概要
主要用于处理MySQL数据库的二进制日志事件,并将其转换为Kafka Connect的源记录
核心流程
相关解释
假设你有一个数据库,里面有一些表。这个数据库有一个功能叫做“二进制日志”(binlog),它可以记录数据库中的所有变更操作(如插入、更新、删除)。
- 二进制日志启用前的表:假设你在某一天启用了二进制日志功能。在启用二进制日志之前,数据库中已经有一些表存在了。这些表的架构信息(比如表的列名、数据类型等)没有被记录在二进制日志中。
- 启用二进制日志后的新表:启用二进制日志之后,新创建的表的元数据信息会被记录在二进制日志中。
- 处理二进制日志:当你的应用程序读取二进制日志时,它需要知道每个表的元数据信息,以便正确解析和处理这些变更操作。对于那些在二进制日志启用前已经存在的表,因为它们的元数据信息没有被记录,所以你的应用程序无法找到这些表的以元数据信息。
- 处理缺失的元数据信息:当应用程序发现某个表的元数据信息缺失时,它会记录一条警告日志,提示这个表的事务影响了未记录元数据的行。为了防止数据处理错误,应用程序会忽略后续对该表的所有变更操作。
总结起来,这句话的意思是:如果在处理某个表的变更事件时,发现该表的元数据信息为空,那么这个表可能是在二进制日志功能启用之前创建的,因此缺少必要的元数据信息。为了避免错误,系统会记录一条警告并忽略后续对该表的变更操作。
技术细节
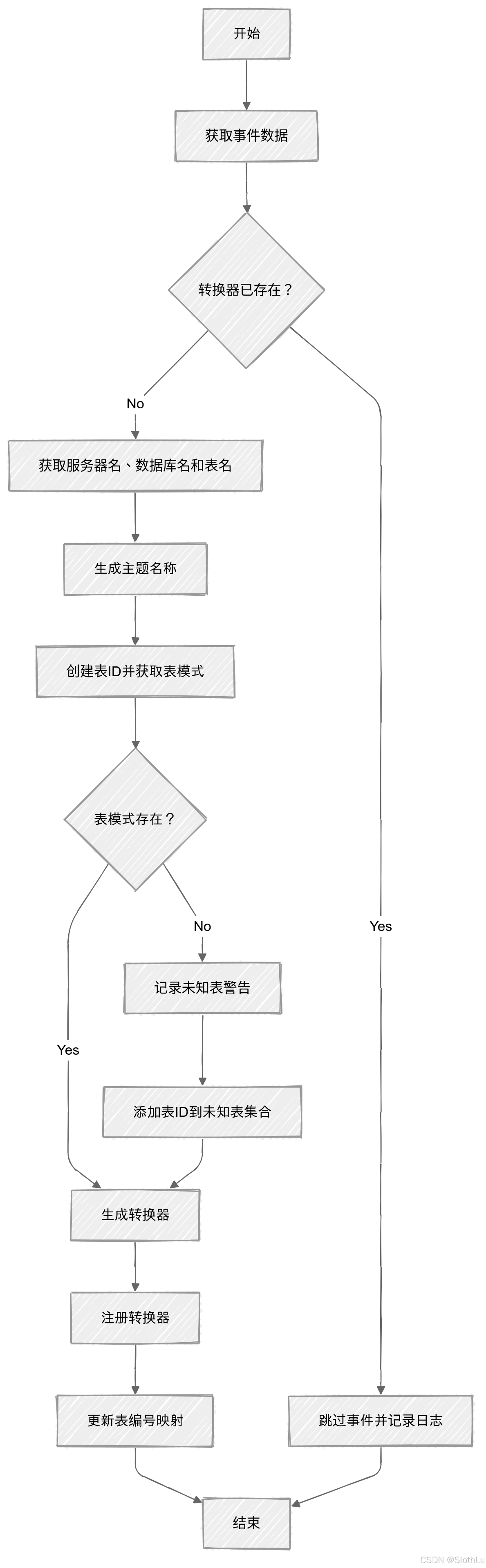
1 updateTableMetadata
public void updateTableMetadata(Event event, SourceInfo source, Consumer<SourceRecord> recorder) {
// 解析事件数据,获取表ID和元数据
TableMapEventData metadata = event.getData();
long tableNumber = metadata.getTableId();
logger.debug("Received update table metadata event: {}", event);
// 检查是否已存在该表的转换器,如果不存在,则创建
if (!convertersByTableId.containsKey(tableNumber)) {
// 获取服务器、数据库和表名称,用于构建主题名称
String serverName = source.serverName();
String databaseName = metadata.getDatabase();
String tableName = metadata.getTable();
String topicName = topicSelector.getTopic(serverName, databaseName, tableName);
// 构建表标识,并获取当前表架构
TableId tableId = new TableId(databaseName, null, tableName);
TableSchema tableSchema = tableSchemaByTableId.get(tableId);
