YOLOv11目标检测创新改进与实战案例专栏
文章目录: YOLOv11创新改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLOv11目标检测创新改进与实战案例

文章目录
前言
本文的目标
- YOLO11 使用CUDA+GPU加速,以及对应环境的安装
- 通过YOLO11源码的方式训练自己的数据集
- 以EMA(Efficient Multi-Scale Attention)注意力为机制,演示如何进行YOLO11改进
- YOLO11的训练推理验证导出四大步
为什么GPU更适合深度学习?为什么要选择Nvidia GPU?
-
并行处理能力:GPU特别适用于执行大量并行运算,这是因为它包含成百上千个处理单元(流处理器),适合进行大规模的浮点计算,如矩阵乘法,这在深度学习等需要大量并行处理的任务中非常重要。
-
内存带宽:GPU提供的内存带宽远高于CPU。例如,RTX 2060的内存带宽为336GB/s,而高端的RTX 3090甚至可达912GB/s至1006GB/s。相比之下,顶级CPU的内存带宽约为50GB/s。更高的带宽使得GPU能够更快地处理和传输大量数据,尤其是在需要大块连续内存空间的应用场景中,如深度学习。
-
存储和缓存优势:GPU为每个处理单元配置了大量寄存器,这使得它在执行需要频繁访问数据的任务时更加高效。GPU的寄存器总量远超CPU,速度也可达到80TB/s,而CPU的寄存器运行速度为10-20TB/s。
-
CUDA和cuDNN优化:NVIDIA的CUDA技术和cuDNN库优化了GPU在深度学习和其他高性能计算任务中的表现。这些技术提供了高效的编程环境和算法优化,使得GPU在执行这些任务时更加高效。
-
行业领先地位:NVIDIA的GPU已成为深度学习加速的行业标准。与AMD相比,NVIDIA的CUDA和相关优化库的成熟度和支持度更高,这也是为什么NVIDIA GPU在深度学习领域更受欢迎。
cuda是个啥
Nvidia显卡可用,ATI等其它显卡直接跳过划走!!
CUDA(Compute Unified Device Architecture)是由NVIDIA开发的一种并行计算平台和应用编程接口(API),它允许软件开发者和软件工程师使用NVIDIA的GPU(图形处理单元)进行通用计算。简单来说,CUDA使得开发者能够利用GPU强大的计算能力来执行复杂的计算任务,而不仅仅是图形渲染。
- 并行处理能力:GPU内部包含成百上千个并行处理核心,能够处理大量并行操作,这对于处理复杂的数学和工程计算特别有效。
- 可编程性:CUDA提供了类似于C语言的编程模型,开发者可以用熟悉的编程语言编写代码,这些代码可以直接在GPU上运行。
- 灵活性:CUDA支持多种编程语言,包括C、C++和Python等,通过对应的库和API,开发者可以轻松地将CUDA集成到现有项目中。
CUDA在深度学习领域的应用
在深度学习领域,CUDA扮演着至关重要的角色,主要体现在以下几个方面:
- 加速神经网络训练:深度学习模型通常包含大量的参数和复杂的数学运算,尤其是在训练过程中,需要执行大量的矩阵乘法和向量运算。GPU的并行处理能力可以显著加快这些运算的速度,从而缩短模型训练的时间。
- 支持主流深度学习框架:几乎所有主流的深度学习框架,如TensorFlow、PyTorch和Keras等,都支持通过CUDA在GPU上进行计算。这意味着开发者可以无缝地将这些框架用于GPU加速,无需对框架核心进行复杂的修改。
- 实时数据处理:在需要实时数据处理的应用中,如自动驾驶和视频分析等,GPU通过CUDA提供的加速能力可以快速处理输入数据,并提供实时的反馈和决策。
cuDNN是个啥
cuDNN(CUDA Deep Neural Network library)是由NVIDIA提供的一个GPU加速的库,专门用于深度神经网络的计算。cuDNN为深度学习框架提供高度优化的实现,包括卷积操作、池化(pooling)、归一化以及激活函数等常见的DNN(Deep Neural Network)操作。下面是关于cuDNN的一些关键信息:
特性与优势
-
高性能:cuDNN提供了为深度学习优化的底层计算核心,它利用CUDA进行编写,能够显著提高神经网络训练和推理的速度。
-
易于集成:cuDNN设计为与主流深度学习框架如TensorFlow、PyTorch和MXNet等无缝集成。这些框架的用户通常无需直接操作cuDNN,因为框架本身已经内嵌了cuDNN的优化实现。
-
功能丰富:cuDNN支持多种类型的神经网络结构,包括卷积神经网络(CNN)、循环神经网络(RNN)和长短时记忆网络(LSTM)。它提供了这些结构中常用的许多操作的高效实现。
使用场景
- 训练加速:在使用GPU进行神经网络训练时,cuDNN可以通过优化的算法减少计算时间,提高训练过程的效率。
- 推理优化:在模型部署和推理阶段,cuDNN同样提供加速,使得模型在生产环境中响应更快。
GPU版本的PyTorch
GPU版本的PyTorch指的是专门为支持NVIDIA GPU进行优化的PyTorch版本。这个版本利用了NVIDIA的CUDA技术,允许PyTorch在GPU上运行大规模并行计算,从而大幅提高计算速度,尤其是在训练和运行深度学习模型时。
关键特性:
-
CUDA支持:GPU版本的PyTorch通过CUDA(Compute Unified Device Architecture)库直接与NVIDIA GPU进行交互,使得在GPU上的张量运算和模型训练变得可能。
-
cuDNN集成:为了进一步优化神经网络的各种操作,GPU版本的PyTorch还集成了NVIDIA的cuDNN(CUDA Deep Neural Network)库。cuDNN提供了高度优化的深度学习例程。
-
自动并行计算:PyTorch能够自动利用CUDA技术在GPU上进行数据并行处理,极大地加速了批处理数据和复杂计算的速度。
第一步:确定硬件条件!!!
1.1 确认有显卡
这一步很重要,请确认你的电脑中有显卡,并且是Nvidia显卡。否则请跳转到本文的:
可以通过下面链接更新显卡的驱动: https://www.nvidia.cn/Download/index.aspx?lang=cn
1.2 确认显卡的算力
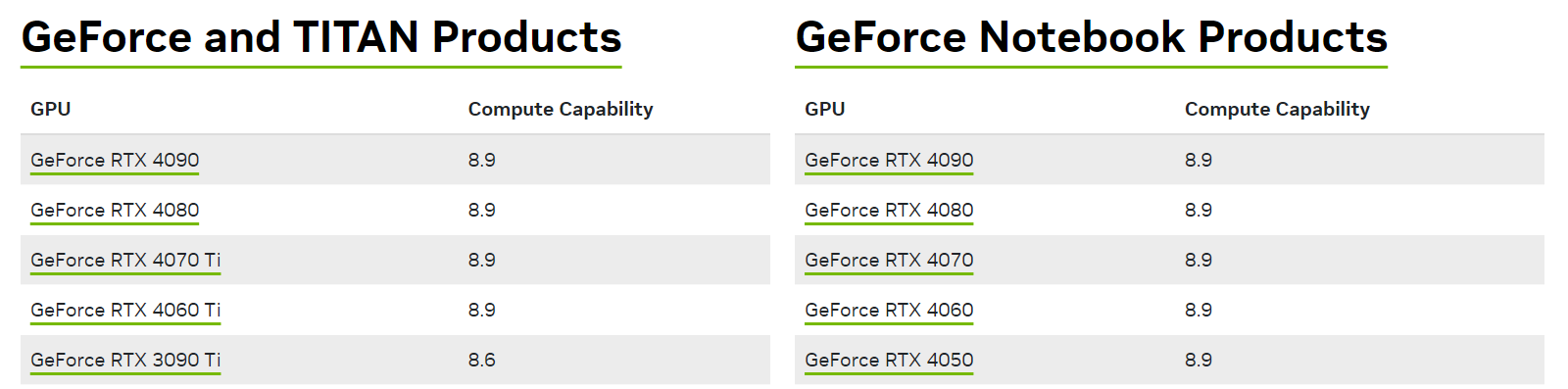
进入以下链接,查询所使用的显卡算力情况,如果算力很低,建议直接跳转到本文:或者使用算力租赁平台。
https://developer.nvidia.com/cuda-gpus
下面是pyTorch支持的算力版本
- PyTorch 1.7 及之前的版本通常支持3.5以上的算力。
- PyTorch 1.8 及之后的版本开始将最低算力提高到3.7。
- PyTorch 1.10 及之后的版本,最低算力要求是5.0。
查看pytorch版本&支持的cuda算力
>>> import torch
>>> print(torch.__version__)
第二步:安装CUDA
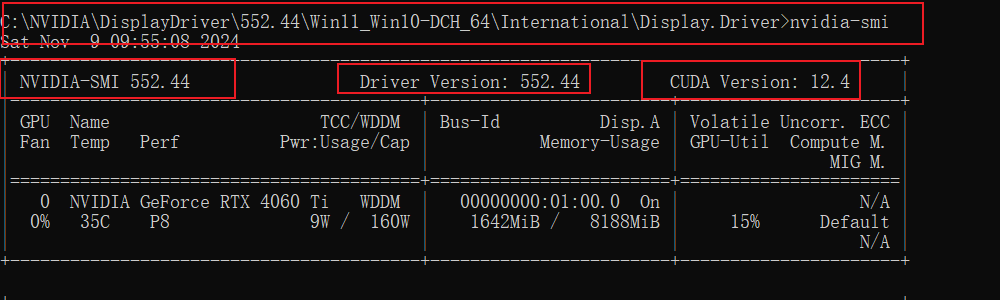
2.1 检查显卡支持的CUDA版本
nvidia-msi
如果提示:**‘nvidia-msi’ 不是内部或外部命令,也不是可运行的程序或批处理文件。**请自行百度。或者直接找到nvidia-msi所在目录执行命令。
2.2 安装CUDA
访问https://developer.nvidia.com/cuda-toolkit-archive,
下载12.4版本(这里笔者是12.4,你要下载你电脑对应的版本)的cuda,如下图所示,我们下载12.4中最新版本的CUDA Toolkit 12.4.0 。
在这里有local和network,两个没什么区别,只是一个先下载到本地可以离线安装,一个直接安装。
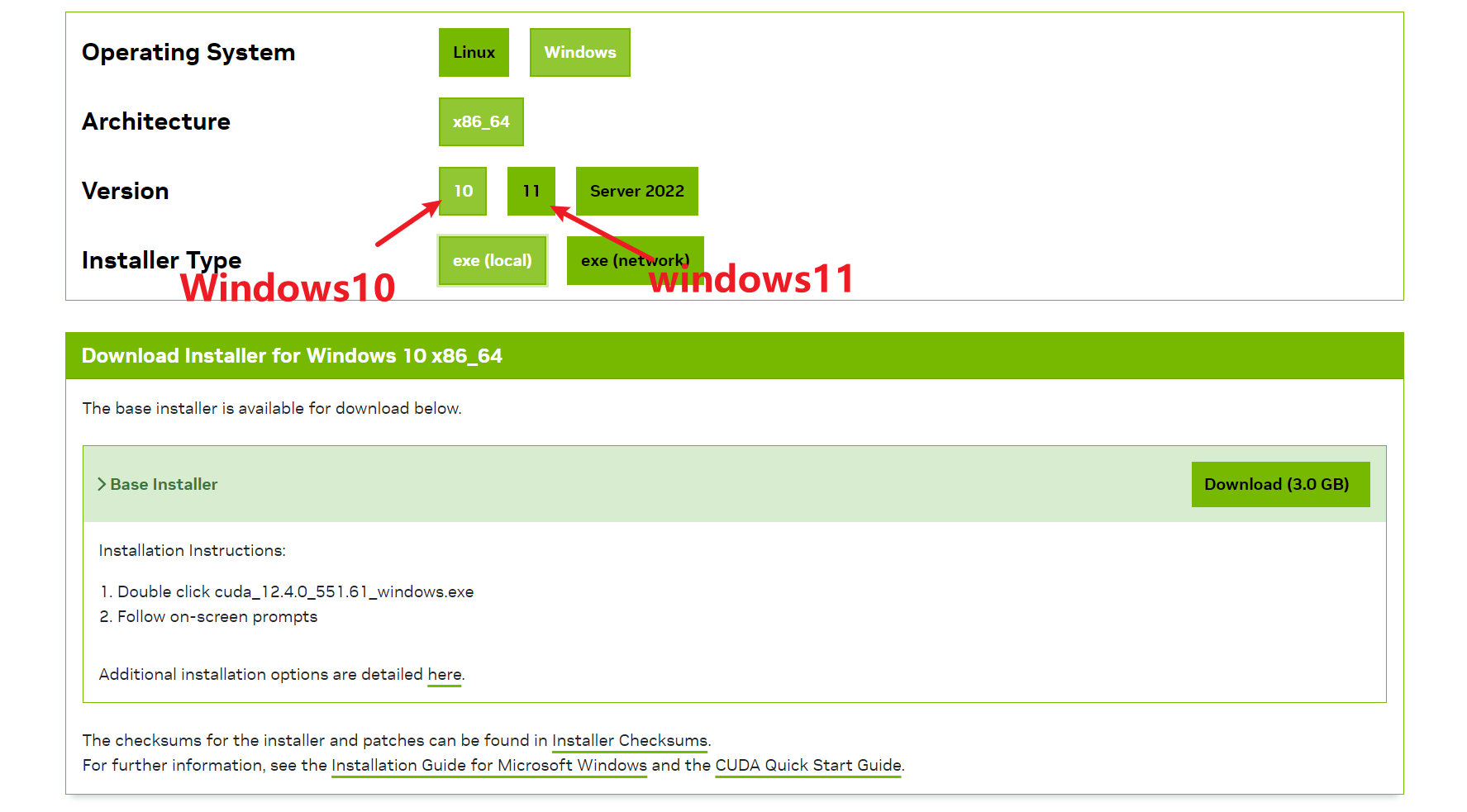
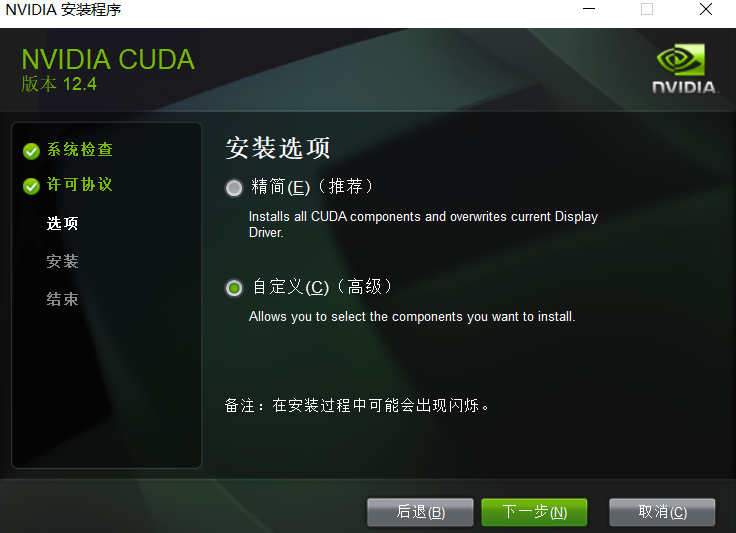
笔者这里下载的是network版本。双击exe,运行安装程序。笔者选择的是自定义然后全选!
2.2 如果安装报错
安装过程出现如下报错!

