前言
本次比赛前期花费的时间精力很多,但是到后期陷入了瓶颈,无法再提高精度。单纯修改优化模型的收益比不上挖掘特征的收益,并且训练时间很长。而且到后期很难再挖出新的有效的特征来,有些有效的特征组合再一起,效果反而变差了。由于后期事务繁多,也没有时间继续研究了,成绩不是很好,但是这个过程还是收益颇多,所以写博客记录下来。
比赛背景
任务
开发一个模型,该模型能够使用来自订单簿和股票收盘竞价的数据来预测数百只纳斯达克上市股票的收盘价走势。
评估
预测值和目标值的平均绝对误差 (MAE):
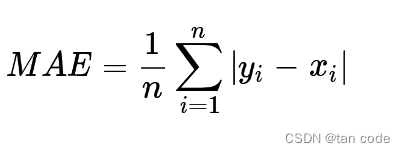
数据说明
-
stock_id - 股票的唯一标识符。
-
date_id - 日期的唯一标识符。日期ID在所有股票中都是连续的和一致的。
-
imbalance_size - 以当前参考价格(美元计)不匹配的金额。
-
imbalance_buy_sell_flag- 反映竞价失衡方向的指标。
买方失衡;1
卖方失衡;-1
无不平衡;0 -
reference_price - 成对份额最大化、不平衡最小化以及与买卖中点的距离最小化的价格,按此顺序排列。也可以认为等于最佳买入价和卖出价之间的近价。
-
matched_size - 可以按当前参考价格(美元)匹配的金额。
-
far_price - 仅根据拍卖利息最大化匹配的股票数量的交叉价格。此计算不包括连续市价单。
-
near_price- 交叉价格,将最大化基于竞价和连续市价订单匹配的股票数量。
-
[bid/ask]_price- 非拍卖账簿中最具竞争力的买入/卖出水平的价格。
-
[bid/ask]_size- 非拍卖账簿中最具竞争力的买入/卖出水平的美元名义金额。
-
wap- 非拍卖账簿中的加权平均价格。
-
seconds_in_bucket- 自当天收盘竞价开始以来经过的秒数,始终从 0 开始。
-
target- 股票波动的 60 秒未来走势减去合成指数的 60 秒未来走势。 仅供训练组使用。
- 综合指数是Optiver为本次比赛构建的纳斯达克上市股票的定制加权指数。
- 目标的单位是基点,这是金融市场中常见的计量单位。1个基点的价格变动相当于0.01%的价格变动。
- 其中 t 是当前观测值的时间,我们可以定义目标:
前面是从网站上copy来的,可能需要一点电子订单簿,电子交易过程的前置知识。由于不是重点,就不赘述。
下面进入代码,结合代码说明一些做法
1.初始化的相关工作
1.1 导入库,设置flag
import gc
import os
import time
import warnings
from itertools import combinations
from warnings import simplefilter
import joblib
import lightgbm as lgb
import numpy as np
import pandas as pd
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import KFold, TimeSeriesSplit
import polars as pl
warnings.filterwarnings("ignore")
simplefilter(action="ignore", category=pd.errors.PerformanceWarning)
is_offline = False
LGB = True
NN = False
is_train = True
is_infer = True
max_lookback = np.nan
split_day = 435
由于训练和提交,是不同的代码,我们提前训练好后模型后,直接把这个模型进行提交,用来预测,不需要在提交后重新训练,所以用 is_train, is_infer, is_offline这几个标志来进行相关的控制。
1.2 加载数据和预处理
df = pd.read_csv("/kaggle/input/optiver-trading-at-the-close/train.csv")
df = df.dropna(subset=["target"])
df.reset_index(drop=True, inplace=True)
df_shape = df.shape
这里缺失数据有多种处理方法,比如用均值填充,填充为了0等等,我尝试过构建模型,将不缺少的部分作为训练集,缺失部分作为目标,用训练的模型得到的结果来填充,但是效果不佳。
1.3 内存优化
本次数据集相当大,如果没有使用内存优化,会导致训练过程中内存用完的情况出现。
主要的思想是,将一些像double等所占内存大的类型,在保证精度的前提下,转换成所占内存小的类型,例如:
double a = 1 ----> int a = 1
def reduce_mem_usage(df, verbose=0):
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtype
if col_type != object:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float32)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float32)
if verbose:
logger.info(f"Memory usage of dataframe is {start_mem:.2f} MB")
end_mem = df.memory_usage().sum() / 1024**2
logger.info(f"Memory usage after optimization is: {end_mem:.2f} MB")
decrease = 100 * (start_mem - end_mem) / start_mem
logger.info(f"Decreased by {decrease:.2f}%")
return df
从上面也能总结出一些内存相关函数的使用方法
