💻博主现有专栏:
C51单片机(STC89C516),c语言,c++,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux,基于HTML5的网页设计及应用,Rust(官方文档重点总结),jQuery,前端vue.js,Javaweb开发,设计模式、Python机器学习等
🥏主页链接:
目录
💻制作“买房会负债.csv”数据集文件,并用pandas载入数据
💻数据预处理,创建多项式贝叶斯模型并用预处理过的蘑菇数据集训练
🎯本文目的
(一)理解朴素贝叶斯算法的基本原理
(二)能够使用sklearn库进行朴素贝叶斯模型的训练和预测
(三)理解朴素贝叶斯算法三种变体模型适用的数据集的不同情况
🎯理解朴素贝叶斯算法的基本原理
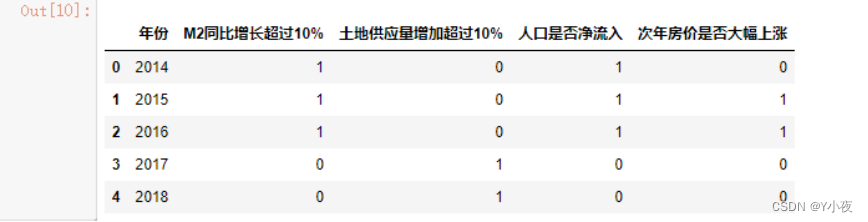
💻制作“买房会负债.csv”数据集文件,并用pandas载入数据
import pandas as pd data=pd.read_csv('aa.csv') data.head()
import pandas as pd # 导入pandas库,用于数据处理和分析
data = pd.read_csv('aa.csv') # 使用pandas的read_csv函数读取名为'aa.csv'的文件,并将数据存储在变量data中
data.head() # 使用head函数显示数据的前5行,以便查看数据的结构和内容
💻创建伯努利贝叶斯模型,并用上一步载入的数据训练模型
from sklearn.naive_bayes import BernoulliNB x=data.drop(['年份','次年房价是否大幅上涨'],axis=1) y=data['次年房价是否大幅上涨'] clf=BernoulliNB() clf.fit(x,y) clf.score(x,y)
# 导入伯努利朴素贝叶斯分类器
from sklearn.naive_bayes import BernoulliNB# 从数据集中删除'年份'和'次年房价是否大幅上涨'列,作为特征矩阵x
x = data.drop(['年份', '次年房价是否大幅上涨'], axis=1)# 提取'次年房价是否大幅上涨'列作为目标变量y
y = data['次年房价是否大幅上涨']# 创建伯努利朴素贝叶斯分类器实例
clf = BernoulliNB()# 使用特征矩阵x和目标变量y训练分类器
clf.fit(x, y)# 计算分类器的准确率
clf.score(x, y)

💻用训练好的模型预测
x_2019=[[0,1,0]] y_2020=clf.predict(x_2019) print(y_2020) x_2020=[[1,1,0]] y_2021=clf.predict(x_2020) print(y_2021)
# 定义一个二维列表x_2019,其中包含一个子列表[0, 1, 0]
x_2019 = [[0, 1, 0]]# 使用分类器clf对x_2019进行预测,将结果存储在变量y_2020中
y_2020 = clf.predict(x_2019)# 打印预测结果y_2020
print(y_2020)# 定义一个二维列表x_2020,其中包含一个子列表[1, 1, 0]
x_2020 = [[1, 1, 0]]# 使用分类器clf对x_2020进行预测,将结果存储在变量y_2021中
y_2021 = clf.predict(x_2020)# 打印预测结果y_2021
print(y_2021)

🎯了解不同朴素贝叶斯变体的差异
💻自己创建分类数据集
from sklearn.datasets import make_blobs from sklearn.naive_bayes import BernoulliNB from sklearn.model_selection import train_test_split x,y=make_blobs(n_samples=400,centers=4,random_state=8)# 导入make_blobs函数,用于生成聚类算法的数据集
from sklearn.datasets import make_blobs
# 导入BernoulliNB模块,即伯努利朴素贝叶斯分类器
from sklearn.naive_bayes import BernoulliNB
