一、. 数组名的理解
int arr[5] = { 0,1,2,3,4 };
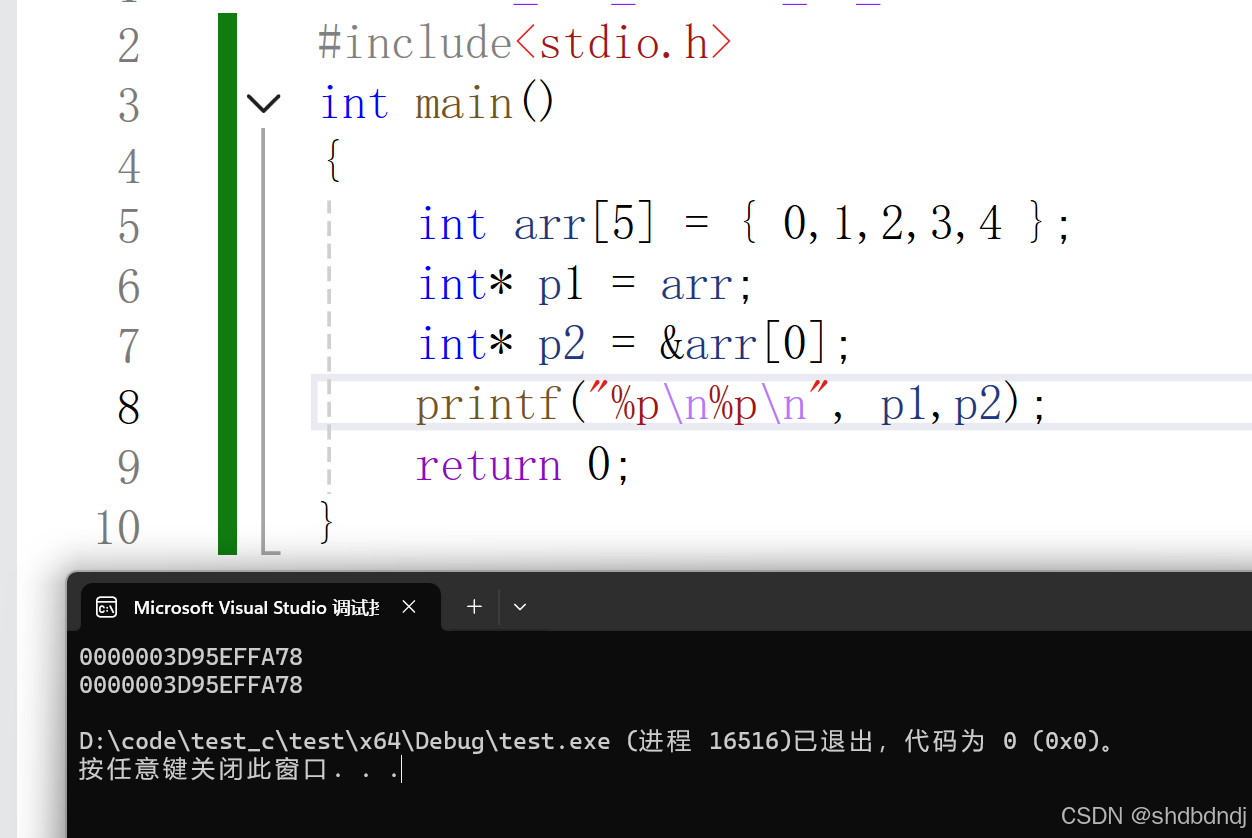
int* p = &arr[0];在之前我们知道要取一个数组的首元素地址就可以使用&arr[0],但其实数组名本身就是地址,而且是数组首元素的地址。在下图中我们就通过测试看出,结果确实如此。
可是我们再来看下图的结果,我们发现当我们对数组名使用sizeof函数是会发现不同之处,如果数组名就是地址,那么再x64环境下应该就是八个字节,但是却输出了20,这是为什么呢?



