前言
在开发过程中要求对 PDF 类型的发票提供 预览 和 下载 功能,**PDF** 类型文件的来源又包括 H5 移动端 和 **PC 端**,而针对这两个不同端的处理会有些许不同,下文会有所提及。
针对 PDF 预览 的文章不在少数,但似乎都没有提及可能遇到的问题,或是提供对应的具体需求场景下如何选择,因此,本文的核心就是结合实际需求场景下,看看目前各种实现方案到底哪一个更适合,当然希望大家可以在评论区对文中的内容进行斧正,或是提供更优质的方案。
基本要求:
-
支持
pdf 文件内容的 完整预览 -
多页 pdf 文件支持分页查看 -
PC 端和移动端都需支持 下载 和 预览
产品要求:
-
PC 端 的预览要支持在 当前页 进行预览
-
pdf 文件预览时的字体要 和 实际文件的 字体保证一致性

PDF 预览
先抛开上面的各种要求,咱们先总结下目前实现 PDF 预览的几种常用方式:
-
借助各种类库,基于代码实现预览,如基于 **`pdfjs-dist`**[1] 的包
-
直接基于各个浏览器内置的
PDF预览插件,如<iframe src="xxx">、<embed src="xxx" > -
服务端将
PDF文件转换成图片
接下来分别看看以上方案如何实现,以及是否符合上述提供的要求!
<embed> / <iframe> 实现预览
<embed> 标签
<embed> 元素 将外部内容嵌入文档中的指定位置,此内容由 外部应用程序 或 其他交互式内容源(如 浏览器插件)提供。
说简单点,就是使用 <embed> 来展示的资源是完全交由它所在的环境提供的展示功能,即如果当前的应用环境支持这个资源的展示那么就可以正常展示,如果不支持那就无法展示。
使用起来也是非常简单:
<embed
type="application/pdf"
:src="pdfUrl"
width="800"
height="600" />
复制代码
多数现代浏览器已经弃用并取消了对浏览器插件的支持,现在已经不建议使用
<embed>标签,但可以使用<img>、<iframe>、<video>、<audio>等标签代替。
<iframe> 标签
基于 <iframe> 的方式和以上差不多,整体效果也一致,这里这就不在额外展示:
<iframe
:src="pdfUrl"
width="800"
height="600" />
复制代码
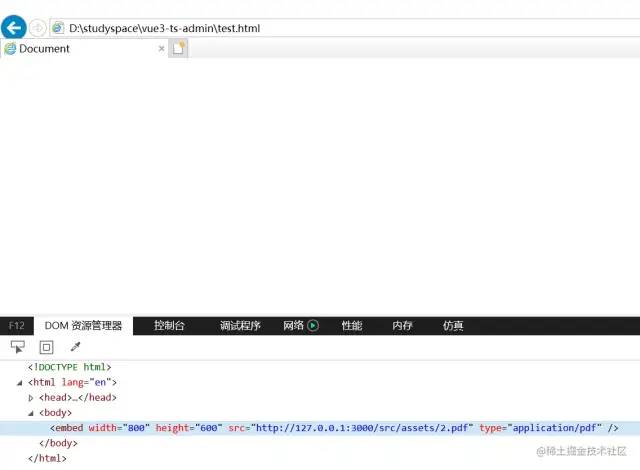
值得注意的是,即便使用的是 <iframe> 但实际展开其内层结构后你会发现:

其内部还是 <embed> 标签?这是怎么回事,不是说最好不建议使用 <embed> 吗?
