文章目录
1. 车道线检测技术
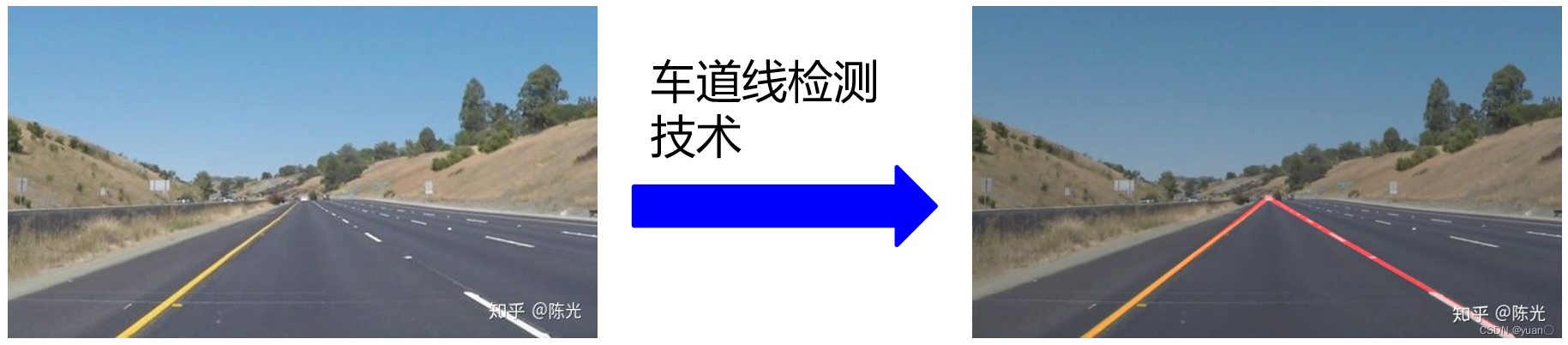
-
输入:图片 Image
- 输入数据来源可以是单目视觉相机、双目视觉相机,数据可以是灰度图或者彩色图。
- 基于单目图片的称为单目车道线检测技术,基于双目图片的称为双目车道线检测技术。
-
输出:车道线信息提取及表达
- 车道线的表示形式可以是直线参数方程,也可以是曲线方程。
- 目前有一些车道线检测方法,除去输出车道线的参数方程表达之外,也可以输出车道线的形式(连续、间断)、颜色等。
1.1 基于规则的车道线检测技术
1.1.1 流程框架
算法输入:前视相机图片
算法输出:车道线方程(前视或俯视)
处理步骤:预处理、特征提取、拟合、后处理

| 模块 | 预处理模块 |
|---|---|
| 模块目的 | 突出图片中的车道线特征 |
| 操作内容 | 俯视图变换、灰度图转换、感兴趣区域设置等 |
| 模块 | 特征提取模块 |
|---|---|
| 模块目的 | 利用机器视觉算法,像素级提取车道线特征 |
| 操作内容 | 颜色检测、边缘检测 |
| 模块输出 | 像素级特征图 |
| 模块 | 拟合模块 |
|---|---|
| 模块目的 | 将像素级特征转换为数学化的曲线方程以便决策利用 |
| 操作内容 | 方程拟合,常用RANSAC及Hough变换等 |
| 模块 | 后处理模块 |
|---|---|
| 模块目的 | 对拟合结果进行进一步处理,减少误检及漏检 |
| 操作内容 | 车道线筛选、追踪等 |
1.1.2 预处理模块
俯视图变换:将前视图转化为真实世界坐标下的俯视图,还原车道线在真实世界中的位置,以利用车道线间距等先验信息
感兴趣区域:保留图片中的路面部分区域
灰度图转换:充分利用车道线的高亮度
1.1.3 车道线识别感兴趣区域提取
感兴趣区域(ROI)设置:根据相机的分辨率、视野范围等,确定感兴趣区域的边界。一般来说,车道线的感兴趣区域位于图片的下半部分,感兴趣区域的边界可以根据车辆姿态动态设置。
1.1.4 灰度图转化
