C++的正则表达式
备注:参考书籍《C++标准库(第二版)》
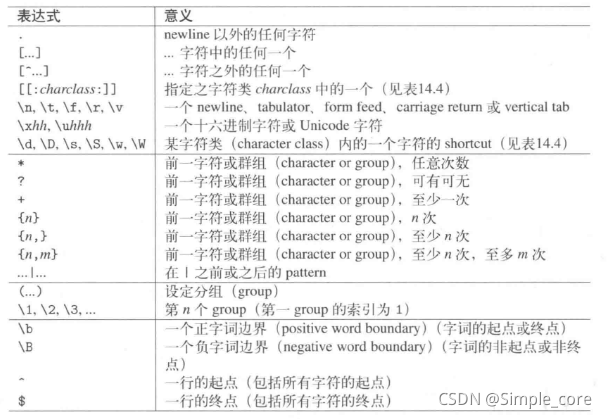
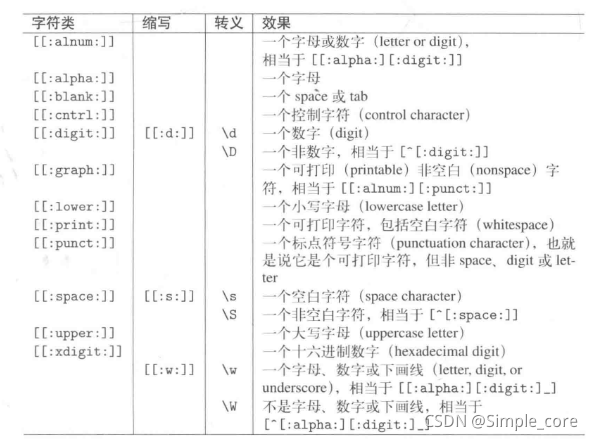
正则表达式的结构
需要的头文件
#include <regex>
//
//regex_match匹配和regex_search
void out(bool b)
{
cout << (b ? "found" : "not found") << endl;
}
//匹配match
void test01()
{
regex reg1("<.*>.*</.*>");
bool found = regex_match("<tag>value</tag>", reg1);
out(found);
regex reg2("<(.*)>.*</\\1>");
found = regex_match("<tag>value</tag>", reg2);
out(found);
regex reg3("<\\(.*\\)>.*</\\1>",regex_constants::grep);
found = regex_match("<tag>value</tag>", reg3);
out(found);
found = regex_match("<tag>value</tag>", regex("<(.*)>.*</\\1>"));
out(found);
}
//查询到的具体的信息smatch
void test02()
{
string data = "XML tag::<tag-name>the value</tag-name>.";
cout << "data: " << data << "\n\n";
smatch m;
bool found = regex_search(data, m, regex("<(.*)>(.*)</(\\1)>"));
cout << "m.empty() : " << boolalpha << m.empty() << endl;
cout << "m.size() : " << m.size() << endl;
if (found)
{
cout << "m.str() : " << m.str() << endl;
cout << "m.length() : " << m.length() << endl;
cout << "m.position() : " << m.position() << endl;
cout << "m.prefix().str() : " << m.prefix().str() << endl;
cout << "m.suffix().str() : " << m.suffix().str() << endl;
//prefix()表示sub_match对象,表示第一个匹配合格的字符的前方所有字符
//suffix()表示sub_match对象,表示最末一个匹配合格的字符的后方所有字符
}
cout << "--------------" << endl;
for (int i = 0; i < m.size(); i++)
{
cout << "m[" << i << "].str(): " << m[i].str() << endl;
cout << "m.str("<<i<<"): " << m.str(i) << endl;
cout << "m.position("<<i<<"): " << m.position(i) << endl;
cout << endl;
//可以查看完全匹配的str(0),也可以查看第n个匹配的
//position查看匹配的位置
//length()查看匹配的字符个数
}
cout << "matches:" << endl;
for (auto pos = m.begin(); pos != m.end(); ++pos)
{
cout << " " << *pos << " ";
cout << "(length(): " << pos->length() << ")" << endl;
}
}
//查找的逐步查找
//使用for循环进行查找,找到之后重查找的位置继续查找
void test03()
{
string data = "<preson>\n"
"<first>Nico</first>\n"
"<last>Josuttis</last>\n"
"</person>\n";
regex reg("<(.*)>(.*)</(\\1)>");
auto pos = data.cbegin();
auto end = data.cend();
smatch m;
int i = 0;
for (; regex_search(pos, end, m, reg); pos = m.suffix().first)
{
i++;
cout << "match: " << m.str() << endl;
cout << "tag: " << m.str(1) << endl;
cout << "value:" << m.str(2) << endl;
}
cout << i << endl;
}
//逐一迭代(使用迭代器)
void test04()
{
string data = "<preson>\n"
"<first>Nico</first>\n"
"<last>Josuttis</last>\n"
"</person>\n";
regex reg("<(.*)>(.*)</(\\1)>");
//使用迭代器
sregex_iterator pos(data.cbegin(), data.cend(), reg);
sregex_iterator end;
for (; pos != end; ++pos)
{
cout << "match: " << pos->str() << endl;
cout << "tag:" << pos->str(1) << endl;
cout << "value: " << pos->str(2) << endl;
}
sregex_iterator beg(data.cbegin(), data.end(), reg);
for_each(beg, end, [](const smatch& m) {
cout << "match: " << m.str() << endl;
cout << "tag:" << m.str(1) << endl;
