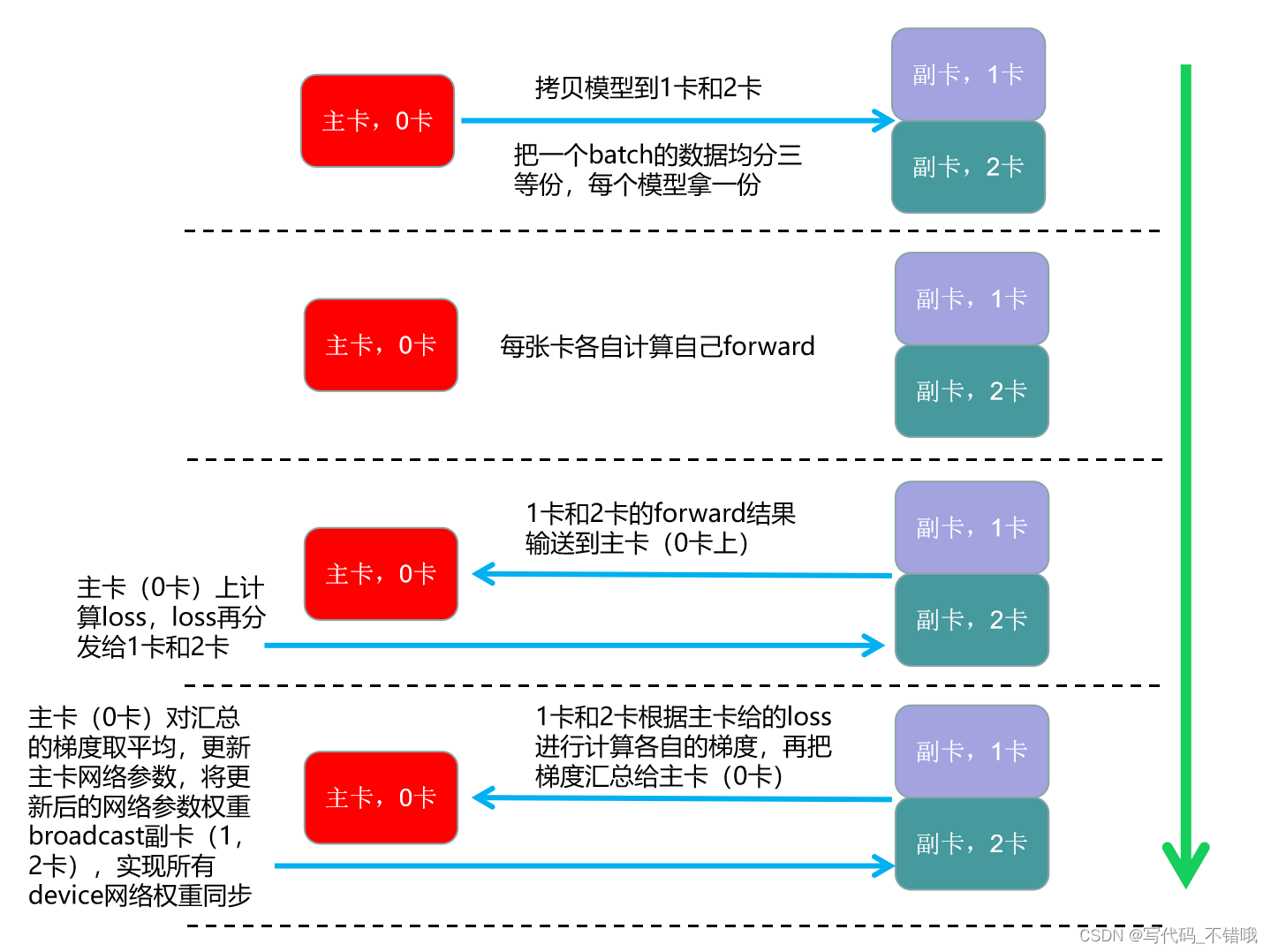
下图是DataParallel运行示意图,其是:单进程,多线程
下图是Dataparallel官网图片
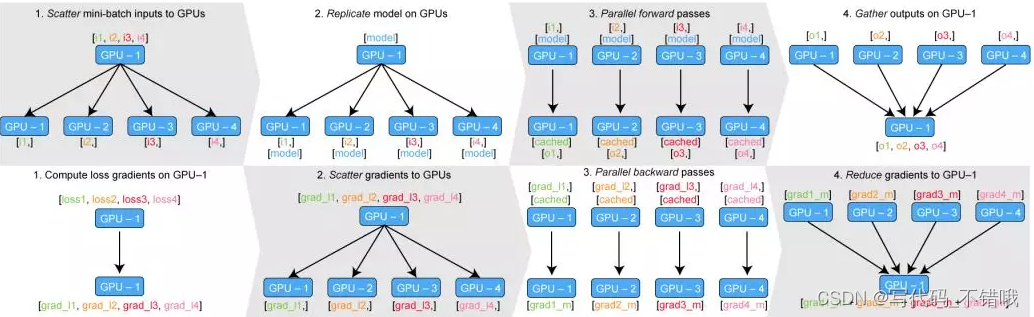
补充:
GitHub - jia-zhuang/pytorch-multi-gpu-training: 整理 pytorch 单机多 GPU 训练方法与原理 这个里面有一句话讲解需要知道:“但master进程可以往下运行完成模型的下载和读入内存,�但在第二个if语句时遇到barrier,那会不会被barrier住呢?答案是不会,因为master进程和slave进程集合在一起了(barrier),barrier会被解除,这样大家都往下执行。” 这个意思就是当 所有进程都一起到了barrier中,那么barrier会自动释放所有进程,这就是这个barrier的神奇操作之处。

原先我也不懂,不理解的点是,当master进入第二个barrier后,不就barrier了吗,那进程还怎么继续执行,现在知道了,当所有进程都进入到barrier后,会自动释放,就是barrier自动解除。如下图实验:
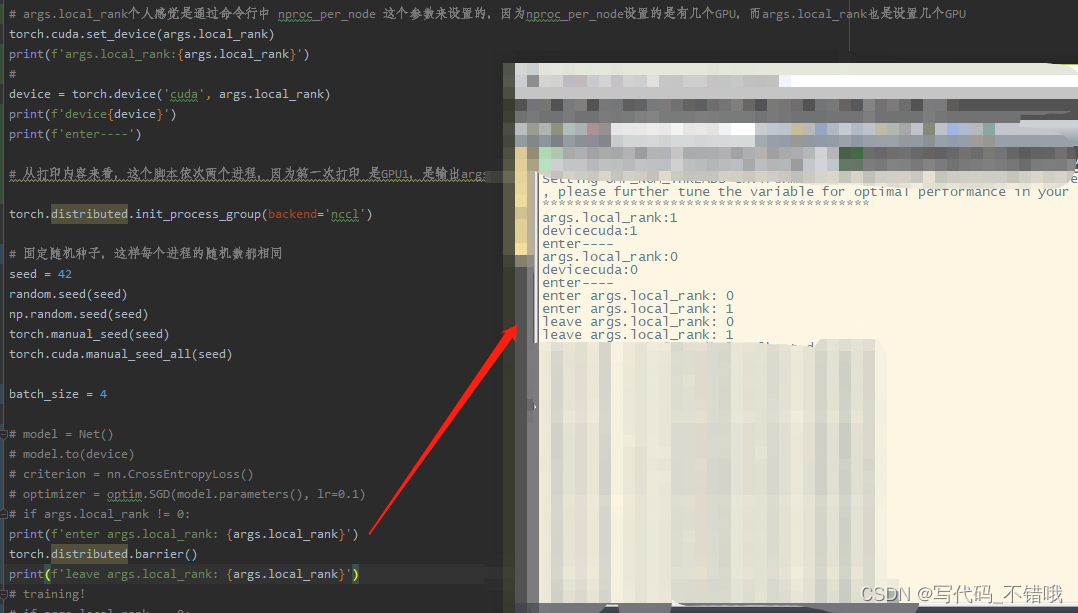
但是上图有个地方有点玄学,就是1先进来的,但是在enter那边是0先enter,这打印的两者之间就是通信设为nccl和随机数初始化,而且是两个独立进程,怎么会这样?当然每次运行也不都是这样,有随机性,不过这里面应该是有什么在影响。
关于distributed data parallel,个人认为,初始化是需要设置以下代码:
# args.local_rank个人感觉是通过命令行中 nproc_per_node 这个参数来设置的,因为nproc_per_node设置的是有几个GPU,而args.local_rank也是设置几个GPU
torch.cuda.set_device(args.local_rank)
print(f'args.local_rank:{args.local_rank}')
#
device = torch.device('cuda', args.local_rank)
print(f'device{device}')
print(f'enter----')
# 两个GPU打印如下内容:
# args.local_rank:1
# devicecuda:1
# enter----
# args.local_rank:0
# devicecuda:0
# enter----
# 从打印内容来看,这个脚本依次两个进程,因为第一次打印 是GPU1,是输出args.local_rank:1、devicecuda:1、enter----,接着输出GPU0,args.local_rank:0、devicecuda:0、enter----
torch.distributed.init_process_group(backend='nccl')
# 固定随机种子,这样每个进程的随机数都相同
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
batch_size = 4
model = Net()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# training!