灰度图转化的加权系数可调。
根据心理学研究,灰度可由RGB线性加权计算,权重反映了人眼对三色光的灵敏程度,图像处理库OpenCV应用了此原理心理学实验得出的通用权值:
X
=
0.30
∗
R
+
0.59
∗
G
+
0.11
∗
B
X = 0.30*R + 0.59*G + 0.11*B
X=0.30∗R+0.59∗G+0.11∗B

1.1.5 灰度图去噪
车道线检测任务中,采用了加权滤波平均的方式对图像进行去噪,减少随机性噪声对像素提取任务的影响。模块运算系数采用高斯分布。
设定邻域格数为n时,像素
(
u
,
v
)
(u,v)
(u,v)处的灰度按下式计算
G
′
(
u
,
v
)
=
∑
j
=
−
n
n
∑
i
=
−
n
n
P
(
u
+
i
,
v
+
j
)
G
(
u
+
i
,
v
+
j
)
P
N
˜
(
(
u
,
v
)
,
σ
2
)
\begin{array}{l}G'(u,v) = \sum\limits_{j = - n}^n {\sum\limits_{i = - n}^n {P(u + i,v + j)G(u + i,v + j)} } \\P\~N((u,v),{\sigma ^2})\end{array}
G′(u,v)=j=−n∑ni=−n∑nP(u+i,v+j)G(u+i,v+j)PN˜((u,v),σ2)
1.1.6 二值化操作
车道线识别中的二值化:一般来说,道路上的车道线利用高亮度颜色描绘。对应的灰度值一般都比较大。
基于车道线像素点的高亮度特征,在灰度图中设置阈值以保留灰度较高的像素,就可以提取出车道线上的像素点。

1.1.7 鲁棒性参数估计——RANSAC
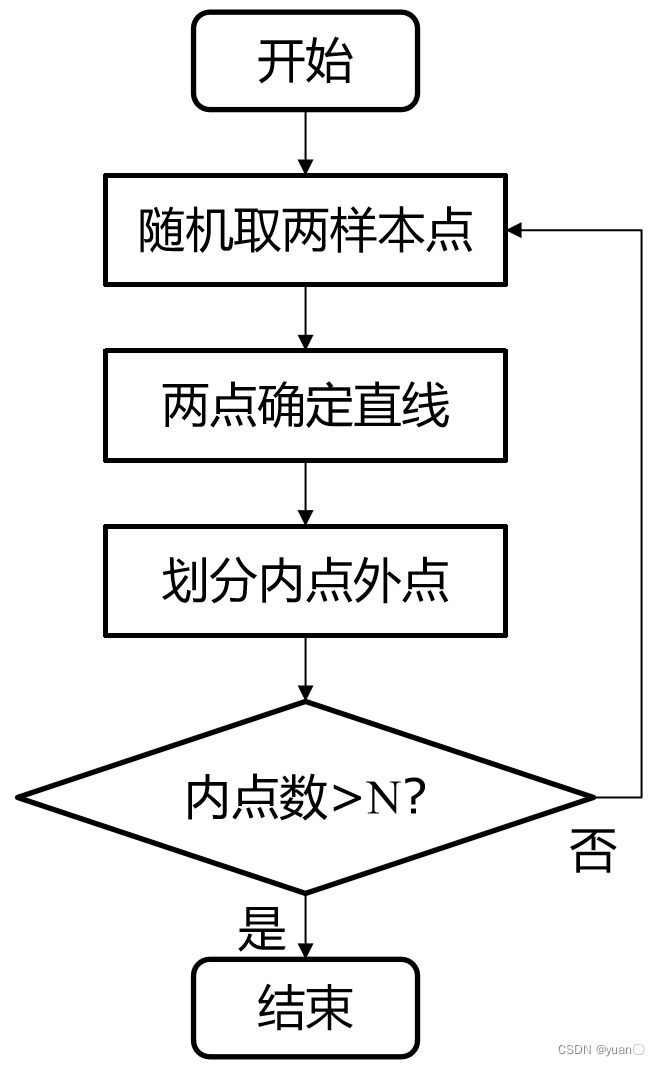
- 随机选取两像素点,拟合一条直线,根据容忍误差,判断其他拟合数据点为内点还是外点
- 如果内点的数量>N(预设阈值),就认为已经找到了车道线,终止算法
- 若不满足要求,重新随机选取两点重复上述过程,直到满足终止条件
阈值设置:根据算法漏检率和误检率手动反馈调节
