python多线程爬取加密后ts文件,解密后合成mp4视频
声明:仅供技术交流,请勿用于非法用途,如有其它非法用途造成损失,和本博客无关
前言
- 续我前几天发布的上篇博客:python多线程爬取ts文件并合成mp4视频,说道爬视频有三种级别,上篇的例子属于中等级别,那么接下来的这篇是困难级别的。
- 其实,这里再修正一下,爬视频应该不止是3种级别,还有很多更加困难的网站。
- 所以,学无止境,尽管路途遥远,也要勇往直前~
废话不多说,下面直接开始吧,本次爬取的网站是点击跳转
一、分析页面
其实,这个网站跟我的上一篇博客的页面差不多,都属于同类型的网站,只不过是它的ts文件是加密的,如果直接运用上一篇的爬取逻辑,下载下来的ts文件合成mp4也是播放不了的,因为ts文件已经加过密了,需要解密才能播放。(跟上一篇的页面分析差不多,这里就不过多讲述了)
这个网站跟我的上一篇博客爬取的视频网站有三点不一样的地方:
- 用requests来请求播放页和js文件都会得不到网页的源代码,而是一个需要执行的JavaScript代码,因此,本文在拿到所有ts文件之前的操作均使用selenium来获取,比如获取播放页的网页源代码、获取js文件的响应内容。
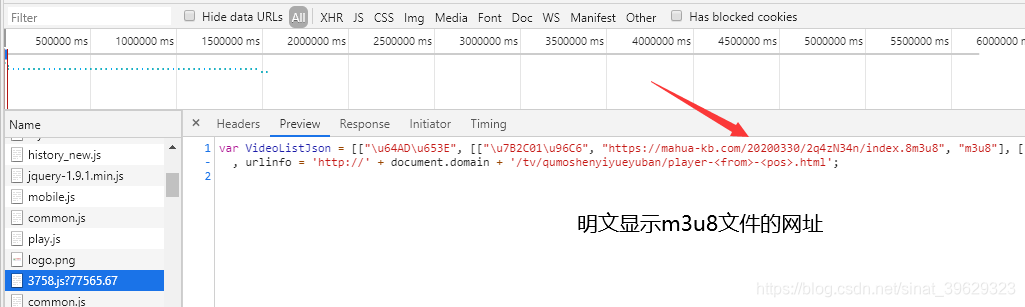
- js文件的响应内容里直接明文展示了所有剧集的m3u8文件的网址,而上一篇博客里的视频网站里的那个js文件是用base64来对m3u8文件网址进行编码加密的,因此,本文无需导入base64库来进行解密了。
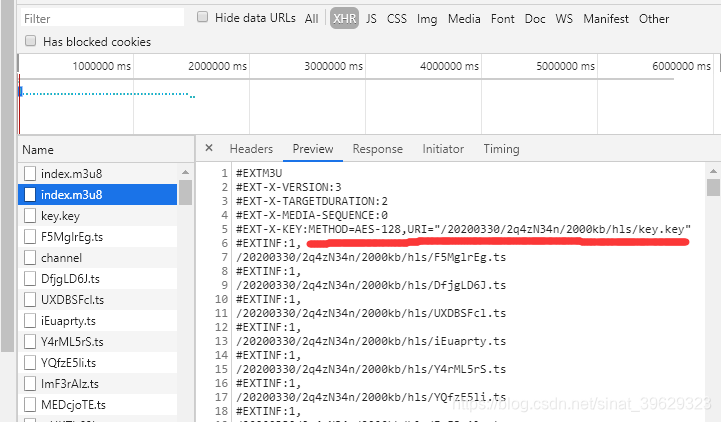
- ts文件是经过加密处理的,下载下来的ts需要对其解密才能播放,这正是本文的重点,随机打开一个播放页,看到在第二个m3u8文件中多出了一行说明:
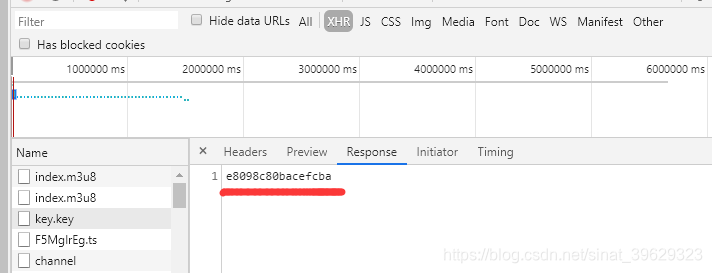
可以看到METHOD=AES-128说明是用AES-128的加密方法,其秘钥的链接为后面URI,请求这个链接得到加密秘钥:

二、视频解密
根据给出的秘钥即可以完成视频解密的操作,基本步骤是:将请求ts文件得到的响应内容进行解密之后,再做保存操作,下面以第一集视频解密为例,具体代码如下:
# 导入相关包或模块
import threading, queue
import time, os, subprocess
import requests, urllib, parsel
import random, re
from Crypto.Cipher import AES
# 下载ts文件
def download_ts(urlQueue,aes,headers):
while True:
try:
#不阻塞的读取队列数据
temp = urlQueue.get_nowait()
url=temp[0]
n=temp[1]
except Exception as e:
break
response=requests.get(url,stream=True,headers=headers)
ts_path = "./ts/%04d.ts"%n # 注意这里的ts文件命名规则
with open(ts_path,"wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
after=aes.decrypt(chunk)
file.write(after)