首先来在 **`caniuse`**[2] 查看兼容情况,如下:

我们再找一个不支持 <embed> 的浏览器,比如 IE,来试试效果:
换成 <iframe> 试试,如下:

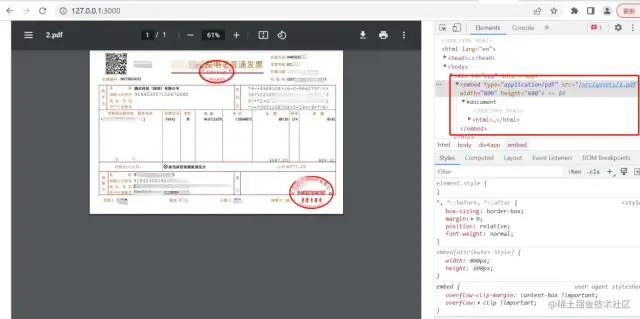
显然,<embed> 在不兼容的环境直接无法显示,而 <iframe> 是能够正常识别的,只不过 <iframe> 加载的资源无法被 IE 浏览器处理,即本质原因是 IE 浏览器根本就不支持对类似 PDF 等文件的预览,比如当尝试直接在地址栏中输入 http://127.0.0.1:3000/src/assets/2.pdf 时会得到:

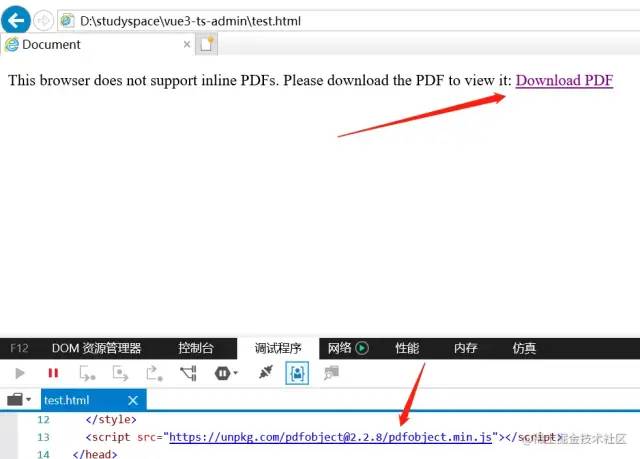
因此,通常情况下当浏览器不支持内联 PDF 时,应该提供一个 PDF 的回退链接,即以下载的方式来实现,而这就是 **pdfobject**[3] 做的事情,实际上它的源码内容比较简单,核心就是 PDFObject 会检测浏览器对内联/嵌入 PDF 的支持,如果支持嵌入,则嵌入 PDF,如果浏览器不支持嵌入,则不会嵌入 PDF,并提供一个指向 PDF 的回退链接,例如在 IE 中的表现:
事实上,这其实只是帮我们少写了一些兼容性的代码而已,也不一定符合大部分人的场景,在这里提到只是因为其与 <embed> 之间存在的联系。
vue3-pdfjs 实现预览
为什么不直接使用 pdfjs-dist?
**pdf.js**[4] 几个明显的可吐槽的点:
-
包名称不统一,
npm上的包名叫pdfjs-dist,然而在Readme中自己又称其为pdf.js -
没有清晰的文档作为指引,只能通过其仓库中的
examples目录的内容作为参考 -
官方示例不够友好,例如没有提供
vue/react等相关的示例 -
直接使用需要引入很多文档没有指明的内容
-
有时展示的
pdf内容文字模糊或缺少部分等 -
...