1.1.8 后处理模块
目的:去除误检的车道线,对多车道线排序。
原理:基于车道线的连贯特征,误检的杂散噪声一般尺寸较小,方向随机。
方法:
- 根据拟合的线的长度、拟合前包含的特征像素数的多少来进行筛选,去除噪声;
- 根据图片中心线判断这些曲线与自车的相对位置关系,以及车道线是否为本车道车道线
1.1.9 输出
俯视图和前视图两种形式的输出,两种输出方式根据逆投影变换关系可转换。

1.2 车道线检测技术发展路线
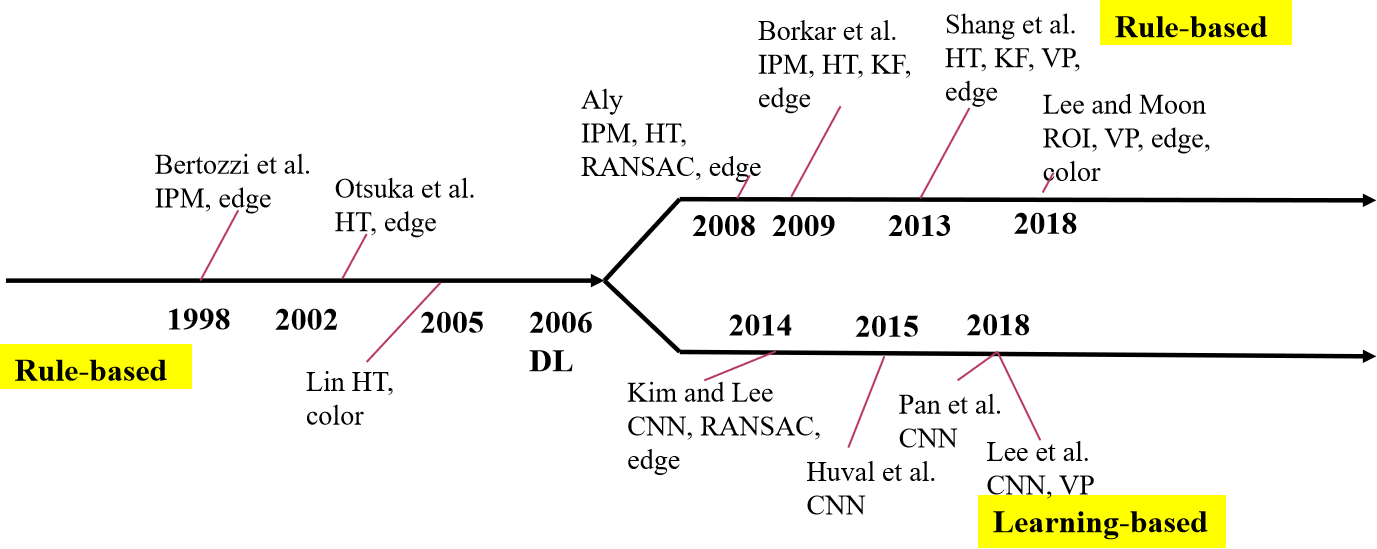
| 方法 | 基于规则的方法 | 基于学习的方法 |
|---|---|---|
| 优势 | 明确可控,可以充分利用人类经验,针对性优化算法 | 通过网络训练代替人工复杂规则,具有复杂环境适应潜力 |
| 劣势 | 为提高复杂环境适应性,需要设计大量规则,工作量巨大,人类经验难以覆盖所有情况 | 网络输出不可控,需要全场景数据集,且少量极端样本难以被学习到 |
2. 目标检测技术
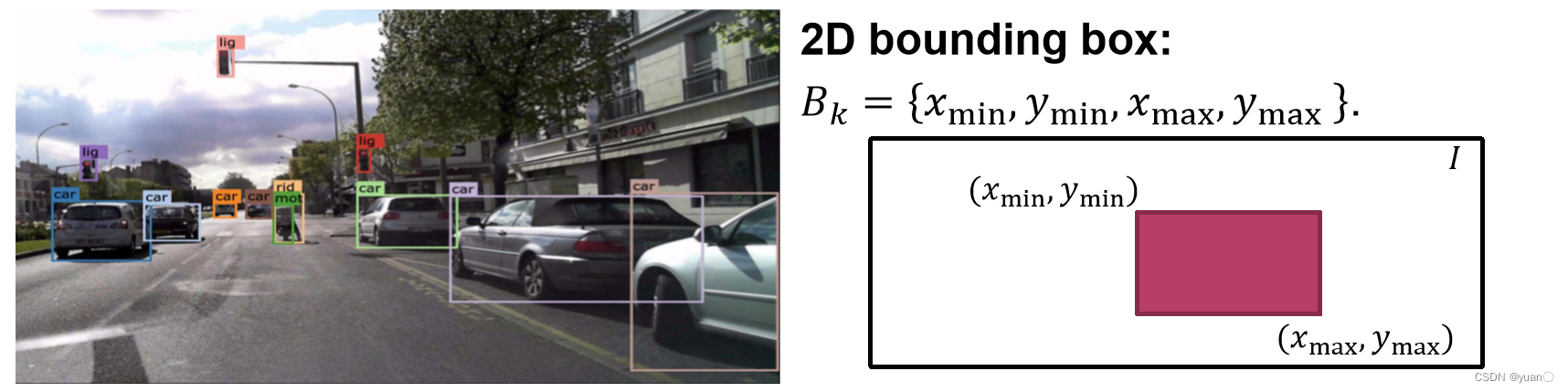
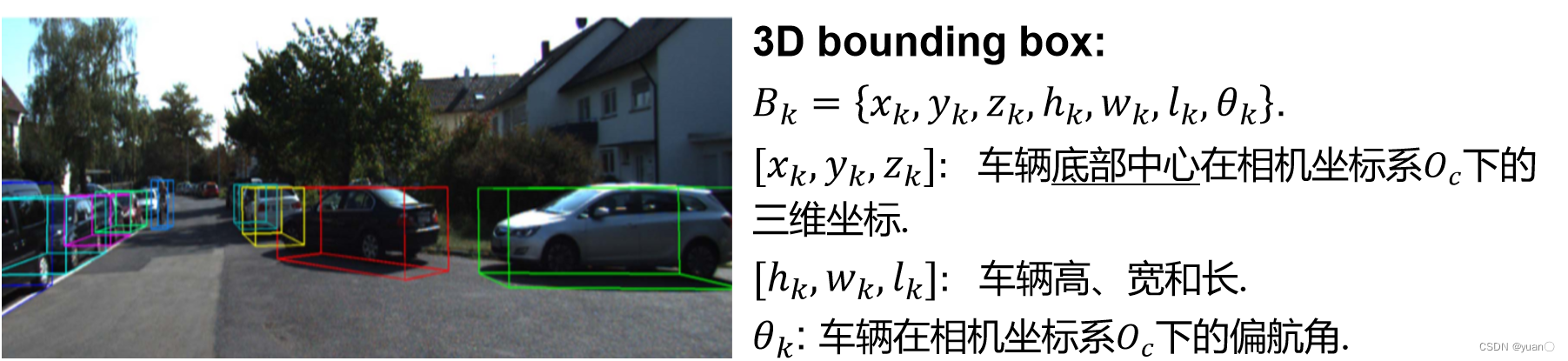
2.1 定义
定义(狭义):给定图像
I
I
I, 输出图像中所有目标实例的包围框集合
B
=
B
k
k
=
1
:
K
B={B_k}_{k=1:K}
B=Bkk=1:K,并提供对应包围框中目标实例的类别。
2.2 技术发展历史
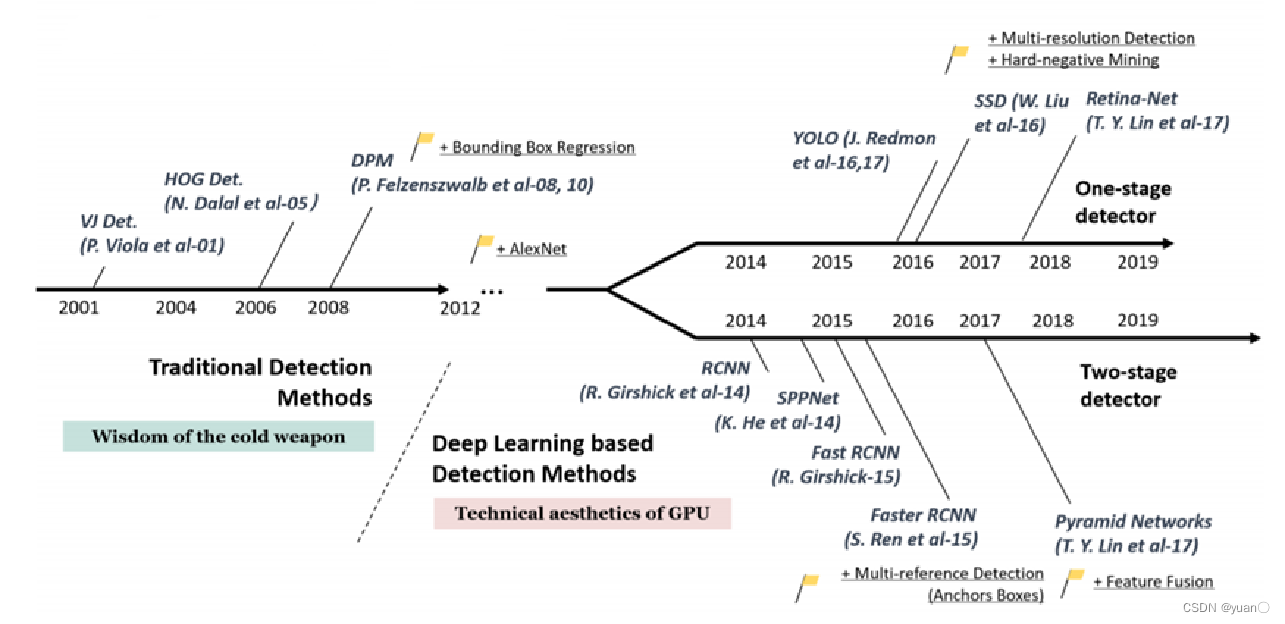
- 传统计算机视觉阶段,经典图像目标检测算法处于主流,性能提升缓慢
- 2014年RCNN的发表,引发了深度学习目标检测算法的热潮。公开数据集检测性能大幅提高
- 基于深度学习的目标检测,从检测步骤的角度,可以分为单阶段检测方法和双阶段检测方法,两种研究方法都有诸多研究发表。
2.3 传统目标检测流程
- 区域选择(穷举策略:采用滑动窗口,且设置不同的大小,不同的长宽比对图像进行遍历)
- 特征提取(Hog, Haar, SIFT等;考虑形态多样性、光照变化多样性、背景多样性)