logger.debug("Registering metadata for table {} with table #{}", tableId, tableNumber);
// 如果表架构为空,说明该表在二进制日志启用前已创建,需要记录警告
if (tableSchema == null) {
if (unknownTableIds.add(tableId)) {
logger.warn("Transaction affects rows in {}, for which no metadata exists. All subsequent changes to rows in this table will be ignored.",
tableId);
}
}
// 创建并注册该表的转换器
Converter converter = new Converter() {
@Override
public TableId tableId() {
return tableId;
}
@Override
public String topic() {
return topicName;
}
@Override
public Integer partition() {
return null;
}
@Override
public Schema keySchema() {
return tableSchema.keySchema();
}
@Override
public Schema valueSchema() {
return tableSchema.valueSchema();
}
@Override
public Object createKey(Serializable[] row, BitSet includedColumns) {
return tableSchema.keyFromColumnData(row);
}
@Override
public Struct inserted(Serializable[] row, BitSet includedColumns) {
return tableSchema.valueFromColumnData(row);
}
@Override
public Struct updated(Serializable[] before, BitSet includedColumns, Serializable[] after,
BitSet includedColumnsBeforeUpdate) {
return tableSchema.valueFromColumnData(after);
}
@Override
public Struct deleted(Serializable[] deleted, BitSet includedColumns) {
return null; // tableSchema.valueFromColumnData(row);
}
};
convertersByTableId.put(tableNumber, converter);
// 更新表名到表号的映射,如果表名已存在,移除旧的表号对应的转换器
