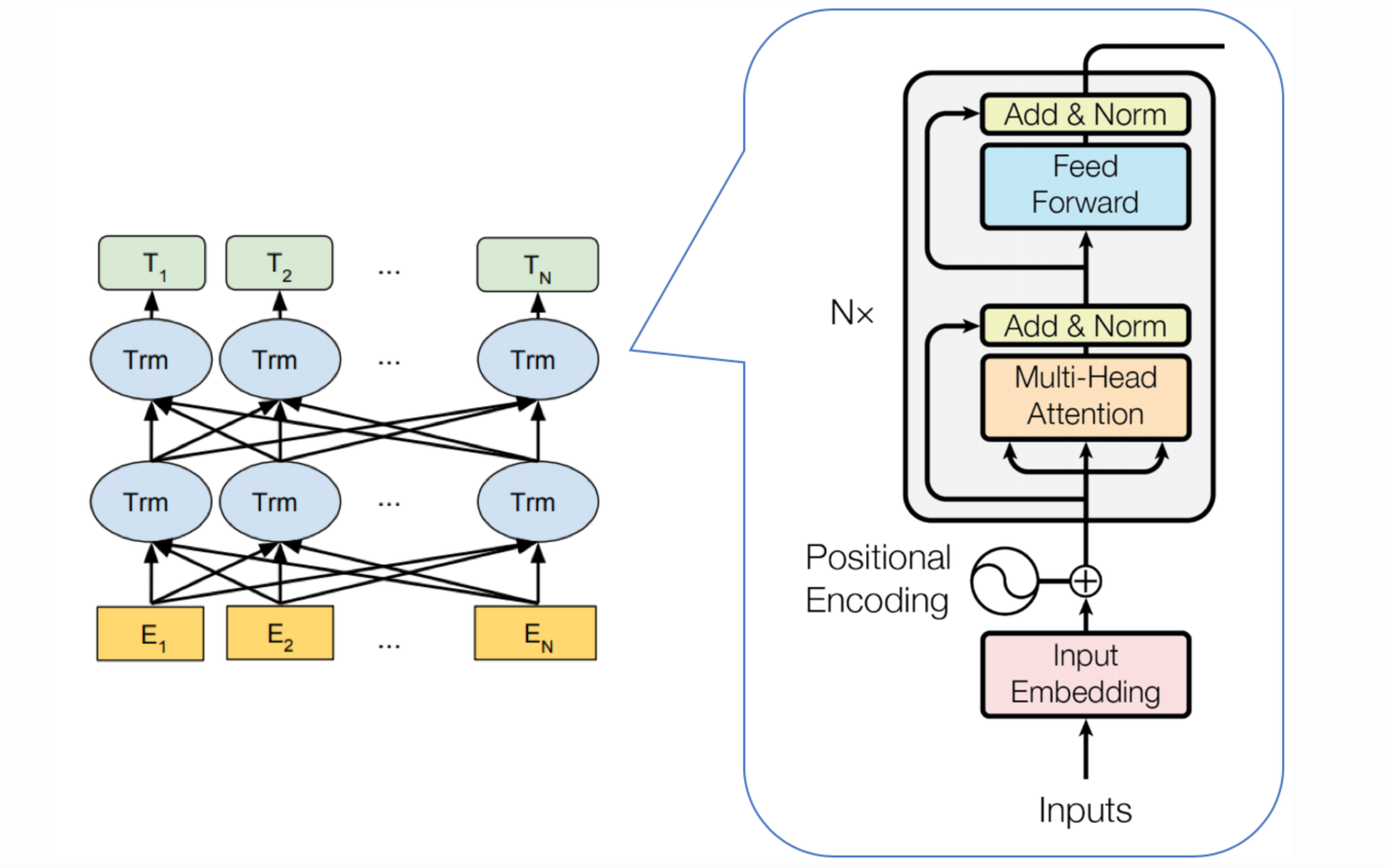
Transformer结构
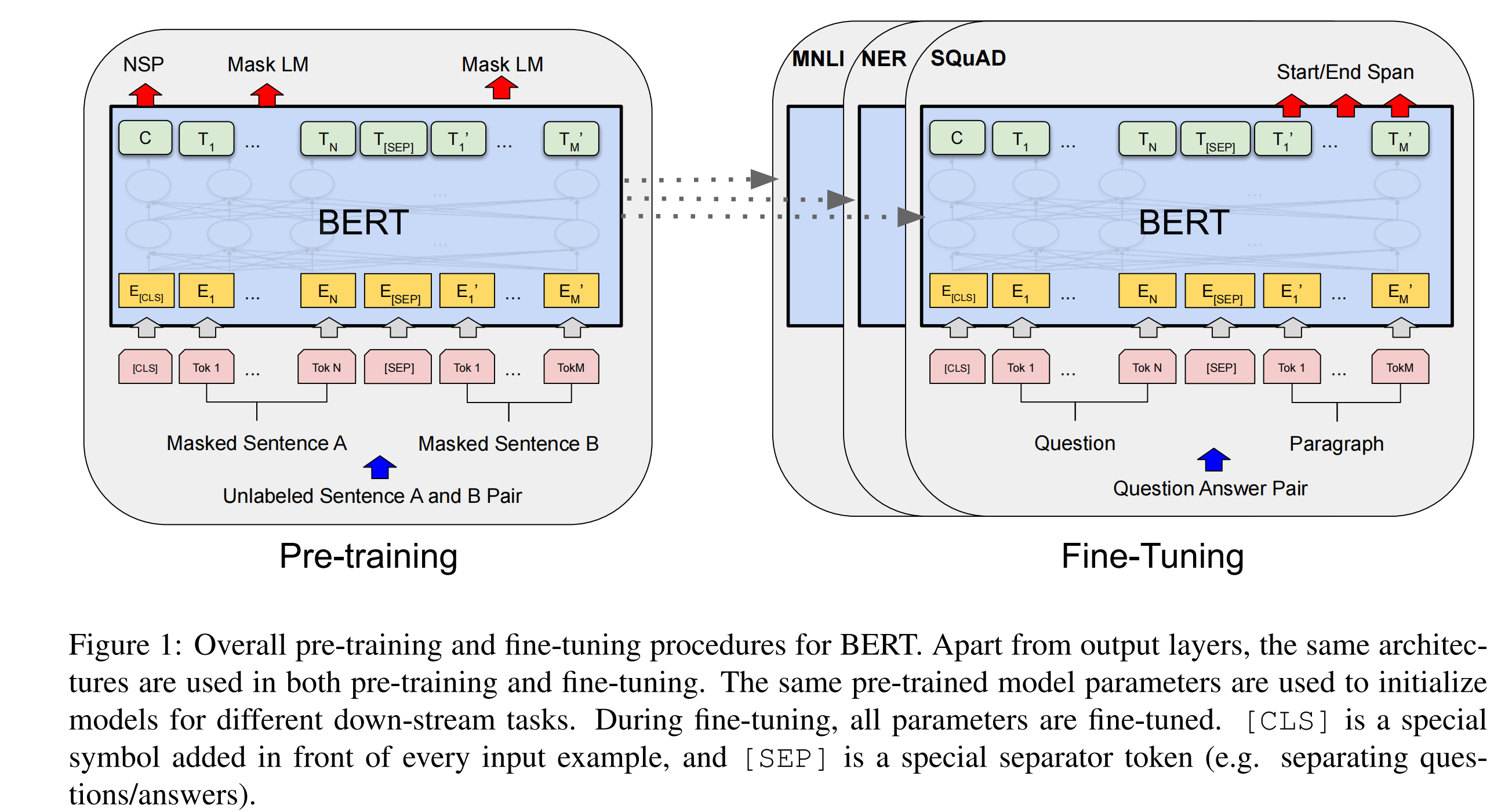
原本的Transformer是有Encoder和Decoder两部分组成,而BERT则仅仅只有Encoder网络,如下图所示:
整体的结构可以总结为:输入表征(Input Embeddings)–>> 多头注意力(Multi-Head Attention)–>> 残差连接(Add) & LayerNorm -->> 前馈网络(Feed Forward)–>> 残差连接(Add) & LayerNorm -->> 输出
1. 输入表征
第一部分是BERT模型的输入,包含三部分,由词表征(token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加,如下图所示:
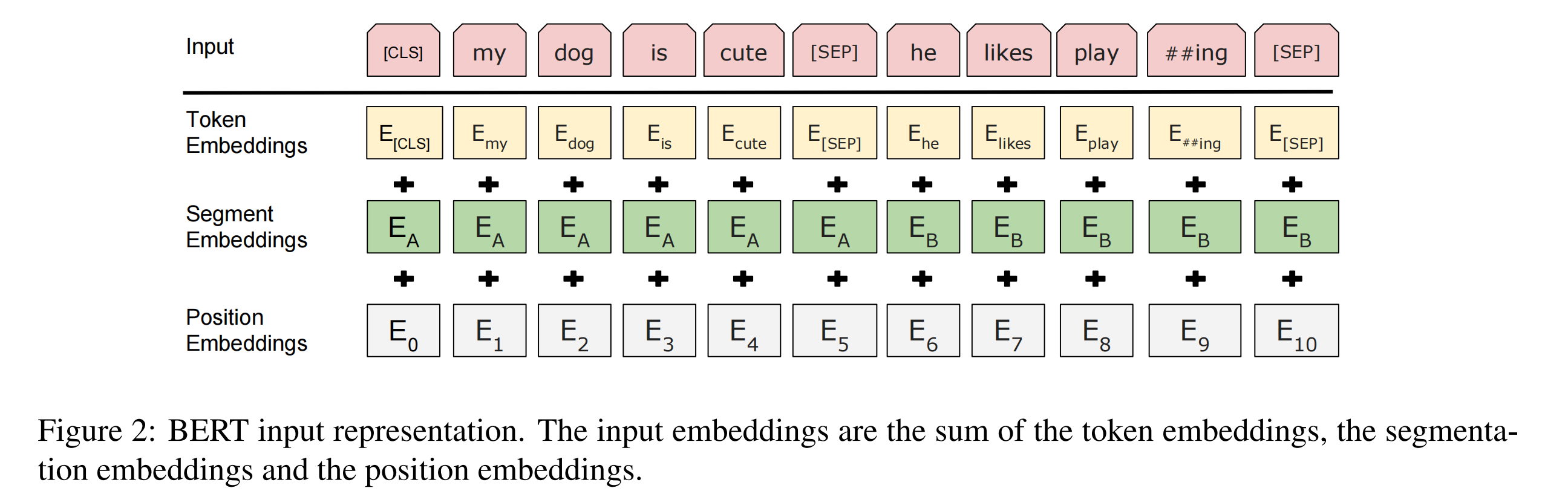
- 其中[CLS]代表初始token,最后改token的可以用于表征整个句子,用于下游的分类任务;
- 模型为了能够处理句子间的关系,两个句子的结尾都插入特殊的token: [SEP],进行分隔,并且两个句子拥有自己的Segment Embedding;
- 不同于RNN或LSTM模型自带序列关系,BERT加入了Position Embedding,来代表不同的位置信息(原Transformer是使用了相对位置编码函数);
- 使用WordPiece来对句子进行token切分,对于英文模型,存在于词表中的则会直接映射,否则会拆分为Subword(如上图的playing被拆分为play和##ing两个Subword),以此来减少词表的规模。而对于中文模型,则可以理解为基于字进行映射。
2. 多头注意力
第二部分是模型的输入表征(上述三种表征相加)会经过Multi-Head Attention,其结构如下图所示:
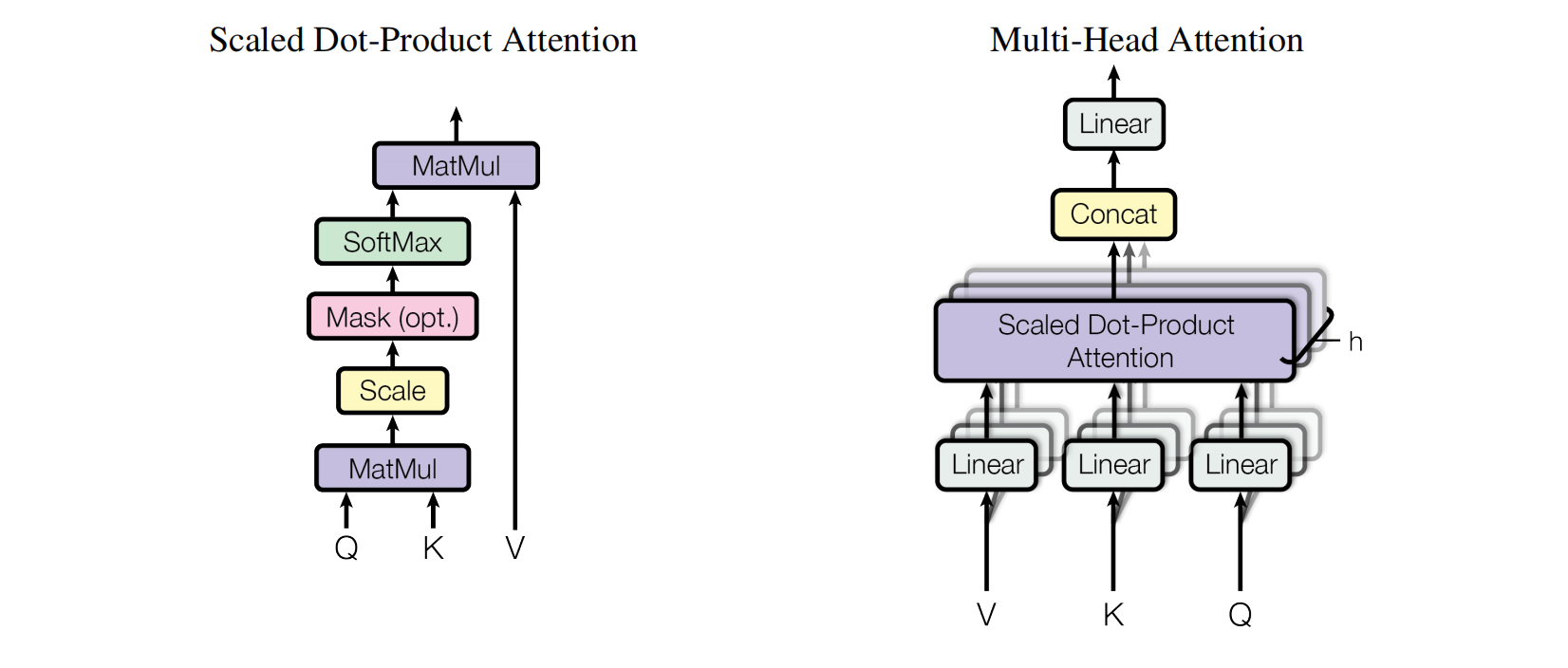
2.1 Multi-Head Attention
首先,来看看Multi-Head Attention的结构:
- 输入由Queries、Keys、Values组成,
- 然后经过一层Linear层,其实就是Dense,并且被拆分为多头。
- 接着又经过一层Scaled Dot-Product Attention;
- 再跟着,将多头Scaled Dot-Product Attention输出进行拼接;
- 最后,经过一层Linear层,得到Multi-Head Attention的输出。

2.2 Scaled Dot-Product Attention
再进一步拆解Scaled Dot-Product Attention的结构:
- 首先,输入就是上面提到的,经过拆分多头的Q、K、V;
- 接着,Q和K进行矩阵相乘,并进行缩放;
- 然后,对填充的token进行Mask,再使用SoftMax函数;
- 最后,与V矩阵相乘得到输出。
具体公式如下:
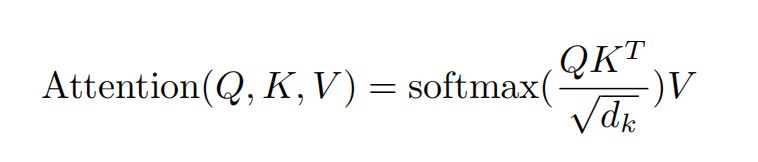
在这有两个疑点:
a. 为什么Q与K相乘之后需要缩放呢?