- 分类器(主要有SVM、Adaboost等)
面临的挑战:
人工设计的特征存在计算复杂,且泛化能力较低的问题,从而难以满足在速度和性能上的要求,难以适用于复杂多样的实际场景。
2.4 神经网络选择/设计
2.4.1 单阶段识别网络(One-stage)
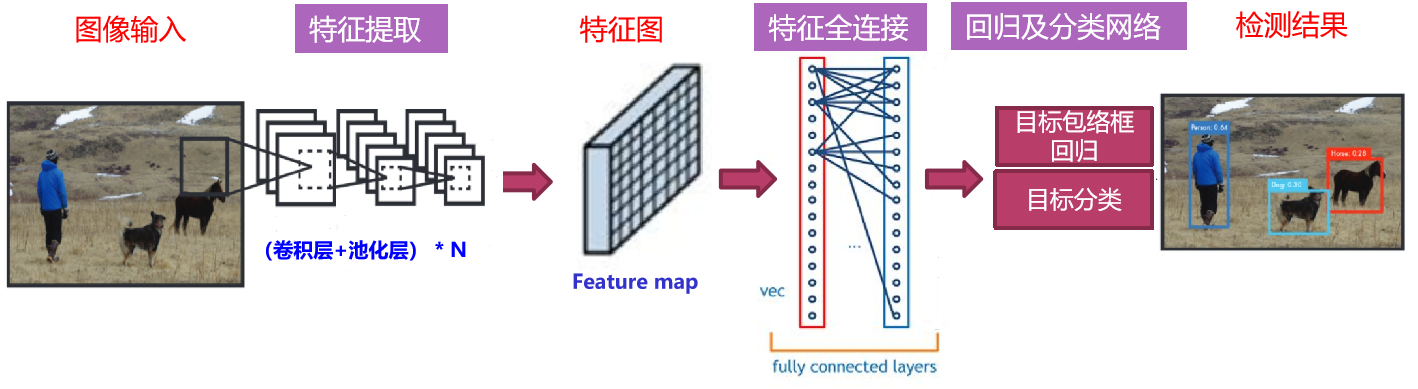
- 图像输入: 输入待检测的图像
- 特征提取: 经过多层的卷积、池化等操作,将图像的特征逐步抽象
- 特征图:输入图像的高维特征表征
- 特征全连接层:特征的全连接层,所有的特征将被映射到另一特征空间
- 回归及分类网络:特征的回归产生目标包络框,分类网络可得到目标的类别
- 输出结果:包括目标的包络框(位置)及分类
2.4.2 双阶段识别网络(Two-stage)
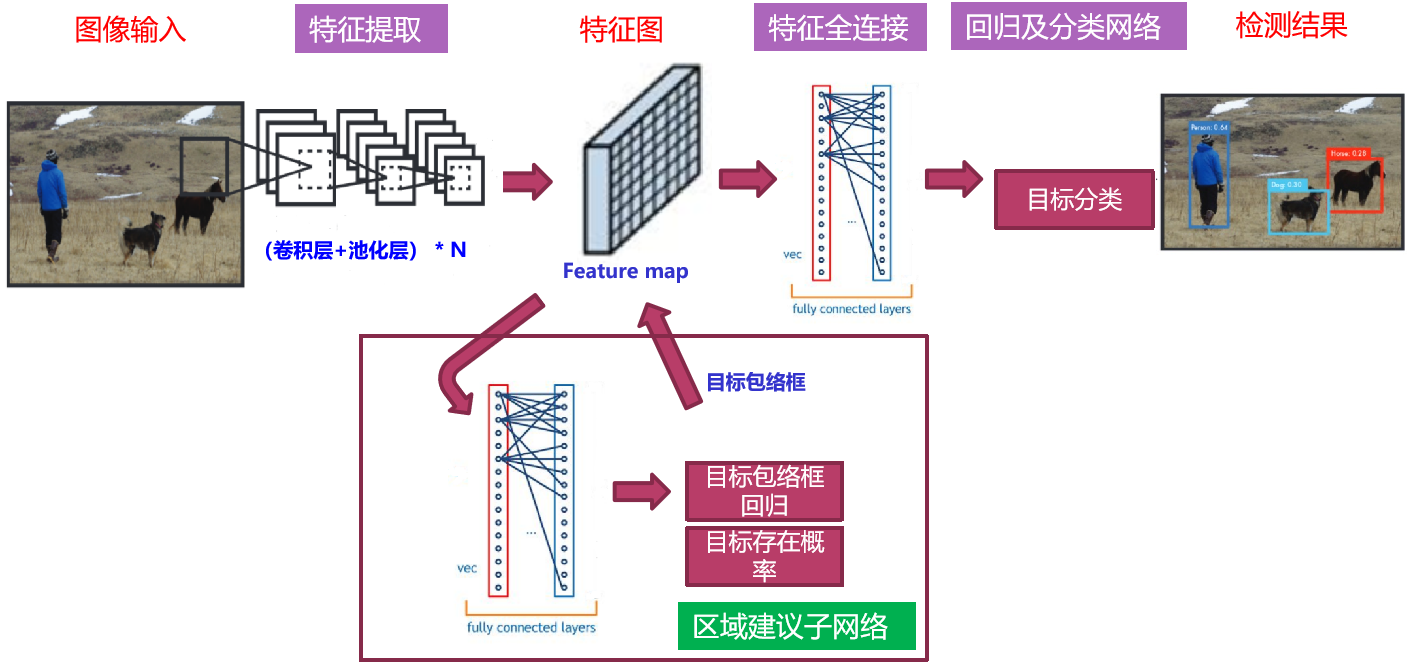
- 双阶段识别网络,比单阶段网络多了区域建议子网络(Region proposal net)
- 区域建议网络的任务是生成目标包络框
2.4.3 One-stage ,Two-stage方法对比
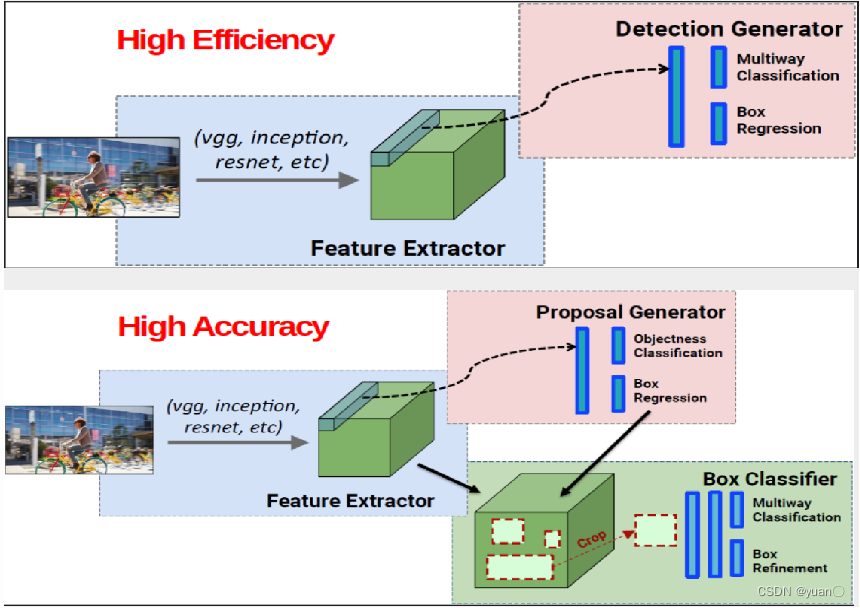
| One-stage | Two-stage |
|---|---|
| One-stage方法更注重效率,相同算力下其处理图片速度更快(高检测帧率) | Two-stage方法更注重检测准确性,此方法检测精度相对更高,误检更少;但相对效率低于One-stage方案。 |
| 端到端方法,便于模型训练 | 分阶段训练,与One-stage方法相比训练慢 |
| 典型的One stage网络包括SSD, YOLO等。 | 典型的网络有Faster-RCNN,R-FCN等。 |
2.5 经典单阶段目标检测网络YOLO
YOLO网络(You Only Look Once)
为什么选择YOLO?
- YOLO是第一个被提出的单阶段目标检测网络
- 由于其高效检测性能,应用广泛