print("%04d.ts OK..."%n)
if __name__ == '__main__':
url='https://mahua-kb.com/20200330/2q4zN34n/2000kb/hls/index.m3u8' # 驱魔神医粤语版第一集
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
r=requests.get(url,headers=headers)
urlQueue = queue.Queue() # 存储ts文件的网址
for i in r.text.split('\n'):
if i.endswith('.ts'):
urlQueue.put([urllib.parse.urljoin(url,i),urlQueue.qsize()])
elif 'URI' in i:
URI=urllib.parse.urljoin(url,re.findall('URI="(.*?)"',i)[0]) # 秘钥的网址
key=requests.get(URI,headers=headers).text # 得到秘钥
aes=AES.new(key,AES.MODE_CBC,key) # 通过秘钥新建解密器
# 下面开始多线程下载
startTime = time.time()
threads = []
# 可以适当调节线程数,进而控制抓取速度
threadNum = 4
for i in range(threadNum):
t = threading.Thread(target=download_ts, args=(urlQueue,aes,headers,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
endTime = time.time()
print ('Done, Time cost: %s ' % (endTime - startTime))
# 下面是执行cmd命令来合成mp4视频
command=r'copy/b D:\python3.7\HEHE\爬虫\ts\*.ts D:\python3.7\HEHE\爬虫\mp4\驱魔神医-第一集.mp4'
output=subprocess.getoutput(command)
print('驱魔神医-第一集.mp4 OK...'
# 下面是把这一集所有的ts文件给删除
file_list = []
for root, dirs, files in os.walk('D:/python3.7/HEHE/爬虫/ts'):
for fn in files:
p = str(root+'/'+fn)
file_list.append(p)
for i in file_list:
os.remove(i)
ps:以上代码只是单独拿出了一集视频,来说明怎么将加密后ts进行解密并合成为mp4,完整的爬取整个电视剧的源代码可以关注我的微信公众号,回复:20200606,即可下载本篇文章的全部源代码

写在最后
因为我的上一篇博客说了我本人对爬视频难度的划分,并且上一篇的难度为中等难度,于是就想再找一篇困难级别的网站来分析,所以就找到了这个网站,不过我发现这个网站有的视频需要解密,而有的又不需要,这其中最关键的就是看第二个m3u8文件响应里是否说明了加密的方法以及其加密的秘钥,所以有的话就可以参考本篇文章所使用的逻辑方法,没有的话就可以参考我的上一篇博客。