本项目采用了大仓的模式,它的一个典型特征是通过组合的方式将多个功能独立且相互以来的模块组合在一起,形成一个完整的系统。本文将阐述为什么采用这种方式,以及如何实现。
大仓的演进
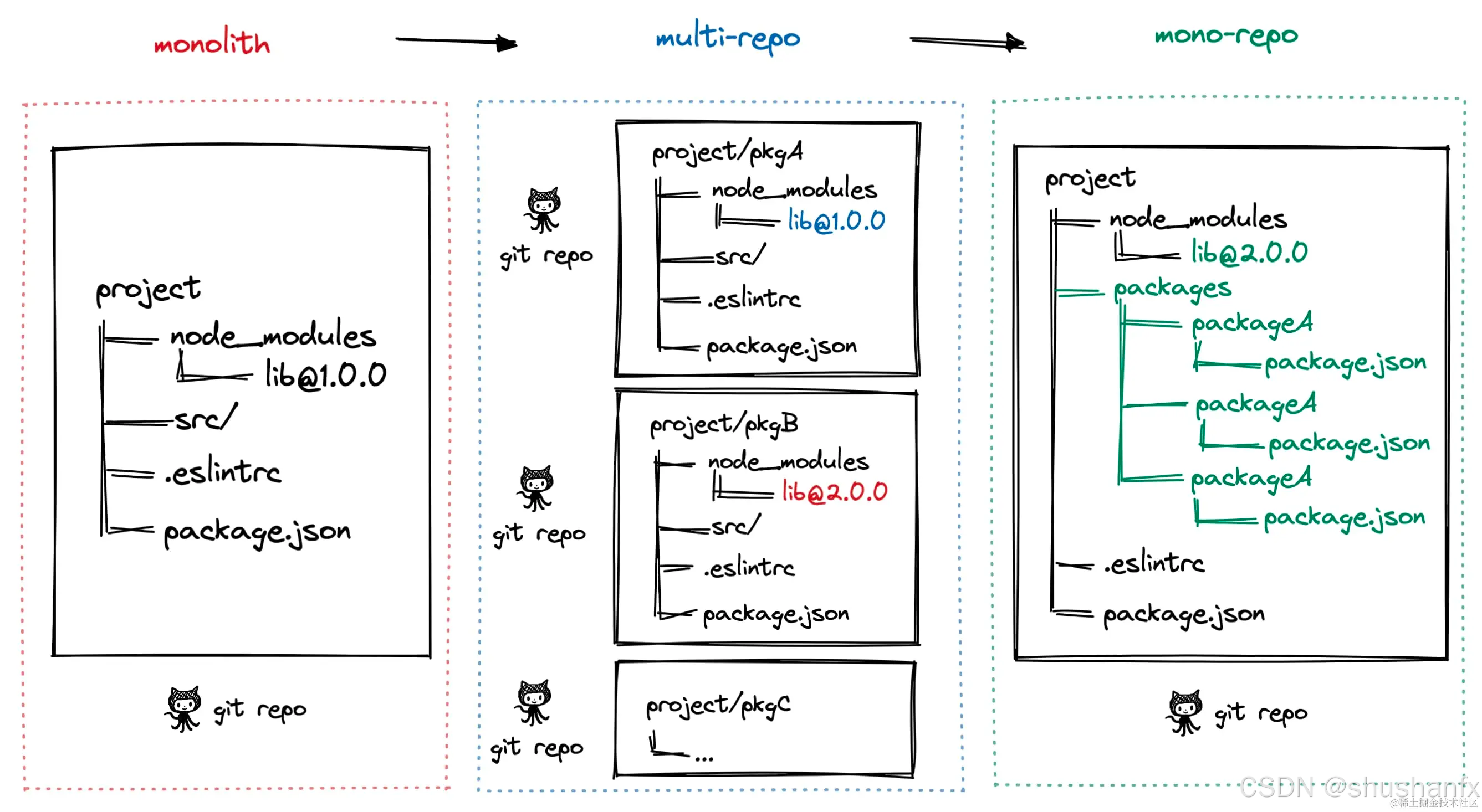
大仓(monorepo)并不是一开始就存在的,它是项目的演进过程中,随着项目规模的增大,代码复用的需求,以及团队协作的需求,逐渐形成的。在项目初期,由于代码量较小,团队规模较小,代码复用的需求不强烈,因此采用单仓的方式即可。但随着项目的发展,代码量逐渐增大,团队规模逐渐扩大,代码复用的需求逐渐增强,此时单仓的方式已经无法满足需求,因此需要将代码拆分成多个模块,每个模块独立开发,独立测试,独立部署,最后再将这些模块组合在一起形成一个完整的系统。如下图:
-
阶段一:单仓库巨石应用, 一个 Git 仓库维护着项目代码,随着迭代业务复杂度的提升,项目代码会变得越来越多,越来越复杂,大量代码构建效率也会降低,最终导致了单体巨石应用,这种代码管理方式称之为
Monolith。 -
阶段二:多仓库多模块应用,于是将项目拆解成多个业务模块,并在多个 Git 仓库管理,模块解耦,降低了巨石应用的复杂度,每个模块都可以独立编码、测试、发版,代码管理变得简化,构建效率也得以提升,这种代码管理方式称之为
MultiRepo。 -
阶段三:单仓库多模块应用,随着业务复杂度的提升,模块仓库越来越多,
MultiRepo这种方式虽然从业务上解耦了,但增加了项目工程管理的难度,随着模块仓库达到一定数量级,会有几个问题:- 跨仓库代码难共享。就前端而言,通过 npm 包管理,但是每次发布都需要发布到 npm 仓库,增加了发布成本;或者通过
npm link这种方式,如果是多人协作,每个人都需要手动链接,不利于团队协作。 - 分散在单仓库的模块依赖管理复杂(底层模块升级后,其他上层依赖需要及时更新,否则有问题)。
- 增加了构建耗时。
于是将多个项目集成到一个仓库下,共享工程配置,同时又快捷地共享模块代码,成为趋势,这种代码管理方式称之为
MonoRepo。 - 跨仓库代码难共享。就前端而言,通过 npm 包管理,但是每次发布都需要发布到 npm 仓库,增加了发布成本;或者通过
大仓的优缺点
在这里我们不妨比对一下Monolith、MultiRepo、MonoRepo三种代码管理方式的优缺点:
| 场景 | Monolith | MultiRepo | MonoRepo |
|---|---|---|---|
| 代码可见性 | ✅ 一个仓库中多个相关项目,很容易看到整个代码库的变化趋势,更好的团队协作。 ❌ 增加了非 owner 改动代码的风险 | ✅ 一个仓库一个项目,代码可见性高,更容易维护。 | 同monolith |
| 依赖管理 | ✅ 嵌入项目内部,直接引用。 ❌ 通过文件引用,不利于维护 | ❌ 通过 npm link 或者发布到 npm,不利于团队协作。 | ✅ 依赖管理简单 |
| 代码权限 | ❌ 一个仓库,无法精准控制,强行精准控制可能会导致构建异常 | ✅ 多个仓库,权限管理简单。 | ❌ 一个仓库,精准控制成本高 |
| 开发迭代 | - | ✅ 仓库体积小,模块划分清晰,可维护性强。 ❌ 多仓库来回切换(编辑器及命令行),项目多的话效率很低。多仓库见存在依赖时,需要手动 npm link,操作繁琐。 ❌ 依赖管理不便,多个依赖可能在多个仓库中存在不同版本,重复安装,npm link 时不同项目的依赖会存在冲突。 | ✅ 多个项目都在一个仓库中,可看到相关项目全貌,编码非常方便。 ✅ 代码复用高,方便进行代码重构。 ❌ 多项目在一个仓库中,代码体积多大几个 G,git clone 时间较长。 ✅ 依赖调试方便,依赖包迭代场景下,借助工具自动 npm link,直接使用最新版本依赖,简化了操作流程。 |