- 自2016年正式发表,YOLO网络已经更新到第版本YOLO V8,版本不断维护迭代,广受研究人员欢迎。
PS:论文——You Only Look Once: Unified, Real-Time Object Detection, Joseph Redmon et al. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
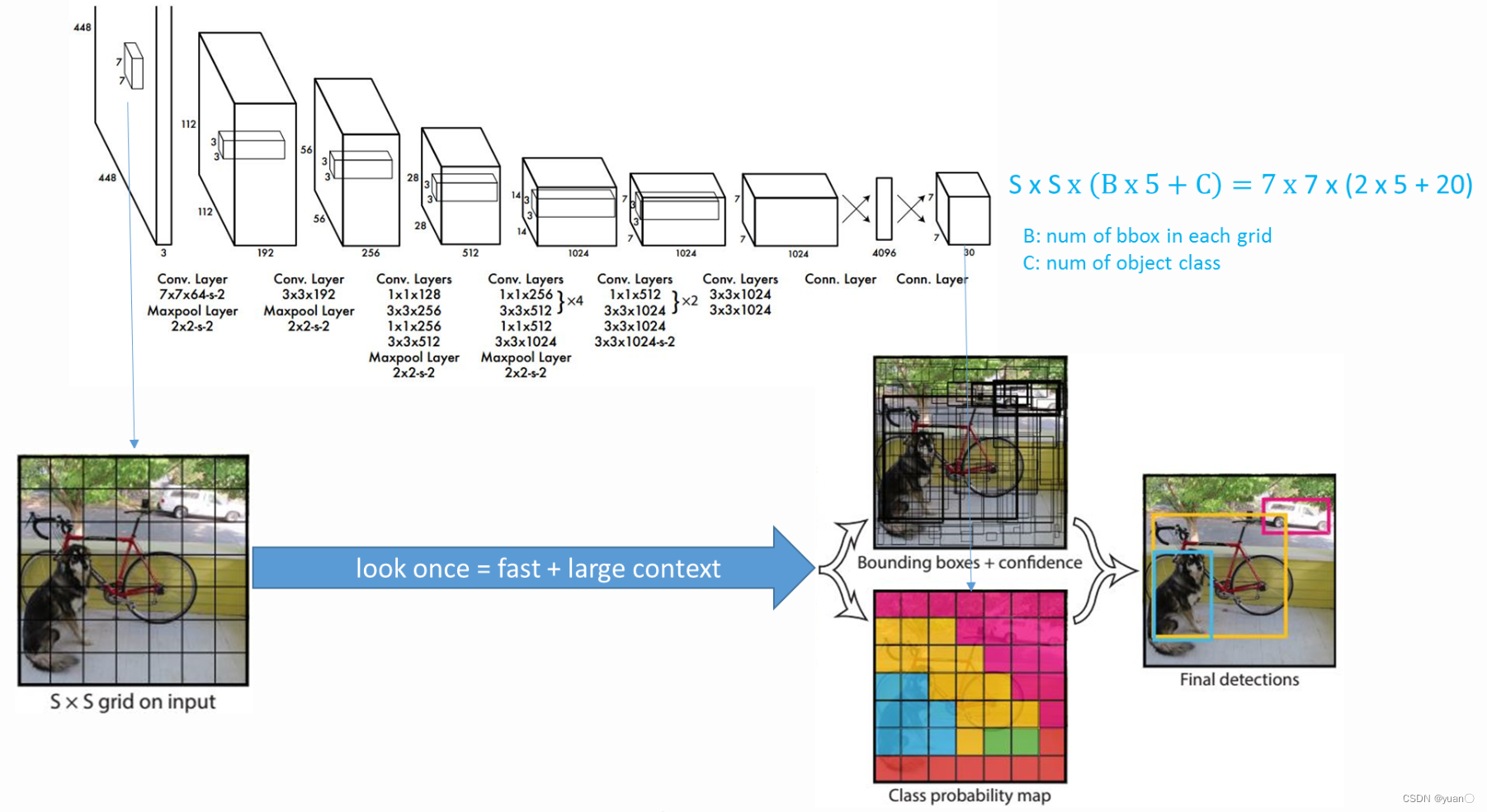
YOLO网络架构
- 输入为448x448x3尺寸图像
- 特征提取包括24个卷积层与2个全连接层
- 输出为7x7x30维特征,包括了包络框及分类信息
- YOLO将全图划分为SXS(实际网络中S=7)的格子,每个格子负责中心在该格子的目标检测
- 每个格子预测两个包络框,一个类别(即一共要预测98个)
- YOLO V1预测20类目标
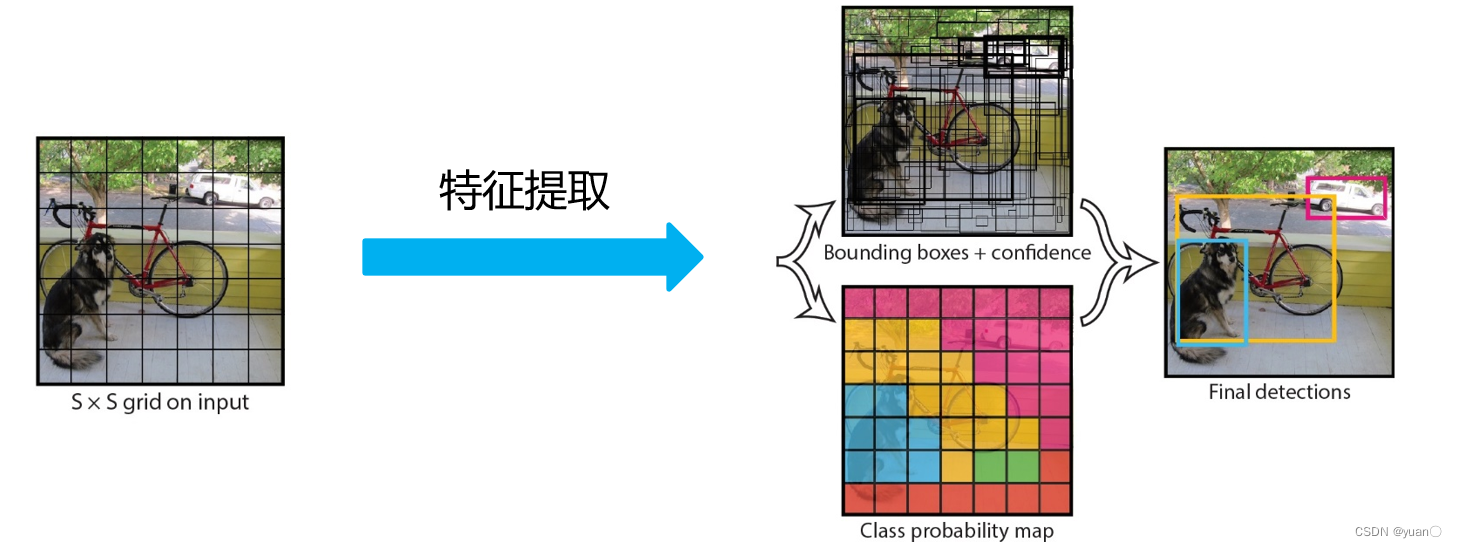
YOLO V1网络 – 详细网络结构
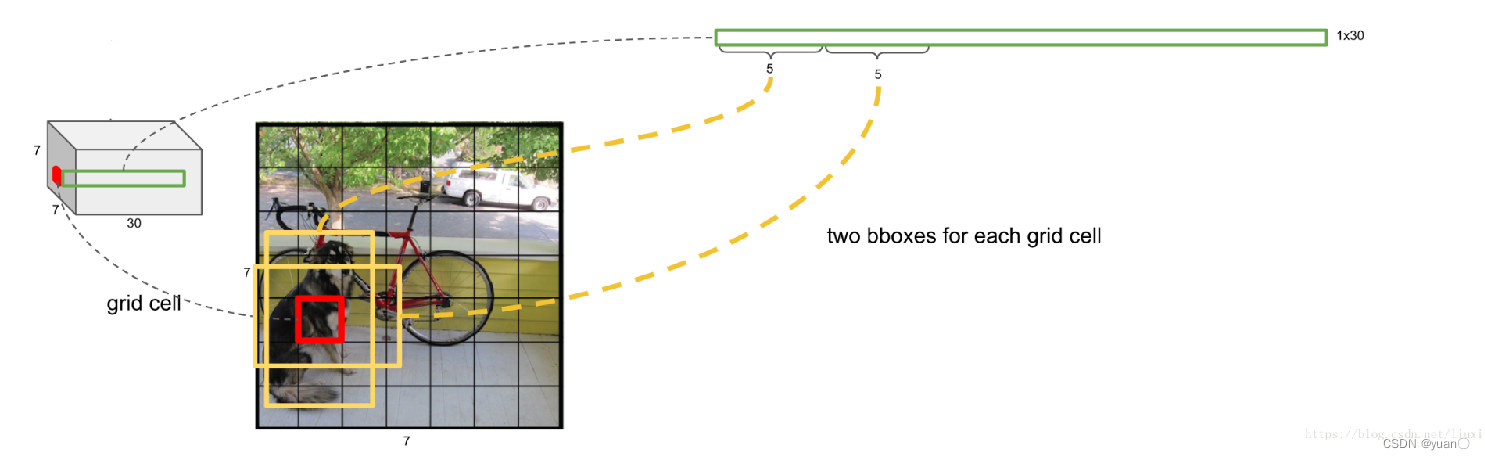
YOLO V1网络 – 特征重排列
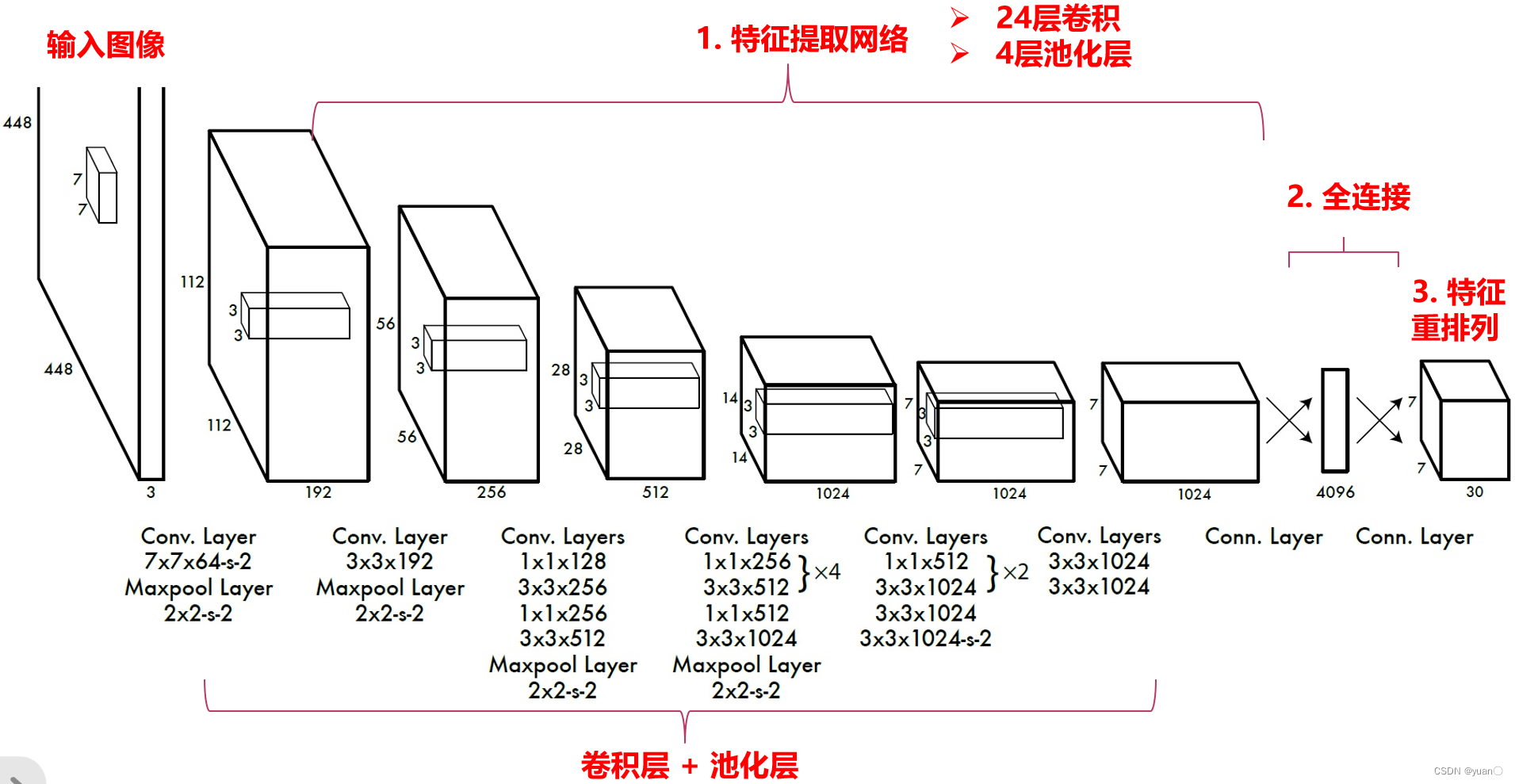
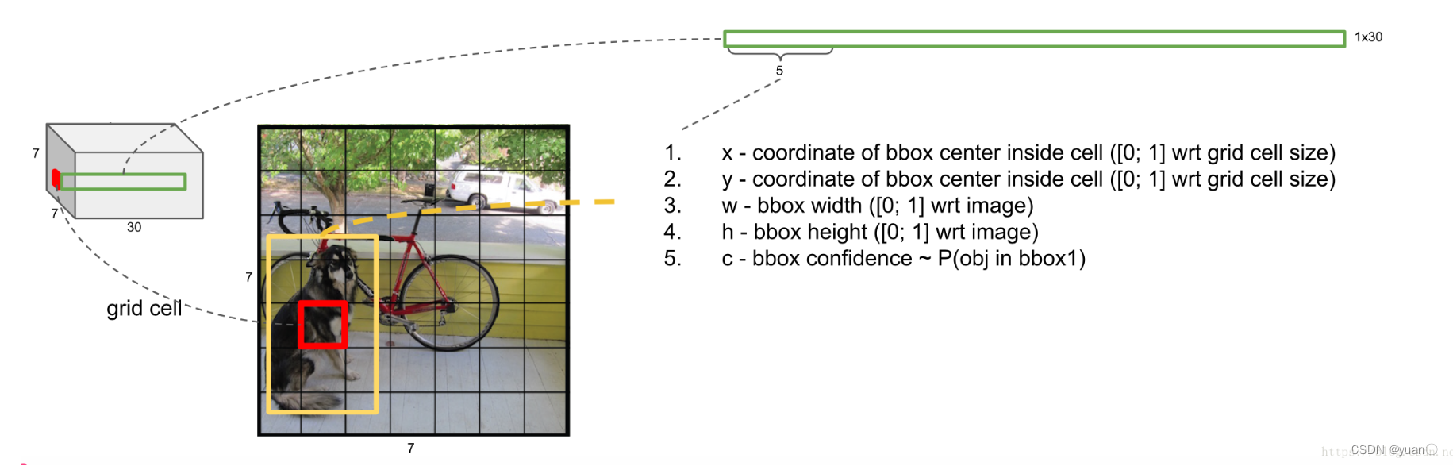
- YOLO网络特征最终排列为7x7x30,对应输入图像中每个格子输出一个30维特征
- 图中展示一个格子对应的30维特征
- 前5维特征,代表了图中红色格子预测的第一个包络框的信息,包括包络框的中心坐标,宽、高,以及包络框中包含目标的概率
- 输入图片的每个格子预测两个包络框
- 第二个5维特征,代表了图中红色格子预测的第二个包络框的信息,包括包络框的中心坐标,宽、高,以及包络框中包含目标的概率
- 每个格子预测的两个包络框,根据概率大小选择使用或丢弃
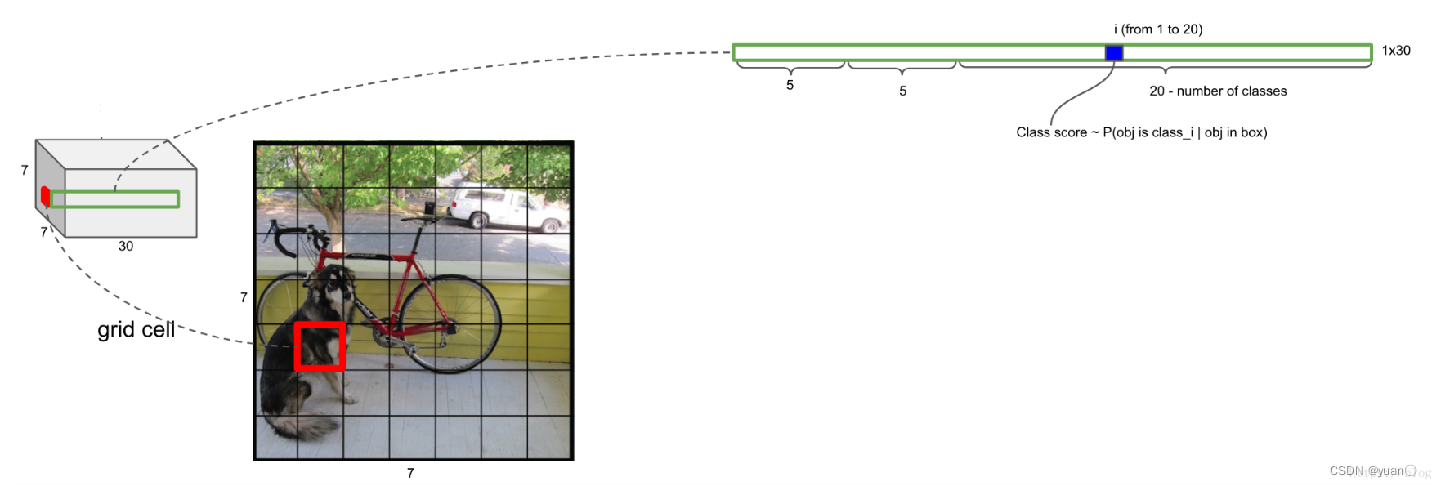
- 30维特征中,剩余的20维特征表示如果格子中对应包含物体,此物体属于预测的20类物体中某一类的概率值