Long previousTableNumber = tableNumbersByTableName.put(tableName, tableNumber);
if (previousTableNumber != null) {
convertersByTableId.remove(previousTableNumber);
}
} else if (logger.isDebugEnabled()) {
logger.debug("Skipping update table metadata event: {}", event);
}
}2 handleInsert
/**
* 处理插入事件的方法
*
* @param event 数据库事件,包含插入信息
* @param source 事件源信息,用于记录分区和偏移量
* @param recorder 消费者,用于处理转换后的源记录
*/
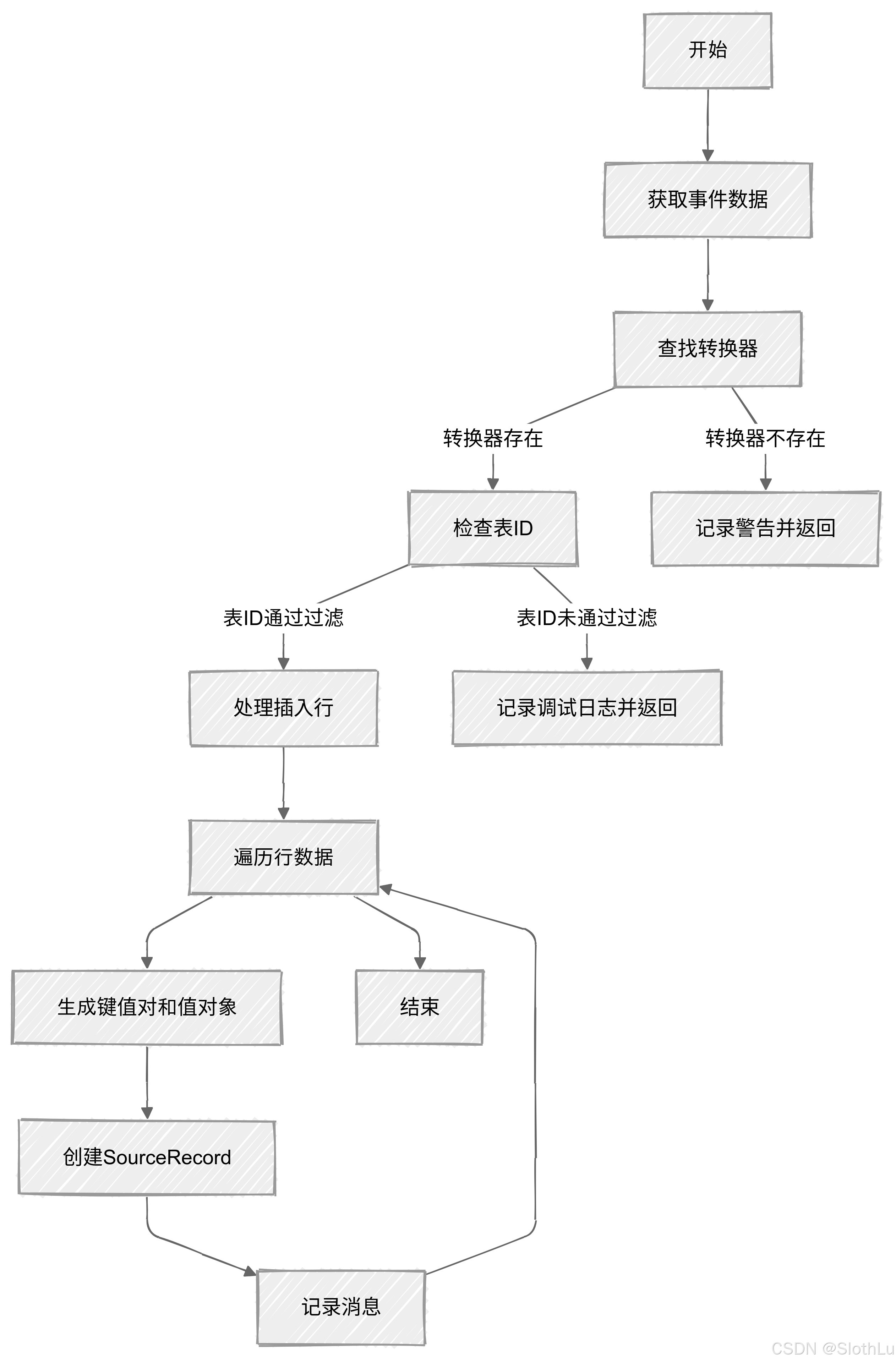
public void handleInsert(Event event, SourceInfo source, Consumer<SourceRecord> recorder) {
// 获取事件中的插入数据
WriteRowsEventData write = event.getData();
// 获取表ID
long tableNumber = write.getTableId();
// 获取包含的列信息
BitSet includedColumns = write.getIncludedColumns();
// 根据表ID获取相应的转换器
Converter converter = convertersByTableId.get(tableNumber);
// 如果找到对应的转换器
if (converter != null) {
// 获取表的唯一标识
TableId tableId = converter.tableId();
// 如果表符合过滤条件,则处理该插入事件
if (tableFilter.test(tableId)) {
logger.debug("Processing insert row event for {}: {}", tableId, event);
// 获取主题和分区信息
String topic = converter.topic();
Integer partition = converter.partition();
// 获取所有插入的行
List<Serializable[]> rows = write.getRows();
// 遍历每一行
for (int row = 0; row != rows.size(); ++row) {
Serializable[] values = rows.get(row);
// 获取键的模式和值
Schema keySchema = converter.keySchema();
Object key = converter.createKey(values, includedColumns);
// 获取值的模式和转换后的值
Schema valueSchema = converter.valueSchema();