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split# 使用make_blobs函数生成一个包含400个样本、4个中心点的数据集
x, y = make_blobs(n_samples=400, centers=4, random_state=8)
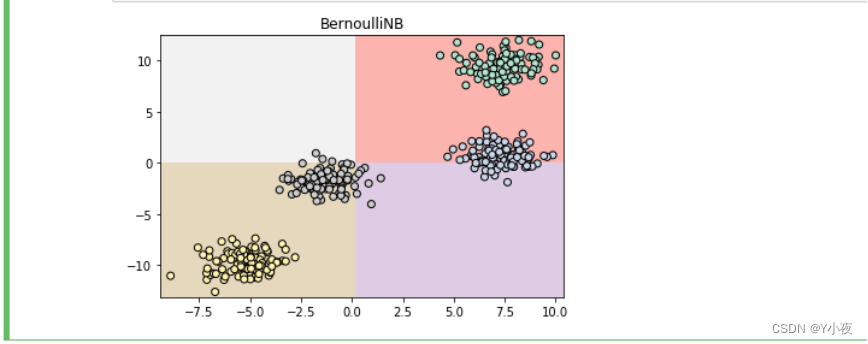
💻创建伯努利朴素贝叶斯模型,并用自己创建的分类数据集进行训练和可视化。
x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=8) nb=BernoulliNB() nb.fit(x_train,y_train)
# 导入train_test_split函数,用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split# 导入BernoulliNB类,用于创建伯努利朴素贝叶斯分类器
from sklearn.naive_bayes import BernoulliNB# 使用train_test_split函数将数据集x和y划分为训练集和测试集
# x_train, x_test为特征数据的训练集和测试集
# y_train, y_test为标签数据的训练集和测试集
# random_state参数设置为8,确保每次划分的结果一致
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=8)# 创建一个伯努利朴素贝叶斯分类器实例
nb = BernoulliNB()# 使用训练集数据对分类器进行训练
nb.fit(x_train, y_train)
import numpy as np import matplotlib.pyplot as plt # 获取x的最小值和最大值,并分别减去0.5和加上0.5 x_min, x_max = x[:, 0].min() - 0.5, x[:, 0].max() + 0.5 y_min, y_max = x[:, 1].min() - 0.5, x[:, 1].max() + 0.5 # 使用numpy的meshgrid函数生成网格点坐标矩阵 xx, yy = np.meshgrid(np.arange(x_min, x_max, .2), np.arange(y_min, y_max, .2)) # 使用朴素贝叶斯模型进行预测,并将结果重塑为与xx相同的形状 z = nb.predict(np.c_[(xx.ravel(), yy.ravel())]).reshape(xx.shape) # 使用pcolormesh函数绘制分类区域 plt.pcolormesh(xx, yy, z, cmap=plt.cm.Pastel1) # 使用scatter函数绘制样本点,并根据类别进行着色 plt.scatter(x[:, 0], x[:, 1], c=y, cmap=plt.cm.Pastel2, edgecolor='k') # 设置x轴和y轴的范围 plt.xlim(xx.min(), xx.max()) plt.ylim(yy.min(), yy.max()) # 设置图表标题 plt.title('BernoulliNB') # 显示图表 plt.show()
这段代码使用了NumPy和Matplotlib库来进行数据可视化。首先,它导入了这两个库。然后,它获取了输入数据的最小值和最大值,并分别减去0.5和加上0.5,以便在图表中留出一些边距。接下来,它使用
np.meshgrid函数生成了一个网格点坐标矩阵,用于绘制分类区域。然后,它使用朴素贝叶斯模型对网格点进行预测,并将结果重塑为与网格点坐标矩阵相同的形状。接着,它使用plt.pcolormesh函数绘制了分类区域,并使用plt.scatter函数绘制了样本点,根据类别进行着色。最后,它设置了x轴和y轴的范围,并添加了图表标题。最终,通过调用plt.show()函数显示了图表。

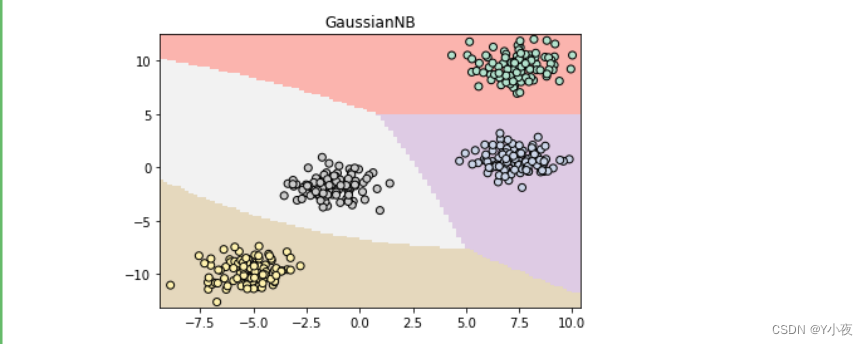
💻创建高斯朴素贝叶斯模型
from sklearn.naive_bayes import GaussianNB gnb=GaussianNB() gnb.fit(x_train,y_train) print('模型得分:{:,.3f}'.format(gnb.score(x_test,y_test)))