google在对比试验发现缩放的效果比未缩放的效果好,怀疑是由于随着 d k d_k dk越大,会使得SoftMax层的梯度变得比较小。
b. 为什么需要在这里接入SoftMax层?
因为接入Mask之后,被遮挡的部分会变为绝对值非常大的负数,那么SoftMax可以将其归零。
另外,BERT中的attention其实是一种self-attention,即Q、K和V都是同一个输入表征。
3. 残差连接&LayerNorm
第三部分则是多头注意力的输出,会经过残差连接,即输出会与未经过Multi-Head Attention的输入相加,残差连接有助于避免深度网络中的梯度消失问题;
接着再使用LayerNorm,它能够与batch normalization一样,可以加快训练收敛。但不同的是, LayerNorm不是在行维度(mini-batch)上计算的,仅在单个样本上完成计算,不会受到batch size的影响,训练阶段与测试阶段的计算完全一致,并且能够套用的RNN这些循环网络上。
4. 前馈网络
前馈网络(Feed Forward)就比较简单,由两个全连接层组成,然后第一个全连接层会带有激活函数-gelu。
最后,会再次使用同上述的残差连接和LayerNorm,得到最终Transformer的输出,这就完整的单层的Transformer结构了。
5. 多层Transformer
以上仅是单层的Transformer结构,而BERT-base版本是12层,large版本是24层。
- 第一层中Scaled Dot-Product Attention的输入是第1点中的三种向量表征相加,后面则每一层的输入则是上一层的Transformer输出;
- 而Scaled Dot-Product Attention之后,进入到后续网络的则是每一层(第K层)的Scaled Dot-Product Attention的输出拼接上前面所有层的Scaled Dot-Product Attention输出( C o n c a t ( a t t e n t i o n 1 , . . . , a t t e n t i o n k − 1 , a t t e n t i o n k ) Concat(attention_1,\ ...,attention_{k-1},\ attention_k) Concat(attention1, ...,attentionk−1, attentionk))。
具体可以前往谷歌的开源代码:https://github.com/google-research/bert/blob/master/modeling.py#L754
预训练
BERT在预训练阶段,摒弃了传统的单向语言模型,即 left-to-right or right-to-left,而是使用双向语言模型,上面也提到了这其实是由于BERT使用了一种新的语言模型掩码语言模型-MLM(masked language model),这是BERT使用的两个无监督任务之一,另外一个则是预测两个句子是否为来自连续的段落-Next Sentence Prediction (NSP)。
1. Masked LM
像那种单向语言模型,一般都是根据上文(前面的tokens)来预测下一个token或者根据下文(后面的tokens)来预测上一个token。因为对于双向语言模型是允许每个token“看见自己的”(see itself),类似于模型输入中包含了真实标签,模型会很容易就能够预测的目标token。
BERT为了能够训练一个双向语言模型,它将输入tokens按照一定比例(论文中使用15%),随机将其中一些token进行掩码(mask),用特殊的token来代替:[MASK],然后让模型去预测这些mask的tokens原来对应哪些tokens,mask tokens最后一层的隐藏层向量会喂给一个对应词表的softmax,与标准的语言模型是一样的。
虽然这种做法能够获得一个双向预训练模型,但这会导致预训练和微调存在一种不匹配(mismatch),因为[MASK]这个特殊的token永远不会出现在微调阶段。为了减少这种不匹配的问题,当一个token被选中mask时,并不是必定会替换为[MASK],而是80%的概率被替换为[MASK],10%的概率会替换为词表中随机的另外一个token,10%的概率保持不变。
2. Next Sentence Prediction
许多重要的下流任务,比如Question Answering (QA) and Natural Language Inference (NLI),都是需要模型具备理解两个句子之间的关系,但这却是语言模型所不具备的。
因此,为了让模型具备这种能力,BERT在预训练的时候,还增加了一个二分类任务:Next Sentence Prediction,预测输入的句子B是否为句子A的下一个真实句子。