因此,既然已经有基于 vue/react 封装好的包,这里就直接用来作为演示。
具体使用
安装和使用过程可参考 **`vue3-pdfjs`**[5] ,具体 Vue3 示例代码如下:
<script setup lang="ts">
import { onMounted, ref } from 'vue'
import { VuePdf, createLoadingTask } from 'vue3-pdfjs/esm'
import type { VuePdfPropsType } from 'vue3-pdfjs/components/vue-pdf/vue-pdf-props' // Prop type definitions can also be imported
import type { PDFDocumentProxy } from 'pdfjs-dist/types/src/display/api'
import pdfUrl from './assets/You-Dont-Know-JS.pdf'
const pdfSrc = ref<VuePdfPropsType['src']>(pdfUrl)
const numOfPages = ref(0)
onMounted(() => {
const loadingTask = createLoadingTask(pdfSrc.value)
loadingTask.promise.then((pdf: PDFDocumentProxy) => {
numOfPages.value = pdf.numPages
})
})
</script>
<template>
<VuePdf v-for="page in numOfPages" :key="page" :src="pdfSrc" :page="page" />
</template>
<style>
@import '@/assets/base.css';
</style>
复制代码
效果如下:

存在问题
看上去加载正常的 pdf 文档 似乎没啥大问题,来试试加载 pdf 发票 看看,但由于实际发票敏感信息较多,这里就不贴出原本的发票内容,直接来看预览后的发票内容:
-
显然整体发票的 内容缺失得非常多,虽然某些发票大部分能够展示,但如 发票抬头 和 印章 部分可能无法正常显示等
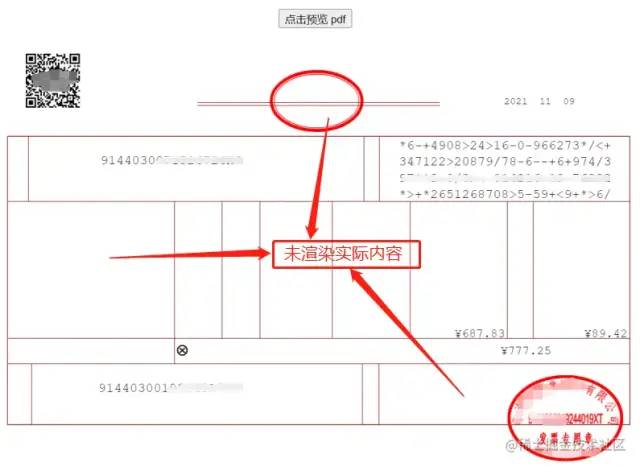
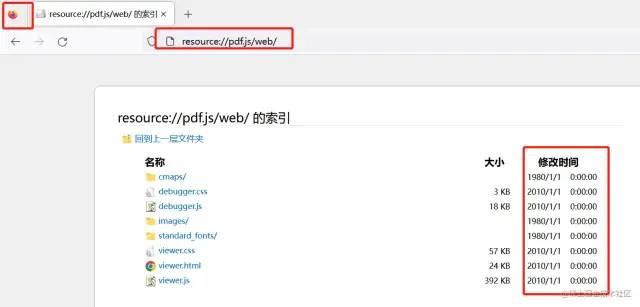
【注意】无法显示完整的内容是因为
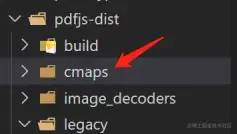
pdf.js是需要一些字体库的支持,如果原 PDF 文件中部分字体没有匹配到字体库将无法在pdf.js中显示,而字体库存放在cmaps文件夹下
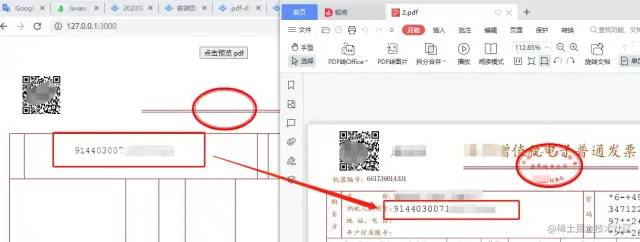
-
另外,预览的字体 和 实际的字体 是 不一致 的,而由于发票的特殊性,对字体的一致性是有较大的要求,毕竟如果同一张发票字体不一致会缺乏 规范性 和 合法性(~~
被要求字体一致时的说法~~)
常见的解决方案: **解决 pdf.js 无法完全显示 pdf 文件内容的问题**[6],实际上还是根据执行环境的错误信息进行分析,需要强行修改源码内容。
Mozilla Firefox(火狐浏览器)
Mozilla Firefox 内置的 PDF 阅读器实际就是 pdf.js,你可以直接用火狐浏览器预览一下 pdf 文件,如下:
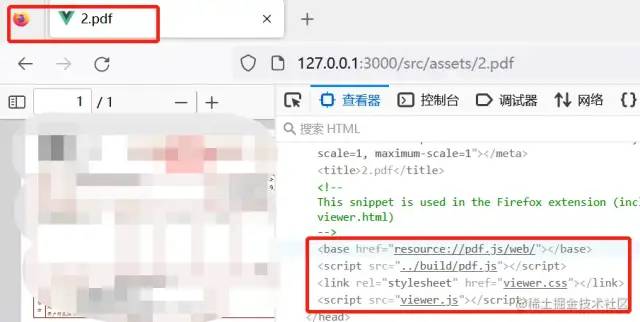
并且大多基于 pdf.js 二次封装的库 vue-pdf、vue3-pdfjs 等在预览 pdf 文件的发票时通常无法显示完整内容,需要或多或少的涉及对源码的更改,而在 Firefox 中内置的 pdf.js 却能够完整的显示对应的 pdf 文件的内容。
PDF 转 图片 实现预览
