基于LangChain-Chatchat实现的RAG-本地知识库的问答应用[1]-最新版快速实践并部署(检索增强生成RAG大模型)

基于 ChatGLM 等大语言模型与 Langchain 等应用框架实现,开源、可离线部署的检索增强生成(RAG)大模型知识库项目。
1.介绍
-
一种利用 langchain思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
-
建立了全流程可使用开源模型实现的本地知识库问答应用。本项目的最新版本中通过使用 FastChat接入 Vicuna, Alpaca, LLaMA, Koala, RWKV 等模型,依托于 langchain框架支持通过基于 FastAPI 提供的 API用服务,或使用基于 Streamlit 的 WebUI 进行操作。
-
依托于本项目支持的开源 LLM 与 Embedding 模型,本项目可实现全部使用开源模型离线私有部署。与此同时,本项目也支持OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
-
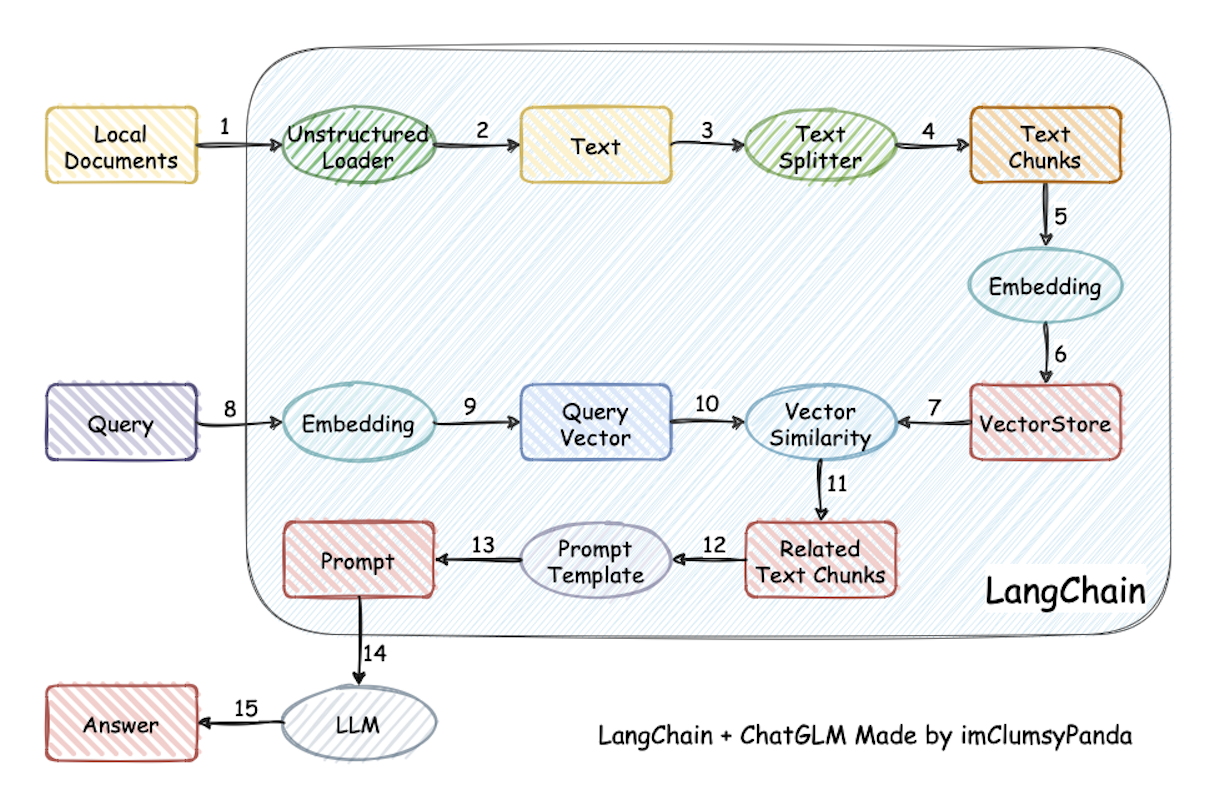
本项目实现原理如下图所示,过程包括加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 ->
在文本向量中匹配出与问句向量最相似的top k个 -> 匹配出的文本作为上下文和问题一起添加到prompt中 -> 提交给LLM生成回答。
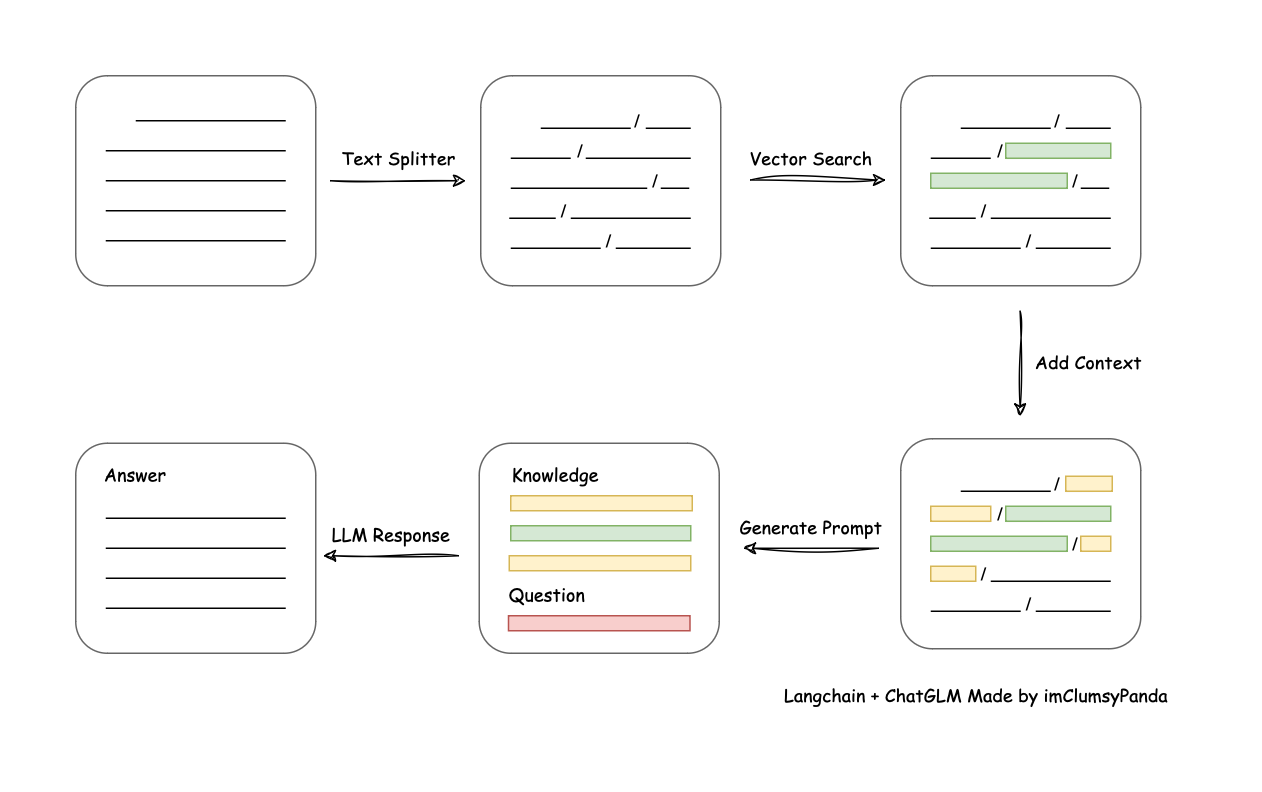
从文档处理角度来看,实现流程如下:
-
本项目未涉及微调、训练过程,但可利用微调或训练对本项目效果进行优化。
-
AutoDL 镜像 中
0.2.10版本所使用代码已更新至本项目v0.2.10版本。 -
Docker 镜像 已经更新到
0.2.10版本。 -
本次更新后同时支持DockerHub、阿里云、腾讯云镜像源:
docker run -d --gpus all -p 80:8501 isafetech/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 uswccr.ccs.tencentyun.com/chatchat/chatchat:0.2.10
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.10
本项目有一个非常完整的Wiki , README只是一个简单的介绍,仅仅是入门教程,能够基础运行。如果你想要更深入的了解本项目,或者想对本项目做出贡献。请移步 Wiki界面
2. 解决的痛点
该项目是一个可以实现 __完全本地化__推理的知识库增强方案, 重点解决数据安全保护,私域化部署的企业痛点。本开源方案采用Apache License,可以免费商用,无需付费。
支持市面上主流的本地大语言模型和Embedding模型,支持开源的本地向量数据库。支持列表详见Wiki
3.快速实现案例
3.0 软硬件要求
推荐系统配置配置
- Linux Ubuntu 22.04.5 kernel version 6.7 其他系统可能出现系统兼容性问题。
最低要求
该要求仅针对标准模式,轻量模式使用在线模型,不需要安装 torch 等库,也不需要显卡即可运行。
- Python 版本: >= 3.8(很不稳定), < 3.12
- CUDA 版本: >= 12.1
推荐要求
开发者在以下环境下进行代码调试,在该环境下能够避免最多环境问题。
- Python 版本 == 3.11.7
- CUDA 版本: == 12.1
本框架使用 fschat驱动,统一使用 huggingface进行推理,其他推理方式 (如 llama-cpp,TensorRT加速引擎 建议通过推理引擎以 API 形式接入框架)。
同时, 没有对 Int4 模型进行适配,不保证Int4模型能够正常运行。因此,量化版本暂时需要由开发者自行适配, 可能在未来放。
如果想要顺利在 GPU 运行本地模型的 FP16 版本,你至少需要以下的硬件配置,来保证在框架下能够实现 稳定连续对话
- ChatGLM3-6B & LLaMA-7B-Chat 等 7B 模型
- 最低显存要求: 14GB
- 推荐显卡: RTX 4080
- Qwen-14B-Chat 等 14B 模型
- 最低显存要求: 30GB
- 推荐显卡: V100
- Yi-34B-Chat 等 34B 模型
- 最低显存要求: 69GB
- 推荐显卡: A100
- Qwen-72B-Chat 等 72B 模型
- 最低显存要求: 145GB
- 推荐显卡:多卡 A100 以上
一种简单的估算方式为:
FP16: 显存占用(GB) = 模型量级 x 2
Int4: 显存占用(GB) = 模型量级 x 0.75
以上数据仅为估算,实际情况以 nvidia-smi 占用为准。 请注意,如果使用最低配置,仅能保证代码能够运行,但运行速度较慢,体验不佳。
同时,Embedding 模型将会占用 1-2G 的显存,历史记录最多会占用 数 GB 的显存,因此,需要多冗余一些显存。内存最低要求: 内存要求至少应该比模型运行的显存大。
例如,运行 ChatGLM3-6B
FP16模型,显存占用 13G,推荐使用 16G 以上内存。
3.1. 环境配置
- 首先,确保你的机器安装了 Python 3.8 - 3.11 (强烈推荐使用 Python3.11)。
python --version
Python 3.11.7
接着,创建一个虚拟环境,并在虚拟环境内安装项目的依赖
# 如果低于这个版本,可使用conda安装环境
conda create -p /your_path/env_name python=3.11
# 激活环境
source activate /your_path/env_name
# 或,conda安装,不指定路径, 注意以下,都将/your_path/env_name替换为env_name
conda create -n env_name python=3.11
conda activate env_name # Activate the environment
# 更新py库
pip3 install --upgrade pip
# 关闭环境
source deactivate /your_path/env_name
# 删除环境
conda env remove -p /your_path/env_name
接着,开始安装项目的依赖
#拉取仓库