start_mem = df.memory_usage().sum() / 1024**2
1.4 并行计算
为了提高计算速度,减少模型运行时间,采用并行计算,这里只对 imbalance采用了,原因是在python中并行计算的一些限制。
from numba import njit, prange
@njit(parallel=True)
def compute_triplet_imbalance(df_values, comb_indices):
num_rows = df_values.shape[0]
num_combinations = len(comb_indices)
imbalance_features = np.empty((num_rows, num_combinations))
for i in prange(num_combinations):
a, b, c = comb_indices[i]
for j in range(num_rows):
max_val = max(df_values[j, a], df_values[j, b], df_values[j, c])
min_val = min(df_values[j, a], df_values[j, b], df_values[j, c])
mid_val = df_values[j, a] + df_values[j, b] + df_values[j, c] - min_val - max_val
if mid_val == min_val:
imbalance_features[j, i] = np.nan
else:
imbalance_features[j, i] = (max_val - mid_val) / (mid_val - min_val)
return imbalance_features
def calculate_triplet_imbalance_numba(price, df):
df_values = df[price].values
comb_indices = [(price.index(a), price.index(b), price.index(c)) for a, b, c in combinations(price, 3)]
features_array = compute_triplet_imbalance(df_values, comb_indices)
columns = [f"{a}_{b}_{c}_imb2" for a, b, c in combinations(price, 3)]
features = pd.DataFrame(features_array, columns=columns)
return features
2. 特征生成
2.1 股票权重
weights = [
0.004, 0.001, 0.002, 0.006, 0.004, 0.004, 0.002, 0.006, 0.006, 0.002, 0.002, 0.008,
0.006, 0.002, 0.008, 0.006, 0.002, 0.006, 0.004, 0.002, 0.004, 0.001, 0.006, 0.004,
0.002, 0.002, 0.004, 0.002, 0.004, 0.004, 0.001, 0.001, 0.002, 0.002, 0.006, 0.004,
0.004, 0.004, 0.006, 0.002, 0.002, 0.04 , 0.002, 0.002, 0.004, 0.04 , 0.002, 0.001,
0.006, 0.004, 0.004, 0.006, 0.001, 0.004, 0.004, 0.002, 0.006, 0.004, 0.006, 0.004,
0.006, 0.004, 0.002, 0.001, 0.002, 0.004, 0.002, 0.008, 0.004, 0.004, 0.002, 0.004,
0.006, 0.002, 0.004, 0.004, 0.002, 0.004, 0.004, 0.004, 0.001, 0.002, 0.002, 0.008,
0.02 , 0.004, 0.006, 0.002, 0.02 , 0.002, 0.002, 0.006, 0.004, 0.002, 0.001, 0.02,
0.006, 0.001, 0.002, 0.004, 0.001, 0.002, 0.006, 0.006, 0.004, 0.006, 0.001, 0.002,
0.004, 0.006, 0.006, 0.001, 0.04 , 0.006, 0.002, 0.004, 0.002, 0.002, 0.006, 0.002,
0.002, 0.004, 0.006, 0.006, 0.002, 0.002, 0.008, 0.006, 0.004, 0.002, 0.006, 0.002,
0.004, 0.006, 0.002, 0.004, 0.001, 0.004, 0.002, 0.004, 0.008, 0.006, 0.008, 0.002,
0.004, 0.002, 0.001, 0.004, 0.004, 0.004, 0.006, 0.008, 0.004, 0.001, 0.001, 0.002,
0.006, 0.004, 0.001, 0.002, 0.006, 0.004, 0.006, 0.008, 0.002, 0.002, 0.004, 0.002,
0.04 , 0.002, 0.002, 0.004, 0.002, 0.002, 0.006, 0.02 , 0.004, 0.002, 0.006, 0.02,
0.001, 0.002, 0.006, 0.004, 0.006, 0.004, 0.004, 0.004, 0.004, 0.002, 0.004, 0.04,
0.002, 0.008, 0.002, 0.004, 0.001, 0.004, 0.006, 0.004,
]
weights = {int(k):v for k,v in enumerate(weights)}
股票权重怎么生成的?