在构造训练样本时,作为输入的两个句子A和B,50%的概率句子B是真实来自句子A的下一句(Label为IsNext),而50%的概率句子B是从所有语料中的随机一个句子(Label为NotNext)。
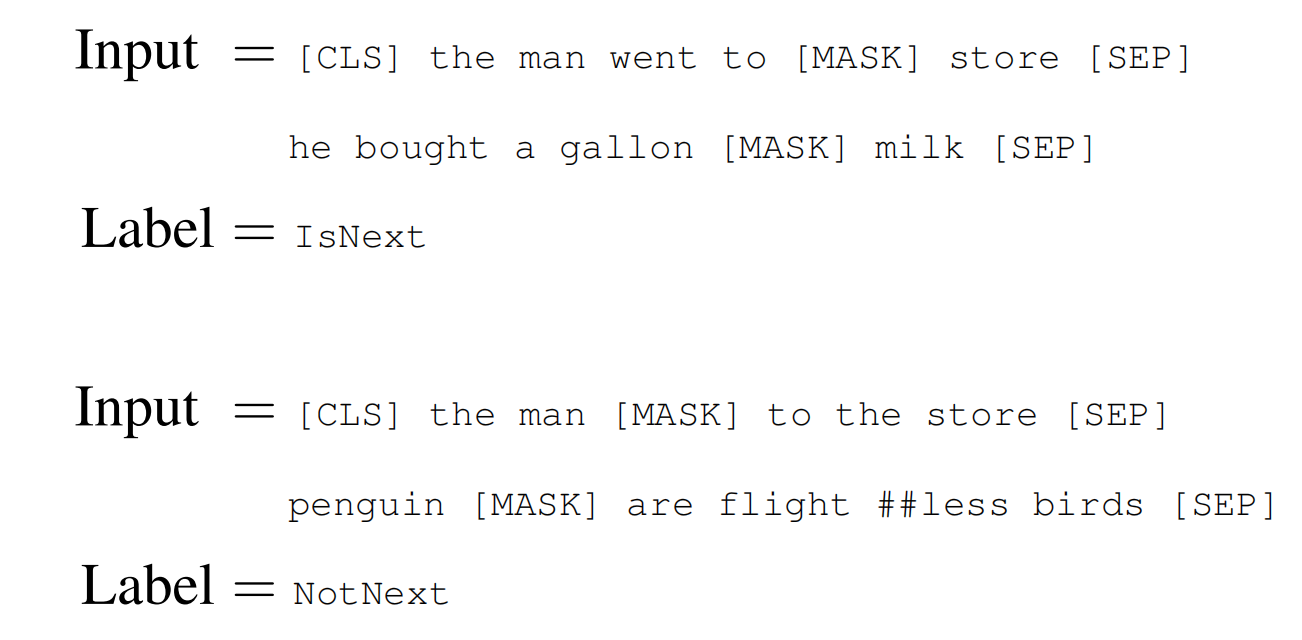
上面也提到每个句子都增加一个初设token-[CLS],这个token的最后输出向量的作用便是用于这个二分类任务的。
实验也表明在预训练时加入这个任务,对QA和NLI有着明显的正向效果。
微调
模型微调则是非常直接,与预训练模型使用完全相同的网络结构,并且预训练模型的参数作为微调模型的初始化。
因为Transformer的self-attention机制,使得BERT能够对许多下流任务进行建模,只需要适当的变换输入和输出,不管是包含单个句子或者是句子对。
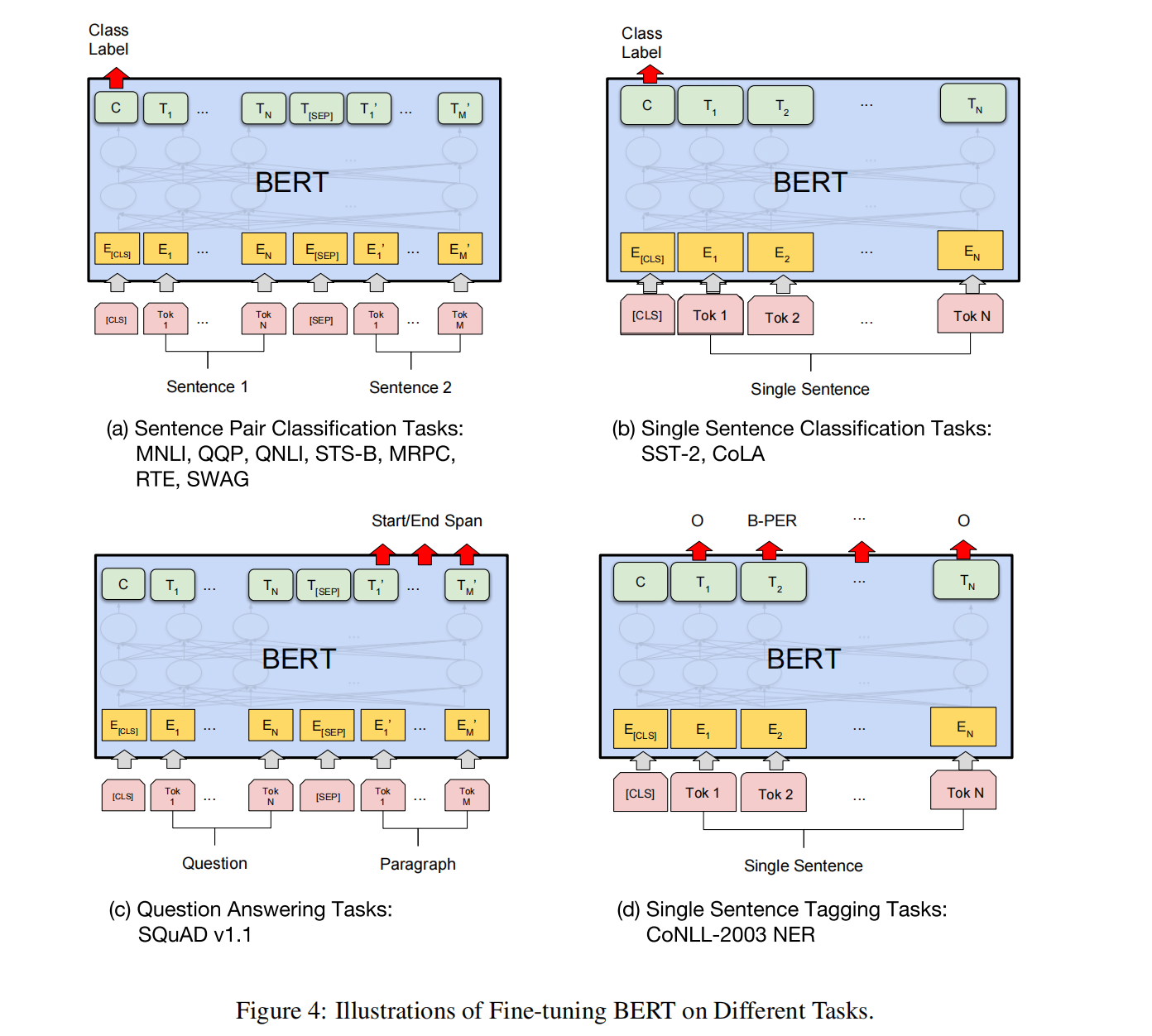
一般来说,对于分类任务,与预训练的NSP任务一样,使用初设token-[CLS]的表征,来喂入到一个分类输出网络中,如K分类任务,则是先将[CLS]的表征向量映射到维度为K的向量,再使用softmax;
对于序列标注(sequence tagging),其实也是类似,使用序列中token的表征来,喂入到一个token级别的分类输出网络,如命名实体识别,将每个token的表征也是先映射到K维的向量,K为实体的数量。
BERT-wwm
后续在2019年,谷歌发布了一个新的预训练模型:BERT-wwm,其调整地方在MLM过程中使用全词掩码(Whole Word Mask):
上述提到,BERT使用WordPiece对句子进行切分tokens,并且会产生Subword,如果Subword被选中mask,那么整个单词都会进行mask,而原来的则不会。
如playing被拆分为play和##ing两个Subword,当##ing被选中mask时,那么play也会同时进行mask。
RoBERTa
论文地址:https://arxiv.org/abs/1907.11692
github地址:https://github.com/facebookresearch/fairseq
RoBERTa出自Facebook:RoBERTa: A Robustly Optimized BERT Pretraining Approach,从论文名称可以明显看出,它提出了一种鲁棒性更强的BERT模型预训练方法。
在这之前,facebook就评估了超参数和训练集规模对BERT预训练的影响,发现BERT其实是明显训练不足的,借此提出了一种更加有效的预训练策略,发布了一个鲁棒性更强的BERT模型:RoBERTa。
不同的训练配置
1. 更多的预训练语料
BERT的预训练语料是 BOOKCORPUS+English WIKIPEDIA的16GB语料,而RoBERTa使用了超过160GB的语料:BOOKCORPUS+English WIKIPEDIA、CC-NEWS、OPENWEBTEXT、STORIES。
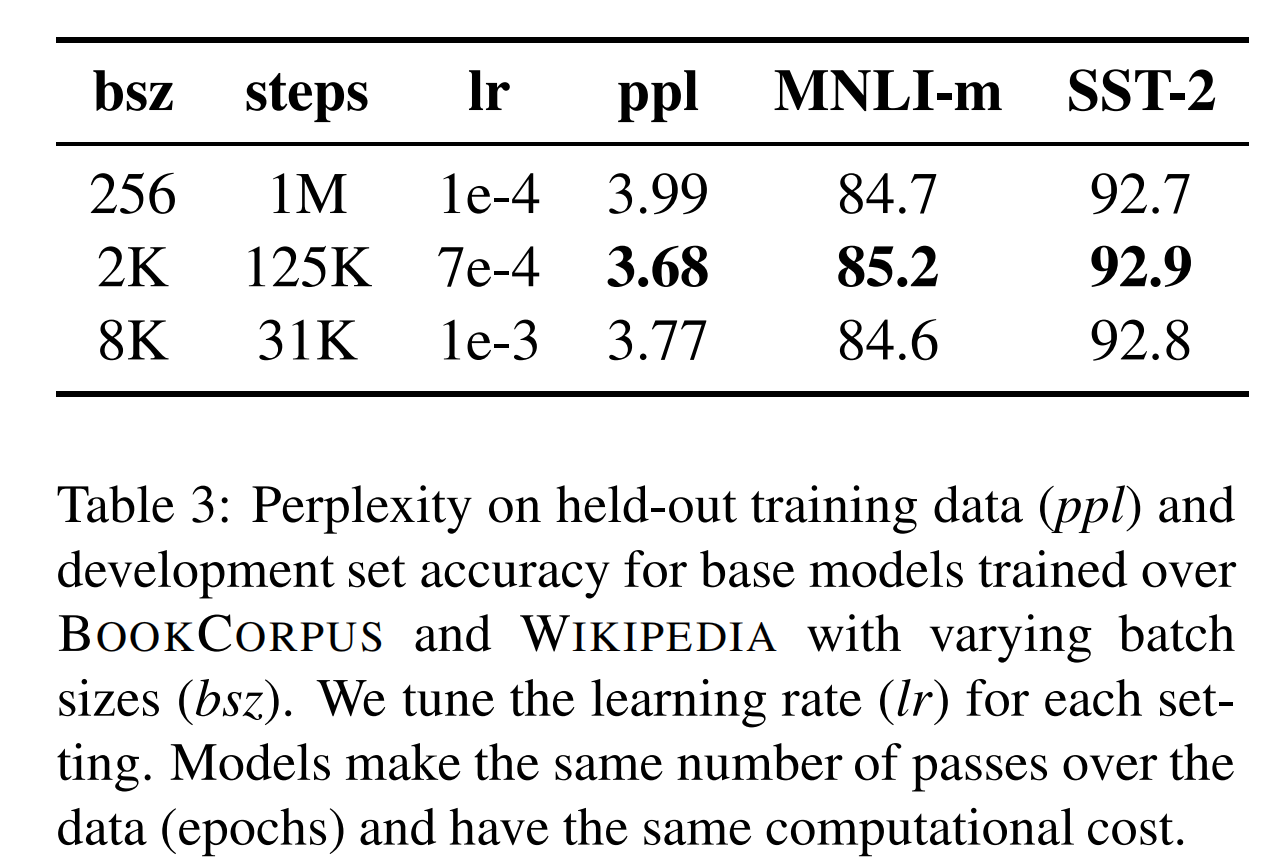
2. 更大的batch size
BERT预训练的batch size为256,而RoBERTa则使用了更大的batch size。
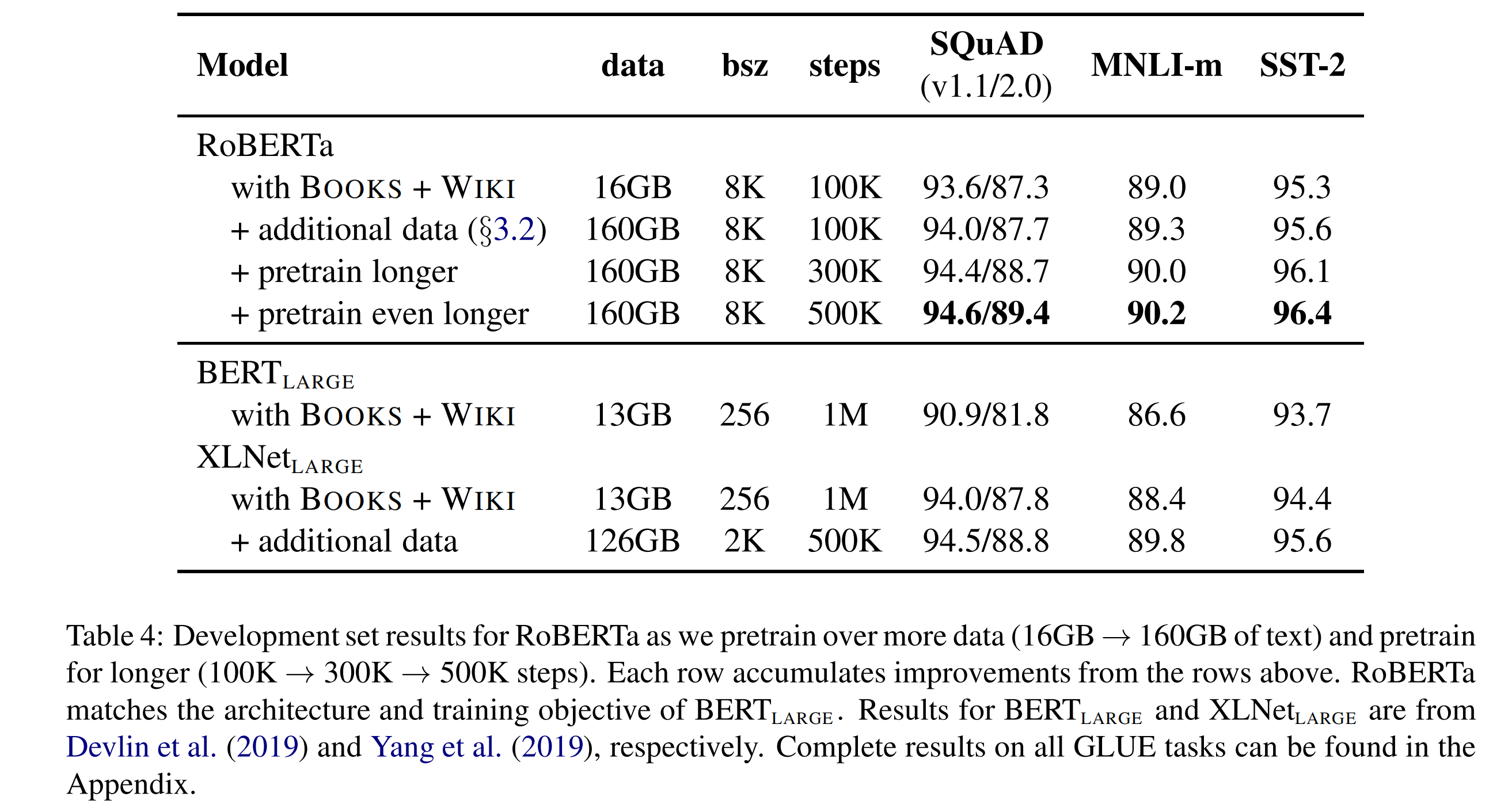
3. 训练更久
论文实验了增加训练步数,可以提升模型的效果表现。这也验证了论文一开始提出的问题:BERT是训练不充分的。
4. 不同的超参数配置
BERT使用AdamW优化器,其中 β 1 = 0.9 , β 2 = 0.999 , ϵ = 1 e − 6 , L 2 w e i g h t d e c a y = 0.01 \beta_1=0.9,\beta_2=0.999,\epsilon=1e-6,L_2\ weight\ decay=0.01 β1=0.9,β2=0.999,ϵ=1e−6,L2 weight decay=0.01,
而RoBERTa修改了 β = 0.98 \beta=0.98 β=0.98,这可以使得更大的batch size,在训练时更稳定。
学习率也如上图所示进行了调整。
##剔除NSP任务
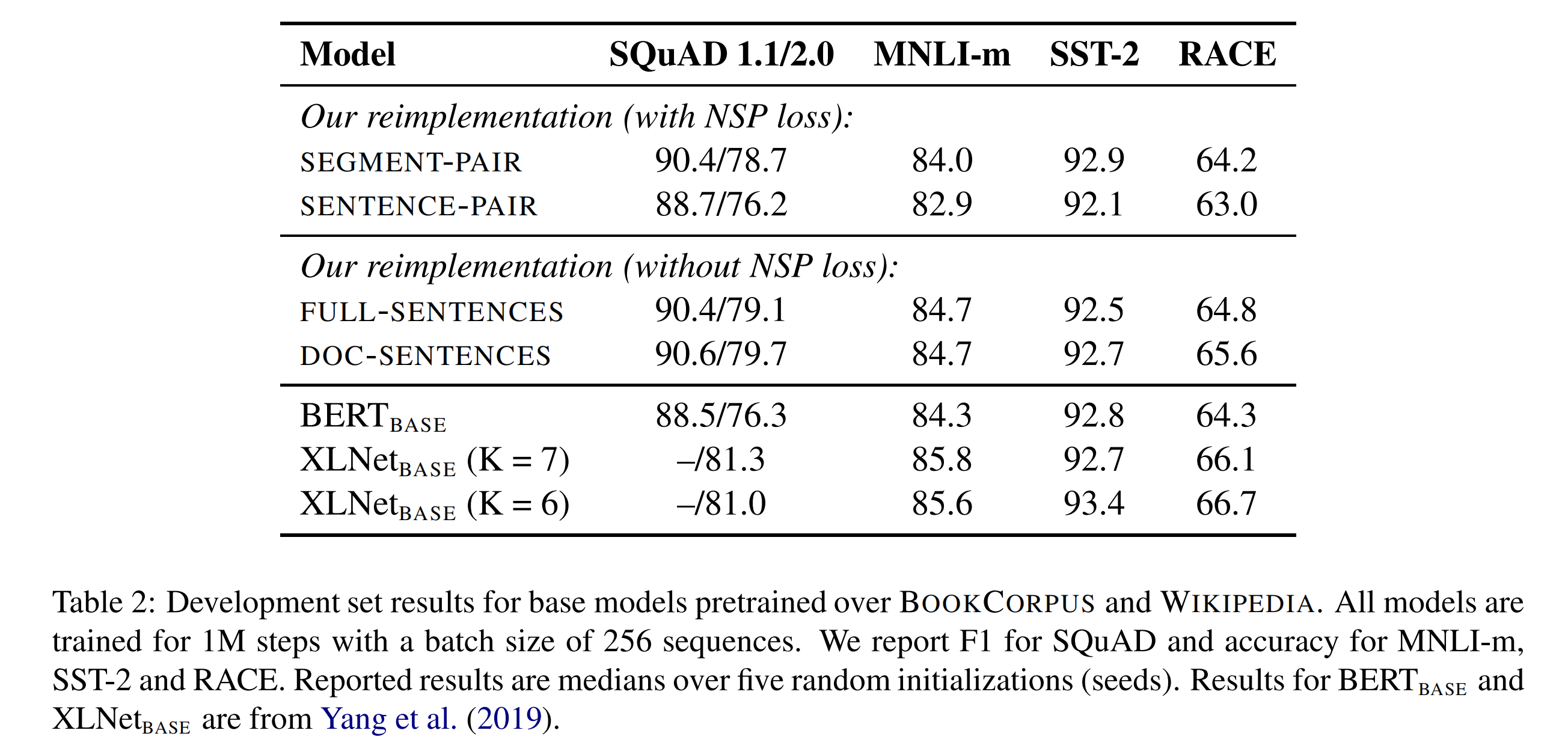
论文实验以下几种句子组合方式的输入格式+NSP保留或剔除的训练方式:
- **SEGMENT-PAIR+NSP:**保留NSP。输入是一对段落(segment),一个segment会包含多个自然句子,tokens序列的最大长度为512;
- **SENTENCE-PAIR+NSP:**保留NSP。输入是一对自然句子,而不是段落。但这样会导致序列长度明显小于512,因此增加batch size,以保证mini-batch下的tokens总数量与上一种方式是差不多的;
- **FULL-SENTENCES:**剔除NSP。输入是完整的句子,并且可能会穿越不同的documents,序列最大长度仍是512;