# 导入sklearn库中的高斯朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB# 创建一个GaussianNB对象,用于后续的模型训练和预测
gnb = GaussianNB()# 使用训练数据集x_train和对应的标签y_train来训练模型
gnb.fit(x_train, y_train)# 使用测试数据集x_test和对应的标签y_test来评估模型的性能,并打印出模型的得分
print('模型得分:{:,.3f}'.format(gnb.score(x_test, y_test)))
z_gnb=gnb.predict(np.c_[(xx.ravel(),yy.ravel())]).reshape(xx.shape) plt.pcolormesh(xx,yy,z_gnb,cmap=plt.cm.Pastel1) plt.scatter(x[:,0],x[:,1],c=y,cmap=plt.cm.Pastel2,edgecolor='k') plt.xlim(xx.min(),xx.max()) plt.ylim(yy.min(),yy.max()) plt.title('GaussianNB') plt.show()
# 使用高斯朴素贝叶斯模型进行预测,并将结果重塑为与xx相同的形状
z_gnb = gnb.predict(np.c_[(xx.ravel(), yy.ravel())]).reshape(xx.shape)# 绘制预测结果的网格图,使用Pastel1颜色映射
plt.pcolormesh(xx, yy, z_gnb, cmap=plt.cm.Pastel1)# 绘制原始数据的散点图,使用Pastel2颜色映射,并设置边缘颜色为黑色
plt.scatter(x[:, 0], x[:, 1], c=y, cmap=plt.cm.Pastel2, edgecolor='k')# 设置x轴和y轴的范围为xx和yy的最小值和最大值
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())# 设置图表标题为'GaussianNB'
plt.title('GaussianNB')# 显示图表
plt.show()

🎯使用朴素贝叶斯模型预测蘑菇分类
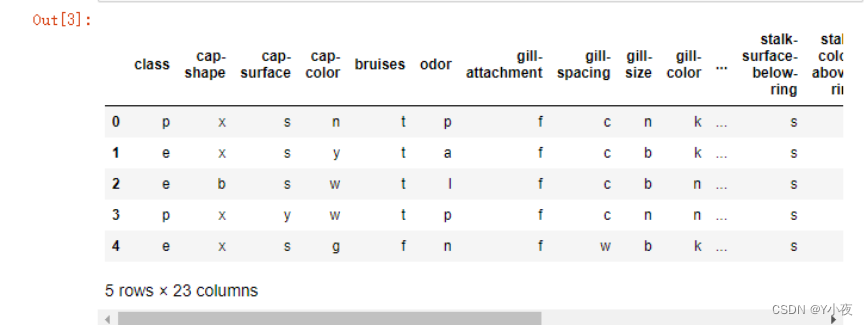
💻加载蘑菇数据集
import pandas as pd mushroom=pd.read_csv('mushroom.csv') mushroom.head()
import pandas as pd # 导入pandas库,用于数据处理和分析
mushroom = pd.read_csv('mushroom.csv') # 使用pandas的read_csv函数读取名为'mushroom.csv'的文件,并将其存储在变量mushroom中
mushroom.head() # 使用pandas的head函数显示mushroom的前5行数据
💻数据预处理,创建多项式贝叶斯模型并用预处理过的蘑菇数据集训练
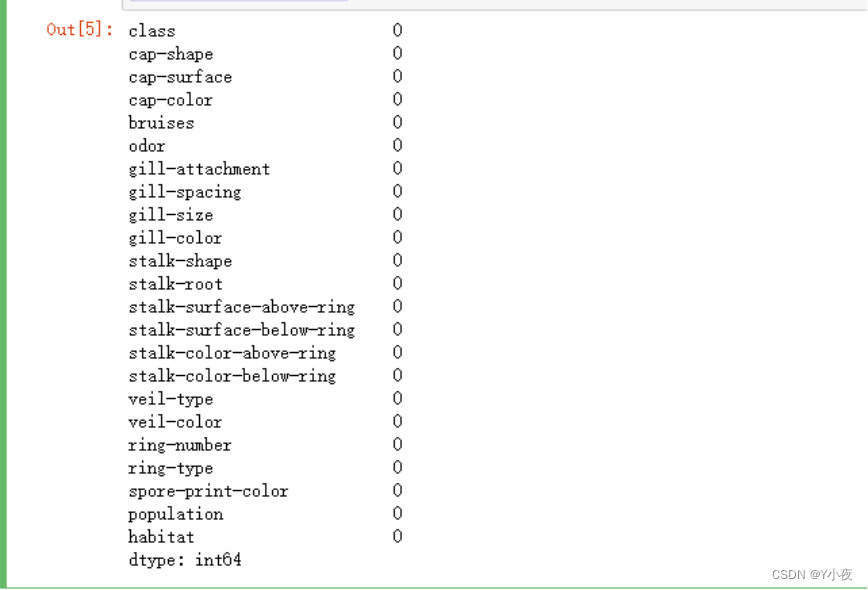
# 导入sklearn库中的train_test_split函数,用于将数据集划分为训练集和测试集 from sklearn.model_selection import train_test_split # 使用isnull()函数检查mushroom数据集中是否存在缺失值,并使用sum()函数统计每列的缺失值数量 mushroom.isnull().sum()
# 获取mushroom字典中'class'键对应的唯一值,并返回一个包含这些唯一值的数组 unique_classes = mushroom['class'].unique()
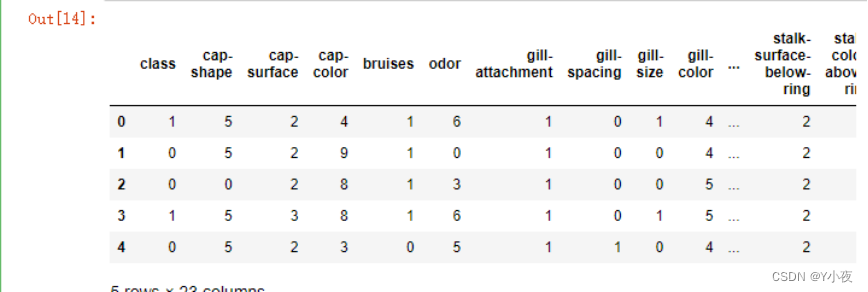
from sklearn.preprocessing import LabelEncoder labelencoder=LabelEncoder() for col in mushroom.columns: mushroom[col]=labelencoder.fit_transform(mushroom[col]) mushroom.head()