git clone https://github.com/chatchat-space/Langchain-Chatchat.git
#进入目录
cd Langchain-Chatchat
#安装全部依赖
pip install -r requirements.txt
# 默认依赖包括基本运行环境(FAISS向量库)。以下是可选依赖:
- 如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果要开启 OCR GPU 加速,请安装 rapidocr_paddle[gpu]
- 如果要使用在线 API 模型,请安装对用的 SDK
此外,为方便用户 API 与 webui 分离运行,可单独根据运行需求安装依赖包。
- 如果只需运行 API,可执行:
$ pip install -r requirements_api.txt
# 默认依赖包括基本运行环境(FAISS向量库)。如果要使用 milvus/pg_vector 等向量库,请将 requirements.txt 中相应依赖取消注释再安装。
- 如果只需运行 WebUI,可执行:
$ pip install -r requirements_webui.txt
注:使用 langchain.document_loaders.UnstructuredFileLoader进行 .docx 等格式非结构化文件接入时,可能需要依据文档进行其他依赖包的安装,
需要注意的是,对于以下依赖,建议源码安装依赖或者定期检查是否为最新版本,的框架可能会大量使用这些依赖的最新特性。
-
transformers
-
fastchat
-
fastapi
-
streamlit 以及其组件
-
langchain 以及其组件
-
xformers
-
如果在安装"pip install -r requirements.txt "遇到报错:
distutils.errors.DistutilsError: Command '['/Users/didiyu/ENTER/envs/chain/bin/python', '-m', 'pip', '--disable-pip-version-check', 'wheel', '--no-deps', '-w', '/var/folders/yd/mp5rd9bx1x3670cth1fp7n180000gn/T/tmpkl7z5ekl', '--quiet', 'setuptools_scm']' returned non-zero exit status 1.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: metadata-generation-failed
× Encountered error while generating package metadata.
╰─> See above for output.
note: This is an issue with the package mentioned above, not pip.
hint: See above for details.
- 解决方案
step1: pip install setuptools_scm
step 2: pip install wavedrom -i https://pypi.tuna.tsinghua.edu.cn/simple
- 参考链接:
-
https://github.com/chatchat-space/Langchain-Chatchat/issues/1268
-
https://github.com/chatchat-space/Langchain-Chatchat/issues/2054
-
请注意,LangChain-Chatchat
0.2.x系列是针对 Langchain0.0.x系列版本的,如果你使用的是 Langchain0.1.x系列版本,需要降级您的Langchain版本。
3.2. 模型下载
如需在本地或离线环境下运行本项目,需要首先将项目所需的模型下载至本地,通常开源 LLM 与 Embedding模型可以从 HuggingFace 下载。
以本项目中默认使用的 LLM 模型 THUDM/ChatGLM3-6B 与 Embedding模型 BAAI/bge-large-zh 为例:
下载模型需要先安装 Git LFS
,然后运行
Git 是分布式 版本控制系统,这意味着在克隆过程中会将仓库的整个历史记录传输到客户端。对于包涵大文件(尤其是经常被修改的大文件)的项目,初始克隆需要大量时间,因为客户端会下载每个文件的每个版本。Git LFS(Large File Storage)是由 Atlassian, GitHub 以及其他开源贡献者开发的 Git 扩展,它通过延迟地(lazily)下载大文件的相关版本来减少大文件在仓库中的影响,具体来说,大文件是在 checkout 的过程中下载的,而不是 clone 或 fetch 过程中下载的(这意味着你在后台定时 fetch 远端仓库内容到本地时,并不会下载大文件内容,而是在你 checkout 到工作区的时候才会真正去下载大文件的内容)。

Git LFS 通过将仓库中的大文件替换为微小的指针(pointer) 文件来做到这一点。在正常使用期间,你将永远不会看到这些指针文件,因为它们是由 Git LFS 自动处理的:
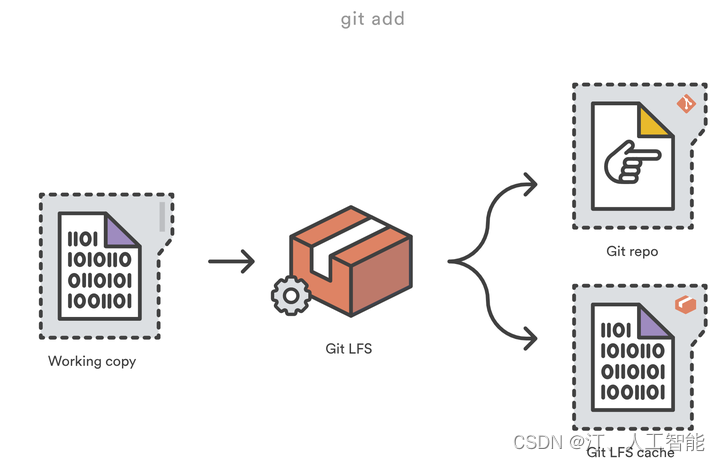
Git LFS 简介- Git LFS(Large File Storage)是 Git 的一个扩展,旨在解决 Git 处理大文件时遇到的问题。它由 Atlassian 公司开发,于 2015 年推出。
- Git LFS 的核心思想是将大文件存储在独立的远程服务器上,而不是直接存储在 Git 仓库中。在 Git 仓库中,只保留一个指向实际文件的指针,称为 LFS 指针。
- 当用户在本地进行 Git 操作时,如提交、推送或拉取,Git LFS 会拦截这些操作,并将实际的大文件上传或下载到远程 LFS 服务器,而 Git 仓库中只处理 LFS 指针。
- 通过这种方式,Git LFS 可以显著减小 Git 仓库的大小,加快克隆和拉取的速度,同时还能保持 Git 的分布式特性和版本控制功能。
安装 Git LFS:
首先,你需要确保 Git LFS 已经安装在你的系统上。你可以从 Git LFS 的官方 GitHub 仓库(https://github.com/git-lfs/git-lfs)下载并安装它,或者使用包管理器(如 apt, yum, brew 等)来安装。 例如,在 Debian/Ubuntu 系统上,你可以使用以下命令安装 Git LFS:
sudo apt-get update
sudo apt-get install git-lfs
初始化 Git LFS:
安装完 Git LFS 后,你可能需要在你的 Git 仓库中初始化它。在仓库的根目录下运行以下命令:
git lfs install
-
检查 Git LFS 是否已安装:
你可以通过运行 git lfs --version 来检查 Git LFS 是否已成功安装。如果返回了版本号,说明安装成功。git lfs --version #git-lfs/2.9.2 (GitHub; linux amd64; go 1.13.5)$ git clone https://huggingface.co/THUDM/chatglm3-6b $ git clone https://huggingface.co/BAAI/bge-large-zh
-
如果遇到模型下载缓慢的情况,可以从魔塔下载
-
chatglm3-6b: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
-
bge-large-zh-v1.5: https://modelscope.cn/models/AI-ModelScope/bge-large-zh-v1.5/files
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
git clone https://www.modelscope.cn/Xorbits/bge-large-zh.git
git clone https://www.modelscope.cn/AI-ModelScope/bge-large-zh-v1.5.git
3.3 Embedding模型介绍
FlagEmbedding专注于检索增强llm领域,目前包括以下项目:
- Long-Context LLM: Activation Beacon, LongLLM QLoRA
- Fine-tuning of LM : LM-Cocktail
- Embedding Model: Visualized-BGE, BGE-M3, LLM Embedder, BGE Embedding
- Reranker Model: llm rerankers, BGE Reranker
- Benchmark: C-MTEB
3.3.1 BGE-M3-多语言
(Paper, Code)
在这个项目中,发布了BGE-M3,它是第一个具有多功能、多语言和多粒度特性的文本检索模型。
- 多功能:可以同时执行三种检索功能:单向量检索、多向量检索和稀疏检索。
- 多语言:支持100多种工作语言。
- 多粒度:它能够处理不同粒度的输入,从短句子到长达8192个词汇的长文档。
在本项目中,为了提高单一检索模式的性能,提出了一种新的自知识蒸馏方法。
优化了批处理策略,支持大批处理大小,这可以在对长文本或大型语言模型进行向量微调时简单使用。
还构建了一个用于文档检索的数据集,并提出了一个简单的策略来提高长文本的建模能力。
训练代码和微调数据将在不久的将来开源。
3.3.2 Visualized-BGE-多模态
官方链接
在这个项目中,发布了Visualized-BGE。通过引入image token embedding,Visualized-BGE可以被用来编码混合图文数据。它可以被应用在广泛的多模态检索任务中,包括但不限于:多模态知识检索,多模态查询的图像检索等。
3.3.3 LongLLM QLoRA
通过 QLoRA 微调将 Llama-3-8B-Instruct 的上下文长度从 8K 扩展到 80K。 整个训练过程非常高效,在一台8xA800 (80G) GPU 机器上仅需要8个小时。 该模型在NIHS、主题检索和长上下文语言理解等广泛的评估任务中表现出卓越的性能; 同时,它在短上下文中也很好地保留了其原有的能力。 如此强大的长文本能力主要归因于GPT-4生成的仅3.5K合成数据,这表明LLM具有扩展其原始上下文的固有(但在很大程度上被低估)潜力。 事实上,一旦有更多的计算资源,该方法可以将上下文长度扩展更长。
3.3.4 Activation Beacon
由于有限的上下文窗口长度,有效利用长上下文信息是对大型语言模型的一个巨大挑战。
Activation Beacon 将 LLM 的原始激活压缩为更紧凑的形式,以便它可以在有限的上下文窗口中感知更长的上下文。它是一种有效、高效、兼容、低成本(训练)的延长LLM上下文长度的方法。
更多细节请参考技术报告和代码。
3.3.5 LM-Cocktail
模型合并被用于提高单模型的性能。发现这种方法对大型语言模型和文本向量模型也很有用, 并设计了”语言模型鸡尾酒“方案,其自动计算融合比例去融合基础模型和微调模型。利用LM-Cocktail可以缓解灾难性遗忘问题,即在不降低通用性能的情况下提高目标任务性能。通过构造少量数据样例,它还可以用于为新任务生成模型,而无需进行微调。它可以被使用来合并生成模型或向量模型。更多细节请参考技术报告和代码。
3.3.6 LLM Embedder
LLM-Embedder向量模型是根据LLM的反馈进行微调的。它可以支持大型语言模型的检索增强需求,包括知识检索、记忆检索、示例检索和工具检索。它在6个任务上进行了微调:问题回答,对话搜索,长对话,长文本建模、上下文学习和工具学习。更多细节请参考
3.3.7 BGE Reranker
交叉编码器将对查询和答案实时计算相关性分数,这比向量模型(即双编码器)更准确,但比向量模型更耗时。因此,它可以用来对嵌入模型返回的前k个文档重新排序。在多语言数据上训练了交叉编码器,数据格式与向量模型相同,因此您可以根据的示例 轻松地对其进行微调。更多细节请参考
提供了新版的交叉编码器,支持更多的语言以及更长的长度。使用的数据格式与向量模型类似,但是新增了prompt用于微调以及推理。您可以使用特定的层进行推理或使用完整的层进行推理,您可以根根据示例 轻松地对其进行微调。更多细节请参考
3.3.8 BGE Embedding
BGE Embedding是一个通用向量模型。 使用retromae 对模型进行预训练,再用对比学习在大规模成对数据上训练模型。**你可以按照的示例 在本地数据上微调嵌入模型。**还提供了一个预训练示例 。请注意,预训练的目标是重构文本,预训练后的模型无法直接用于相似度计算,需要进行微调之后才可以用于相似度计算。更多关于bge的训练情况请参阅论文和代码.
注意BGE使用CLS的表征作为整个句子的表示,如果使用了错误的方式(如mean pooling)会导致效果很差。
3.3.9 C-MTEB
中文向量榜单,已整合入MTEB中。更多细节参考 论文 和代码.