- **DOC-SENTENCES:**剔除NSP。输入是完成的句子,但不同的是不会穿越documents。同样动态增加batch size,并保证tokens总数量与FULL-SENTENCES接近。
从实验结果来看,使用独立的句子即SENTENCE-PAIR会破坏下流任务的效果,论文认为是这样会导致模型无法学习长距离的上下文依赖;
剔除NSP任务可以轻微提升下流任务的效果,论文认为是BERT仅仅是剔除NSP,但仍然保留SEGMENT-PAIR的输入格式,因此结论是:
剔除NSP的同时,应该使用FULL-SENTENCES或者DOC-SENTENCES的输入格式。
(由于DOC-SENTENCES会导致batch size需要是动态变化的,因此论文后面的实验都是使用FULL-SENTENCES的输入格式)
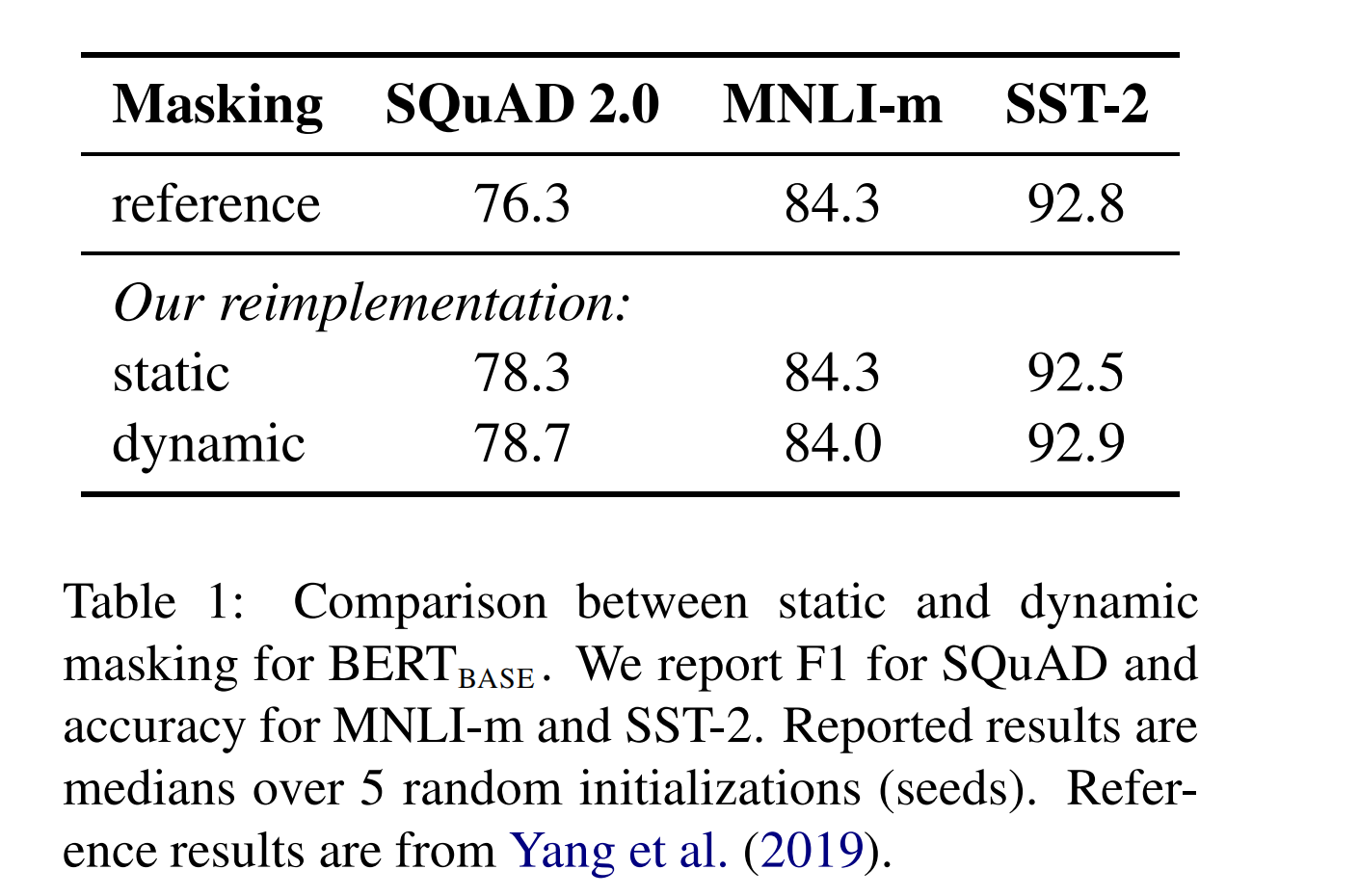
动态mask
BERT中,对于每一个样本序列进行mask之后,mask的tokens都固定下来了,即是静态mask的方式;
而论文使用了动态mask的方式:对于每一个输入样本序列,都会复制10条,然后复制的每一个都会重新进行mask,即拥有不同的masked tokens。
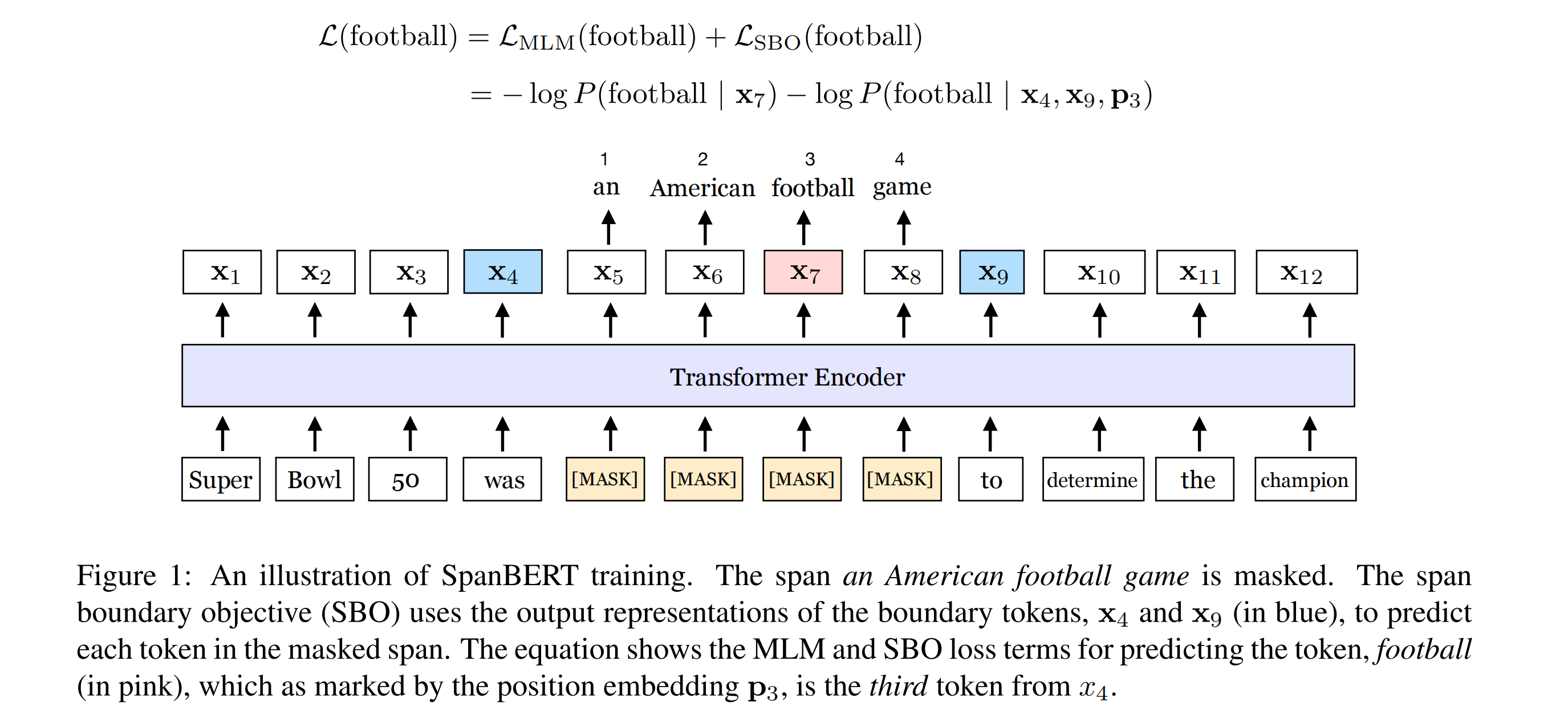
SpanBERT
论文地址:https://arxiv.org/abs/1907.10529
github地址:https://github.com/facebookresearch/SpanBERT
SpanBERT出自Facebook:SpanBERT: Improving Pre-training by Representing and Predicting Spans,看着名字多了一个span,因为它就是在BERT的基础上,针对预测spans of text的任务,在预训练阶段做了特定的优化。
比如SQuAD v1.1数据集,给定一个问题和一个包含答案的段落,任务就是去预测出这个段落的答案片段。
SpanBERT所做的预训练调整主要是以下三点:
- 使用一种span masking来代替BERT的mask;
- 加入另外一个新的训练目标:Span Boundary Objective (SBO)
- 使用单个句子而非一对句子,并且不使用Next Sentence Prediction任务。
因此,SpanBERT最终的预训练目标如下图公式所示: L M L M + L S B O L_{MLM}+L_{SBO} LMLM+LSBO
Span Masking
给定一个tokens序列 X = ( x 1 , x 2 , . . . , x n ) X=(x_1,x_2,...,x_n) X=(x1,x2,...,xn),每次都会通过采样文本的一个片段(span),得到一个子集 Y ∈ X Y\in X Y∈X,直到满足15%的mask。
在每次采样过程中,首先,随机选取一个片段长度,它是满足一个几何分布的 l ∼ G e o ( p ) l \sim Geo(p) l∼Geo(p),然后再随机选取一个起点,这样就可以到一个span进行mask了;
span的长度会进行截断,即不超过10,并且实验得到p取0.2效果最好;
另外,span的长度是指word的长度,而不是subword,这也意味着采样的单位是word而非subword,并且随取的起点必须是一个word的开头。
与BERT一样,mask机制仍然为:80%替换为[MASK],10%保持不变,10%用随机的token替换。但不用的是,span masking是span级别的,即同一个span里的所有tokens会是同一种mask。
Span Boundary Objective
这个新增的预训练任务概括起来其实就是:仅使用span边界的tokens的表征,来预测该span内的这些mask的tokens原来对应哪些tokens,这其实与mask lm类似,但它不使用上下文的所有tokens的表征。
首先,输入文本序列的每个tokens的Transformer输出为 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn。
给定一个mask的span,其tokens的Transformer输出为 ( x s , . . . , x e ) (x_s,...,x_e) (xs,...,xe),其中s和e为span的起点和终点位置。当然,这些span是按照上面的span masking采样得到。
那么,该span的外边界tokens的Transformer输出即分别为 s s − 1 s_{s-1} ss−1和 s e + 1 s_{e+1} se+1,并且待预测的target token的位置embedding为 p i − s + 1 p_{i-s+1} pi−s+1