这种方式应该不用多说了,核心是服务端在响应 pdf 文件时,先转换成图片类型再返回,前端直接展示具体图片内容即可。
具体实现
下面通过用 node 来模拟:
const pdf = require('pdf-poppler')
const path = require('path')
const Koa = require('koa')
const koaStatic = require('koa-static')
const cors = require('koa-cors')
const app = new Koa()
// 跨域
app.use(cors())
// 静态资源
app.use(koaStatic('./server'))
function getFileName(filePath) {
return filePath
.split('/')
.pop()
.replace(/\.[^/.]+$/, '')
}
function pdf2png(filePath) {
// 获取文件名
const fileName = getFileName(filePath);
const dir = path.dirname(filePath);
// 配置参数
const options = {
format: 'png',
out_dir: dir,
out_prefix: fileName,
page: null,
}
// pdf 转换 png
return pdf
.convert(filePath, options)
.then((res) => {
console.log('Successfully converted !')
return `http://127.0.0.1:4000${dir.replace('./server','')}/${fileName}-1.png`
})
.catch((error) => {
console.error(error)
})
}
// 响应
app.use(async (ctx) => {
if(ctx.path.endsWith('/getPdf')){
const url = await pdf2png('./server/pdf/2.pdf')
ctx.body = { url }
}else{
ctx.body = 'hello world!'
}
})
app.listen(4000)
复制代码
避免踩一些坑
坑一:不推荐 pdf-image
在实现服务端将 pdf 文件转换成图片时需要依赖到一些第三方包,一开始使用了 **`pdf-image`**[7] 这个包,但在实际转换时发生较多的异常错误,顺着错误查看源码后发现其内部需要依赖一些额外的工具,因为其中需要使用 pdfinfo xxx 相关命令,并且其对应的 `issue`[8] 上也存在着一些类似问题,但都试了试最后还是没有成功!
因此,更推荐使用 `pdf-poppler`[9] 其中附带了一个 pdftocairo 的程序可以实现 pdf 到 图片 的转换能力,不过它目前版本支持 Windows 和 Mac OS,如下:

坑二:path.basename not a function
在上述的代码内容中需要获取文件的名称,实际上我们可以简单直接的使用 Node Api 中 path.basename(path[, suffix]) 来达到目的:
但是在程序运行时发生了如下 异常,对应的 代码内容 和 运行结果 如下:
// 配置参数
const options = {
format: 'png',
out_dir: dir,
out_prefix: path.baseName(filePath, path.extname(filePath)), // 发生异常
page: null,
}
复制代码

这个暂时没有找到是什么原因,只能自己简单实现了一个 getFileName 方法用于获取文件的名称。
报错原因:太依赖编辑器的自动提示,将 basename 输出成 baseName ,没错就是 n 和 N 的区别.