3.3.10 Embedding模型列表
| Model | Language | Description | query instruction for retrieval [1] | |
|---|---|---|---|---|
| BAAI/bge-m3 | Multilingual | 推理 微调 | 多功能(向量检索,稀疏检索,多表征检索)、多语言、多粒度(最大长度8192) | |
| LM-Cocktail | English | 微调的Llama和BGE模型,可以用来复现LM-Cocktail论文的结果 | ||
| BAAI/llm-embedder | English | 推理 微调 | 专为大语言模型各种检索增强任务设计的向量模型 | 详见 README |
| BAAI/bge-reranker-large | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-reranker-base | Chinese and English | 推理 微调 | 交叉编码器模型,精度比向量模型更高但推理效率较低 [2] | |
| BAAI/bge-large-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | English | 推理 微调 | 1.5版本,相似度分布更加合理 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chinese | 推理 微调 | 1.5版本,相似度分布更加合理 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | English | 推理 微调 | 向量模型,将文本转换为向量 | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | English | 推理 微调 | base-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | English | 推理 微调 | small-scale 向量模型 | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | Chinese | 推理 微调 | 向量模型,将文本转换为向量 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chinese | 推理 微调 | base-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | Chinese | 推理 微调 | small-scale 向量模型 | 为这个句子生成表示以用于检索相关文章: |
3.4 ChatGLM3-6B
ChatGLM3-6B 是 ChatGLM 系列最新一代的开源模型,在保留了前两代模型对话流畅、部署门槛低等众多优秀特性的基础上,ChatGLM3-6B 引入了如下特性:
- 更强大的基础模型: ChatGLM3-6B 的基础模型 ChatGLM3-6B-Base 采用了更多样的训练数据、更充分的训练步数和更合理的训练策略。在语义、数学、推理、代码、知识等不同角度的数据集上测评显示,ChatGLM3-6B-Base 具有在 10B 以下的预训练模型中最强的性能。
- 更完整的功能支持: ChatGLM3-6B 采用了全新设计的 Prompt 格式,除正常的多轮对话外。同时原生支持工具调用(Function Call)、代码执行(Code Interpreter)和 Agent 任务等复杂场景。
- 更全面的开源序列: 除了对话模型 ChatGLM3-6B 外,还开源了基础模型 ChatGLM-6B-Base、长文本对话模型 ChatGLM3-6B-32K。
pip install protobuf 'transformers>=4.30.2' cpm_kernels 'torch>=2.0' gradio mdtex2html sentencepiece accelerate
- 模型下载
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
- git下载
git lfs install
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
- 代码调用
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.0")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
3.5. 初始化知识库和配置文件
按照下列方式初始化自己的知识库和简单的复制配置文件 【第一次跑项目推荐使用简单】
$ python copy_config_example.py
$ python init_database.py --recreate-vs
当前项目的知识库信息存储在数据库中,在正式运行项目之前请先初始化数据库(我们强烈建议您在执行操作前备份您的知识文件)。
-
如果已经有创建过知识库,可以先执行以下命令创建或更新数据库表:
$ python init_database.py --create-tables如果可以正常运行,则无需再重建知识库。
-
如果是第一次运行本项目,知识库尚未建立,或者之前使用的是低于最新 master 分支版本的框架,或者配置文件中的知识库类型、嵌入模型发生变化,或者之前的向量库没有开启
normalize_L2,需要以下命令初始化或重建知识库:$ python init_database.py --recreate-vs
3.6 更多参数配置
在开始参数配置之前,先执行以下脚本
python copy_config_example.py
该脚本将会将所有config目录下的配置文件样例复制一份到config目录下,方便开发者进行配置。 接着,开发者可以根据自己的需求,对配置文件进行修改。