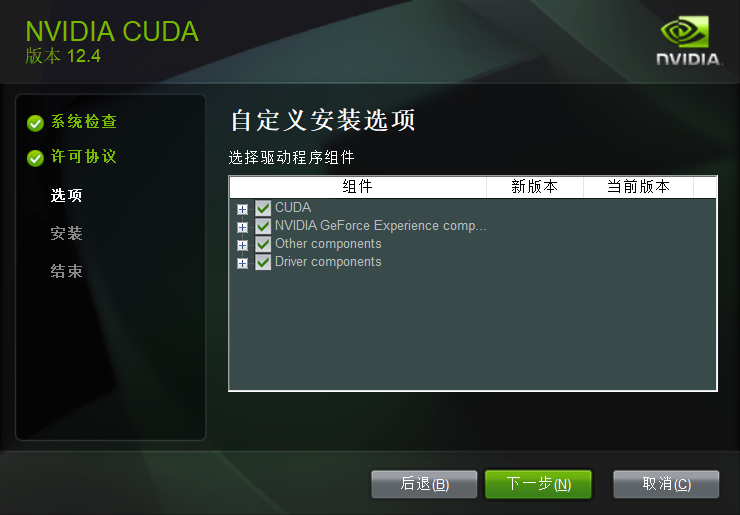
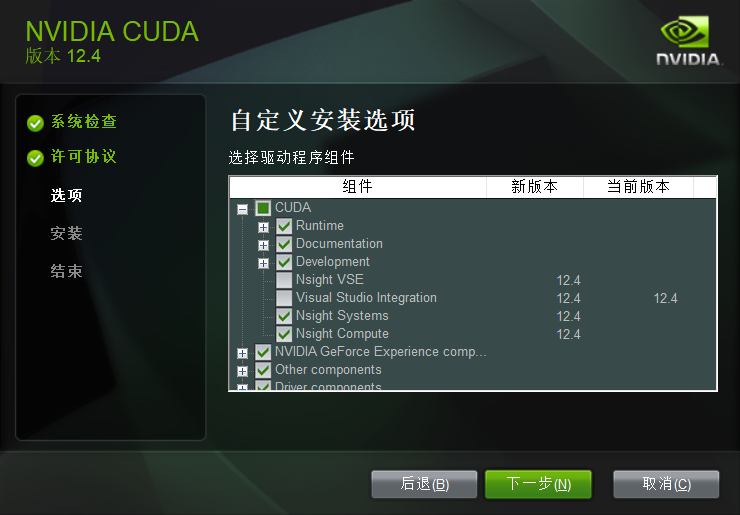
在选择组件的时候,将CUDA中的Nsight VSE和Visual Studio Integration取消勾选,后选择下一步,即可安装成功
如果还是不行,你就看状态那一栏,哪一个安装失败,就把那个取消勾选,这种的缺点就是安装的cuda不全,所以最好事先谷歌下取消勾选有没有影响
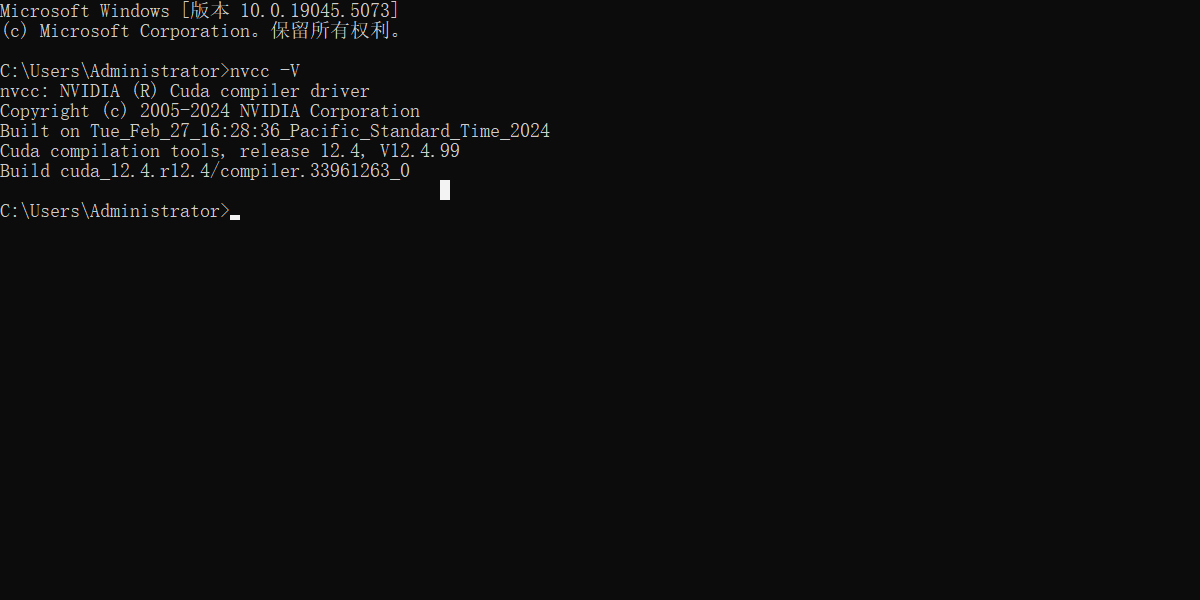
2.3 验证:
nvcc -V
nvcc的环境变量不需要配置,因为在安装之后就默认添加好了,9.0版本之前(包括9.0)还是需要配置环境变量的。
第三步:安装cuDNN
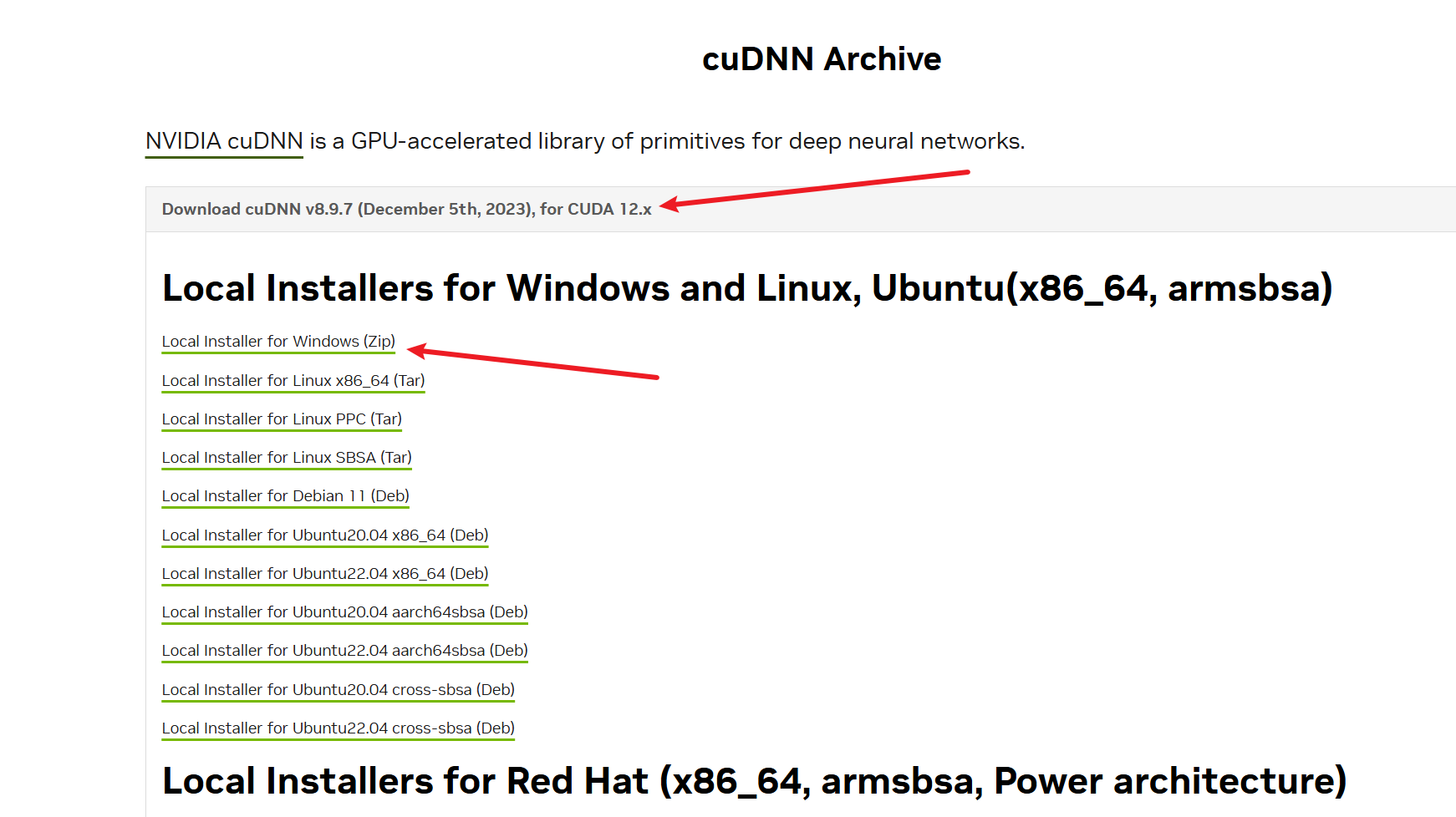
安装完CUDA后,我们为了实现加速,还应安装【对应版本】的cuDNN。访问https://developer.nvidia.com/rdp/cudnn-archive页面,下载对应版本的cuDNN,如下图所示
3.1 拷贝文件
解压后有下面三个文件夹

然后把文件夹里面的内容,拷贝到cuda安装目录下对应的文件夹里面。
- 把bin目录的内容拷贝到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin
- 把include目录的内容拷贝到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include
- 把lib\x64目录的内容拷贝到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib\x64
实在不明白的可以参考官方文档:https://docs.nvidia.com/deeplearning/cudnn/latest/installation/windows.html
3.2 环境配置
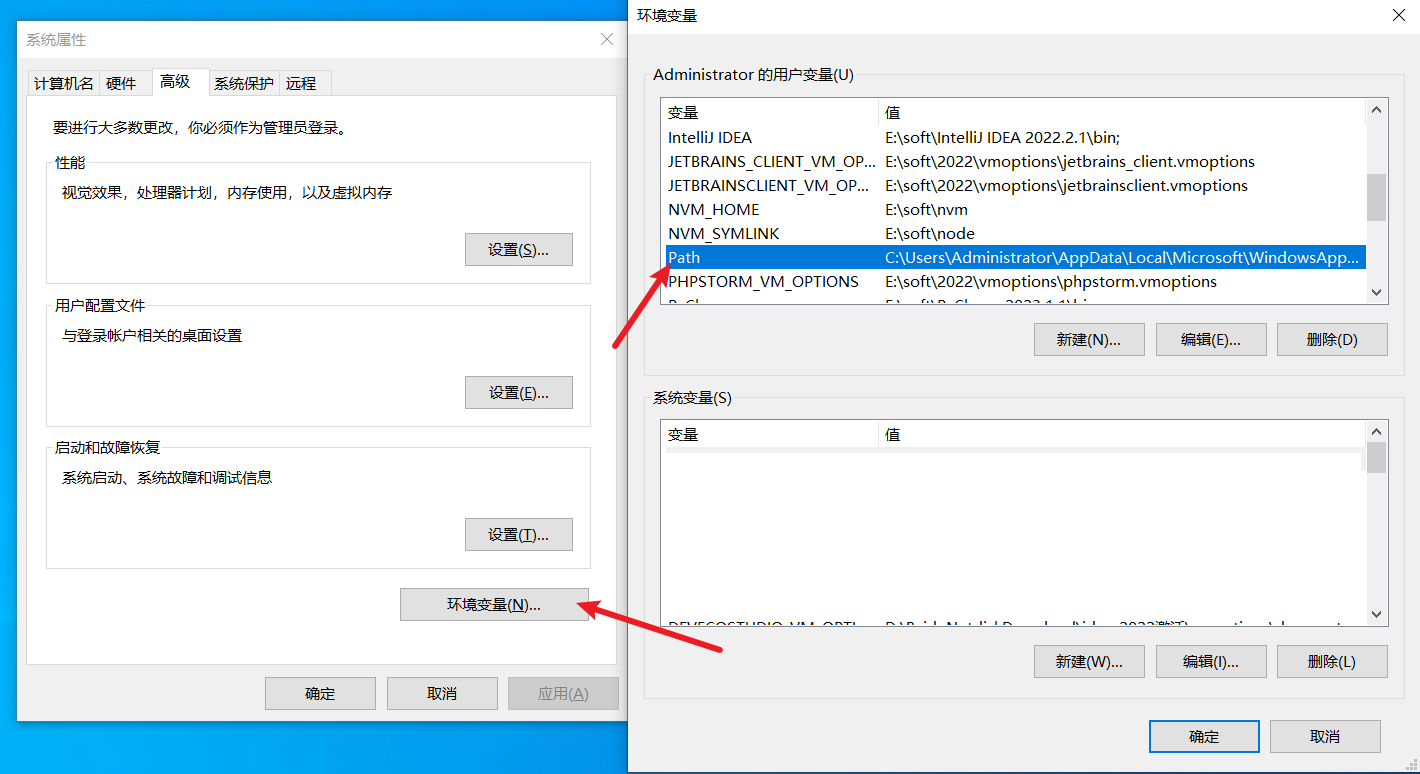
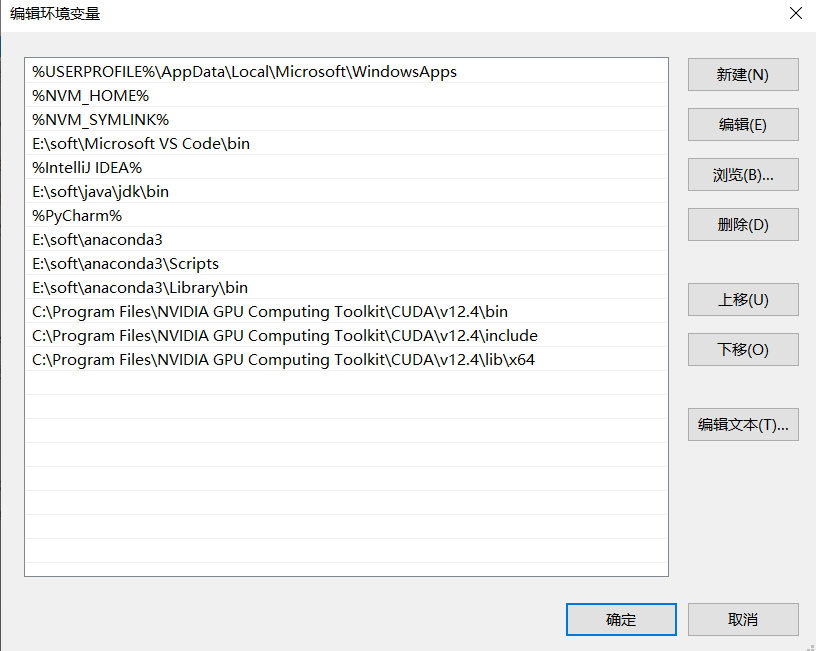
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib\x64
3.2 验证
在C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite执行bandwidthTest.exe和deviceQuery.exe。
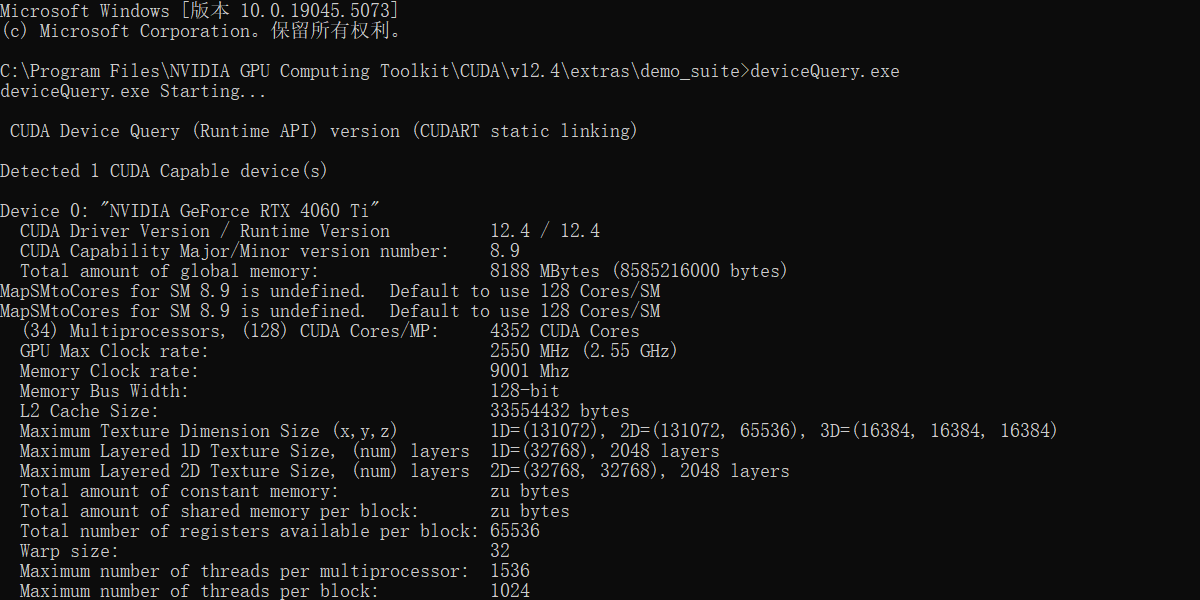
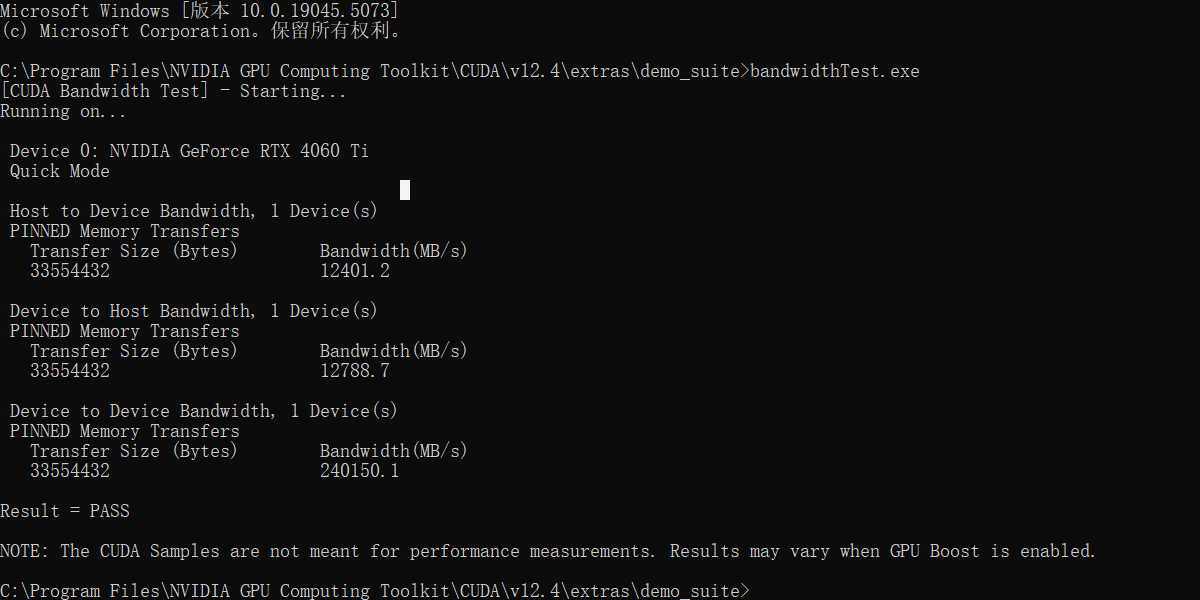
第4步:创建虚拟环境
4.1 安装Anaconda
相信写python的同学应该都有自己的一套管理python环境的办法。笔者这里用的是Anaconda。
可以通过链接下载安装:https://www.anaconda.com/,安装时请选择自动注册环境变量。
这里太具体的笔者不介绍了!!!