#include <stdio.h>
int main()
{
int arr[5] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
scanf("%d", arr + i);
}
for (int i = 0; i < sz; i++)
{
printf("%d ", *(arr + i));
}
return 0;
}在scanf()中arr是arr数组首元素的地址。因为数组元素的地址是递增的,所以随着这个地址的增加,出现的地址就变成了数组中其他元素的地址了,也就是arr+i相当于&arr[i]。在打印输出时,也是相同的原理,依次取出每个元素的地址并解引用即可,也就是*(arr+i)相当于arr[i]。
三、一维数组传参的本质
#include <stdio.h>
void test(int arr[5])
{
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("%d ", sz1);
}
int main()
{
int arr[5] = { 0 };
int sz2 = sizeof(arr) / sizeof(arr[0]);
test(arr);
printf("%d ", sz2);
return 0;
}
当我们把数组传给函数去实现求其中的元素数时,我们会发现得到的结果并不是我们想要的结果。这是为什么呢?我们接下来分析一下这段代码并想一想一维数组传参的本质。在一维数组传参中我们传的其实是这个数组的首元素的地址,所以在test()中得到的是arr这个数组中第一个元素的地址,在x64环境下它就占八个字节。而在它后面的arr[0]就像前面说的一样,相当于*arr,也就是arr数组的首元素的值,因为它的类型是int,所以占四个字节。所以一维数组传参的本质就是传递的是指针,也就解决不了求元素数的问题。当然在传参时我们也可以写成指针的形式。
#include <stdio.h>
void test(int* arr)
{
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("sz1=%d ", sz1);
}
int main()
{
int arr[5] = { 0 };
int sz2 = sizeof(arr) / sizeof(arr[0]);
test(arr);
printf("sz2=%d ", sz2);
return 0;
}四、冒泡排序
其实冒泡排序的核心就是两两相邻元素比较。如果我们要将一个数组中的数从小到大排列就可以使用冒泡排序。
#include <stdio.h>
void bubble_sort(int* arr,int sz)
{
int temp;
for (int j = 1; j < sz; j++)
{
for (int i = 1; i <= sz - j; i++)
{
if (*(arr + i - 1) > *(arr + i))
{
temp = *(arr + i - 1);
*(arr + i - 1) = *(arr + i);