- 配置文件下内容
3.6.1 基础配置项 basic_config.py
该配置基负责记录日志的格式和储存路径,通常不需要修改。
- basic_config.py.example
import logging
import os
import langchain
import tempfile
import shutil
#是否显示详细日志
log_verbose = False
langchain.verbose = False
#通常情况下不需要更改以下内容
#日志格式
LOG_FORMAT = "%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s"
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logging.basicConfig(format=LOG_FORMAT)
#日志存储路径
LOG_PATH = os.path.join(os.path.dirname(os.path.dirname(__file__)), "logs")
if not os.path.exists(LOG_PATH):
os.mkdir(LOG_PATH)
#临时文件目录,主要用于文件对话
BASE_TEMP_DIR = os.path.join(tempfile.gettempdir(), "chatchat")
try:
shutil.rmtree(BASE_TEMP_DIR)
except Exception:
pass
os.makedirs(BASE_TEMP_DIR, exist_ok=True)
3.6.2 数据库配置 kb_config.py
请确认本地分词器路径是否已经填写,如:
text_splitter_dict = {
"ChineseRecursiveTextSplitter": {
"source":"huggingface", # 选择tiktoken则使用openai的方法,不填写则默认为字符长度切割方法。
"tokenizer_name_or_path":"", # 空格不填则默认使用大模型的分词器。
}
}
设置好的分词器需要再TEXT_SPLITTER_NAME中指定并应用。在这里,通常使用huggingface的方法,并且,我们推荐使用大模型自带的分词器来完成任务。
请注意,使用
gpt2分词器将要访问 huggingface 官网下载权重。
此外还支持使用tiktoken 和传统的 按照长度分词的方式,开发者可以自行配置。
kbs_config设置了使用的向量数据库,目前可以选择
faiss: 使用 faiss 数据库,需要安装 faiss-gpumilvus: 使用 milvus 数据库,需要安装 milvus 并进行端口配置pg: 使用 pg 数据库,需要配置 connection_uri
import os
#默认使用的知识库
DEFAULT_KNOWLEDGE_BASE = "samples"
#默认向量库/全文检索引擎类型。可选:faiss, milvus(离线) & zilliz(在线), pgvector, chromadb 全文检索引擎es
DEFAULT_VS_TYPE = "faiss"
#缓存向量库数量(针对FAISS)
CACHED_VS_NUM = 1
#缓存临时向量库数量(针对FAISS),用于文件对话
CACHED_MEMO_VS_NUM = 10
#知识库中单段文本长度(不适用MarkdownHeaderTextSplitter)
CHUNK_SIZE = 250
#知识库中相邻文本重合长度(不适用MarkdownHeaderTextSplitter)
OVERLAP_SIZE = 50
#知识库匹配向量数量
VECTOR_SEARCH_TOP_K = 3
#知识库匹配的距离阈值,一般取值范围在0-1之间,SCORE越小,距离越小从而相关度越高。
#但有用户报告遇到过匹配分值超过1的情况,为了兼容性默认设为1,在WEBUI中调整范围为0-2
SCORE_THRESHOLD = 1.0
#默认搜索引擎。可选:bing, duckduckgo, metaphor
DEFAULT_SEARCH_ENGINE = "duckduckgo"
#搜索引擎匹配结题数量
SEARCH_ENGINE_TOP_K = 3
3.6.3 模型配置项 model_config.py
本文件包含本地 LLM 模型、本地 Embeddings 模型、在线 LLM 模型 API 的相关配置。
-
本地模型路径配置。建议将所有下载的模型放到一个统一的目录下,然后将
MODEL_ROOT_PATH指定为该目录,只要模型目录名称符合下列情况之一(以 text2vec 为例),即可自动识别加载:- text2vec,即
MODEL_PATH中的键 - GanymedeNil/text2vec-large-chinese,即
MODEL_PATH中的值 - text2vec-large-chinese,即
MODEL_PATH中的值的简写形式
- text2vec,即
-
在线模型 API 配置。在
ONLINE_LLM_MODEL已经预先写好了所有支持的在线 API 服务,通常只需要把申请的API_KEY等填入即可。 有些在线 API 服务需要安装额外的依赖:- zhipu-api: zhipuai
- fangzhou-api: volcengine>=1.0.106
- qianfan-api: qianfan
- qwen-api: dashscope
-
HISTORY_LEN。历史对话轮数通常不建议设置超过 10,因为这可能导致以下问题
- ·
显存占用过高:尤其是部分模型,本身就已经要占用满显存的情况下,保留太多历史,一次传入 token 太多,可能会爆显存。 速度处理很慢:还是因为一次传入了太多 token,导致速度很慢。
- ·
-
TEMPERATURE。通常不建议设置过高。 在 Agent 对话模式和知识库问答中,强烈建议将要其设置成 0 或者接近于 0。
-