Struct value = converter.inserted(values, includedColumns);
// 如果值或键不为空,则创建源记录并传递给消费者
if (value != null || key != null) {
SourceRecord record = new SourceRecord(source.partition(), source.offset(row), topic, partition,
keySchema, key, valueSchema, value);
recorder.accept(record);
}
}
} else if (logger.isDebugEnabled()) {
logger.debug("Skipping insert row event: {}", event);
}
} else {
logger.warn("Unable to find converter for table #{} in {}", tableNumber, convertersByTableId);
}
}
3 handleUpdate
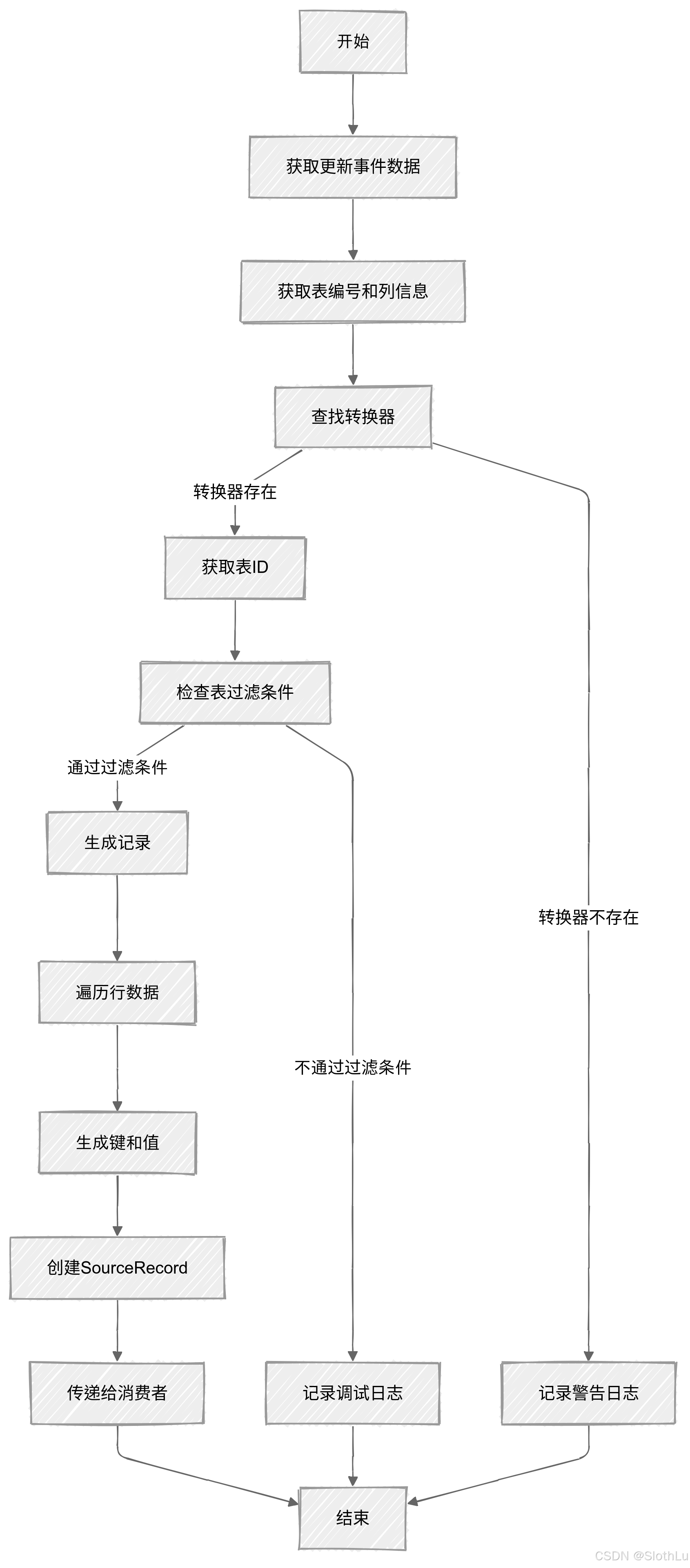
public void handleUpdate(Event event, SourceInfo source, Consumer<SourceRecord> recorder) {
UpdateRowsEventData update = event.getData();
long tableNumber = update.getTableId();
BitSet includedColumns = update.getIncludedColumns();
BitSet includedColumnsBefore = update.getIncludedColumnsBeforeUpdate();
Converter converter = convertersByTableId.get(tableNumber);
if (converter != null) {
TableId tableId = converter.tableId();
if (tableFilter.test(tableId)) {
logger.debug("Processing update row event for {}: {}", tableId, event);
String topic = converter.topic();
Integer partition = converter.partition();
List<Entry<Serializable[], Serializable[]>> rows = update.getRows();
for (int row = 0; row != rows.size(); ++row) {
Map.Entry<Serializable[], Serializable[]> changes = rows.get(row);
Serializable[] before = changes.getKey();
Serializable[] after = changes.getValue();