# 导入LabelEncoder模块,用于将类别标签转换为整数编码
from sklearn.preprocessing import LabelEncoder# 创建LabelEncoder对象
labelencoder = LabelEncoder()# 遍历数据集的每一列
for col in mushroom.columns:
# 使用LabelEncoder的fit_transform方法将每一列的类别标签转换为整数编码
mushroom[col] = labelencoder.fit_transform(mushroom[col])# 显示数据集的前几行
mushroom.head()
# 导入pandas库 import pandas as pd # 读取名为mushroom的数据集 mushroom = pd.read_csv('mushroom.csv') # 使用groupby方法按照'class'列对数据进行分组,并计算每个分组的大小(即每个类别的数量) print(mushroom.groupby('class').size())


💻多项式朴素贝叶斯模型对蘑菇数据集的预测准确率
from sklearn.naive_bayes import MultinomialNB x=mushroom.iloc[:,1:23] y=mushroom.iloc[:, 0] x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=42) mnb=MultinomialNB() mnb.fit(x_train,y_train) print(mnb.score(x_train,y_train)) print(mnb.score(x_test,y_test))
# 导入sklearn库中的MultinomialNB模块,用于实现多项式朴素贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB# 从mushroom数据集中提取特征矩阵x(第1列到第23列)
x = mushroom.iloc[:, 1:23]# 从mushroom数据集中提取目标变量y(第0列)
y = mushroom.iloc[:, 0]# 将数据集划分为训练集和测试集,其中测试集占比为30%,随机种子为42
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)# 创建一个多项式朴素贝叶斯分类器对象
mnb = MultinomialNB()# 使用训练集对分类器进行训练
mnb.fit(x_train, y_train)# 输出训练集上的准确率
print(mnb.score(x_train, y_train))# 输出测试集上的准确率
print(mnb.score(x_test, y_test))

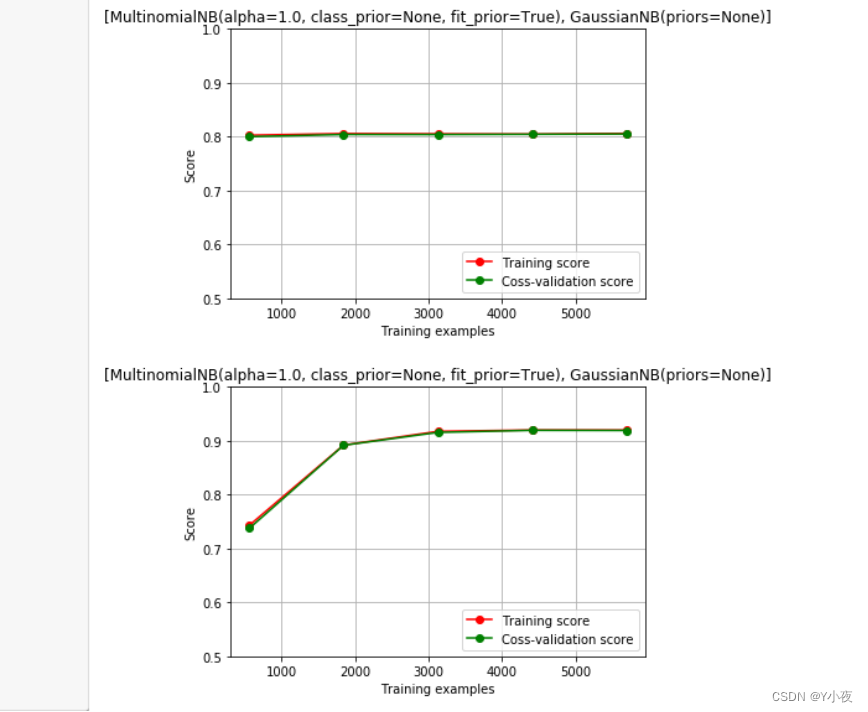
💻研究样本数量对朴素贝叶斯模型的影响
import numpy as np from sklearn.model_selection import learning_curve from sklearn.model_selection import ShuffleSplit from sklearn.naive_bayes import GaussianNB import matplotlib.pyplot as plt def plot_learning_curve(estimator,title,x,y,ylim=None,cv=None,n_jobs=-1,train_sizes=np.linspace(.1, 1.0,5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel('Training examples') plt.ylabel('Score') train_sizes,train_scores,test_scores=learning_curve(estimator,x,y,cv=cv,n_jobs=n_jobs,train_sizes=train_sizes) train_scores_mean=np.mean(train_scores,axis=1) test_scores_mean=np.mean(test_scores,axis=1) plt.grid() plt.plot(train_sizes,train_scores_mean,'o-',color='r',label='Training