Agent_MODEL = None 支持用户使用 “模型接力赛” 的用法,即: 选择的大模型仅能调用工具,但是在工具中表现较差,则这个工具作为 “模型调用工具” 如果用户设置了
Agent_MODEL,则在 Agent 中,使用Agent_MODEL来执行任务,否则,使用LLM_MODEL
import os
#可以指定一个绝对路径,统一存放所有的Embedding和LLM模型。
#每个模型可以是一个单独的目录,也可以是某个目录下的二级子目录。
#如果模型目录名称和 MODEL_PATH 中的 key 或 value 相同,程序会自动检测加载,无需修改 MODEL_PATH 中的路径。
MODEL_ROOT_PATH = ""
#选用的 Embedding 名称
EMBEDDING_MODEL = "bge-large-zh-v1.5"
#Embedding 模型运行设备。设为 "auto" 会自动检测(会有警告),也可手动设定为 "cuda","mps","cpu","xpu" 其中之一。
EMBEDDING_DEVICE = "auto"
#选用的reranker模型
RERANKER_MODEL = "bge-reranker-large"
#是否启用reranker模型
USE_RERANKER = False
RERANKER_MAX_LENGTH = 1024
#如果需要在 EMBEDDING_MODEL 中增加自定义的关键字时配置
EMBEDDING_KEYWORD_FILE = "keywords.txt"
EMBEDDING_MODEL_OUTPUT_PATH = "output"
#要运行的 LLM 名称,可以包括本地模型和在线模型。列表中本地模型将在启动项目时全部加载。
#列表中第一个模型将作为 API 和 WEBUI 的默认模型。
#在这里,使用目前主流的两个离线模型,其中,chatglm3-6b 为默认加载模型。
#如果你的显存不足,可使用 Qwen-1_8B-Chat, 该模型 FP16 仅需 3.8G显存。
3.6.4 提示词配置项 prompt_config.py
提示词配置分为三个板块,分别对应三种聊天类型。
- llm_chat: 基础的对话提示词, 通常来说,直接是用户输入的内容,没有系统提示词。
- knowledge_base_chat: 与知识库对话的提示词,在模板中,我们为开发者设计了一个系统提示词,开发者可以自行更改。
- agent_chat: 与 Agent 对话的提示词,同样,我们为开发者设计了一个系统提示词,开发者可以自行更改。
prompt 模板使用 Jinja2 语法,简单点就是用双大括号代替 f-string 的单大括号 请注意,本配置文件支持热加载,修改 prompt 模板后无需重启服务。
#prompt模板使用Jinja2语法,简单点就是用双大括号代替f-string的单大括号
#本配置文件支持热加载,修改prompt模板后无需重启服务。
#LLM对话支持的变量:
#- input: 用户输入内容
#知识库和搜索引擎对话支持的变量:
#- context: 从检索结果拼接的知识文本
#- question: 用户提出的问题
#Agent对话支持的变量:
#- tools: 可用的工具列表
#- tool_names: 可用的工具名称列表
#- history: 用户和Agent的对话历史
#- input: 用户输入内容
#- agent_scratchpad: Agent的思维记录
3.6.5 服务和端口配置项 server_config.py
通常,这个页面并不需要进行大量的修改,仅需确保对应的端口打开,并不互相冲突即可。
如果你是 Linux 系统推荐设置
DEFAULT_BIND_HOST ="0.0.0.0"
如果使用联网模型,则需要关注联网模型的端口。
这些模型必须是在 model_config.MODEL_PATH 或 ONLINE_MODEL 中正确配置的。
#在启动 startup.py 时,可用通过--model-worker --model-name xxxx指定模型,不指定则为 LLM_MODEL
import sys
from configs.model_config import LLM_DEVICE
#httpx 请求默认超时时间(秒)。如果加载模型或对话较慢,出现超时错误,可以适当加大该值。
HTTPX_DEFAULT_TIMEOUT = 300.0
#API 是否开启跨域,默认为False,如果需要开启,请设置为True
#is open cross domain
OPEN_CROSS_DOMAIN = False
#各服务器默认绑定host。如改为"0.0.0.0"需要修改下方所有XX_SERVER的host
DEFAULT_BIND_HOST = "0.0.0.0" if sys.platform != "win32" else "127.0.0.1"
#webui.py server
WEBUI_SERVER = {
"host": DEFAULT_BIND_HOST,
"port": 8501,
}
3.6.5 覆盖配置文件 或者配置 startup.py
在 server_config.py中有以下配置文件被注释了
"gpus": None, # 使用的GPU,以str的格式指定,如"0,1",如失效请使用CUDA_VISIBLE_DEVICES="0,1"等形式指定
"num_gpus": 1, # 使用GPU的数量
"max_gpu_memory":"20GiB", # 每个GPU占用的最大显存
以下为model_worker非常用参数,可根据需要配置
"load_8bit": False, # 开启8bit量化
"cpu_offloading": None,
"gptq_ckpt": None,
"gptq_wbits": 16,
"gptq_groupsize": -1,
"gptq_act_order": False,
"awq_ckpt": None,
"awq_wbits": 16,
"awq_groupsize": -1,
"model_names": [LLM_MODEL],