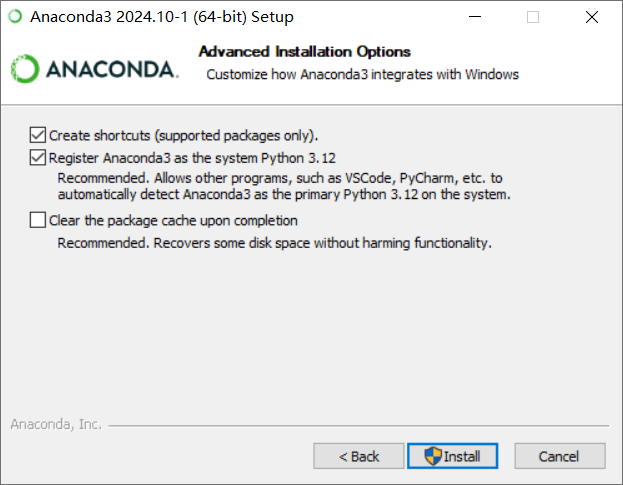
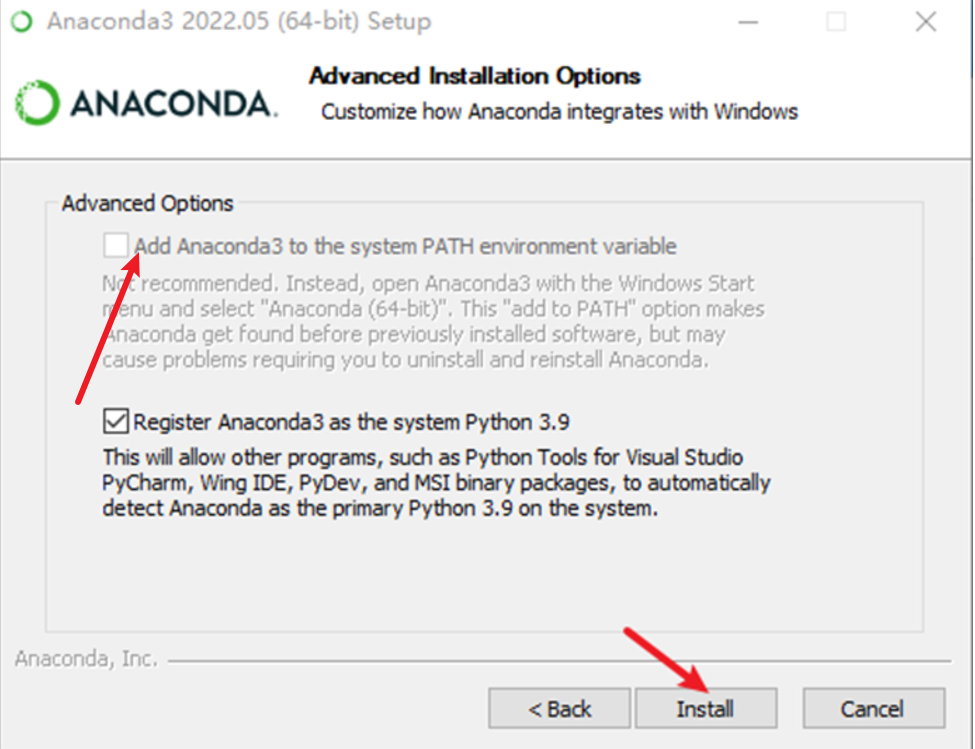
新版的anaconda是不支持自动加入环境变量的,需要手动加入环境变量。旧版本的只是,如下图所示:
4.2 创建虚拟环境
打开Anaconda命令行工具
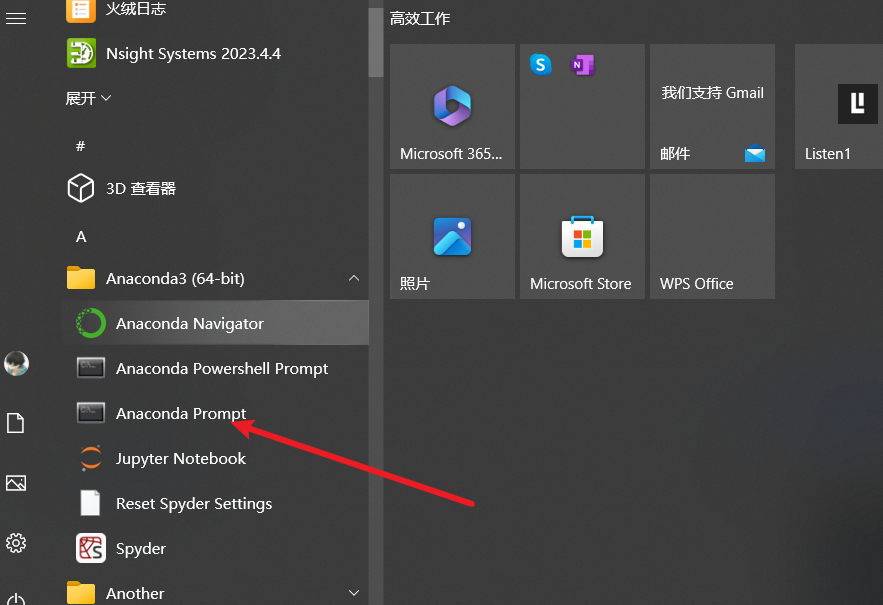
点开执行命令,这里的YOLO-GPU可以是任意名字。
conda create -n YOLO-GPU python=3.12
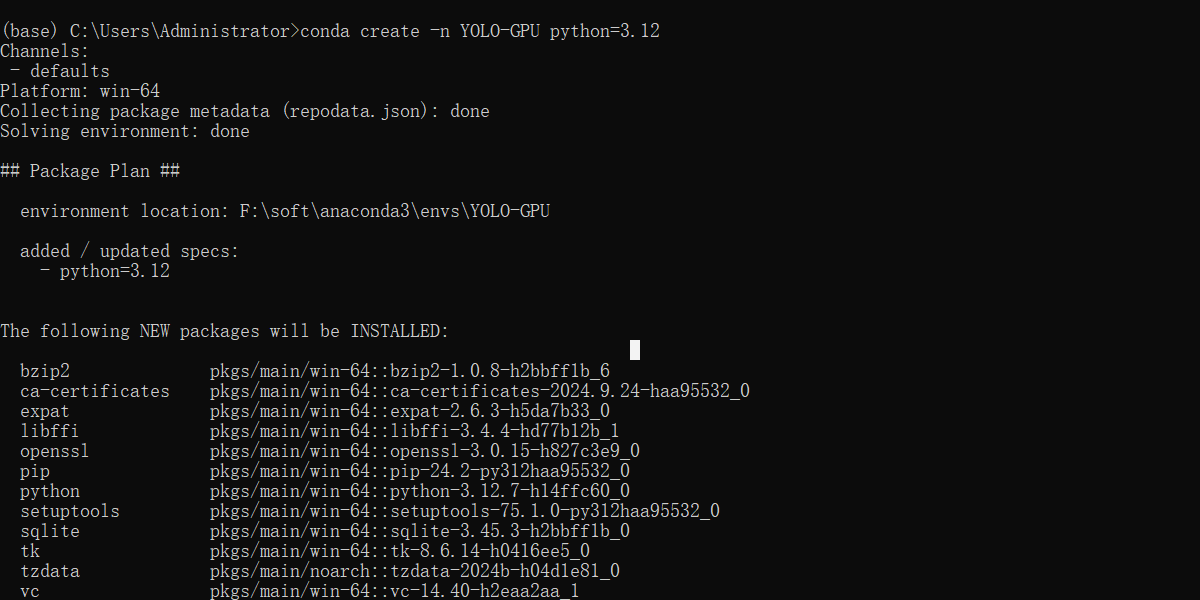
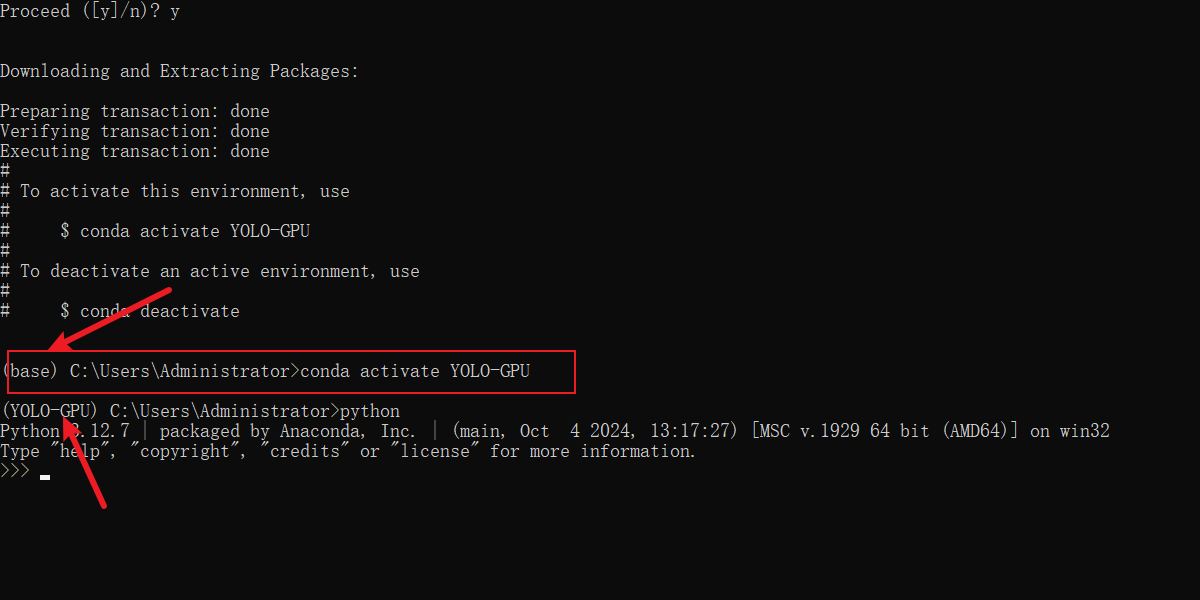
4.3 验证环境
先后执行下面脚本
conda activate YOLO-GPU
python
第五步: 安装GPU版本的PyTorch
5.1 下载
链接:https://pytorch.org/get-started/locally/,选择与cuda对应的pytorch版本。如果安装的cuda版本大于pytorch支持的版本,请选择向下版本的。
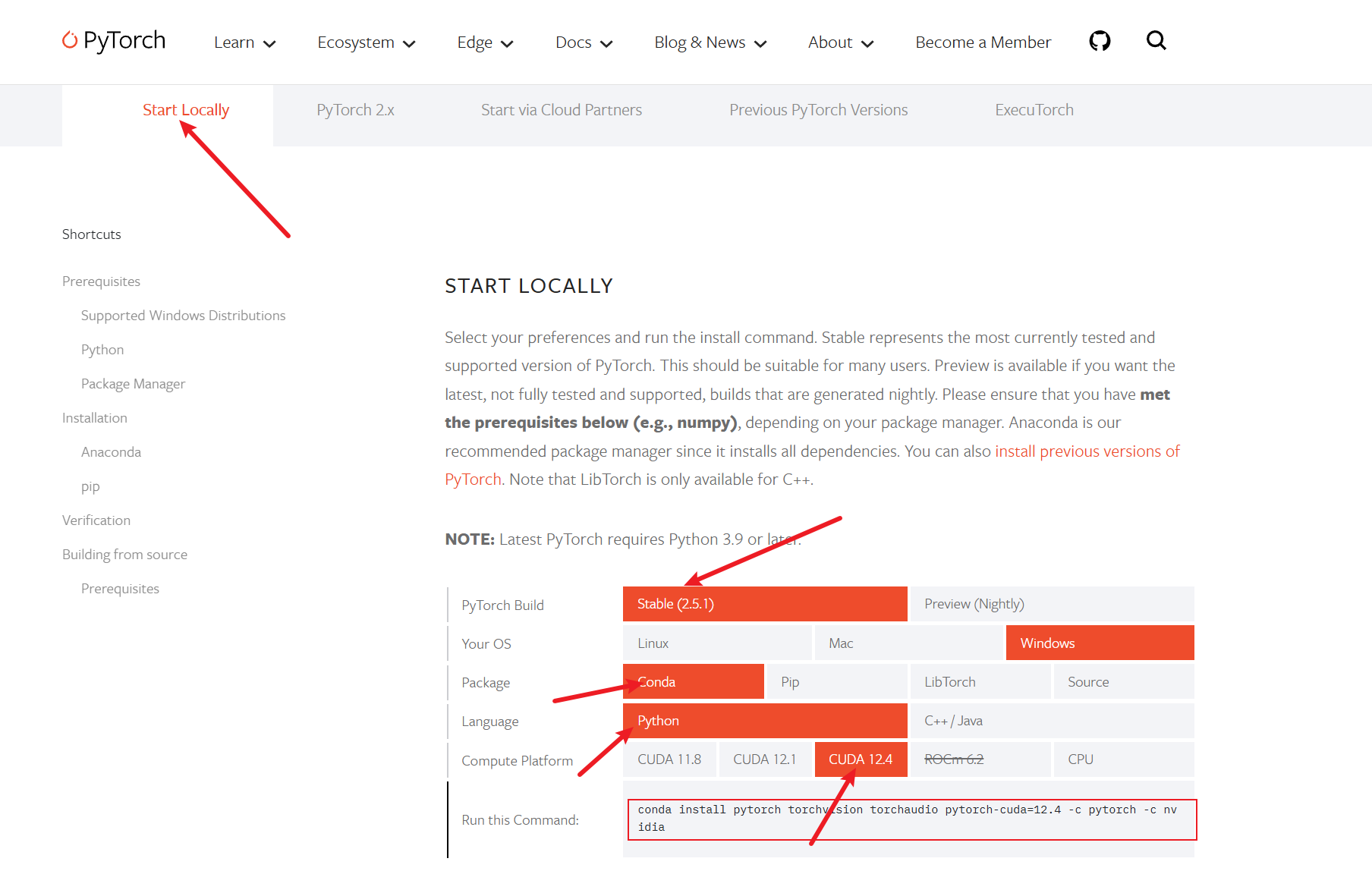
5.2 安装
复制底下的Anaconda的命令到打开Anaconda命令行工具执行即可。
请注意,需要激活你的虚拟环境,然后执行命令。
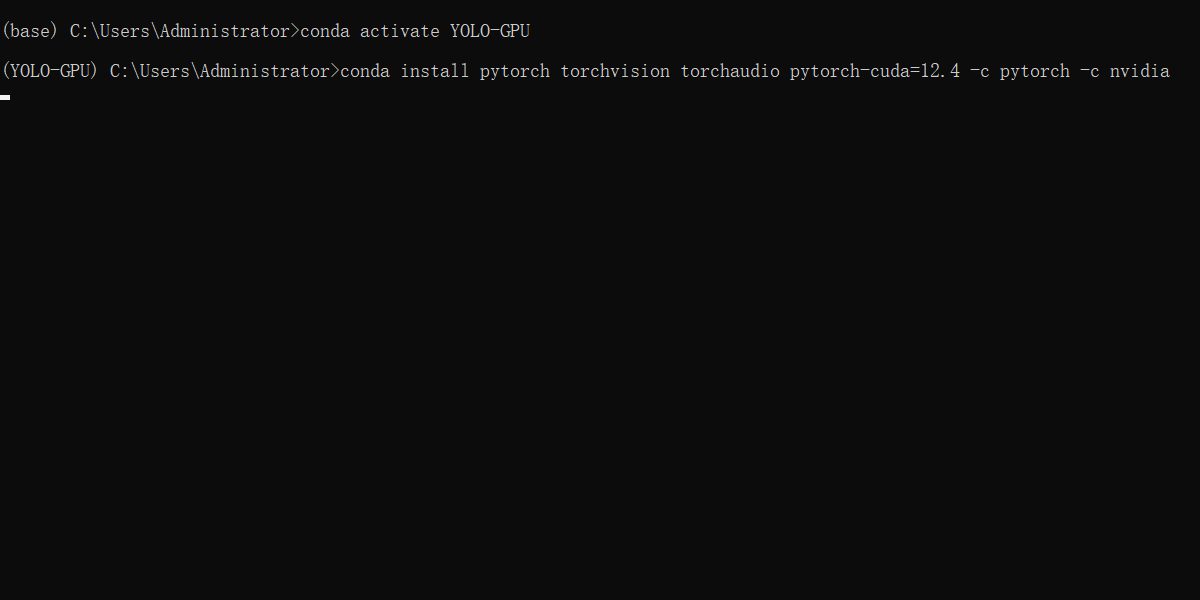
据此
conda activate YOLO-GPU
conda install pytorch torchvision torchaudio pytorch-cuda=12.4 -c pytorch -c nvidia
接下来就是等着输入y,然后漫长的等待!!!