import numpy as np
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from tqdm import tqdm
data = pd.read_parquet("train.parquet")
num_stocks = data["stock_id"].nunique()
num_dates = data["date_id"].nunique()
num_updates = data["seconds_in_bucket"].nunique()
print(f"# stocks : {num_stocks}")
print(f"# dates : {num_dates}")
print(f"# updates per day: {num_updates}")
stock_returns = np.zeros((num_stocks, num_dates, num_updates))
index_returns = np.zeros((num_stocks, num_dates, num_updates))
for (stock_id, date_id), frame in tqdm(data.groupby(["stock_id", "date_id"])):
frame["stock_return"] = ((frame["wap"] / frame["wap"].shift(6)).shift(-6) - 1) * 10_000
frame["index_return"] = frame["stock_return"] - frame["target"]
stock_returns[stock_id, date_id] = frame["stock_return"].values
index_returns[stock_id, date_id] = frame["index_return"].values
index_return = np.mean(index_returns, axis=0)
lr = LinearRegression()
y = index_return.reshape(-1)
X = stock_returns.reshape((num_stocks, -1)).T
mask = ~((np.isnan(y) | np.isnan(X).any(axis=1)))
X, y = X[mask], y[mask]
lr.fit(X, y)
print(" Fit ".center(80, ">"))
print("Coef:", lr.coef_)
print("Intercept:", lr.intercept_)
print("R2:", r2_score(y, lr.predict(X)))
lr.coef_ = lr.coef_.round(3)
lr.intercept_ = 0.0
print(" Round with 3 digits ".center(80, ">"))
print("Coef:", lr.coef_)
print("Sum of Coef:", lr.coef_.sum())
print("R2:", r2_score(y, lr.predict(X)))
使用的方法是线性回归模型。线性回归模型是一种用于预测目标变量(在这里是股票指数收益率)与一个或多个特征变量(在这里是股票收益率)之间关系的统计模型。
我们希望通过股票的收益率来预测股票指数收益率,并根据预测结果来确定每个股票在投资组合中的权重。
具体步骤如下:
- 计算每个股票在每个日期的每次交易的收益率和指数收益率。
- 计算了指数收益率的平均值,作为目标变量。
- 将股票收益率作为特征变量,建立线性回归模型。
- 使用线性回归模型来拟合数据,通过拟合得到的回归系数(权重)来估计每个股票在投资组合中的比重。
- 输出了拟合结果,包括每个股票的权重、截距和拟合的准确程度(R2分数)。
通过使用线性回归模型,可以根据股票的历史收益率来估计它对整个投资组合的贡献程度,从而确定股票的权重。这样可以帮助在投资决策中合理分配资金,以达到预期的风险和收益目标。
2.2 主要特征
首先对训练集中给出的主要特征分为价格类和数量类
def imbalance_features(df):
# Define lists of price and size-related column names
prices = ["reference_price", "far_price", "near_price", "ask_price", "bid_price", "wap"]
sizes = ["matched_size", "bid_size", "ask_size", "imbalance_size"]
按我个人的理解,数量特征更为重要,由于是在高频市场,大量的不平衡订单会使人们涌入另外一端。
第一部分,特征之间的简单计算,加减乘除。当然得到的新特征在现实世界是有一定的物理意义的,如 ask_x_size 对应的时候卖端收入的总金额。
# V0
df['imbalance_ratio'] = df.eval('imbalance_size / matched_size') # 重要性中等
df["imbalance_buy_sell_size"] = df.eval("imbalance_buy_sell_flag * imbalance_size") # 重要性高
df["bid_price_over_ask_price"] = df.eval("bid_price / ask_price") # 这重要性高
df['bid_ask_volume_diff'] = df.eval("ask_size - bid_size") # 低
df['ask_x_size'] = df.eval("ask_size * ask_price")
df['bid_x_size'] = df.eval("bid_size * bid_price")
# V1
df["volume"] = df.eval("ask_size + bid_size")
df["mid_price"] = df.eval("(ask_price + bid_price) / 2")
df["liquidity_imbalance"] = df.eval("(bid_size-ask_size)/(bid_size+ask_size)")
df["matched_imbalance"] = df.eval("(imbalance_size-matched_size)/(matched_size+imbalance_size)")
df["size_imbalance"] = df.eval("bid_size / ask_size")
for c in combinations(prices, 2):
df[f"{c[0]}_{c[1]}_imb"] = df.eval(f"({c[0]} - {c[1]})/({c[0]} + {c[1]})")
for c in [['ask_price', 'bid_price', 'wap', 'reference_price'], sizes]:
triplet_feature = calculate_triplet_imbalance_numba(c, df)
df[triplet_feature.columns] = triplet_feature.values
第二部分是利用金融知识构造的特征,包括有:
- 股票权重
- 加权wap
- wap动量
- 不均衡动量
- 市场紧急性
- 深度压力
-等等