"conv_template": None,
"limit_worker_concurrency": 5,
"stream_interval": 2,
"no_register": False,
"embed_in_truncate": False,
以下为vllm_woker配置参数,注意使用vllm必须有gpu,仅在Linux测试通过
tokenizer = model_path # 如果tokenizer与model_path不一致在此处添加
'tokenizer_mode':'auto',
'trust_remote_code':True,
'download_dir':None,
'load_format':'auto',
'dtype':'auto',
'seed':0,
'worker_use_ray':False,
'pipeline_parallel_size':1,
'tensor_parallel_size':1,
'block_size':16,
'swap_space':4 , # GiB
'gpu_memory_utilization':0.90,
'max_num_batched_tokens':2560,
'max_num_seqs':256,
'disable_log_stats':False,
'conv_template':None,
'limit_worker_concurrency':5,
'no_register':False,
'num_gpus': 1
'engine_use_ray': False,
'disable_log_requests': False
在这些参数中,如果没有设置,则使用startup.py中的默认值,如果设置了,则使用设置的值。 因此,强烈建议开发不要在startup.py中进行配置,而应该在server_config.py中进行配置。避免配置文件覆盖。
3.6.6 选择使用的模型
在model_config.py完成模型配置后,还不能直接使用,需要在该文件下配置本地模型的运行方式或在线模型的 API,例如
"agentlm-7b": { # 使用default中的IP和端口
"device": "cuda",
},
"zhipu-api": { # 请为每个要运行的在线API设置不同的端口
"port": 21001,
},
本地模型使用 default 中的 IP 和端口,在线模型可以自己选择端口
4. 模型启动
4.1 一键启动
启动前,确保已经按照参数配置正确配置各 config 模块。【相关配置后续会出详细文章说明,请见专栏】
一键启动脚本 startup.py, 一键启动所有 Fastchat 服务、API 服务、WebUI 服务,示例代码:
$ python startup.py -a
并可使用 Ctrl + C 直接关闭所有运行服务。如果一次结束不了,可以多按几次。
可选参数包括 -a (或--all-webui), --all-api, --llm-api, -c (或--controller), --openai-api, -m (或--model-worker), --api, --webui,其中:
-
--all-webui为一键启动 WebUI 所有依赖服务; -
--all-api为一键启动 API 所有依赖服务; -
--llm-api为一键启动 Fastchat 所有依赖的 LLM 服务; -
--openai-api为仅启动 FastChat 的 controller 和 openai-api-server 服务; -
其他为单独服务启动选项。
- –all-webui
- –all-api

若想指定非默认模型,需要用 --model-name 选项,示例:
$ python startup.py --all-webui --model-name Qwen-7B-Chat
更多信息可通过
python startup.py -h查看。
4.2 多卡加载
项目支持多卡加载,需在 startup.py 中的 create_model_worker_app 函数中,修改如下三个参数:
gpus=None,
num_gpus= 1,
max_gpu_memory="20GiB"
- 其中:
-
gpus控制使用的显卡的 ID,例如 “0,1”; -
num_gpus控制使用的卡数; -
max_gpu_memory控制每个卡使用的显存容量。
-
注 1: server_config.py 的 FSCHAT_MODEL_WORKERS 字典中也增加了相关配置,如有需要也可通过修改 FSCHAT_MODEL_WORKERS 字典中对应参数实现多卡加载,且需注意 server_config.py 的配置会覆盖 create_model_worker_app 函数的配置。
注 2: 少数情况下,gpus 参数会不生效,此时需要通过设置环境变量 CUDA_VISIBLE_DEVICES 来指定 torch 可见的 gpu, 示例代码:
CUDA_VISIBLE_DEVICES=0,1 python startup.py -a
4.3 额外信息使用telnet验证连接
4.3.1 Linux下安装
- 第一步,安装Telnet服务器:
在大部分Linux发行版中,Telnet服务器包含在telnet-server软件包中。我们可以使用系统的包管理器进行安装。
对于Debian和Ubuntu用户,可以通过以下命令进行安装:
sudo apt-get install telnetd
- 第二步,配置Telnet服务:
安装完Telnet服务器之后,我们需要进行一些配置以确保其正常工作。
- 编辑Telnet配置文件:
sudo vi /etc/xinetd.d/telnet
-
在打开的文件中,找到“disable = yes”这一行,并将其改为“disable = no”。
保存并关闭文件。 -
重新启动Telnet服务:
sudo service xinetd restart
- 第三步,使用Telnet客户端连接:
现在我们可以使用Telnet客户端来连接到Telnet服务器了。