| 工程配置 | ✅ 多项目在一个仓库,工程配置一致,代码质量标准及风格也很容易一 | ❌ 各项目构建、打包、代码校验都各自维护,不一致时会导致代码差异或构建差异。 | ✅ 多项目在一个仓库,工程配置一致,代码质量标准及风格也很容易一致。 |
| 构建部署 | ✅ 一个仓库,构建部署简单 ❌ 每每次均全量构建,构建成本高 | ❌ 多个仓库,构建部署复,升级成本高 ❌ 构建配置可能不一致,可能影响最终构建产物 | ✅ 一个仓库,构建部署简单 |
很明显,MonoRepo是最优的选择,它综合了Monolith和MultiRepo的优点,同时避免了它们的缺点。
同时,针对需要控制文件级的权限,当前git暂时做不到这一点,在大厂内部已经开始探索了文件级权限控制,相信未来会有更好的解决方案。
如何实现的
对于我们项目而言,我们采用yarn + lerna的方式进行大仓控制。yarn 用于管理依赖,lerna 用于控制包的发布。
具体操作流程如下:
-
项目结构,packages 存放所有的工具包,app 存放 web 包。
-
修改
package.json,添加workspaces字段,指定所有的包。
{
"workspaces": ["packages/*", "app"]
}
执行命令: yarn workspaces info,可以查看所有的包。查看它们彼此的依赖情况。
类似如下的结果:
$ yarn workspaces info
{
"@shushanfx/tetris-core": {
"location": "packages/core",
"workspaceDependencies": [],
"mismatchedWorkspaceDependencies": []
},
"@shushanfx/tetris-console": {
"location": "packages/console",
"workspaceDependencies": [
"@shushanfx/tetris-core"
],
"mismatchedWorkspaceDependencies": []
},
"@shushanfx/tetris-web": {
"location": "packages/web",
"workspaceDependencies": [
"@shushanfx/tetris-core"
],
"mismatchedWorkspaceDependencies": []
},
"app": {
"location": "app",
"workspaceDependencies": [
"@shushanfx/tetris-core",
"@shushanfx/tetris-web"
],
"mismatchedWorkspaceDependencies": []
}
}
由上面我们可以看出,workspaces 被 yarn 识别了。 关系如下:
@shushanfx/tetris-core: 无依赖@shushanfx/tetris-console: 依赖@shushanfx/tetris-core@shushanfx/tetris-web: 依赖@shushanfx/tetris-coreapp: 依赖@shushanfx/tetris-core和@shushanfx/tetris-web
lerna配置文件lerna.json,指定lerna的配置。
{