(位置embeddings: p 1 , p 2 , . . . p_1,p_2,... p1,p2,...,代表token在span中相对于左边界token x s − 1 x_{s-1} xs−1的位置,如上述图片所示)
最后,通过外边界tokens的表征和相对位置embedding,得到该token的向量表征 y i y_i yi,用它去预测token x i x_i xi,与BERT中的MLM任务一样。
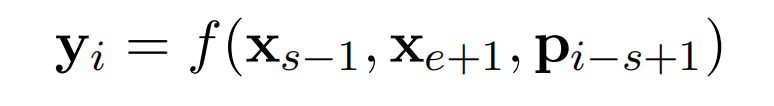
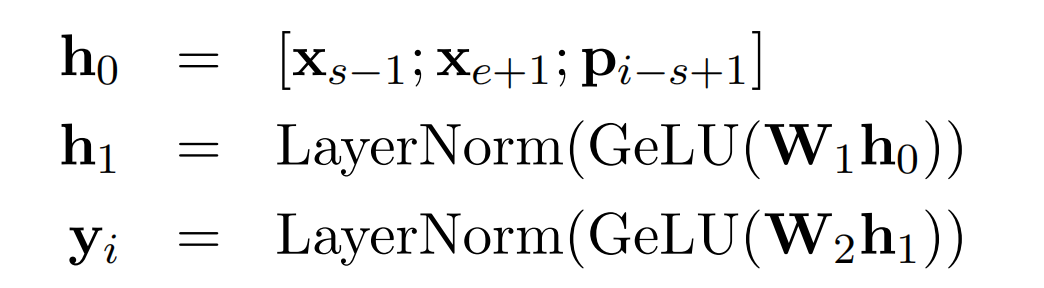
ALBERT
论文地址:https://arxiv.org/abs/1909.11942
github地址:https://github.com/google-research/albert
ALBERT(A Lite BERT)同样出自google:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations,看这个模型的全称,就知道它设计的初衷就是给BERT瘦身。
ALBERT所做的调整主要包括以下几点:
- 大大减少BERT模型的参数量;
- 预训练中的Next Sentence Prediction(NSP)任务使用了Sentence Order Prediction(SOP)进行代替;
- 增加了n-gram mask,使用了LAMB优化器来代替AdamW,该优化器在batch size较大时效果更佳。
参数量优化
增加预训练语言模型的参数规模,往往给下流任务能够带来效果提升。但GPU/TPU这些设备内存资源的限制,注定了参数规模无法无止境的增加。
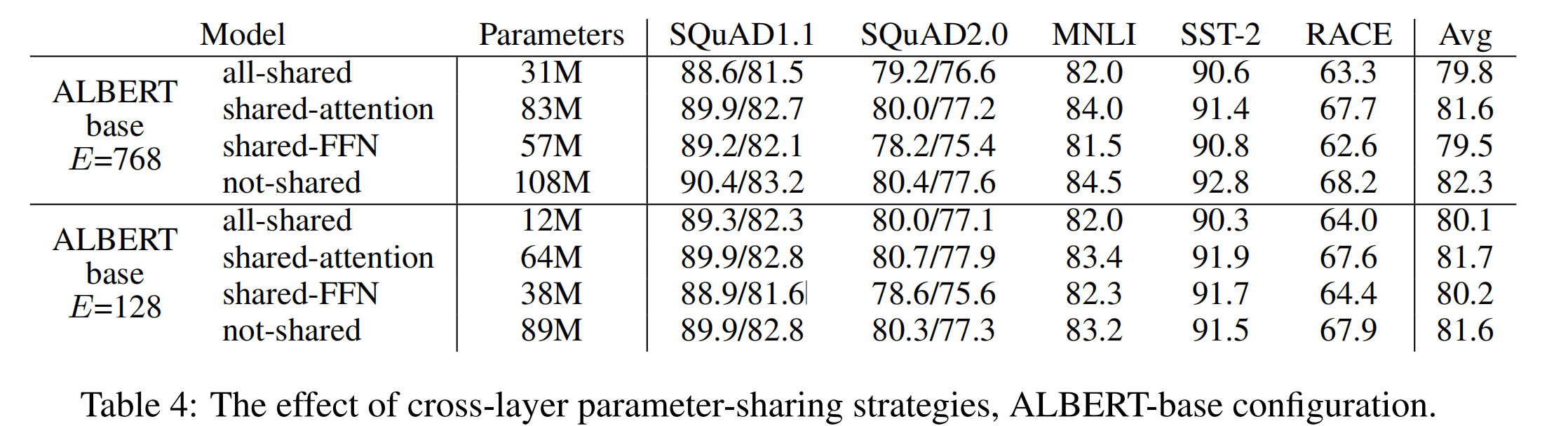
ALBERT主要通过两个方式来显著减少模型的参数量:Factorized embedding parameterization和Cross-layer parameter sharing,大大降低了训练成本,也包括训练速度。
1. Factorized embedding parameterization
BERT和RoBERTa模型中,WordPiece拆分的词表映射的词向量维度E是与Transformer中的隐藏层大小H是绑定的,即E=H。
- 从建模角度来看,词向量是为了学习一种与上下文无关(context-independent)的表征,而隐藏层中的embeddings则相反,是为了学习一种上下文相关(context-dependent)的表征。而从一些实验表明,BERT这类模型的表征能力更多是来自这些上下文相关的表征学习。那么,解绑词向量的维度与隐藏层大小,可以根据模型的需要更加有效得利用模型的所有参数,这意味着H可以远大于E,即H>>E;
- 从实践角度来看,NLP往往需要很大的词表容量V,如果E=H的话,那么想增加隐藏层大小H的话,词向量矩阵也随着变大即 V × E V \times E V×E,这会导致模型参数的激增,并且这些参数在训练过程中仅仅是稀疏地更新,即每一步训练仅会更新极少数的词向量参数。
因此,ALBERT使用一种因子分解的方法,将词的one-hot向量先投影到一个较小的向量空间大小E,然后再重新投影到隐藏对应的空间大小H,而不是直接将one-hot向量直接投影到H,这样,词向量矩阵参数规模则从 O ( V × H ) O(V \times H) O(V×H)变为 O ( V × E + E × H ) O(V \times E + E \times H) O(V×E+E×H),并且H>>E。
2. Cross-layer parameter sharing
ALBERT提供了几种网络层参数共享的选项,包括:
- 只共享所有前馈网络层 feed-forward network (FFN)的参数;
- 只共享所有attention层的参数;
- 共享所有attention网络层和前馈网络层的参数,这也是ALBERT的默认选项。
下图分别为ALBERT的参数优化效果和不同参数共享选项的效果对比:

Sentence Order Prediction(SOP)
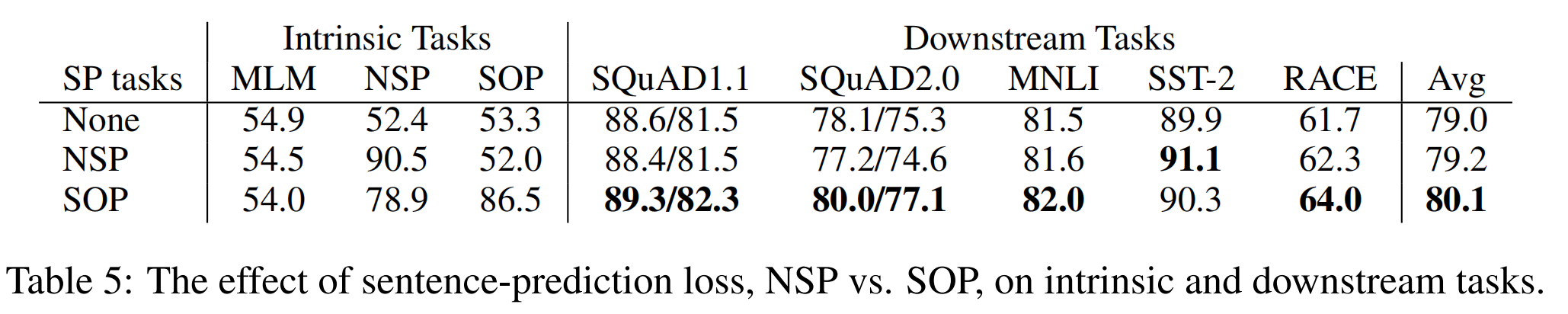
上述BERT也提到过,next-sentence prediction (NSP)任务是为了提升预训练模型在下流任务的表现,比如那些需要理解句子对之间的关系的自然语言任务推理。然而,RoBERTa研究表明NSP的效果是不可靠的,消除这个预训练任务反而能够提升一些下流任务的效果。
论文猜测是NSP任务失效的原因是相比于MLM,NSP缺乏一定的困难性,即该任务相对来说过于简单。
从NSP的设计来看:负样本是从不同的文档中提取的语料,意味着负样本在主题和连贯性上(topic and coherence)都是偏离的。NSP是将主题预测和连贯性预测两个任务进行合并了,但是主题预测相比连贯性预测简单许多,而主题预测与MLM是存在更多的重叠了。