cout << "value: " << m.str(2) << endl;
});
}
//token,拆分
//token,拆分
void test05()
{
string data = "<preson>\n"
"<first>Nico</first>\n"
"<last>Josuttis</last>\n"
"</person>\n";
regex reg("<(.*)>(.*)</(\\1)>");
//使用迭代器
sregex_token_iterator pos(data.cbegin(), data.cend(), reg, { 0,2 });
sregex_token_iterator end;
for (; pos != end; ++pos)
{
cout << "match: " << pos->str() << endl;
}
cout << endl;
string name = "nice,jim,helut,paul,tim,john,paul,rita";
regex sep("[\t\n]*[,;.][\t\n]*");
sregex_token_iterator p(name.cbegin(), name.cend(), sep, -1);
sregex_token_iterator e;
for (; p != e; ++p)
{
cout << "name: " << *p << endl;
}
}
//replace 替代
替代用的符号:

//replace
void test06()
{
string data = "<preson>\n"
"<first>Nico</first>\n"
"<last>Josuttis</last>\n"
"</person>\n";
regex reg("<(.*)>(.*)</(\\1)>");
cout << regex_replace(data, reg, "<$1 value=\"$2\"/>") << endl;
cout << regex_replace(data, reg, "<\\1 value=\"\\2\"/>", regex_constants::format_sed) << endl;
string res2;
regex_replace(back_inserter(res2), data.begin(), data.end(), reg, "<$1 value=\"$2\"/>", regex_constants::format_no_copy | regex_constants::format_first_only);
cout << res2 << endl;
}
//regex的常量
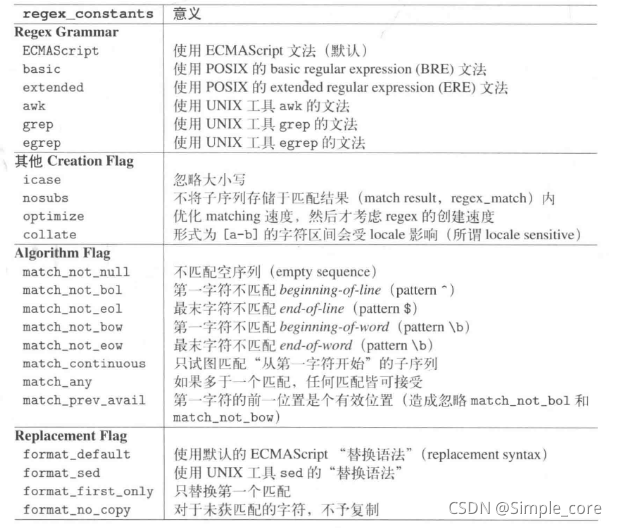
//regex的常量
void test07()
{
string pat1 = R"(\\.*index\{([^}]*)\})";
string pat2 = R"(\\.*index\{(.*)\}\{(.*)\})";
regex pat(pat1 + "\n" + pat2, regex_constants::egrep | regex_constants::icase);
string data((istreambuf_iterator<char>(cin)), istreambuf_iterator<char>());
smatch m;
auto pos = data.cbegin();
auto end = data.cend();
for (; regex_search(pos, end, m, pat); pos = m.suffix().first)
{
cout << "match:" << m.str() << endl;
cout << "val:" << m.str(1)+m.str(2) << endl;
cout << "see: " << m.str(3) << endl;
}
}
常用正则表达式大全
注意:未验证于 c++ ,使用时自行检验
一、校验数字的表达式
1 数字:^[0-9]*$
2 n位的数字:^\d{n}$
3 至少n位的数字:^\d{n,}$
4 m-n位的数字:^\d{m,n}$
5 零和非零开头的数字:^(0|[1-9][0-9]*)$
6 非零开头的最多带两位小数的数字:^([1-9][0-9]*)+(.[0-9]{1,2})?$
7 带1-2位小数的正数或负数:^(\-)?\d+(\.\d{1,2})?$
8 正数、负数、和小数:^(\-|\+)?\d+(\.\d+)?$
9 有两位小数的正实数:^[0-9]+(.[0-9]{2})?$
10 有1~3位小数的正实数:^[0-9]+(.[0-9]{1,3})?$
11 非零的正整数:^[1-9]\d*$ 或 ^([1-9][0-9]*){1,3}$ 或 ^\+?[1-9][0-9]*$
12 非零的负整数:^\-[1-9][]0-9"*$ 或 ^-[1-9]\d*$
13 非负整数:^\d+$ 或 ^[1-9]\d*|0$
14 非正整数:^-[1-9]\d*|0$ 或 ^((-\d+)|(0+))$
15 非负浮点数:^\d+(\.\d+)?$ 或 ^[1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0$
16 非正浮点数:^((-\d+(\.\d+)?)|(0+(\.0+)?))$ 或 ^(-([1-9]\d*\.\d*|0\.\d*[1-9]\d*))|0?\.0+|0$
17 正浮点数:^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ 或 ^(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*))$
18 负浮点数:^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ 或 ^(-(([0-9]+\.[0-9]*[1-9][0-9]*)|([0-9]*[1-9][0-9]*\.[0-9]+)|([0-9]*[1-9][0-9]*)))$
19 浮点数:^(-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0)$
二、校验字符的表达式
1 汉字:^[\u4e00-\u9fa5]{0,}$
2 英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$