5.3 验证
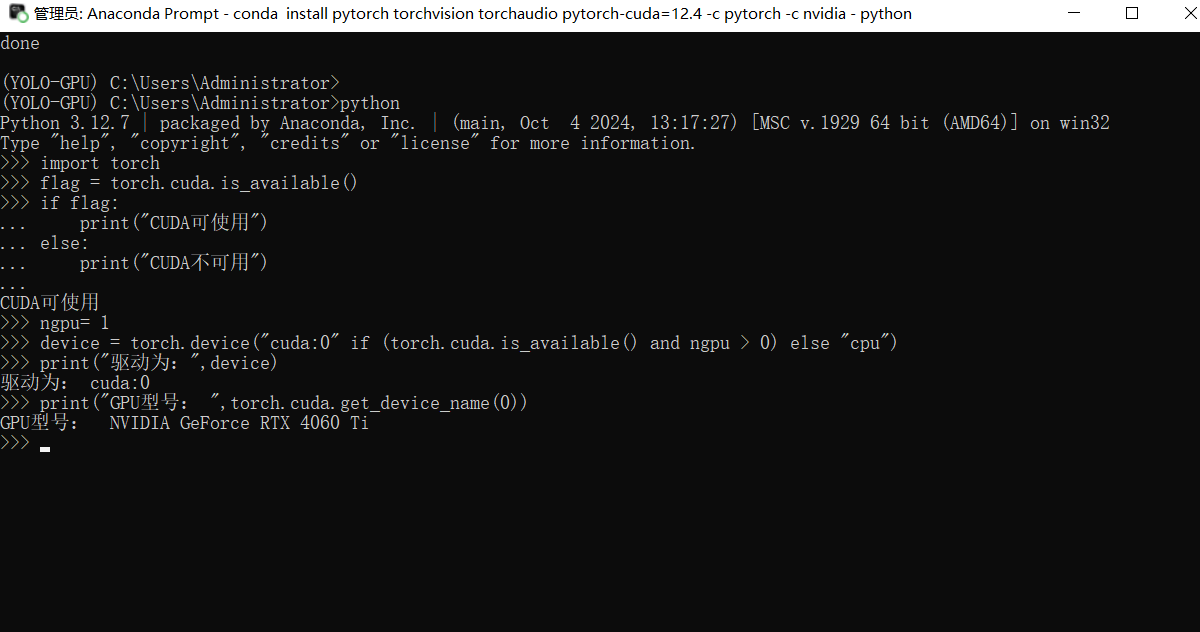
import torch
flag = torch.cuda.is_available()
if flag:
print("CUDA可使用")
else:
print("CUDA不可用")
ngpu= 1
# Decide which device we want to run on
device = torch.device("cuda:0" if (torch.cuda.is_available() and ngpu > 0) else "cpu")
print("驱动为:",device)
print("GPU型号: ",torch.cuda.get_device_name(0))
torch.cuda.is_available()
cuda是否可用;
torch.cuda.device_count()
返回gpu数量;
torch.cuda.get_device_name(0)
返回gpu名字,设备索引默认从0开始;
torch.cuda.current_device()
返回当前设备索引;
第六步:pycharm搭建YOLO11环境
下载链接:https://github.com/ultralytics/ultralytics,这里笔者直接下载压缩包。
请注意:tag大于等于8.3的是YOLO11,小于8.3的是YOLO11
6.1 pycharm 导入
解压缩下载的文件,把ultralytics-main\ultralytics-main 拷贝到你需要存放的位置。
然后Pycharm导入项目。
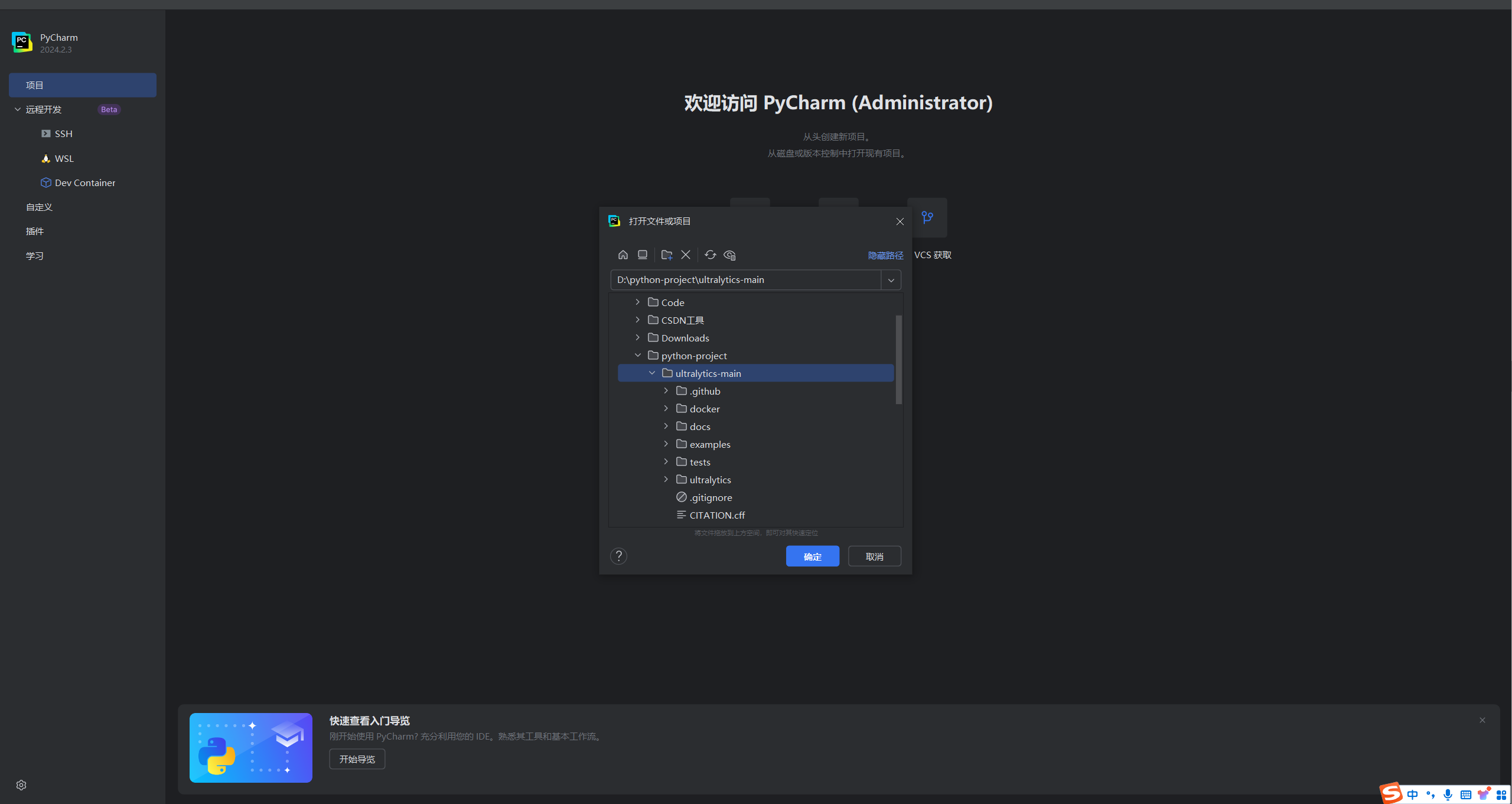
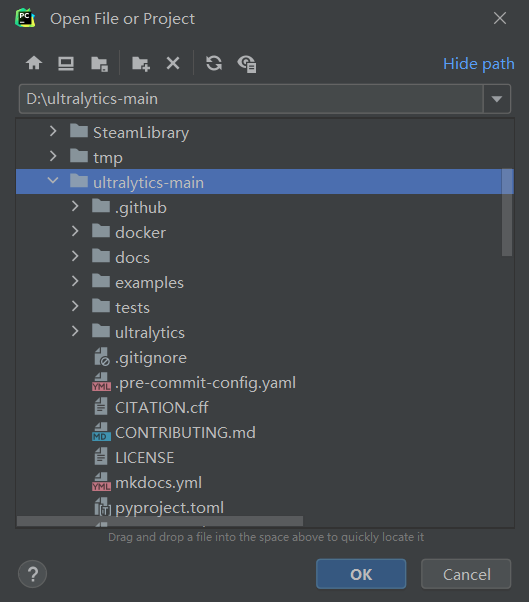
如果是是已经打开过其他项目了,可以直接右上角导入。然后选择你的项目:
6.2 pycharm更换python环境
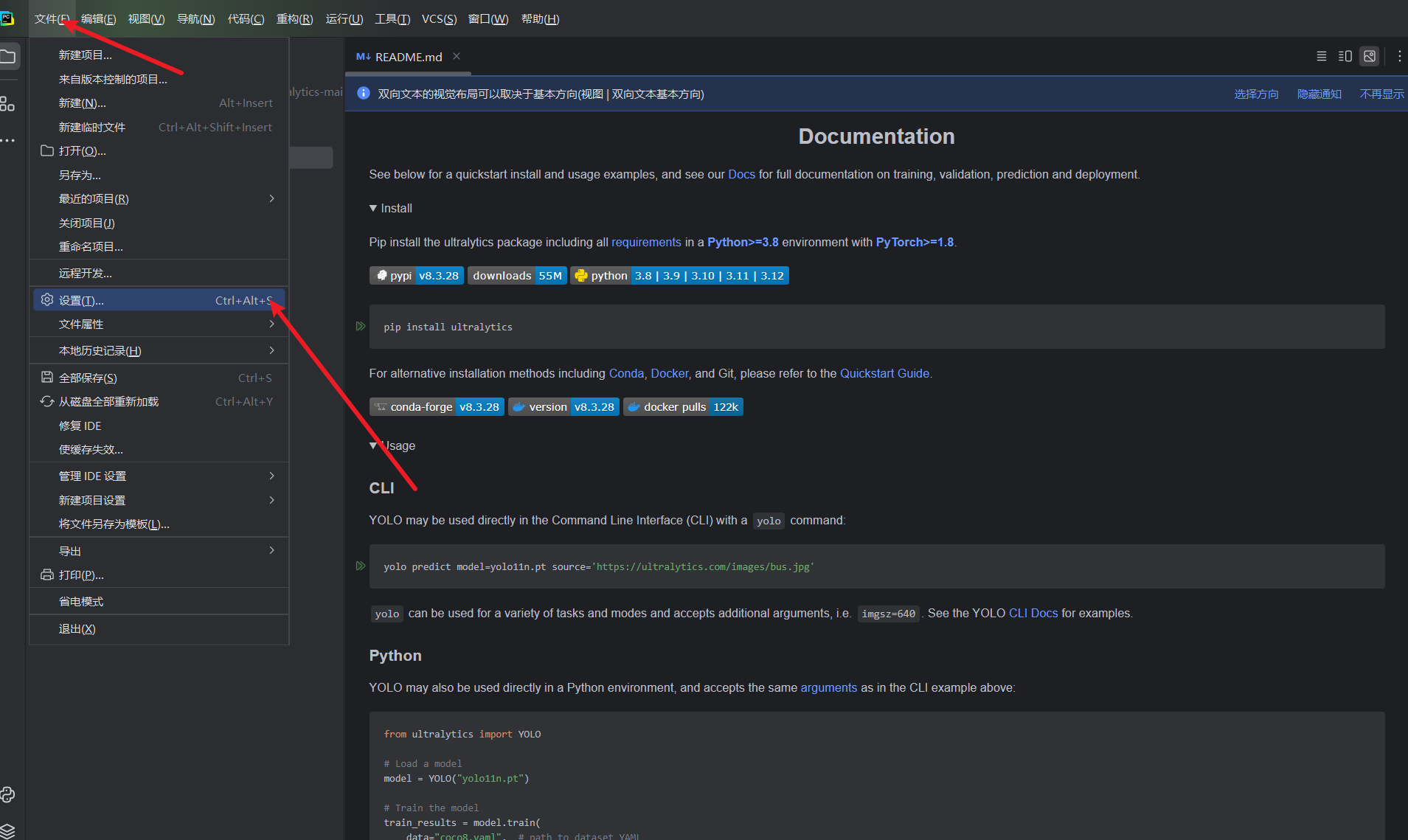
找到python解释器,这里提供了新版pycharm和旧版pycharm的截图:
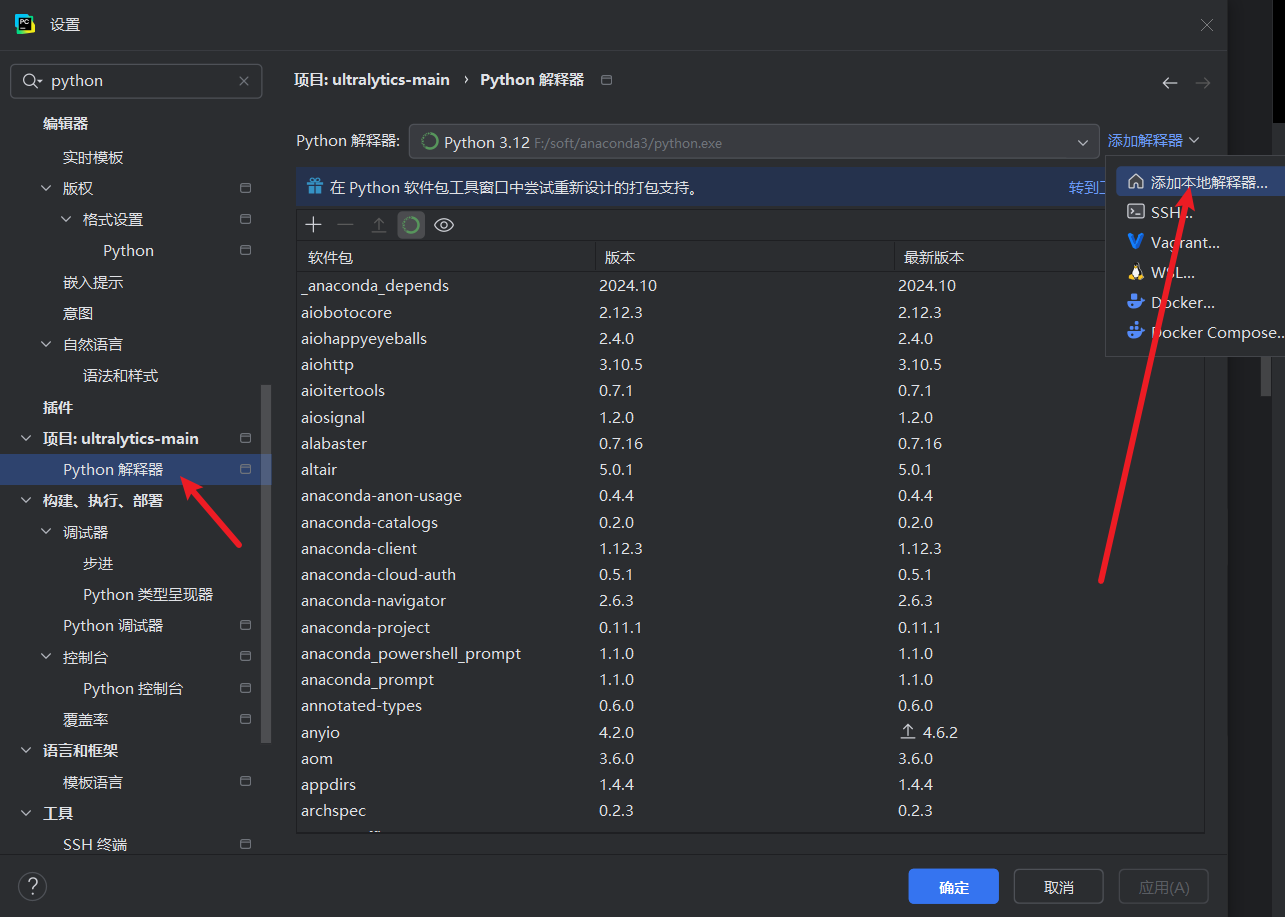
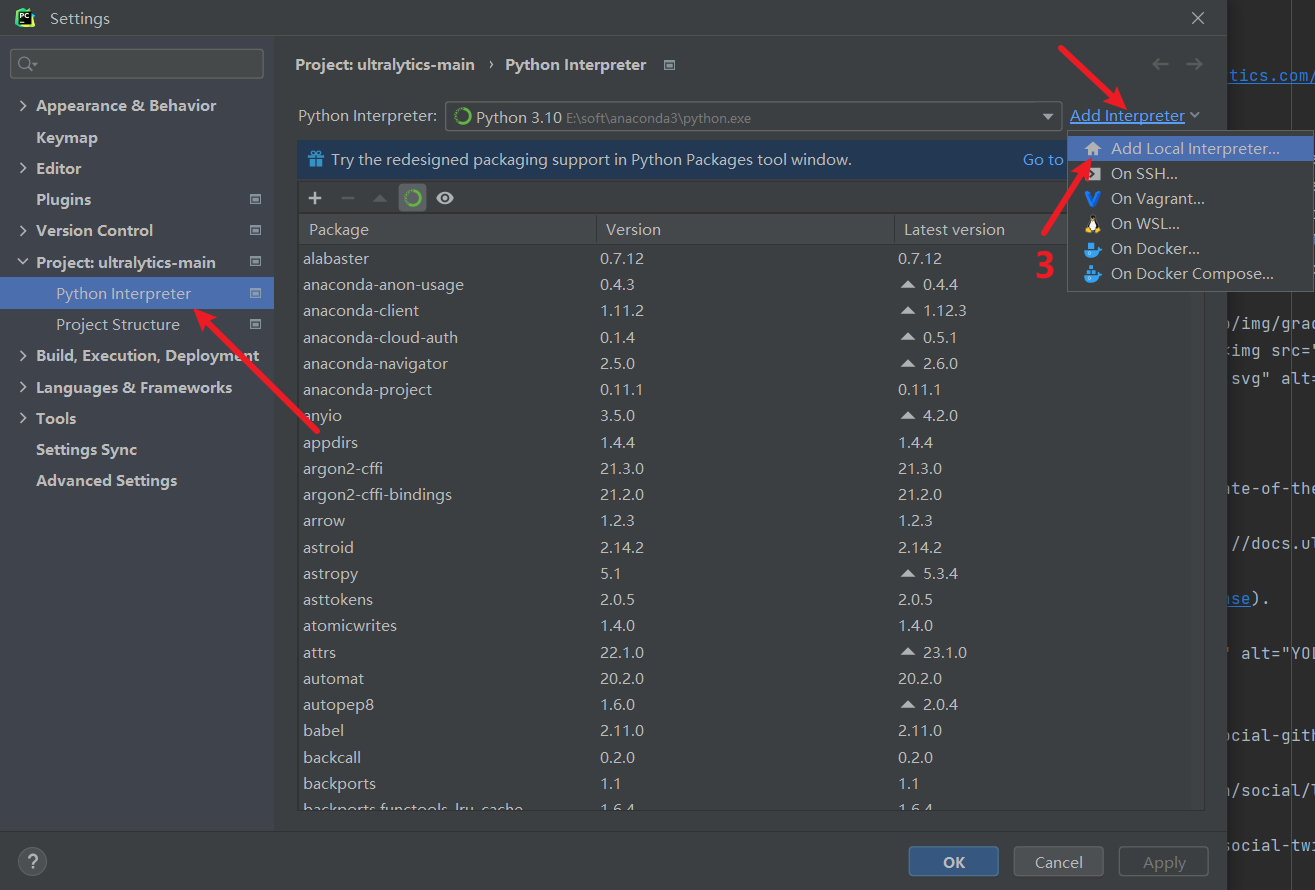
添加anaconda,按下面的序号操作:这里需要找anaconda安装目录下的conda.exe,然后点击Load Environments,加载conda。
选择带有GPU-pytorch的conda环境
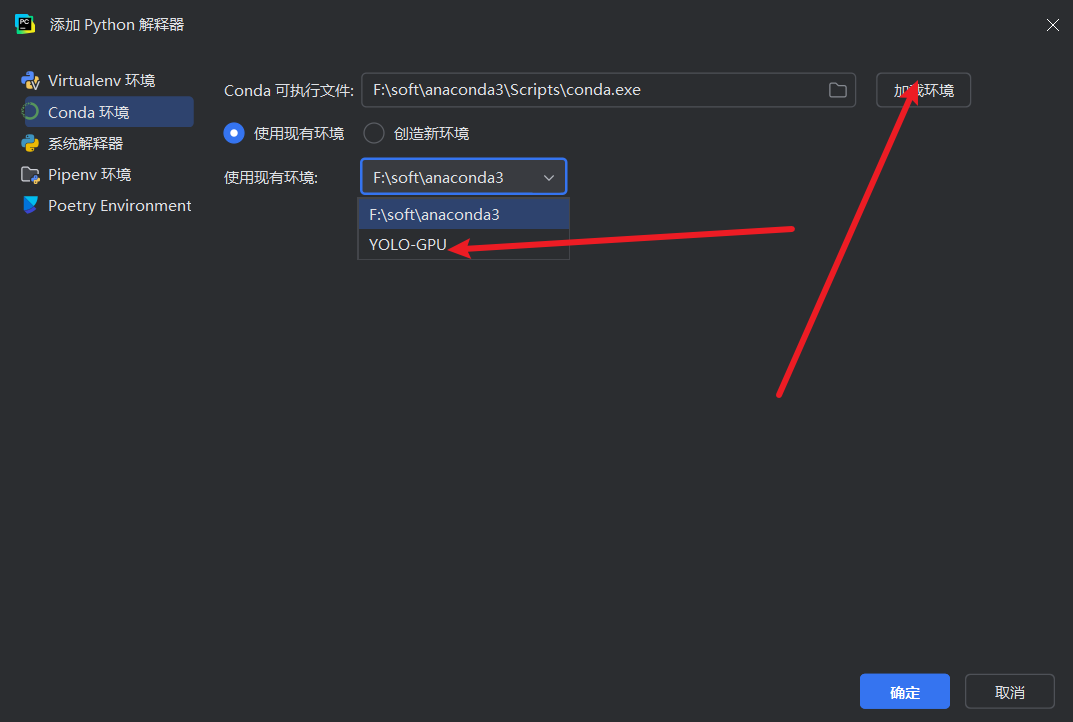
验证
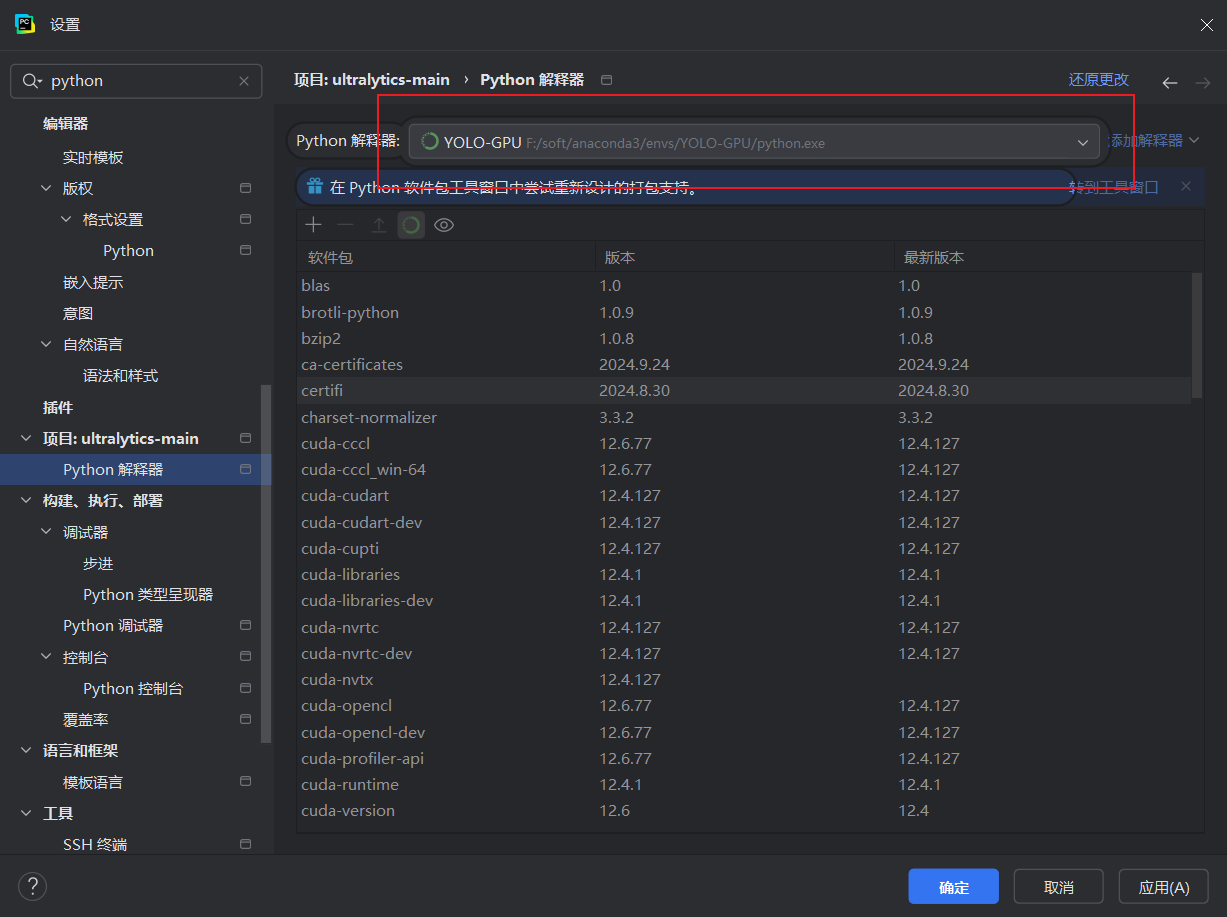
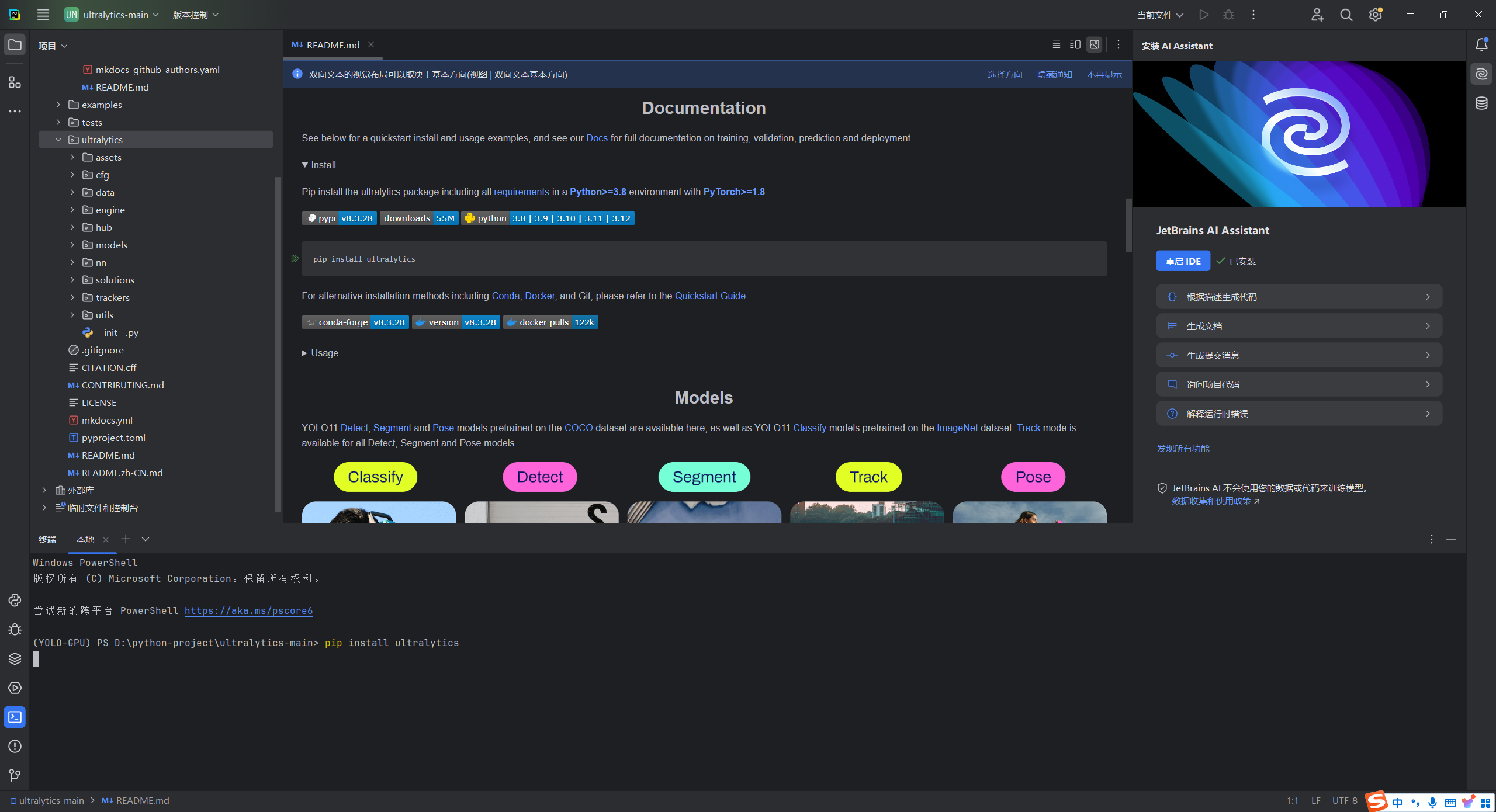
6.3 安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
在最新版本中,官方已经废弃了requirements.txt文件,转而将所有必要的代码和依赖整合进了ultralytics包中。因此,用户只需安装这个单一的ultralytics库,就能获得所需的全部功能和环境依赖。