坑三:细节
上述内容通过 koa 启动模拟业务服务,由于 业务服务(http://127.0.0.1:4000) 和 应用服务 (http://127.0.0.1:3000) 间的端口不一致,因此会产生 跨域,此时可以通过 koa-cors 来解决,值得注意的是有时候的那个业务服务器重启时 koa-cors 可能不起作用。
由于响应的内容直接在 koa 通用中间件中返回,因此,如果你需要支持业务服务提供 静态资源 的访问能力,就可以通过 koa-static 来实现,值得注意的是,当你通过 koa-static 指定静态文件资源后,如 **app.use(koaStatic('./static'))**,此时如果你直接通过 http://127.0.0.1:4000/static/pdf/xxx.png 时,那么会得到 404 Not Found 的错误,原因在于 koa-static 是直接把 /static/ 设置成了 根路径,因此正确的访问路径为:http://127.0.0.1:4000/pdf/xxx.png 。
效果演示
发票内容不方便展示这里就不直接展示了,只需要关注生成的图片和路径即可:
PDF 下载
这里的下载实际不仅指 pdf 的下载,而是客户端方面所能支持的下载方式,最常见的如下几种:
-
a 标签,例如
<a href="xxxx" download="xxx">下载</a> -
location.href,例如
window.location.href = xxx -
window.open,例如
window.open(xxx) -
Content-disposition,例如
Content-disposition:attachment;filename="xxx"
<a> 实现下载
<a> 的 download 属性用于指示浏览器 下载 href 指定的 URL,而不是导航到该资源,通常会提示用户将其保存为本地文件,如果 download 属性有指定内容,这个值就会在下载保存过程中作为 预填充的文件名,主要是因为如下原因:
-
这个值可能会通过
JavaScript进行动态修改 -
或者
Content-Disposition中指定的download属性优先级高于a.download
这种应该是大家最熟悉的方式了,但熟悉归熟悉,还有一些值得注意的点:
-
download属性只适用于 同源 URL-
同源 URL 会进行 下载 操作
-
非同源 URL 会进行 导航 操作
-
非同源的资源 仍需要进行下载,那么可以将其转换为 **`blob: URL`**[10] 和 **`data: URL`**[11] 形式
-
-
若 HTTP 响应头中的 **`Content-Disposition`**[12] 属性中指定了一个不同的文件名,那么会优先使用
Content-Disposition中的内容 -
HTTP 若 HTTP 响应头中的 **`Content-Disposition`**[13] 被设置为
Content-Disposition='inline',那么在 Firefox 中会优先使用Content-Disposition的download属性
静态方式:
<a href="http://127.0.0.1:4000/pdf/2-1.png" download="2.pdf">下载</a>
复制代码
动态方式:
function download(url, filename){
const a = document.createElement("a"); // 创建 a 标签
a.href = url; // 下载路径
a.download = filename; // 下载属性,文件名
a.style.display = "none"; // 不可见
document.body.appendChild(a); // 挂载
a.click(); // 触发点击事件
document.body.removeChild(a); // 移除
}
复制代码
Blob 方式
if (reqConf.responseType == 'blob') {
// 返回文件名
let contentDisposition = config.headers['content-disposition'];
if (!contentDisposition) {
contentDisposition = `;filename=${decodeURI(config.headers.filename)}`;
}
const fileName = window.decodeURI(contentDisposition.split(`filename=`)[1]);
// 文件类型
const suffix = fileName.split('.')[1];
// 创建 blob 对象
const blob = new Blob([config.data], {
type: FileType[suffix],
});
const link = document.createElement('a');
link.style.display = 'none';