3 长度为3-20的所有字符:^.{3,20}$
4 由26个英文字母组成的字符串:^[A-Za-z]+$
5 由26个大写英文字母组成的字符串:^[A-Z]+$
6 由26个小写英文字母组成的字符串:^[a-z]+$
7 由数字和26个英文字母组成的字符串:^[A-Za-z0-9]+$
8 由数字、26个英文字母或者下划线组成的字符串:^\w+$ 或 ^\w{3,20}$
9 中文、英文、数字包括下划线:^[\u4E00-\u9FA5A-Za-z0-9_]+$
10 中文、英文、数字但不包括下划线等符号:^[\u4E00-\u9FA5A-Za-z0-9]+$ 或 ^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$
11 可以输入含有^%&',;=?$\"等字符:[^%&',;=?$\x22]+
12 禁止输入含有~的字符:[^~\x22]+
三、特殊需求表达式
1 Email地址:^\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*$
2 域名:[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(/.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+/.?
3 InternetURL:[a-zA-z]+://[^\s]* 或 ^http://([\w-]+\.)+[\w-]+(/[\w-./?%&=]*)?$
4 手机号码:^(13[0-9]|14[0-9]|15[0-9]|16[0-9]|17[0-9]|18[0-9]|19[0-9])\d{8}$ (由于工信部放号段不定时,所以建议使用泛解析 ^([1][3,4,5,6,7,8,9])\d{9}$)
5 电话号码("XXX-XXXXXXX"、"XXXX-XXXXXXXX"、"XXX-XXXXXXX"、"XXX-XXXXXXXX"、"XXXXXXX"和"XXXXXXXX):^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$
6 国内电话号码(0511-4405222、021-87888822):\d{3}-\d{8}|\d{4}-\d{7}
7 18位身份证号码(数字、字母x结尾):^((\d{18})|([0-9x]{18})|([0-9X]{18}))$
8 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{4,15}$
9 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):^[a-zA-Z]\w{5,17}$
10 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在8-10之间):^(?=.*\d)(?=.*[a-z])(?=.*[A-Z]).{8,10}$
11 日期格式:^\d{4}-\d{1,2}-\d{1,2}
12 一年的12个月(01~09和1~12):^(0?[1-9]|1[0-2])$
13 一个月的31天(01~09和1~31):^((0?[1-9])|((1|2)[0-9])|30|31)$
14 钱的输入格式:
15 1.有四种钱的表示形式我们可以接受:"10000.00" 和 "10,000.00", 和没有 "分" 的 "10000" 和 "10,000":^[1-9][0-9]*$
16 2.这表示任意一个不以0开头的数字,但是,这也意味着一个字符"0"不通过,所以我们采用下面的形式:^(0|[1-9][0-9]*)$
17 3.一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:^(0|-?[1-9][0-9]*)$
18 4.这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧.下面我们要加的是说明可能的小数部分:^[0-9]+(.[0-9]+)?$
19 5.必须说明的是,小数点后面至少应该有1位数,所以"10."是不通过的,但是 "10" 和 "10.2" 是通过的:^[0-9]+(.[0-9]{2})?$
20 6.这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:^[0-9]+(.[0-9]{1,2})?$
21 7.这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:^[0-9]{1,3}(,[0-9]{3})*(.[0-9]{1,2})?$
22 8.1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:^([0-9]+|[0-9]{1,3}(,[0-9]{3})*)(.[0-9]{1,2})?$
23 备注:这就是最终结果了,别忘了"+"可以用"*"替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
24 xml文件:^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$
25 中文字符的正则表达式:[\u4e00-\u9fa5]
26 双字节字符:[^\x00-\xff] (包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))
27 空白行的正则表达式:\n\s*\r (可以用来删除空白行)
28 HTML标记的正则表达式:<(\S*?)[^>]*>.*?</\1>|<.*? /> (网上流传的版本太糟糕,上面这个也仅仅能部分,对于复杂的嵌套标记依旧无能为力)
29 首尾空白字符的正则表达式:^\s*|\s*$或(^\s*)|(\s*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)
30 腾讯QQ号:[1-9][0-9]{4,} (腾讯QQ号从10000开始)
31 中国邮政编码:[1-9]\d{5}(?!\d) (中国邮政编码为6位数字)
32 IP地址:\d+\.\d+\.\d+\.\d+ (提取IP地址时有用)
33 IP地址:((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))