pip install ultralytics
6.4 制作数据
可以选择使用YOLO官方推荐的网站制作数据:https://roboflow.com/。具体的制作过程会在另一篇文章中呈现。
这里我们直接使用公开的数据集进行训练。
数据集下载链接:
https://public.roboflow.com/object-detection/license-plates-us-eu/3
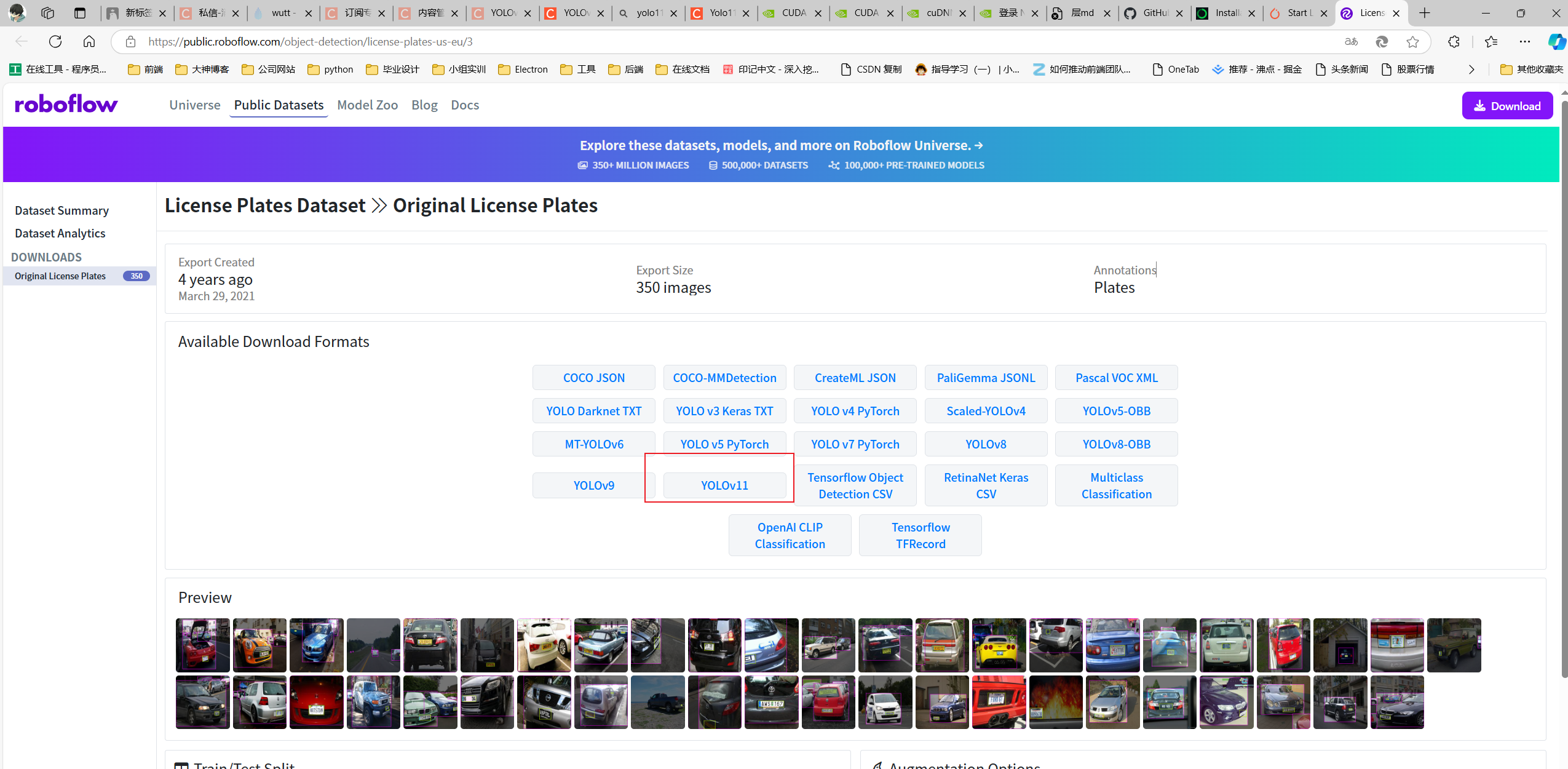
6.5 把数据集导入项目
数据集解压后目录如下:
在目标检测任务中,通常将整个数据集划分为训练集(training set)、验证集(validation set)和测试集(test set)。这三个数据集在训练和评估过程中具有不同的作用:
训练集(Training Set): 用于模型的训练,即通过反向传播和梯度下降等优化算法来调整模型的权重,使其能够从数据中学到有用的特征和模式。
验证集(Validation Set): 用于在训练过程中评估模型的性能和调整超参数。在每个训练周期(epoch)结束时,模型会在验证集上进行评估,以判断模型是否过拟合、欠拟合,以及选择最佳的超参数。
测试集(Test Set): 用于最终评估模型的泛化性能。测试集是模型在训练和验证阶段都没有见过的数据,用于模拟模型在实际应用中的表现。在训练完成后,通过测试集评估模型的性能,获取最终的性能指标。
在YOLO11中,通常使用model.train()函数进行训练,而这个函数会处理训练集(Training Set)和验证集(Validation Set)的批处理(batching)以及相应的训练过程。model.train()的主要作用是在模型上执行训练步骤,其中包括前向传播、计算损失、反向传播和权重更新等步骤。
YOLO11 所需要的数据集路径的格式如下:(YOLO11支持不止这一种格式数据集)
├── YOLO11_dataset
└── train
└── images (folder including all training images)
└── labels (folder including all training labels)
└── test
└── images (folder including all testing images)
└── labels (folder including all testing labels)
└── valid
└── images (folder including all testing images)
└── labels (folder including all testing labels)
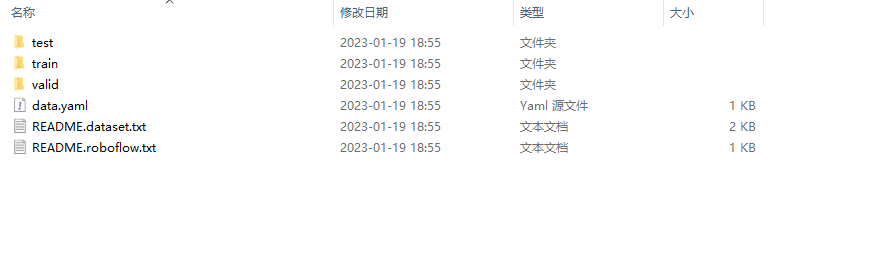
把License Plates.v3-original-license-plates.yolov11目录中的图片复制到项目的ultralytics\datasets下面,这里你需要先创建datasets目录!!!