if args.local_rank == 0:
tb_writer = SummaryWriter(comment='ddp-3')
# 以下三行就是分布式训练必须要的,第一行构建一个分布式采样器,第二行把数据和分布式采样器构建到DataLoader中,第三行把模型构建到分布式数据并行中
train_sampler = DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
完整代码训练代码:
import os
# os.environ["CUDA_VISIBLE_DEVICES"]="0,1"
import argparse
import random
import numpy as np
import torch
import torch.optim as optim
import torch.nn as nn
from torch.utils.data.distributed import DistributedSampler
from torch.utils.tensorboard import SummaryWriter
from model import Net
from data import train_dataset, test_dataset
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", type=int, default=-1)
args = parser.parse_args()
# args.local_rank个人感觉是通过命令行中 nproc_per_node 这个参数来设置的,因为nproc_per_node设置的是有几个GPU,而args.local_rank也是设置几个GPU
torch.cuda.set_device(args.local_rank)
print(f'args.local_rank:{args.local_rank}')
#
device = torch.device('cuda', args.local_rank)
print(f'device{device}')
print(f'enter----')
# 两个GPU打印如下内容:
# args.local_rank:1
# devicecuda:1
# enter----
# args.local_rank:0
# devicecuda:0
# enter----
# 从打印内容来看,这个脚本依次两个进程,因为第一次打印 是GPU1,是输出args.local_rank:1、devicecuda:1、enter----,接着输出GPU0,args.local_rank:0、devicecuda:0、enter----
torch.distributed.init_process_group(backend='nccl')
# 固定随机种子,这样每个进程的随机数都相同
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
batch_size = 4
model = Net()
model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
# training!
if args.local_rank == 0:
tb_writer = SummaryWriter(comment='ddp-3')
# 以下三行就是分布式训练必须要的,第一行构建一个分布式采样器,第二行把数据和分布式采样器构建到DataLoader中,第三行把模型构建到分布式数据并行中
train_sampler = DistributedSampler(train_dataset)
train_loader = torch.utils.data.DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True)
for i, (inputs, labels) in enumerate(train_loader):
# forward
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
# log
if args.local_rank == 0 and i % 5 == 0:
tb_writer.add_scalar('loss', loss.item(), i)
if args.local_rank == 0:
print(f'close')
tb_writer.close()
完整能跑的代码是在参考2,不过我是把model.py里面下面这段代码注释了才运行的起来的:
以下是我注释了,原代码是放开的
# x = (x,) # if labels is not None: # print(f'label is not None') # loss_fct = nn.CrossEntropyLoss() # loss = loss_fct(x[0], labels) # x = (loss,) + x
参考:
1.
2.GitHub - jia-zhuang/pytorch-multi-gpu-training: 整理 pytorch 单机多 GPU 训练方法与原理
3.Pytorch 多GPU训练-单运算节点-All you need - walter_xh - 博客园 这个博主讲解的也很详细(Pytorch多GPU训练本质上是数据并行,每个GPU上拥有整个模型的参数,将一个batch的数据均分成N份,每个GPU处理一份数据,然后将每个GPU上的梯度进行整合得到整个batch的梯度,用整合后的梯度更新所有GPU上的参数,完成一次迭代。)
4.关于人工智能:PyTorch之分布式操作Barrier - 乐趣区 这个里面的参考资料的博客写的蛮好的
5.GitHub - jia-zhuang/pytorch-multi-gpu-training: 整理 pytorch 单机多 GPU 训练方法与原理
6.walter_xh - 博客园 这个博主的博客还不错