*(arr + i) = temp;
}
}
}
}
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
scanf("%d",&arr[i]);
}
bubble_sort(arr,sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}当然如果该数列的元素如果本来就是正序排列的,那么这样做就会很浪费效率,我们可以对程序再进行优化一下。
#include <stdio.h>
void bubble_sort(int* arr,int sz)
{
int temp;
for (int j = 1; j < sz; j++)
{
int flag = 1;
for (int i = 1; i <= sz - j; i++)
{
if (*(arr + i - 1) > *(arr + i))
{
flag = 0;
temp = *(arr + i - 1);
*(arr + i - 1) = *(arr + i);
*(arr + i) = temp;
}
}
if (flag)
break;
}
}
int main()
{
int arr[10] = { 0 };
int sz = sizeof(arr) / sizeof(arr[0]);
for (int i = 0; i < sz; i++)
{
scanf("%d",&arr[i]);
}
bubble_sort(arr,sz);
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}在程序中加入了flag变量,如果在第一次排序中没有改变排序,也就是这个数组的数本来就为正序,就会跳出这个循环。
五、二级指针
我们知道指针变量也是变量,那么它也应该有地址,什么能储存它呢,就是二级指针。
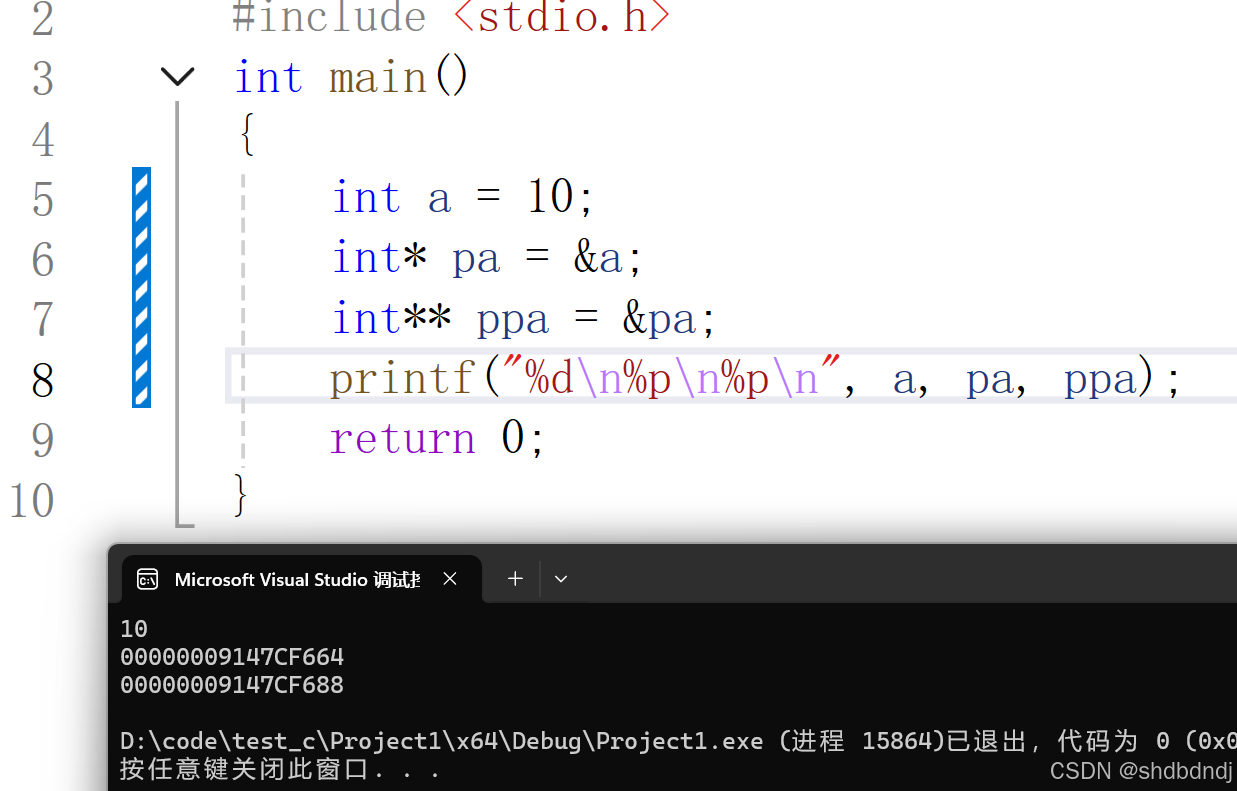
如图所示,pa是a的指针变量,我们对pa进行取地址,也就是我们刚才说的二级指针。
从名字中我们就能看出这是存放指针的数组。指针数组的每个元素都是用来存放地址(指针)的。

接下来,我们用指针数组模拟二维数组。
#include <stdio.h>
int main()
{
int arr1[4] = { 1,2,3,4 };
int arr2[4] = { 2,3,4,5 };
int arr3[4] = { 3,4,5,6 };
int* arr[3] = {arr1,arr2,arr3};
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}
return 0;
}
我们能看出来打印出的样子和二维数组一模一样。这是怎么实现呢?arr指针数组中存放的是数组名,也就是每行首元素的地址。我们打印时使用的arr[i][j]其实是通过arr[i],也就是arr+i找到是哪个小数组;再通过arr[i][j],就是*(arr[n]+j),也就是*(*(arr+i)+j)就能找出该行的每个数了。上述的代码模拟出二维数组的效果,实际上并非完全是二维数组,因为每一行并非是连续的。