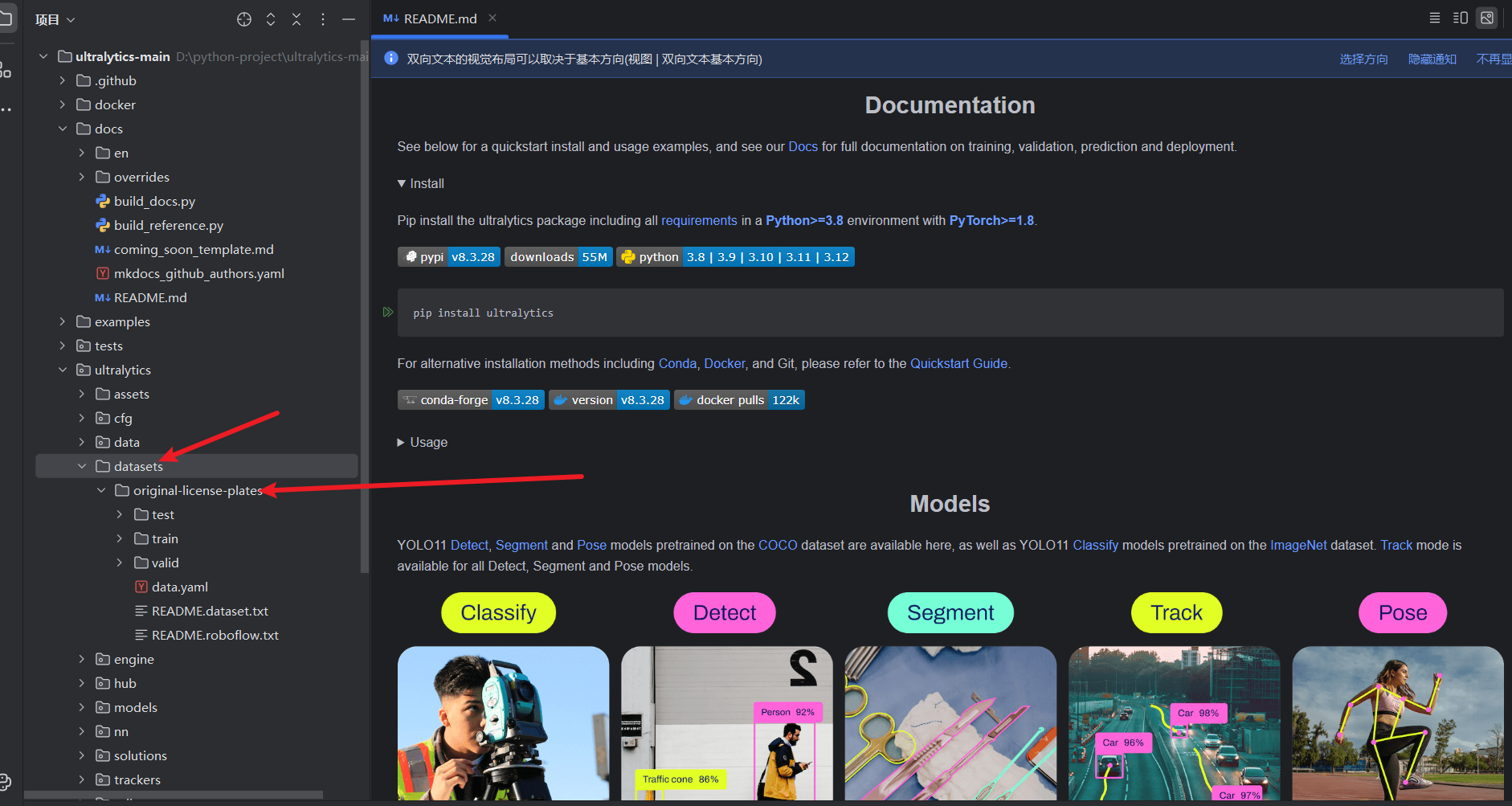
在original-license-plates目录下有一个data.yaml文件,打开,可以看到这个是数据集的配置文件。
train: ../train/images
val: ../valid/images
test: ../test/images
nc: 2
names: ['license-plate', 'vehicle']
roboflow:
workspace: samrat-sahoo
project: license-plates-f8vsn
version: 3
license: CC BY 4.0
url: https://universe.roboflow.com/samrat-sahoo/license-plates-f8vsn/dataset/3
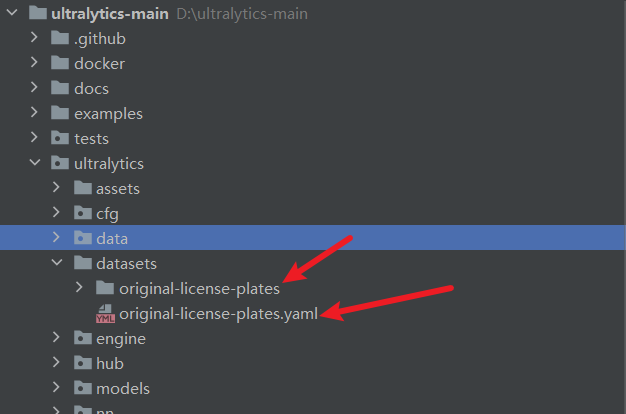
笔者通常不会直接用它,会在original-license-plates同级目录下 ,新建一个同名的yaml文件,并使用绝对路径索引数据集。当然你也可以不移动原来的data.yaml文件位置,直接使用,这个纯属个人习惯。
train: D:\python-project\ultralytics-main\ultralytics\datasets\original-license-plates\train
val: D:\python-project\ultralytics-main\ultralytics\datasets\original-license-plates\valid
test: D:\python-project\ultralytics-main\ultralytics\datasets\original-license-plates\test
nc: 2
names: ['license-plate', 'vehicle']
roboflow:
workspace: samrat-sahoo
project: license-plates-f8vsn
version: 3
license: CC BY 4.0
url: https://universe.roboflow.com/samrat-sahoo/license-plates-f8vsn/dataset/3
以EMA(Efficient Multi-Scale Attention)注意力改进YOLO11
YOLO11引入代码
在根目录下的ultralytics/nn/目录,新建一个attention目录,然后新建一个以 EMA_attention为文件名的py文件, 把代码拷贝进去。
import torch
from torch import nn
class EMA(nn.Module):
def __init__(self, channels, c2=None, factor=32):
super(EMA, self).__init__()
self.groups = factor
assert channels // self.groups > 0
self.softmax = nn.Softmax(-1)
self.agp = nn.AdaptiveAvgPool2d((1, 1))
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
self.gn = nn.GroupNorm(channels // self.groups, channels // self.groups)
self.conv1x1 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=1, stride=1, padding=0)
self.conv3x3 = nn.Conv2d(channels // self.groups, channels // self.groups, kernel_size=3, stride=1, padding=1)
def forward(self, x):
b, c, h, w = x.size()
group_x = x.reshape(b * self.groups, -1, h, w) # b*g,c//g,h,w
x_h = self.pool_h(group_x)
x_w = self.pool_w(group_x).permute(0, 1, 3, 2)
hw = self.conv1x1(torch.cat([x_h, x_w], dim=2))
x_h, x_w = torch.split(hw, [h, w], dim=2)
x1 = self.gn(group_x * x_h.sigmoid() * x_w.permute(0, 1, 3, 2).sigmoid())
x2 = self.conv3x3(group_x)
x11 = self.softmax(self.agp(x1).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x12 = x2.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
x21 = self.softmax(self.agp(x2).reshape(b * self.groups, -1, 1).permute(0, 2, 1))
x22 = x1.reshape(b * self.groups, c // self.groups, -1) # b*g, c//g, hw
weights = (torch.matmul(x11, x12) + torch.matmul(x21, x22)).reshape(b * self.groups, 1, h, w)
return (group_x * weights.sigmoid()).reshape(b, c, h, w)
tasks注册
在ultralytics/nn/tasks.py中进行如下操作:
步骤1:
from ultralytics.nn.attention.EMA_attention import EMA
步骤2
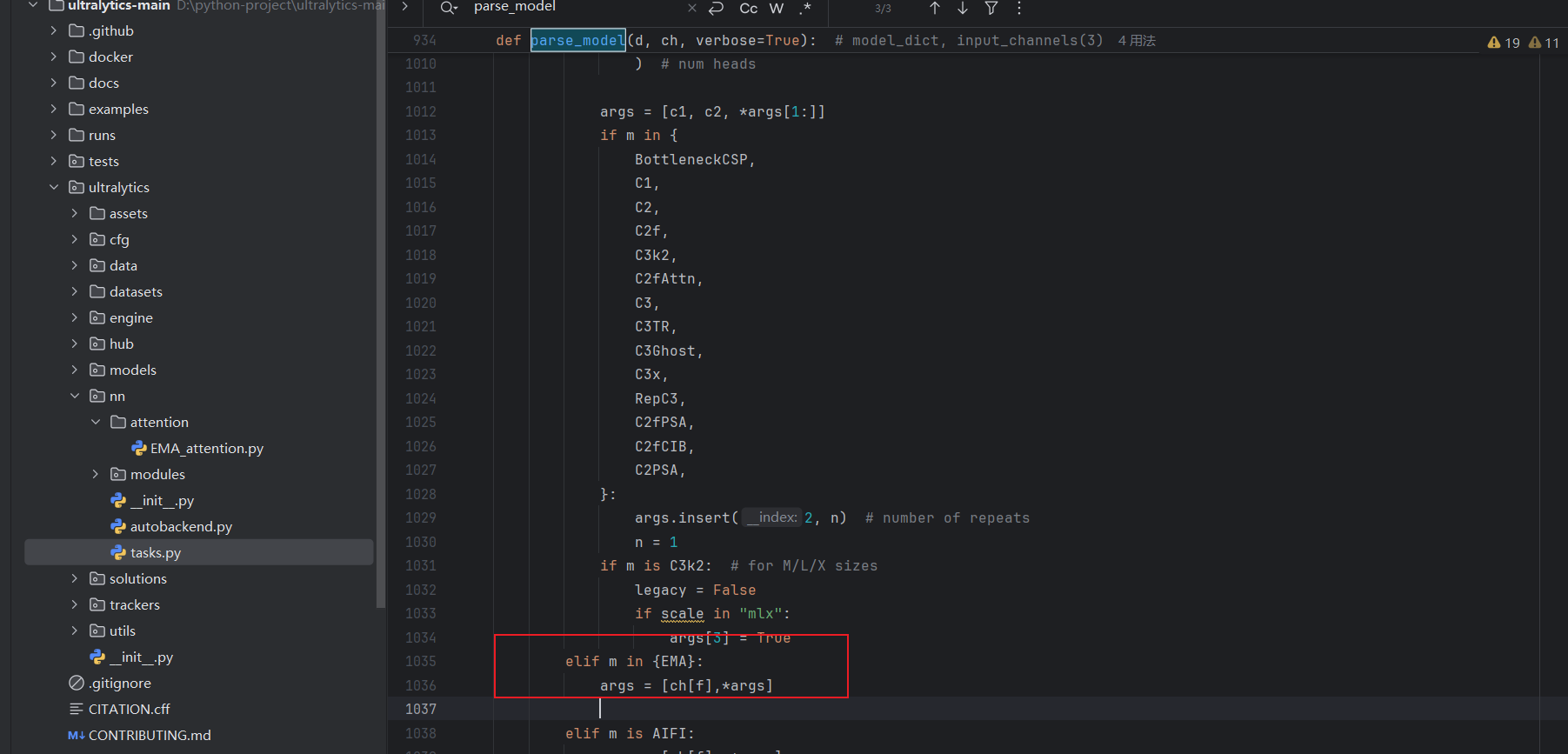
修改def parse_model(d, ch, verbose=True):
elif m in {EMA}:
args = [ch[f],*args]
配置yolov11-EMA.yaml
配置文件目录:ultralytics/cfg/models/11/yolov11-EMA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 2 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, EMA, []] #17
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 20 (P4/16-medium)
- [-1, 1, EMA, []] # 21
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 24 (P5/32-large)
- [-1, 1, EMA, []] # 25
- [[17, 21, 25], 1, Detect, [nc]] # Detect(P3, P4, P5)
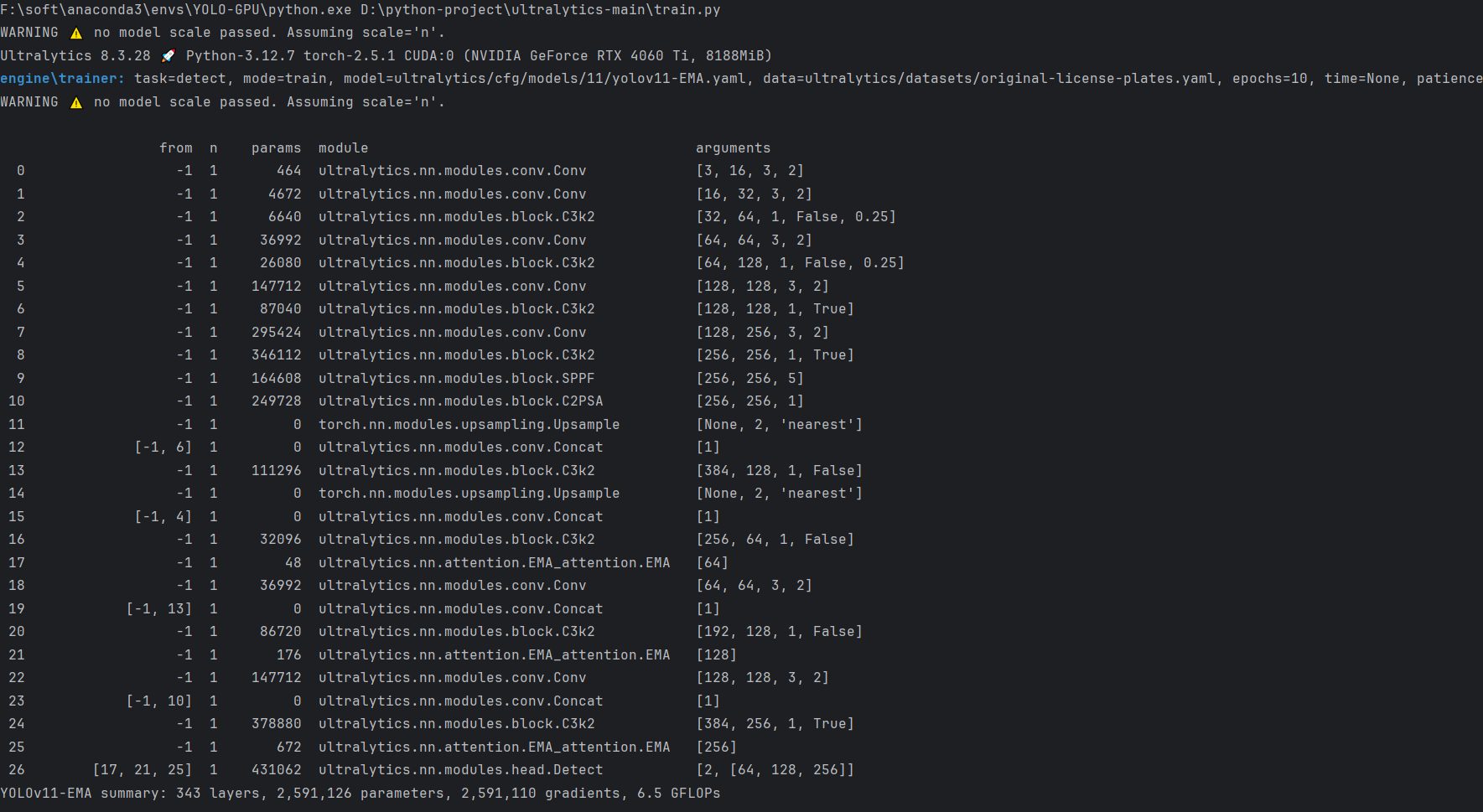
实验
脚本
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO(' ultralytics/cfg/models/11/yolov11-EMA.yaml')
# 修改为自己的数据集地址
model.train(data='ultralytics/datasets/original-license-plates.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
optimizer='SGD',
amp=True,
project='runs/train',
name='EMA',
)
结果
第七步:训练模型
使用 Ultralytics,一般会经历以下过程:
- 训练(Train) 模式:在自定义或预加载的数据集上微调您的模型。
- 验证(Val)模式:训练后进行校验,以验证模型性能。
- 预测(Predict)模式:在真实世界数据上释放模型的预测能力。
- 导出(Export)模式:以各种格式使模型准备就绪,部署至生产环境。
- 跟踪(Track)模式:将您的目标检测模型扩展到实时跟踪应用中。
- 基准(Benchmark)模式:在不同部署环境中分析模型的速度和准确性。
官方文档:https://docs.ultralytics.com/modes/train/#usage-examples
下面我将详细介绍前四步骤及其操作:
7.1 训练模型(Training)
训练模型的目的是使模型学习如何从给定的数据集中识别目标。这涉及到使用大量带标注的图像数据训练模型,以便模型能够学会识别不同的对象。
ultralytics 中常见的文件格式有两种,模型以 .pt 结尾。数据集以 .yaml 结尾。
7.1.1 训练包含三种模式
-
基于官方模型进行训练,
-
从已有模型进行训练,
-
在没有模型的情况下训练出自己的模型。
7.1.2 训练的三种方式
下面这三种方式,本质上就是同一种东西,所支持的参数都是一样的。还记得我们在5.3验证的时候获取的GPU设备吗,这里我们可以指定参数device=0来使用GPU设备进行加速训练
-
命令行
这种方式不推荐啊,会有莫名其妙的问题。
我们可以通过命令直接进行训练在其中指定参数,但是这样的方式,我们每个参数都要在其中打出来。命令如下:
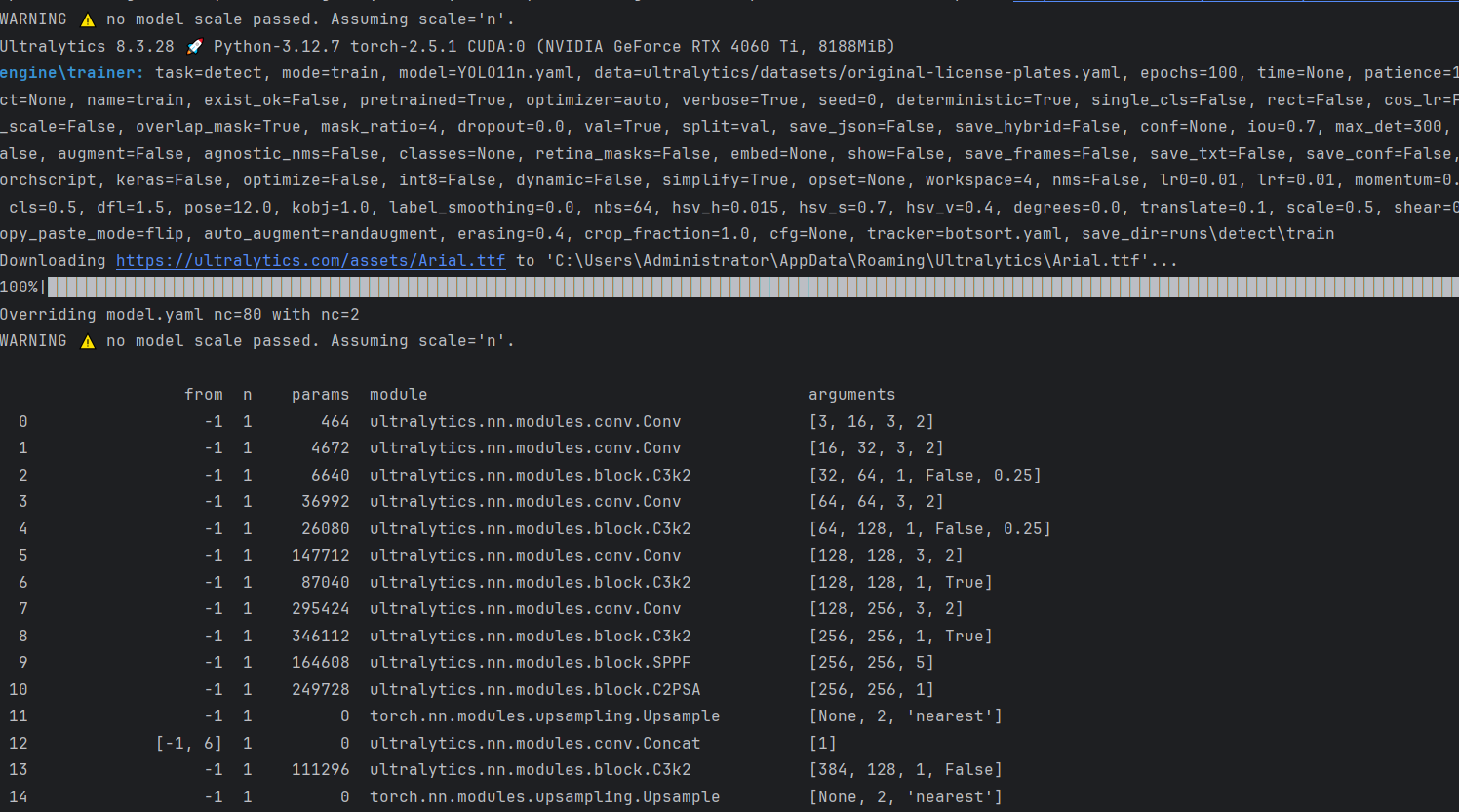