"$schema": "node_modules/lerna/schemas/lerna-schema.json",
"version": "1.0.3",
"npmClient": "yarn"
}
一个重要的配置是使用npmClient: yarn,这样lerna会使用yarn来安装依赖。
如此,我们基本上完成了大仓的配置。
如何运作
我们利用大仓来管理项目的其中两个很重要目的:一个是管理公共依赖,另一个是管理内部依赖。
公共依赖如何管理
所谓公共依赖,也可以细分为两个情况:
-
通过根
package.json声明的依赖,这些依赖会被所有的包共享。 -
通过两个及以上的项目依赖。
对于这两种情况,一般的建议都是通过根package.json进行管理。当时在实际情况下第二种情况也确实存在。不过大仓都将这些情况考虑进去了。
比如,项目中均依赖typescript、eslint等,那么我们只需要在根package.json中声明即可。
最终会在根目录下的node_modules中看到这些依赖。如下:
tetris
|-- node_modules
| |-- typescript
注意:有两个地方需要注意
-
如果子项目声明同一个依赖,但版本不一致,yarn 会在子项目下安装对应的依赖版本。如子项目分别使用了
vue@2和vue@3,那么最终在子项目的目录下分别包含vue2和vue3。 -
如果子项目安装的依赖包含
bin声明,则会在子项目的node_modules/.bin目录下生成对应的可执行文件。
内部依赖如何管理
对于内部依赖,yarn 的处理要简单得多,直接在根目录下生成对应的软链接。
如本项目中,@shushanfx/tetris-core、@shushanfx/tetris-console、@shushanfx/tetris-web都是内部依赖,那么在根目录下会生成对应的软链接。
tetris
|-- node_modules
| |-- @shushanfx
| |-- tetris-core -> ../../packages/core
| |-- tetris-console -> ../../packages/console
| |-- tetris-web -> ../../packages/web
这样,我们在app项目中引用@shushanfx/tetris-core时,实际上引用的是packages/core目录。
PS: 实际上它利用了 node 的
require机制,当引用一个模块时,会先在node_modules中查找,如果没有找到,会继续在父目录中查找,直到根目录。有兴趣的同学可以去了解一下node的模块加载机制。无论是webpack还是rollup,均参照了该机制进行模块加载。
小结
本文正对项目中采用的大仓模式进行了阐述,从大仓的演进、优缺点、以及如何实现这三个方面进行了详细的介绍。讲解得比较浅显,深入的使用还是要去实践一下。同时,大仓模式并不是万能的,对于一些特殊的场景,还是需要根据实际情况进行选择。技术选型也并非我们所描述的yarn + lerna的组合,还有很多其他的选择,比如rush等。
引入大仓是一个开始,但是它的引入带了一些新的调整,如:
- 构建依赖如何管理?
- eslint 在大仓模式下如何生效?
- 不同的构建体系如何融入大仓模式?
- 单元测试如何组织?
- 其他问题
后续的文章将进一步阐述这些问题。
我已经把项目上传到github上,有兴趣的同学可以去了解一下: https://github.com/shushanfx/tetris/
欢迎关注我的github,一起与我探索技术这件事情: https://github.com/shushanfx