在此理论基础上,ALBERT仍然认为句子间的建模能力是语言理解中一个重要部分,但是要避开主题预测,并且更关注于句子间连贯性的建模能力,提出了另外一种任务:sentence-order prediction (SOP) :
- 正样本仍然是与BERT一样,从相同的文档中提取两个连续的片段;
- 负样本则与BERT不同,首先依旧是相同的文档中提取两个连续的片段,但是调换这个片段的顺序。
N-gram
增加了n-gram mask,比如tokens序列为a b c d,按照原mask方法,仅存在这些mask选项:[a, b, c, d],但3-gram则不同:[a, b, c, d, a b, b c, c d, a b c, b c d],具体可以前往源码
其他调整
在预训练过程中,ALBERT还另外进行了一些调整:
- 输入序列会以10%的概率让它低于最大长度512;
- 使用LAMB优化器(针对大batch size的优化器),batch size为4096,学习率为0.00176
中文RoBERTa-wwm
论文地址:https://arxiv.org/abs/1906.08101
github地址:https://github.com/ymcui/Chinese-BERT-wwm
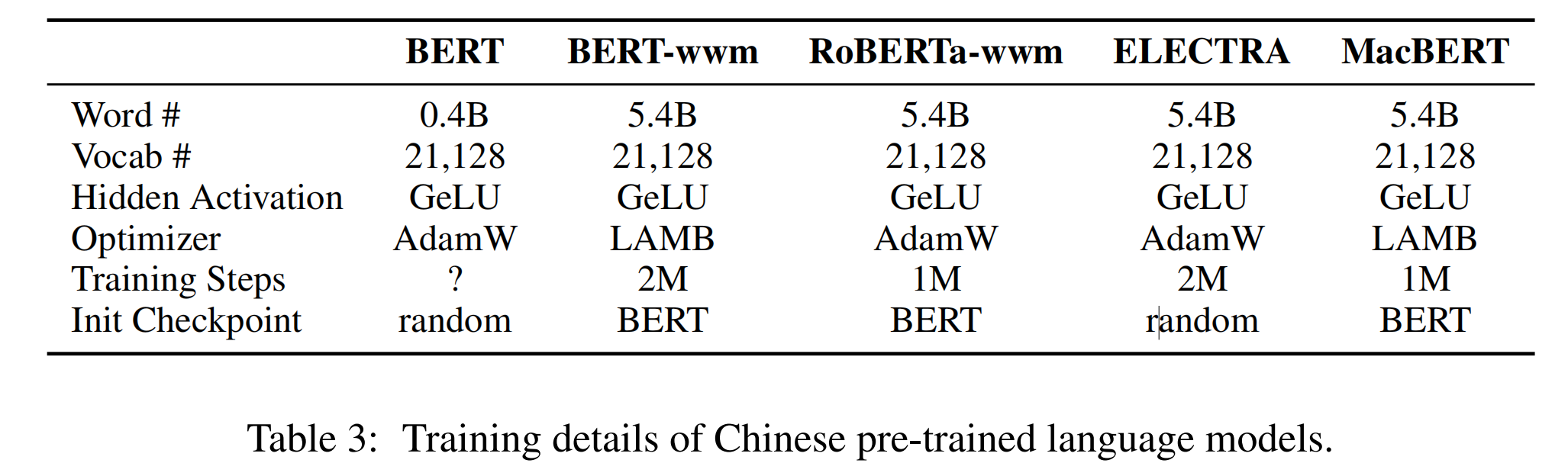
该模型是哈工大讯飞联合实验室针对NLP中文特性进行优化的一个BERT系列模型。
其最主要的优化在于:由于谷歌官方发布的BERT中,中文是以字为粒度进行切分,没有考虑到传统NLP中的中文分词。 我们将全词Mask的方法应用在了中文中,使用了中文维基百科(包括简体和繁体)进行训练,并且使用了哈工大LTP作为分词工具,即对组成同一个词的汉字全部进行Mask。

另外,预训练取消Next Sentence Prediction(NSP)loss。
MacBERT
论文地址:https://aclanthology.org/2020.findings-emnlp.58/
github地址:https://github.com/ymcui/MacBERT
该模型也是出自哈工大讯飞联合实验室,仍然是一个中文BERT模型,该模型引入了一种纠错型掩码语言模型(Mac)预训练任务,缓解了“预训练-下游任务”不一致的问题。
掩码语言模型(MLM)中,引入了[MASK]标记进行掩码,但[MASK]标记并不会出现在下游任务中。在MacBERT中,使用相似词来取代[MASK]标记。相似词通过Synonyms toolkit (Wang and Hu, 2017)工具获取,算法基于word2vec相似度计算。同时也引入了Whole Word Masking(wwm)和N-gram masking技术。
还有一些细节问题:
- 当要对N-gram进行掩码时,会对N-gram里的每个词分别查找相似词。
- 当没有相似词可替换时,则会使用随机词进行替换。

另外,预训练中除了使用MLM loss,还保留了SOP loss。
百度ERNIE
github地址:https://github.com/PaddlePaddle/ERNIE
##ERNIE 1.0
论文地址:https://arxiv.org/abs/1904.09223
**百度文心1.0认为BERT模型没有考虑到句子里的先验知识。**比如这个句子:哈尔滨是黑龙江的省会,国际冰雪文化名城。
- 模型很容易通过「哈」与「滨」预测到「尔」这个单词,仅仅需要通过局部共现关系,完全不需要上下文的帮助;
- 而无法直接通过黑龙江与哈尔滨的关系来预测「哈尔滨」。
因此,如果模型能够学到这些先验知识,那模型应该可以获得更可靠的语言表征。
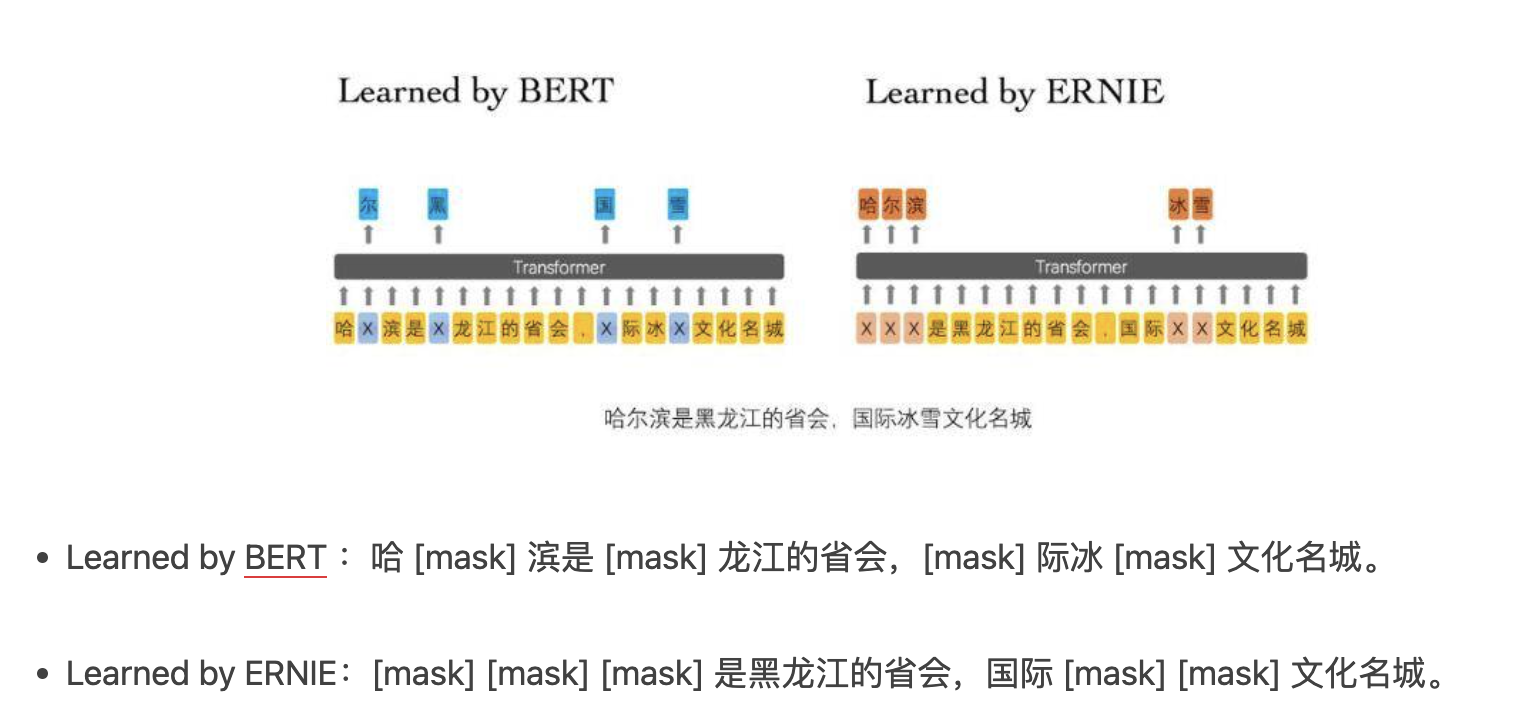
基于这个思想,ERNIE 1.0提出了两种新的掩码(Mask)机制:Entity-Level Masking、Phrase-Level Masking。
再加上Basic-Level Masking,进行多阶段的预训练。
1. Basic-Level Masking
第一阶段,使用与BERT一样的基础Mask机制,同样是15%的Mask概率。这个阶段,模型难以获得高级别的语义知识的建模能力。
2. Phrase-Level Masking
第二阶段,使用短语级别的Mask机制。对于英文文本,使用lexical analysis工具获取短语的边界,对于中文或者其他语言的文本,使用对应语言的分词/分段工具,来得到单词/短语。
这个阶段会随机Mask掉一些短语,并进行预测。这个阶段短语的信息会被编码到词向量中。
3. Entity-Level Masking
第三阶段,使用实体级别的Mask机制。命名实体包括人名、地点、组织、产品等等,通常情况下,实体会包括句子的重要信息。
在这个阶段,首先会解析出句子中的所有实体(应该是通过命名实体识别模型,论文未明确说明),然后Mask掉某些实体,并进行预测。