# 从YAML文件构建一个新的YOLO11n模型,数据集从头开始训练一个新的YOLO11n模型 yolo detect train data=ultralytics/datasets/original-license-plates.yaml model=YOLO11n.yaml epochs=100 imgsz=640 # 从预训练的YOLO11n.pt模型开始,使用自定义数据集进行训练 yolo detect train data=ultralytics/datasets/original-license-plates.yaml model=YOLO11n.pt epochs=100 imgsz=640 # 从YAML中构建一个新模型,将预训练的YOLO11n.pt模型的权重转移到它,并使用数据集开始训练 yolo detect train data=ultralytics/datasets/original-license-plates.yaml model=YOLO11n.yaml pretrained=YOLO11n.pt epochs=100 imgsz=640如果你是Windows系统的电脑,其中的Workers最好设置成0否则容易报线程的错误。
yolo detect train data=ultralytics/datasets/data.yaml model=YOLO11n.yaml workers=0An attempt has been made to start a new process before the current process has finished its bootstrapping phase. This probably means that you are not using fork to start your child processes and you have forgotten to use the proper idiom in the main module: if __name__ == '__main__': freeze_support() ... The "freeze_support()" line can be omitted if the program is not going to be frozen to produce an executable. -
指定cfg
通过指定cfg直接进行训练,我们配置好
ultralytics/cfg/default.yaml这个文件之后,可以直接执行这个文件进行训练,这样就不用在命令行输入其它的参数了。yolo cfg=ultralytics/cfg/default.yaml -
代码
在项目根目录下面新建train.py文件,笔者比较喜欢实用此种方式,但是推荐大家使用cfg的方式。
from ultralytics import YOLO model = YOLO('yolo11n.yaml').load('yolo11n.pt') # build from YAML and transfer weights if __name__ == '__main__': model.train(data='ultralytics/datasets/original-license-plates.yaml', epochs=10, imgsz=640, device=0)
7.1.3 训练结果
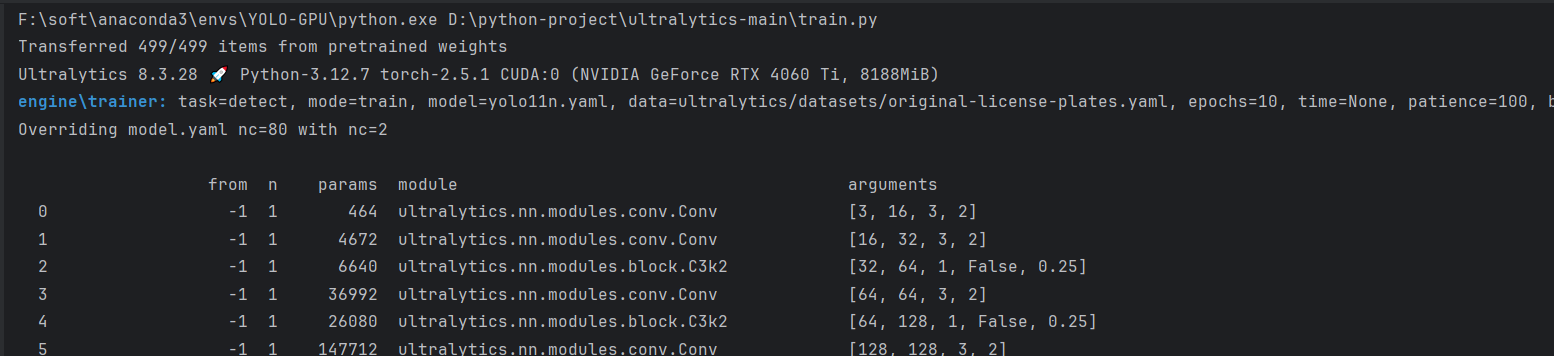
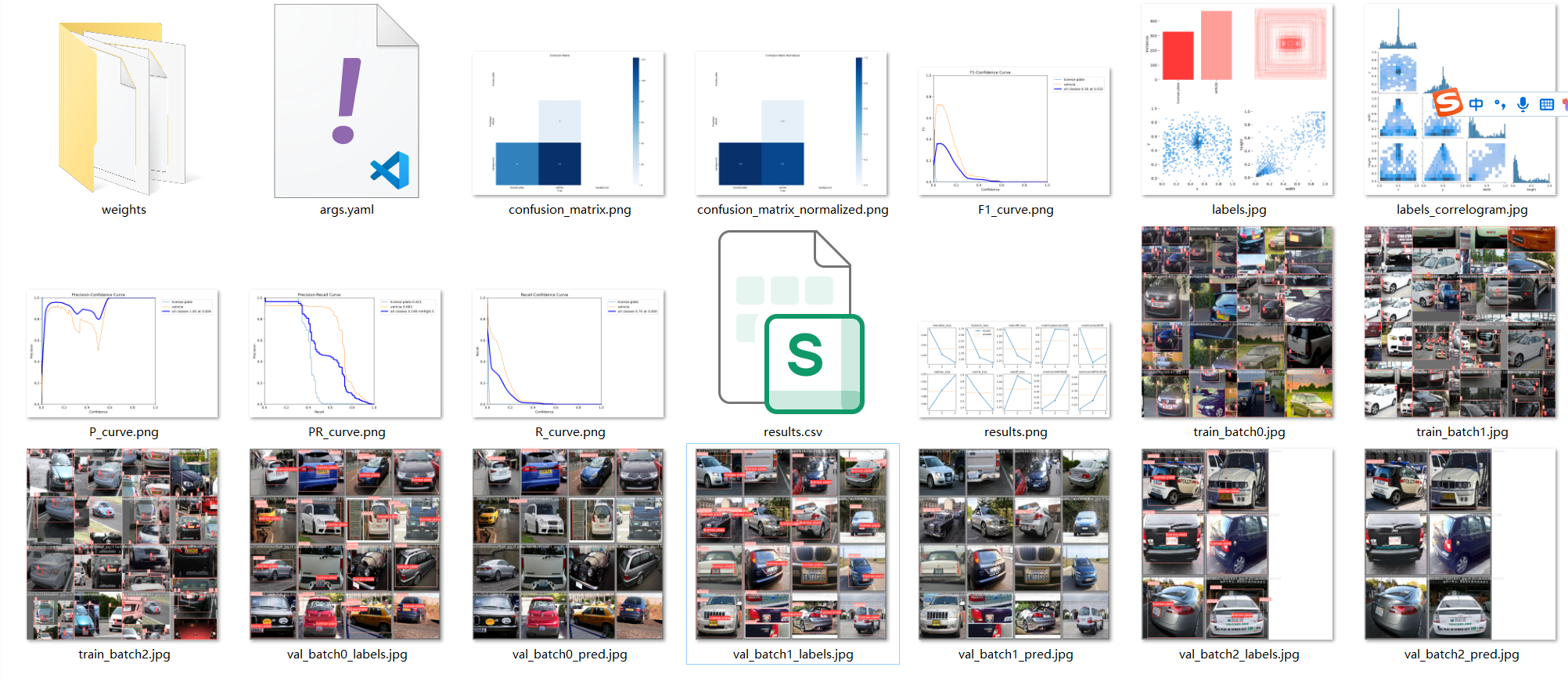
训练后的结果保存在runs\detect\train目录下,训练出的模型会存储在 runs\detect\train\weights目录下。
7.1.4 参数
上面所有的训练方式的训练参数,都在ultralytics/cfg/default.yaml里面。
| 参数名 | 输入类型 | 参数解释 | |
|---|---|---|---|
| 0 | task | str | YOLO模型的任务选择,选择你是要进行检测、分类等操作 |
| 1 | mode | str | YOLO模式的选择,选择要进行训练、推理、输出、验证等操作 |
| 2 | model | str/optional | 模型的文件,可以是官方的预训练模型,也可以是训练自己模型的yaml文件 |
| 3 | data | str/optional | 模型的地址,可以是文件的地址,也可以是配置好地址的yaml文件 |
| 4 | epochs | int | 训练的轮次,将你的数据输入到模型里进行训练的次数 |
| 5 | patience | int | 早停机制,当你的模型精度没有改进了就提前停止训练 |
| 6 | batch | int | 我们输入的数据集会分解为多个子集,一次向模型里输入多少个子集 |
| 7 | imgsz | int/list | 输入的图片的大小,可以是整数就代表图片尺寸为int*int,或者list分别代表宽和高[w,h] |
| 8 | save | bool | 是否保存模型以及预测结果 |
| 9 | save_period | int | 在训练过程中多少次保存一次模型文件,就是生成的pt文件 |
| 10 | cache | bool | 参数cache用于控制是否启用缓存机制。 |
| 11 | device | int/str/list/optional | GPU设备的选择:cuda device=0 or device=0,1,2,3 or device=cpu |
| 12 | workers | int | 工作的线程,Windows系统一定要设置为0否则很可能会引起线程报错 |
| 13 | name | str/optional | 模型保存的名字,结果会保存到’project/name’ 目录下 |
| 14 | exist_ok | bool | 如果模型存在的时候是否进行覆盖操作 |
| 15 | prepetrained | bool | 参数pretrained用于控制是否使用预训练模型。 |
| 16 | optimizer | str | 优化器的选择choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto] |
| 17 | verbose | bool | 用于控制在执行过程中是否输出详细的信息和日志。 |
| 18 | seed | int | 随机数种子,模型中涉及到随机的时候,根据随机数种子进行生成 |
| 19 | deterministic | bool | 用于控制是否启用确定性模式,在确定性模式下,算法的执行将变得可重复,即相同的输入将产生相同的输出 |
| 20 | single_cls | bool | 是否是单标签训练 |
| 21 | rect | bool | 当 rect 设置为 True 时,表示启用矩形训练或验证。矩形训练或验证是一种数据处理技术,其中在训练或验证过程中,输入数据会被调整为具有相同宽高比的矩形形状。 |
| 22 | cos_lr | bool | 控制是否使用余弦学习率调度器 |
| 23 | close_mosaic | int | 控制在最后几个 epochs 中是否禁用马赛克数据增强 |
| 24 | resume | bool | 用于从先前的训练检查点(checkpoint)中恢复模型的训练。 |
| 25 | amp | bool | 用于控制是否进行自动混合精度 |
| 26 | fraction | float | 用于指定训练数据集的一部分进行训练的比例。默认值为 1.0 |
| 27 | profile | bool | 用于控制是否在训练过程中启用 ONNX 和 TensorRT 的性能分析 |
| 28 | freeze | int/list/optinal | 用于指定在训练过程中冻结前 n 层或指定层索引的列表,以防止它们的权重更新。这对于迁移学习或特定层的微调很有用。 |
7.2 验证模型(Validation)
验证模型是在独立的【验证数据集】上测试模型的性能,以评估其泛化能力。这有助于检测模型是否过拟合或欠拟合,并调整模型参数。
7.2.1 验证的三种方式
同样的验证模型也支持上面的三种方式来操作。
-
命令行
yolo task=detect mode=val model=best.pt data=data.yaml device=0 -
指定cfg
yolo cfg=ultralytics/cfg/default.yaml -
python代码
在项目根目录下面新建validate.py文件,笔者比较喜欢实用此种方式,但是推荐大家使用cfg的方式。
对于下面的print还不太熟悉的同学,请参考:https://blog.csdn.net/shangyanaf/article/details/138966767
# 导入ultralytics的YOLO库 from ultralytics import YOLO # 加载模型 model = YOLO('runs/detect/train/weights/best.pt') # 加载自定义的训练模型 if __name__ == '__main__': # 对模型进行验证 metrics = model.val() # 调用val方法进行模型验证,不需要传入参数,数据集和设置已被模型记住 # 输出不同的性能指标 print("AP ([email protected]:0.95):", metrics.box.map) # 输出平均精度均值(AP,Average Precision)在IoU阈值从0.5到0.95的范围内的结果 print("[email protected] ([email protected]):", metrics.box.map50) # 输出在IoU=0.5时的平均精度(AP50) print("[email protected] ([email protected]):", metrics.box.map75) # 输出在IoU=0.75时的平均精度(AP75) print("APs per category ([email protected]:0.95 per category):", metrics.box.maps) # 输出每个类别在IoU阈值从0.5到0.95的平均精度的列表
7.2.2 验证结果
训练后的结果保存在runs\detect\val目录下。

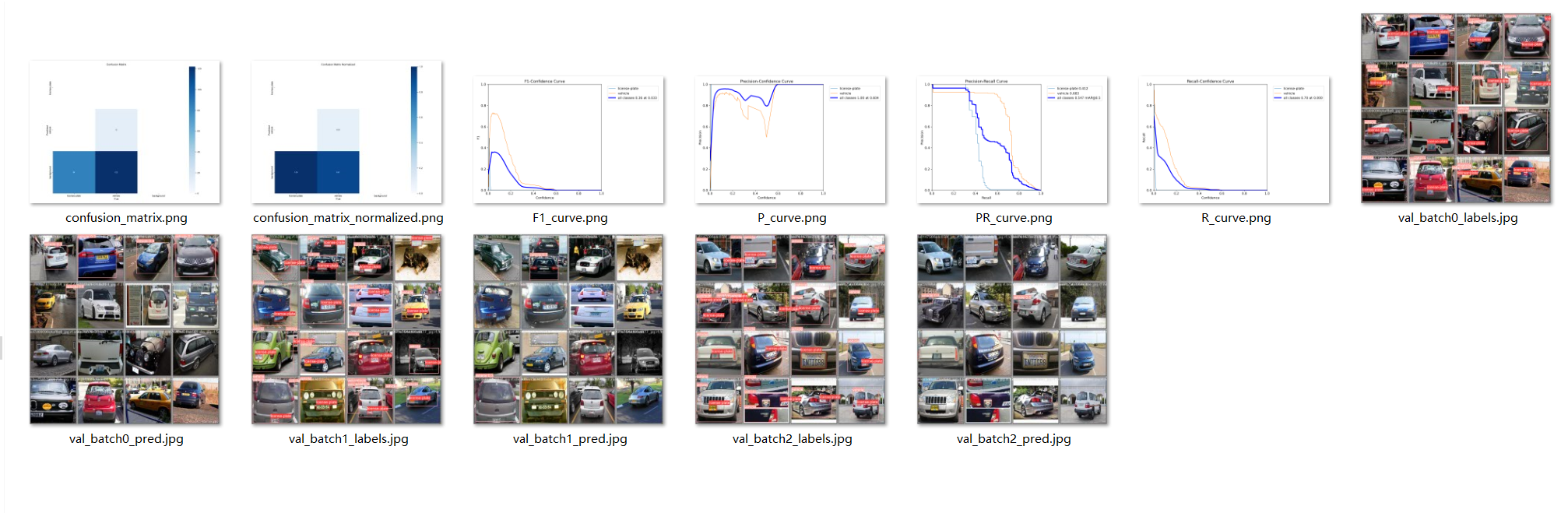
7.2.3 验证参数
| 论据 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| data | str | None | 指定数据集配置文件的路径(如 coco8.yaml).该文件包括验证数据的路径、类名和类数。 |
| imgsz | int | 640 | 定义输入图像的尺寸。所有图像在处理前都会调整到这一尺寸。 |