使用以下命令连接到服务器:
telnet <服务器IP地址>
例如,要连接到IP地址为192.168.0.100的服务器,可以使用以下命令:
telnet 192.168.0.100
4.3.2 Windows下安装
-
通过控制面板启用Telnet客户端:
- 点击“开始”按钮或按下键盘上的“Win”键。找到并打开“控制面板”。
打开控制面板,按组合键”Windows + R“,在#运行#中输入:control,点击【确认】或按回车键”Enter“。
2. 点击“程序”或“程序和功能”选项。
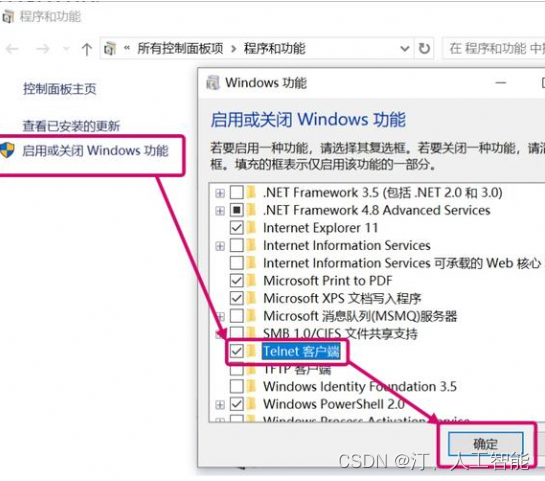
-
点击“启用或关闭Windows功能”。 在弹出的“Windows功能”窗口中,向下滚动找到“Telnet客户端”选项。勾选“Telnet客户端”旁边的复选框。
-
点击“确定”按钮,按照系统提示完成安装。
-
安装完成后,打开命令提示符窗口(这里可以不需要管理员权限),输入:telnet,然后按【Enter】,随即跳出telnet客户端命令行窗口。
- 点击“开始”按钮或按下键盘上的“Win”键。找到并打开“控制面板”。
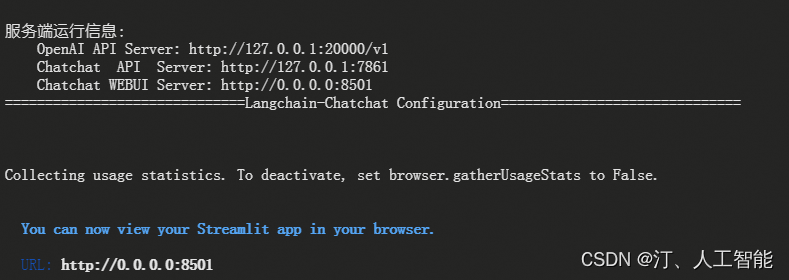
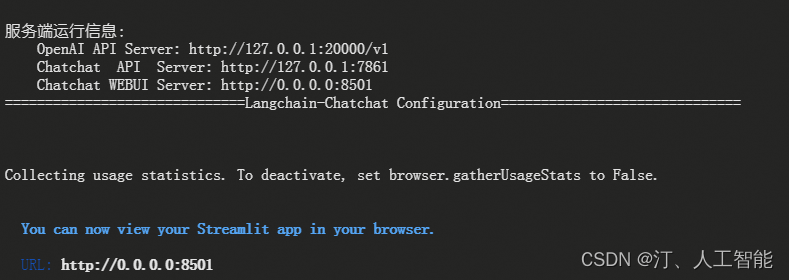
5. 启动界面示例(UI界面 & API调用)
如果正常启动,你将能看到以下界面
5.1. FastAPI Docs 界面
访问链接:
#http://127.0.0.1:7861
http://10.80.2.195:7861
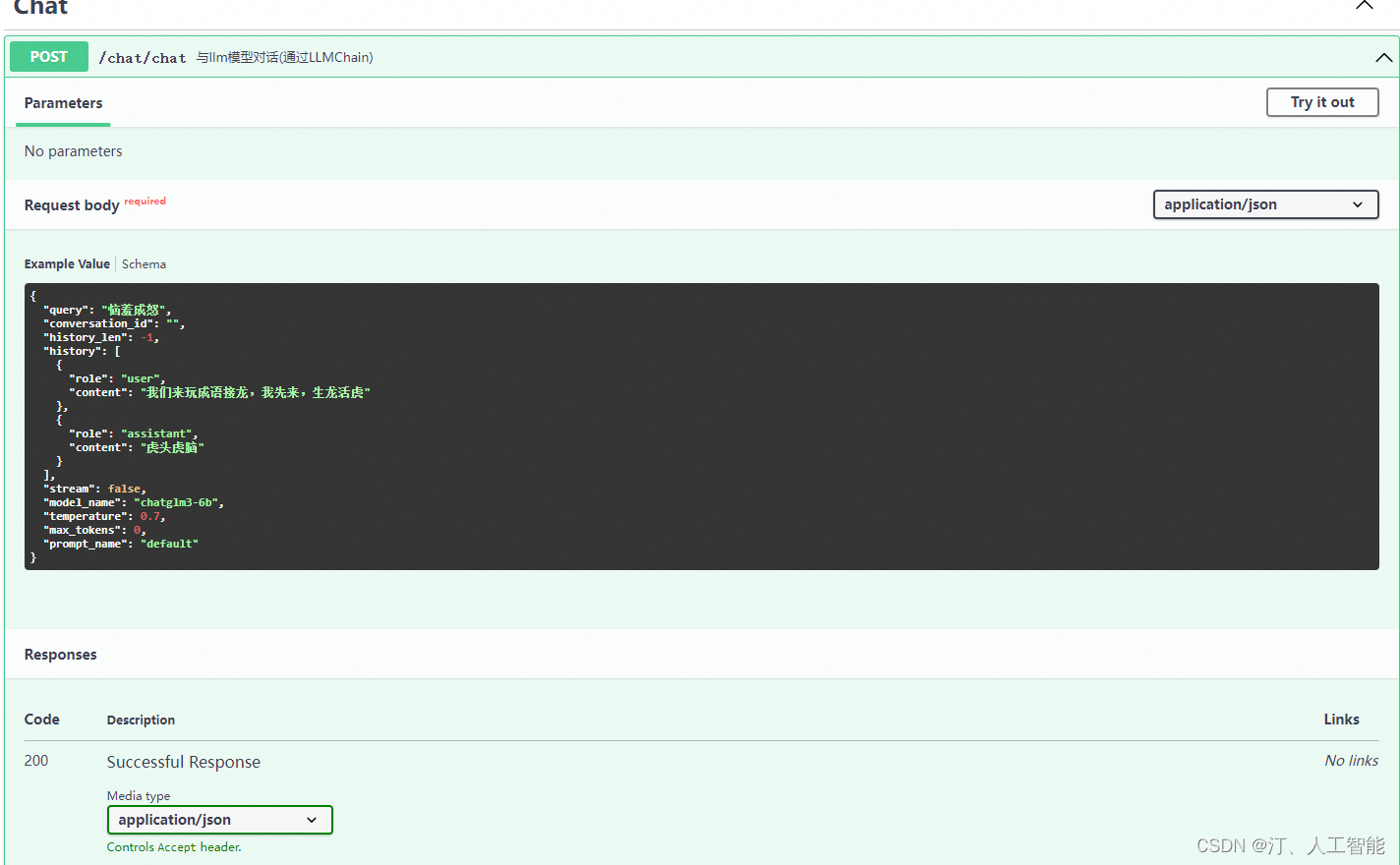
以大模型chat为例:按照实例相关格式进行填写即可
- CURL调用
curl -X POST http://localhost:7861/chat/chat -H "Content-Type: application/json" -d '{"query":"恼羞成怒","conversation_id":"12345","history_len":10,"history":[{"role":"user","content":"我们来玩成语接龙,我先来,生龙活虎"},{"role":"assistant","content":"虎头虎脑"}],"stream":false,"model_name":"chatglm3-6b","temperature":0.7,"max_tokens":150,"prompt_name":"default"}'

- python调用
import requests
import json
url = "http://10.80.2.195:7861/chat/chat"
payload = {
"query": "恼羞成怒",
"knowledge_base_name": "samples",
"top_k": 6,
"score_threshold": 1,
"history": [
{
"role": "user",
"content": "我们来玩成语接龙,我先来,生龙活虎"
},
{
"role": "assistant",
"content": "虎头虎脑"
}
],
"stream": False,
"model_name": "chatglm3-6b",
"temperature": 0.7,
"max_tokens": 0,
"prompt_name": "default"
}
try:
response = requests.post(url, json=payload)
response.raise_for_status() # Raise an exception for HTTP errors (4xx or 5xx)
# Check if response contains JSON data
if response.headers['content-type'] == 'application/json':
data = response.json()
print(data)
else:
print("Response is not in JSON format:", response.text)
except requests.exceptions.RequestException as e:
print("Request failed:", e)
except json.JSONDecodeError as e:
print("Failed to decode JSON response:", e)

5.2. Web UI 启动界面示例:
- 在浏览器输入:
http://10.80.2.195:8501/
## ip填写你自己的ip即可 端口号同理
- Web UI 对话界面:

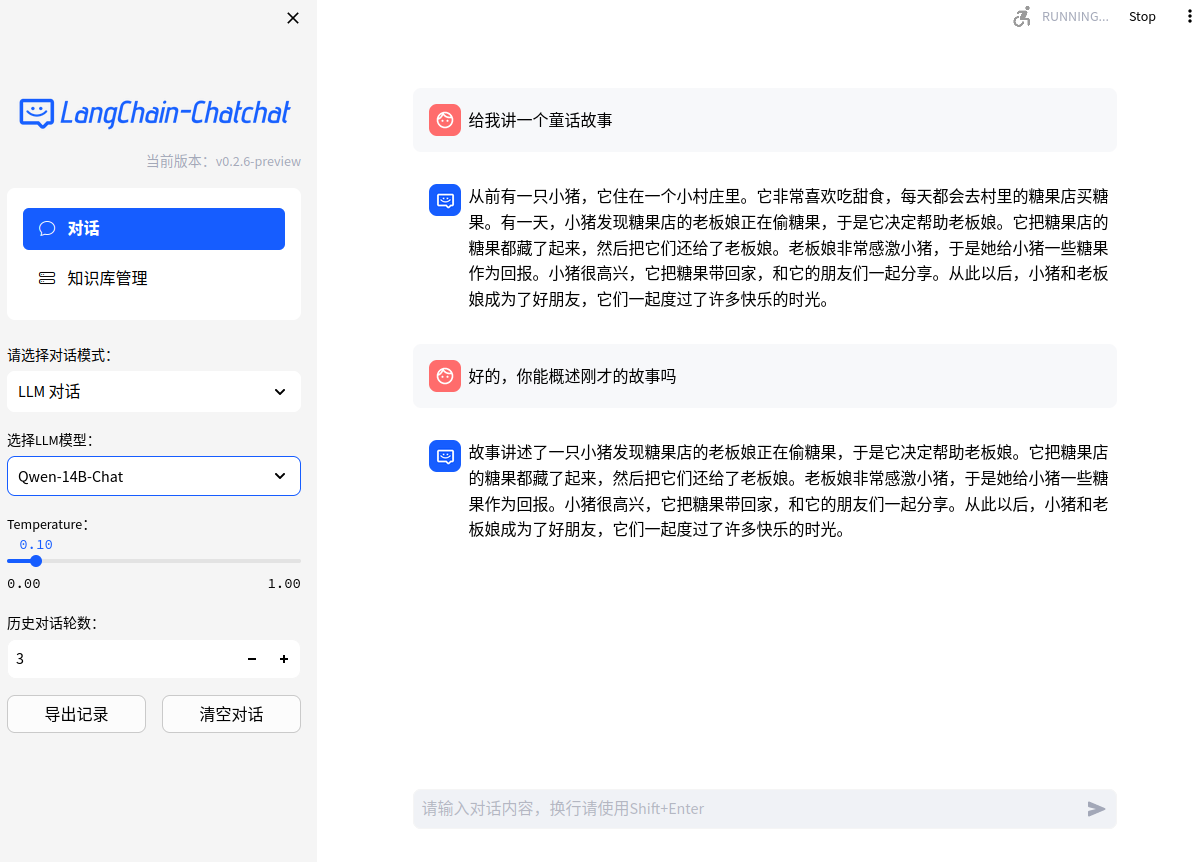
- Agent-Tool效果
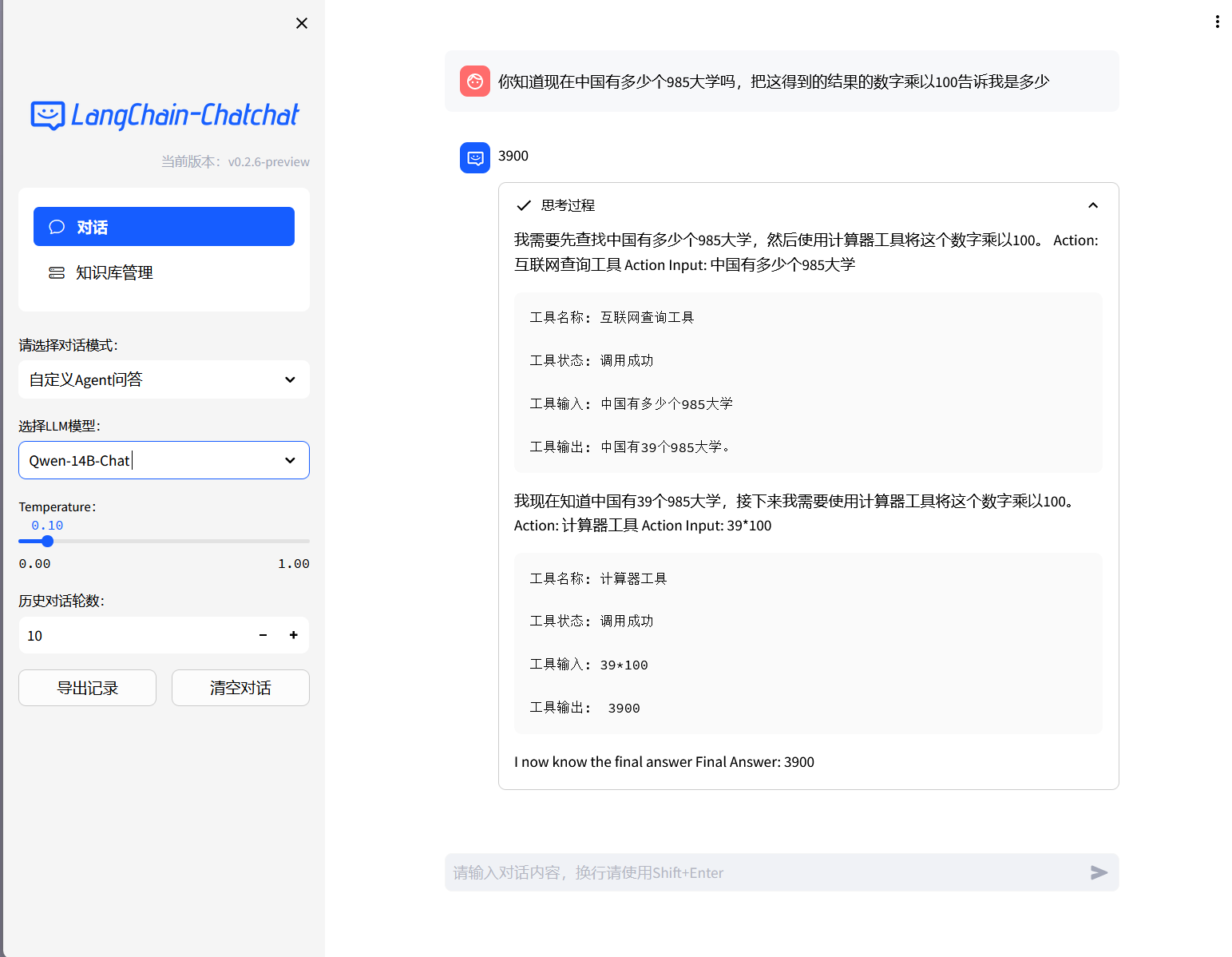
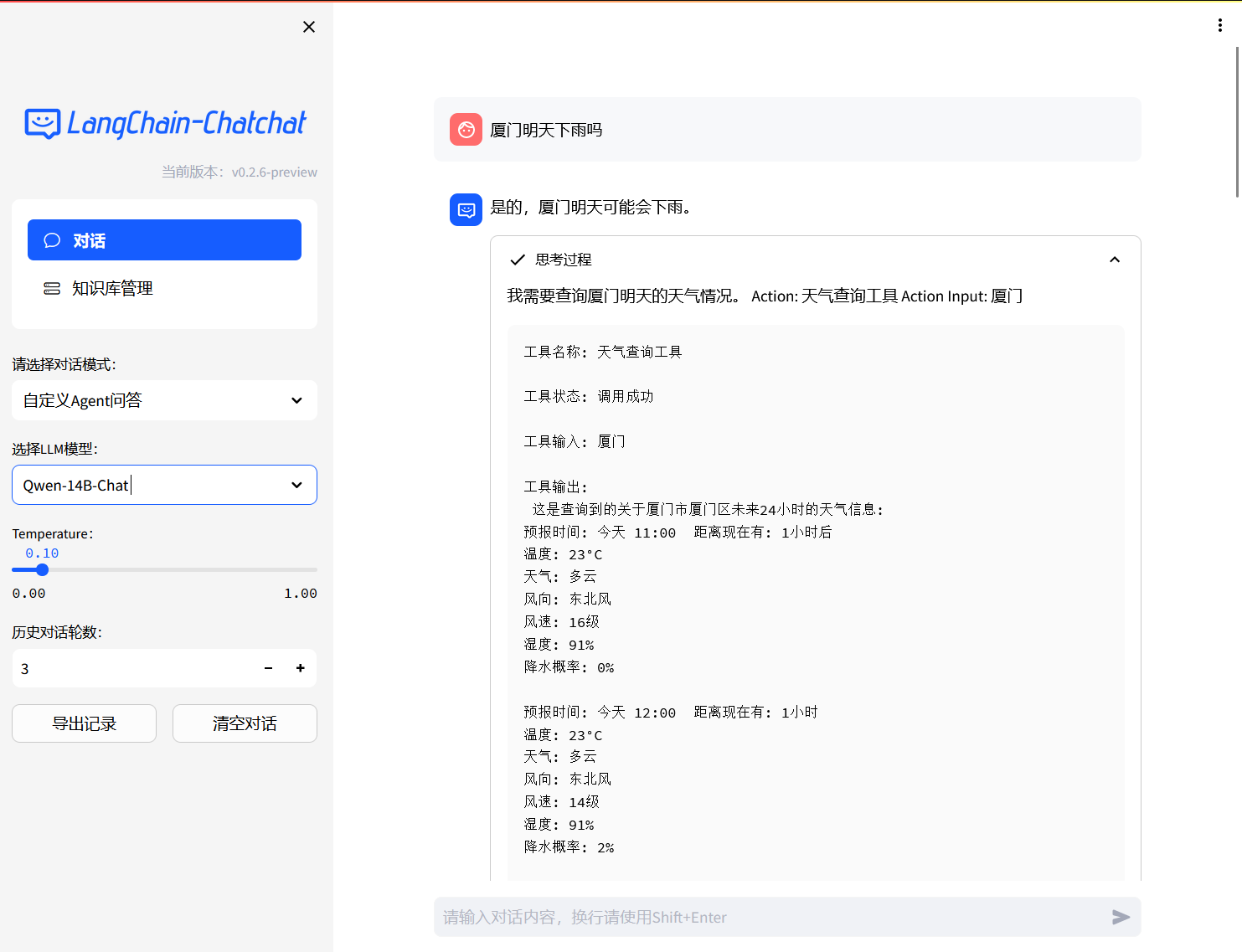
- Web UI 知识库管理页面:
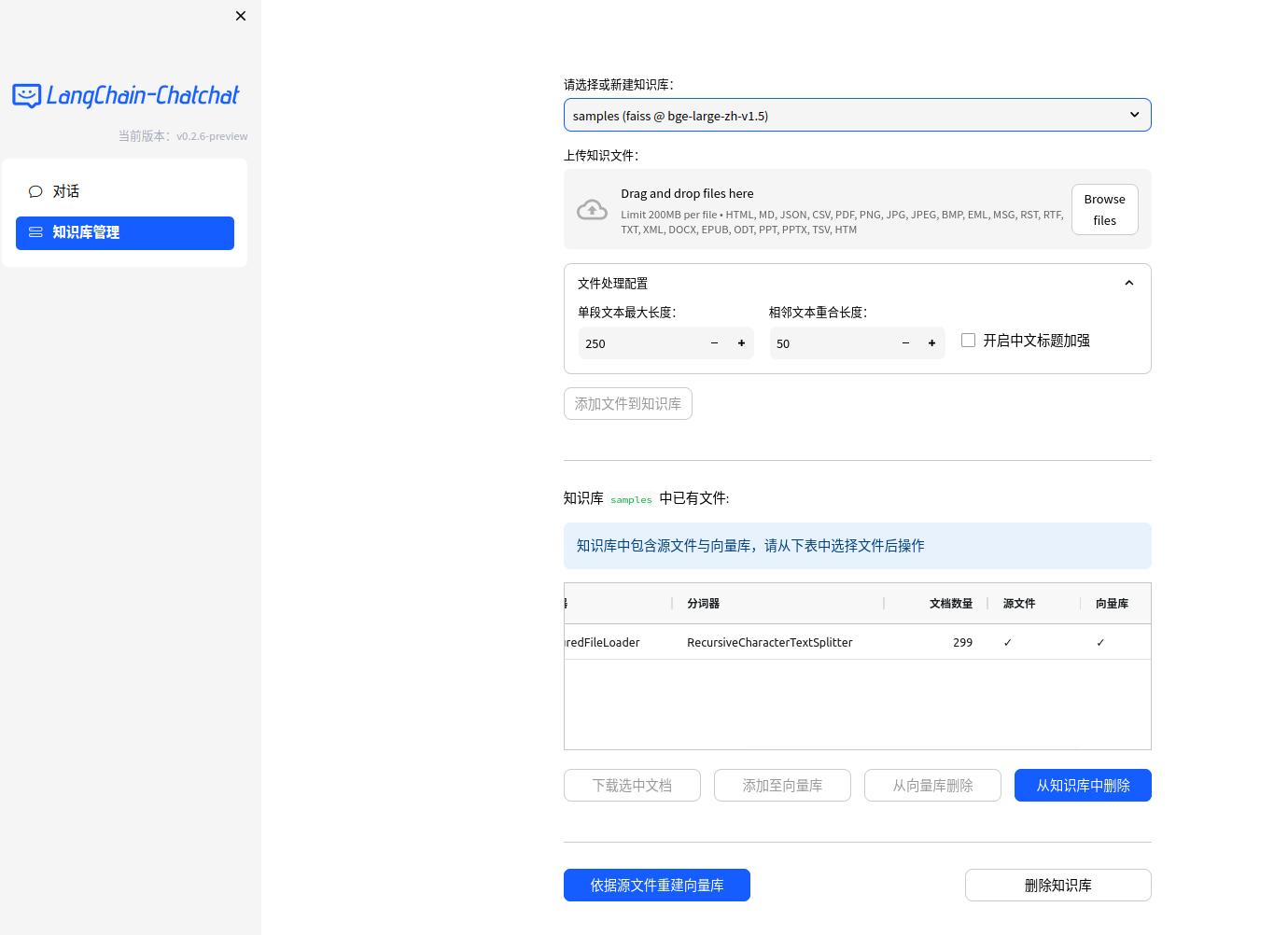
最轻模式本地部署方案
该模式的配置方式与常规模式相同,但无需安装 torch 等重依赖,通过在线 API 实现 LLM 和 Ebeddings 相关功能,适合没有显卡的电脑使用。
$ pip install -r requirements_lite.txt
$ python startup.py -a --lite
该模式支持的在线 Embeddings 包括:
在 model_config.py 中 将 LLM_MODELS 和 EMBEDDING_MODEL 设置为可用的在线 API 名称即可。
注意:在对话过程中并不要求 LLM 模型与 Embeddings 模型一致,你可以在知识库管理页面中使用 zhipu-api 作为嵌入模型,在知识库对话页面使用其它模型。