# V2
df["stock_weights"] = df["stock_id"].map(weights)
df["weighted_wap"] = df["stock_weights"] * df["wap"]
df['wap_momentum'] = df.groupby('stock_id')['weighted_wap'].pct_change(periods=6)
df["imbalance_momentum"] = df.groupby(['stock_id'])['imbalance_size'].diff(periods=1) / df['matched_size']
df["price_spread"] = df["ask_price"] - df["bid_price"]
df["spread_intensity"] = df.groupby(['stock_id'])['price_spread'].diff()
df['price_pressure'] = df['imbalance_size'] * (df['ask_price'] - df['bid_price'])
df['market_urgency'] = df['price_spread'] * df['liquidity_imbalance']
df['depth_pressure'] = (df['ask_size'] - df['bid_size']) * (df['far_price'] - df['near_price'])
df['spread_depth_ratio'] = (df['ask_price'] - df['bid_price']) / (df['bid_size'] + df['ask_size'])
df['mid_price_movement'] = df['mid_price'].diff(periods=5).apply(lambda x: 1 if x > 0 else (-1 if x < 0 else 0))
df['micro_price'] = ((df['bid_price'] * df['ask_size']) + (df['ask_price'] * df['bid_size'])) / (df['bid_size'] + df['ask_size'])
df['relative_spread'] = (df['ask_price'] - df['bid_price']) / df['wap']
加上一些统计特征
# Calculate various statistical aggregation features
for func in ["mean", "std", "skew", "kurt"]:
df[f"all_prices_{func}"] = df[prices].agg(func, axis=1)
df[f"all_sizes_{func}"] = df[sizes].agg(func, axis=1)
滑动窗口,滚动特征
# V3
#for col in ['matched_size', 'imbalance_size', 'reference_price', 'imbalance_buy_sell_flag']:
for col in ['matched_size', 'reference_price', 'imbalance_buy_sell_size']:
for window in [1,3,5,10]:
df[f"{col}_shift_{window}"] = df.groupby('stock_id')[col].shift(window)
df[f"{col}_ret_{window}"] = df.groupby('stock_id')[col].pct_change(window)
# Calculate diff features for specific columns
for col in ['ask_price', 'bid_price', 'ask_size', 'bid_size', 'weighted_wap','price_spread']:
for window in [1,3,5,10]:
df[f"{col}_diff_{window}"] = df.groupby("stock_id")[col].diff(window)
#V4 feature
for window in [3,5,10]:
df[f'price_change_diff_{window}'] = df[f'bid_price_diff_{window}'] - df[f'ask_price_diff_{window}']
df[f'size_change_diff_{window}'] = df[f'bid_size_diff_{window}'] - df[f'ask_size_diff_{window}']
#V5 - rolling diff
# Convert from pandas to Polars
pl_df = pl.from_pandas(df)
#Define the windows and columns for which you want to calculate the rolling statistics
windows = [3, 5, 10]
columns = ['ask_price', 'bid_price', 'ask_size', 'bid_size']
# prepare the operations for each column and window
group = ["stock_id"]
expressions = []
# Loop over each window and column to create the rolling mean and std expressions
for window in windows:
for col in columns:
rolling_mean_expr = (
pl.col(f"{col}_diff_{window}")
.rolling_mean(window)
.over(group)
.alias(f'rolling_diff_{col}_{window}')
)
rolling_std_expr = (
pl.col(f"{col}_diff_{window}")
.rolling_std(window)
.over(group)
.alias(f'rolling_std_diff_{col}_{window}')
)
expressions.append(rolling_mean_expr)
expressions.append(rolling_std_expr)
2.3 其他特征
主要是时间特征。如:
- 星期几
- 分
- 秒
- 相对收盘时间的距离
def other_features(df):
df["dow"] = df["date_id"] % 5 # Day of the week
df["seconds"] = df["seconds_in_bucket"] % 60
df["minute"] = df["seconds_in_bucket"] // 60
df['time_to_market_close'] = 540 - df['seconds_in_bucket']
for key, value in global_stock_id_feats.items():
df[f"global_{key}"] = df["stock_id"].map(value.to_dict())
return df