- 如包含物体,此物体的类别选择对应此20维特征中概率最大的类
- 由于YOLO最终的输出特征维度为7730,所以最多检测目标数量为49个
2.6 基于深度学习的目标检测通常步骤

2.6.1 常见数据集
以KITTI数据集为例,说明以下如何划分数据集:
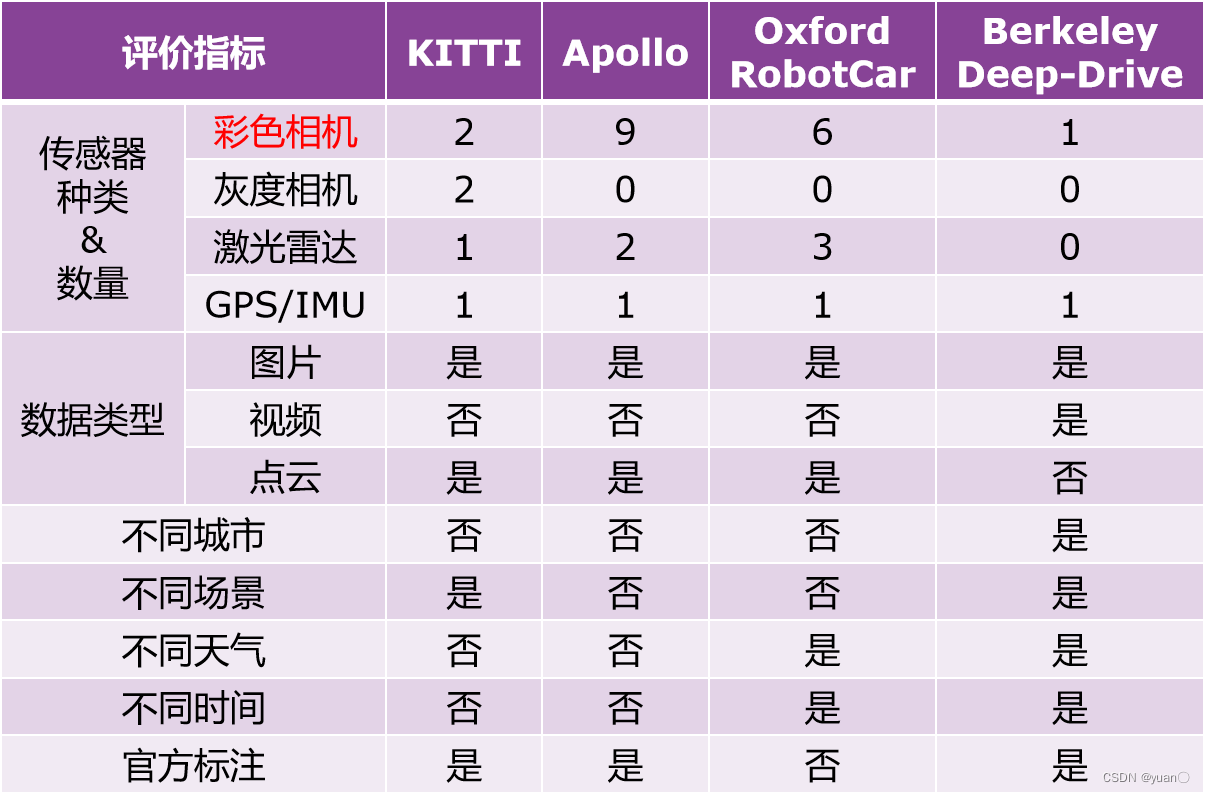
- 训练数据采用7481张带有官方标注的KITTI数据集图片
- 采用留出法,顺序随机,满足数据分布要求
- 训练集:验证集=70:30
2.6.2 数据集标注方法及标签格式
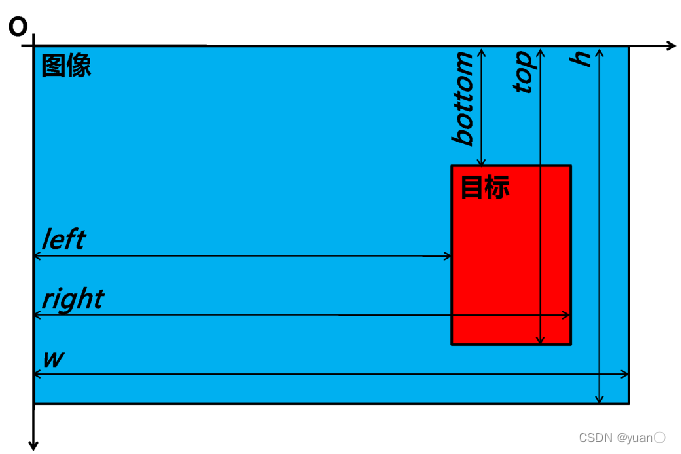
<type> <truncated> <occluded> <alpha> <bbox> <dimensions> <location> <rotation_y> <score>
bbox=<left> <bottom> <right> <top>
Car 0.00 0 -1.35 334.28 180.65 490.02 297.48 1.65 1.67 3.81 -3.18 1.79 12.20 -1.60
Car 0.00 0 -1.93 785.85 179.67 1028.82 340.75 1.52 1.51 3.10 3.18 1.61 8.46 -1.59
Car 0.00 1 -1.80 711.98 179.65 848.82 277.62 1.53 1.58 3.53 2.90 1.66 13.14 -1.59
Truck 0.00 2 1.71 445.91 131.69 539.77 228.36 2.60 2.06 5.42 -3.48 1.52 22.27 1.56
Car 0.00 0 -1.64 660.82 178.72 713.09 222.03 1.46 1.60 3.71 2.71 1.69 26.41 -1.54
2.6.3 损失函数
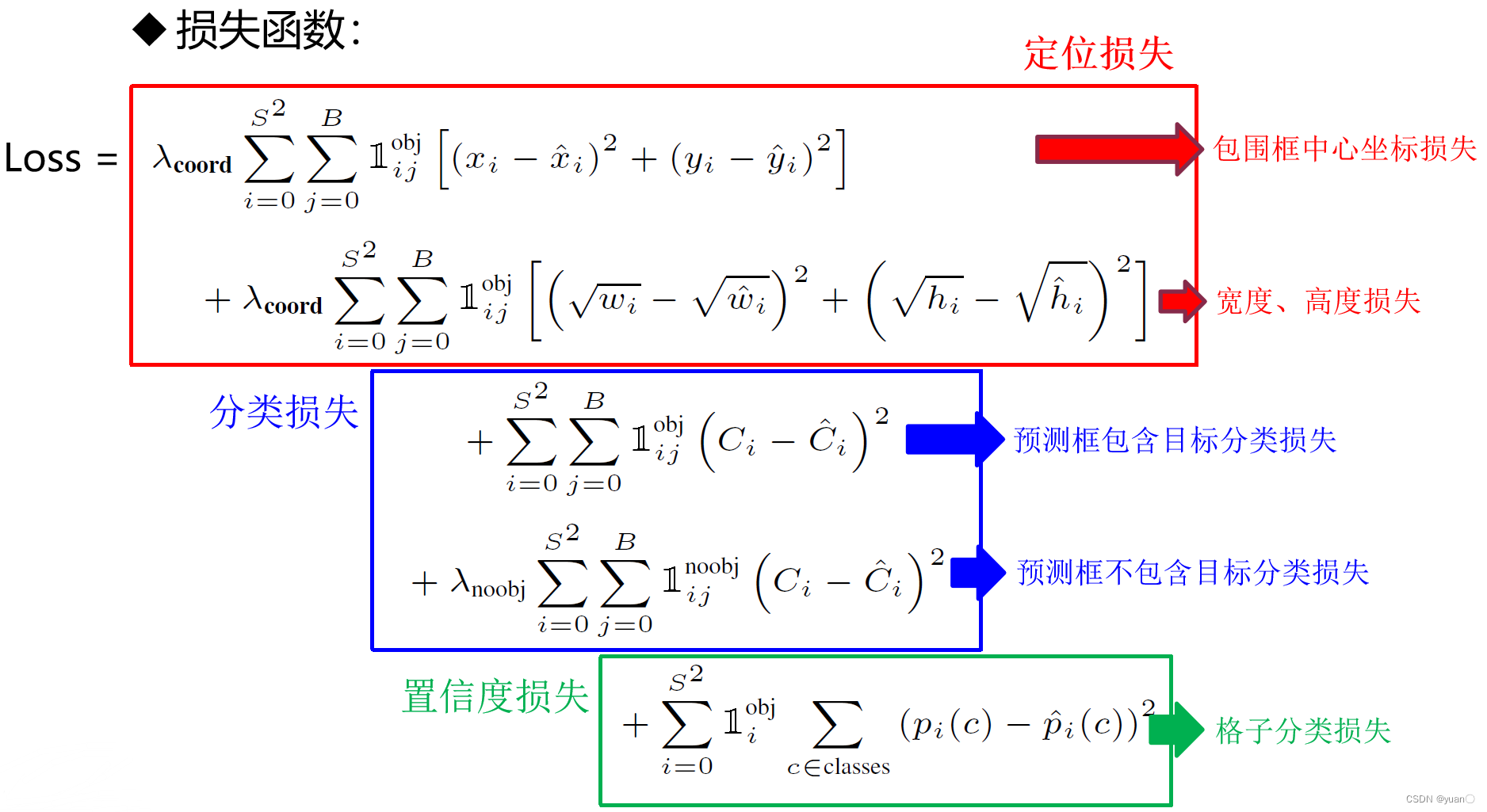