Schema keySchema = converter.keySchema();
Object key = converter.createKey(after, includedColumns);
Schema valueSchema = converter.valueSchema();
Struct value = converter.updated(before, includedColumnsBefore, after, includedColumns);
if (value != null || key != null) {
SourceRecord record = new SourceRecord(source.partition(), source.offset(row), topic, partition,
keySchema, key, valueSchema, value);
recorder.accept(record);
}
}
} else if (logger.isDebugEnabled()) {
logger.debug("Skipping update row event: {}", event);
}
} else {
logger.warn("Unable to find converter for table #{} in {}", tableNumber, convertersByTableId);
}
}
4 handleDelete
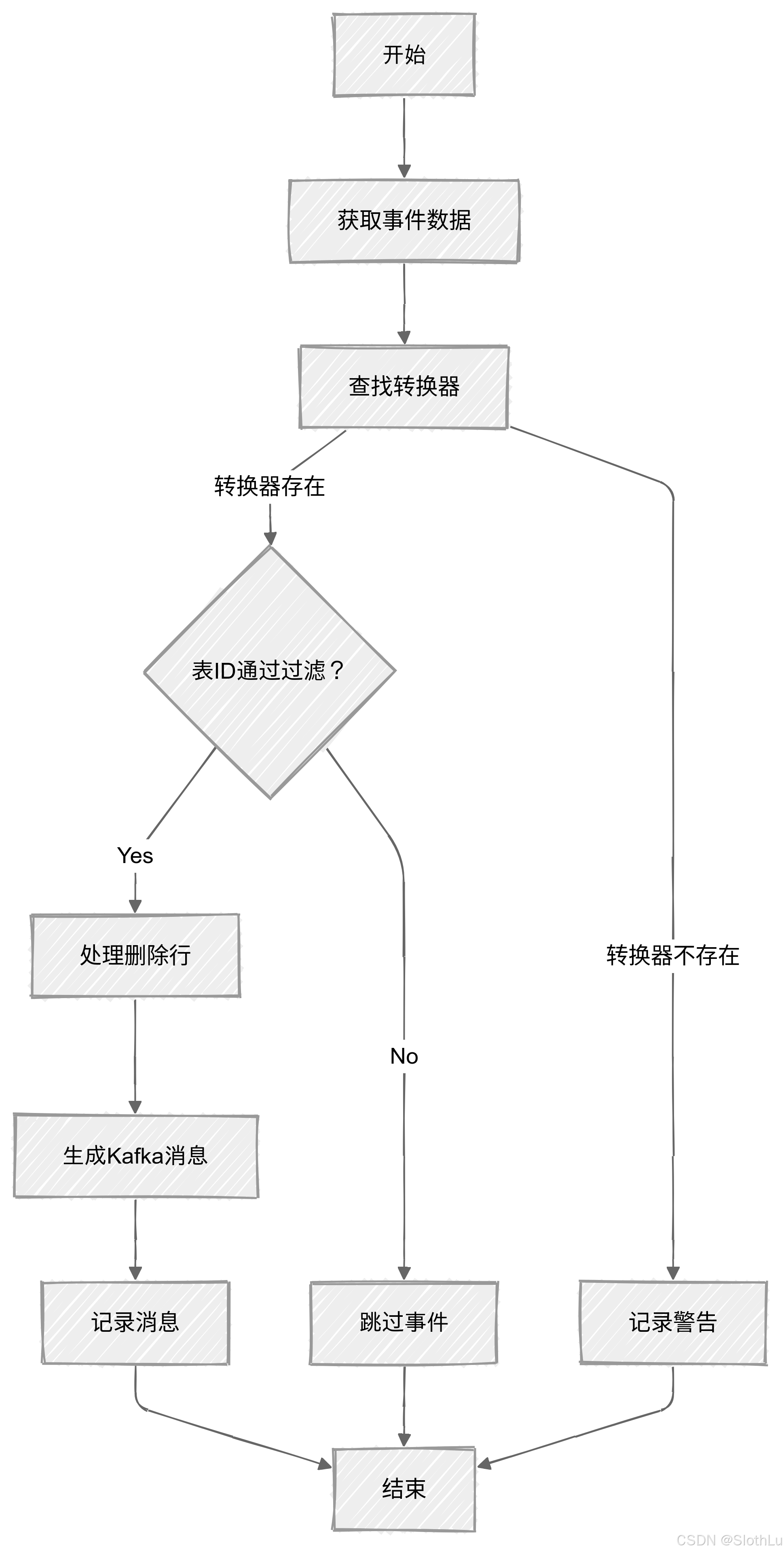
public void handleDelete(Event event, SourceInfo source, Consumer<SourceRecord> recorder) {
DeleteRowsEventData deleted = event.getData();
long tableNumber = deleted.getTableId();
BitSet includedColumns = deleted.getIncludedColumns();
Converter converter = convertersByTableId.get(tableNumber);
if (converter != null) {
TableId tableId = converter.tableId();
if (tableFilter.test(tableId)) {
logger.debug("Processing delete row event for {}: {}", tableId, event);
String topic = converter.topic();
Integer partition = converter.partition();
List<Serializable[]> rows = deleted.getRows();
for (int row = 0; row != rows.size(); ++row) {
Serializable[] values = rows.get(row);
Schema keySchema = converter.keySchema();