通过这三个阶段的预训练学习,模型可以通过更丰富的语义信息,得到增强的词表征。

多样的预训练语料
预训练数据集使用了中文维基百科、百度百科、百度新闻和百度贴吧,数量分别为21M、51M、47M、54M。
并且,在中文使用了繁体字到简体字的转换,英文上的大写到小写的转换,最终的词表大小为17964。
DLM (Dialogue Language Model)
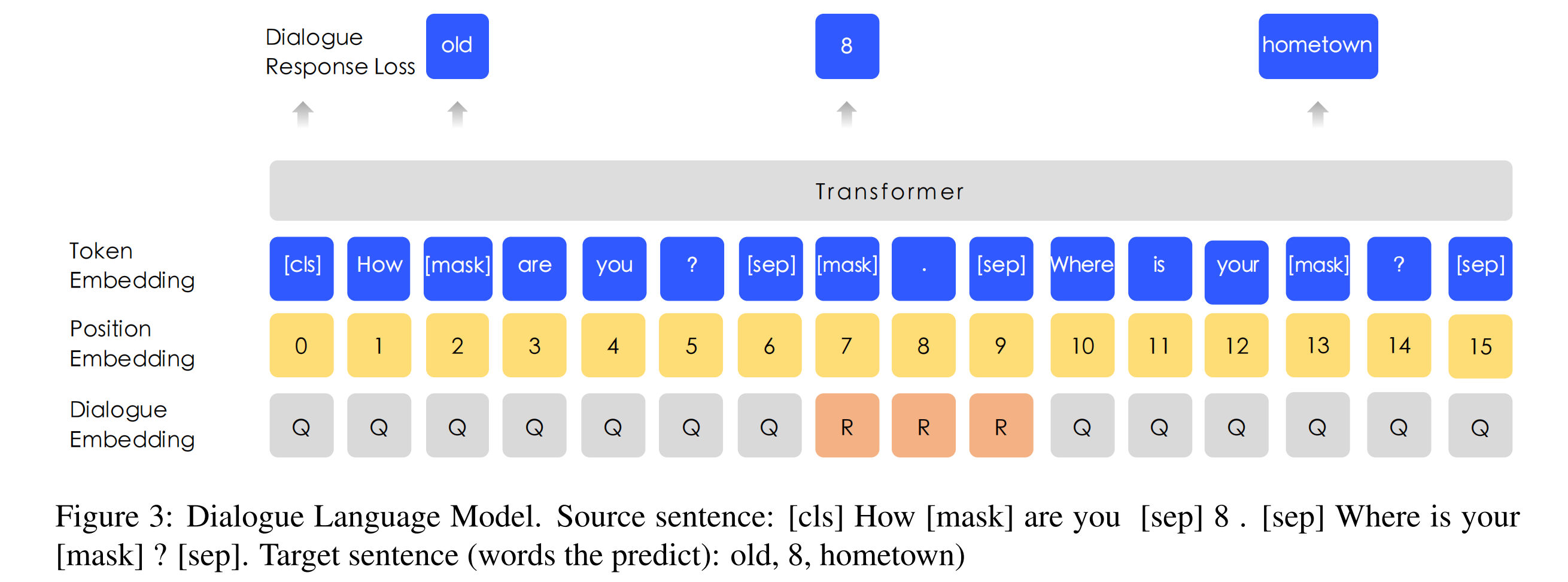
其中,百度贴吧属于对话类型的数据,对话数据对语义表征是很重要的,因为一个问题下的回答通常下是相似的。
论文针对这类型的数据,ERNIE在Query-Response的对话结构下,使用一种新的DLM (Dialogue Language Model) 任务,如下图DLM-Figure 3所示。
- 加入了新的对话嵌入dialogue embedding,来区分对话中的角色,作用类似于type embedding;
- 输入文本格式有几种形式:QRQ、QRR、QQR,Q代表问题,R代表回答;
- 负样本会随机替换掉句子的问题或者回答,模型需要预测它是正样本还是负样本,类似于NSP和SOP。
DLM任务可以让ERNIE学习对话之间的内在关系,这也可以提升模型语义表征的学习能力。
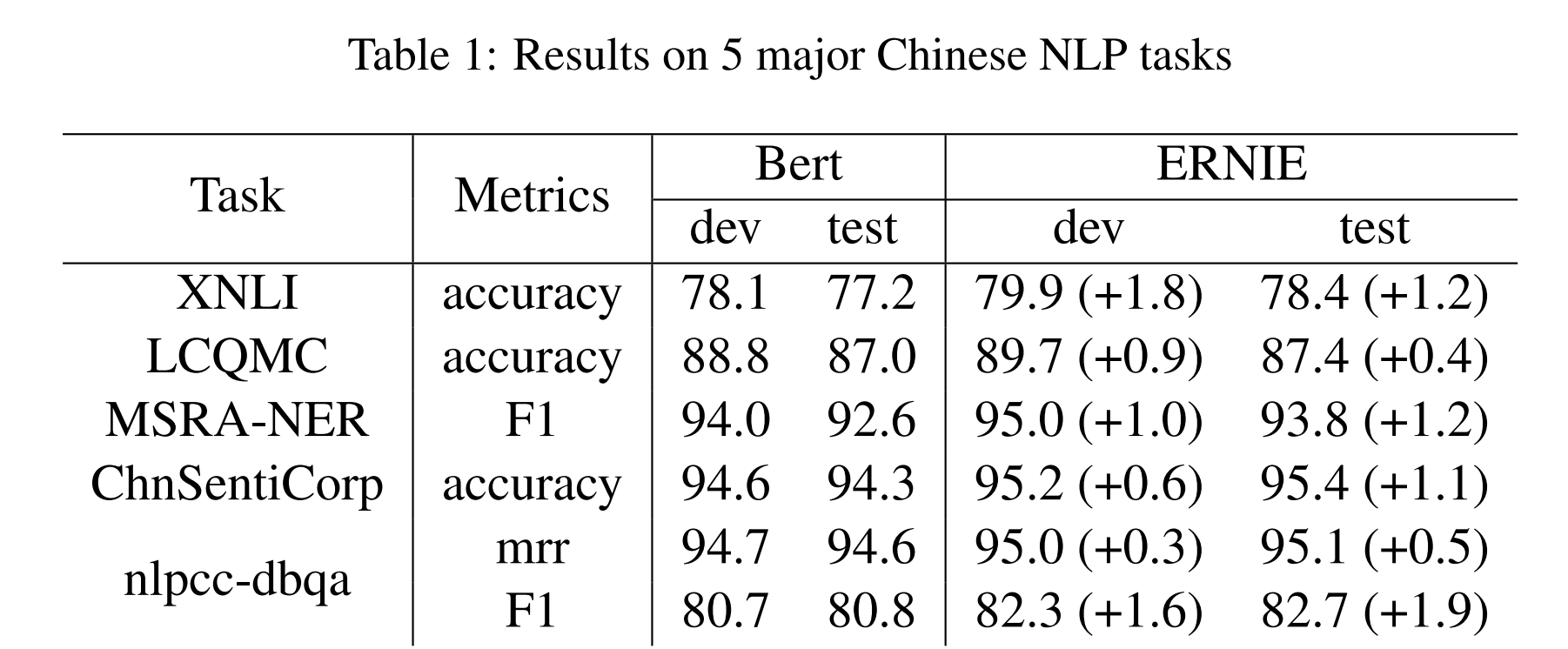
实验结果
在以下5个中文NLP数据集都取得了比BERT更好的成绩:
Cross-lingual Natural Language Inference (XNLI):判断句子对属于哪种标签,包含矛盾、中立和蕴涵。
Large-scale Chinese Question Matching Corpus (LCQMC):判断两个句子是否为相同的意图(intention)
MSRA-NER:亚洲微软研究发布的命名实体识别数据集
ChnSentiCorp(TAN Song-bo. Chnsenticorp.):判断句子的观点是积极还是消极
NLPCC-DBQA:选出问题的正确答案
ERNIE 2.0
论文地址:https://arxiv.org/abs/1907.12412v2
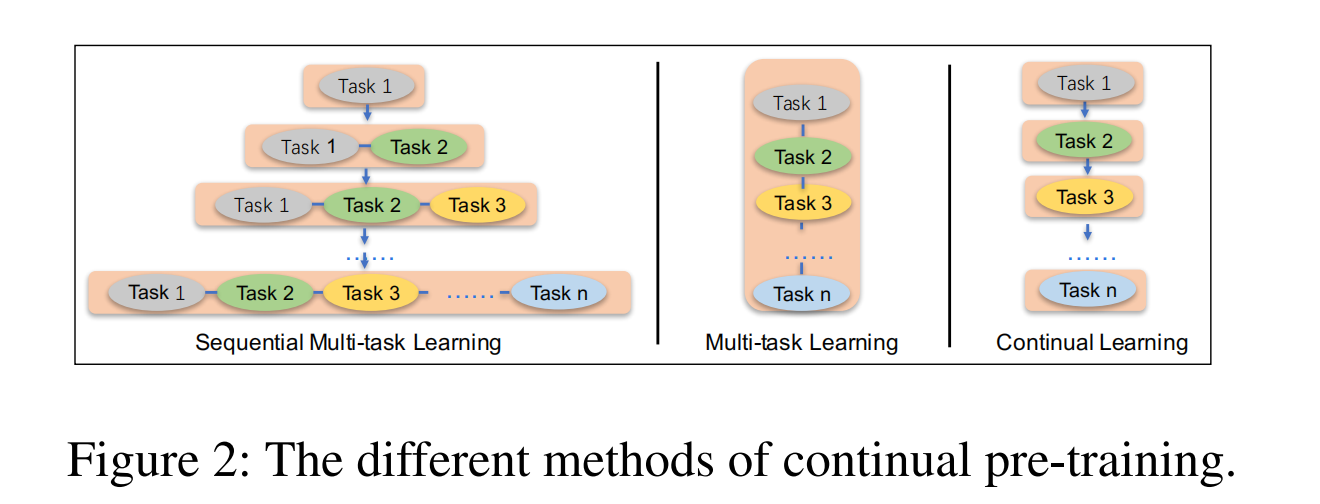
百度文心2.0提出了一种持续学习的预训练框架:预训练使用了7种任务,而不是一两种简单的任务。不断引入新的预训练任务,让模型可以持续性地学习不同的预训练任务,并且不会遗忘先前学习的知识,以此让模型能够获得更为全面的表征能力。大体结构如下图:
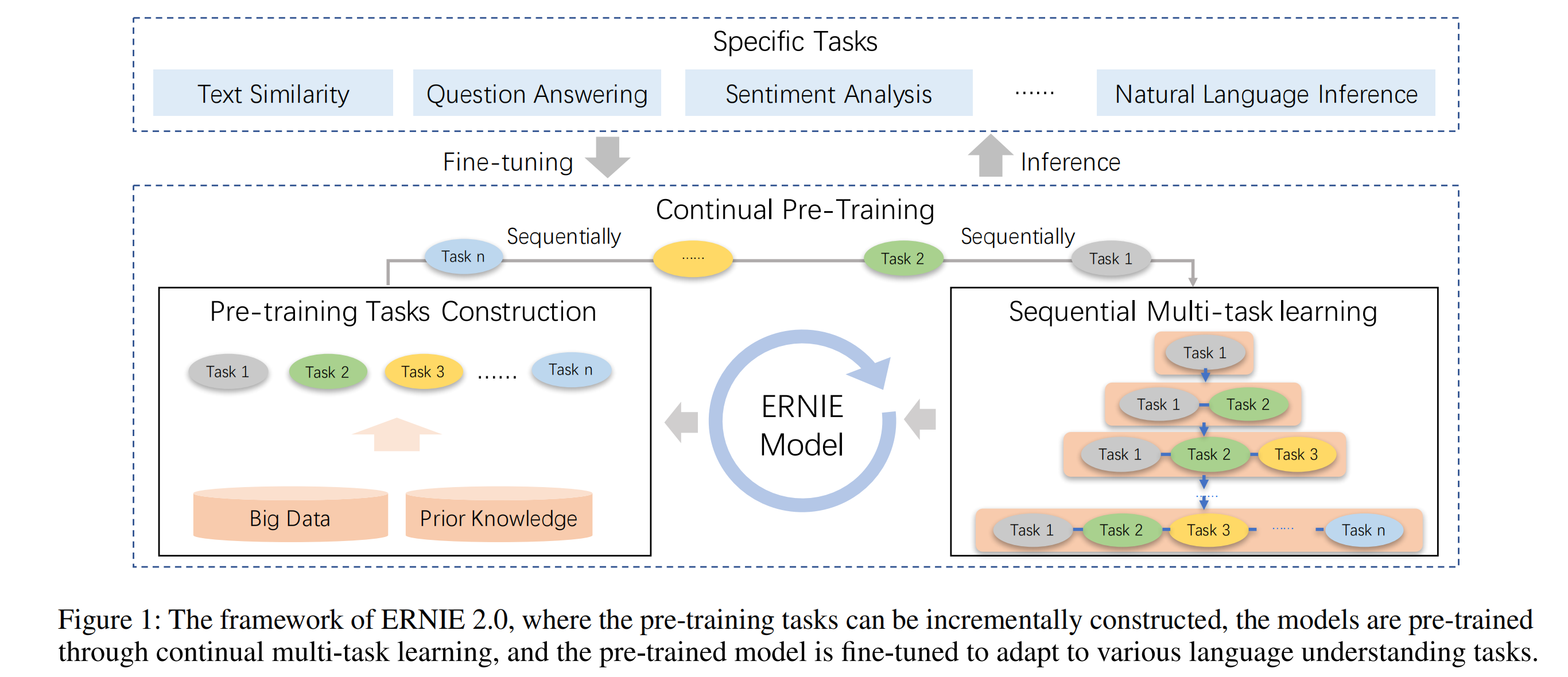
1. 持续多任务预训练学习
ERNIE 2.0提出的持续多任务预训练学习框架,目的在于让模型从一系列的任务中学习词汇、句法和语法信息。
主要存在以下两个挑战:
- 如何持续性地预训练多个任务,并且让模型不会遗忘前面已经学到的知识;
- 如何高效地预训练这多个任务。
论文使用以下方法“对症下药”:
- 序列多任务学习方法。当一个阶段加入新的任务时,会使用上一阶段训练好的模型参数进行初始化,并且训练新的任务时,会一起与上个阶段的任务进行同步训练。保证模型学习好的参数能够编码前面学到的知识;
- 给每个任务分配N个训练迭代,即每个任务会按照顺序,一个接着一个,依次训练N步。
下图比较清晰地展示了该框架与多任务学习、持续性学习的区别。
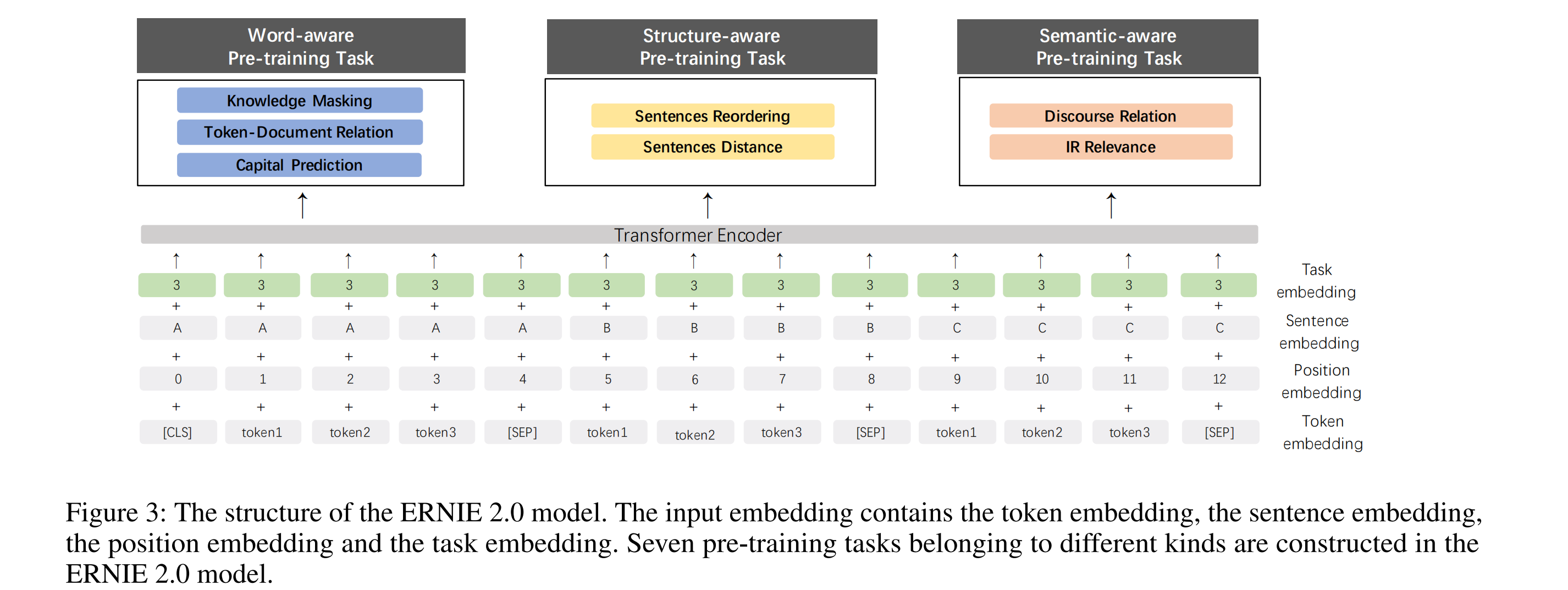
2. 三大类-7个预训练任务
Word-aware Pre-training Tasks
这类可以让模型能够捕获词汇信息,具体包括2个任务:
- Knowledge Masking Task:与ERNIE 1.0中的Mask机制相同,这个任务可以帮助模型学习局部和全局上下文的依赖信息,ERNIE 2.0使用这个任务来预训练,得到初始版本的模型;
- Capitalization Prediction Task:预测单词是否为大小写。大写的单词相比其他单词,往往有着特别的语义信息。区分大小写的模型对命名实体识别这类任务比较有优势;
- Token-Document Relation Prediction Task:预测单词是否也出现在另外的文本片段。根据经验来看,在文档中许多片段都出现的单词往往与主题相关。因此,这个任务可以提升模型捕获关键单词的能力。
Structure-aware Pre-training Tasks
- Sentence Reordering Task:一个段落被拆分为m个片段并打乱顺序,模型需要预测这m个片段的原始顺序,其实就是一个k分类任务, k = ∑ n = 1 m n ! k=\sum_{n=1}^m n! k=∑n=1mn!。这个任务可以让模型学习一个文档中句子之间的关系。