score') plt.plot(train_sizes,test_scores_mean,'o-',color='g',label='Coss-validation score') plt.legend(loc='lower right') return plt cv=ShuffleSplit(n_splits=30,test_size=0.3,random_state=28) estimators=[MultinomialNB(),GaussianNB()] for estimator in estimators: title=estimators plot_learning_curve(estimator,title,x,y,ylim=(0.5,1.0),cv=cv,n_jobs=-1) plt.show()
import numpy as np # 导入numpy库,用于进行数值计算
from sklearn.model_selection import learning_curve # 导入学习曲线函数
from sklearn.model_selection import ShuffleSplit # 导入随机划分数据集的函数
from sklearn.naive_bayes import GaussianNB # 导入高斯朴素贝叶斯分类器
import matplotlib.pyplot as plt # 导入绘图库matplotlib# 定义绘制学习曲线的函数
def plot_learning_curve(estimator, title, x, y, ylim=None, cv=None, n_jobs=-1, train_sizes=np.linspace(.1, 1.0, 5)):
plt.figure() # 创建一个新的图形
plt.title(title) # 设置图形标题
if ylim is not None: # 如果y轴范围不为空,则设置y轴范围
plt.ylim(*ylim)
plt.xlabel('Training examples') # 设置x轴标签
plt.ylabel('Score') # 设置y轴标签
# 调用学习曲线函数,获取训练集大小、训练得分和测试得分
train_sizes, train_scores, test_scores = learning_curve(estimator, x, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes)
train_scores_mean = np.mean(train_scores, axis=1) # 计算训练得分的均值
test_scores_mean = np.mean(test_scores, axis=1) # 计算测试得分的均值
plt.grid() # 添加网格线
# 绘制训练得分曲线
plt.plot(train_sizes, train_scores_mean, 'o-', color='r', label='Training score')
# 绘制交叉验证得分曲线
plt.plot(train_sizes, test_scores_mean, 'o-', color='g', label='Coss-validation score')
plt.legend(loc='lower right') # 设置图例位置
return pltcv = ShuffleSplit(n_splits=30, test_size=0.3, random_state=28) # 创建随机划分数据集的对象
estimators = [MultinomialNB(), GaussianNB()] # 创建分类器列表
for estimator in estimators: # 遍历分类器列表
title = estimators # 设置图形标题为分类器名称
plot_learning_curve(estimator, title, x, y, ylim=(0.5, 1.0), cv=cv, n_jobs=-1) # 调用绘制学习曲线函数
plt.show() # 显示图形