| batch | int | 16 | 设置每批图像的数量。使用 -1 的自动批处理功能,可根据 GPU 内存可用性自动调整。 |
| save_json | bool | False | 如果 True此外,还可将结果保存到 JSON 文件中,以便进一步分析或与其他工具集成。 |
| save_hybrid | bool | False | 如果 True,保存混合版本的标签,将原始注释与额外的模型预测相结合。 |
| conf | float | 0.001 | 设置检测的最小置信度阈值。置信度低于此阈值的检测将被丢弃。 |
| iou | float | 0.6 | 设置非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。有助于减少重复检测。 |
| max_det | int | 300 | 限制每幅图像的最大检测次数。在密度较高的场景中非常有用,可以防止检测次数过多。 |
| half | bool | True | 可进行半精度(FP16)计算,减少内存使用量,在提高速度的同时,将对精度的影响降至最低。 |
| device | str | None | 指定验证设备 (cpu, cuda:0等)。可灵活利用 CPU 或 GPU 资源。 |
| dnn | bool | False | 如果 True它使用 OpenCV DNN 模块进行ONNX 模型推断,为PyTorch 推断方法提供了一种替代方法。 |
| plots | bool | False | 当设置为 True此外,它还能生成并保存预测结果与地面实况的对比图,以便对模型的性能进行可视化评估。 |
| rect | bool | False | 如果 True该软件使用矩形推理进行批处理,减少了填充,可能会提高速度和效率。 |
| split | str | val | 确定用于验证的数据集分割 (val, test或 train).可灵活选择数据段进行性能评估。 |
7.3 预测模型(Prediction)
7.3.1 预测的三种方式
同样的验证模型也支持上面的三种方式来操作。
-
命令行
yolo task=detect mode=predict model=best.pt source=****.jpg device=0 -
指定cfg
yolo cfg=ultralytics/cfg/default.yaml -
python代码
在项目根目录下面新建predict.py文件,笔者比较喜欢实用此种方式,但是推荐大家使用cfg的方式。
# 导入ultralytics的YOLO库 from ultralytics import YOLO # 加载模型 model = YOLO('runs/detect/train/weights/best.pt') # 加载自定义的训练模型 if __name__ == '__main__': results = model.predict( r" D:\python-project\ultralytics-main\ultralytics\datasets\original-license-plates\test\images\b9f5b9acf1777acf_jpg.rf.b92969d5c3738ece6a84dcd2d0ea3ce0.jpg", save=True, imgsz=320, conf=0.5,device=0,iou=0.5)
7.3.4 预测结果
当我们使用save=true,训练后的结果保存在runs\detect\predict目录下。

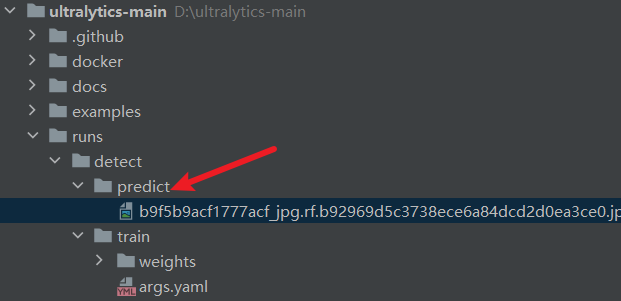
7.3.3 预测参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| source | str | ‘ultralytics/assets’ | 指定推理的数据源。可以是图像路径、视频文件、目录、URL 或用于实时馈送的设备 ID。支持多种格式和来源,可灵活应用于不同类型的输入。 |
| conf | float | 0.25 | 设置检测的最小置信度阈值。如果检测到的对象置信度低于此阈值,则将不予考虑。调整该值有助于减少误报。 |
| iou | float | 0.7 | 非最大抑制 (NMS) 的交叉重叠 (IoU) 阈值。较低的数值可以消除重叠的方框,从而减少检测次数,这对减少重复检测非常有用。 |
| imgsz | int or tuple | 640 | 定义用于推理的图像大小。可以是一个整数 640 或一个(高、宽)元组。适当调整大小可以提高检测精度和处理速度。 |
| half | bool | False | 启用半精度(FP16)推理,可加快支持的 GPU 上的模型推理速度,同时将对精度的影响降至最低。 |
| device | str | None | 指定用于推理的设备(例如:…)、 cpu, cuda:0 或 0).允许用户选择 CPU、特定 GPU 或其他计算设备来执行模型。 |
| max_det | int | 300 | 每幅图像允许的最大检测次数。限制模型在单次推理中可检测到的物体总数,防止在密集场景中产生过多输出。 |
| vid_stride | int | 1 | 视频输入的帧间距。允许跳过视频中的帧,以加快处理速度,但会牺牲时间分辨率。值为 1 时处理每一帧,值越大跳帧越多。 |
| stream_buffer | bool | False | 确定在处理视频流时是否对所有帧进行缓冲 (True),或者模型是否应该返回最近的帧 (False).适用于实时应用。 |
| visualize | bool | False | 在推理过程中激活模型特征的可视化,从而深入了解模型 "看到 "了什么。这对调试和模型解释非常有用。 |
| augment | bool | False | 可对预测进行测试时间增强(TTA),从而在牺牲推理速度的情况下提高检测的鲁棒性。 |
| agnostic_nms | bool | False | 启用与类别无关的非最大抑制 (NMS),可合并不同类别的重叠方框。这在多类检测场景中非常有用,因为在这种场景中,类的重叠很常见。 |
| classes | list[int] | None | 根据一组类别 ID 过滤预测结果。只返回属于指定类别的检测结果。在多类检测任务中,该功能有助于集中检测相关对象。 |
| retina_masks | bool | False | 如果模型中存在高分辨率的分割掩膜,则使用高分辨率的分割掩膜。这可以提高分割任务的掩膜质量,提供更精细的细节。 |
| embed | list[int] | None | 指定从中提取特征向量或嵌入的层。这对聚类或相似性搜索等下游任务非常有用。 |
7.4 导出模型(Exporting)
导出模型是将训练好的模型转换为其他格式,便于部署到不同的平台或设备上。
7.4.1 导出的三种方式
同样的验证模型也支持上面的三种方式来操作。
-
命令行
yolo export model=YOLO11n.pt format=onnx # export official model yolo export model=path/to/best.pt format=onnx # export custom trained model -
指定cfg
yolo cfg=ultralytics/cfg/default.yaml -
python代码
在项目根目录下面新建predict.py文件,笔者比较喜欢实用此种方式,但是推荐大家使用cfg的方式。
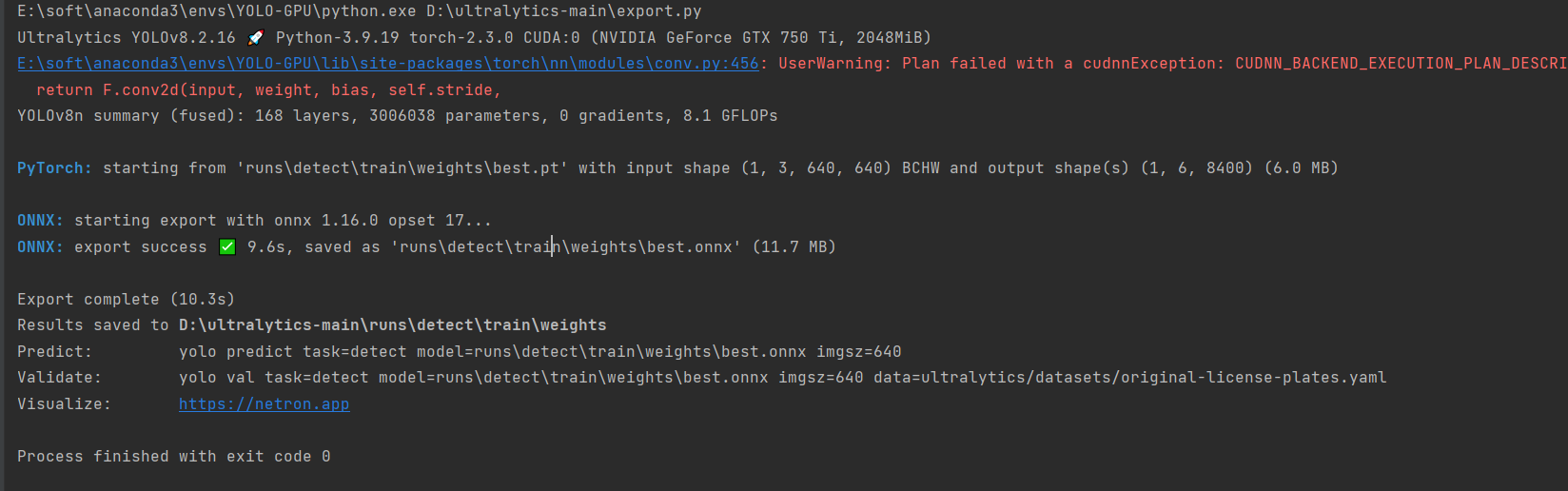
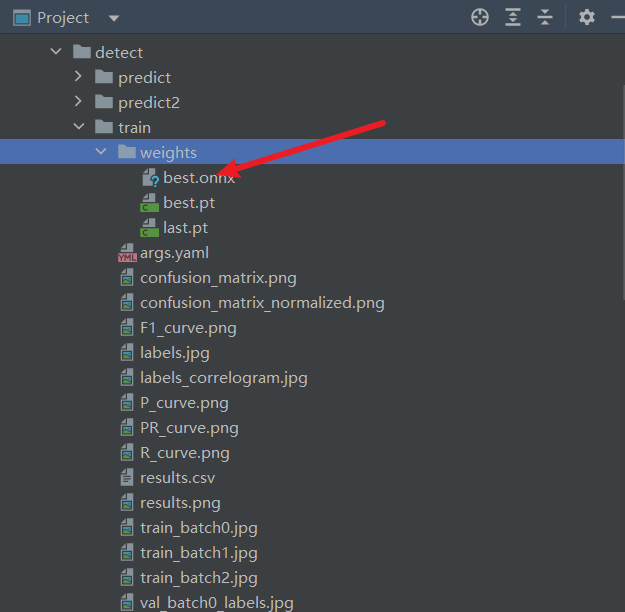
# 导入ultralytics的YOLO库 from ultralytics import YOLO # 加载模型 model = YOLO('runs/detect/train/weights/best.pt') # 加载自定义的训练模型 # 如果当前脚本作为主程序运行 if __name__ == '__main__': model.export(format='onnx')
7.4.2 导出结果
训练后的结果保存在runs/detect/train/weights目录下。
7.3.3 导出参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| format | str | ‘torchscript’ | 导出模型的目标格式,例如 ‘onnx’, ‘torchscript’, 'tensorflow’或其他,定义与各种部署环境的兼容性。 |
| imgsz | int 或 tuple | 640 | 模型输入所需的图像尺寸。对于正方形图像,可以是一个整数,或者是一个元组 (height, width) 了解具体尺寸。 |
| keras | bool | False | 启用导出为 Keras 格式的TensorFlow SavedModel ,提供与TensorFlow serving 和 API 的兼容性。 |
| optimize | bool | False | 在导出到TorchScript 时,应用针对移动设备的优化,可能会减小模型大小并提高性能。 |
| half | bool | False | 启用 FP16(半精度)量化,在支持的硬件上减小模型大小并可能加快推理速度。 |
| int8 | bool | False | 激活 INT8 量化,进一步压缩模型并加快推理速度,同时将精度损失降至最低,主要用于边缘设备。 |
| dynamic | bool | False | 允许ONNX 和TensorRT 导出动态输入尺寸,提高了处理不同图像尺寸的灵活性。 |
| simplify | bool | False | 简化了ONNX 导出的模型图,可能会提高性能和兼容性。 |
| opset | int | None | 指定ONNX opset 版本,以便与不同的ONNX 解析器和运行时兼容。如果未设置,则使用最新的支持版本。 |
| workspace | float | 4.0 | 为TensorRT 优化设置最大工作区大小(GiB),以平衡内存使用和性能。 |
| nms | bool | False | 在CoreML 导出中添加非最大值抑制 (NMS),这对精确高效的检测后处理至关重要。 |
| batch | int | 1 | 指定导出模型的批量推理大小,或导出模型将同时处理的图像的最大数量。 predict 模式。 |