2.6.4 深度学习模型的评测指标
分类问题,模型的预测结果可按照是否正确分为以下几类:
| 类别 | 说明 |
|---|---|
| True Positive(真正, T P TP TP) | 将正类预测为正类数. |
| True Negative(真负 , T N TN TN) | 将负类预测为负类数 |
| False Positive(假正, F P FP FP) | 将负类预测为正类数,即误报 (Type I error). |
| False Negative(假负 , F N FN FN) | 将正类预测为负类数,即漏报 (Type II error) |
准确率(accuracy) =
(
T
P
+
T
N
)
/
(
T
P
+
F
N
+
F
P
+
T
N
)
(TP+TN)/(TP+FN+FP+TN)
(TP+TN)/(TP+FN+FP+TN)
精确率(precision) =
T
P
/
(
T
P
+
F
P
)
TP/(TP+FP)
TP/(TP+FP)
召回率(recall) =
T
P
/
(
T
P
+
F
N
)
TP/(TP+FN)
TP/(TP+FN)
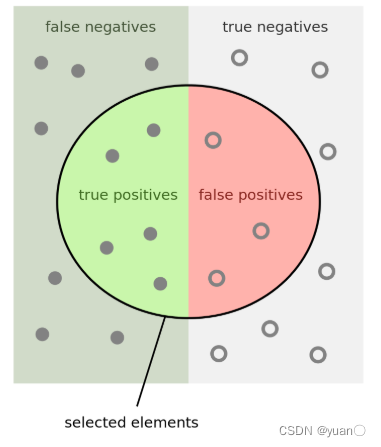
- 图中所有的点表示分类结果,圈内表示分类器分类出来
- 圈内绿色部分,表示分类正确的样本,红色代表分类错误的结果
解释: - Precision可认为是分类器对分类出的正样本,不犯错误的概率
- Recall可以认为是分类器不漏掉正样本的概率

单个检测结果的判断 – 交并比 IoU
交并比:产生的候选框(candidate bound)与原标记框(ground truth bound)的交叠率,即它们的交集与并集的比值。
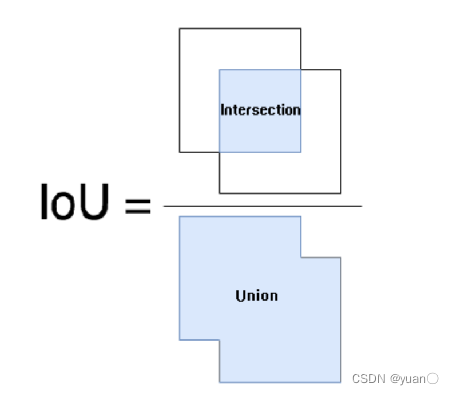
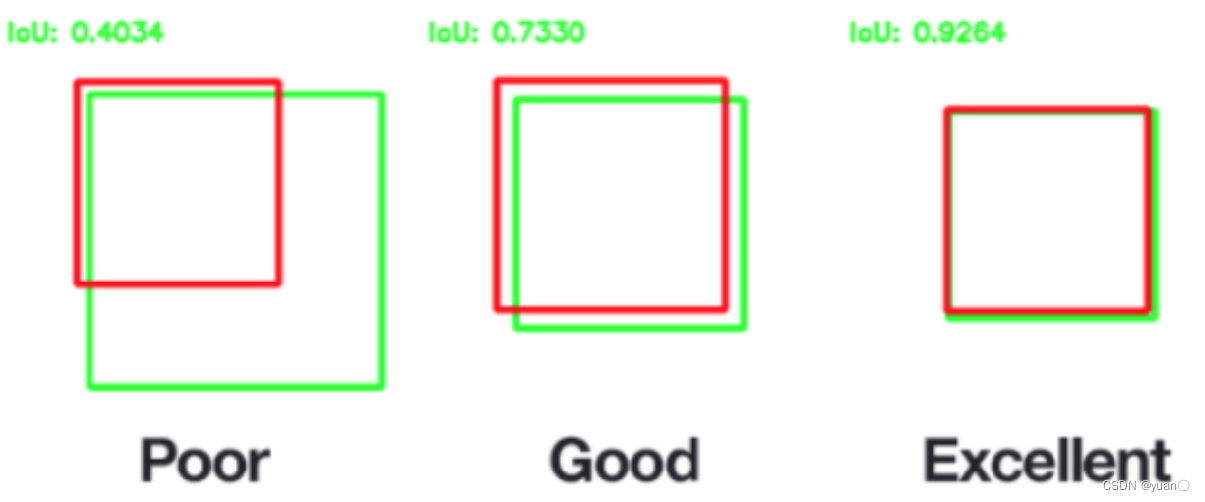
交并比值可以衡量目标检测问题中,检测框相对于真值框的精度。交并比越高,则认为目标检测的位置越精确。