- Sentence Distance Task:三分类任务,“0”代表两个句子属于同个文档并且是相邻的,“1”代表两个句子属于同个文档但不是相邻的,“2”则代表两个句子来自不同文档。这个任务可以让模型通过文档级别的信息,学习句子之间的距离。
Semantic-aware Pre-training Tasks
- Discourse Relation Task :预测两个句子的语义或者修饰(rhetorical)关系,数据集出自这篇论文:Mining discourse markers for unsupervised sentence representation learning。
- IR Relevance Task:三分类任务,查询文本为第一个句子,标题为第二个句子,模型需要预测这两个句子的关系,“0”代表强关联,用户输入可该查询文本并且点击了这个标题,“1”代表弱关联,用户输入了该查询,并且这个标题出现在了搜索结果中,但用户并未点击,“2”则代表查询文本和标题在语义信息上是随机的,完全不相关的。这个任务可以让模型学习信息检索中的短文本之间的关联。
3. Task Embedding
模型加入了一个新的嵌入 Task Embedding,用来表征不同任务的特征,即每一个预训练任务对应着一个id,从0到N。
微调阶段,可以使用任意一个任务的id来加载模型。
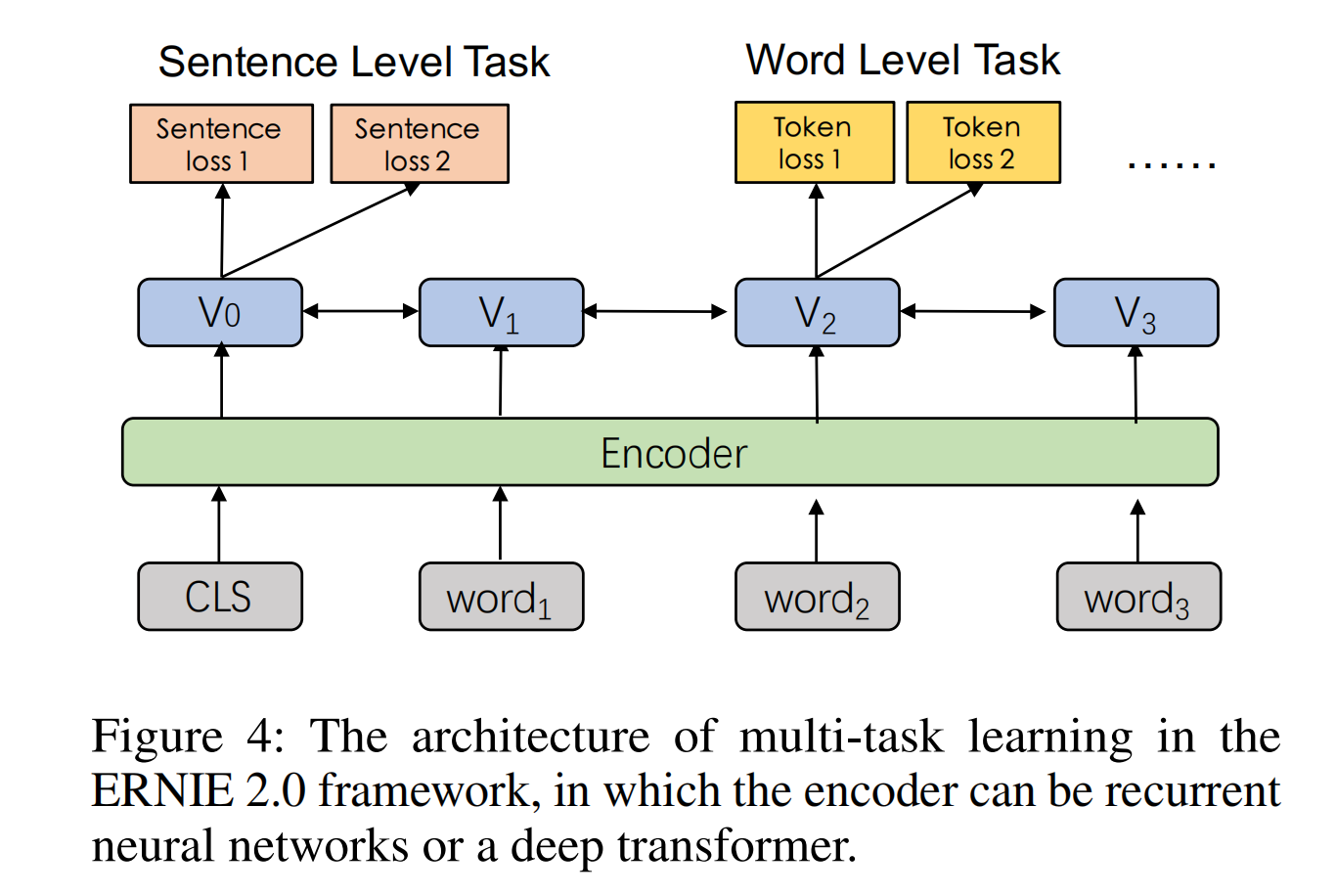
4. 训练结构
如下图[ERNIE 2.0-Figure 4]所示,Encoder可以使用循环神经网络或者Transformer,ERNIE当然是用了Transformer。Encoder参数对于所有任务都是共享的,每个任务都可以更新参数。
其中存在两种损失函数,一种是句子级别的loss,一种的token级别的loss(与BERT类似)。每个预训练任务拥有自己的损失函数。
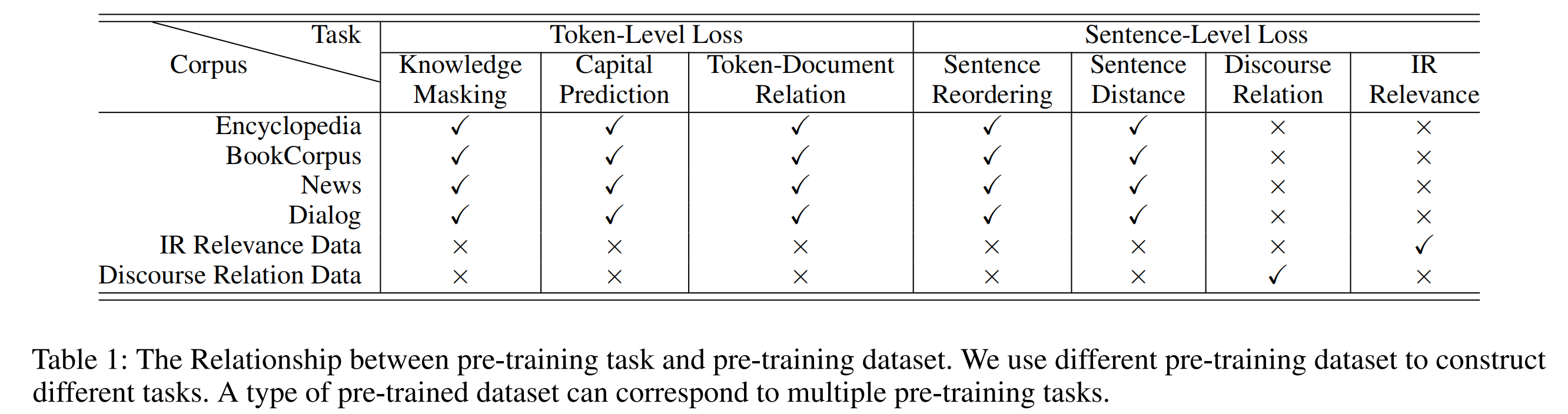
预训练过程,一个句子级别的loss可以与多个token级别的loss联合。下图展示了上述介绍的预训练任务属于哪种loss,同时展示了使用的数据集,以及数据集对应哪些预训练任务和loss。
ERNIE 3.0
论文地址:https://arxiv.org/abs/2107.02137
NEZHA
论文地址:https://arxiv.org/abs/1909.00204
github地址:https://github.com/huawei-noah/Pretrained-Language-Model
NEZHA全称为NEURAL CONTEXTUALIZED REPRESENTATION FOR CHINESE LANGUAGE UNDERSTANDING,是华为诺亚方舟实验室提出的一个模型。
##相对位置编码
NEZHA使用了类似Transformer-XL中的相对位置编码函数来代替BERT中的位置嵌入position embeddings。
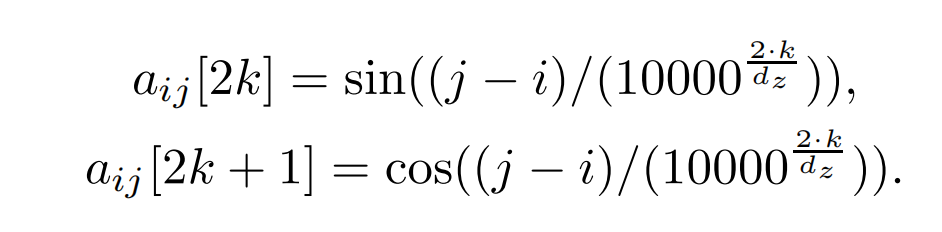
其中, a i j ∈ R d z , d z a_{ij} \in \mathbb{R} ^{d_z},d_z aij∈Rdz,dz为每个注意力头的size。
如何将相对位置编码加入注意力,如下式:
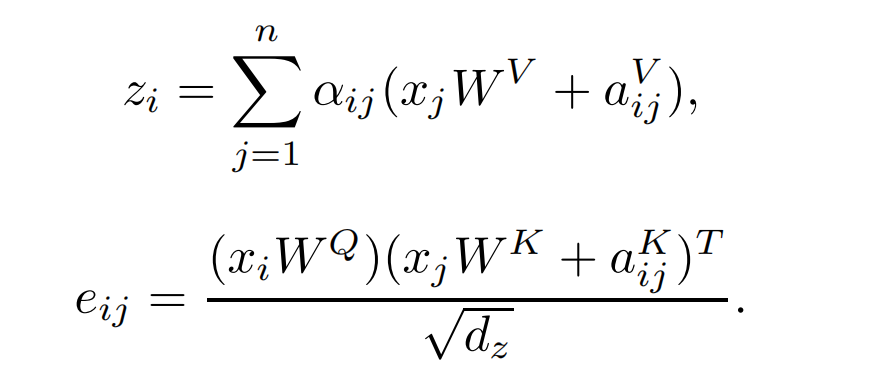
其中,输入tokens序列为 x = ( x 1 , x 2 , . . . , x n ) , w h e r e x i ∈ R d x x=(x_1,x_2,...,x_n),\ where\ x_i \in \mathbb{R} ^{d_x} x=(x1,x2,...,xn), where xi∈Rdx,
a i j V , a i j K a_{ij}^V,a_{ij}^K aijV,aijK即有上面的相对位置编码函数而来, z i z_i zi为第i个注意力头的输出。
中文全词掩码
NEZHA也使用了中文的WWM(whole word masking),也就是上述的中文RoBERTa-wwm的Mask机制,分词工具使用的是Jieba。
混合精度训练
通常,深度神经网络训练时,模型参数和梯度使用的是FP32精度(单精度)。
而NEZHA使用了混合精度训练:
- 首先,模型会保留一份单精度的权重Master Weights;
- 每一步训练时,会将模型权重Master Weights转化为FP16精度(半精度),然后使用半精度来进行前向和反向传播,包括权重、激活函数和梯度;
- 最后,将半精度的梯度恢复到单精度,然后再更新Master Weights。
Span Prediction
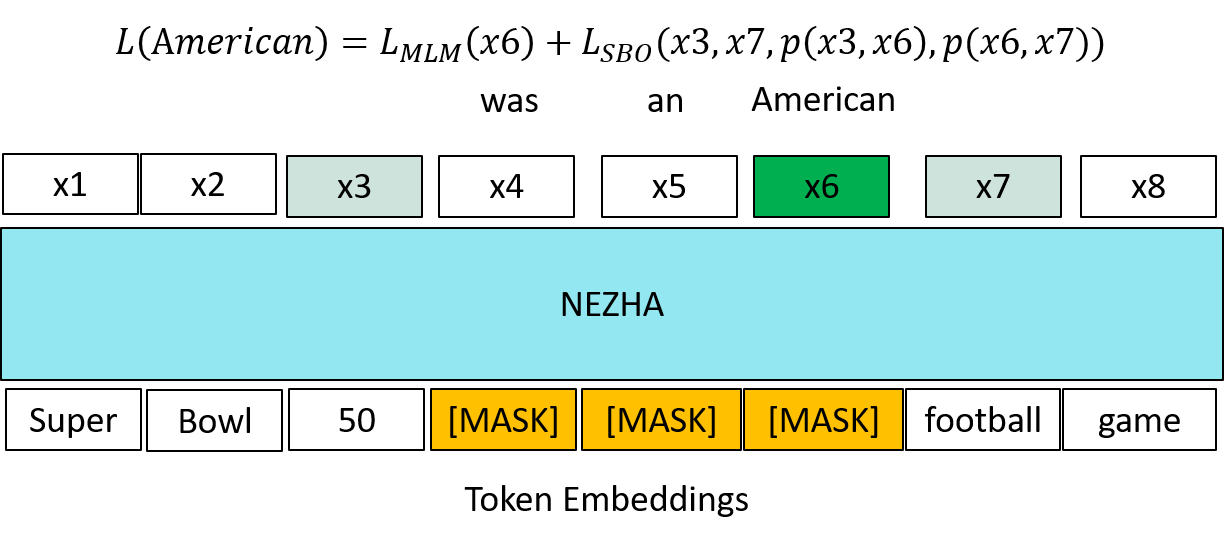
NEZHA还加入了类似于上述SpanBERT模型的预训练:Span Prediction
其他
全局batch size为5120,使用LAMB Optimizer。