link.href = URL.createObjectURL(blob); // 创建 url 对象
link.download = fileName; // 下载后文件名
document.body.appendChild(link);
link.click();
document.body.removeChild(link); // 移除隐藏的 a 标签
URL.revokeObjectURL(link.href); // 销毁 url 对象
}
复制代码
Content-disposition 和 location.href/window.open 实现下载
这看似是三种下载方式,但实际上就是一种,而且还是以 Content-disposition 为准。
Content-Disposition 响应头 指示回复的内容该以何种形式展示,是以 内联 的形式(即网页或页面的一部分)展示,还是以 附件 的形式 下载 并保存到本地,如下:
inline: 是 默认值,表示回复中的消息体会以页面的一部分或者整个页面的形式展示Content-Disposition: inline 复制代码attachment: 设置为此值意味着消息体应该被下载到本地,大多数浏览器会呈现一个 "保存为" 的对话框,并将filename的值预填为下载后的文件名Content-Disposition: attachment; filename="filename.jpg" 复制代码
因此,基于 location.href='xxx' 和 window.open(xxx) 的方式能实现下载就是基于 Content-Disposition: attachment; filename="filename.jpg" 的形式,又或者说是触发了浏览器本身的下载行为,满足了这个条件,无论是通过 a 标签跳转、location.href 导航、window.open 打开新页面、直接在地址栏上输入 URL 等都可以实现下载。
H5 移动端的下载
H5 移动端针对于 预览 操作而言基于以上的方式都是可以实现,但是 下载 操作可就不同了,因为这是要区分场景:
-
基于 手机浏览器
-
基于 微信内置浏览器
基于 手机浏览器 的下载方式和上述提到的内容大致上也是一致的,本质上只要所在的客户端支持下载那就没有问题,然而在 微信内置浏览器 中你使用常规的下载方式可能达不到预期:
-
在
Android中使用常规的下载方式,通常会弹出对话框,询问你是否需要唤醒 手机浏览器 来实现对应资源的下载,部分机型却不会 -
在
IOS中以上方式都 无法实现下载,因此通常情况下会打开一个新的webview来提供预览,部分机型在新的页面中支持 长按屏幕 的方式进行保存操作,但并不是所有机型都支持
本质原因是在 微信内置浏览器 中屏蔽任何的 下载链接,如 APP 的下载链接、普通文件 的下载链接 等等。
H5 移动端的下载还能怎么做?
由于这是 微信内置浏览器 环境对下载功能的屏蔽,因此 不用再考虑(~~想都不敢想~~)基于 微信内置浏览器 来实现下载功能,转而应该考虑的是如何实现 间接下载:
-
判断当前是否是属于 微信内置浏览器,若是则帮助用户自动唤起 手机浏览器 实现下载,但并不是所有机型都支持 唤起 操作,因此最好是提示使用用户直接通过 手机浏览器 实现下载,为了方便用户,可以实现 一键复制 的功能进行辅助
-
另一种就直接提示只支持
PC端下载,放弃对移动端的下载操作

最后
综上所述,实际在实现 pdf 预览的过程中可能暂时没有办法达到完美的方式,特别是针对类似 发票类 的 pdf 文件,仍存在如下的问题:
-
无法保证
h5移动端都具备 下载 功能 -
无法保证
pdf预览 时,预览的字体和实际发票 字体 保持一致
现有大部分的预览方式都基于 pdf.js 的方式实现,而 pdf.js 内部通过 PDFJs.getDocument(url/buffer) 的方式基于 文件地址 或 数据流 来获取内容,再通过 canvas 处理渲染 pdf 文件,感兴趣可以去研究 pdf.js 源码。
pdf.js 带来相关问题就是如果对应的 pdf 文件中包含了 pdf.js 中不存在的字体,那么就无法完整渲染,另外渲染出来的字体和原本的 pdf 文件字体会存在差异。
针对这两点,目前发现谷歌内置的 pdf 插件似乎提供了很好的支持,意味着其他浏览器如果包含了谷歌相关的插件(如:Edge、QQ Browser),就可以直接基于 <iframe> 的方式实现预览,又或者为了更严谨字体一致性只能通过下载的方式来查看源文件。
实现不了产品的要求怎么办?
例如上述探讨的方案其实无法满足文章开头提到的部分要求。产品提出需求的目的也是为了提供更好的用户体验(~~
正常情况下),但是这些要求仍然要落实到技术上,而技术支持程度如何需要我们及时反馈(除非你的产品是技术经验~~),因此作为开发者你需要提供充足的内容向产品证明,然后自己再给出一些间接实现的方案(又或者产品自己就给出新的方案),看是否符合 第二预期,核心就是 合理沟通 + 其他方案(每个人的处境不同,实际情况也许 ... 懂得都懂)。

以上是个人的一些看法和理解,有不当之处,可以在评论区指正!!!
希望本文对你有所帮助!!!