在检测问题中,一般设置若检测框与真实框的IoU 大于阈值θ,则认为该检测有效TP(True Positive)
单类别目标检测结果的判断 – Average Precision(AP)
对某个类别C,首先计算C在一张图片上的Precision:
P
r
e
c
i
s
i
o
n
C
=
N
(
T
P
)
C
N
(
T
o
t
a
l
O
b
j
e
c
t
s
)
C
Precisio{n_C} = \frac{{N{{(TP)}_C}}}{{N{{(TotalObjects)}_C}}}
PrecisionC=N(TotalObjects)CN(TP)C
对于类别C,可能在多张图片上有该类别,计算类别C的AP指数:
A
v
e
r
a
g
e
P
r
e
c
i
s
i
o
n
C
=
N
P
r
e
c
i
s
i
o
n
C
N
(
T
o
t
a
l
I
m
a
g
e
s
)
C
AveragePrecisio{n_C} = \frac{{NPrecisio{n_C}}}{{N{{(TotalImages)}_C}}}
AveragePrecisionC=N(TotalImages)CNPrecisionC
对于整个数据集,存在多个类别C1、C2、C3, mAP(mean Average Precision) 表示所有类别的平均精确度:
M
e
a
n
A
v
e
r
a
g
e
P
r
e
c
i
s
i
o
n
C
=
N
A
v
e
r
a
g
e
P
r
e
c
i
s
i
o
n
C
N
(
c
l
a
s
s
e
s
)
C
MeanAveragePrecisio{n_C} = \frac{{NAveragePrecisio{n_C}}}{{N{{(classes)}_C}}}
MeanAveragePrecisionC=N(classes)CNAveragePrecisionC
声明
本人所有文章仅作为自己的学习记录,若有侵权,联系立删。本系列文章主要参考了清华大学、北京理工大学、哈尔滨工业大学、深蓝学院、百度Apollo等相关课程。