Object key = converter.createKey(values, includedColumns);
Schema valueSchema = converter.valueSchema();
Struct value = converter.deleted(values, includedColumns);
if (value != null || key != null) {
if ( value == null ) valueSchema = null;
SourceRecord record = new SourceRecord(source.partition(), source.offset(row), topic, partition,
keySchema, key, valueSchema, value);
recorder.accept(record);
}
}
} else if (logger.isDebugEnabled()) {
logger.debug("Skipping delete row event: {}", event);
}
} else {
logger.warn("Unable to find converter for table #{} in {}", tableNumber, convertersByTableId);
}
}
5 Converter
protected static interface Converter {
TableId tableId();
String topic();
Integer partition();
Schema keySchema();
Schema valueSchema();
Object createKey(Serializable[] row, BitSet includedColumns);
Struct inserted(Serializable[] row, BitSet includedColumns);
Struct updated(Serializable[] before, BitSet includedColumns, Serializable[] after, BitSet includedColumnsBeforeUpdate);
Struct deleted(Serializable[] deleted, BitSet includedColumns);
}
小结
- 初始化:构造函数中初始化了日志记录器、数据库历史记录、主题选择器、DDL解析器等组件。
- 加载表信息:loadTables 方法加载现有的表信息并创建表模式。
- 处理日志旋转:rotateLogs 方法处理日志旋转事件,清空转换器缓存。
- 处理表更新命令:updateTableCommand 方法处理DDL语句,更新表结构并记录历史。
- 更新表元数据:updateTableMetadata 方法处理表元数据更新事件,创建并注册新的转换器。
- 处理插入、更新和删除事件:handleInsert、handleUpdate 和 handleDelete 方法分别处理插入、更新和删除事件,生成相应的Kafka源记录。